O Google Gemma 4 foi lançado oficialmente, adotando pela primeira vez a licença de código aberto Apache 2.0 e apresentando 4 modelos que cobrem desde Raspberry Pi até data centers. Como a versão open-source da tecnologia do Gemini 3, o Gemma 4 traz melhorias avassaladoras em relação ao Gemma 3 em áreas como raciocínio, codificação, visão e janelas de contexto longas.
Valor central: Ao ler este artigo, você entenderá a seleção dos 4 modelos do Gemma 4, as inovações em sua arquitetura, os limites das capacidades multimodais e os requisitos de hardware para implantação local.

Visão geral das informações do Gemma 4
O Gemma 4 foi lançado em 2 de abril de 2026 no Google Cloud Next, construído com base na pesquisa do Gemini 3, sendo a quarta geração da família de modelos open-source do Google.
| Item de informação | Detalhes |
|---|---|
| Data de lançamento | 2 de abril de 2026 |
| Quantidade de modelos | 4 (E2B / E4B / 26B-A4B / 31B) |
| Licença | Apache 2.0 (pela primeira vez, anteriormente era licença proprietária do Google) |
| Janela de contexto máxima | 256K tokens (31B e 26B-A4B) |
| Multimodal | Texto + Imagem + Vídeo + Áudio (E2B/E4B) |
| Destaques da arquitetura | Primeira variante MoE, tecnologia PLE, atenção híbrida |
| Plataformas disponíveis | Hugging Face, Google AI Studio, Vertex AI, Ollama, etc. |
Visão geral dos quatro modelos do Gemma 4
| Modelo | Parâmetros efetivos | Parâmetros totais | Arquitetura | Contexto | Multimodal |
|---|---|---|---|---|---|
| Gemma 4 E2B | 2.3B | 5.1B | Denso | 128K | Texto+Imagem+Vídeo+Áudio |
| Gemma 4 E4B | 4.5B | 8B | Denso | 128K | Texto+Imagem+Vídeo+Áudio |
| Gemma 4 26B-A4B | 3.8B ativados | 25.2B | MoE | 256K | Texto+Imagem+Vídeo |
| Gemma 4 31B | 30.7B | 30.7B | Denso | 256K | Texto+Imagem+Vídeo |
Regras de nomenclatura: O prefixo "E" representa "Parâmetros Efetivos", já que a tecnologia PLE faz com que os parâmetros totais sejam maiores que os parâmetros efetivos. 26B-A4B indica uma arquitetura MoE com 26B de parâmetros totais e 4B de parâmetros ativados por token.
🎯 Dica técnica: Os quatro modelos do Gemma 4 cobrem todos os cenários, desde dispositivos de borda até inferência em nuvem. Se você precisa comparar o desempenho entre vários modelos open-source, recomendo usar a plataforma APIYI (apiyi.com) para integração unificada, facilitando a alternância e avaliação de diferentes modelos.
Comparativo de desempenho: Gemma 4 vs Gemma 3: O maior salto geracional da história
O Google afirma que o Gemma 4 representa "o maior salto de desempenho em uma única geração no campo dos modelos de código aberto". Os dados de benchmark comprovam totalmente essa afirmação.
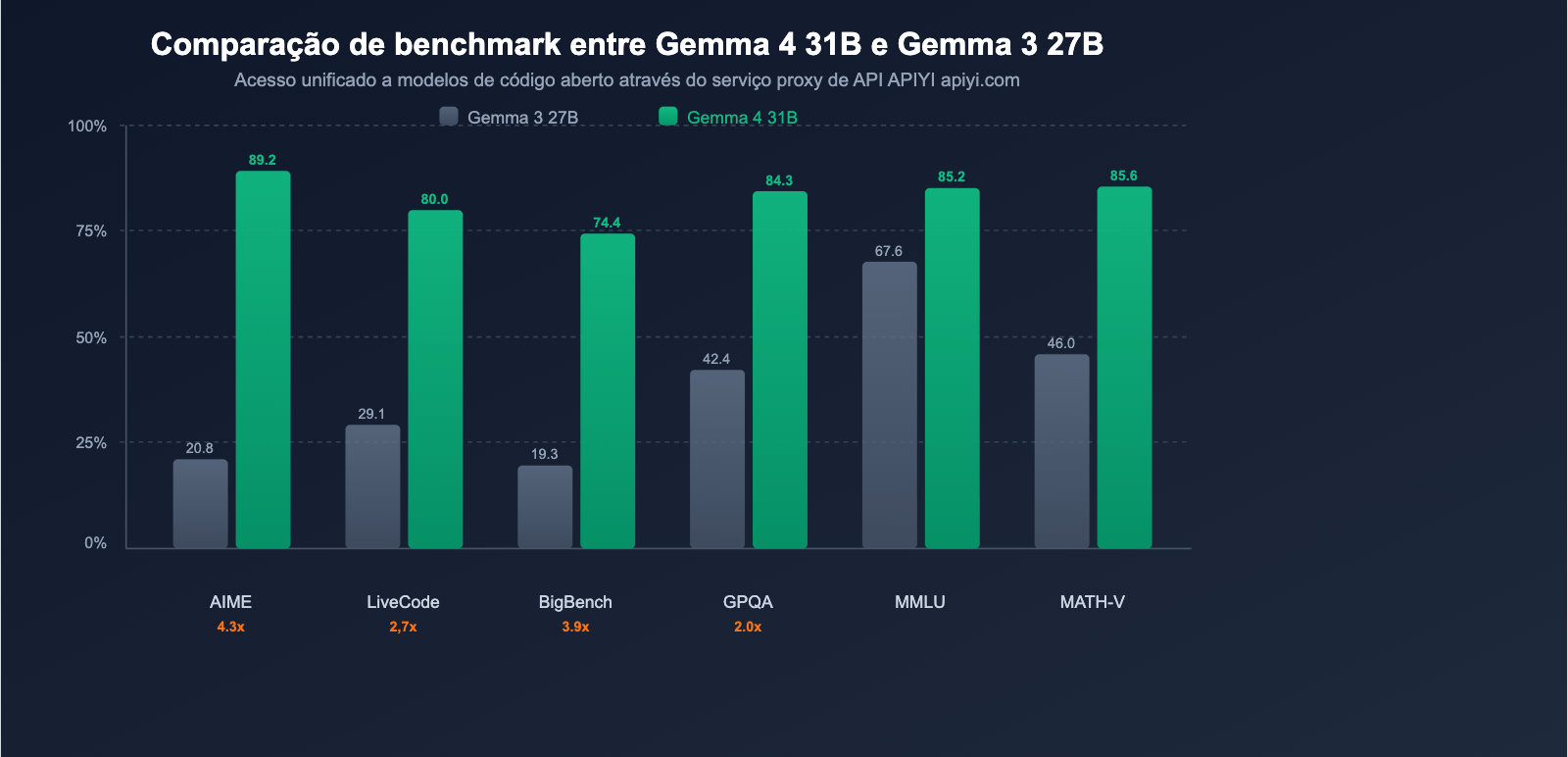
Comparativo dos principais benchmarks
| Benchmark | Gemma 3 27B | Gemma 4 31B | Melhoria |
|---|---|---|---|
| AIME 2026 (Raciocínio matemático) | 20,8% | 89,2% | +68,4 pts (4,3x) |
| LiveCodeBench v6 (Codificação) | 29,1% | 80,0% | +50,9 pts (2,7x) |
| BigBench Extra Hard (Raciocínio) | 19,3% | 74,4% | +55,1 pts (3,9x) |
| GPQA Diamond (Raciocínio científico) | 42,4% | 84,3% | +41,9 pts (2,0x) |
| MMLU Pro (Conhecimento) | 67,6% | 85,2% | +17,6 pts |
| MATH-Vision (Matemática visual) | 46,0% | 85,6% | +39,6 pts |
| MRCR 128K (Janela de contexto longa) | 13,5% | 66,4% | +52,9 pts |
Descobertas principais: O raciocínio matemático no AIME saltou de 20,8% para 89,2%, uma melhoria de 4,3 vezes; a codificação no LiveCodeBench subiu de 29,1% para 80,0%, uma melhoria de 2,7 vezes. Isso não é uma melhoria incremental, é um salto geracional.
Dados completos de benchmark dos 4 modelos
| Benchmark | 31B | 26B-A4B | E4B | E2B |
|---|---|---|---|---|
| MMLU Pro | 85,2% | 82,6% | 69,4% | 60,0% |
| AIME 2026 | 89,2% | 88,3% | 42,5% | 37,5% |
| GPQA Diamond | 84,3% | 82,3% | 58,6% | 43,4% |
| LiveCodeBench v6 | 80,0% | 77,1% | 52,0% | 44,0% |
| MATH-Vision | 85,6% | 82,4% | 59,5% | 52,4% |
| MMMU Pro (Visual) | 76,9% | 73,8% | 52,6% | 44,2% |
| Codeforces ELO | 2150 | 1718 | 940 | 633 |
Vantagem de eficiência do MoE: O 26B-A4B atingiu cerca de 97% do desempenho do modelo denso de 31B usando apenas 3,8B de parâmetros ativos, reduzindo drasticamente o custo de inferência. No LMArena, o 26B-A4B (~1441 ELO) superou até mesmo o gpt-oss-120B da OpenAI.
💡 Dica de escolha: Se você busca desempenho máximo, escolha o 31B; se busca custo-benefício, o 26B-A4B é a melhor opção (97% de desempenho usando apenas 12% dos parâmetros ativos). Através da plataforma APIYI (apiyi.com), você pode comparar rapidamente o desempenho real de ambas as versões em seus casos de uso específicos.
As 6 principais inovações arquiteturais do Gemma 4
O Gemma 4 introduziu diversas tecnologias inovadoras em sua arquitetura, o que é a razão fundamental para seu salto de desempenho.

Técnica 1: Per-Layer Embeddings (PLE)
O PLE adiciona um caminho condicional paralelo fora do fluxo residual principal, gerando vetores de token dedicados para cada camada do decodificador. Essa técnica aumenta a capacidade expressiva de modelos menores, permitindo que o E2B, com 2,3 bilhões de parâmetros efetivos, obtenha um desempenho muito superior ao que seu tamanho sugeriria.
Técnica 2: Atenção Híbrida (Hybrid Attention)
Alterna entre camadas de atenção de janela deslizante local e atenção de contexto completo global:
- Camada de janela deslizante: Processa o contexto local (E2B/E4B: 512 tokens; 31B/26B: 1024 tokens)
- Camada de atenção global: Processa o escopo de contexto completo
Esse design híbrido reduz significativamente o custo computacional enquanto mantém a capacidade de lidar com contextos longos.
Técnica 3: Codificação de posição Dual RoPE
- A camada de janela deslizante utiliza o RoPE padrão
- A camada de atenção global utiliza o Proportional RoPE
Esse design de RoPE duplo torna possível um contexto de 256K sem perda de qualidade.
Técnica 4: Cache KV Compartilhado
As últimas N camadas reutilizam os tensores K/V da última camada não compartilhada do mesmo tipo, reduzindo drasticamente o cálculo e o uso de memória de vídeo. Esta é uma das tecnologias-chave que permite ao Gemma 4 executar modelos grandes em hardware de consumo.
Técnica 5: MoE (Mistura de Especialistas) (26B-A4B)
O Gemma 4 introduz pela primeira vez uma variante MoE:
- 128 pequenos especialistas
- 8 especialistas ativados por token + 1 especialista compartilhado
- Alcança cerca de 97% do desempenho de um modelo denso de 31B com apenas 3,8B de parâmetros ativos
Técnica 6: Multimodal Nativo
As capacidades de visão e áudio são integradas diretamente na fase de pré-treinamento:
- Codificador visual: E2B/E4B ~150M de parâmetros; 31B/26B ~550M de parâmetros
- Codificador de áudio: Conformer estilo USM, ~300M de parâmetros (apenas E2B/E4B)
- Suporta imagens com proporções variáveis, com orçamento de tokens configurável (70-1120 tokens)
Detalhes sobre as capacidades multimodais e de Agente do Gemma 4
O Gemma 4 não é apenas um modelo de conversação, mas um sistema multimodal completo equipado com capacidades robustas de Agente.
Capacidades de entrada multimodal
| Modalidade | E2B | E4B | 31B | 26B-A4B |
|---|---|---|---|---|
| Texto | ✅ | ✅ | ✅ | ✅ |
| Imagem | ✅ | ✅ | ✅ | ✅ |
| Vídeo (máx. 60s, 1fps) | ✅ | ✅ | ✅ | ✅ |
| Áudio (máx. 30s) | ✅ | ✅ | ❌ | ❌ |
As capacidades visuais abrangem:
- Detecção de objetos e saída de caixas delimitadoras (formato JSON nativo)
- Detecção e apontamento de elementos de GUI
- Análise de documentos/PDF e compreensão de gráficos
- Compreensão de telas/interfaces de usuário
- Entrada cruzada de texto e imagem (mistura em qualquer ordem)
Chamada de função nativa e capacidades de Agente
O Gemma 4 possui capacidades de chamada de função integradas desde a fase de treinamento, não sendo algo adicionado via ajuste fino posterior:
- Chamada de função nativa: Otimizada diretamente na fase de treinamento, com suporte para orquestração de múltiplas ferramentas
- Raciocínio Estendido (Extended Thinking): Pode ser ativado via
enable_thinking=Truepara raciocínio em múltiplas etapas - Saída estruturada: Saída JSON nativa, ideal para integração com APIs
- Fluxo de Agente de múltiplos turnos: Suporta ciclos de Agente autônomos de planejamento-execução-observação
# Exemplo de chamada de função do Gemma 4 (via interface unificada da APIYI)
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Obtém a previsão do tempo para a cidade especificada",
"parameters": {
"type": "object",
"properties": {
"city": {"type": "string"}
},
"required": ["city"]
}
}
}
]
response = client.chat.completions.create(
model="gemma-4-31b-it",
messages=[{"role": "user", "content": "Como está o tempo em Pequim hoje?"}],
tools=tools,
tool_choice="auto",
)
🚀 Começo rápido: A chamada de função nativa do Gemma 4 o torna a escolha ideal para construir Agentes de IA. Recomendamos usar a plataforma APIYI (apiyi.com) para uma integração rápida, com suporte a interfaces compatíveis com OpenAI, sem necessidade de adaptações extras.
Guia de hardware para implantação local do Gemma 4
A licença Apache 2.0 significa que você pode implantar o Gemma 4 livremente em qualquer hardware. Abaixo estão os requisitos de hardware para cada modelo.
Visão geral dos requisitos de hardware
| Modelo | Hardware mínimo | Cenário típico de implantação |
|---|---|---|
| E2B (2.3B) | <1.5GB de RAM | Raspberry Pi 5 (133 tok/s pré-preenchimento, 7.6 tok/s decodificação) |
| E4B (4.5B) | NPU/GPU de nível mobile | Dispositivos móveis, Apple Silicon (MLX) |
| 26B-A4B (MoE) | GPU de consumo única (quantizada) | Estações de trabalho pessoais, servidores pequenos |
| 31B (Dense) | H100 de 80GB única (FP16) | Inferência em nuvem, data centers |
Hardware e frameworks suportados
| Hardware/Framework | Suporte |
|---|---|
| NVIDIA (H100/B200/RTX) | ✅ Suporte para toda a série |
| Google TPU (Trillium/Ironwood) | ✅ Otimização nativa |
| Apple Silicon (MLX) | ✅ mlx-community/gemma-4-* |
| AMD ROCm | ✅ Suportado |
| Qualcomm NPU (IQ8) | ✅ Inferência em dispositivos móveis |
| GGUF (llama.cpp/Ollama) | ✅ Quantização de 2-bit/4-bit |
| ONNX (WebGPU/Navegador) | ✅ onnx-community/gemma-4-* |
| NVIDIA NIM | ✅ Implantação em containers |
O E2B pode rodar a decodificação no Raspberry Pi 5 a uma velocidade de 7,6 tokens por segundo, o que abre possibilidades totalmente novas para aplicações de IA de borda (edge AI).
Licença Apache 2.0: Por que desta vez é diferente
O Gemma 4 adotou pela primeira vez a licença Apache 2.0, o que representa uma mudança significativa. Anteriormente, todos os modelos Gemma utilizavam os acordos de licença proprietários do Google, que impunham restrições de uso específicas e cláusulas de rescisão.
Comparação de Licenças
| Dimensão | Gemma 3 (Licença Google) | Gemma 4 (Apache 2.0) |
|---|---|---|
| Uso comercial | Com restrições | ✅ Totalmente livre |
| Modificação e distribuição | Sujeito a termos adicionais | ✅ Totalmente livre |
| Modelos derivados | Com restrições | ✅ Totalmente livre |
| Direito de rescisão | Google reserva o direito | ❌ Irrevogável |
| Licenciamento de patentes | Limitado | ✅ Licença explícita |
Apache 2.0 significa que:
- Empresas podem utilizar em produtos comerciais com tranquilidade, sem riscos jurídicos.
- É possível ajustar (fine-tuning) e distribuir modelos derivados livremente.
- Alinha-se às estratégias de código aberto do Meta Llama e do DeepSeek.
- Reduz drasticamente as barreiras de conformidade para adoção corporativa.
💰 Otimização de custos: Apache 2.0 + implantação local = custo zero de invocação do modelo. Para cenários com alto volume de inferência, a implantação local do Gemma 4 pode ser mais econômica do que a invocação via API. Se precisar comparar o custo-benefício entre a implantação local e a invocação do modelo, você pode usar a plataforma APIYI (apiyi.com) para validar os resultados via API antes de decidir pela implantação local.
Obtenção e primeiros passos com o modelo Gemma 4
Canais de download do modelo
| Plataforma | Modelos disponíveis | Finalidade |
|---|---|---|
| Hugging Face | Todos os 4 (base + IT) | Download geral, pesquisa |
| Google AI Studio | 31B, 26B MoE | Experiência online gratuita |
| Vertex AI | Todos os 4 | Implantação de nível empresarial |
| Ollama / llama.cpp | Versões quantizadas GGUF | Implantação local rápida |
| Google AI Edge Gallery | E4B, E2B | Implantação em dispositivos móveis |
Implantação rápida com Ollama
# Implantar o Gemma 4 31B (recomendado)
ollama run gemma4:31b
# Implantar a versão MoE (alto custo-benefício)
ollama run gemma4:26b-a4b
# Implantar a versão leve (dispositivos de borda)
ollama run gemma4:e4b
Suporte a ajuste fino (Fine-tuning)
O Gemma 4 oferece um ecossistema completo de ajuste fino:
| Framework | Métodos suportados |
|---|---|
| TRL | SFT, DPO, aprendizado por reforço (incluindo multimodal) |
| PEFT | LoRA, QLoRA (via bitsandbytes) |
| Vertex AI | Treinamento gerenciado |
| Unsloth Studio | Ajuste fino via interface gráfica |
Os codificadores de visão e áudio podem ser congelados, ajustando apenas a parte de texto, o que reduz drasticamente os custos de ajuste fino.
🎯 Dica técnica: Recomendamos testar primeiro o desempenho do Gemma 4 via API na plataforma APIYI (apiyi.com). Confirme se ele atende às suas necessidades antes de prosseguir com a implantação local ou o ajuste fino, evitando desperdício de recursos.
Perguntas Frequentes
Q1: Qual é a relação entre o Gemma 4 e o Gemini 3?
O Gemma 4 foi construído com base na mesma pesquisa do Gemini 3, podendo ser entendido como uma versão de código aberto da tecnologia do Gemini 3. O Gemma 4 possui um tamanho de modelo menor (máximo de 31B contra centenas de bilhões do Gemini), mas adota as mesmas inovações de arquitetura central. Através da plataforma APIYI apiyi.com, você pode usar tanto o Gemma 4 quanto a série Gemini para realizar análises comparativas.
Q2: Como escolher entre o 26B MoE e o 31B Dense?
Se o seu hardware for limitado ou se você precisar de alta taxa de transferência (throughput), escolha o 26B-A4B MoE — ele atinge cerca de 97% do desempenho do 31B usando apenas 3,8B de parâmetros ativos. Se você busca desempenho máximo e possui uma GPU de 80GB, escolha o 31B Dense. O custo de inferência da versão MoE é aproximadamente 1/8 da versão Dense.
Q3: Para quais cenários o E2B e o E4B são adequados?
O E2B é ideal para cenários de borda extremos (Raspberry Pi, dispositivos IoT, dispositivos móveis), enquanto o E4B é adequado para dispositivos móveis e implantação em PCs leves. Ambos suportam entrada de áudio, algo que o 31B e o 26B não suportam. Se a sua aplicação precisa de compreensão de voz, você deve escolher o E2B ou o E4B.
Q4: Qual é o impacto da licença Apache 2.0 no uso comercial?
A Apache 2.0 é uma das licenças de código aberto mais flexíveis, permitindo uso comercial, modificação e distribuição totalmente livres e irrevogáveis. Em comparação com a licença proprietária do Google para o Gemma 3, as empresas não precisam se preocupar com riscos de conformidade. Você pode testar primeiro via API na plataforma APIYI apiyi.com e, após confirmar os resultados, realizar a implantação local para produtos comerciais.
Resumo
O Gemma 4 representa uma grande atualização na estratégia de IA de código aberto do Google. A licença Apache 2.0 quebra as barreiras de uso anteriores; os 4 modelos cobrem cenários de computação que vão desde Raspberry Pi até H100; o salto de desempenho geracional de 4,3 vezes no AIME e 2,7 vezes no LiveCodeBench, além do suporte multimodal nativo e chamada de funções, tornam este modelo a base preferida para o desenvolvimento de agentes de código aberto.
Revisão dos pontos principais:
- Licença: Pela primeira vez sob Apache 2.0, totalmente livre para uso comercial
- Modelos: 4 modelos cobrindo de 2B a 31B, incluindo a primeira variante MoE
- Desempenho: AIME +68pts (4,3x), LiveCodeBench +51pts (2,7x)
- Multimodal: Texto + imagem + vídeo + áudio, integração nativa
- Agente: Chamada de função nativa + Extended Thinking
- Implantação: Cobertura total de Raspberry Pi a H100, múltiplos frameworks (GGUF/ONNX/MLX)
Recomendamos acessar rapidamente a série de modelos Gemma 4 através da APIYI apiyi.com para comparar os resultados reais de diferentes modelos sob uma interface unificada.
Referências
- Blog oficial do Google – Lançamento do Gemma 4:
blog.google/innovation-and-ai/technology/developers-tools/gemma-4/ - Hugging Face – Modelo Gemma 4:
huggingface.co/blog/gemma4 - Google AI – Ficha técnica do modelo Gemma 4:
ai.google.dev/gemma/docs/core/model_card_4
Este artigo foi escrito pela equipe técnica da APIYI. Para mais tutoriais sobre o uso de Modelos de Linguagem Grande, acompanhe a APIYI em apiyi.com