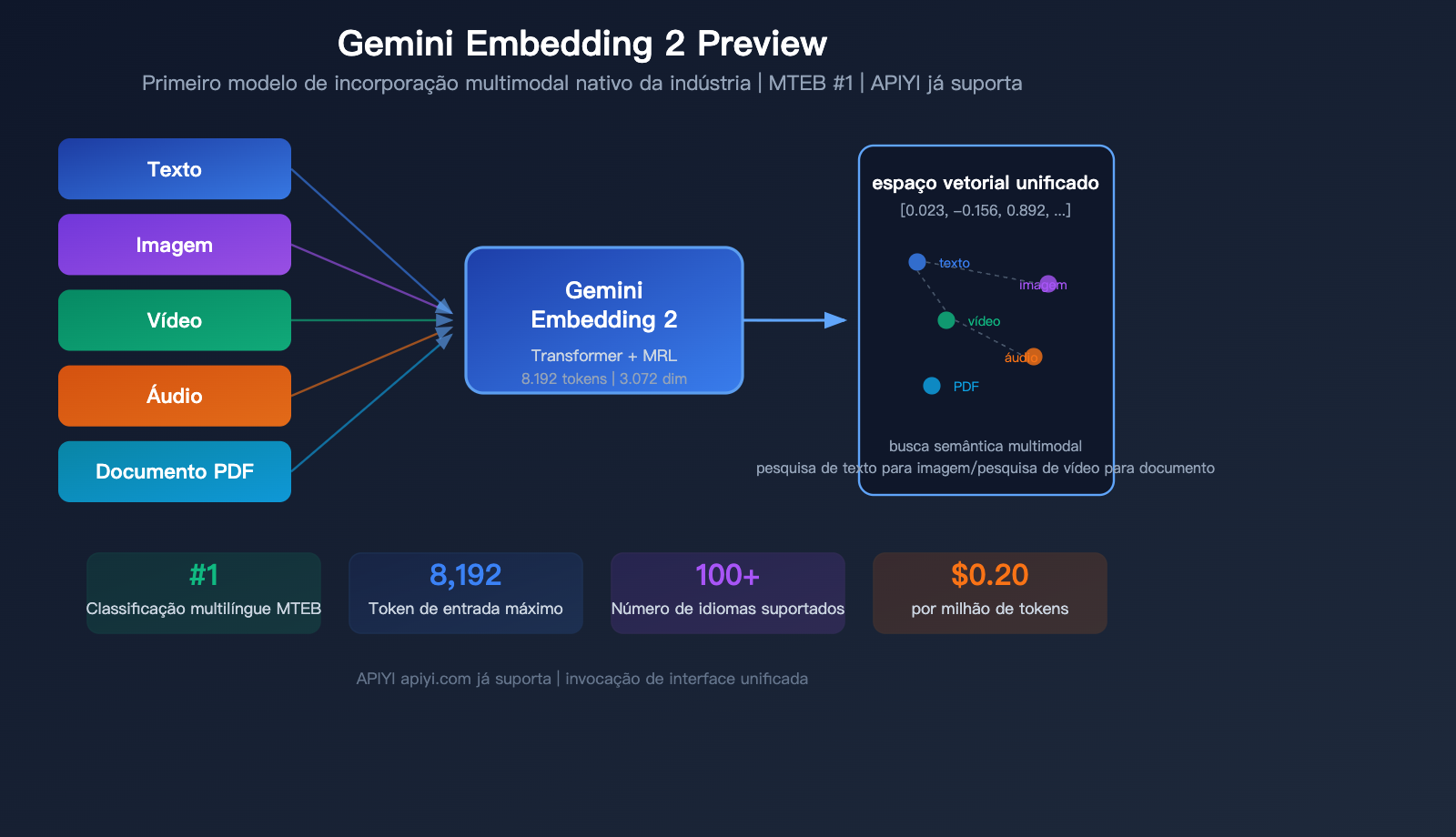
Em março de 2026, o Google lançou um modelo fundamental: o Gemini Embedding 2 Preview, o primeiro modelo de embedding multimodal nativo da indústria. Ele é capaz de mapear textos, imagens, vídeos, áudios e documentos PDF para um mesmo espaço vetorial, alcançando o 1º lugar no benchmark multilíngue MTEB, com uma vantagem de mais de 5 pontos percentuais sobre o segundo colocado.
Valor central: Ao ler este artigo, você entenderá os 5 principais avanços técnicos do Gemini Embedding 2 Preview, a comparação de preço e desempenho com a concorrência e como integrá-lo rapidamente via API.
title: "O que é o Gemini Embedding 2 Preview"
description: "Conheça o Gemini Embedding 2 Preview, o novo modelo de embedding multimodal da Google com suporte a 8K tokens e desempenho líder no MTEB."
O que é o Gemini Embedding 2 Preview
O Gemini Embedding 2 Preview é o mais recente modelo de embedding lançado pelo Google em 10 de março de 2026. Ele é inicializado com base na arquitetura Gemini, utiliza uma estrutura Transformer de atenção bidirecional e é o primeiro modelo de embedding do Google com suporte nativo para entrada multimodal.
| Especificação | Detalhes |
|---|---|
| ID do Modelo | gemini-embedding-2-preview |
| Data de Lançamento | 10 de março de 2026 |
| Status | Preview (versão de visualização, versão final a definir) |
| Dimensão de saída padrão | 3.072 |
| Intervalo de dimensão opcional | 128 — 3.072 |
| Máximo de tokens de entrada | 8.192 (4 vezes maior que a geração anterior) |
| Suporte multimodal | Texto, imagem, vídeo, áudio, PDF |
| Suporte a idiomas | Mais de 100 idiomas |
| Treinamento Matryoshka | Suportado (pode truncar dimensões mantendo a qualidade semântica) |
| Plataformas disponíveis | Gemini API, Vertex AI, APIYI apiyi.com |
Principais diferenças em relação à geração anterior
| Característica | text-embedding-004 | gemini-embedding-001 | gemini-embedding-2-preview |
|---|---|---|---|
| Máximo de tokens de entrada | 2.048 | 2.048 | 8.192 |
| Dimensão de saída | Até 768 | 128-3.072 | 128-3.072 |
| Multimodal | Apenas texto | Apenas texto | Texto+Imagem+Vídeo+Áudio+PDF |
| Especificação do tipo de tarefa | Campo task_type |
Campo task_type |
Instruções embutidas no comando |
| Suporte a MRL | Não suportado | Suportado | Suportado |
| Preço/milhão de tokens | Descontinuado | $0,15 | $0,20 |
🎯 Dica de integração: O APIYI apiyi.com já suporta a invocação do modelo gemini-embedding-2-preview.
Você pode integrá-lo através da interface compatível com OpenAI, sem a necessidade de configurar uma chave API do Google separadamente.
Detalhamento das 5 grandes inovações técnicas
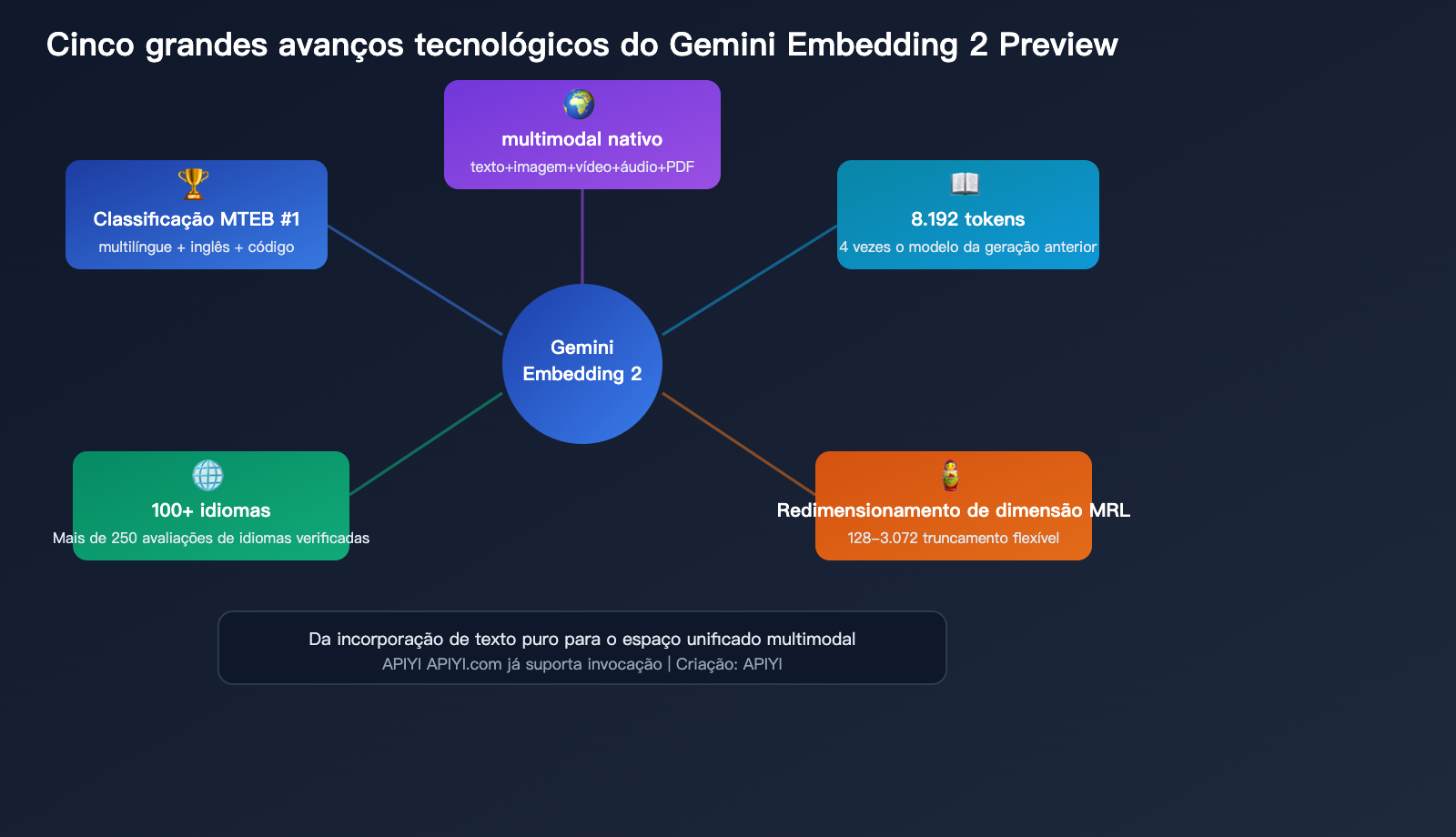
Inovação 1: Espaço de embedding unificado nativamente multimodal
Esta é a maior vantagem diferencial do Gemini Embedding 2 — conteúdos de 5 modalidades são mapeados para o mesmo espaço vetorial.
| Modalidade | Requisitos de formato | Limite por solicitação | Observações |
|---|---|---|---|
| Texto | Texto simples | 8.192 Tokens | Suporta 100+ idiomas |
| Imagem | PNG, JPEG | Até 6 por solicitação | Processamento direto de pixels |
| Vídeo | MP4, MOV | Até 120 segundos | Amostragem automática de até 32 quadros |
| Áudio | MP3, WAV | Até 80 segundos | Processamento nativo, sem necessidade de transcrição |
| Documento PDF | Até 6 páginas por solicitação | Inclui capacidade de OCR |
Cenários de aplicação prática:
- Pesquisar imagens usando texto ("carro esportivo vermelho na pista" → retorna imagens correspondentes)
- Pesquisar clipes de vídeo semelhantes usando imagens
- Pesquisar documentos relevantes usando descrições de voz
- Construir uma base de conhecimento unificada e multimodal
Isso era impossível em modelos de embedding anteriores — a série text-embedding-3 da OpenAI suporta apenas texto. Se você precisasse de busca por imagem, teria que usar um modelo visual para extrair descrições antes de fazer o embedding, o que adicionava uma etapa extra e causava perda de informações.
Inovação 2: Janela de contexto de 8.192 tokens
A janela de entrada aumentou de 2.048 para 8.192 tokens, o que significa que você pode incorporar trechos de documentos muito mais longos de uma só vez.
Para sistemas de RAG (Geração Aumentada por Recuperação), essa melhoria é extremamente útil:
- Antes, era necessário dividir documentos em pequenos segmentos de 500-1000 tokens.
- Agora, você pode usar segmentos maiores de 2000-4000 tokens, preservando mais contexto.
- Segmentos de documento maiores = menos divisões = resultados de busca mais completos.
Inovação 3: Escalonamento de dimensão Matryoshka
O Gemini Embedding 2 utiliza o treinamento Matryoshka Representation Learning (MRL), onde o modelo concentra as informações semânticas mais importantes nas primeiras dimensões do vetor.
Isso significa que você pode escolher a dimensão de forma flexível de acordo com o cenário:
| Dimensão | Tamanho do vetor | Cenário de aplicação | Perda de qualidade |
|---|---|---|---|
| 3.072 (padrão) | 12,3 KB | Busca de alta precisão | Nenhuma |
| 1.536 | 6,1 KB | Equilíbrio entre precisão e armazenamento | Mínima |
| 768 | 3,1 KB | Preferencial para implantações em larga escala | Pequena |
| 256 | 1,0 KB | Sistemas de recomendação em tempo real | Média |
| 128 | 0,5 KB | Cenários de compressão extrema | Significativa |
Nota: Ao usar dimensões inferiores a 3.072, é necessário normalizar manualmente o vetor antes de calcular a similaridade.
Inovação 4: Suporte a mais de 100 idiomas
No benchmark multilíngue MTEB, o Gemini Embedding 2 foi avaliado em mais de 250 idiomas, cobrindo uma gama muito superior aos concorrentes.
Principais indicadores de desempenho de idiomas:
- Mineração de texto bilingue (Bitext Mining): 79,32 pontos
- Busca translinguística (XOR-Retrieve): Recall@5kt 90,42 pontos
- Compreensão multilíngue (XTREME-UP): MRR@10 64,33 pontos
Inovação 5: Primeiro lugar em vários rankings do MTEB
| Benchmark | Pontuação | Ranking | Margem de liderança |
|---|---|---|---|
| MTEB Multilíngue (Tarefa Média) | 68,32 | 1º | +5,09 |
| MTEB Multilíngue (Tipo Médio) | 59,64 | 1º | — |
| MTEB Inglês v2 (Tarefa Média) | 73,30 | 1º | — |
| MTEB Inglês v2 (Tipo Médio) | 67,67 | 1º | — |
| MTEB Código (Média Geral) | 74,66 | 1º | — |
Para efeito de comparação, o segundo colocado, o modelo gte-Qwen2-7B-instruct, obteve 62,51 pontos no MTEB multilíngue — o Gemini Embedding 2 lidera por quase 6 pontos, o que representa uma diferença muito grande no campo dos modelos de embedding.
💡 Sugestão de desenvolvimento: Se você está construindo um sistema de RAG ou uma aplicação de busca semântica,
o Gemini Embedding 2 é a escolha mais poderosa atualmente para cenários multilíngues e de código.
Através do APIYI apiyi.com, você pode integrar este modelo com um clique, além de suportar modelos de embedding da OpenAI,
facilitando a comparação rápida de resultados.
Comparativo de preços e desempenho com concorrentes
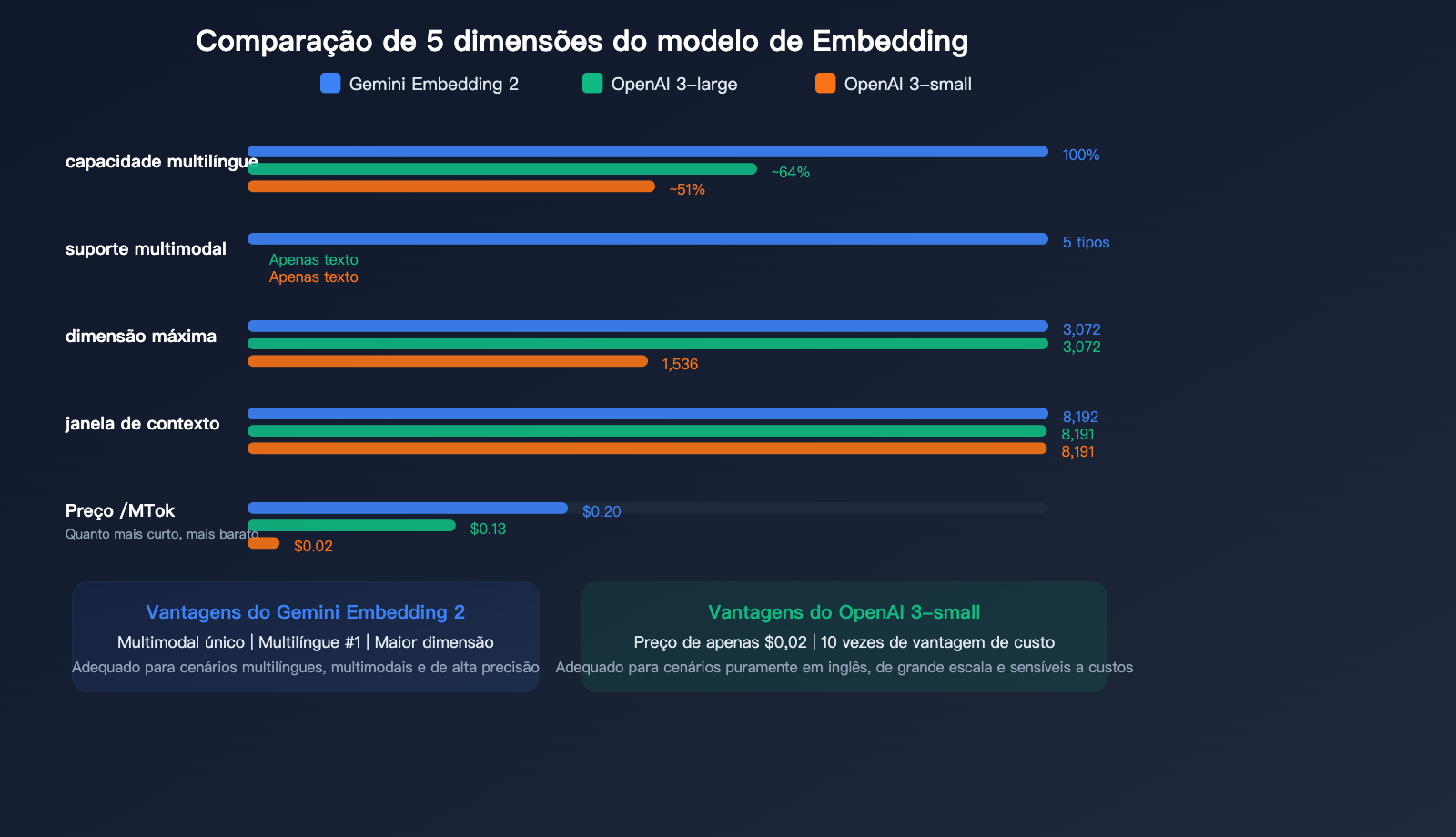
Comparativo de preços de incorporação de texto (Embedding)
| Modelo | Preço/milhão de tokens | Dimensão máxima | Entrada máxima | Multimodal | Ranking multilíngue |
|---|---|---|---|---|---|
| Gemini Embedding 2 | $0.20 | 3.072 | 8.192 | ✅ Multimodal | #1 |
| gemini-embedding-001 | $0.15 | 3.072 | 2.048 | ❌ | — |
| OpenAI text-embedding-3-large | $0.13 | 3.072 | 8.191 | ❌ | — |
| OpenAI text-embedding-3-small | $0.02 | 1.536 | 8.191 | ❌ | — |
Preços de conteúdo multimodal (exclusivo do Gemini Embedding 2):
| Tipo de entrada | Preço pago/milhão de tokens | Preço em lote/milhão de tokens |
|---|---|---|
| Texto | $0.20 | $0.10 |
| Imagem | $0.45 (~$0.00012/imagem) | $0.225 |
| Áudio | $6.50 (~$0.00016/segundo) | $3.25 |
| Vídeo | $12.00 (~$0.00079/frame) | $6.00 |
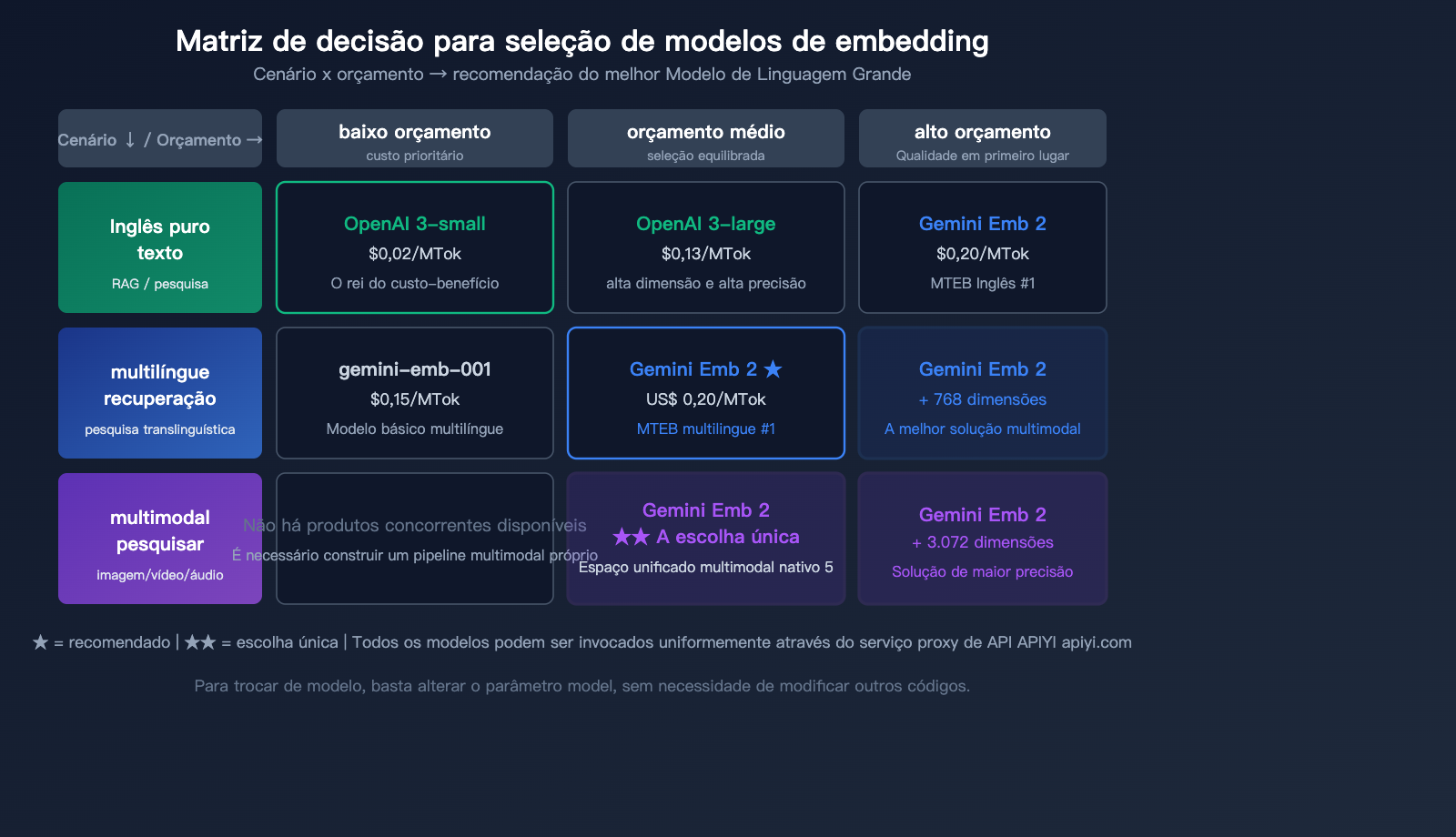
Sugestões de seleção
| Cenário de necessidade | Modelo recomendado | Motivo |
|---|---|---|
| Texto puro, sensível a custos | OpenAI text-embedding-3-small | O mais barato ($0.02) |
| Texto puro, alta precisão | Gemini Embedding 2 ou OpenAI 3-large | Precisão próxima, Gemini é melhor em multilíngue |
| Busca multimodal | Gemini Embedding 2 | Única solução multimodal nativa |
| Busca multilíngue | Gemini Embedding 2 | #1 em multilíngue no MTEB |
| Busca de código | Gemini Embedding 2 | #1 em código no MTEB |
| Baixo custo em larga escala | OpenAI 3-small + API em lote | Vantagem de preço de 10x |
🎯 Dica de escolha: A escolha do modelo de embedding depende do seu cenário específico.
Recomendamos acessar os modelos de embedding do Gemini e da OpenAI simultaneamente através da plataforma APIYI (apiyi.com),
para comparar os resultados de busca com dados reais antes de decidir. A plataforma suporta chamadas de interface unificadas, permitindo trocar de modelo sem alterar o código.
Detalhes sobre a invocação da API
Como especificar o tipo de tarefa (Mudança importante)
Diferente do gemini-embedding-001, o Gemini Embedding 2 não utiliza mais o parâmetro task_type. Em vez disso, você deve especificar o tipo de tarefa incorporando instruções diretamente no conteúdo de entrada.
8 tipos de tarefas suportadas:
| Tipo de tarefa | Formato da consulta | Formato do documento |
|---|---|---|
| Busca/Recuperação | task: search result | query: {conteúdo} |
title: {título} | text: {conteúdo} |
| Perguntas e Respostas | task: question answering | query: {pergunta} |
title: {título} | text: {conteúdo} |
| Verificação de fatos | task: fact checking | query: {afirmação} |
title: {título} | text: {conteúdo} |
| Recuperação de código | task: code retrieval | query: {descrição} |
title: {título} | text: {código} |
| Classificação | task: classification | query: {conteúdo} |
Mesmo formato |
| Agrupamento (Clustering) | task: clustering | query: {conteúdo} |
Mesmo formato |
| Similaridade de frases | task: sentence similarity | query: {frase} |
Mesmo formato |
Para o lado do documento, caso não haja título, utilize title: none.
Exemplo de invocação em Python
import openai
# Invocação através da interface unificada da APIYI
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
# Embedding de texto - cenário de busca
response = client.embeddings.create(
model="gemini-embedding-2-preview",
input="task: search result | query: o que é um banco de dados vetorial",
dimensions=768 # Dimensões opcionais: 128-3072
)
embedding = response.data[0].embedding
print(f"Dimensão do vetor: {len(embedding)}")
print(f"Primeiros 5 valores: {embedding[:5]}")
Ver o código completo do fluxo de recuperação RAG
import openai
import numpy as np
from typing import List
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
def get_embedding(text: str, task: str = "search result", dim: int = 768) -> List[float]:
"""Obtém o vetor de embedding do texto"""
formatted = f"task: {task} | query: {text}"
response = client.embeddings.create(
model="gemini-embedding-2-preview",
input=formatted,
dimensions=dim
)
vec = response.data[0].embedding
# A truncagem de dimensão MRL requer normalização manual
if dim < 3072:
norm = np.linalg.norm(vec)
vec = (np.array(vec) / norm).tolist()
return vec
def get_doc_embedding(title: str, text: str, dim: int = 768) -> List[float]:
"""Obtém o vetor de embedding do documento"""
formatted = f"title: {title} | text: {text}"
response = client.embeddings.create(
model="gemini-embedding-2-preview",
input=formatted,
dimensions=dim
)
vec = response.data[0].embedding
if dim < 3072:
norm = np.linalg.norm(vec)
vec = (np.array(vec) / norm).tolist()
return vec
def cosine_similarity(a: List[float], b: List[float]) -> float:
"""Calcula a similaridade de cosseno"""
a, b = np.array(a), np.array(b)
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
# Exemplo de uso
query_vec = get_embedding("como otimizar resultados de recuperação RAG")
doc_vec = get_doc_embedding(
"Guia de otimização RAG",
"Este artigo apresenta 5 métodos para otimizar a qualidade da recuperação RAG..."
)
similarity = cosine_similarity(query_vec, doc_vec)
print(f"Similaridade: {similarity:.4f}")
🚀 Comece rápido: Recomendamos usar a plataforma APIYI apiyi.com para integrar o Gemini Embedding 2 rapidamente.
A plataforma oferece uma interface de embedding compatível com OpenAI, permitindo a integração em 5 minutos,
além de suportar a invocação unificada de modelos de embedding líderes como OpenAI, Gemini e Cohere.
Observações importantes
Limitações do estado Preview
| Limitação | Descrição | Impacto |
|---|---|---|
| Possíveis mudanças de versão | Especificações e preços podem mudar durante a fase Preview | Recomendamos preparar planos de fallback para o ambiente de produção |
| Incompatibilidade de espaço vetorial | Não pode ser misturado com vetores de modelos antigos | A atualização exige uma reindexação completa |
| Necessidade de normalização | Requer normalização manual ao usar dimensões < 3.072 | É necessário adicionar etapas de normalização no código |
| Limites de taxa rigorosos | As cotas do modelo Preview são inferiores aos modelos GA | É necessário solicitar aumento de cota para uso em larga escala |
| Uso de dados no nível gratuito | Dados do nível gratuito podem ser usados para melhoria do produto | Recomendamos o uso do nível pago para dados sensíveis |
Observações sobre a migração de modelos antigos
- Reindexação obrigatória: Os espaços vetoriais de modelos diferentes são incompatíveis; não podem ser misturados no mesmo banco de dados.
- Mudança no formato do tipo de tarefa: Alterado do parâmetro
task_typepara instruções incorporadas no comando (prompt). - Processamento de normalização: Se utilizar dimensões não padrão, é necessário adicionar lógica de normalização no código.
- Teste antes da migração: Recomendamos comparar a eficácia da recuperação entre os modelos novos e antigos em um ambiente de teste antes de decidir pela migração.
Perguntas Frequentes
Q1: Quais são as vantagens do Gemini Embedding 2 Preview em relação ao OpenAI text-embedding-3-large?
As principais vantagens estão em três pilares: suporte nativo multimodal (o OpenAI suporta apenas texto), o 1º lugar no ranking multilíngue do MTEB (com uma margem significativa) e uma qualidade superior de incorporação de código. No entanto, o OpenAI text-embedding-3-large tem um preço menor ($0,13 vs $0,20) e, se você precisar apenas de incorporação de texto em inglês, a qualidade entre ambos é muito próxima. Através do serviço proxy de API da APIYI (apiyi.com), você pode invocar ambos os modelos simultaneamente para compará-los com dados reais.
Q2: Qual é a utilidade prática da incorporação multimodal?
A aplicação mais direta é a busca cross-modal: o usuário insere um texto e a busca retorna imagens, vídeos ou documentos relevantes. Por exemplo, em um cenário de e-commerce, você pode usar "vestido vermelho" para buscar fotos de produtos, ou em uma base de conhecimento corporativa, usar uma descrição textual para encontrar trechos relevantes em vídeos de treinamento. A abordagem tradicional exigia o uso de um modelo visual para extrair descrições antes de incorporar o texto; o Gemini Embedding 2 processa imagens/vídeos brutos diretamente, resultando em uma menor perda de informação.
Q3: Qual é a dimensão ideal? Existe muita diferença entre 768 e 3072?
Para a maioria das aplicações, 768 dimensões representam o ponto de equilíbrio ideal — o custo de armazenamento é apenas 1/4 do de 3072 dimensões, mas a perda na qualidade de recuperação é mínima (graças ao treinamento Matryoshka). Se o seu conjunto de dados for pequeno (<1 milhão de registros) e exigir precisão extrema, use 3072 dimensões. Se o volume de dados for grande ou se você precisar de recuperação em tempo real, 768 ou até 256 dimensões são escolhas perfeitamente razoáveis.
Q4: Como a APIYI suporta o Gemini Embedding 2? É necessária alguma configuração extra?
A APIYI (apiyi.com) já suporta o modelo gemini-embedding-2-preview. Você pode invocá-lo através da interface de embedding padrão compatível com OpenAI, sem a necessidade de configurar uma chave API do Google adicional. Basta especificar gemini-embedding-2-preview no parâmetro model; os outros parâmetros (como dimensions) são exatamente iguais aos da interface de embedding da OpenAI.
Resumo: O novo padrão para embeddings multimodais
O Gemini Embedding 2 Preview representa um marco importante para os modelos de embedding — a transição do texto puro para um espaço multimodal verdadeiramente unificado. Ao conquistar o 1º lugar nas dimensões multilíngue, inglês e código no MTEB, somado a uma janela de contexto de 8K e escalabilidade de dimensão MRL, ele oferece a base mais robusta atualmente disponível para sistemas de RAG, busca semântica e construção de bases de conhecimento.
Principais pontos:
- Primeiro modelo de embedding nativamente multimodal da indústria (texto + imagem + vídeo + áudio + PDF)
- 1º lugar no benchmark MTEB multilíngue, com uma vantagem de mais de 5 pontos
- Janela de contexto de 8.192 tokens, 4 vezes maior que a geração anterior
- Treinamento MRL com suporte a escalabilidade flexível de 128 a 3.072 dimensões
- Preço de US$ 0,20 por milhão de tokens, excelente custo-benefício para cenários multimodais
Recomendamos a integração rápida do Gemini Embedding 2 Preview através da APIYI (apiyi.com). Com uma única chave API, você acessa modelos de embedding do Gemini, OpenAI e outros, facilitando comparações e alternâncias entre eles.
📝 Autor deste artigo: Equipe técnica da APIYI | APIYI apiyi.com – Plataforma de acesso unificado a mais de 300 APIs de Modelos de Linguagem Grande
Referências
-
Blog oficial do Google: Anúncio de lançamento do Gemini Embedding 2
- Link:
blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-embedding-2/ - Descrição: Contém a filosofia de design do modelo e a introdução às capacidades multimodais
- Link:
-
Documentação de Embedding da API Gemini: Guia oficial de uso da API
- Link:
ai.google.dev/gemini-api/docs/embeddings - Descrição: Parâmetros completos da API e exemplos de invocação do modelo
- Link:
-
Artigo de pesquisa do Gemini Embedding: Detalhes técnicos e benchmarks
- Link:
arxiv.org/html/2503.07891v1 - Descrição: Dados detalhados de testes MTEB e análise da arquitetura do modelo
- Link:
-
Preços da API Gemini: Informações detalhadas de preços por modalidade
- Link:
ai.google.dev/gemini-api/docs/pricing - Descrição: Precificação detalhada para texto, imagem, áudio e vídeo
- Link: