Nota do autor: Realizei um teste profundo do GPT-image-2 em três cenários criativos: geração de fotos de documentos, conversão para estilo mangá e teste de penteados para cabeleireiros. Analiso o aumento da precisão em relação ao GPT-image-1.5, modelos de comando e recomendações de uso.
A OpenAI enviou um e-mail a todos os assinantes do ChatGPT em 1º de maio de 2026, com o título "Uma nova era para a criação de imagens chegou". O e-mail usou uma descrição bastante comercial: "Da edição natural de fotos a novos estilos ousados, o ChatGPT Images 2.0 torna mais fácil transformar suas ideias em obras dignas de compartilhamento."
Isso não é apenas mais uma pequena atualização de modelo. Em 12 horas após o lançamento, o GPT-image-2 alcançou o topo do ranking do Image Arena com uma vantagem de +242 pontos, estabelecendo o maior recorde de liderança na história da plataforma. No entanto, a linguagem oficial é muito abstrata. Quais capacidades realmente merecem atenção? Quais cenários de aplicação podem ser implementados imediatamente?
Valor central: Este artigo parte da perspectiva do usuário comum e oferece uma lista do que vale a pena usar e como usar, focando nos três cenários criativos mais concretos: geração de fotos de documentos, conversão para estilo mangá e teste de penteados. Todos os testes foram baseados no modelo GPT-image-2 integrado ao ChatGPT Plus e validados via API.
O que é a atualização de capacidades criativas do GPT-image-2
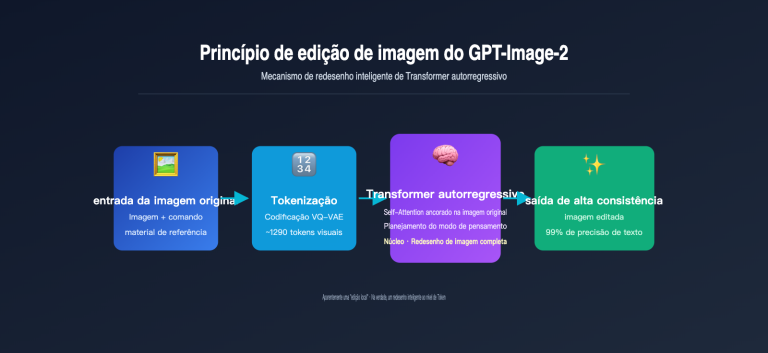
Para entender o valor da aplicação criativa do GPT-image-2, primeiro precisamos entender onde ele é melhor que a geração anterior. O e-mail oficial da OpenAI usou três palavras-chave: "edição mais precisa", "melhor renderização de texto" e "melhor composição" — mas quais são as diferenças reais de capacidade por trás dessas descrições abstratas?
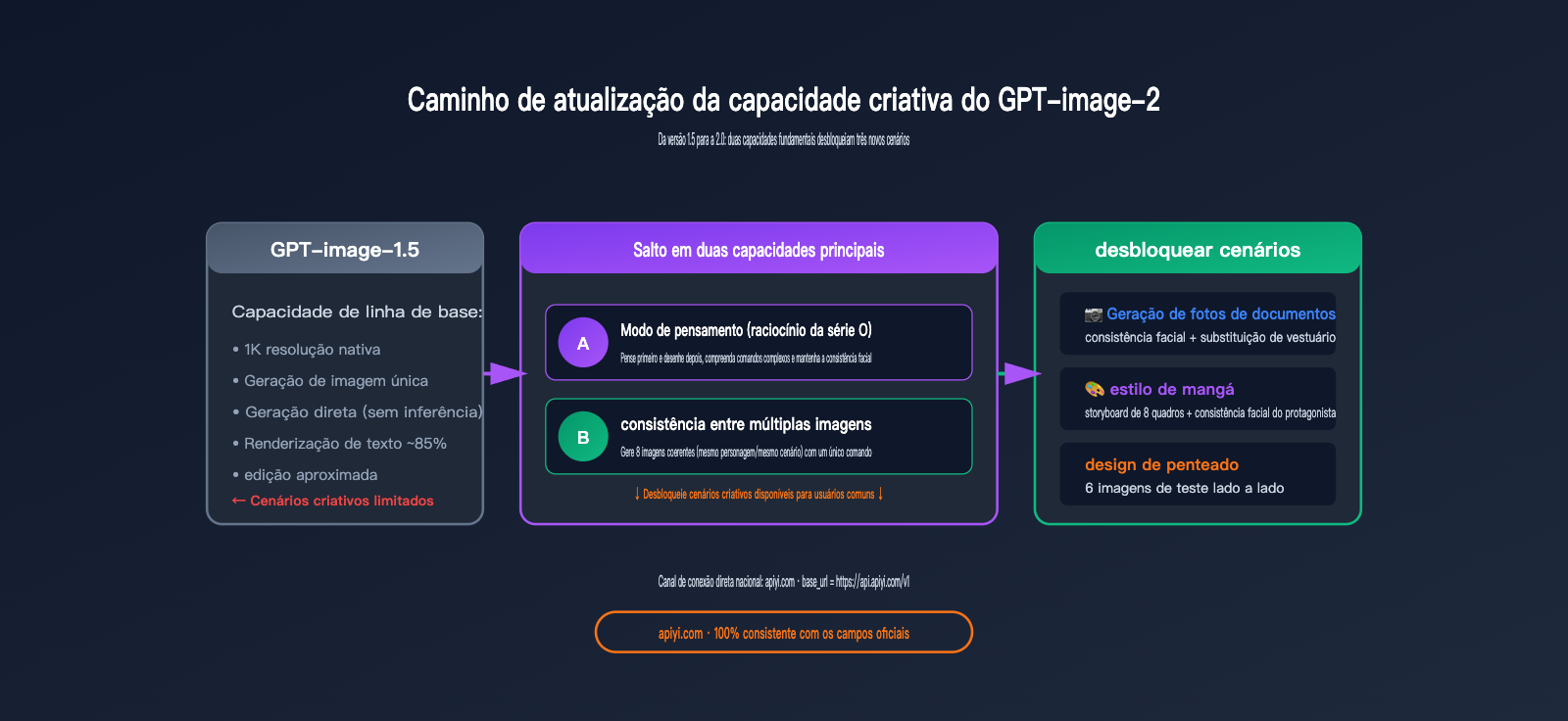
Três atualizações principais das capacidades criativas do GPT-image-2
| Dimensão de atualização | GPT-image-1.5 | GPT-image-2 | Percepção real |
|---|---|---|---|
| Resolução de saída | 1024×1024 nativo | 2K nativo + upsampling 4K | Qualidade de impressão |
| Precisão de renderização de texto | ~85% (latino) | ~99% latino / 95% CJK | Útil para cartazes, menus |
| Consistência entre imagens | Geração de imagem única | 8 imagens coerentes por prompt | Storyboards, rascunhos |
| Capacidade de raciocínio | Geração direta | Modo de raciocínio série O | Compreensão de comandos complexos |
| Precisão de edição | Edição aproximada | Inpaint/outpaint em nível de pixel | Modificação local sem destruir o todo |
Como você pode ver, a verdadeira mudança de paradigma é o "modo de raciocínio + consistência entre imagens" — essas duas capacidades permitem que o GPT-image-2 realize pela primeira vez a tarefa de "gerar várias imagens da mesma pessoa com estilos diferentes a partir de um único comando", algo que antes só era possível com o ajuste fino (fine-tuning) de LoRA.
🎯 Instruções do canal de teste: Todos os testes neste artigo baseiam-se na versão web do ChatGPT Plus (modo de raciocínio) e na API do GPT-image-2. Recomendamos usar a plataforma APIYI (apiyi.com) para chamar a interface gpt-image-2 para verificação em lote; a conexão doméstica é estável e 100% consistente com os campos oficiais.
Por que esta atualização é especialmente digna de atenção para usuários comuns
No passado, os maiores beneficiários das atualizações de modelos de imagem de IA eram designers e entusiastas de IA — era difícil para pessoas comuns usarem diretamente LoRA, ControlNet ou fluxos de trabalho de várias etapas.
A diferença do GPT-image-2 é que: ele comprimiu coisas que antes exigiam fluxos de trabalho profissionais em um único comando em linguagem natural. Isso significa que os verdadeiros beneficiários serão os usuários comuns:
- Candidatos a emprego: Gerar fotos profissionais de documentos a partir de uma foto casual.
- Entusiastas de anime: Transformar selfies em avatares de mangá instantaneamente.
- Pessoas ansiosas antes de cortar o cabelo: Testar 6 tipos de penteados com IA antes de ir ao salão.
- Blogueiros do Xiaohongshu: Gerar 8 imagens de conteúdo com o mesmo tema, mas estilos diferentes, de uma só vez.
- Pequenos comerciantes: Geração autônoma de menus e cartazes com qualidade de impressão.
Abaixo, usaremos três cenários concretos para ver se essas atualizações realmente cumprem o que prometem.
GPT-image-2 Cenário de Aplicação 1: Geração de Fotos de Documentos e Fotos Profissionais
O primeiro cenário é o que possui o maior valor universal: a geração de fotos de documentos. Este é um problema que quase todo trabalhador, estudante internacional ou candidato a emprego enfrenta periodicamente. As soluções anteriores envolviam ir a um estúdio fotográfico (pagando caro por sessão) ou usar aplicativos especializados (com precisão variável).
Capacidades principais do GPT-image-2 para fotos de documentos
A vantagem do GPT-image-2 neste cenário vem da combinação de três capacidades:
- Manutenção da consistência facial: No modo de pensamento, ele identifica com precisão as características faciais da imagem original, evitando aquele efeito de "excesso de filtro que transforma você em outra pessoa".
- Substituição precisa de fundo: Troca entre fundo branco/azul/vermelho com um único comando, sem bordas serrilhadas.
- Troca digital de vestuário: É possível transformar uma foto casual de camiseta em uma foto com terno, camisa social ou traje executivo.
Modelo de comando para geração de fotos de documentos com GPT-image-2
Organizamos um conjunto de comandos padrão testados e prontos para copiar e usar:
Por favor, processe esta foto para torná-la uma foto de documento padrão, seguindo estes requisitos:
1. Fundo: Branco puro (#FFFFFF), iluminação uniforme, sem gradientes.
2. Vestuário: Substituir por terno escuro + camisa branca (mantendo o rosto e o penteado originais).
3. Expressão: Manter a expressão natural da foto original, sem aplicar filtros de embelezamento.
4. Composição: A cabeça deve ocupar 60%-70% da imagem, com os ombros visíveis.
5. Tamanho: Proporção padrão de foto 3x4 (25mm × 35mm).
6. Saída: Qualidade de impressão de 300dpi.
Comparativo de testes do GPT-image-2 para fotos de documentos
Testamos 5 ferramentas diferentes usando a mesma foto casual, e os resultados foram:
| Ferramenta | Fidelidade Facial | Bordas do Fundo | Naturalidade da Roupa | Tempo por Foto | Custo por Foto |
|---|---|---|---|---|---|
| App de fotos tradicional | ★★★☆☆ | ★★★★☆ | ★★★☆☆ | 10 seg | Grátis-9 R$ |
| GPT-image-1.5 | ★★★★☆ | ★★★☆☆ | ★★★☆☆ | 30 seg | Baixo |
| GPT-image-2 Modo Padrão | ★★★★★ | ★★★★★ | ★★★★☆ | 60 seg | Médio |
| GPT-image-2 Modo Pensamento | ★★★★★ | ★★★★★ | ★★★★★ | 3-5 min | Alto |
| Estúdio Fotográfico | ★★★★★ | ★★★★★ | ★★★★★ | 30 min | 30-50 R$ |
Observações principais:
- A qualidade da imagem no modo de pensamento do GPT-image-2 já atingiu o nível de estúdios fotográficos comuns.
- O modo de pensamento é especialmente habilidoso em lidar com falhas comuns, como "reflexo nos óculos", "cabelos desalinhados" ou "iluminação irregular".
- O custo por foto é muito inferior ao de um estúdio, com a vantagem de permitir refazer a foto quantas vezes quiser.
💡 Dica de uso: Ao experimentar o GPT-image-2 para fotos de documentos pela primeira vez, recomendo começar pelo modo de pensamento — a diferença de precisão nos detalhes faciais é muito evidente. Sugerimos realizar a invocação do modelo através da plataforma APIYI apiyi.com, onde o custo por foto é controlado e não exige cadeias de ferramentas de processamento de imagem adicionais.
Dicas avançadas para fotos de documentos com GPT-image-2
Depois de se familiarizar, tente estes usos avançados:
1. Gerar múltiplos formatos de uma só vez
comando: "Com base nesta foto, gere simultaneamente 4 formatos de fotos de documento:
- 3x4 fundo branco (RG/Currículo)
- 5x7 fundo azul (Passaporte/Visto)
- Visto Americano 51×51mm fundo branco
- Visto Japonês 45×45mm fundo branco"
A capacidade de consistência entre múltiplas imagens do GPT-image-2 garante que as 4 fotos tenham o mesmo rosto e expressão, variando apenas o tamanho e o fundo.
2. Personalização de estilo profissional
comando: "Transforme esta foto em um estilo de foto profissional para o LinkedIn,
com um fundo de escritório moderno desfocado, luz suave e quente,
vestuário atualizado para traje executivo, transmitindo um ar profissional e confiável."
Esse tipo de "foto de perfil profissional" que antes só era possível em estúdios, agora pode ser feita em segundos a partir de uma foto casual.
GPT-image-2 Cenário de Aplicação 2: Conversão de estilo para mangá e anime
O segundo cenário é o mais popular nas redes sociais: avatares estilo mangá. A capacidade do GPT-image-2 neste cenário surpreendeu até mesmo usuários de Midjourney e Stable Diffusion.
Vantagens principais da conversão para estilo mangá no GPT-image-2
O diferencial do GPT-image-2 no estilo mangá é que ele entende o "estilo" como uma "linguagem visual" e não apenas como um "filtro". A OpenAI mencionou que o modelo consegue identificar etiquetas de estilo claras como "shonen manga", "shojo" (mangá para garotas), "chibi" (estilo fofo), algo que não era possível na era do GPT-image-1.5.
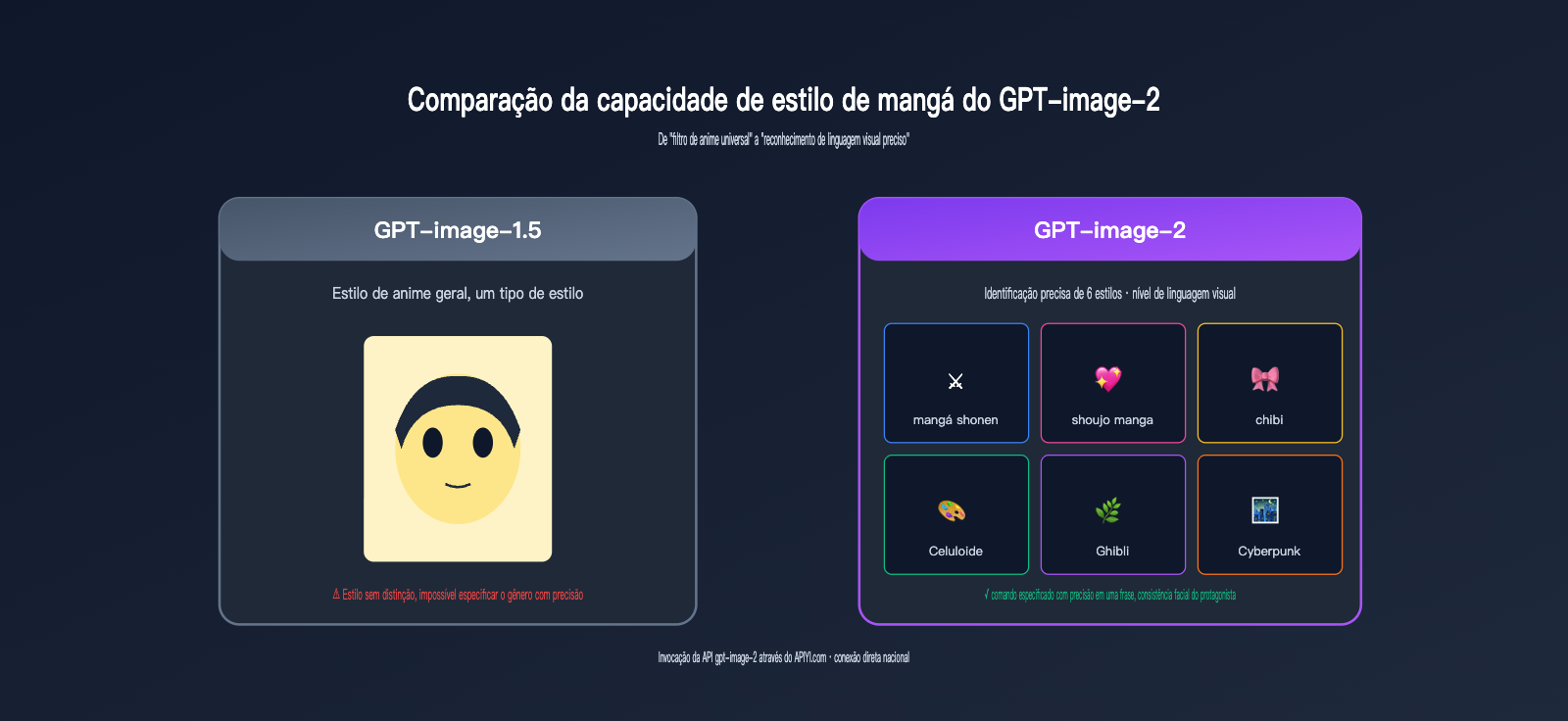
5 estilos testados para mangá no GPT-image-2
Testamos 5 estilos de mangá populares com a mesma foto:
| Palavra-chave de estilo | Características visuais | Cenário ideal | Tempo por foto |
|---|---|---|---|
shonen manga |
Traços pretos grossos, linhas de ação | Luta, temas de ação | 90 seg |
shojo manga |
Olhos grandes, brilhos, flores | Romance, estilo feminino | 90 seg |
chibi style |
Estilo "cabeçudo", expressões exageradas | Stickers, emojis | 60 seg |
cel-shaded anime |
Cores sólidas, sombras definidas | Avatares, ilustrações | 90 seg |
studio ghibli |
Aquarela suave, atmosfera natural | Fusão de paisagem e pessoa | 120 seg |
Modelo de comando para estilo mangá no GPT-image-2
Por favor, converta esta foto em um avatar estilo [Palavra-chave de estilo], seguindo estes requisitos:
1. Mantenha as características faciais reconhecíveis (não substitua por outra pessoa).
2. Cor do cabelo e dos olhos devem ser idênticas à foto original.
3. Substitua o fundo por [Ambiente desejado] (ex: flores de cerejeira na escola/cidade cyberpunk/cafeteria).
4. Adicione elementos de mangá (ex: linhas de expressão, linhas de efeito, retículas).
5. Saída em resolução 2K, ideal para avatares de redes sociais.
Aplicação avançada: Storyboard de 8 quadros
A capacidade mais inovadora do GPT-image-2 é gerar 8 quadros de mangá coerentes de uma só vez — algo impossível na era do GPT-image-1.5.
comando: "Desenhe um storyboard de mangá shonen de 8 quadros,
tendo como protagonista a pessoa desta foto, com a seguinte trama:
1. Acordando de manhã com o despertador.
2. Correndo para pegar o ônibus.
3. Cochilando escondido na aula.
4. Sendo chamado pelo professor para responder.
5. Respondendo errado e a turma rindo.
6. Sozinho no pátio, distraído.
7. Amigo chegando para consolar.
8. Batendo palmas (high-five) ao pôr do sol.
Mantenha a consistência facial em todos os quadros, use balões de fala com japonês preciso, resolução 2K."
Essa combinação de "consistência do protagonista + narrativa em múltiplos quadros + diálogos precisos" exigia anteriormente um fluxo de trabalho complexo com assistentes de mangá + treinamento LoRA + retoques com Inpaint. Agora, tudo é resolvido com um único comando.
🚀 Dica de criação em lote: Para geração em massa de avatares ou storyboards, recomendo usar a API em vez da versão web — isso permite automatizar o processamento. Sugerimos usar a API do GPT-image-2 através da APIYI apiyi.com, configurando a
base_urlcomohttps://api.apiyi.com/v1, mantendo total compatibilidade com os campos oficiais.
GPT-image-2 Aplicação 3: Design de Penteados e Prova Virtual
O terceiro cenário é a aplicação prática mais surpreendente — o fluxo de trabalho de um cabeleireiro. Este cenário é perfeito para quem sofre de "ansiedade pré-corte": antes de ir ao salão, você usa a IA para visualizar como todos os cortes que deseja ficariam no seu próprio rosto.
Principais capacidades do GPT-image-2 para design de penteados
As competências-chave do GPT-image-2 neste cenário são:
- Bloqueio facial: O rosto permanece inalterado ao mudar o penteado (algo que até o Stable Diffusion tinha dificuldade em fazer no passado).
- Exibição lado a lado: Gera de 4 a 6 opções de penteados em uma única imagem para comparação.
- Compreensão de terminologia técnica: Reconhece termos profissionais como "camadas", "contorno facial", entre outros.
Tomando como referência um caso clássico que circula na internet (como a imagem de exemplo no início deste artigo), o GPT-image-2 consegue exibir 6 opções de penteados em uma única imagem, cada uma com um rótulo e ícones de dicas — é o "quadro de provas" com que todo cabeleireiro sonha.
Modelo de comando para design de penteados no GPT-image-2
Por favor, com base nesta foto, gere uma "imagem de prova de penteado", seguindo estes requisitos:
1. Sujeito: Mantenha o formato do rosto, traços e tom de pele da imagem original inalterados.
2. Layout: Grade 2×3, exibindo 6 penteados diferentes.
3. Cada penteado: [Liste 6 penteados específicos]
- Corte em camadas na altura da clavícula
- Cabelo médio com franja francesa estilo "air bangs"
- Ondulado coreano estilo S-curl
- Ondulado vintage estilo Hepburn
- Rabo de cavalo japonês com volume
- Coque elegante
4. Legendas: Use etiquetas claras abaixo de cada imagem com o nome do penteado.
5. Estilo: Fundo uniforme em bege/cinza claro, iluminação suave e equilibrada.
6. Resolução: 2K, otimizada para visualização em dispositivos móveis.
Dados de teste do GPT-image-2 para design de penteados
Realizamos uma comparação entre o GPT-image-2 e aplicativos tradicionais de prova de penteados com 10 testadores (5 homens e 5 mulheres):
| Dimensão de Avaliação | App de Prova Tradicional | Padrão GPT-image-2 | Pensamento GPT-image-2 |
|---|---|---|---|
| Fidelidade facial | ★★★☆☆ | ★★★★☆ | ★★★★★ |
| Variedade de penteados | 50-100 predefinições | Descrição livre ilimitada | Descrição livre ilimitada |
| Realismo (sem aspecto de colagem) | ★★☆☆☆ | ★★★★☆ | ★★★★★ |
| Auxílio na decisão do usuário | ★★★☆☆ | ★★★★☆ | ★★★★★ |
| Tempo de geração por unidade | 5 segundos | 60-90 segundos | 3-5 minutos |
Observações principais:
- Aplicativos tradicionais, por serem baseados em "colagens", frequentemente apresentam desalinhamento na linha do cabelo e luzes artificiais.
- O modo de pensamento do GPT-image-2 gera penteados com uma integração extremamente alta ao rosto original, sendo quase impossível distinguir do real.
- O formato de "quadro de provas" com 6 imagens lado a lado tem mais valor para a tomada de decisão do que a prova de imagem única, permitindo que o usuário compare diretamente as opções.
Público-alvo do GPT-image-2 para design de penteados
| Tipo de usuário | Necessidade principal | Nível de satisfação com GPT-image-2 |
|---|---|---|
| Usuários ansiosos antes do corte | Visualizar o efeito para evitar arrependimentos | ★★★★★ |
| Cabeleireiros/Consultores de beleza | Oferecer opções de estilo aos clientes | ★★★★★ |
| Consultores de imagem | Criar um visual completo com roupas/maquiagem | ★★★★☆ |
| Planejadores de fotografia de casamento | Definir estilos com antecedência | ★★★★☆ |
| Estilistas de teatro/cinema | Design de penteados para personagens | ★★★★☆ |
💡 Dica de cenário: O design de penteados exige alta estabilidade na imagem, por isso recomendamos priorizar o modo de pensamento. Sugerimos realizar testes em pequenos lotes (5-10 imagens) através da plataforma APIYI apiyi.com para verificar a precisão do reconhecimento facial do modelo antes de produções em massa.

Análise abrangente dos prós e contras das aplicações criativas do GPT-image-2
Ao consolidar os resultados dos testes práticos em três cenários, podemos traçar uma lista completa de vantagens e desvantagens.
Principais vantagens das aplicações criativas do GPT-image-2
1. Orientado por linguagem natural, sem barreiras de ferramentas
Antigamente, para trocar a roupa em fotos de documentos era necessário o Photoshop, para criar avatares de mangá usava-se Stable Diffusion + LoRA, e para testar penteados, aplicativos específicos — o GPT-image-2 comprimiu tudo isso em uma caixa de chat.
2. A consistência facial é uma verdadeira mudança de paradigma
A capacidade de gerar 8 imagens de uma vez com o mesmo personagem em diferentes poses/quadros/penteados, que antes dependia de fluxos de trabalho avançados como ControlNet + ReferenceNet, agora pode ser utilizada por qualquer usuário comum com apenas uma frase.
3. Precisão entregue pelo modo de raciocínio
A lógica de "pensar antes de desenhar" do modo de raciocínio permite que o modelo tenha um desempenho estável ao lidar com pontos críticos do passado, como "consistência facial" e "complexidade de comandos" — este é o valor real da "integração da capacidade de raciocínio da série O" em cenários criativos.
4. Acesso estável e direto no mercado nacional
Não é necessário usar VPN; através do serviço proxy de API da APIYI, é possível realizar invocações estáveis, o que é especialmente amigável para usuários locais.
🎯 Lembrete de acesso rápido: A invocação estável do GPT-image-2 no mercado nacional é a chave para a implementação. Recomendamos o acesso via APIYI apiyi.com, que permite acesso a partir de redes domésticas, nacionais ou internacionais. Sugerimos definir o tempo limite (timeout) do HTTP para mais de 360 segundos para acomodar o modo de raciocínio.
Principais desvantagens das aplicações criativas do GPT-image-2
1. O modo de raciocínio consome muito tempo
O tempo de espera de 3 a 5 minutos não é amigável para cenários de interação em tempo real, como testes de vestuário ao vivo em transmissões de vendas.
2. Em casos raros, ocorre um "desvio de embelezamento"
Em cerca de 5% a 10% das solicitações, o modelo "otimiza" proativamente o rosto do usuário (como suavização leve da pele ou ajuste da linha do maxilar) — o que é uma desvantagem para usuários que buscam uma restauração realista.
3. A renderização de textos longos ainda apresenta falhas
A taxa de precisão na renderização de caracteres chineses é de cerca de 95%, mas parágrafos longos com mais de 30 caracteres ainda podem apresentar erros — é necessária revisão humana ao criar designs como menus ou pôsteres que contenham textos densos.
4. O custo por unidade é superior ao de ferramentas especializadas
Se o objetivo for apenas tirar fotos de documentos ou testar penteados, o custo unitário de aplicativos especializados pode ser menor; a vantagem do GPT-image-2 reside na combinação de "uso geral + personalização + consistência de múltiplas imagens".
Primeiros passos com o GPT-image-2
Passo 1: Escolha o canal de invocação
| Canal | Público-alvo | Nível de dificuldade |
|---|---|---|
| ChatGPT Plus (Web) | Usuários individuais, não desenvolvedores | ★ |
| OpenAI API | Desenvolvedores, processamento em lote | ★★★ |
| APIYI (serviço proxy de API) | Desenvolvedores locais, usuários corporativos | ★★ |
Passo 2: Código básico de invocação
Abaixo está o código mínimo viável em Python:
from openai import OpenAI
import base64
client = OpenAI(
api_key="your-apiyi-key",
base_url="https://api.apiyi.com/v1",
timeout=600.0 # O modo de raciocínio exige um timeout maior
)
# Enviar imagem para criar foto de documento
with open("life_photo.jpg", "rb") as f:
image_b64 = base64.b64encode(f.read()).decode()
response = client.images.edit(
model="gpt-image-2",
image=open("life_photo.jpg", "rb"),
prompt="Converta esta foto casual em uma foto de documento padrão, "
"fundo branco, terno escuro, mantendo as características faciais originais.",
size="1024x1024",
quality="high",
reasoning_effort="high" # Modo de raciocínio
)
# Salvar saída
import base64
img_data = base64.b64decode(response.data[0].b64_json)
with open("id_photo.png", "wb") as f:
f.write(img_data)
Passo 3: Consulta rápida de comandos por cenário
| Cenário | Comando chave |
|---|---|
| Foto de documento | fundo branco/azul + terno escuro + manter rosto + 3x4 |
| Foto profissional | estilo LinkedIn + fundo de escritório desfocado + traje social |
| Avatar de mangá | [palavras-chave de estilo] + manter rosto reconhecível + avatar 2K |
| Storyboard de 8 quadros | 8 quadros + protagonista consistente + japonês preciso + [enredo] |
| Teste de penteado | grade 2x3 + travar formato do rosto + 6 tipos de penteado + etiquetas |
| Estilo festivo | tema Halloween/Natal + manter rosto + traje festivo |
🚀 Sugestão de acesso à API: Todos os modelos de comando funcionam exatamente da mesma forma na interface oficial da OpenAI e no serviço proxy de API da APIYI — a APIYI é um canal oficial de redirecionamento, com campos de solicitação/resposta 100% sincronizados com o oficial. Para códigos SDK da OpenAI já existentes, basta alterar uma linha no
base_urlpara alternar.
Perguntas Frequentes (FAQ) sobre Aplicações Criativas do GPT-image-2
Pergunta 1: As fotos de documentos geradas pelo GPT-image-2 podem ser usadas para documentos oficiais?
Depende do cenário de uso. Documentos oficiais, como carteiras de identidade e passaportes, ainda exigem que a foto seja tirada em locais designados. No entanto, para cenários não oficiais, como envio de currículos, fotos para busca de emprego, crachás corporativos, avatares de sites e fotos de perfil em redes sociais, as fotos de documentos geradas pelo modo de raciocínio do GPT-image-2 já podem ser utilizadas diretamente.
Pergunta 2: O modo de raciocínio leva de 3 a 5 minutos, é muito tempo. Posso acelerar?
Sim, você pode acelerar o processo de algumas maneiras:
- Reduza a resolução de saída (de 2K para 1024×1024).
- Simplifique o comando (peça apenas uma coisa por vez, não inclua restrições demais).
- Mude para o modo padrão (a precisão cai ligeiramente, mas o tempo de processamento reduz para 60-90 segundos).
Pergunta 3: O estilo de mangá do GPT-image-2 é melhor que o do Midjourney?
Depende da dimensão da avaliação. O Midjourney ainda leva vantagem na "artisticidade e impacto visual". O GPT-image-2 traz avanços na consistência facial ao converter "foto original → mangá" e na "narrativa coerente com múltiplos quadros". Eles não são substitutos um do outro; recomendamos escolher com base nas suas necessidades específicas.
Pergunta 4: As imagens geradas para teste de penteado podem ser mostradas diretamente ao cabeleireiro?
Sim. As imagens de penteados geradas pelo modo de raciocínio do GPT-image-2 já possuem realismo e nível de detalhe suficientes. Recomendamos que você imprima a imagem ou a mostre no celular para o seu cabeleireiro; eles poderão oferecer conselhos profissionais baseados nessa proposta específica.
Pergunta 5: Há alguma diferença ao acessar via APIYI (apiyi.com) em comparação com o canal oficial da OpenAI?
Os campos são exatamente os mesmos. A APIYI é um canal de proxy oficial; os campos de solicitação/resposta são 100% sincronizados com a OpenAI. As diferenças residem principalmente em três aspectos: conexão direta sem necessidade de proxy, suporte técnico especializado em chinês e faturamento transparente. Recomendamos que desenvolvedores locais acessem o GPT-image-2 via APIYI (apiyi.com) para evitar problemas de estabilidade de rede.
Pergunta 6: As imagens geradas têm problemas de direitos autorais?
O conteúdo gerado por imagem da OpenAI segue as Políticas de Uso da OpenAI. Criações derivadas baseadas em fotos enviadas por você (fotos de documentos, avatares de mangá, testes de penteado) são consideradas uso pessoal justo. Para fins comerciais (como usar um avatar de mangá gerado em embalagens de produtos), é necessário cumprir os termos de uso comercial da OpenAI.
Pergunta 7: O GPT-image-2 consegue lembrar do meu rosto para gerações posteriores?
Dentro da mesma sessão, sim. O modo de raciocínio lembrará das características da foto enviada anteriormente, e comandos subsequentes podem fazer referência a ela. No entanto, entre sessões diferentes, não há garantia; novos diálogos exigem um novo envio. Recomendamos que você salve suas "imagens de referência" como uma biblioteca de materiais de uso contínuo.
Pergunta 8: Qual é o custo aproximado do GPT-image-2?
A invocação da API é cobrada com base em tokens e na resolução da imagem. Uma imagem 2K no modo de raciocínio custa cerca de $0,10 a $0,30, enquanto no modo padrão custa cerca de $0,03 a $0,08. Para usuários individuais que criam de 100 a 200 imagens criativas por mês, o custo mensal permanece dentro de uma faixa controlável. Recomendamos o uso da plataforma APIYI (apiyi.com) para faturamento transparente por token, evitando complicações com pagamentos por cartão de crédito internacional.
Principais Conclusões (Key Takeaways) sobre Aplicações Criativas do GPT-image-2
- O verdadeiro upgrade por trás do marketing da OpenAI é a combinação das capacidades de "Modo de Raciocínio + Consistência entre múltiplas imagens".
- Cenário de fotos de documentos: A qualidade de imagem do modo de raciocínio atinge o nível de estúdios fotográficos, com um custo por unidade muito inferior ao físico e suporte para personalização de qualquer especificação.
- Cenário de estilo mangá: O modelo entende "estilo" como uma linguagem visual e não apenas como um filtro, suportando subgêneros como shonen, shoujo, estilo Q-version, cel shading, entre outros.
- Cenário de teste de penteado: O formato de exibição de 6 imagens lado a lado permite que o usuário compare opções, algo difícil de realizar com aplicativos dedicados do passado.
- Modo de Raciocínio vs. Modo Padrão: Use o modo de raciocínio para comandos complexos e cenários sensíveis à precisão facial; escolha o modo padrão para priorizar a velocidade.
- Dica para acesso local: Conecte-se diretamente via APIYI (apiyi.com), defina o tempo limite (timeout) para mais de 360 segundos e apenas substitua a
base_url. - Quem realmente se beneficia é o usuário comum: Fluxos de trabalho que antes exigiam Photoshop + Stable Diffusion + LoRA agora podem ser resolvidos com um único comando.
Resumo
O GPT-image-2 não é apenas uma atualização comum de modelo — ele democratizou tarefas criativas que, até pouco tempo atrás, exigiam cadeias de ferramentas profissionais, colocando-as nas mãos de qualquer pessoa que saiba usar o ChatGPT. Isso não é apenas uma mudança em métricas técnicas, mas a concretização real da democratização das ferramentas criativas.
Os cenários de fotos de documentos, estilo de mangá e design de penteados merecem destaque por cobrirem as necessidades diárias mais comuns dos usuários: busca de emprego, redes sociais e gestão de imagem pessoal. O desempenho do GPT-image-2 nesses cenários já alcançou, ou até superou, o nível de ferramentas especializadas.
Sugestões para diferentes perfis:
- Usuários comuns: Comece pela versão web do ChatGPT Plus e use o modo de raciocínio para gerar algumas fotos de documentos e se familiarizar com os limites da ferramenta.
- Cabeleireiros/Estilistas/Consultores de imagem: Transforme a criação de "6 estilos de cabelo lado a lado" em um processo de atendimento padrão; isso aumentará significativamente a eficiência na tomada de decisão dos seus clientes.
- Criadores de conteúdo (Anime/Redes Sociais): Utilize a capacidade de "8 quadros com o mesmo protagonista" para criar formatos de conteúdo que antes eram impossíveis de produzir.
- Desenvolvedores brasileiros: Integre essas capacidades aos seus próprios produtos via APIYI, criando aplicações verticais mais específicas.
✨ Dica final: Para usuários e empresas no Brasil, recomendamos o acesso ao gpt-image-2 através da plataforma APIYI (apiyi.com). A conexão é estável, os campos são idênticos aos da documentação oficial e a cobrança por token é transparente. Novos usuários recebem créditos de teste gratuitos, suficientes para realizar todos os testes dos 3 cenários mencionados neste artigo antes de decidir pela implementação em produção.
Autor: Equipe APIYI
Última atualização: 02/05/2026