Nota do autor: Uma comparação profunda entre o Claude Opus 4.6 e o Sonnet 4.6 em 5 dimensões — preço, performance, contexto, codificação e cenários de aplicação — para ajudar desenvolvedores a escolherem a melhor solução de modelo.
Escolher entre o Claude Opus 4.6 ou o Sonnet 4.6 é um dilema real para muitos desenvolvedores. O Sonnet 4.6 custa apenas 60% do preço do Opus, mas o Opus possui vantagens claras em raciocínio profundo e processamento de contextos longos. Este artigo compara os dois modelos sob as perspectivas de preço, benchmarks de performance, processamento de contexto, capacidade de codificação e cenários de uso para te ajudar a tomar a melhor decisão.
Valor Principal: Ao terminar de ler, você saberá exatamente quando escolher o Opus 4.6 ou o Sonnet 4.6 para diferentes necessidades de negócio, e como reduzir ainda mais os custos de uso através de bônus de recarga.

Comparação Principal: Claude Opus 4.6 vs Sonnet 4.6
Em fevereiro de 2026, a Anthropic lançou em um intervalo de duas semanas o Claude Opus 4.6 (5 de fevereiro) e o Sonnet 4.6 (17 de fevereiro). Cada modelo tem seu foco; a tabela abaixo apresenta uma comparação direta em 5 dimensões cruciais.
| Dimensão de Comparação | Claude Opus 4.6 | Claude Sonnet 4.6 | Explicação da Diferença |
|---|---|---|---|
| Preço de Entrada | $15 / Milhão de Tokens | $3 / Milhão de Tokens | Sonnet é 80% mais barato |
| Preço de Saída | $75 / Milhão de Tokens | $15 / Milhão de Tokens | Sonnet é 80% mais barato |
| SWE-bench | 80.8% | 79.6% | Praticamente empatados |
| GPQA Diamond | 91.3% | — | Opus lidera em raciocínio científico |
| Contexto Longo (MRCR v2) | 76% | Aprox. 18.5% (dados 4.5) | Vantagem esmagadora do Opus |
Comparação Detalhada de Preços: Claude Opus 4.6 vs Sonnet 4.6
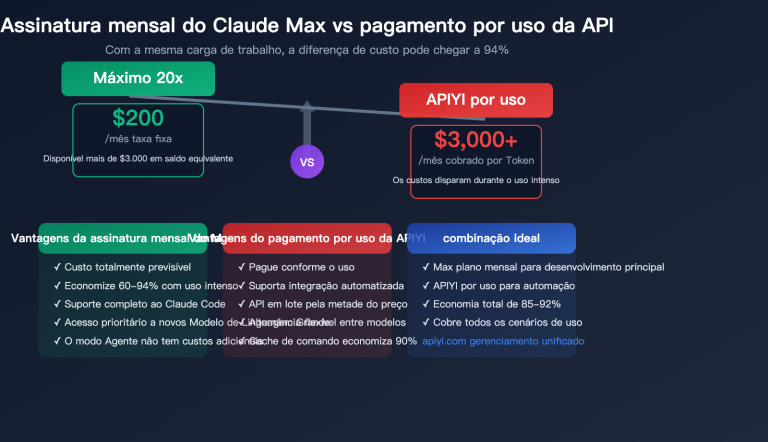
A diferença de preço é o fator mais direto na escolha de um modelo. Ambos os modelos já estão disponíveis na plataforma APIYI, com suporte a promoções de recarga.
| Item de Preço | Preço Oficial Opus 4.6 | Preço Oficial Sonnet 4.6 | Preço Promocional APIYI (aprox. 15% off) |
|---|---|---|---|
| Token de Entrada | $15 / milhão | $3 / milhão | Bônus de 10% a partir de 100 |
| Token de Saída | $75 / milhão | $15 / milhão | Quanto maior a recarga, maior o desconto |
| Contexto >200K Entrada | $30 / milhão | $6 / milhão | Mesmos benefícios de recarga |
| Batch API | 50% de desconto | 50% de desconto | Primeira escolha para tarefas em lote |
| Leitura de Cache | 0.1x preço base | 0.1x preço base | Ferramenta essencial para economizar em chamadas repetidas |
Considerando um cenário típico de chamada de API: cada requisição com cerca de 2000 Tokens de entrada + 500 Tokens de saída, repetida 1000 vezes:
- Opus 4.6: Entrada $0.03 + Saída $0.0375 = aprox. $0.068 / mil chamadas
- Sonnet 4.6: Entrada $0.006 + Saída $0.0075 = aprox. $0.014 / mil chamadas
O custo de uma única chamada do Sonnet 4.6 é de apenas cerca de 20% do Opus. Para cenários de chamadas de média e alta frequência, a diferença de custo aumenta rapidamente.
🎯 Dica de Economia: Ao recarregar a partir de 100 dólares no APIYI (apiyi.com), você ganha 10% de bônus, o que equivale a um desconto adicional sobre um preço que já é competitivo, permitindo chegar a cerca de 85% do valor oficial.
Comparativo de Benchmarks de Desempenho: Claude Opus 4.6 vs. Sonnet 4.6
O preço é apenas um lado da moeda; os benchmarks de desempenho determinam se o modelo é capaz de realizar suas tarefas. Veja abaixo como os dois modelos se saem nas principais avaliações.

| Benchmark | Opus 4.6 | Sonnet 4.6 | Interpretação |
|---|---|---|---|
| SWE-bench Verified | 80.8% | 79.6% | Capacidade de codificação quase idêntica |
| GPQA Diamond | 91.3% | — | Opus é topo de linha em raciocínio científico |
| Terminal-Bench 2.0 | 65.4% | ~56% | Opus é superior em operações de terminal |
| OSWorld Agent | 72.7% | 72.5% | Capacidade de Agente equivalente |
| Humanity's Last Exam | 40.0% | ~26% | Opus domina em raciocínio complexo |
| GDPval-AA | Lidera sobre o GPT-5.2 por cerca de 144 Elo | — | Primeiro lugar em tarefas de trabalho de conhecimento |
Principais descobertas: Em codificação rotineira (SWE-bench) e tarefas de Agentes (OSWorld), o Sonnet 4.6 já está muito próximo do Opus 4.6. No entanto, em cenários que exigem raciocínio profundo — como o Humanity's Last Exam (problemas interdisciplinares de nível universitário) e o GPQA Diamond (questões científicas de nível de pós-graduação) — o Opus 4.6 demonstra uma superioridade clara.
🎯 Sugestão de teste: Recomendamos realizar testes A/B chamando ambos os modelos simultaneamente via APIYI (apiyi.com). A plataforma suporta a troca de modelos através de uma interface unificada, permitindo comparar os resultados com apenas uma chave de API (API Key).
Diferenças de Capacidades Essenciais: Claude Opus 4.6 vs. Sonnet 4.6
Além das pontuações, existem algumas diferenças fundamentais no uso prático que valem a pena destacar.
Vantagens Exclusivas do Claude Opus 4.6
1. Pensamento Adaptativo (Adaptive Thinking)
O Opus 4.6 é o primeiro modelo da Anthropic a suportar o pensamento adaptativo. Ele ajusta automaticamente a profundidade do raciocínio com base na complexidade da tarefa, e os desenvolvedores podem controlar manualmente o equilíbrio entre qualidade, velocidade e custo através do parâmetro /effort. Respostas rápidas para perguntas simples, reflexão profunda para problemas complexos.
2. Janela de Contexto de 1 Milhão de Tokens (Beta)
O Opus 4.6 é o primeiro da família Opus a suportar um contexto de 1 milhão de tokens. No teste MRCR v2 (versão de 8 agulhas com 1 milhão de tokens), ele marcou 76%, enquanto o modelo da geração anterior atingiu apenas 18,5%. Isso significa que você pode processar de 10 a 15 artigos científicos completos ou grandes bases de código de uma só vez.
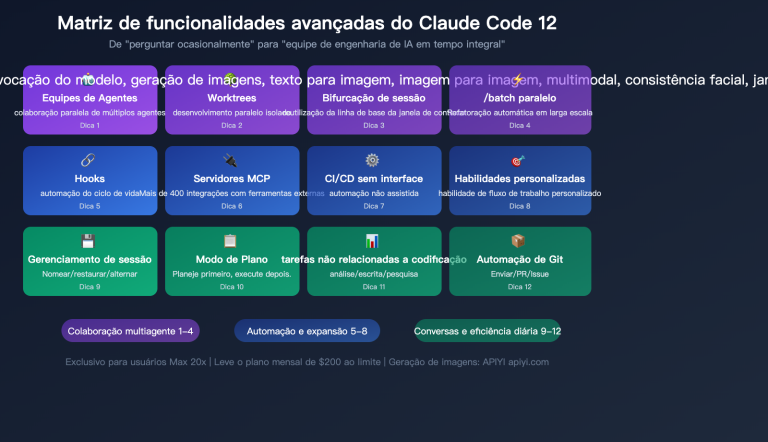
3. Capacidade de Paralelismo com Agent Teams
No Claude Code, o Opus 4.6 suporta a funcionalidade Agent Teams, permitindo o agendamento paralelo de múltiplas subtarefas. Isso traz um ganho de eficiência significativo para cenários como revisão de código e refatoração em grandes projetos.
Vantagens Principais do Claude Sonnet 4.6
1. Custo-benefício Extremo
A mesma tarefa custa apenas 20% do valor do Opus. No benchmark de codificação SWE-bench, a diferença é de apenas 1,2 ponto percentual, mas a diferença de preço é de 5 vezes. Para a maioria das tarefas diárias de codificação e chat, este é o melhor retorno sobre o investimento.
2. Velocidade de Resposta Superior
O Sonnet 4.6 é visivelmente superior ao Opus 4.6 em velocidade de inferência, sendo ideal para ambientes de produção sensíveis à latência. Recomendamos o Sonnet para processamento em lote e aplicações de interação em tempo real.
3. Líder Global em Agentes de Escritório e Finanças
O Sonnet 4.6 ocupa o primeiro lugar global em produtividade de escritório, tarefas de agentes financeiros e avaliações de chamadas de ferramentas em larga escala. Se o seu cenário foca em processamento de dados estruturados e chamadas de ferramentas (tool calling), o Sonnet 4.6 é a melhor escolha.
Recomendações de Cenários: Claude Opus 4.6 vs. Sonnet 4.6

| Cenário de Uso | Modelo Recomendado | Motivo |
|---|---|---|
| Programação diária, preenchimento de código | Sonnet 4.6 | Apenas 1.2% de diferença no SWE-bench, 80% mais barato |
| Refatoração de grandes bases de código | Opus 4.6 | Agent Teams + 1 milhão de contexto |
| Análise de artigos científicos | Opus 4.6 | GPQA 91.3% + leitura de documentos longos de uma vez |
| Geração de conteúdo em lote | Sonnet 4.6 | Batch API pela metade do preço + mais rápido |
| Chatbots de atendimento ao cliente | Sonnet 4.6 | Baixa latência, baixo custo, qualidade suficiente |
| Conformidade jurídica/financeira | Opus 4.6 | Líder global no GDPval-AA |
| Agents de automação de escritório | Sonnet 4.6 | Líder global em testes de produtividade de escritório |
| Raciocínio matemático/científico complexo | Opus 4.6 | HLE 40%, superando de longe a concorrência |
🎯 Dica de escolha: Para 80% das tarefas diárias dos desenvolvedores, o Sonnet 4.6 é mais que suficiente. Mude para o Opus 4.6 apenas quando precisar de raciocínio profundo, contexto ultra longo ou a mais alta qualidade de saída. Recomendamos ativar ambos os modelos através do APIYI (apiyi.com) para alternar de forma flexível conforme a necessidade.
Claude Opus 4.6 e Sonnet 4.6: Guia Rápido
Ambos os modelos são compatíveis com o formato do SDK da OpenAI e podem ser chamados através de uma interface unificada pela plataforma APIYI.
Exemplo Minimalista
O código a seguir demonstra como alternar entre Opus e Sonnet usando a mesma API Key:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Usando o Sonnet 4.6 para tarefas diárias (baixo custo)
response = client.chat.completions.create(
model="claude-sonnet-4-6-20260217",
messages=[{"role": "user", "content": "Ajude-me a escrever um QuickSort em Python"}]
)
print("Sonnet:", response.choices[0].message.content)
# Alternando para o Opus 4.6 para raciocínio complexo (alta qualidade)
response = client.chat.completions.create(
model="claude-opus-4-6-20260205",
messages=[{"role": "user", "content": "Analise as falhas metodológicas deste artigo..."}]
)
print("Opus:", response.choices[0].message.content)
Ver código de implementação completo (com roteamento automático de modelo)
import openai
from typing import Optional
def smart_call(
prompt: str,
complexity: str = "normal",
api_key: str = "YOUR_API_KEY"
) -> str:
"""
Seleciona automaticamente o modelo com base na complexidade da tarefa
Args:
prompt: entrada do usuário
complexity: complexidade da tarefa - simple/normal/complex
api_key: API Key
Returns:
Conteúdo da resposta do modelo
"""
client = openai.OpenAI(
api_key=api_key,
base_url="https://vip.apiyi.com/v1"
)
# Roteamento automático baseado na complexidade
model_map = {
"simple": "claude-sonnet-4-6-20260217",
"normal": "claude-sonnet-4-6-20260217",
"complex": "claude-opus-4-6-20260205"
}
model = model_map.get(complexity, "claude-sonnet-4-6-20260217")
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
max_tokens=4096
)
return response.choices[0].message.content
# Codificação diária → usa Sonnet automaticamente (economia)
result = smart_call("Escreva um exemplo de CRUD para uma REST API", complexity="normal")
# Raciocínio complexo → usa Opus automaticamente (prioridade em qualidade)
result = smart_call("Analise a complexidade de tempo deste código e otimize-o", complexity="complex")
Sugestão: Obtenha sua API Key através da APIYI (apiyi.com). Com uma única conta, você pode acessar tanto o Opus 4.6 quanto o Sonnet 4.6. A plataforma suporta o formato compatível com OpenAI, então não é necessário modificar seu código existente.
Perguntas Frequentes
Q1: A diferença de capacidade de codificação entre o Sonnet 4.6 e o Opus 4.6 é grande?
A diferença é mínima. No benchmark SWE-bench Verified, o Opus atingiu 80,8% vs 79,6% do Sonnet, uma diferença de apenas 1,2 pontos percentuais. Para a maioria das tarefas de programação, o Sonnet 4.6 é perfeitamente capaz e custa apenas 20% do Opus. O Opus só mostra uma vantagem clara em refatorações de bases de código gigantescas ou quando se utilizam Agent Teams em paralelo.
Q2: Como é o desempenho real da janela de contexto de 1 milhão de tokens do Opus 4.6?
Muito forte. No teste MRCR v2 de 8-needle com 1 milhão de tokens, ele marcou 76%, enquanto o modelo da geração anterior atingiu apenas 18,5%. Na prática, ele consegue processar de 10 a 15 artigos acadêmicos ou todo o código de um projeto de médio porte de uma só vez. Se sua tarefa envolve documentos extremamente longos, o Opus 4.6 é a melhor escolha atual. Ambos os modelos podem ser testados na APIYI (apiyi.com).
Q3: Como usar esses dois modelos na APIYI?
- Acesse apiyi.com e registre uma conta.
- Recarregue para obter créditos (ganhe 10% de bônus a partir de 100 USD).
- Obtenha sua API Key no painel de controle.
- Use
claude-opus-4-6-20260205ouclaude-sonnet-4-6-20260217como o nome do modelo. - A interface é totalmente compatível com o formato OpenAI, permitindo reutilizar seu código existente diretamente.
Resumo
Os pontos centrais da comparação entre o Claude Opus 4.6 e o Sonnet 4.6 são:
- Diferença de preço de 5 vezes: O Sonnet 4.6 custa $3/$15 por milhão de tokens, enquanto o Opus 4.6 custa $15/$75. Para 80% das tarefas diárias, o Sonnet é mais que suficiente.
- Capacidade de codificação equivalente: No benchmark SWE-bench, a diferença é de apenas 1,2%. O Sonnet 4.6 é o rei do custo-benefício para cenários de programação.
- Opus vence em raciocínio profundo: Com GPQA de 91,3%, HLE de 40% e MRCR de 76%, o Opus é insubstituível em pesquisa científica e cenários de raciocínio complexo.
- O cenário decide a escolha: Escolha o Sonnet para desenvolvimento diário e tarefas em lote; escolha o Opus para pesquisa científica, documentos longos e raciocínio complexo.
Recomendamos utilizar ambos os modelos através da APIYI (apiyi.com). Ao recarregar a partir de 100 dólares, você ganha 10% de bônus, o que permite um custo de até 85% do valor oficial. A plataforma suporta chamadas de interface unificada, permitindo alternar entre os modelos com uma única chave (API Key) conforme a necessidade, encontrando o equilíbrio ideal entre desempenho e custo.
📚 Referências
⚠️ Nota sobre o formato dos links: Todos os links externos utilizam o formato
Nome do recurso: domain.com. Eles foram formatados assim para facilitar a cópia, mas não são clicáveis, evitando a perda de autoridade de SEO.
-
Lançamento Oficial da Anthropic – Claude Opus 4.6: Principais capacidades e especificações técnicas do Opus 4.6
- Link:
anthropic.com/news/claude-opus-4-6 - Descrição: Anúncio oficial de lançamento, contendo os dados completos de benchmark.
- Link:
-
Lançamento Oficial da Anthropic – Claude Sonnet 4.6: Informações de lançamento e avaliação do Sonnet 4.6
- Link:
anthropic.com/news/claude-sonnet-4-6 - Descrição: Especificações técnicas oficiais e explicação de capacidades.
- Link:
-
Página de Preços da API do Claude: Preços oficiais atualizados da API
- Link:
platform.claude.com/docs/en/about-claude/pricing - Descrição: Tabela de preços padrão oficial da Anthropic.
- Link:
-
Análise Comparativa da VentureBeat: Análise de desempenho do Sonnet 4.6
- Link:
venturebeat.com/technology/anthropics-sonnet-4-6-matches-flagship-ai-performance-at-one-fifth-the-cost - Descrição: Perspectiva de avaliação independente de terceiros.
- Link:
Autor: Equipe Técnica
Troca de Conhecimento: Sinta-se à vontade para discutir na seção de comentários. Para mais materiais, acesse a comunidade técnica da APIYI (apiyi.com).