No início de abril de 2026, um misterioso modelo de vídeo de IA chamado HappyHorse apareceu silenciosamente no ranking de testes cegos da Artificial Analysis Video Arena. As versões V1 e V2 atualizaram quase simultaneamente as pontuações Elo nas categorias de texto para vídeo (Text-to-Video) e imagem para vídeo (Image-to-Video), deixando para trás nomes de peso como Seedance 2.0, Kling 3.0 e PixVerse V6. No entanto, apenas alguns dias depois, o HappyHorse 1.0 desapareceu repentinamente do ranking, deixando para trás apenas algumas capturas de tela e uma página oficial vaga.
As especulações em torno do modelo HappyHorse explodiram na comunidade de IA de língua inglesa: seria ele um disfarce para o Wan 2.7? Seria a próxima geração experimental da equipe Seedance da ByteDance? Ou seria um laboratório asiático desconhecido que revelou seu potencial de repente? Este artigo, baseado em dados publicamente verificáveis, faz uma análise completa da arquitetura, desempenho, status de código aberto e possível origem do HappyHorse 1.0, ajudando você a decidir se este "azarão" merece ser incluído em sua pilha de ferramentas de geração de vídeos.

Visão geral das informações principais do modelo HappyHorse
Antes de dissecar os detalhes técnicos, vamos condensar as informações conhecidas em uma tabela para facilitar a compreensão rápida.
| Dimensão | Informações conhecidas do HappyHorse 1.0 |
|---|---|
| Tipo de modelo | Modelo de geração de vídeo por texto+imagem (geração conjunta de imagem e áudio) |
| Arquitetura | Transformer de fluxo único (Single-stream) de 40 camadas, sem Cross-Attention |
| Passos de inferência | Apenas 8 passos de remoção de ruído, sem necessidade de CFG (Classifier-Free Guidance) |
| Suporte a idiomas | Chinês, inglês, japonês, coreano, alemão, francês |
| Lançamento | Modelo base / Modelo destilado / Modelo de super-resolução / Código de inferência (oficialmente declarado como código aberto) |
| Local de aparição | Artificial Analysis Video Arena (alguns materiais também mencionam a categoria de vídeo do LMArena) |
| Status atual | V1/V2 removidos do ranking público, site oficial ainda online, mas GitHub/Model Hub marcado como "Em breve" |
| Origem suspeita | Equipe asiática, a comunidade especula relação com o ecossistema Wan 2.7 / Seedance, mas não confirmado oficialmente |
🎯 Dica para testes rápidos: Como os pesos oficiais do modelo HappyHorse ainda não foram disponibilizados em plataformas de inferência convencionais, se você deseja comparar modelos de vídeo do mesmo nível (como Seedance 2.0, Kling 3.0, Veo 3.1) em ambiente de produção, recomendamos usar primeiro uma plataforma de serviço proxy de API como a APIYI (apiyi.com) para invocar vários modelos de vídeo em paralelo. Assim, você poderá migrar perfeitamente assim que o HappyHorse for lançado oficialmente, evitando retrabalho de engenharia.
A linha do tempo do surgimento do modelo HappyHorse
Para entender por que esse "cavalo feliz" abalou a comunidade global de IA, precisamos analisar a linha do tempo dos acontecimentos.
O Ano do Cavalo e a coincidência do nome
2026 é o Ano do Cavalo no calendário chinês. Desde o Festival da Primavera em fevereiro, veículos de mídia internacionais e colunas como a UX Tigers mencionaram repetidamente que o ecossistema de IA chinês estava preparando uma série de lançamentos focados no tema "cavalo". O nome "HappyHorse" não apenas faz referência ao zodíaco, mas também cria uma associação com outro modelo que surgiu na mesma época, apelidado de "The Horse". Essa foi uma das principais pistas que levaram a comunidade a identificar, desde o início, que o projeto vinha de uma equipe asiática.
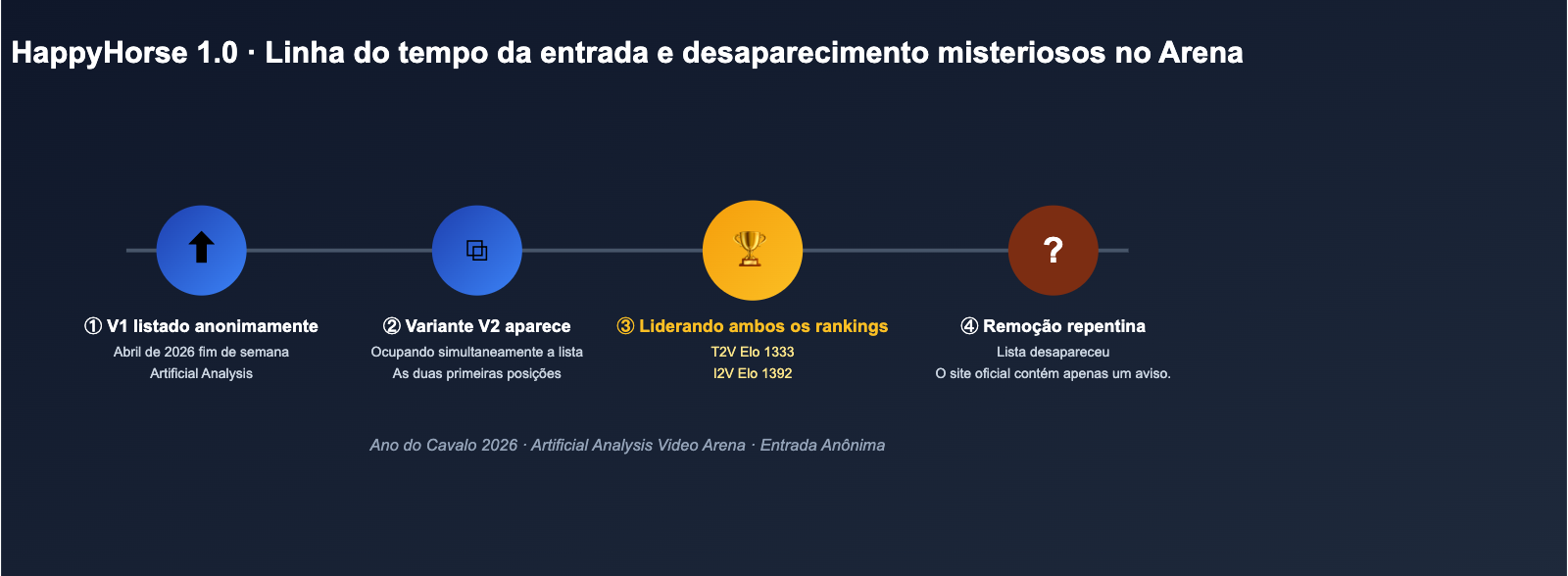
A explosão e o desaparecimento na Arena
De acordo com capturas de tela e relatos publicados no início de abril por especialistas em avaliação de vídeo por IA, como Brent Lynch no X (antigo Twitter), o ritmo de lançamento do HappyHorse 1.0 foi aproximadamente o seguinte:
- Primeira aparição: A versão V1 surgiu como uma entrada anônima na Artificial Analysis Video Arena e, em poucas horas, alcançou o top 3 em testes cegos de texto para vídeo;
- Lançamento da versão V2: Quase simultaneamente, surgiu uma variante V2, com ambas as versões ocupando, por um tempo, o primeiro e o segundo lugares no ranking de imagem para vídeo;
- Topo do ranking: Na categoria sem áudio, o HappyHorse 1.0 superou modelos de ponta como Seedance 2.0 720p, Kling 3.0 e PixVerse V6;
- Desaparecimento: Em poucos dias, as versões V1/V2 foram removidas simultaneamente do ranking público, restando apenas capturas de tela e registros de terceiros. Posteriormente, a página oficial publicou um aviso de que o "modelo base seria disponibilizado como código aberto em breve".
Esse padrão de "aparecer do nada → dominar o ranking → sair silenciosamente" geralmente significa duas coisas: ou um laboratório está realizando testes A/B anônimos, ou a empresa por trás do modelo ainda está preparando o lançamento oficial e retirou o acesso após o tráfego inesperado. Ambas as explicações elevaram o nível de mistério em torno do modelo HappyHorse.
Análise da arquitetura do modelo HappyHorse: como o Transformer de fluxo único de 40 camadas domina o ranking
Embora o artigo oficial ainda não tenha sido publicado, podemos deduzir as principais escolhas de design do HappyHorse 1.0 através das descrições no happyhorse-ai.com e no site espelho happy-horse.net.
Self-Attention de fluxo único substituindo estruturas complexas
Os modelos de geração de vídeo tradicionais (especialmente modelos multimodais que processam áudio, texto e imagem simultaneamente) geralmente adotam uma arquitetura de múltiplos fluxos (multi-stream), onde texto, vídeo e áudio possuem seus próprios codificadores e interagem via Cross-Attention. Essa estrutura é flexível, mas desperdiça muitos parâmetros e exige a movimentação constante de tensores entre os ramos durante a inferência.
O HappyHorse 1.0 simplificou tudo em uma única linha de processamento: um Transformer de Self-Attention de 40 camadas que processa tokens de texto, vídeo e áudio simultaneamente, sem qualquer Cross-Attention intermediária ou sub-redes dedicadas a uma modalidade específica. Todos os dados são codificados uniformemente em uma sequência de tokens, modelados diretamente no mesmo espaço de atenção. Esse design traz várias vantagens teóricas:
- Alta utilização de parâmetros: Não há necessidade de parâmetros redundantes para isolar modalidades;
- Caminho de inferência curto: Sem movimentação extra entre modalidades, tornando o kernel mais contínuo;
- Objetivo de treinamento unificado: Texto, imagem e áudio compartilham a mesma função de perda, facilitando a otimização de ponta a ponta;
- Suporte nativo para áudio e vídeo: Som e imagem são tokens na mesma sequência, garantindo sincronia por natureza.
Inferência extrema: 8 passos de remoção de ruído e sem CFG
Para desenvolvedores acostumados com modelos como Stable Video Diffusion, Sora e Kling, "dezenas de passos de remoção de ruído + Classifier-Free Guidance (CFG)" já virou memória muscular. A descrição oficial do HappyHorse 1.0 é bastante agressiva: apenas 8 passos de remoção de ruído e sem uso de CFG para produzir a qualidade de imagem que lidera o ranking da Arena.
Isso geralmente significa que, durante o treinamento, o modelo passou por processos como Destilação de Consistência / Fluxo Retificado / Destilação Progressiva, comprimindo a amostragem de múltiplos passos em apenas alguns passos de predição direta. Combinado com os "modelos de destilação" e "modelos de super-resolução" liberados oficialmente, toda a pilha de inferência está muito próxima dos objetivos de "amigável para dispositivos locais + alta taxa de transferência em servidor".
Escala de parâmetros e requisitos de VRAM
Como os pesos ainda não foram abertos, não é possível verificar diretamente o número de parâmetros do modelo HappyHorse. No entanto, considerando as 40 camadas, o fluxo único, o suporte a 6 idiomas e seu desempenho na Arena, é razoável supor que seu tamanho esteja na mesma ordem de grandeza de modelos públicos como Wan 2.x, Seedance 1.x e Hunyuan Video, provavelmente na faixa de 10B a 30B de parâmetros. Isso significa que, para uma implantação local real, será necessária pelo menos uma placa profissional com alta VRAM; usuários com GPUs comuns precisarão aguardar versões quantizadas em INT8/FP8.
🎯 Sugestão de escolha de arquitetura: Se você está avaliando a "próxima geração de infraestrutura de geração de vídeo" para sua equipe, recomendamos observar de perto o paradigma de "Transformer de fluxo único + inferência de poucos passos" do HappyHorse 1.0. Antes que ele seja totalmente aberto, você pode usar modelos como Seedance, Kling e Veo na APIYI (apiyi.com) para ajustar seus comandos (prompts), roteiros de câmera e fluxos de pós-processamento, estando pronto para migrar assim que os pesos do HappyHorse estiverem disponíveis.
Dados de teste do modelo HappyHorse: Como ele conquistou o topo do Arena
Depois de explicar a arquitetura, o que realmente convence as equipes de ponta são os números. A tabela abaixo resume as pontuações Elo de testes cegos do HappyHorse 1.0 no Artificial Analysis Video Arena, conforme registros públicos de terceiros, junto com a posição dos principais concorrentes.
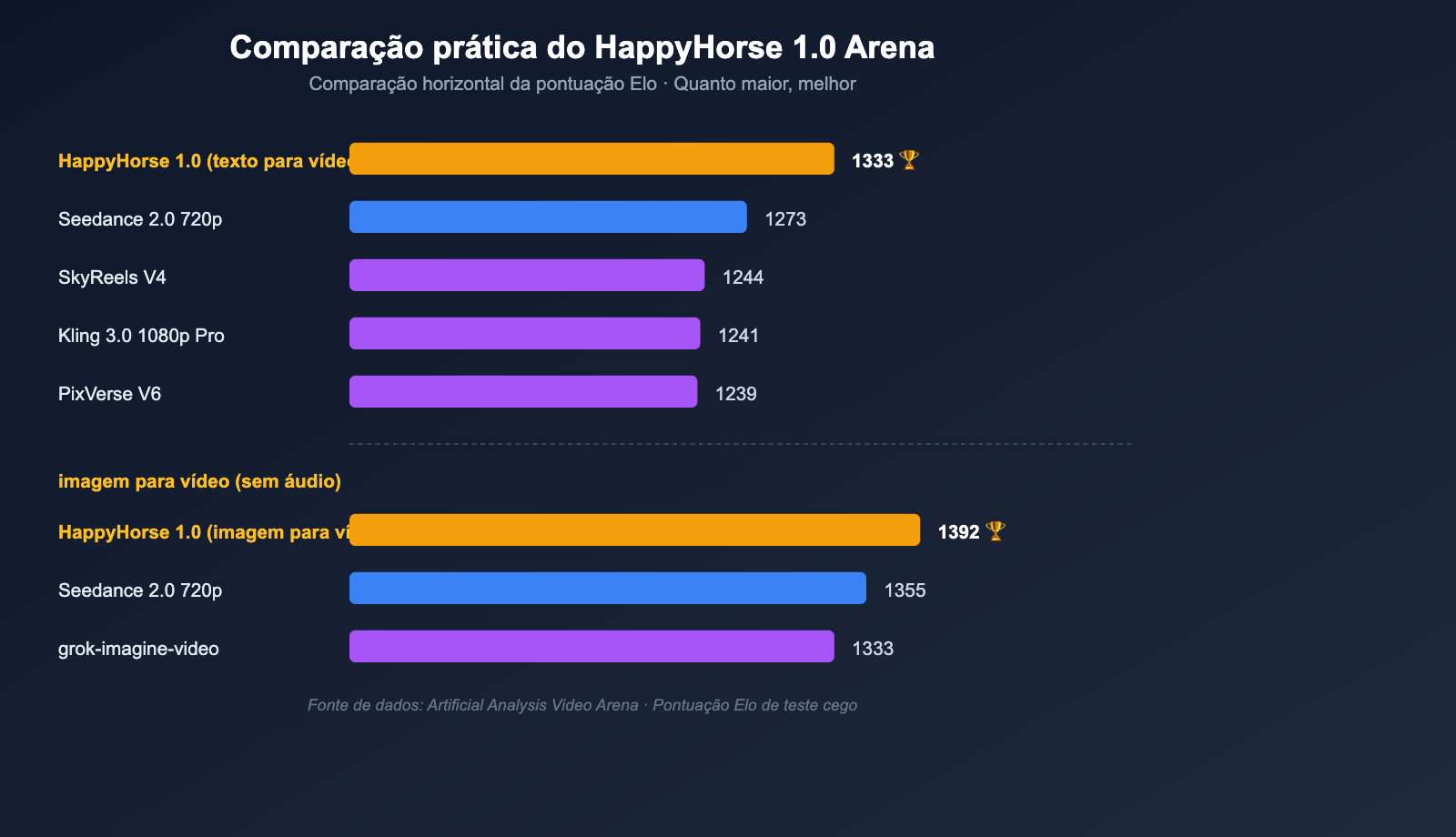
Comparação de Elo: Texto para Vídeo / Imagem para Vídeo
| Categoria | Ranking | Modelo | Pontuação Elo |
|---|---|---|---|
| Texto para vídeo (sem áudio) | 1 | HappyHorse-1.0 | 1333 |
| Texto para vídeo (sem áudio) | 2 | Dreamina Seedance 2.0 720p | 1273 |
| Texto para vídeo (sem áudio) | 3 | SkyReels V4 | 1244 |
| Texto para vídeo (sem áudio) | 4 | Kling 3.0 1080p (Pro) | 1241 |
| Texto para vídeo (sem áudio) | 5 | PixVerse V6 | 1239 |
| Texto para vídeo (com áudio) | 1 | Dreamina Seedance 2.0 720p | 1219 |
| Texto para vídeo (com áudio) | 2 | HappyHorse-1.0 | 1205 |
| Imagem para vídeo (sem áudio) | 1 | HappyHorse-1.0 | 1392 |
| Imagem para vídeo (sem áudio) | 2 | Dreamina Seedance 2.0 720p | 1355 |
| Imagem para vídeo (sem áudio) | 3 | PixVerse V6 | 1338 |
| Imagem para vídeo (sem áudio) | 4 | grok-imagine-video | 1333 |
| Imagem para vídeo (sem áudio) | 5 | Kling 3.0 Omni 1080p (Pro) | 1297 |
Algumas observações importantes:
- Maior vantagem na categoria de imagem para vídeo: 1392 vs 1355, uma diferença de quase 40 pontos no Elo, o que, em um sistema de teste cego, é um nível onde "os usuários conseguem sentir a diferença de forma consistente";
- Primeiro lugar também em texto para vídeo: 1333 vs 1273, uma liderança de 60 pontos, o que significa que, mesmo sem uma imagem de referência, o modelo HappyHorse já superou o Seedance 2.0 em habilidades básicas como composição de cena e movimento de personagens;
- Segundo lugar temporário na categoria de áudio: O Seedance 2.0 ainda lidera na sincronia audiovisual, o que está relacionado ao refinamento de engenharia que eles fizeram para a "direção de IA" em narrativas longas;
- Variante V2: A V2 apareceu brevemente em algumas capturas de tela, mas o oficial só divulgou a descrição da 1.0 até o momento; ainda não se confirmou se a V2 é a versão que "desapareceu".
Suporte multilíngue e cenários centrados no ser humano
O oficial declarou explicitamente que o HappyHorse 1.0 suporta nativamente 6 idiomas: chinês, inglês, japonês, coreano, alemão e francês, enfatizando que o modelo tem um desempenho particularmente notável em cenários "centrados no ser humano (human-centric)", incluindo:
- Performance facial detalhada (facial performance);
- Coordenação de fala natural (speech coordination);
- Movimentos corporais realistas (body motion);
- Sincronia labial precisa (lip sync).
Essa descrição posiciona claramente o modelo HappyHorse no segmento de "humanos virtuais / conteúdo digital / curtas-metragens", e não apenas em "vídeos promocionais de paisagens". Isso explica por que sua maior vantagem está na categoria de imagem para vídeo (fazer uma foto de uma pessoa ganhar vida) — que é a necessidade central para humanos digitais.
Especulações sobre a origem do modelo HappyHorse: WAN 2.7? Seedance? Ou um novo azarão?
Quando as capturas de tela do HappyHorse 1.0 começaram a circular na comunidade de IA em inglês, a discussão mais animada foi "de quem ele é". Combinando pistas da comunidade, podemos organizar as especulações na tabela abaixo.
Comparação das três principais especulações
| Origem da especulação | Argumento central | Argumento contrário |
|---|---|---|
| Disfarce do Alibaba Wan 2.7 | Lançado na mesma época que o Wan 2.7; o Alibaba Tongyi Lab é agressivo no setor de vídeo; o nome "Horse" ecoa o Ano do Cavalo | A descrição oficial do Wan 2.7 é mais voltada para imagem / modo de pensamento, o que não condiz com a arquitetura de fluxo único de 40 camadas do HappyHorse |
| Versão experimental da equipe ByteDance Seedance | O Seedance 2.0 é um competidor chinês que ocupa o topo do Arena; a ByteDance tem motivação suficiente para testes anônimos | O oficial do Seedance 2.0 ainda lidera o HappyHorse na categoria de áudio; a ByteDance não teria motivos para enviar uma "versão melhor" com outro nome |
| Laboratório não revelado / Consórcio acadêmico | O pacote "código aberto completo + modelo destilado + modelo de super-resolução" parece mais um estilo de pesquisa; nome estranho, site minimalista | A qualidade do modelo atingiu um nível comercial de ponta; é difícil para uma equipe puramente acadêmica treinar independentemente algo dessa escala |
Nós pessoalmente tendemos a acreditar que a probabilidade da terceira hipótese está aumentando: o HappyHorse 1.0 provavelmente vem de uma nova equipe que deseja se destacar da noite para o dia através de uma estratégia de código aberto, escolhendo o anonimato no Arena para construir credibilidade com dados de testes cegos antes do lançamento oficial. Essa estratégia de "subir no ranking, abrir o código e depois lançar o produto" foi validada por vários laboratórios asiáticos nos últimos 18 meses.
No entanto, isso é apenas uma especulação. Até que o repositório no GitHub e o Model Hub estejam oficialmente online, qualquer afirmação de que "ele é X" não deve ser tratada como fato. Uma atitude mais pragmática para os desenvolvedores é: foque primeiro na curva de capacidade do modelo, não no seu sobrenome.
🎯 Sugestão cautelosa: Enquanto os pesos do modelo HappyHorse não forem abertos e a origem não for confirmada oficialmente, não recomendamos apostar operações de produção diretamente nele. Você pode usar plataformas maduras como a APIYI (apiyi.com) para invocar modelos de vídeo já comercializados, como Seedance 2.0, Kling 3.0 e Veo 3.1, para concluir seus projetos, enquanto avalia internamente o progresso do código aberto do HappyHorse.
Os três níveis de impacto do modelo HappyHorse na indústria
Mesmo que o HappyHorse 1.0 acabe sendo apenas uma campanha de marketing bem orquestrada, ele já deixou três impactos dignos de nota em todo o setor de geração de vídeo por IA.
Primeiro nível: O sinal de uma mudança de paradigma arquitetural
Nos últimos dois anos, os principais modelos de vídeo continuaram focados no refinamento do caminho de Diffusion multfluxo + Cross-Attention. O modelo HappyHorse, ao alcançar o primeiro lugar no Arena, provou que o caminho de "Self-Attention de fluxo único + inferência com pouquíssimos passos" também pode chegar ao estado da arte (SOTA), sendo, inclusive, mais limpo do ponto de vista de engenharia. Isso forçará muitas equipes a repensar: não seria hora de eliminar essa "taxa de complexidade" que é o Cross-Attention?
Segundo nível: A evolução da estratégia de código aberto
O HappyHorse escolheu o ritmo de "aparecer anonimamente no ranking → anunciar publicamente que será open source → liberar os pesos", em vez do tradicional "publicar artigo → liberar pesos". Essa é uma abordagem mais próxima do lançamento de produtos de consumo, colocando os "dados de percepção do usuário" antes do artigo acadêmico. Se ele cumprir a promessa de abrir o código, o HappyHorse 1.0 pode se tornar mais um modelo base de vídeo amplamente desenvolvido pela comunidade, seguindo os passos de Wan, Hunyuan Video e Open-Sora.
Terceiro nível: A credibilidade dos rankings de teste cego
Por outro lado, a "ascensão e desaparecimento repentinos" do HappyHorse também serviu como um alerta para plataformas de teste cego como Artificial Analysis e LMArena. Com cada vez mais entradas anônimas, distinguir entre um "modelo genuinamente novo" e um "checkpoint de um modelo existente" se tornará um desafio inevitável para os mantenedores dos rankings. Para os desenvolvedores, isso significa que, ao ler o ranking Elo, precisamos combinar mais informações, como "cartão do modelo + exemplos de inferência + dados reais de negócio", em vez de olhar apenas para um número.

Como os desenvolvedores podem lidar com eventos de "ataque surpresa" como o modelo HappyHorse
Para equipes de engenharia e criadores de conteúdo, em vez de ficarem presos em especulações sobre "quem é ele e quando será aberto", é melhor estabelecer um conjunto de ações padrão para lidar com esses eventos inesperados.
Fluxo de resposta recomendado em quatro etapas
| Etapa | Ação | Objetivo |
|---|---|---|
| 1 | Use uma interface unificada para rodar seus negócios de geração de vídeo | Garantir a troca imediata sempre que um novo modelo surgir |
| 2 | Colete comandos típicos de negócio e materiais de referência | Criar um "conjunto de benchmark" interno, independente do Arena público |
| 3 | Execute o benchmark interno assim que o novo modelo estiver disponível | Validar com seus próprios dados se a pontuação do Arena é reproduzível |
| 4 | Avalie o custo total (preço da API / latência de inferência / conformidade) | Decidir se vale a pena substituir o modelo principal |
O cerne desse processo é: não se deixe refém pelo ritmo de lançamento de qualquer modelo único, mas torne a "integração rápida de novos modelos" uma capacidade fundamental. O HappyHorse 1.0 foi apenas o começo; é previsível que, no segundo semestre de 2026, mais modelos anônimos similares apareçam em diversos Arenas de vídeo.
🎯 Dica de engenharia: Para equipes que desejam acompanhar a longo prazo o modelo HappyHorse e concorrentes como Seedance, Kling e Veo, recomendamos integrar a geração de vídeo a um serviço proxy de API como o APIYI (apiyi.com), que suporta a invocação de múltiplos modelos em paralelo. Assim, independentemente de quem apareça no ranking, o lado do negócio só precisa trocar um parâmetro de modelo para concluir a comparação e o lançamento gradual.
FAQ sobre o modelo HappyHorse
Q1: O HappyHorse 1.0 já está disponível para download?
Atualmente (início de abril de 2026), a página oficial do HappyHorse 1.0 ainda marca os links do repositório GitHub e do Model Hub como "Em breve" (Coming Soon). Isso significa que os pesos e o código de inferência ainda não foram tornados públicos. Qualquer canal que afirme que "já é possível baixar e implantar" deve ser tratado com muita cautela. Recomendamos acompanhar o site oficial e, antes que os pesos sejam liberados, utilizar plataformas como a APIYI (apiyi.com) para realizar a invocação do modelo de modelos já comercializados, como o Seedance 2.0 ou o Kling 3.0.
Q2: Por que o modelo HappyHorse desapareceu do ranking do Arena?
Não há uma explicação oficial definitiva sobre o motivo do desaparecimento. Com base nas discussões da comunidade, existem duas explicações principais: primeiro, o autor do modelo retirou-o voluntariamente para reorganizar os resultados antes de um lançamento oficial; segundo, a plataforma o removeu temporariamente devido à incerteza sobre a identidade da entrada anônima. De qualquer forma, isso não deve ser interpretado simplesmente como "o modelo não é bom" — sua pontuação Elo antes do desaparecimento era um dado real de testes cegos.
Q3: O HappyHorse 1.0 e o Wan 2.7 são o mesmo modelo?
Não há nenhuma informação oficial que confirme isso. O Wan 2.7 é um modelo de imagem/vídeo lançado oficialmente pelo Alibaba Tongyi Lab em abril de 2026, focado em "modo de pensamento" e renderização de textos longos; enquanto o modelo HappyHorse enfatiza um Transformer de fluxo único de 40 camadas e inferência de desruído de 8 passos. As descrições técnicas de ambos não são consistentes. Alguns membros da comunidade especulam que possuem a mesma origem, mas, no momento, parecem mais "dois produtos do mesmo período e categoria" do que embalagens diferentes para o mesmo modelo.
Q4: O modelo HappyHorse consegue realizar geração conjunta de áudio e vídeo?
Sim. A equipe oficial declarou explicitamente que o HappyHorse 1.0 processa tokens de texto, vídeo e áudio conjuntamente dentro do mesmo Transformer de 40 camadas, portanto, ele suporta nativamente a função de "entrada de texto → saída de curta-metragem com som". No ranking de áudio do Arena, ele ocupa atualmente o segundo lugar, atrás do Seedance 2.0, mas ainda pertence ao primeiro escalão.
Q5: Como desenvolvedor, como devo me preparar agora?
A estratégia mais eficiente é manter a neutralidade na cadeia de ferramentas: integre o serviço de geração de vídeo a uma plataforma unificada que suporte a invocação paralela de múltiplos modelos, como a APIYI (apiyi.com). Prepare antecipadamente seus comandos (prompts), roteiros de câmera e fluxos de revisão. Assim que o modelo HappyHorse for oficialmente aberto ou disponibilizado via API, você só precisará alterar o parâmetro do modelo para integrar esse novo competidor sem precisar reescrever o código.
Q6: Para quais cenários de negócio o HappyHorse 1.0 é adequado?
Considerando a ênfase oficial em "cenários humanos, performance facial, sincronia labial e multilinguismo", as direções mais adequadas para o modelo HappyHorse incluem: curtas-metragens com apresentadores virtuais / avatares digitais, minisséries de IA, vídeos promocionais em vários idiomas e segmentos de personagens em publicidade. Se o seu negócio foca principalmente em paisagens ou cenas de produtos, o Seedance 2.0, Veo 3.1 e Kling 3.0 continuam sendo escolhas mais seguras e consolidadas.
Conclusão: O que o modelo HappyHorse nos ensina
Juntando todas as peças, o HappyHorse 1.0 merece uma análise completa não apenas porque sua pontuação Elo no Artificial Analysis Video Arena é impressionante, mas porque representa uma cristalização do paradigma de lançamento de modelos de geração de vídeo em 2026: Transformer de fluxo único substituindo estruturas complexas de múltiplos fluxos, inferência de poucos passos substituindo dezenas de passos de desruído, entradas anônimas no ranking substituindo a publicação prévia de artigos, e promessas de código aberto substituindo APIs fechadas. Nenhuma dessas mudanças, isoladamente, seria disruptiva, mas, somadas, significam que estamos entrando em um novo ritmo de iteração de modelos de vídeo.
O conselho para as equipes de ponta é simples e direto: não se perca no jogo de adivinhação sobre "quem ele é", mas trate-o como um teste de estresse de engenharia — sua linha de produção de geração de vídeo consegue realizar a integração e avaliação no mesmo dia em que um novo modelo surge? Se a resposta for sim, então, independentemente de o modelo HappyHorse ser realmente de código aberto, ser confirmado como um disfarce de algum fabricante ou desaparecer silenciosamente, você sairá ganhando.
🎯 Recomendação final: Se você deseja experimentar todos os principais modelos de vídeo de IA (Seedance 2.0 / Kling 3.0 / Veo 3.1 / PixVerse V6, etc.) além do HappyHorse 1.0, e manter a capacidade de alternar para o HappyHorse com um clique no futuro, recomendamos a integração através de uma plataforma de serviço proxy de API unificada como a APIYI (apiyi.com). Isso evita a necessidade de realizar integrações repetidas com o SDK de cada fabricante e minimiza os custos de migração quando novos modelos forem lançados.
Autor: Equipe APIYI | Focados na implementação e prática de engenharia de Modelos de Linguagem Grande de IA. Para mais avaliações de modelos de vídeo e multimodais, visite APIYI (apiyi.com).