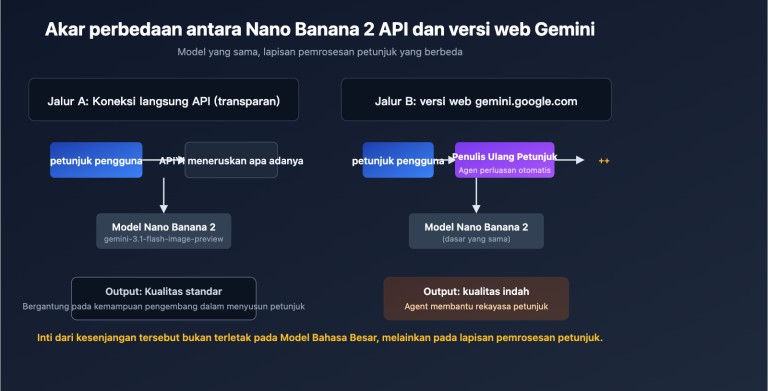
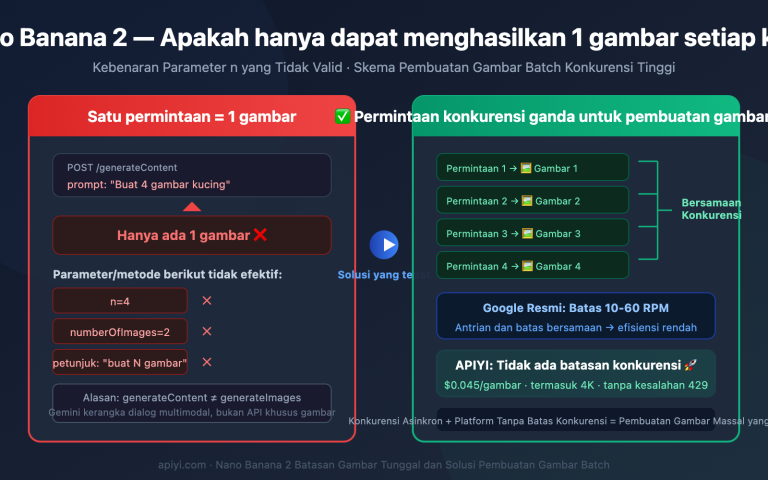
Akhir-akhir ini, banyak developer menemui pesan kesalahan ini saat memanggil Gemini API:
{
"error": {
"code": 503,
"message": "This model is currently experiencing high demand. Spikes in demand are usually temporary. Please try again later.",
"status": "UNAVAILABLE"
}
}
Sederhananya, ini berarti: Model ini sedang sangat populer, server tidak sanggup menanganinya, coba lagi nanti.
Masalah ini sangat parah terutama pada dua model baru: Gemini 3.1 Pro Preview dan Gemini 3.1 Flash Image Preview (Nano Banana 2). Artikel ini akan menjelaskan secara tuntas esensi kesalahan ini, perbedaannya dengan kesalahan umum lainnya, serta 5 solusi yang terbukti efektif.
Nilai Inti: Setelah membaca artikel ini, Anda akan memahami secara akurat akar penyebab kesalahan 503 permintaan tinggi, menguasai 5 solusi yang dapat langsung diterapkan, dan tidak lagi terhambat dalam pengembangan karena kesalahan ini.
Apa Sebenarnya Arti Error 503 High Demand pada Gemini API?
Mari kita pahami masalah ini dengan analogi yang mudah dicerna:
Bayangkan server Gemini Google adalah sebuah restoran viral. Biasanya bisnis berjalan baik, tempat duduk cukup. Tiba-tiba suatu hari menjadi viral (peluncuran model baru), dan semua orang di kota berbondong-bondong mengantre. Kapasitas restoran terbatas, kalau sudah penuh ya penuh. Saat Anda tiba di depan, pelayan akan berkata: "Maaf, saat ini terlalu banyak orang, jam sibuk biasanya sementara, mohon datang lagi nanti."
Inilah esensi dari This model is currently experiencing high demand — bukan kode Anda yang bermasalah, bukan kunci API Anda yang bermasalah, melainkan kapasitas komputasi server Google yang tidak mencukupi.
3 Fakta Penting tentang Error 503 Gemini
| Fakta | Penjelasan | Dampak |
|---|---|---|
| Masalah Sisi Server | 503 berarti kapasitas server Google tidak mencukupi, tidak ada hubungannya dengan kode atau konfigurasi Anda | Upgrade paket berbayar pun tidak akan menyelesaikannya |
| Semua Pengguna Terkena Dampak | Pengguna gratis, berbayar, dan pelanggan korporat semuanya akan mengalaminya | Bukan masalah yang bisa "diselesaikan dengan membayar" |
| Biasanya Bersifat Sementara | Sekitar 70% error 503 selama jam sibuk pulih sendiri dalam 60 menit | Membutuhkan mekanisme coba ulang, bukan perbaikan kode |
Mengapa Gemini 3.1 Pro dan Nano Banana 2 Sangat Rentan Terhadap Error 503
Peningkatan error 503 pada Februari 2026 memiliki linimasa yang jelas:
- 19 Februari: Google merilis Gemini 3.1 Pro Preview, banyak developer berbondong-bondong untuk menguji.
- 26 Februari: Nano Banana 2 (
gemini-3.1-flash-image-preview) dirilis, permintaan pembuatan gambar melonjak. - 17-21 Februari: StatusGator terus-menerus mencatat peringatan penurunan layanan Gemini selama seminggu penuh.
- Tingkat Kegagalan Puncak sekitar 45%: Data komunitas menunjukkan tingkat kegagalan permintaan selama jam sibuk mendekati setengahnya.
Penyebab Mendasar: Model baru baru saja diluncurkan, dan kapasitas komputasi (kluster GPU) yang dialokasikan Google belum diskalakan sesuai permintaan. Sumber daya server model dalam status Preview memang terbatas, dan ketika developer global berbondong-bondong menguji secara bersamaan, terjadilah situasi di mana permintaan melebihi penawaran.

Perbedaan Mendasar antara Gemini 503 High Demand dan 429 Rate Limit
Banyak developer sering keliru antara 503 dan 429, padahal penyebab kedua kesalahan ini sangat berbeda, dan solusinya juga sangat berbeda. Salah arah hanya akan membuang-buang tenaga.
| Dimensi Perbandingan | 503 High Demand | 429 Rate Limit |
|---|---|---|
| Pesan Kesalahan | "This model is currently experiencing high demand" | "Resource has been exhausted" |
| Penyebab Mendasar | Kapasitas komputasi server Google tidak mencukupi | Frekuensi permintaan pribadi Anda melebihi batas |
| Cakupan Dampak | Semua pengguna terpengaruh | Hanya Anda yang terpengaruh |
| Apakah Upgrade Dapat Menyelesaikan? | ❌ Upgrade paket berbayar tidak dapat menyelesaikan | ✅ Upgrade ke Tier 1 dapat menyelesaikan |
| Apakah Coba Lagi Efektif? | ✅ Menunggu sebentar biasanya dapat pulih | ❌ Tidak menurunkan frekuensi akan terus menghasilkan kesalahan |
| Karakteristik Puncak | Sering terjadi selama jam kerja Amerika Utara (9 pagi-5 sore PT) | Tidak tergantung waktu, akan error jika melebihi batas |
| Solusi Fundamental | Coba lagi + model cadangan + hindari jam sibuk | Kurangi frekuensi permintaan atau upgrade paket |
Cara Cepat Membedakan
- Jika melihat 503 → Masalah dari Google, tunggu sebentar atau ganti model
- Jika melihat 429 → Permintaan Anda terlalu cepat, perlambat atau upgrade paket
🎯 Saran Teknis: Menangani kedua jenis kesalahan 503 dan 429 secara bersamaan di lingkungan produksi adalah keterampilan dasar integrasi API. Dengan memanggil model seri Gemini melalui platform APIYI apiyi.com, platform ini memiliki mekanisme coba lagi cerdas dan penyeimbangan beban yang dapat secara signifikan mengurangi frekuensi kesalahan 503 yang dirasakan oleh pengguna akhir.
Solusi Pertama: Coba Lagi dengan Exponential Backoff (Paling Dasar)
Karena 503 berarti "coba lagi nanti", respons paling langsung adalah coba lagi secara otomatis. Namun, tidak bisa coba lagi secara membabi buta—perlu menggunakan strategi "exponential backoff", di mana setiap interval coba lagi digandakan untuk menghindari peningkatan tekanan pada server.
Kode Coba Lagi Exponential Backoff Gemini 503
import openai
import time
import random
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Antarmuka terpadu APIYI
)
def call_gemini_with_retry(messages, model="gemini-3.1-pro-preview", max_retries=5):
"""Pemanggilan API Gemini dengan exponential backoff"""
for attempt in range(max_retries):
try:
response = client.chat.completions.create(
model=model,
messages=messages
)
return response
except openai.APIStatusError as e:
if e.status_code == 503:
# Exponential backoff: 2s, 4s, 8s, 16s, 32s + jitter acak
wait_time = (2 ** attempt) + random.uniform(0, 1)
print(f"⏳ 503 High Demand - Coba lagi ke-{attempt+1}, menunggu {wait_time:.1f}s...")
time.sleep(wait_time)
elif e.status_code == 429:
# 429 Rate Limit: tunggu lebih lama
wait_time = 60 + random.uniform(0, 10)
print(f"🚫 429 Rate Limit - Menunggu {wait_time:.1f}s...")
time.sleep(wait_time)
else:
raise # Lempar kesalahan lain secara langsung
raise Exception(f"Gagal setelah {max_retries} kali coba lagi")
# Contoh penggunaan
response = call_gemini_with_retry(
messages=[{"role": "user", "content": "Hello, Gemini!"}]
)
print(response.choices[0].message.content)
Parameter Utama untuk Coba Lagi Exponential Backoff
| Parameter | Nilai yang Disarankan | Deskripsi |
|---|---|---|
| Jumlah Maksimal Coba Lagi | 5 kali | Lebih dari 5 kali pada dasarnya menunjukkan bukan masalah sementara |
| Penantian Awal | 2 detik | Terlalu singkat akan meningkatkan tekanan server |
| Faktor Backoff | 2x | Setiap kali digandakan: 2s → 4s → 8s → 16s → 32s |
| Jitter Acak | 0-1 detik | Menghindari banyak klien mencoba lagi secara bersamaan |
| Penantian Terlama | 32 detik | Lebih dari 32 detik sebaiknya beralih ke solusi cadangan |
💡 Tips Praktis: Jitter acak sangat penting. Jika semua klien mencoba lagi tepat setelah 2 detik, ini akan menyebabkan "efek kawanan"—semua permintaan membanjiri server secara bersamaan lagi, menyebabkan putaran berikutnya juga menjadi 503. Menambahkan jitter acak dapat menyebarkan permintaan coba lagi.
Solusi Kedua: Penurunan Model/Pengalihan Otomatis ke Model Cadangan
Ketika Gemini 3.1 Pro Preview terus-menerus mengalami 503, solusi paling praktis adalah secara otomatis beralih ke model cadangan yang lebih stabil.
Strategi Penurunan Model Gemini 503
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
# Rantai penurunan model: Prioritaskan yang terkuat, jika gagal, turunkan.
FALLBACK_MODELS = [
"gemini-3.1-pro-preview", # Pilihan utama: Terbaru dan terkuat
"gemini-3.0-pro", # Cadangan 1: Pro generasi sebelumnya, lebih stabil
"gemini-2.5-flash-image-preview", # Cadangan 2: Versi Flash, cepat
"gemini-2.5-flash", # Cadangan terakhir: Flash paling stabil
]
def call_with_fallback(messages):
"""Pemanggilan API dengan penurunan model"""
for model in FALLBACK_MODELS:
try:
response = client.chat.completions.create(
model=model,
messages=messages
)
if model != FALLBACK_MODELS[0]:
print(f"⚠️ Telah diturunkan ke model cadangan: {model}")
return response
except openai.APIStatusError as e:
if e.status_code in (503, 429):
print(f"❌ {model} mengembalikan {e.status_code}, mencoba model berikutnya...")
continue
raise
raise Exception("Semua model tidak tersedia")
response = call_with_fallback(
messages=[{"role": "user", "content": "Analisis hambatan kinerja kode ini"}]
)
Peringkat Stabilitas Model Gemini
| Model | Stabilitas | Frekuensi 503 | Skenario yang Cocok |
|---|---|---|---|
gemini-2.5-flash |
⭐⭐⭐⭐⭐ | Sangat rendah | Cadangan untuk lingkungan produksi ketersediaan tinggi |
gemini-3.0-pro |
⭐⭐⭐⭐ | Rendah | Skenario stabil yang membutuhkan kemampuan Pro |
gemini-2.5-flash-image-preview |
⭐⭐⭐ | Sedang | Cadangan untuk pembuatan gambar |
gemini-3.1-pro-preview |
⭐⭐ | Cukup tinggi | Membutuhkan kemampuan terbaru tetapi dapat menerima kegagalan sesekali |
gemini-3.1-flash-image-preview |
⭐⭐ | Cukup tinggi | Pembuatan gambar Nano Banana 2 |
🚀 Mulai Cepat: Melalui platform APIYI apiyi.com, Anda dapat memanggil semua model di tabel di atas dengan satu kunci API. Pengalihan model hanya perlu mengubah parameter model, tanpa perlu mengkonfigurasi ulang otentikasi. Menerapkan rantai penurunan model dalam kode sangatlah mudah.
Solusi Ketiga: Pemanggilan di Luar Jam Sibuk (Solusi Tanpa Biaya)
Permintaan tinggi 503 memiliki pola waktu yang jelas. Data komunitas menunjukkan:
- Jam sibuk (9AM-5PM PT): Tingkat kegagalan sekitar 45%
- Jam sepi (2AM-7AM PT): Tingkat kegagalan di bawah 5%
Dikonversi ke Waktu Beijing:
| Periode Waktu (Waktu Beijing) | Waktu Pasifik yang Sesuai | Frekuensi Gemini 503 | Saran |
|---|---|---|---|
| Pukul 01:00 – 10:00 Pagi | 9AM-6PM PT (hari sebelumnya) | 🔴 Puncak | Hindari atau gunakan model cadangan |
| Pukul 10:00 Pagi – 15:00 Sore | 6PM-11PM PT (hari sebelumnya) | 🟡 Sedang | Panggil dengan mekanisme coba ulang |
| Pukul 15:00 Sore – 23:00 Malam | 11PM-7AM PT | 🟢 Rendah | Jendela pemanggilan terbaik |
| Pukul 23:00 Malam – 01:00 Pagi | 7AM-9AM PT | 🟡 Sedang | Mulai meningkat |
Skenario yang Cocok untuk Pemanggilan di Luar Jam Sibuk
- Pemrosesan data batch: Tugas yang tidak memerlukan respons real-time, jadwalkan untuk berjalan selama jam sepi.
- Tugas terjadwal: Atur cron job untuk dieksekusi selama jam sepi.
- Pembuatan konten: Skenario di mana artikel, gambar, dll., dapat dibuat terlebih dahulu dan diterbitkan kemudian.
Solusi Empat: Strategi Kombinasi (Direkomendasikan untuk Lingkungan Produksi)
Di lingkungan produksi yang sebenarnya, satu solusi saja seringkali tidak cukup. Kami merekomendasikan untuk menggabungkan 3 solusi sebelumnya:
Skema Pemanggilan Gemini API Tingkat Produksi
import openai
import time
import random
from datetime import datetime
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
FALLBACK_MODELS = [
"gemini-3.1-pro-preview",
"gemini-3.0-pro",
"gemini-2.5-flash",
]
def smart_gemini_call(messages, max_retries=3):
"""
Pemanggilan Gemini API tingkat produksi
Strategi: coba ulang eksponensial backoff + penurunan model + klasifikasi kesalahan
"""
for model in FALLBACK_MODELS:
for attempt in range(max_retries):
try:
response = client.chat.completions.create(
model=model,
messages=messages,
timeout=30
)
return response, model
except openai.APIStatusError as e:
if e.status_code == 503:
if attempt < max_retries - 1:
wait = (2 ** attempt) + random.uniform(0, 1)
print(f"⏳ {model} 503 - Coba ulang {attempt+1}/{max_retries}, tunggu {wait:.1f}s")
time.sleep(wait)
else:
print(f"⚠️ {model} terus-menerus 503, turunkan ke model berikutnya")
break # Keluar dari coba ulang, ganti model
elif e.status_code == 429:
wait = 60
print(f"🚫 {model} 429 Batas tarif - Tunggu {wait}s")
time.sleep(wait)
else:
raise
except openai.APITimeoutError:
print(f"⏰ {model} Permintaan timeout, coba model berikutnya")
break
raise Exception("Semua model dan coba ulang gagal, periksa jaringan atau coba lagi nanti")
# Penggunaan
response, used_model = smart_gemini_call(
messages=[{"role": "user", "content": "Halo"}]
)
print(f"✅ Menggunakan model: {used_model}")
print(response.choices[0].message.content)
Lihat implementasi tingkat produksi lengkap (termasuk log, pemantauan, cache)
import openai
import time
import random
import hashlib
import json
import logging
from datetime import datetime
from functools import lru_cache
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger("gemini_client")
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
# Cache permintaan sederhana
_cache = {}
def get_cache_key(messages, model):
"""Menghasilkan kunci cache untuk permintaan"""
content = json.dumps(messages, sort_keys=True) + model
return hashlib.md5(content.encode()).hexdigest()
def gemini_call_production(
messages,
models=None,
max_retries=3,
cache_ttl=3600,
enable_cache=True
):
"""
Pembungkus pemanggilan Gemini API tingkat produksi
Fitur:
- Coba ulang eksponensial backoff (menangani 503)
- Penurunan model otomatis
- Cache respons (mengurangi permintaan berulang)
- Log terstruktur
"""
if models is None:
models = ["gemini-3.1-pro-preview", "gemini-3.0-pro", "gemini-2.5-flash"]
# Periksa cache
if enable_cache:
cache_key = get_cache_key(messages, models[0])
if cache_key in _cache:
cached_time, cached_response = _cache[cache_key]
if time.time() - cached_time < cache_ttl:
logger.info("Cache hit, lewati pemanggilan API")
return cached_response, "cache"
errors = []
for model in models:
for attempt in range(max_retries):
try:
start_time = time.time()
response = client.chat.completions.create(
model=model,
messages=messages,
timeout=30
)
elapsed = time.time() - start_time
logger.info(f"Berhasil | model={model} | Waktu={elapsed:.2f}s")
# Tulis ke cache
if enable_cache:
_cache[cache_key] = (time.time(), response)
return response, model
except openai.APIStatusError as e:
errors.append(f"{model}:{e.status_code}")
if e.status_code == 503:
if attempt < max_retries - 1:
wait = (2 ** attempt) + random.uniform(0, 1)
logger.warning(f"503 | model={model} | coba ulang={attempt+1} | tunggu={wait:.1f}s")
time.sleep(wait)
else:
logger.warning(f"503 terus-menerus | model={model} | turunkan ke model berikutnya")
break
elif e.status_code == 429:
logger.warning(f"429 Batas tarif | model={model}")
time.sleep(60)
else:
raise
except Exception as e:
logger.error(f"Pengecualian | model={model} | error={e}")
break
raise Exception(f"Semua gagal: {errors}")

Solusi Kelima: Menggunakan Rute Cerdas dari Platform Proksi API
Ketika Anda tidak ingin mengimplementasikan logika percobaan ulang dan failover yang rumit seperti di atas, ada pilihan yang lebih mudah—menggunakan platform proksi API yang memiliki kemampuan rute cerdas.
Bagaimana Platform Proksi API Menyelesaikan Masalah Gemini 503
Platform proksi API profesional biasanya memiliki fitur:
- Rotasi Banyak Kunci API: Platform memiliki beberapa kunci API Google, dan secara otomatis beralih saat satu kunci API mengalami pembatasan laju.
- Percobaan Ulang Cerdas: Platform mengimplementasikan percobaan ulang dengan exponential backoff di tingkat platform, transparan bagi pengembang.
- Penyeimbangan Beban: Mendistribusikan permintaan ke beberapa akun dan wilayah Google.
- Deteksi Kegagalan: Ketika terdeteksi frekuensi error 503 pada suatu model meningkat, secara otomatis mengurangi rasio alokasi permintaan untuk model tersebut.
🎯 Saran Teknis: Platform APIYI apiyi.com menyediakan kemampuan rute cerdas di atas untuk model seri Gemini. Dengan menggunakan pemanggilan antarmuka yang kompatibel dengan OpenAI, platform secara otomatis menangani percobaan ulang 503 dan penyeimbangan beban multi-kunci API di backend, sehingga pengembang tidak perlu mengimplementasikan logika toleransi kesalahan yang rumit sendiri.
Contoh Kode Minimalis untuk Solusi Platform Proksi API
import openai
# Menggunakan platform proksi APIYI, penanganan 503 ditangani oleh platform
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
# Sesederhana itu, tidak perlu menangani 503 sendiri
response = client.chat.completions.create(
model="gemini-3.1-pro-preview",
messages=[{"role": "user", "content": "你好"}]
)
print(response.choices[0].message.content)
Alur Lengkap Pemecahan Masalah Error API Gemini
Ketika menghadapi error API Gemini, ikuti alur berikut untuk dengan cepat mengidentifikasi masalah:
Langkah Pertama: Periksa Kode Error
| Kode Error | Pesan Error | Tipe | Tindakan Segera |
|---|---|---|---|
| 503 | "high demand" / "overloaded" | Kapasitas komputasi server tidak cukup | Tunggu percobaan ulang atau ganti model |
| 429 | "resource exhausted" | Pembatasan laju pribadi | Kurangi frekuensi permintaan atau tingkatkan paket |
| 400 | "invalid request" | Parameter permintaan salah | Periksa format dan parameter permintaan |
| 401 | "unauthorized" | Autentikasi gagal | Periksa kunci API |
| 500 | "internal error" | Error internal server | Tunggu percobaan ulang |
Langkah Kedua: Bedakan antara 503 dan 429
- Jika beberapa kunci API mengalami error → 503, itu masalah server Google.
- Jika hanya kunci API Anda yang mengalami error → 429, itu masalah batas kuota pribadi Anda.
Langkah Ketiga: Pilih Solusi yang Sesuai
- 503: Percobaan ulang exponential backoff → Penurunan model → Pemanggilan di luar jam sibuk
- 429: Kurangi frekuensi permintaan → Aktifkan penagihan untuk upgrade ke Tier 1 (lapisan gratis 5-15 RPM, Tier 1 adalah 150-300 RPM)
Pertanyaan Umum
Q1: Mengapa saya masih mengalami 503 High Demand meskipun sudah membayar?
503 sama sekali tidak ada hubungannya dengan apakah Anda sudah membayar atau belum. 503 adalah masalah kapasitas server Google yang tidak mencukupi, dan akan dialami baik oleh pengguna gratis maupun pelanggan korporat. Ini berbeda dengan pembatasan laju 429 — 429 memang bisa diatasi dengan upgrade paket, tapi 503 tidak. Jika menghadapi 503, disarankan untuk menggunakan percobaan ulang eksponensial (exponential backoff retry) atau beralih ke versi model yang lebih stabil. Pemanggilan model melalui platform APIYI apiyi.com dapat memanfaatkan penyeimbangan beban multi-kunci untuk mengurangi frekuensi 503 yang dirasakan.
Q2: Kapan masalah 503 pada Gemini 3.1 Pro Preview akan membaik?
Berdasarkan pengalaman sebelumnya, puncak 503 setelah rilis model baru biasanya berlangsung 1-3 minggu, dan akan membaik secara signifikan seiring dengan peningkatan kapasitas Google secara bertahap. Gemini 3.0 Pro juga mengalami gelombang 503 serupa saat pertama kali dirilis, dan sekarang sudah sangat stabil. Selama masa tunggu, disarankan untuk menerapkan strategi penurunan model (model degradation), yaitu secara otomatis kembali ke gemini-3.0-pro atau gemini-2.5-flash saat terjadi 503.
Q3: Apakah “high demand” dan “model is overloaded” adalah kesalahan yang sama?
Pada dasarnya, ini adalah masalah yang sama dengan frasa yang berbeda. "This model is currently experiencing high demand" dan "The model is overloaded" keduanya adalah kode status 503, yang menunjukkan bahwa kapasitas server Google tidak mencukupi. Yang pertama lebih sering muncul di versi API yang lebih baru, sedangkan yang kedua lebih banyak muncul di versi awal. Cara penanganannya sama persis.
Q4: Adakah cara untuk mengetahui sebelumnya apakah Gemini API akan mengalami 503?
Tidak ada peringatan dini resmi. Namun, Anda bisa memperhatikan beberapa sinyal: (1) 1-2 minggu setelah Google merilis model baru adalah periode berisiko tinggi; (2) Frekuensi 503 lebih tinggi selama jam kerja Amerika Utara (dini hari hingga pagi waktu Beijing); (3) Forum komunitas discuss.ai.google.dev biasanya memiliki umpan balik real-time. Disarankan untuk selalu menyertakan logika percobaan ulang dan penurunan model dalam kode Anda, daripada menambahkannya secara ad hoc saat masalah muncul. Platform APIYI apiyi.com menyediakan pemantauan status ketersediaan model, yang dapat membantu Anda mendeteksi lebih awal.
Q5: Haruskah saya menangani 503 dan 429 secara bersamaan dalam kode saya?
Tentu saja. Dalam lingkungan produksi, 503 dan 429 akan sama-sama ditemui, dan meskipun strategi penanganannya berbeda, keduanya sama pentingnya. Untuk 503, gunakan percobaan ulang eksponensial + penurunan model; untuk 429, gunakan pengurangan frekuensi permintaan + antrean pembatasan laju. Kode "Solusi Empat: Strategi Kombinasi" dalam artikel ini menangani kedua jenis kesalahan tersebut secara bersamaan dan dapat langsung digunakan di lingkungan produksi.
Ringkasan
Inti dari kesalahan 503 This model is currently experiencing high demand sangat sederhana — kapasitas server Google sementara tidak mencukupi. Terutama untuk model baru seperti Gemini 3.1 Pro Preview dan Nano Banana 2, masalah ini hampir pasti akan ditemui pada tahap awal peluncuran.
5 solusi berdasarkan prioritas yang direkomendasikan:
- Percobaan Ulang Eksponensial (Exponential Backoff Retry) — Paling dasar, setiap proyek harus memilikinya
- Rantai Penurunan Model (Model Degradation Chain) — Otomatis beralih ke model yang lebih stabil saat terjadi 503
- Pemanggilan di Luar Jam Sibuk — Jadwalkan tugas non-real-time pada periode sepi
- Strategi Kombinasi — Direkomendasikan untuk lingkungan produksi, percobaan ulang + penurunan model + klasifikasi kesalahan
- Rute Cerdas Platform Proksi API — Paling praktis, platform menangani logika toleransi kesalahan
Apapun solusi yang Anda pilih, prinsip intinya adalah: 503 bukanlah kesalahan Anda, tetapi Anda perlu menanganinya dengan elegan. Disarankan untuk mengintegrasikan model seri Gemini dengan cepat melalui APIYI apiyi.com untuk menikmati kemampuan rute cerdas dan percobaan ulang bawaan.
Referensi
-
Google AI Developers Forum – Diskusi Error 503
- Tautan:
discuss.ai.google.dev - Deskripsi: Diskusi komunitas dan tanggapan resmi mengenai error 503 API Gemini.
- Tautan:
-
Google Gemini API – Dokumentasi Batas Tingkat
- Tautan:
ai.google.dev/gemini-api/docs/rate-limits - Deskripsi: Aturan pembatasan tingkat resmi dan penjelasan kuota untuk setiap Tingkat.
- Tautan:
-
Google Gemini API – Panduan Pemecahan Masalah
- Tautan:
ai.google.dev/gemini-api/docs/troubleshooting - Deskripsi: Panduan pemecahan masalah error resmi.
- Tautan:
📝 Penulis: Tim APIYI | Untuk diskusi teknis dan integrasi API, silakan kunjungi apiyi.com