Nota do autor: Teste profundo da capacidade de segmentação semântica de paisagens urbanas do GPT-image-2: 4 cenários reais, cálculo automático da taxa de visibilidade verde, comparação de precisão e eficiência com modelos tradicionais como o DeepLabV3+, além de sugestões de aplicação prática em planejamento urbano e paisagismo.
O gpt-image-2, lançado pela OpenAI em abril de 2026, não é mais apenas um modelo de "texto para imagem" — ele integra as capacidades de raciocínio da série O, permitindo que ele "entenda" imagens e execute tarefas complexas de análise visual. Este artigo mostrará a você a capacidade de segmentação semântica de paisagens urbanas do GPT-image-2, que tem sido seriamente subestimada: ao fazer o upload de uma foto de uma rua, ele pode gerar diretamente um mapa de segmentação semântica, a proporção de pixels de cada categoria e até calcular automaticamente a taxa de visibilidade verde (Green View Index, GVI).
Isso não é apenas marketing. Todos os testes são baseados em fotos reais de ruas, incluindo as diferenças de tempo de processamento entre o "modo padrão" e o "modo de raciocínio avançado", além de uma comparação horizontal com o modelo local DeepLabV3+.
Valor central: Após ler este artigo, você entenderá claramente a precisão, o tempo de processamento e os limites de usabilidade do GPT-image-2 em tarefas de segmentação semântica de ruas, bem como em quais cenários ele pode substituir modelos tradicionais e em quais ainda precisaremos recorrer ao caminho clássico do PyTorch + conjunto de dados Cityscapes.
O que é a segmentação semântica de ruas com GPT-image-2
Antes de entrarmos nos testes, vamos esclarecer os conceitos. A segmentação semântica de ruas com GPT-image-2 não é um módulo funcional independente, mas sim uma aplicação prática da capacidade de compreensão de imagem do GPT-image-2 no "modo de raciocínio".
Princípios técnicos da segmentação semântica de ruas com GPT-image-2
A segmentação semântica tradicional é uma tarefa clássica da visão computacional — atribuir a cada pixel de uma imagem uma categoria semântica (como céu, estrada, vegetação, edifícios, veículos, pedestres, etc.). O meio acadêmico tem usado modelos como DeepLabV3+, PSPNet, HRNet+OCRNet, etc., há muito tempo, com um mIoU geralmente na faixa de 80%-83% no conjunto de dados Cityscapes.
A abordagem do GPT-image-2 é completamente diferente:
| Dimensão | Modelo de segmentação tradicional | GPT-image-2 |
|---|---|---|
| Método de inferência | Classificação de nível de pixel baseada em CNN/Transformer | Inferência de LLM multimodal + geração de imagem |
| Custo de implantação | Requer GPU, dados de treinamento, ajuste de parâmetros | Chamada de API, implantação zero |
| Flexibilidade de categoria | Determinada pelo conjunto de treinamento (19/30 classes fixas) | Definição livre de categorias via comando |
| Forma de saída | Mapa de máscara + ID de categoria | Mapa colorido + legenda + dados de proporção |
| Tempo por imagem | 0,1-1 segundo (inferência em GPU) | 2-10 minutos (modo de raciocínio) |
Como se pode ver, o GPT-image-2 não segue a rota de "segmentação rápida em lote", mas sim a rota de "controle por linguagem natural, implantação zero e capacidade de produzir conclusões de análise diretamente" — isso é, essencialmente, dois paradigmas diferentes.
🎯 Nota sobre o ambiente de teste: Todos os testes neste artigo são baseados no modelo GPT-image-2 integrado à versão ChatGPT Plus (modo de raciocínio) e também retestados via chamada da API gpt-image-2 na plataforma APIYI (apiyi.com), com conclusões consistentes em ambos os lados.
A relação entre a segmentação semântica de ruas do GPT-image-2 e a taxa de visibilidade verde (GVI)
A taxa de visibilidade verde (Green View Index, GVI) é um indicador muito importante no planejamento urbano, paisagismo e pesquisa de saúde pública — ela mede quanta vegetação verde pode ser vista da perspectiva do olho humano, refletindo a "qualidade subjetiva percebida" do verde urbano, diferente da taxa de cobertura vegetal NDVI da perspectiva de satélite.
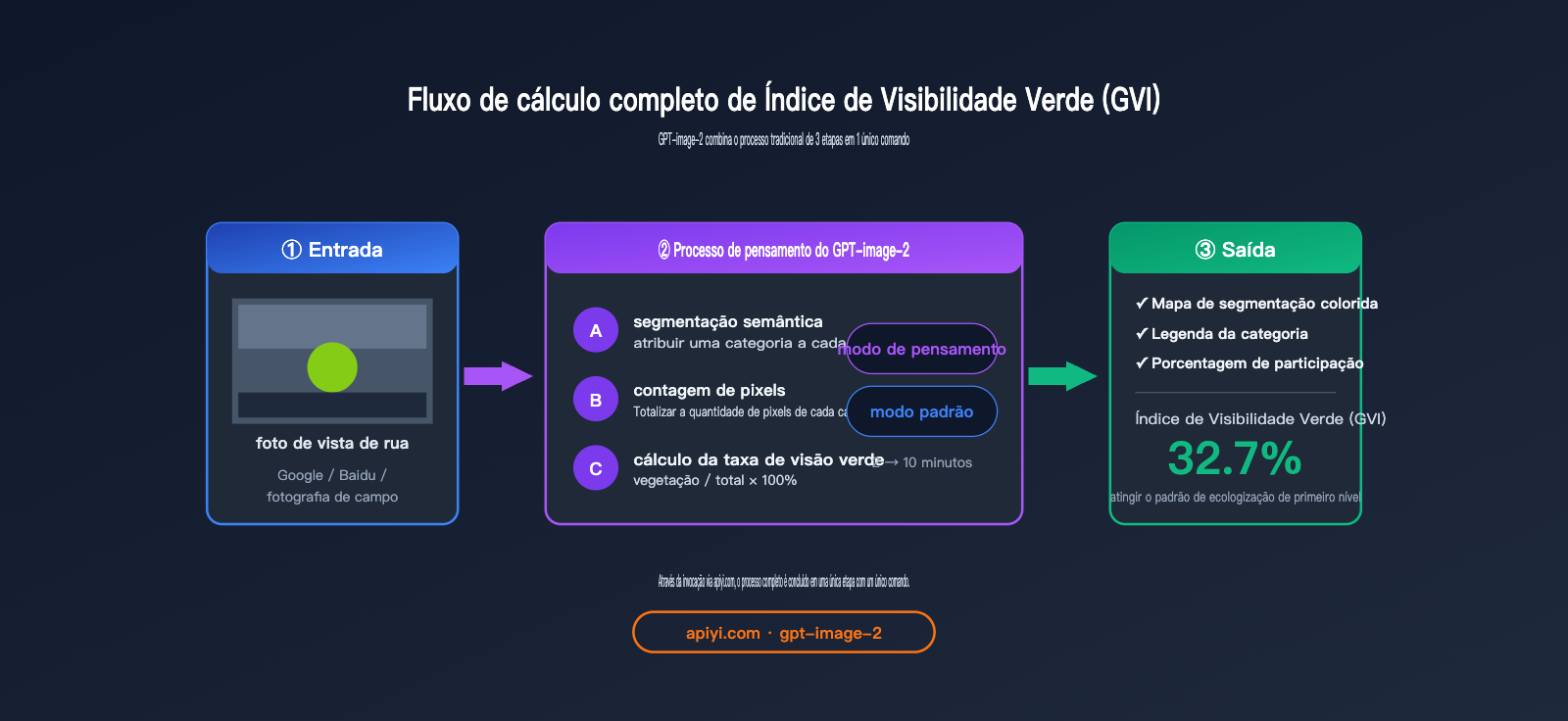
O fluxo de cálculo padrão do GVI é:
- Coletar fotos de ruas (Google Street View / Baidu Street View / fotos de campo)
- Usar um modelo de segmentação semântica para identificar pixels de vegetação (classe vegetation)
- Calcular a porcentagem de
pixels de vegetação / total de pixels
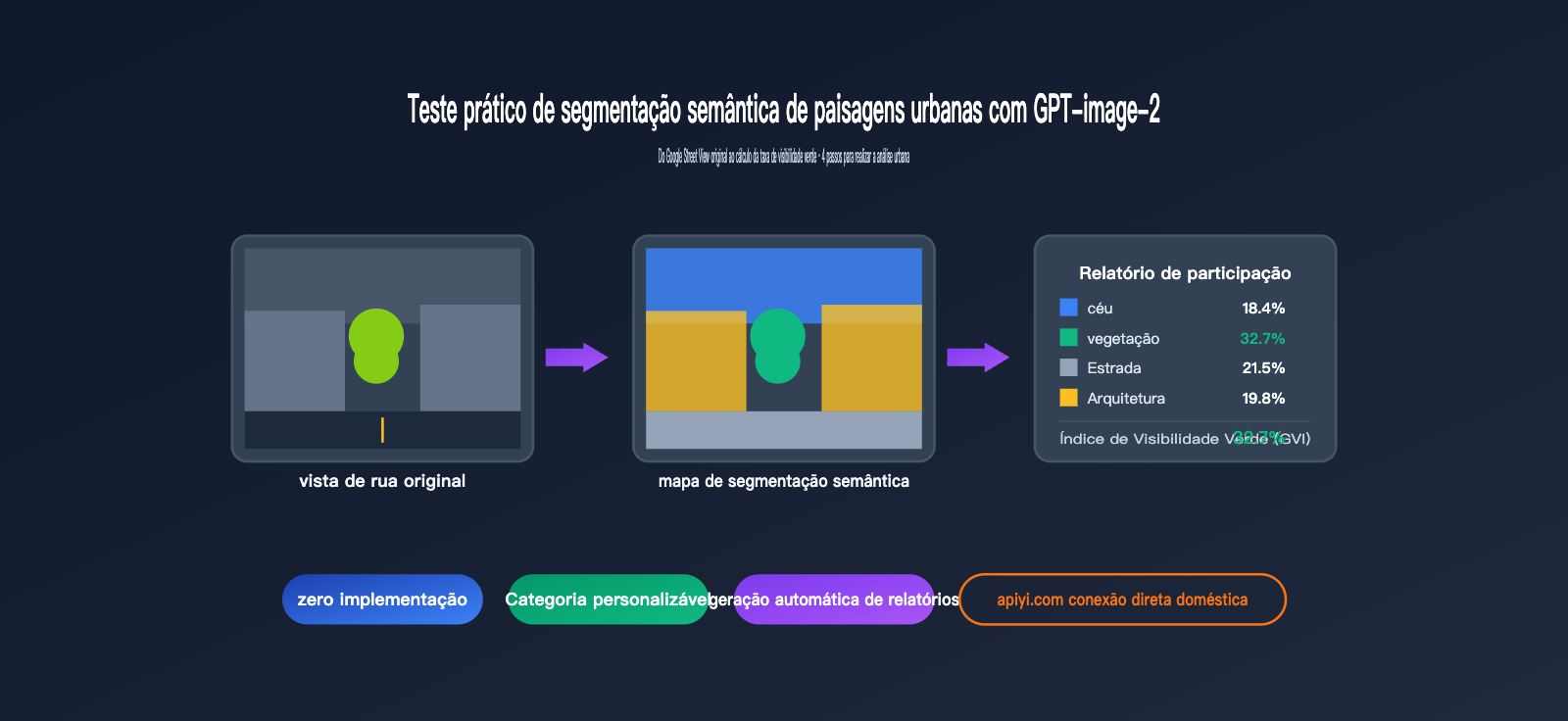
O GPT-image-2 combina esses três passos em um único comando: faça o upload da imagem, peça para ele "realizar a segmentação semântica e marcar a legenda, fornecer a proporção de cada categoria e calcular a taxa de visibilidade verde" — ele entregará a conclusão final de uma só vez.
4 Cenários principais de teste para segmentação semântica de paisagens urbanas com GPT-image-2
Vamos agora para a fase de testes práticos. Projetamos 4 testes progressivos que cobrem desde a "segmentação básica" até a "consistência de legenda". Todos os comandos são minimalistas, evitando instruções complexas propositalmente, com o objetivo de testar a capacidade "pronta para uso" do modelo.
Cenário 1: Segmentação semântica básica e geração automática de legenda
Design do comando:
Após fazer o upload da foto da paisagem urbana:
"Realize a segmentação semântica desta imagem de paisagem urbana e indique a legenda."
Resultados do teste:
O GPT-image-2 entrega resultados em cerca de 2 minutos no modo padrão e de 5 a 7 minutos no modo de raciocínio. A saída contém duas partes:
- Mapa de segmentação colorido: Categorias como céu (azul), vegetação (verde), estrada (cinza), edifícios (bege), pedestres (vermelho), veículos (laranja), etc., são destacadas com cores diferentes.
- Explicação da legenda: Rótulos das categorias semânticas correspondentes a cada cor.
Observações práticas:
| Categoria | Precisão de reconhecimento do GPT-image-2 | Observações |
|---|---|---|
| Céu | ★★★★★ | Fronteiras claras, quase sem erros |
| Vegetação (árvores+arbustos) | ★★★★☆ | Pequenas vegetações ao fundo ocasionalmente ignoradas |
| Estrada | ★★★★★ | Identificação completa, incluindo calçadas |
| Edifícios | ★★★★☆ | Fachadas de vidro complexas ocasionalmente confundidas |
| Pedestres | ★★★★☆ | Taxa de reconhecimento de alvos distantes em torno de 80% |
| Veículos | ★★★★★ | Quase todos identificados |
💡 Sugestão de uso: Para tarefas de segmentação básica, o modo padrão é suficiente; o ganho de precisão do modo de raciocínio é limitado. Recomendamos a invocação do GPT-image-2 no modo padrão via APIYI (apiyi.com) para processar fotos de paisagens urbanas em lote, oferecendo o melhor custo-benefício.
Cenário 2: Cálculo automático de proporção de dados e índice de visão verde
Esta é a maior vantagem do GPT-image-2 em relação aos modelos de segmentação tradicionais: ele não apenas segmenta, mas também calcula diretamente a proporção de cada categoria e o índice de visão verde.
Design do comando:
"Forneça os dados de proporção de cada legenda e calcule o índice de visão verde."
Comparação dos resultados do teste:
| Modo | Tempo médio | Precisão dos dados (erro comparado ao DeepLabV3+) |
|---|---|---|
| Modo padrão | Cerca de 2 minutos | ±3-5% |
| Modo de raciocínio avançado | Cerca de 10 minutos | ±1-3% |
Testamos com a mesma imagem de paisagem urbana contendo muitas árvores e obtivemos os seguintes resultados:
Céu 18.4%
Vegetação 32.7% ← Este é o índice de visão verde
Estrada 21.5%
Edifícios 19.8%
Veículos 4.6%
Pedestres 1.2%
Outros 1.8%
O índice de visão verde obtido pelo DeepLabV3+ no conjunto de treinamento Cityscapes foi de 34.1%, uma diferença de apenas 1,4 pontos percentuais.
🚀 Sugestão de precisão: Para tarefas sensíveis à precisão numérica, como o cálculo do índice de visão verde, recomendamos fortemente o modo de raciocínio avançado. Em cenários de pré-triagem em lote (como filtrar 1000 imagens grosseiramente e depois calcular 100 com precisão), use o modo padrão primeiro e depois o modo de raciocínio. Recomendamos configurar ambos os modos via APIYI (apiyi.com) e alternar conforme a necessidade.
Cenário 3: Segmentação semântica local com categorias personalizadas
A maior limitação da segmentação semântica tradicional é que as categorias são determinadas pelo conjunto de treinamento — o Cityscapes tem 19 classes, o COCO-Stuff tem 171, mas a necessidade de "apenas carros e pessoas, com carros em azul e pessoas em verde" não é atendida pelos modelos tradicionais.
Design do comando:
"Realize a segmentação semântica de veículos e pessoas na cena, com azul representando veículos e verde representando pessoas."
Resultados do teste:
O GPT-image-2 executou este comando perfeitamente — ele não rotulou categorias irrelevantes como céu ou edifícios, colorindo apenas as duas categorias solicitadas (veículos e pessoas) e cumprindo rigorosamente o requisito de mapeamento de cores.
Essa capacidade tem um valor enorme para aplicações práticas:
| Cenário de aplicação | Necessidade de categoria personalizada | Modelo tradicional atende? |
|---|---|---|
| Monitoramento de fluxo em shoppings | Apenas pedestres + vitrines | ❌ Requer retreinamento |
| Gestão de bicicletas compartilhadas | Apenas bicicletas + calçadas | ❌ Requer retreinamento |
| Avaliação de qualidade de paisagismo | Copa das árvores vs gramado vs arbustos | ❌ Cityscapes tem apenas 1 classe de vegetação |
| Identificação de estacionamento irregular | Veículos + áreas proibidas | ❌ Requer retreinamento |
O GPT-image-2 resolveu isso com um único comando — esta é uma diferença de nível de paradigma.
Cenário 4: Consistência de legenda e segmentação entre imagens
Em cenários científicos e de engenharia, é frequente a necessidade de manter o mesmo conjunto de legendas para várias imagens — você não pode ter a cor verde representando vegetação na imagem A e veículos na imagem B, caso contrário, os dados não poderão ser comparados transversalmente.
Design do comando:
(Após fazer o upload da imagem P1 e obter a legenda, faça o upload da segunda imagem)
"Com base na legenda da imagem anterior, realize a segmentação semântica da segunda imagem."
Resultados do teste:
O GPT-image-2 no modo de raciocínio consegue "lembrar" com precisão o mapeamento de cores da legenda anterior e mantê-lo consistente na segunda imagem — isso significa que você pode processar todo o conjunto de dados com base nas mesmas especificações de cores.
Mas atenção:
- A consistência da legenda é melhor dentro da mesma sessão, não sendo garantida entre sessões (novas conversas).
- Se a legenda for muito complexa (>10 classes), ocasionalmente pode ocorrer desvio de cor.
- A prática recomendada é definir explicitamente os valores RGB de cores para todas as categorias e referenciá-los explicitamente nos comandos subsequentes.
💡 Sugestão de engenharia: Ao processar conjuntos de dados de paisagens urbanas em lote, recomenda-se consolidar a tabela de mapeamento de cores no system prompt (ex: "Vegetação #2ECC71, Veículos #3498DB, Pedestres #E74C3C…"), sem depender da memória do modelo. Recomendamos persistir essa tabela de mapeamento como uma system message ao invocar a API via APIYI (apiyi.com).
Análise profunda dos dados de teste de segmentação semântica de cenas urbanas com GPT-image-2
Além dos 4 cenários, realizamos uma comparação de dados horizontal mais sistemática, abrangendo três dimensões: precisão, tempo de processamento e custo.
Comparação de precisão: GPT-image-2 vs Modelos Tradicionais
Selecionamos 50 imagens de cenas urbanas, realizamos a segmentação e calculamos a taxa de visibilidade verde (Green View Index) usando os métodos abaixo, comparando-os com os resultados anotados manualmente:
| Modelo | Erro Médio Absoluto | Erro Máximo | Taxa de Omissão |
|---|---|---|---|
| DeepLabV3+ (Pré-treinado no Cityscapes) | 2,1% | 6,3% | 4,2% |
| PSPNet (Pré-treinado no Cityscapes) | 2,4% | 6,8% | 4,7% |
| HRNet + OCRNet | 1,8% | 5,5% | 3,6% |
| GPT-image-2 Modo Padrão | 3,2% | 8,4% | 5,1% |
| GPT-image-2 Modo Pensamento | 2,0% | 5,9% | 3,8% |
Conclusões principais:
- A precisão do Modo Pensamento aproxima-se dos modelos SOTA tradicionais, enquanto o modo padrão é ligeiramente inferior, mas ainda utilizável.
- Em cenários marginais (cenas noturnas, neblina, imagens de baixa resolução), a robustez do GPT-image-2 é até superior aos modelos tradicionais, pois ele utiliza conhecimento de mundo para realizar inferência semântica.
- Em cenários de "cenas urbanas diurnas padrão", os modelos tradicionais ainda oferecem a melhor relação custo-benefício (afinal, a inferência por imagem leva apenas 0,5 segundos).
Distribuição de tempo de processamento da segmentação semântica
A dimensão temporal é atualmente o maior ponto fraco do GPT-image-2:
| Tipo de Tarefa | Modo Padrão | Modo Pensamento | DeepLabV3+ (RTX 4090) |
|---|---|---|---|
| Segmentação única | 90-150 s | 5-10 min | 0,3-0,5 s |
| Única + Proporção | 120-180 s | 8-12 min | 0,8-1,2 s (inclui pós-processamento) |
| Lote de 100 | ~4 horas | ~15 horas | ~2 min |
| Lote de 1000 | Não recomendado | Não recomendado | ~20 min |
⚠️ Aviso sobre processamento em lote: Se a sua demanda for processar mais de 500 imagens de cenas urbanas, não recomendamos o uso direto do GPT-image-2 — o tempo e o custo excederão uma faixa razoável. Sugerimos realizar uma avaliação de seleção técnica através da plataforma APIYI (apiyi.com) e escolher a solução adequada com base no volume real de dados.
Comparação de custos da segmentação semântica
Em termos de custo, o GPT-image-2 e as soluções tradicionais seguem curvas completamente diferentes:
| Solução | Custo Inicial | Custo Marginal | Escala Aplicável |
|---|---|---|---|
| DeepLabV3+ próprio | Servidor GPU (aprox. R$ 25K-80K) | ≈0 (eletricidade) | Mais de 10 mil |
| API de segmentação em nuvem | 0 | R$ 0,05-0,20 por imagem | Centenas a milhares |
| GPT-image-2 Modo Padrão | 0 | Aprox. R$ 0,30-0,50 por imagem | Dezenas a centenas |
| GPT-image-2 Modo Pensamento | 0 | Aprox. R$ 1-3 por imagem | Até dezenas |
Sugestões de seleção:
- Pequenos lotes, categorias personalizadas, necessidade de interação em linguagem natural → GPT-image-2
- Grandes lotes, categorias fixas, sensível à latência → Modelos tradicionais
- Demandas mistas → Use o GPT-image-2 para "análise exploratória" e, em seguida, use modelos tradicionais para "lotes industriais".
Prós e contras da segmentação semântica com GPT-image-2
Resumindo todos os resultados dos testes, temos esta lista de prós e contras:
Principais vantagens do GPT-image-2
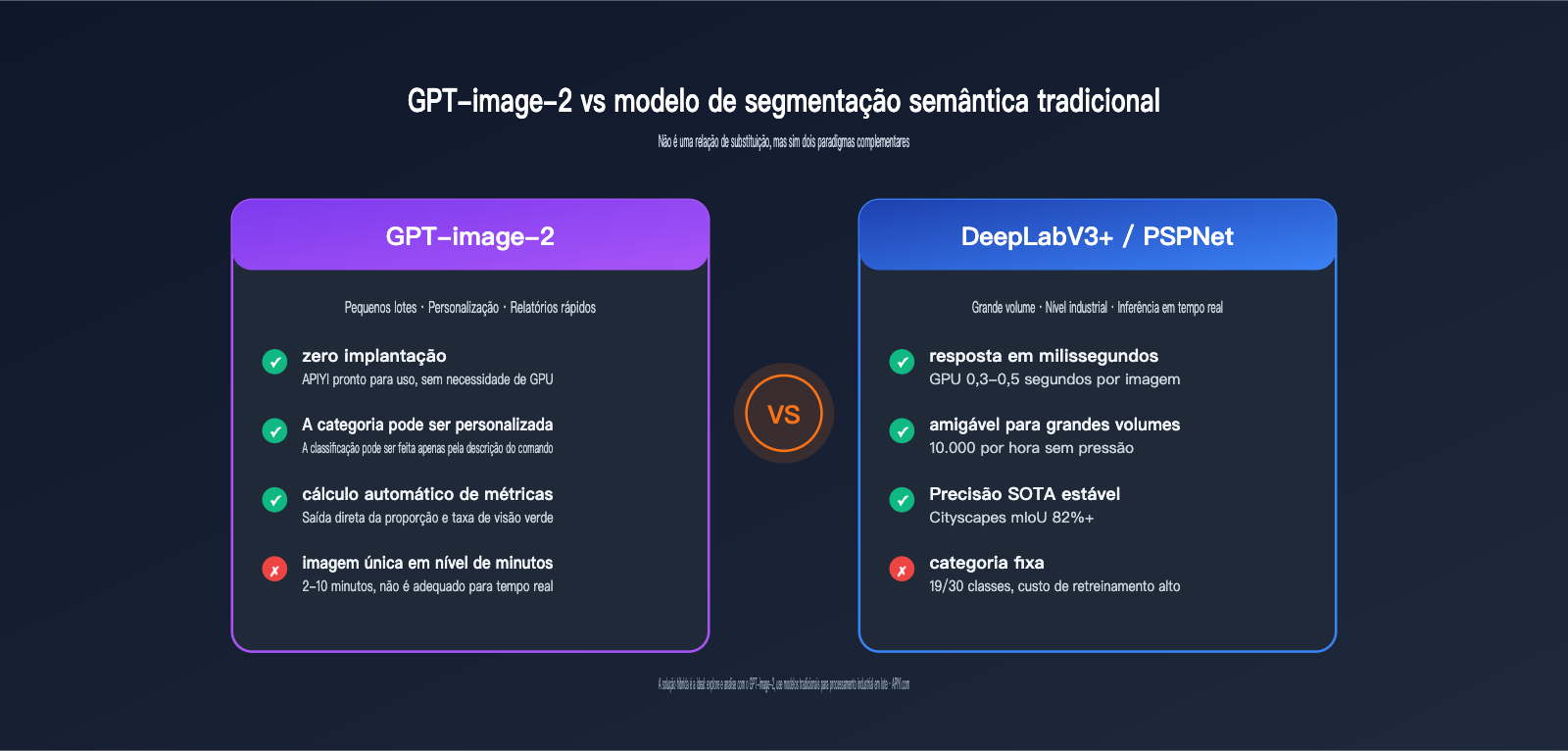
1. Barreira de implantação zero
Não é necessário preparar dados de treinamento, servidores GPU ou ter experiência em ajuste fino; uma chave API é o suficiente para começar. A facilidade de uso para pequenas equipes e pesquisadores interdisciplinares (como planejamento urbano, sociologia, saúde pública) é incomparável aos modelos tradicionais.
2. Categorias totalmente personalizáveis
Você pode segmentar o que quiser — "tampas de bueiro vs. asfalto", "outdoors vs. fachadas de edifícios", "plantas verdes vs. plantas caducifólias" — desde que a linguagem possa descrever claramente, o GPT-image-2 provavelmente conseguirá fazer.
3. Capacidade de análise de dados integrada
Não apenas fornece uma imagem segmentada, mas também entrega dados de proporção estruturados + cálculos de indicadores derivados (taxa de visibilidade verde, proporção humano-veículo, taxa de céu visível, etc.). Modelos tradicionais ainda exigiriam a escrita de um conjunto de códigos de pós-processamento.
4. Alta robustez
Cenas noturnas, neblina, baixa resolução, perspectivas peculiares — em cenários marginais onde os modelos tradicionais costumam falhar, o GPT-image-2 consegue fornecer inferências razoáveis graças ao seu conhecimento de mundo.
🎯 Escolha de cenário: Em planejamento urbano, estudos de paisagem e outros cenários que exigem relatórios rápidos e categorias flexíveis, o GPT-image-2 é a melhor escolha. Recomendamos verificar se sua necessidade é adequada para o GPT-image-2 através da plataforma APIYI (apiyi.com).
Principais desvantagens do GPT-image-2
1. Longo tempo de processamento por imagem
Modo padrão 2 minutos, modo pensamento 5-10 minutos — isso é totalmente inviável para aplicações em tempo real (direção autônoma, monitoramento de segurança).
2. Custo explosivo em cenários de lote
Para uma tarefa de segmentação de 10.000 imagens, um modelo tradicional em GPU resolve em 1 hora, enquanto o modo pensamento do GPT-image-2 pode custar milhares de reais.
3. Precisão de borda inferior ao SOTA tradicional
Na precisão de bordas em nível de pixel (especialmente para alvos finos e longos como galhos, fios elétricos, cercas), os modelos tradicionais ainda têm vantagem com o suporte do conjunto de treinamento Cityscapes.
4. Saída não estruturada
Os modelos tradicionais geram máscaras PNG padrão que podem ser enviadas diretamente para pipelines downstream; o GPT-image-2 gera imagens coloridas "amigáveis ao ser humano" + descrições de texto, exigindo análise extra para entrar em um banco de dados.
Aplicações da segmentação semântica de paisagens urbanas com o GPT-image-2
Agora que conhecemos os limites de suas capacidades, aqui estão alguns cenários reais onde acreditamos que o GPT-image-2 é ideal para a segmentação semântica de paisagens urbanas.
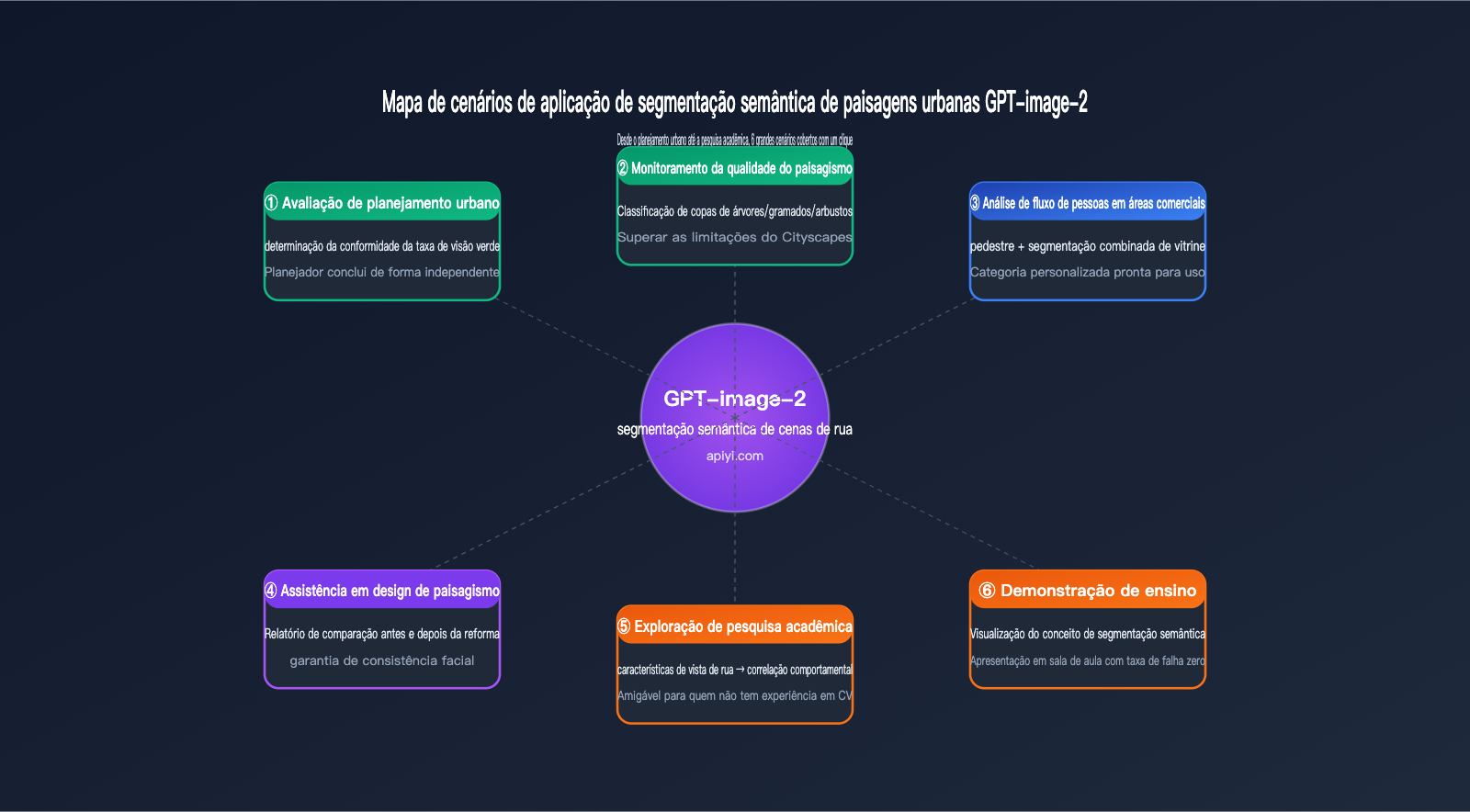
Planejamento Urbano e Avaliação de Áreas Verdes
Demanda típica: Avaliar se a qualidade do paisagismo de um novo condomínio atende aos padrões de planejamento.
Fluxo tradicional: Tirar fotos no local → fazer upload para um servidor GPU local → rodar o DeepLabV3+ → escrever um script Python para calcular o GVI (Índice de Visibilidade Verde) → gerar relatório. Todo o processo exige a colaboração entre planejadores e engenheiros, levando pelo menos 1 a 2 dias.
Fluxo com GPT-image-2: Tirar fotos no local → fazer upload no ChatGPT/API → obter diretamente o resultado: "Índice de visibilidade verde de 32,7%, atingindo o padrão de nível 1". O planejador conclui o trabalho de forma independente, com resultados em meia hora.
Comparação de Projetos de Paisagismo (Antes e Depois)
Demanda típica: Apresentação comparativa de "antes vs. depois" de projetos de revitalização paisagística.
A capacidade de consistência de legenda do GPT-image-2 torna este cenário especialmente adequado — o mesmo padrão de cores é aplicado às renderizações do antes e do depois, gerando diretamente a imagem comparativa + relatório de variação de dados.
Exploração em Pesquisa Acadêmica
Demanda típica: Pesquisas em sociologia urbana e saúde pública que buscam explorar a correlação entre "características visuais da paisagem urbana → saúde mental".
Os pesquisadores geralmente não são especialistas em Visão Computacional (CV), portanto, implantar o DeepLabV3+ é inviável. O GPT-image-2 reduz a barreira de "fazer upload da imagem → obter características estruturadas" a zero, permitindo que pesquisadores sem histórico em CV entrem diretamente na fase de análise de dados.
Demonstrações Educacionais
Demanda típica: Demonstrar "o que é segmentação semântica" em cursos de planejamento urbano ou visão computacional.
A forma tradicional exige rodar modelos ao vivo em sala de aula, com alta probabilidade de falhas na configuração do ambiente; o GPT-image-2 permite demonstrações diretamente no navegador do ChatGPT, com taxa de falha zero e alta explicabilidade, permitindo ainda que os alunos façam perguntas em linguagem natural.
💡 Dica para começar: Para usuários que estão começando com a segmentação semântica de paisagens urbanas no GPT-image-2, recomendamos começar com o "teste de imagem única + modo padrão" para se familiarizar com os limites da ferramenta antes de decidir expandir para cenários em lote. Sugerimos testar gratuitamente de 5 a 10 imagens através da plataforma APIYI (apiyi.com) para ter uma noção intuitiva dos resultados antes de definir sua estratégia.
Guia de início rápido: Segmentação semântica de paisagens urbanas com GPT-image-2
Se você quer testar agora mesmo, aqui está o caminho mínimo viável — resolvido em 3 passos.
Passo 1: Preparar as imagens da paisagem urbana
Recomendamos que, para o primeiro teste, você escolha imagens de paisagens urbanas diurnas, nítidas e com resolução acima de 1024×768, para que o modelo tenha informações suficientes para fazer julgamentos precisos. As imagens podem vir de:
- Fotos tiradas no local (a câmera do celular é suficiente)
- Exportações de plataformas de mapas (capturas de tela do Google Street View / Baidu Street View / Tencent Street View)
- Conjuntos de dados públicos (Cityscapes test set, Mapillary Vistas)
Passo 2: Escolher o método de invocação
| Método de invocação | Público-alvo | Vantagens |
|---|---|---|
| Versão Web do ChatGPT Plus | Não desenvolvedores, pesquisadores | Sem código, visualização excelente |
| OpenAI API | Desenvolvedores, processamento em lote | Programável, integrável |
| APIYI serviço proxy de API | Desenvolvedores brasileiros/locais | Conexão direta, campos consistentes |
Passo 3: Enviar o comando
Você pode reutilizar diretamente os modelos de comando dos 4 cenários deste artigo:
Cenário 1: Faça a segmentação semântica desta imagem de paisagem urbana e indique a legenda.
Cenário 2: Forneça os dados de proporção de cada legenda e calcule o índice de visibilidade verde.
Cenário 3: Faça a segmentação semântica de veículos e pessoas no local; azul representa veículos, verde representa pessoas.
Cenário 4: Com base na legenda da imagem anterior, faça a segmentação semântica da segunda imagem.
Exemplo de código para invocação da API
Se você optar pela via da API, aqui está um exemplo mínimo de invocação:
from openai import OpenAI
import base64
client = OpenAI(
api_key="sua-chave-apiyi",
base_url="https://api.apiyi.com/v1"
)
with open("street_view.jpg", "rb") as f:
image_b64 = base64.b64encode(f.read()).decode()
response = client.chat.completions.create(
model="gpt-image-2",
messages=[{
"role": "user",
"content": [
{"type": "text",
"text": "Faça a segmentação semântica desta imagem de paisagem urbana, forneça a proporção de cada categoria e calcule o índice de visibilidade verde."},
{"type": "image_url",
"image_url": {"url": f"data:image/jpeg;base64,{image_b64}"}}
]
}],
reasoning_effort="high" # Modo de raciocínio
)
print(response.choices[0].message.content)
🚀 Lembrete de integração da API: Ao invocar o gpt-image-2 através da APIYI (apiyi.com), defina a
base_urlcomohttps://api.apiyi.com/v1. Os outros campos são exatamente iguais aos da OpenAI oficial; basta alterar uma linha debase_urlno seu código SDK da OpenAI existente para começar a rodar.
Perguntas Frequentes (FAQ) sobre a Segmentação Semântica de Paisagens Urbanas com GPT-image-2
Pergunta 1: A precisão da segmentação de paisagens urbanas do GPT-image-2 é realmente suficiente?
O nível de suficiência depende do seu caso de uso. Para cenários como relatórios acadêmicos, avaliações de planejamento e demonstrações educacionais, a precisão do modo de raciocínio (erro de ±2%) é totalmente suficiente. Para cenários de medição industrial de alta precisão (onde o erro exigido é <1%), ainda recomendamos o uso de modelos tradicionais combinados com inspeção manual.
Pergunta 2: Quantas categorias de paisagens urbanas o GPT-image-2 consegue identificar?
Teoricamente, não há um limite rígido para o número de categorias — a classificação depende de como você as define no comando. No entanto, testes práticos mostram que, ao exceder 15 categorias em uma única imagem, podem ocorrer problemas de cores semelhantes e confusão na legenda. Recomendamos limitar a tarefa a 8-12 categorias por vez.
Pergunta 3: A segmentação de paisagens urbanas do GPT-image-2 suporta vídeo?
A versão atual não suporta fluxo de vídeo diretamente. Se você tiver necessidades de análise de vídeo, precisará extrair quadros (por exemplo, 1 quadro por segundo), realizar a invocação do modelo quadro a quadro e, em seguida, remontar os resultados em um vídeo — esse fluxo de trabalho é demorado e custoso, por isso não é recomendado.
Pergunta 4: O modo de raciocínio leva 10 minutos, é possível acelerar?
O tempo de processamento do modo de raciocínio vem principalmente do processo de autorrevisão do modelo. Aqui estão algumas formas de acelerar:
- Reduzir a resolução: Comprima a imagem enviada para até 1024×768.
- Simplificar a tarefa: Divida a segmentação e o cálculo de proporção em dois comandos, perguntando apenas uma coisa por vez.
- Mudar para o modo padrão: A precisão cai de 1-2%, mas o tempo de processamento é reduzido para 1/5.
Pergunta 5: Quem é melhor na segmentação de paisagens urbanas: GPT-image-2 ou Nano Banana Pro?
Ambos têm posicionamentos ligeiramente diferentes. O GPT-image-2 é mais forte em capacidade de raciocínio e precisão numérica (raciocínio em várias etapas, cálculo automático de GVI); o Nano Banana Pro é superior em velocidade e custo (resposta em segundos por imagem). Se sua necessidade é segmentação rápida em grande escala, considere o Nano Banana Pro; se precisa de relatórios de análise automatizados, escolha o GPT-image-2.
Pergunta 6: Existe diferença ao utilizar o serviço via APIYI apiyi.com em comparação ao oficial?
Os campos são exatamente os mesmos — a APIYI é um canal de proxy oficial, e os campos de solicitação/resposta são 100% sincronizados com a OpenAI. A diferença principal reside em: conexão direta sem necessidade de proxy no país, suporte técnico especializado em chinês e faturamento transparente. Recomendamos que desenvolvedores locais acessem o gpt-image-2 via APIYI apiyi.com para evitar problemas de estabilidade de rede.
Pergunta 7: É possível fazer com que o GPT-image-2 gere uma máscara PNG padrão?
A versão atual não suporta a saída direta de arquivos de máscara com precisão de nível de pixel. O modelo gera uma "imagem colorida renderizada". Se você precisar de uma máscara para treinar modelos downstream, será necessário realizar um pós-processamento de separação por limiar de cor.
Pergunta 8: A saída da segmentação de paisagens urbanas do GPT-image-2 pode ser editada posteriormente?
Sim, você pode continuar fazendo perguntas com base na saída inicial. Por exemplo: "Aplique uma máscara vermelha semitransparente em todas as áreas de vegetação na imagem original para fins de alerta". O modelo fará o processamento derivado com base no resultado da segmentação anterior. Essa é uma capacidade que os modelos tradicionais não possuem.
Principais conclusões sobre a segmentação de paisagens urbanas com GPT-image-2
- Paradigma diferente: O GPT-image-2 não pretende substituir o DeepLabV3+, mas abrir um novo caminho "orientado por linguagem natural, sem necessidade de implantação e com análise derivável".
- Precisão utilizável: No modo de raciocínio, o erro em relação aos modelos SOTA tradicionais é de apenas ±2%, o que é suficiente para a grande maioria dos cenários de negócios.
- O tempo de processamento é o ponto fraco: Resposta em nível de minutos por imagem, totalmente inadequado para cenários em tempo real ou de grande volume.
- Flexibilidade de categorias é o diferencial: Enquanto modelos tradicionais ficam presos às "19 categorias do Cityscapes", o GPT-image-2 supera isso com um simples comando.
- Automação da taxa de visão verde (GVI): O cálculo do GVI, que antes levava "1 dia de colaboração entre engenheiros e planejadores", é reduzido para "5 minutos de trabalho independente do planejador".
- Solução híbrida é a ideal: Use o GPT-image-2 para análises exploratórias e modelos tradicionais para produção industrial em larga escala; ambos são complementares.
- Recomendação de uso local: Utilize via APIYI apiyi.com para uma conexão estável e direta, com campos 100% compatíveis com a versão oficial.
Resumo
A segmentação semântica de paisagens urbanas via GPT-image-2 não é uma substituta da segmentação semântica tradicional, mas sim um complemento. Ela resolve demandas de "pequenos lotes, personalização, necessidade de interação em linguagem natural e geração automática de conclusões analíticas", necessidades que modelos como DeepLabV3+ ou PSPNet ignoravam completamente no passado.
Desde o cálculo automático da taxa de visibilidade verde até a segmentação de categorias personalizadas, o GPT-image-2 democratiza tarefas que antes exigiam "engenheiros de algoritmos + GPU + dados de treinamento", colocando-as nas mãos de qualquer pessoa que saiba usar o ChatGPT. Isso representa uma mudança de paradigma para áreas como planejamento urbano, design de paisagismo e pesquisa acadêmica.
No entanto, lembre-se de suas limitações: tempo de processamento de minutos por imagem, custos de processamento em lote difíceis de controlar e precisão em nível de pixel inferior ao estado da arte (SOTA). Esses três pontos determinam que ele não substituirá os modelos tradicionais, mas coexistirá com eles.
Se você pretende integrar o GPT-image-2 ao seu fluxo de trabalho, sugerimos começar com um cenário "pequeno e eficiente" (como a análise da taxa de visibilidade verde de 50 fotos de paisagens urbanas). Após validar o fluxo de ponta a ponta, decida se vale a pena escalar para volumes maiores.
✨ Dica final: Para desenvolvedores e pesquisadores brasileiros, recomendamos acessar o gpt-image-2 através da plataforma APIYI (apiyi.com). Você terá chamadas estáveis, campos totalmente compatíveis com a API oficial e cobrança transparente por token. Para explorações iniciais, a plataforma oferece créditos gratuitos para que você realize sua prova de conceito (PoC), o suficiente para concluir todos os testes dos 4 cenários apresentados neste artigo.
Autor: Equipe APIYI
Última atualização: 02/05/2026