title: "Análise do Grok 4.20: A revolução da arquitetura multi-agente e o fim das alucinações?"
description: "O Grok 4.20 chegou com uma abordagem inovadora de multi-agentes para reduzir alucinações. Confira a análise técnica da arquitetura, benchmarks e como testar."
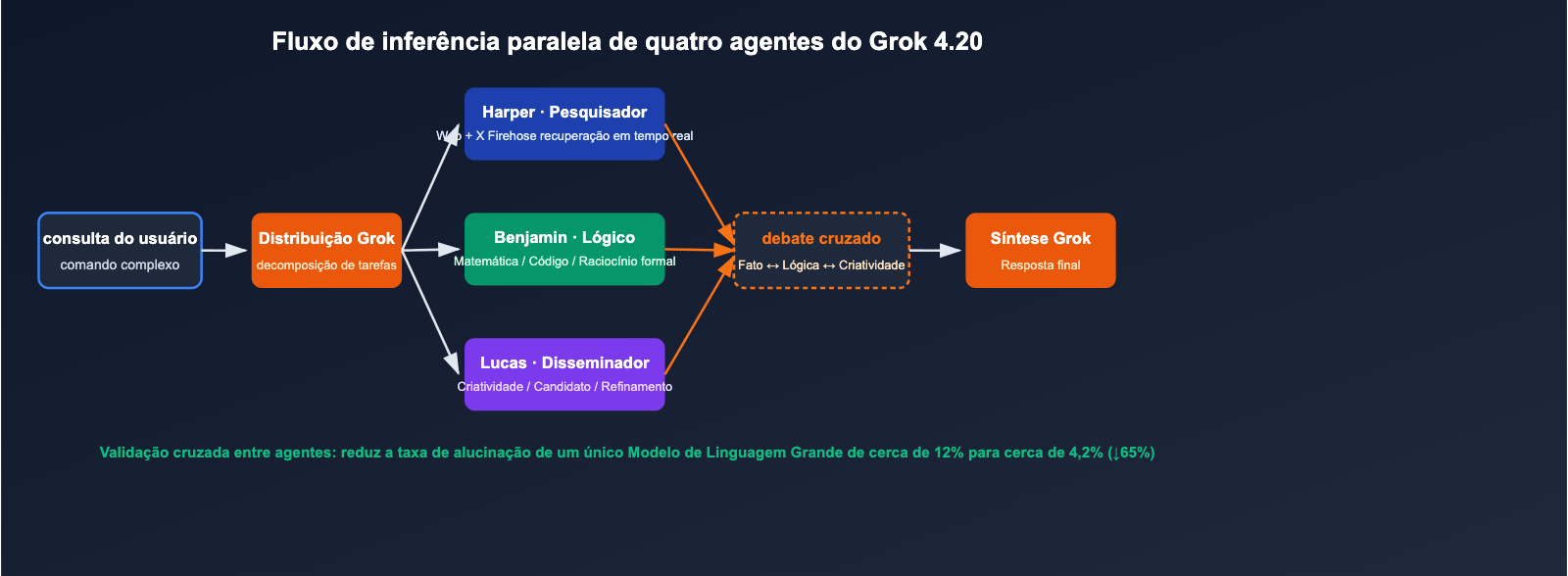
Em 17 de fevereiro de 2026, a xAI lançou oficialmente o Grok 4.20 Beta. O modelo adota uma abordagem nada convencional para superar o ranking de "taxa de não alucinação", um domínio até então dominado pelas séries Claude e GPT: em vez de simplesmente aumentar os parâmetros ou os passos de inferência, o Grok coloca 4 agentes especializados (Grok / Harper / Benjamin / Lucas) para trabalhar em paralelo em cada consulta complexa, debatendo entre si e sintetizando a resposta final. A avaliação independente da Artificial Analysis Omniscience aponta uma taxa de não alucinação de 78%, enquanto a xAI afirma que, em testes abrangentes, pode chegar a 83%, superando o Claude Opus 4.6 e o GPT-5.4 em avaliações públicas. Além disso, o Grok 4.20 expandiu a janela de contexto para 2M de tokens, ganhando uma vantagem significativa em documentos ultralongos e tarefas de agentes de ciclo longo.
O suporte computacional por trás disso também está sendo atualizado: o cluster de supercomputação Colossus 2 da xAI está sendo expandido gradualmente para o nível de 1,5 GW, preparando o terreno para o Grok 5 e a futura escalabilidade multi-agente. Este artigo, baseado em fontes primárias em inglês, sistematiza a arquitetura, os benchmarks, o modo "Heavy", a disponibilidade da API e os cenários de aplicação do Grok 4.20, ajudando você a decidir em 10 minutos se vale a pena migrar.

O avanço central da arquitetura multi-agente do Grok 4.20
Comparado à abordagem convencional de "um modelo maior + cadeia de raciocínio mais profunda", o Grok 4.20 escolheu o caminho da inteligência coletiva (Raciocínio estilo Swarm).
Divisão de tarefas dos 4 agentes
| Papel | Nome | Responsabilidade | Capacidade Chave |
|---|---|---|---|
| Coordenador | Grok | Decomposição de tarefas, arbitragem de debate, síntese final | Orquestração / Árbitro |
| Pesquisador | Harper | Busca Web em tempo real + recuperação de dados do X Firehose | Completude de fatos, verificação de tempo |
| Lógico | Benjamin | Matemática, código, raciocínio estruturado e verificação | Verificação de execução de código, raciocínio formal |
| Disseminador | Lucas | Saída criativa, expansão de soluções, polimento de linguagem | Geração de múltiplas candidatas, otimização de respostas |
Sempre que uma consulta complexa entra no modelo, Harper busca o contexto em tempo real, Benjamin realiza o raciocínio lógico e de código simultaneamente, Lucas gera múltiplos conjuntos de respostas candidatas e, finalmente, o Grok coordena o debate e sintetiza o rascunho final. Esse mecanismo eleva a "inferência direta de um modelo" para "negociações internas de múltiplas rodadas entre quatro papéis especializados".
Por que ele reduz alucinações?
As alucinações dos LLMs tradicionais vêm principalmente da falta de autoverificação do modelo sobre "coisas que ele não sabe". O Grok 4.20 forma um mecanismo natural de verificação de fatos através da validação cruzada entre agentes:
- Harper descobre que a inferência de Benjamin contradiz os dados mais recentes da web/X → Rejeita;
- Benjamin descobre que a matemática da solução criativa de Lucas não se sustenta → Veta;
- O Grok, como coordenador, só produz conclusões que não possuem objeções das três partes.
Divulgação oficial: esse mecanismo reduziu a taxa de alucinação de modelo único, que era de cerca de 12%, para aproximadamente 4,2%, o que equivale a uma queda de 65% nas alucinações.
🎯 Dica de compreensão da arquitetura: O multi-agente não é "4 vezes a concatenação de um único modelo", mas sim 4 caminhos paralelos + debate em uma única inferência. Equipes que desejam experimentar rapidamente as diferenças podem usar o serviço proxy de API APIYI (apiyi.com) para invocar o Grok 4.20 diretamente, rodando o mesmo conjunto de comandos (prompt) lado a lado com outros modelos para comparar a diferença na taxa de alucinação.
Métricas-chave e comparação de mercado do Grok 4.20
O valor dos benchmarks depende muito do conjunto de dados utilizado. Abaixo, separamos os resultados autorrelatados dos testes independentes.
Visão geral dos benchmarks públicos
| Métrica | Grok 4.20 | Claude Opus 4.6 | GPT-5.4 |
|---|---|---|---|
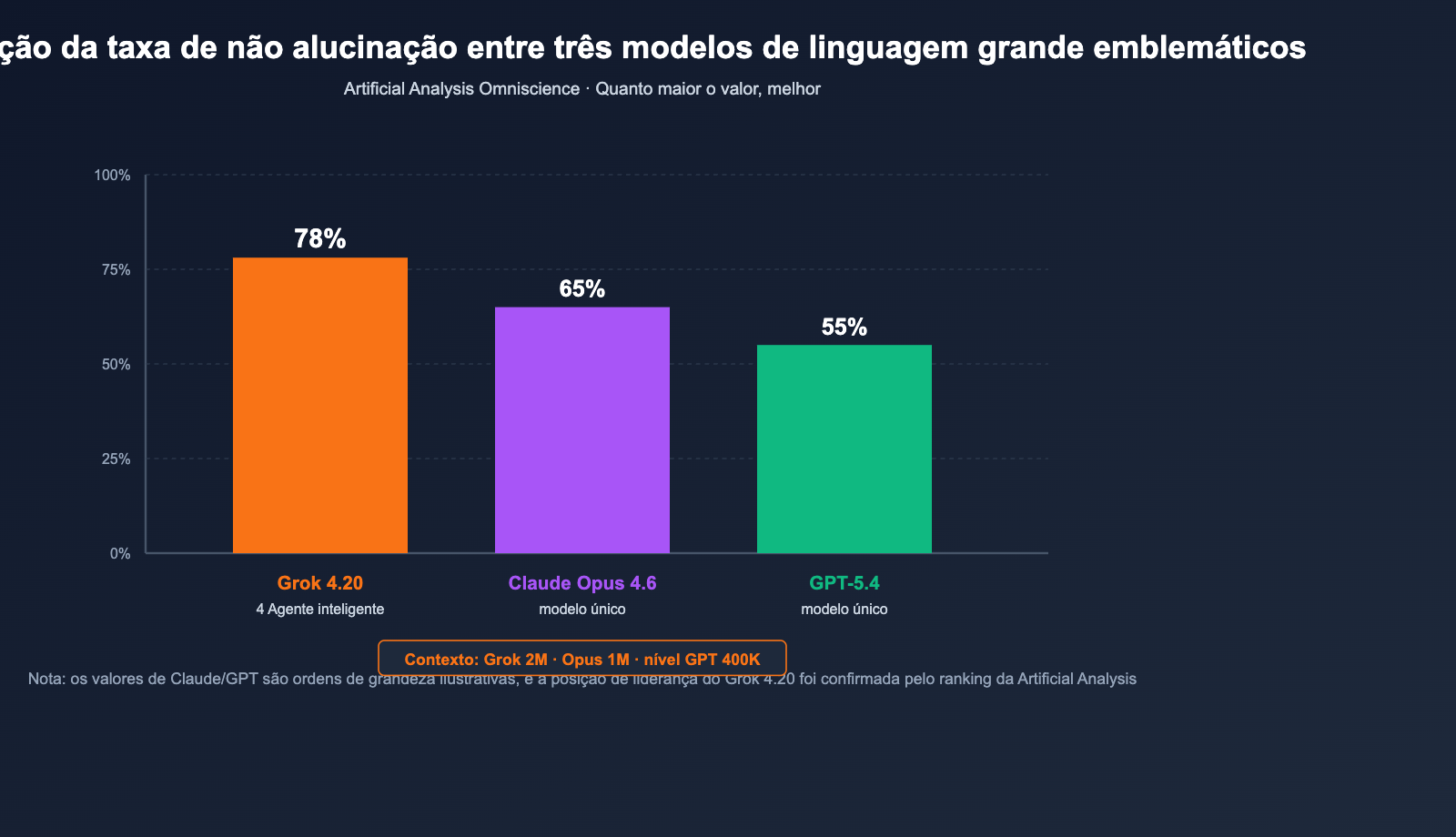
| Artificial Analysis Omniscience (taxa de não alucinação) | 78% (Líder) | 2º lugar | 3º lugar |
| Taxa de não alucinação (autoavaliação xAI) | ~ 83% | — | — |
| Taxa de alucinação (relativa à base Grok 4.1) | 4,22% (↓65%) | — | — |
| LMArena Thinking Elo | 1483 | — | — |
| Janela de contexto | 2.000.000 tokens | 200K (expansível para 1M) | Nível 400K |
| Arquitetura | 4 agentes em paralelo (Modo Heavy 16) | Modelo único | Modelo único |
Modo Heavy: expansão de 4 para 16 agentes
Além da configuração padrão de 4 agentes, o Grok 4.20 oferece o Modo Heavy: quando é necessária uma maior profundidade de raciocínio, o número de agentes aumenta de 4 para 16, cobrindo um espaço de debate mais amplo e uma validação cruzada de cadeias de evidências de maior dimensão. O custo é um aumento na latência e no custo por solicitação, sendo ideal para cenários onde a precisão é crítica e o custo não é o fator principal (pesquisa de investimento, auditoria de conformidade, análise de segurança, etc.).
Guia rápido de modos e cenários
| Modo | Nº de agentes | Cenários aplicáveis | Características |
|---|---|---|---|
| Grok 4.20 Modo não-raciocínio | 1 | Chat, perguntas e respostas | Baixa latência, baixo custo |
| Grok 4.20 Modo raciocínio | 1 + CoT | Matemática, código | Custo moderado |
| Grok 4.20 Multiagente (padrão) | 4 | Consultas complexas, verificação de fatos | Queda significativa de alucinações |
| Grok 4.20 Heavy | 16 | Pesquisa profissional, auditoria de conformidade | Maior precisão |
🎯 Dica de leitura de benchmarks: Pode haver uma diferença de 5 a 10 pontos percentuais entre a autoavaliação de um modelo e testes de terceiros. Ao selecionar um modelo, priorize referências independentes como o Artificial Analysis. Ao comparar o Grok 4.20 / Opus 4.6 / GPT-5.4 com o mesmo comando através da APIYI (apiyi.com), você terá uma visão mais realista do desempenho no seu contexto de negócio.
A janela de contexto de 2M e a base de computação Colossus 2 do Grok 4.20
A inovação arquitetural exige suporte de hardware; estes dois upgrades fundamentais do Grok 4.20 merecem atenção.
O valor da janela de contexto de 2M tokens
O Grok 4.20 elevou a janela de contexto para 2.000.000 de tokens, o que significa que:
- Documentos do tamanho de livros inteiros podem ser inseridos no comando de uma só vez, sem necessidade de divisão manual;
- Conversas longas / sessões de agentes longas podem manter o histórico completo;
- Revisão de código em múltiplos arquivos pode cobrir monorepos de tamanho médio;
- A sobreposição com a capacidade de busca em tempo real do Harper cria uma vantagem combinada de "memória longa + fatos em tempo real".
Upgrade do cluster de supercomputação Colossus 2 para 1.5GW
O cluster de supercomputação Colossus 2, criado pela xAI para a série Grok, está sendo atualizado para uma escala de computação de nível 1.5GW. Este objetivo de infraestrutura mira o Grok 5 e grupos de multiagentes em maior escala. O impacto direto para os desenvolvedores:
- Maior disponibilidade de inferência e limites de concorrência;
- Velocidade de iteração de novas versões de modelos mais rápida;
- O Grok 4.20 já consegue suportar o modo Heavy de "16 agentes × 2M de contexto", cuja base de computação provém deste cluster.

Guia Rápido: Invocação da API Grok 4.20 e Integração com APIYI
Exemplo de invocação básica (compatível com OpenAI)
from openai import OpenAI
client = OpenAI(
base_url="https://api.apiyi.com/v1",
api_key="SUA_CHAVE_API",
)
# Modo multiagente padrão com 4 agentes
resp = client.chat.completions.create(
model="grok-4-20",
messages=[
{"role": "system", "content": "Você é um assistente de pesquisa factual."},
{"role": "user", "content": "Resuma os dados de remessas globais de chips de IA no Q1 de 2026 e liste as fontes principais."},
],
temperature=0.3,
max_tokens=4096,
)
print(resp.choices[0].message.content)
Invocação no modo Heavy (16 agentes)
# O modo Heavy é ideal para cenários que exigem alta precisão, com maior latência e custo
resp = client.chat.completions.create(
model="grok-4-20-heavy",
messages=[
{"role": "user", "content": "Faça um resumo dos pontos de risco e verificação de referência cruzada deste documento de conformidade de 800 páginas."},
],
max_tokens=16384,
)
📎 Clique para ver o exemplo de invocação com janela de contexto de 2M
# A janela de contexto de 2M permite processar um livro inteiro ou um repositório completo de uma só vez
with open("large_repo_dump.txt", "r") as f:
repo_text = f.read() # Pode chegar a milhões de tokens
resp = client.chat.completions.create(
model="grok-4-20",
messages=[
{"role": "system", "content": "Você é um revisor de código sênior."},
{"role": "user", "content": f"Aqui está o código de todo o repositório, por favor, encontre os 5 problemas mais graves:\n\n{repo_text}"},
],
max_tokens=8192,
)
Vantagens da integração com a plataforma APIYI
A API do Grok 4.20 já está disponível oficialmente na APIYI apiyi.com, com preços equivalentes aos do site oficial e os seguintes diferenciais:
- Descontos de até 15% em recargas, tornando o custo de uso a longo prazo menor do que a conexão direta;
- Sem limite de concorrência, ideal para execução de tarefas em lote no modo Heavy;
- Interface compatível com OpenAI, sem necessidade de modificar o código existente, bastando substituir os campos
base_urlemodel; - Faturamento unificado com outros modelos como Claude/GPT, facilitando testes A/B entre modelos.
🎯 Dica de integração: O consumo de tokens por chamada no modo Heavy é várias vezes maior que no modo comum; a vantagem da ausência de limite de concorrência é mais evidente neste cenário. Recomendamos que novas equipes testem a lógica básica no APIYI apiyi.com usando o modo sem inferência antes de migrar os fluxos críticos para o modo multiagente ou Heavy.
Cenários de aplicação típicos do Grok 4.20
As 5 principais cargas de trabalho para o Grok 4.20
| Cenário | Modo recomendado | Benefício principal |
|---|---|---|
| Verificação de fatos em notícias/relatórios | Multiagente (padrão) | Busca em tempo real Harper + verificação cruzada entre agentes |
| Pesquisa de investimento e conformidade | Heavy | 16 agentes reduzem a taxa de erro em fatos críticos |
| Análise de documentos longos (livros/repositórios) | Multiagente + 2M | Processamento completo sem necessidade de fragmentação |
| Fluxos de trabalho de agentes de várias etapas | Multiagente | Coordenador integrado, reduzindo a engenharia externa |
| Monitoramento de opinião pública/redes sociais | Multiagente | Integração nativa com o X Firehose via Harper |
Cenários não recomendados
- Autocompletar de IDE em milissegundos: A latência causada pelo paralelismo multiagente não é adequada para interações de nível "Tab";
- Processamento em lote de custo extremamente baixo: O preço do modo Heavy é alto; prefira o modo sem inferência ou modelos de nível Haiku;
- Necessidade de implantação local rigorosa: O Grok 4.20 é fornecido atualmente via API, sem pesos para auto-hospedagem.
🎯 Sugestão de migração: Priorize a migração de fluxos "sensíveis a alucinações" (conformidade, medicina, pesquisa financeira, etc.) para o modo multiagente do Grok 4.20. Utilize o painel de faturamento da APIYI apiyi.com para estatísticas detalhadas por fluxo e quantifique o ganho de negócio gerado pela redução de alucinações.
Perguntas Frequentes (FAQ)
Q1: Entre 78% e 83% de taxa de não alucinação, qual é mais confiável?
78% provém do conjunto de testes independente de terceiros da Artificial Analysis Omniscience, sendo atualmente o dado mais credível; 83% é o resultado de autoteste da xAI em um conjunto de testes mais amplo. A recomendação de seleção é priorizar benchmarks independentes e usar dados oficiais como referência secundária. A conclusão consistente de ambos é: o Grok 4.20 superou o Claude Opus 4.6 e o GPT-5.4 na dimensão de não alucinação.
Q2: Quatro agentes significam que preciso fazer 4 invocações do modelo via API?
Não. O agendamento multiagente é realizado internamente no servidor da xAI, expondo apenas uma única invocação do modelo ao usuário. A cobrança de tokens será maior do que no modo de agente único, mas muito menor do que a solução de "encadear 4 requisições no cliente por conta própria", além de oferecer uma latência menor.
Q3: Qual a diferença entre o modo Heavy e o multiagente comum?
O modo Heavy expande os agentes paralelos de 4 para 16, aumentando ainda mais a taxa de precisão em tarefas de raciocínio complexo e cadeias de evidências longas, ao custo de um aumento significativo no custo por requisição e na latência. Recomendamos habilitá-lo apenas em cenários onde "cada erro custa muito caro", como conformidade, medicina e pesquisa de investimentos. Ao rotear para diferentes modos via APIYI (apiyi.com) por requisição, você consegue "usar poder computacional de acordo com o valor".
Q4: É possível realmente utilizar os 2M da janela de contexto?
Sim. O Grok 4.20 declara o contexto efetivamente utilizável, não apenas o limite teórico. No entanto, observe: quanto maior o contexto, o custo por token e a latência aumentam linearmente; para contextos super grandes, recomendamos combinar compressão de contexto + recuperação Harper multiagente.
Q5: Qual a diferença entre o serviço da APIYI e o site oficial?
O preço é o mesmo do site oficial, com promoções de recarga que podem chegar a 15% de desconto. A principal vantagem é a ausência de limites de concorrência, ideal para chamadas em lote no modo Heavy. A interface mantém a compatibilidade com o schema da OpenAI; no código, basta apontar a base_url para apiyi.com.
Q6: O Grok 4.20 substituirá o Grok 5?
Não. O Grok 5 continua sendo o principal objetivo da próxima geração da xAI, suportado pelo cluster Colossus 2 de 1.5GW. O posicionamento do Grok 4.20 é mais como "validar o paradigma multiagente na arquitetura de 4ª geração", fornecendo validação de engenharia para o multiagente em escala do Grok 5.
Resumo: O paradigma multiagente começa a mudar o cenário dos modelos de ponta
O Grok 4.20 não traz apenas uma atualização de versão, mas uma mudança na dimensão da concorrência entre modelos de ponta: de "modelos únicos maiores com cadeias de raciocínio mais profundas" para "raciocínio de grupo com múltiplos papéis + verificação de evidências em tempo real". A combinação de 78% de taxa de não alucinação independente com 2M de janela de contexto significa que, pela primeira vez, negócios de alto risco (conformidade, pesquisa de investimentos, medicina, direito) possuem uma solução de "baixa alucinação" disponível via API geral.
Para os desenvolvedores, o primeiro passo não é substituir todos os modelos, mas migrar prioritariamente os fluxos onde o erro é mais crítico para o modo multiagente do Grok 4.20, mantendo os fluxos convencionais em modelos de menor custo, criando uma orquestração híbrida. Na tendência da indústria, o Grok 5 e o cluster de 1.5GW do Colossus 2 continuarão a ampliar essa vantagem; integrar-se cedo significa acumular experiência em invocações multiagente mais rapidamente.
🎯 Sugestão de ação: A API do Grok 4.20 já está disponível na APIYI (apiyi.com), com preços iguais aos do site oficial e 15% de desconto em recargas. O ponto principal é a ausência de limites de concorrência, sendo ideal para multiagentes, modo Heavy e grandes demandas de processamento com 2M de janela de contexto. Basta usar um código compatível com OpenAI para integrar; migre hoje mesmo os fluxos onde você "mais teme alucinações".
— Equipe APIYI (Equipe técnica da APIYI apiyi.com)