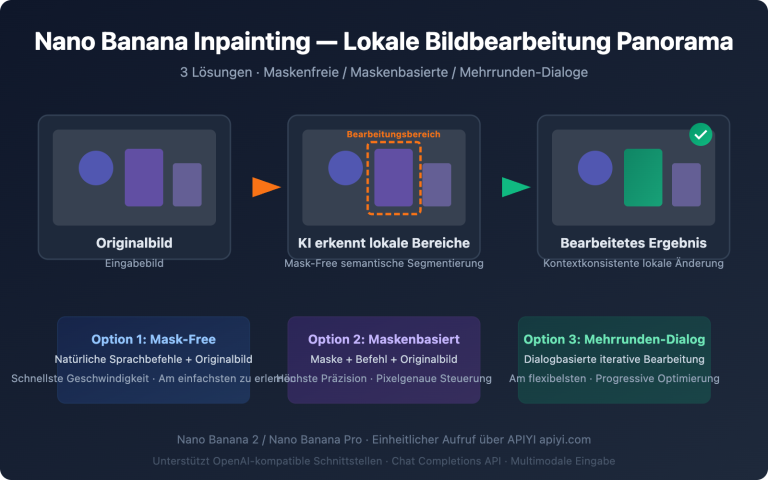
Anmerkung des Autors: Tiefgehende Praxistests von GPT-image-2 in drei kreativen Szenarien: Erstellung von Passfotos, Umwandlung in Comic-Stil und Frisuren-Simulation für Hairstylisten. Wir vergleichen die Präzisionssteigerung gegenüber GPT-image-1.5 sowie Vorlagen für Eingabeaufforderungen und Empfehlungen für die Zielgruppe.
Am 1. Mai 2026 verschickte OpenAI eine E-Mail an alle ChatGPT-Abonnenten mit dem Betreff „Eine neue Ära der Bildgestaltung ist angebrochen“. Die E-Mail war in sehr werblichem Ton gehalten: "Von natürlicher Fotobearbeitung bis hin zu gewagten neuen Stilen – ChatGPT Images 2.0 macht es dir leichter, deine kreativen Ideen in teilenswerte Werke zu verwandeln."
Das ist kein bloßes kleines Modell-Update. Innerhalb von 12 Stunden nach der Veröffentlichung stürmte GPT-image-2 mit einem Vorsprung von +242 Punkten an die Spitze der Image Arena-Rangliste und stellte damit den bisher größten Vorsprung in der Geschichte dieser Rangliste auf. Doch die offizielle E-Mail war zu abstrakt. Welche Fähigkeiten sind wirklich beachtenswert? Welche Anwendungsszenarien lassen sich sofort umsetzen?
Kernnutzen: Dieser Artikel betrachtet die Neuerungen aus der Sicht eines normalen Nutzers. Anhand der drei konkreten kreativen Szenarien – Passfoto-Erstellung, Comic-Stil-Umwandlung und Frisuren-Simulation – erhalten Sie eine Liste der Funktionen, die sich wirklich lohnen und wie man sie einsetzt. Alle Tests basieren auf dem in ChatGPT Plus integrierten GPT-image-2-Modell und wurden zusätzlich via API verifiziert.
Was ist das Upgrade der kreativen Fähigkeiten von GPT-image-2?
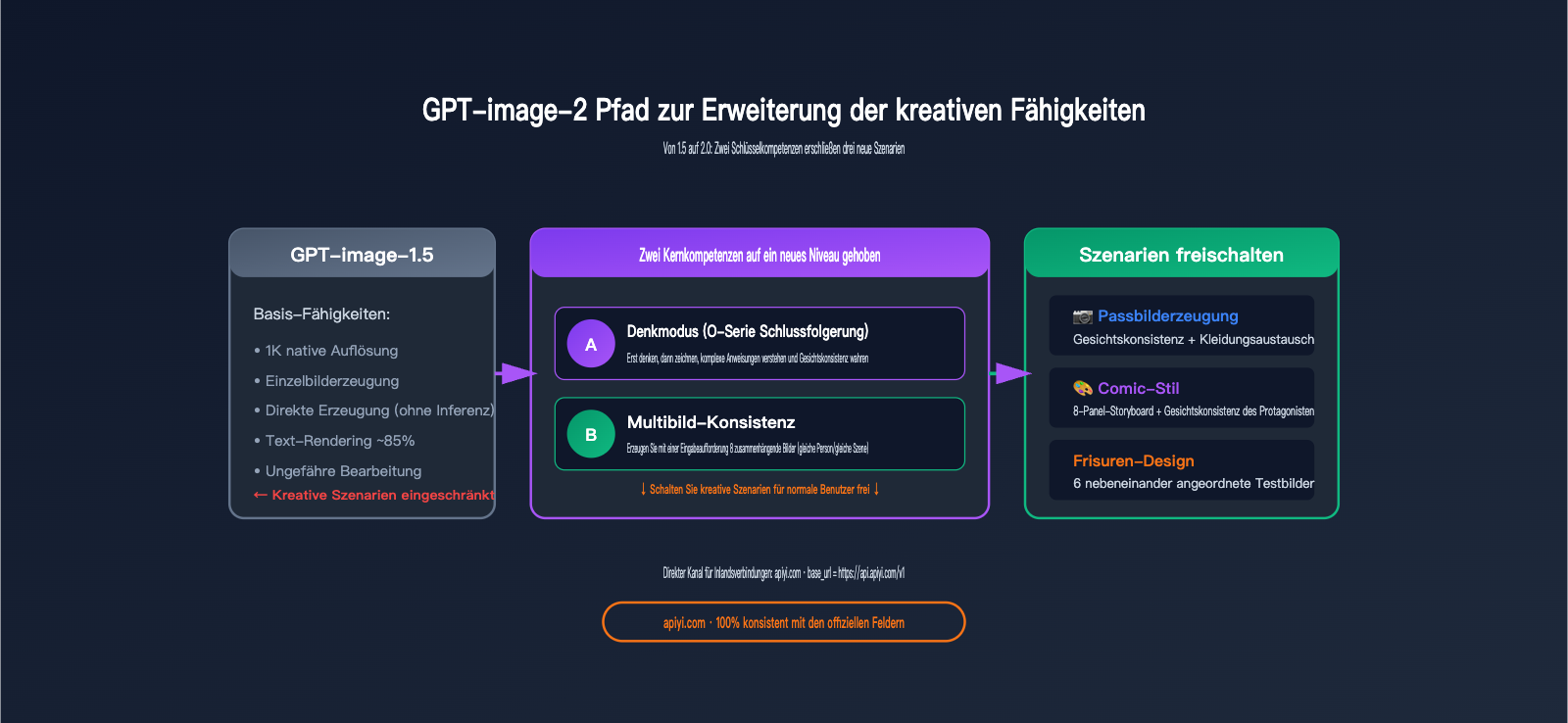
Um den kreativen Anwendungswert von GPT-image-2 zu verstehen, muss man zunächst klären, worin es sich von der Vorgängergeneration unterscheidet. Die offizielle E-Mail von OpenAI verwendete drei Schlüsselbegriffe: „präzisere Bearbeitung“, „bessere Textwiedergabe“, „bessere Komposition“ – aber was sind die tatsächlichen Fähigkeitsunterschiede hinter diesen abstrakten Beschreibungen?
Drei Kern-Upgrades der kreativen Fähigkeiten von GPT-image-2
| Upgrade-Dimension | GPT-image-1.5 | GPT-image-2 | Wahrnehmung in der Praxis |
|---|---|---|---|
| Ausgabeauflösung | 1024×1024 nativ | 2K nativ + 4K Upsampling | Druckqualität |
| Genauigkeit Textwiedergabe | ~85% (Lateinisch) | ~99% Lateinisch / 95% CJK | Für Poster, Menüs nutzbar |
| Konsistenz bei mehreren Bildern | Einzelbild-Generierung | 8 konsistente Bilder pro Prompt | Storyboards, Entwürfe |
| Schlussfolgerungsfähigkeit | Direkte Generierung | O-Serie Denkmodus | Verständnis komplexer Befehle |
| Bearbeitungspräzision | Grobe Bearbeitung | Pixelgenaues Inpaint/Outpaint | Teiländerungen ohne Gesamtstörung |
Man sieht, dass der echte Paradigmenwechsel im „Denkmodus + Konsistenz bei mehreren Bildern“ liegt – diese beiden Fähigkeiten ermöglichen es GPT-image-2 erstmals, Aufgaben wie „Ausgabe mehrerer Bilder derselben Person mit unterschiedlichen Stilen durch einen einzigen Prompt“ zu erledigen, was früher nur durch LoRA-Feinabstimmung möglich war.
🎯 Hinweis zum Testzugang: Alle Tests in diesem Artikel basieren auf der ChatGPT Plus Web-Version (Denkmodus) und der GPT-image-2 API. Wir empfehlen, die gpt-image-2-Schnittstelle über die APIYI-Plattform (apiyi.com) für Batch-Validierungen aufzurufen. Die Verbindung aus China ist stabil und die Felder sind zu 100 % mit denen des Originals identisch.
Warum dieses Upgrade für normale Nutzer besonders beachtenswert ist
In der Vergangenheit profitierten von Upgrades bei KI-Bildmodellen meist Designer und KI-Enthusiasten – für normale Menschen war es schwierig, LoRA, ControlNet oder mehrstufige Workflows direkt zu nutzen.
Das Besondere an GPT-image-2 ist: Es komprimiert Dinge, die früher professionelle Workflows erforderten, in einen einzigen Prompt in natürlicher Sprache. Das bedeutet, dass normale Nutzer die größten Profiteure sein werden:
- Arbeitssuchende: Erstellung professioneller Passfotos aus einem Schnappschuss
- Anime-Fans: Selfies in Sekundenschnelle in Comic-Avatare verwandeln
- Menschen vor dem Friseurbesuch: Vor dem Haarschnitt 6 verschiedene Frisuren per KI testen
- Xiaohongshu-Blogger: 8 Inhaltsbilder zum gleichen Thema in verschiedenen Stilen auf einmal erstellen
- Kleine Unternehmen: Selbstständige Erstellung von Menüs und Postern in Druckqualität
Im Folgenden betrachten wir anhand von drei konkreten Szenarien, ob diese Upgrades ihre Versprechen halten können.
GPT-image-2 Anwendungsfall 1: Erstellung von Pass- und Bewerbungsfotos
Das erste Szenario ist das mit dem größten praktischen Nutzen: die Erstellung von Passfotos. Dies ist eine lästige Aufgabe, der sich fast jeder Arbeitnehmer, Student oder Arbeitssuchende regelmäßig stellen muss. Bisherige Lösungen bestanden entweder darin, ein Fotostudio aufzusuchen (kostspielig) oder spezielle Passfoto-Apps zu nutzen (oft mit schwankender Qualität).
Kernkompetenzen von GPT-image-2 bei Passfotos
Die Stärken von GPT-image-2 bei Passfotos ergeben sich aus der Kombination dreier Fähigkeiten:
- Wahrung der Gesichtskonsistenz: Im Denkmodus werden die Merkmale der Person auf dem Originalfoto präzise erkannt, ohne dass das Gesicht durch übermäßige „Schönheitsfilter“ unkenntlich gemacht wird.
- Präzise Hintergrundersetzung: Wechsel zwischen weißem, blauem oder rotem Hintergrund per einfachem Befehl, ohne ausgefranste Kanten.
- Digitale Kleideranpassung: Alltagskleidung (z. B. T-Shirts) kann in formelle Anzüge, Hemden oder Business-Outfits umgewandelt werden.
Prompt-Vorlage für Passfotos mit GPT-image-2
Wir haben eine erprobte Standard-Eingabeaufforderung zusammengestellt, die Sie direkt kopieren und verwenden können:
Bitte bearbeite dieses Foto zu einem Standard-Passfoto. Anforderungen:
1. Hintergrund: Reinweiß (#FFFFFF), gleichmäßige Ausleuchtung, kein Verlauf.
2. Kleidung: Ersetzen durch einen dunklen Anzug + weißes Hemd (Gesicht und Frisur der Person beibehalten).
3. Ausdruck: Natürlicher Gesichtsausdruck des Originals beibehalten, keine Schönheitsfilter anwenden.
4. Bildaufbau: Kopf nimmt 60%-70% des Bildes ein, Schultern sind vollständig zu sehen.
5. Größe: Standard-Passfoto-Format (25mm × 35mm).
6. Ausgabe: 300dpi Druckqualität.
Vergleich der Passfoto-Ergebnisse mit GPT-image-2
Wir haben dasselbe Alltagsfoto mit fünf verschiedenen Tools getestet. Die Ergebnisse:
| Tool | Gesichtstreue | Hintergrundkanten | Kleidungsechtheit | Zeit pro Bild | Kosten pro Bild |
|---|---|---|---|---|---|
| Herkömmliche Passfoto-App | ★★★☆☆ | ★★★★☆ | ★★★☆☆ | 10 Sek. | Kostenlos-9 € |
| GPT-image-1.5 | ★★★★☆ | ★★★☆☆ | ★★★☆☆ | 30 Sek. | Niedrig |
| GPT-image-2 Standardmodus | ★★★★★ | ★★★★★ | ★★★★☆ | 60 Sek. | Mittel |
| GPT-image-2 Denkmodus | ★★★★★ | ★★★★★ | ★★★★★ | 3-5 Min. | Höher |
| Fotostudio | ★★★★★ | ★★★★★ | ★★★★★ | 30 Min. | 30-50 € |
Wichtige Beobachtungen:
- Die Qualität der Ergebnisse im GPT-image-2 Denkmodus erreicht das Niveau professioneller Fotostudios.
- Der Denkmodus ist besonders effektiv bei der Korrektur typischer Mängel wie „Reflektionen in der Brille“, „abstehenden Haaren“ oder „ungleichmäßiger Beleuchtung“.
- Die Kosten pro Bild liegen weit unter denen eines Fotostudios und das Foto kann jederzeit beliebig oft neu generiert werden.
💡 Nutzungsempfehlung: Wenn Sie GPT-image-2 zum ersten Mal für Passfotos verwenden, empfehlen wir den Denkmodus – der Unterschied in der Präzision der Gesichtsdetails ist deutlich sichtbar. Wir empfehlen den Aufruf über die Plattform APIYI (apiyi.com), da die Kosten pro Bild kontrollierbar sind und keine zusätzliche Bildbearbeitungskette erforderlich ist.
Fortgeschrittene Anwendungsmöglichkeiten
Sobald Sie geübt sind, können Sie diese erweiterten Funktionen ausprobieren:
1. Generierung mehrerer Formate in einem Durchgang
prompt: "Erstelle basierend auf diesem Foto Passfotos in den folgenden 4 Formaten:
- 1 Zoll weißer Hintergrund (chinesischer Personalausweis/Lebenslauf)
- 2 Zoll blauer Hintergrund (Reisepass/Visum)
- US-Visum 51×51mm weißer Hintergrund
- Japan-Visum 45×45mm weißer Hintergrund"
Die Konsistenzfähigkeit von GPT-image-2 stellt sicher, dass alle 4 Fotos dasselbe Gesicht und denselben Ausdruck bei unterschiedlichen Größen und Hintergründen zeigen.
2. Professionelle Business-Stile
prompt: "Bearbeite dieses Foto im Stil eines LinkedIn-Business-Porträts.
Hintergrund: verschwommenes modernes Büro, weiches und warmes Licht.
Kleidung: Upgrade auf einen professionellen Business-Anzug, Ausstrahlung: professionell und vertrauenswürdig."
Solche „Business-Porträts“ waren früher nur im Fotostudio möglich; heute reicht ein einziges Alltagsfoto aus.
GPT-image-2 Anwendungsfall 2: Umwandlung in Manga- und Anime-Stile
Das zweite Szenario ist der aktuell beliebteste Trend in den sozialen Medien: Manga-Profilbilder. Die Fähigkeiten von GPT-image-2 in diesem Bereich überraschen selbst Nutzer von Midjourney oder Stable Diffusion.
Kernvorteile der Manga-Stil-Umwandlung
Das Besondere an GPT-image-2 ist, dass es „Stil“ als eine „visuelle Sprache“ und nicht als bloßen „Filter“ versteht. OpenAI gibt an, dass das Modell spezifische Stil-Tags wie „Shonen Manga“, „Shojo“ (Mädchen-Manga) oder „Chibi“ (niedlicher Stil) erkennt – etwas, das mit GPT-image-1.5 noch nicht möglich war.

5 getestete Manga-Stile mit GPT-image-2
Wir haben dieselbe Person mit 5 gängigen Manga-Stilen getestet:
| Stil-Keyword | Visuelle Merkmale | Geeignetes Szenario | Zeit pro Bild |
|---|---|---|---|
shonen manga |
Grobe schwarze Linien, dynamische Linien | Kampf, Action-Themen | 90 Sek. |
shojo manga |
Große Augen, Glanzlichter, Blumendekor | Romantik, Mädchen-Stil | 90 Sek. |
chibi style |
Q-Version (großer Kopf), übertriebene Mimik | Emojis, Sticker | 60 Sek. |
cel-shaded anime |
Klare Farbflächen, deutliche Schatten | Profilbilder, Illustrationen | 90 Sek. |
studio ghibli |
Weiche Aquarellfarben, natürliche Atmosphäre | Landschafts- und Porträtmix | 120 Sek. |
Prompt-Vorlage für Manga-Stile
Bitte wandle dieses Porträtfoto in einen Manga-Avatar im [Stil-Keyword] Stil um. Anforderungen:
1. Gesichtszüge der Person müssen erkennbar bleiben (nicht durch eine völlig andere Person ersetzen).
2. Haar- und Augenfarbe müssen mit dem Originalfoto übereinstimmen.
3. Hintergrund ersetzen durch [gewünschte Atmosphäre] (z. B. Kirschblüten auf dem Campus / Cyberpunk-Stadt / Café).
4. Angemessene Manga-Elemente hinzufügen (z. B. Ausdruckslinien, Effektlinien, Rasterfolien).
5. Ausgabe in 2K-Auflösung, geeignet als Profilbild für soziale Medien.
Fortgeschrittene Anwendung: 8-Panel-Storyboards
Die bahnbrechendste Fähigkeit von GPT-image-2 ist die Erstellung von 8 zusammenhängenden Manga-Panels in einem Durchgang – etwas, das mit GPT-image-1.5 unmöglich war.
prompt: "Erstelle ein 8-Panel-Storyboard für einen Shonen-Manga.
Hauptfigur ist die Person auf diesem Foto. Handlung:
1. Morgens vom Wecker geweckt werden.
2. Zur Bushaltestelle rennen.
3. Im Unterricht heimlich einnicken.
4. Vom Lehrer aufgerufen werden, um eine Frage zu beantworten.
5. Falsche Antwort geben, die ganze Klasse lacht.
6. Alleine auf dem Sportplatz in Gedanken versunken sein.
7. Ein Freund kommt und tröstet.
8. Beide klatschen sich im Sonnenuntergang ab.
Die Figur muss in jedem Panel konsistent bleiben, japanische Sprechblasen verwenden, 2K-Auflösung."
Diese Kombination aus „konsistenter Hauptfigur + Storytelling über mehrere Panels + präzisen japanischen Dialogen“ erforderte früher einen Manga-Assistenten, LoRA-Training und Inpaint-Nachbearbeitung. Heute reicht eine einzige Eingabeaufforderung.
🚀 Tipp für die Massenproduktion: Für die Erstellung von Manga-Avataren oder Storyboards in Serie empfiehlt sich der API-Aufruf anstelle der Web-Version – so lässt sich die Verarbeitung automatisieren. Wir empfehlen den Aufruf über APIYI (apiyi.com), wobei die
base_urlaufhttps://api.apiyi.com/v1gesetzt wird, was vollständig mit den offiziellen Feldern kompatibel ist.
GPT-image-2 Anwendungsfall 3: Friseure und virtuelles Haarstyling
Das dritte Szenario ist eine der überraschendsten und nützlichsten Anwendungen – der Arbeitsablauf für Friseure. Dieser Anwendungsfall ist ideal für alle, die vor einem Haarschnitt unter „Friseur-Angst“ leiden: Bevor Sie den Salon besuchen, nutzen Sie einfach KI, um alle gewünschten Frisuren direkt an Ihrem eigenen Gesicht zu testen.
Kernkompetenzen von GPT-image-2 für das Haarstyling
GPT-image-2 bietet entscheidende Vorteile beim Haarstyling:
- Gesichtskonsistenz: Das Gesicht bleibt beim Wechsel der Frisuren identisch (etwas, das selbst Stable Diffusion in der Vergangenheit nur schwer beherrschte).
- Mehrfache Frisuren-Darstellung: Erstellung von Vergleichsbildern mit 4 bis 6 Frisurenoptionen gleichzeitig.
- Verständnis von Friseur-Fachsprache: Begriffe wie „Stufenschnitt“, „Gesichtskonturierung“ oder „Volumen“ werden präzise umgesetzt.
Ein klassisches Beispiel (wie in der Beispielgrafik am Anfang zu sehen) ist die „Test-Pinnwand“: GPT-image-2 kann sechs Frisurenvorschläge auf einem einzigen Bild darstellen, wobei jede Frisur mit einem Namen und kleinen Hinweisen versehen ist – genau das, wovon Friseure und Kunden gleichermaßen träumen.
Eingabeaufforderungs-Vorlage für das Haarstyling mit GPT-image-2
Bitte generiere basierend auf diesem Foto eine „Frisuren-Vorschau“. Anforderungen:
1. Motiv: Behalte die Gesichtsform, Gesichtszüge und Hautfarbe des Originalfotos unverändert bei.
2. Layout: 2×3 Raster zur Darstellung von 6 verschiedenen Frisuren.
3. Frisuren: [Liste 6 spezifische Frisuren auf]
- Stufiger Schlüsselbein-Schnitt
- Französischer Pony mit mittellangem Haar
- Koreanische S-Wellen
- Vintage-Locken (Hepburn-Stil)
- Japanischer, voluminöser hoher Pferdeschwanz
- Eleganter Dutt
4. Beschriftung: Unter jedem Bild soll der Name der Frisur in einem dezenten Etikett stehen.
5. Stil: Einheitlicher, beiger/hellgrauer Hintergrund, weiche und gleichmäßige Beleuchtung.
6. Auflösung: 2K, optimiert für die Ansicht auf Smartphones.
Testergebnisse für das Haarstyling mit GPT-image-2
Wir haben GPT-image-2 mit 10 Testern (5 Männer, 5 Frauen) gegen herkömmliche Styling-Apps getestet:
| Bewertungskriterium | Herkömmliche App | GPT-image-2 Standard | GPT-image-2 Denkmodus |
|---|---|---|---|
| Gesichtsreproduktion | ★★★☆☆ | ★★★★☆ | ★★★★★ |
| Frisurenvielfalt | 50-100 Vorlagen | Unbegrenzt frei beschreibbar | Unbegrenzt frei beschreibbar |
| Realismus (kein Aufkleber-Look) | ★★☆☆☆ | ★★★★☆ | ★★★★★ |
| Entscheidungshilfe | ★★★☆☆ | ★★★★☆ | ★★★★★ |
| Dauer pro Generierung | 5 Sek. | 60-90 Sek. | 3-5 Min. |
Wichtige Beobachtungen:
- Herkömmliche Apps wirken oft wie „aufgeklebt“, was zu verschobenen Haaransätzen und unnatürlichem Licht führt.
- Im Denkmodus erzeugt GPT-image-2 eine extrem hohe Verschmelzung mit dem Gesicht, die täuschend echt wirkt.
- Die „Pinnwand-Darstellung“ mit 6 Frisuren bietet einen höheren Nutzwert für Entscheidungen als Einzelbilder, da Nutzer direkt vergleichen können.
Zielgruppen für das Haarstyling mit GPT-image-2
| Nutzertyp | Kernbedarf | GPT-image-2 Eignung |
|---|---|---|
| Personen mit Friseur-Angst | Vorab-Vorschau zur Vermeidung von Reue | ★★★★★ |
| Friseure/Styling-Berater | Kunden passende Optionen präsentieren | ★★★★★ |
| Image-Berater | Ganzheitliche Gestaltung (mit Outfit/Make-up) | ★★★★☆ |
| Hochzeitsplaner | Vorab-Festlegung des Stylings | ★★★★☆ |
| Theater-/Film-Stylisten | Charakter-Frisuren-Design | ★★★★☆ |
💡 Tipp zum Szenario: Da Haarstyling hohe Anforderungen an die Bildstabilität stellt, empfehlen wir den Einsatz des Denkmodus. Nutzen Sie vorab kleine Testläufe (5-10 Bilder) über die Plattform APIYI (apiyi.com), um die Erkennungsgenauigkeit für Ihr Gesicht zu verifizieren.

Umfassende Analyse der Vor- und Nachteile von GPT-image-2 für kreative Anwendungen
Durch die Zusammenfassung der Testergebnisse aus drei verschiedenen Szenarien lässt sich eine vollständige Liste der Vor- und Nachteile erstellen.
Kernvorteile von GPT-image-2 für kreative Anwendungen
1. Steuerung durch natürliche Sprache, keine Hürden bei der Toolchain
Früher benötigte man für Passbilder Photoshop, für Comic-Avatare Stable Diffusion + LoRA und für Frisuren-Tests spezielle Apps – GPT-image-2 komprimiert all dies in ein einziges Chat-Fenster.
2. Multimodale Konsistenz als echter Paradigmenwechsel
Die Fähigkeit, auf einen Schlag 8 Bilder derselben Person mit unterschiedlichen Posen, Storyboards oder Frisuren auszugeben, erforderte früher komplexe Workflows wie ControlNet + ReferenceNet. Heute kann dies jeder Nutzer mit einer einfachen Anweisung erreichen.
3. Präzision durch den Denkmodus
Die „Erst denken, dann zeichnen“-Logik des Denkmodus sorgt dafür, dass das Modell bei der „Gesichtskonsistenz“ und komplexen Anweisungen – beides klassische Fehlerquellen – stabil bleibt. Dies ist der reale Mehrwert der „O-Serie-Schlussfolgerungsfähigkeit“ in kreativen Szenarien.
4. Stabile Verbindung in China
Es ist kein VPN erforderlich. Über den API-Proxy-Dienst von APIYI ist ein stabiler Modellaufruf möglich, was besonders für Nutzer in China vorteilhaft ist.
🎯 Hinweis zur schnellen Anbindung: Die stabile Nutzung von GPT-image-2 in China ist der Schlüssel zum Erfolg. Wir empfehlen die Anbindung über APIYI (apiyi.com), da diese über inländische, private und ausländische Knotenpunkte erreichbar ist. Wir empfehlen, das HTTP-Timeout auf über 360 Sekunden einzustellen, um den Denkmodus zu unterstützen.
Kernnachteile von GPT-image-2 für kreative Anwendungen
1. Lange Dauer durch den Denkmodus
Die Wartezeit von 3 bis 5 Minuten ist für Echtzeit-Interaktionen, wie etwa bei Live-Shopping-Events für virtuelle Anproben, nicht geeignet.
2. In sehr seltenen Fällen „Schönheits-Verschiebungen“
Bei etwa 5–10 % der Anfragen „optimiert“ das Modell das Gesicht des Nutzers eigenständig (z. B. leichte Glättung der Haut oder Anpassung der Kieferpartie) – für Nutzer, die eine exakte, realistische Wiedergabe wünschen, ist dies ein Nachteil.
3. Mängel bei der Darstellung von langem Text
Die Genauigkeit bei der Darstellung chinesischer Schriftzeichen liegt bei etwa 95 %, aber bei langen Absätzen mit mehr als 30 Zeichen kann es zu Fehlern kommen. Bei Designs wie Menüs oder Postern mit dichtem Text ist daher eine manuelle Korrektur erforderlich.
4. Höhere Kosten pro Bild im Vergleich zu Spezialwerkzeugen
Wenn es rein um Passbilder oder Frisuren-Tests geht, können spezialisierte Apps günstiger sein. Der Vorteil von GPT-image-2 liegt in der Kombination aus „Allgemeingültigkeit + Anpassbarkeit + Konsistenz über mehrere Bilder hinweg“.
Schnelleinstieg in GPT-image-2 für kreative Anwendungen
Schritt 1: Auswahl des Zugangskanals
| Kanal | Zielgruppe | Schwierigkeitsgrad |
|---|---|---|
| ChatGPT Plus Webversion | Privatnutzer, Nicht-Entwickler | ★ |
| OpenAI API | Entwickler, Batch-Verarbeitung | ★★★ |
| APIYI API-Proxy-Dienst | Inländische Entwickler, Unternehmenskunden | ★★ |
Schritt 2: Basis-Code für den Modellaufruf
Hier ist der minimale, ausführbare Code für Python:
from openai import OpenAI
import base64
client = OpenAI(
api_key="your-apiyi-key",
base_url="https://api.apiyi.com/v1",
timeout=600.0 # Timeout muss für den Denkmodus verlängert werden
)
# Hochladen eines Bildes für ein Passbild
with open("life_photo.jpg", "rb") as f:
image_b64 = base64.b64encode(f.read()).decode()
response = client.images.edit(
model="gpt-image-2",
image=open("life_photo.jpg", "rb"),
prompt="Wandle dieses Alltagsfoto in ein Standard-Passbild um, "
"weißer Hintergrund, dunkler Anzug, behalte die ursprünglichen Gesichtsmerkmale bei.",
size="1024x1024",
quality="high",
reasoning_effort="high" # Denkmodus
)
# Ausgabe speichern
import base64
img_data = base64.b64decode(response.data[0].b64_json)
with open("id_photo.png", "wb") as f:
f.write(img_data)
Schritt 3: Kurzübersicht für szenariobasierte Eingabeaufforderungen
| Szenario | Schlüsselwörter für die Eingabeaufforderung |
|---|---|
| Passbild | Weißer/Blauer Hintergrund + dunkler Anzug + Gesicht beibehalten + 1 Zoll |
| Business-Foto | LinkedIn-Stil + verschwommener Büro-Hintergrund + Business-Kleidung |
| Comic-Avatar | [Stil-Schlüsselwort] + Gesicht erkennbar halten + 2K-Avatar |
| 8-Panel-Storyboard | 8-Panel-Storyboard + Hauptfigur konsistent + präzises Japanisch + [Handlung] |
| Frisuren-Test | 2×3 Raster + Gesichtsform fixieren + 6 Frisuren + Labels |
| Festliche Looks | Halloween/Weihnachts-Thema + Gesicht beibehalten + festliche Kleidung |
🚀 Empfehlung zur API-Anbindung: Alle Prompt-Vorlagen funktionieren bei der offiziellen OpenAI-Schnittstelle und dem APIYI-Proxy-Dienst identisch – APIYI ist ein offizieller Proxy-Kanal, bei dem die Anfrage-/Antwortfelder zu 100 % mit dem Original synchron sind. Bestehender OpenAI-SDK-Code kann durch Ändern der
base_urleinfach umgestellt werden.
Häufig gestellte Fragen (FAQ) zur kreativen Anwendung von GPT-image-2
Frage 1: Kann ich mit GPT-image-2 erstellte Passbilder für offizielle Dokumente verwenden?
Das hängt vom jeweiligen Verwendungszweck ab. Für offizielle Dokumente wie Personalausweise oder Reisepässe ist weiterhin eine Aufnahme an den dafür vorgesehenen Stellen erforderlich. Für inoffizielle Zwecke wie Bewerbungsunterlagen, Profilbilder für Lebensläufe, Mitarbeiterausweise, Avatare für Websites oder soziale Medien sind die mit dem Denkmodus von GPT-image-2 erstellten Bilder jedoch bereits bestens geeignet.
Frage 2: Der Denkmodus dauert 3–5 Minuten – kann man das beschleunigen?
Ja, es gibt mehrere Möglichkeiten zur Beschleunigung:
- Ausgabeauflösung reduzieren (von 2K auf 1024×1024).
- Anweisungen vereinfachen (nur eine Aufgabe pro Anfrage, nicht zu viele Einschränkungen gleichzeitig).
- Standardmodus verwenden (geringfügig geringere Präzision, dafür sinkt die Dauer auf 60–90 Sekunden).
Frage 3: Ist der Comic-Stil von GPT-image-2 besser als bei Midjourney?
Das kommt auf die Bewertungskriterien an. Midjourney hat bei „Künstlerischem Anspruch und visueller Wirkung“ weiterhin die Nase vorn. GPT-image-2 bietet jedoch Durchbrüche bei der Gesichtskonsistenz von „Originalfoto zu Comic“ und bei der „kohärenten Erzählung über mehrere Panels hinweg“. Beide Modelle schließen sich nicht aus; wir empfehlen die Wahl je nach spezifischem Anwendungsfall.
Frage 4: Kann ich die generierten Bilder für eine Frisuren-Vorschau direkt meinem Friseur zeigen?
Ja. Die im Denkmodus von GPT-image-2 erstellten Frisurbilder sind bereits sehr realistisch und detailgetreu. Wir empfehlen, sie auszudrucken oder auf dem Smartphone zu zeigen, damit Ihr Friseur auf Basis dieses konkreten Entwurfs eine professionelle Beratung durchführen kann.
Frage 5: Gibt es Unterschiede bei der Anbindung über APIYI (apiyi.com) im Vergleich zum offiziellen OpenAI-Weg?
Die Felder sind identisch. APIYI fungiert als offizieller Proxy-Dienst; die Anfrage- und Antwortfelder sind zu 100 % mit OpenAI synchron. Die Unterschiede liegen hauptsächlich in drei Punkten: Direktverbindung aus China ohne Proxy, spezieller technischer Support auf Chinesisch und transparente Abrechnung. Wir empfehlen Entwicklern in China, GPT-image-2 über APIYI (apiyi.com) anzubinden, um Netzwerkstabilitätsprobleme zu vermeiden.
Frage 6: Gibt es urheberrechtliche Probleme bei den generierten Bildern?
Die von OpenAI generierten Inhalte unterliegen den OpenAI Usage Policies. Die kreative Weiterverarbeitung eigener hochgeladener Fotos (Passbilder, Comic-Avatare, Frisuren-Vorschau) fällt unter die persönliche, angemessene Nutzung. Für kommerzielle Zwecke (z. B. die Verwendung eines generierten Comic-Avatars auf Produktverpackungen) müssen die kommerziellen Nutzungsbedingungen von OpenAI beachtet werden.
Frage 7: Kann sich GPT-image-2 mein Gesicht für spätere Generierungen merken?
Innerhalb derselben Sitzung ja. Der Denkmodus merkt sich die Merkmale des zuvor hochgeladenen Fotos, auf die sich nachfolgende Eingabeaufforderungen beziehen können. Sitzungsübergreifend ist dies jedoch nicht garantiert – bei einem neuen Chat muss das Bild erneut hochgeladen werden. Wir empfehlen, die „Referenzbilder“ als persönliche Materialbibliothek separat zu speichern.
Frage 8: Wie hoch sind die Kosten für GPT-image-2?
Der Modellaufruf wird nach Token und Bildauflösung abgerechnet. Ein 2K-Bild im Denkmodus kostet etwa 0,10–0,30 $, im Standardmodus etwa 0,03–0,08 $. Für Privatanwender, die monatlich 100–200 kreative Bilder erstellen, bleiben die Kosten in einem überschaubaren Rahmen. Wir empfehlen die transparente Abrechnung nach Token über die Plattform APIYI (apiyi.com), um Komplikationen bei Zahlungen mit ausländischen Kreditkarten zu vermeiden.
Wichtige Erkenntnisse zur kreativen Anwendung von GPT-image-2
- Der wahre Fortschritt hinter dem E-Mail-Marketing von OpenAI ist die Kombination aus „Denkmodus“ und „Konsistenz über mehrere Bilder hinweg“.
- Passbild-Szenario: Die Bildqualität im Denkmodus erreicht das Niveau professioneller Fotostudios, die Kosten pro Bild liegen weit unter denen vor Ort und jede Spezifikation ist individuell anpassbar.
- Comic-Stil-Szenario: Das Modell versteht „Stil“ als visuelle Sprache und nicht nur als Filter; es unterstützt diverse Genres wie Shonen, Shojo, Chibi oder Cel-Shading.
- Frisuren-Vorschau: Die Darstellung von 6 Frisuren nebeneinander ermöglicht dem Nutzer einen direkten Vergleich, was mit früheren spezialisierten Apps kaum möglich war.
- Denkmodus vs. Standardmodus: Für komplexe Anweisungen und Szenarien mit hoher Anforderung an die Gesichtspräzision ist der Denkmodus ein Muss; für geschwindigkeitskritische Anwendungen ist der Standardmodus vorzuziehen.
- Empfehlung für die Anbindung: Nutzen Sie die Direktverbindung über APIYI (apiyi.com), setzen Sie das Timeout auf mindestens 360 Sekunden und passen Sie die
base_urlentsprechend an. - Der größte Nutzen für Endanwender: Was früher einen Workflow aus Photoshop, Stable Diffusion und LoRA erforderte, lässt sich heute mit einer einzigen Eingabeaufforderung erledigen.
Zusammenfassung
GPT-image-2 ist weit mehr als nur ein gewöhnliches Modell-Update – es macht kreative Aufgaben, die früher spezialisierten Toolchains vorbehalten waren, nun für jeden zugänglich, der ChatGPT bedienen kann. Dies ist nicht nur eine Verbesserung technischer Kennzahlen, sondern die tatsächliche Demokratisierung kreativer Werkzeuge.
Die drei Szenarien – Passbilder, Comic-Stil und Frisuren-Design – sind deshalb so bemerkenswert, weil sie die häufigsten Alltagsbedürfnisse normaler Nutzer abdecken: Jobsuche, soziale Medien und persönliches Image-Management. Die Leistung von GPT-image-2 in diesen Bereichen erreicht oder übertrifft sogar das Niveau spezialisierter Anwendungen.
Empfehlungen für verschiedene Zielgruppen:
- Privatanwender: Starten Sie mit der ChatGPT Plus-Webversion und machen Sie sich mit dem „Denkmodus“ vertraut, indem Sie zunächst einige Passbilder erstellen, um die Grenzen der Möglichkeiten auszuloten.
- Friseure/Stylisten/Imageberater: Integrieren Sie „6 Frisuren-Varianten im direkten Vergleich“ als festen Bestandteil Ihres Service-Prozesses; dies wird die Entscheidungsfindung Ihrer Kunden erheblich beschleunigen.
- Anime-Fans/Social-Media-Creator: Nutzen Sie die Fähigkeit, „8-Panel-Storyboards mit konsistenten Charakteren“ zu erstellen, um Inhalte zu produzieren, die bisher technisch nicht möglich waren.
- Entwickler in China: Nutzen Sie APIYI, um die API einzubinden und diese Funktionen in Ihre eigenen Produkte zu integrieren, um spezialisierte vertikale Anwendungen zu entwickeln.
✨ Abschließender Tipp: Für Nutzer und Unternehmen in China empfehlen wir den Zugriff auf gpt-image-2 über die Plattform APIYI (apiyi.com). Die direkte Verbindung ist stabil, die Felder sind vollständig mit dem offiziellen Standard kompatibel und die Abrechnung erfolgt transparent pro Token. Neue Nutzer erhalten ein kostenloses Testguthaben, das ausreicht, um alle drei in diesem Artikel beschriebenen Szenarien vollständig zu testen, bevor Sie sich für den produktiven Einsatz entscheiden.
Autor: APIYI Team
Letzte Aktualisierung: 02.05.2026