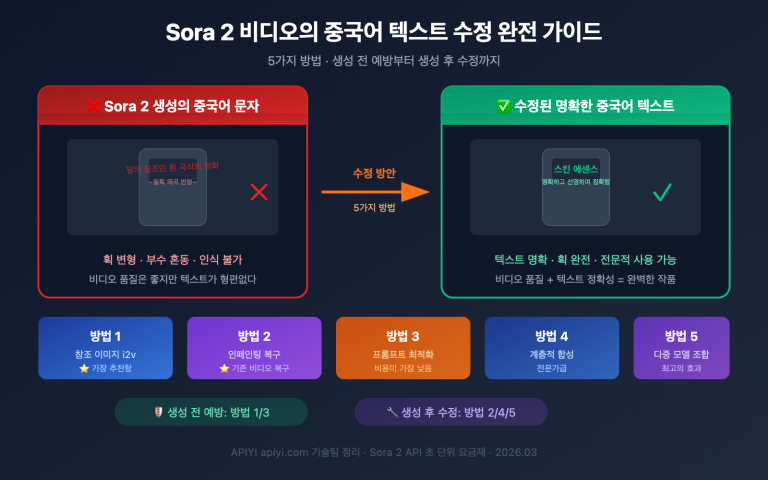
Gemini API를 사용하여 이미지 인식 서비스를 구축하는 많은 팀이 공통적으로 겪는 고민이 있습니다. 바로 gemini.google.com 웹 버전에서는 동일한 이미지와 프롬프트로도 모델이 세부 사항을 정확히 파악하고 구조화된 답변을 내놓는데, gemini-1.5-flash API로 전환하면 결과가 훨씬 거칠고 핵심 정보를 놓치는 경우가 많다는 점입니다. 이러한 "웹은 강력하고 API는 약하다"는 체감 차이는 모델 자체가 약해진 것이 아니라, 웹 버전과 API 사이의 엔지니어링 수준 차이에서 비롯됩니다.
이 글은 핵심 결론을 중심으로 전개됩니다. 웹 버전 Gemini는 프롬프트 최적화, 다단계 추론, 도구 호출 및 결과 검증을 자동으로 수행하는 종합 에이전트인 반면, API는 모델 그 자체를 호출하는 '날것'의 상태입니다. 이 차이를 이해하고 나면, 단순히 "프롬프트 수정"을 넘어선 6가지 API 성능 향상 기법을 통해 이미지 인식 결과의 품질을 웹 버전 수준으로 안정적으로 끌어올릴 수 있습니다.

왜 Gemini API의 이미지 인식 성능이 웹 버전보다 떨어질까요: 에이전트와 모델의 차이
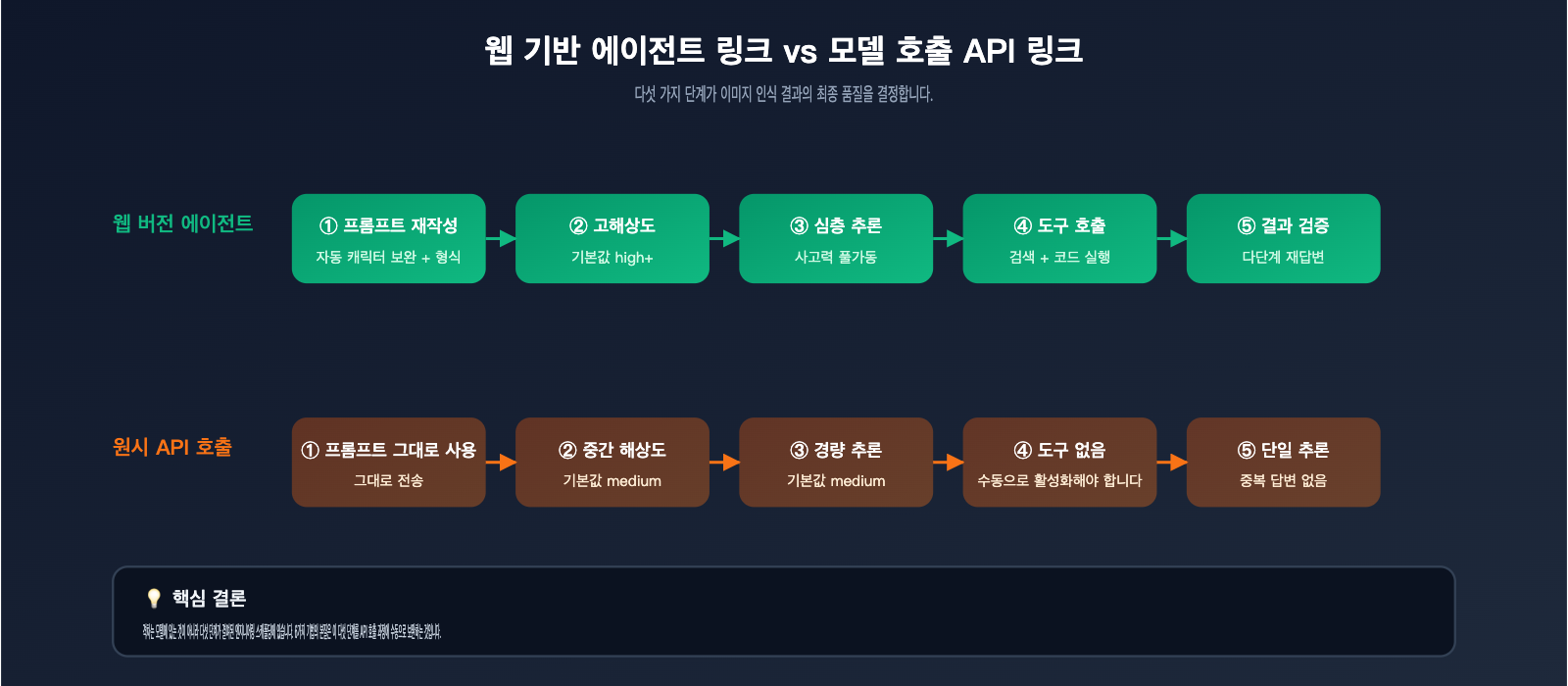
이 차이를 명확히 이해하려면 gemini.google.com에 이미지를 업로드하고 최종 답변을 받기까지 모델이 어떤 작업을 수행하는지 알아야 합니다. Google의 공개된 Agentic Vision 문서와 APIYI(apiyi.com)에서 관찰한 웹 버전 vs API 응답 차이를 보면, 웹 버전은 본질적으로 기초 모델을 중심으로 구축된 제품급 에이전트입니다. 이 에이전트는 사용자가 명시적으로 요구하지 않아도 최소 5가지 작업을 수행합니다.
- 프롬프트 자동 재작성: "이 사진을 인식해줘"라는 요청을 역할, 작업, 출력 형식이 포함된 완전한 지시문으로 보완합니다.
- 고해상도 처리: 내부적으로 더 높은 해상도 단계에서 이미지를 처리하여 세부 정보가 흐릿한 픽셀로 압축되지 않도록 합니다.
- 고강도 추론: 기본적으로 높은 추론 예산(thinking_level=high와 유사)을 사용하여 모델이 충분히 "생각"할 시간을 줍니다.
- 도구 호출: 필요 시 코드 실행, 웹 검색 등 내장 도구를 호출하여 교차 검증을 수행하고 세부 정보의 신뢰성을 확인합니다.
- 결과 검증: 출력 결과에 대해 포맷팅 및 "재답변" 판단을 수행하며, 답변이 모호할 경우 모델에게 다시 질문합니다.
반면, API를 직접 호출할 때는 이러한 5가지 작업이 자동으로 수행되지 않습니다. 즉, 완전한 기능을 갖춘 "모델"을 호출하고 있지만, 그 뒤를 받쳐주는 "엔지니어링 비계"가 없는 상태입니다. 아래 표는 두 방식의 주요 차이점을 정리한 것입니다.
| 비교 항목 | gemini.google.com 웹 버전 | gemini-1.5-flash API |
|---|---|---|
| 프롬프트 처리 | 자동 재작성, 역할 및 형식 보완 | 사용자 입력 그대로 전달 |
| 이미지 해상도 | 기본 고해상도 | 기본 중해상도 (수동 조절 필요) |
| 추론 예산 | 고강도, 제한 없음 | 기본 중강도 (수동 설정 가능) |
| 도구 호출 | 검색, 코드 실행 기본 연결 | 기본 비활성화 (명시적 활성화 필요) |
| 결과 검증 | 에이전트 다단계 검증 | 단일 추론, 검증 없음 |
| 비용 투명성 | 월간 구독제 포함 | 토큰당 과금 |
APIYI(apiyi.com)와 같은 통합 게이트웨이에서 동일한 이미지와 프롬프트를 사용하여 gemini-1.5-flash API, Claude 3.5 Sonnet, GPT-4o 등 여러 모델의 인식 결과를 비교해 보는 것을 추천합니다. 이를 통해 현재 작업이 모델 자체의 한계 때문인지, 아니면 엔지니어링 파이프라인의 문제인지 빠르게 판단할 수 있습니다.
Gemini API 识图技巧一:拉高 media_resolution 参数
Gemini 3 系列开始引入 media_resolution 参数,它直接控制 API 为图像分配多少 Token 来“看”。这个参数有 low、medium、high、ultra high 四档,默认通常是 medium。对识别小字、票据、电路图、UI 截图这类细节密集的图像,medium 往往不够,模型会把图像压缩到一个粗糙的特征图,导致细节丢失。
下表给出四档的实际差异,便于你按任务类型选择:
| 分辨率档位 | Token 开销 | 适用场景 | 典型问题 |
|---|---|---|---|
| low | 최저 | 썸네일, 로고 인식 | 작은 글씨 거의 유실 |
| medium(기본값) | 보통 | 일반 사진, 인물 | 디테일 흐림 |
| high | 높음 | 문서, 표, 영수증 | 정보 대부분 판독 가능 |
| ultra high | 최고 | 복잡한 도면, 밀집된 UI | 공식 웹사이트 인식 수준 |
이미지 인식 업무의 경우, 이 파라미터를 medium에서 high로 올리는 것만으로도 인식 정확도를 즉시 한 단계 높일 수 있습니다. 예산이 허용되고 작업 내용이 작은 글씨나 복잡한 표를 포함한다면, 바로 ultra high를 선택하는 것도 합리적인 방법입니다.
# APIYI를 통해 gemini-3.5-flash 호출, 미디어 해상도를 high로 명시적 지정
from google import genai
from google.genai import types
client = genai.Client(
api_key="YOUR_APIYI_KEY",
http_options={"base_url": "https://api.apiyi.com"}
)
resp = client.models.generate_content(
model="gemini-3.5-flash",
contents=[image_part, "이미지 내 모든 텍스트를 추출하여 표 형식으로 출력해줘"],
config=types.GenerateContentConfig(
media_resolution="MEDIA_RESOLUTION_HIGH"
)
)
print(resp.text)
APIYI(apiyi.com)에서 호출할 때는 파라미터가 하위 계층으로 그대로 전달되며 게이트웨이에서 재포장되지 않으므로, 공식 문서에 따라 안심하고 값을 전달하시면 됩니다.
Gemini API 识图技巧二:显式开启 thinking_level=high
Gemini 3.5 Flash는 thinking_level 파라미터를 도입하여 모델이 답변을 생성하기 전 내부 추론 깊이를 제어할 수 있게 했습니다. 이미지 인식 작업에서 "충분히 오래 생각하는 것"과 "꼼꼼하게 생각하는 것"은 디테일을 제대로 보느냐, 아니면 놓치느냐의 차이를 만듭니다. API 기본 설정은 품질보다는 속도에 맞춰져 있으므로, 이미지 인식 업무 시에는 이를 high로 설정하여 모델이 웹 버전처럼 공간 추론과 카운팅을 수행할 충분한 시간을 갖도록 하는 것이 좋습니다.
| thinking_level | 추천 상황 | 체감 차이 |
|---|---|---|
| low | 간단한 대화, 스타일 판단 | 속도 빠름, 인식 거침 |
| medium | 일반적인 질의응답 | 평균 수준 |
| high(이미지 인식 추천) | 문서, 영수증, 카운팅, 공간 추론 | 공식 웹사이트 체감 수준 |
공식 문서에서는 직관에 반하는 한 가지 포인트를 강조합니다. thinking_level=high를 사용하면 오히려 프롬프트를 더 직접적이고 간결하게 작성해야 하며, "단계별로 추론해줘", "다양한 상황을 고려해줘"와 같은 구식 Chain-of-Thought 방식은 피해야 합니다. 이러한 방식은 이전 모델들의 능력을 보완하기 위한 것이며, Gemini 3 시리즈에서는 오히려 "과도한 분석"을 유발할 수 있습니다.
🎯 파라미터 설정 제안:
media_resolution=HIGH와thinking_level=high를 이미지 인식 작업의 기본 조합으로 설정하여 APIYI(apiyi.com) 호출 템플릿에 저장해 두세요. 이후 업무 체감에 따라 ultra high나 low 쪽으로 미세 조정하면, 매 요청마다 파라미터를 반복해서 테스트할 필요가 없습니다.
Gemini API 이미지 인식 팁 3: 프롬프트를 user prompt가 아닌 system_instruction에 작성하세요
API를 사용할 때 흔히 하는 실수 중 하나는 역할 설정, 작업 설명, 출력 형식, 사용자 질문 등 모든 내용을 user prompt에 한꺼번에 집어넣는 것입니다. 이렇게 하면 모델이 매번 전체 문맥을 다시 읽어야 합니다. 반면, 웹 버전의 '시스템 프롬프트'는 캐시를 재사용할 수 있다는 장점이 있죠.
가장 좋은 방법은 '변하지 않는 지침'을 system_instruction에 넣는 것입니다.
config = types.GenerateContentConfig(
media_resolution="MEDIA_RESOLUTION_HIGH",
thinking_level="high",
system_instruction=(
"당신은 엄격한 이미지 분석 보조원입니다."
"답변할 때는 이미지에 명확하게 보이는 세부 정보만 인용하고, 근거 없는 추측은 하지 마세요."
"출력은 entities/attributes/text 필드로 고정된 구조화된 JSON 형식으로 작성하세요."
)
)
이렇게 하면 두 가지 이점이 있습니다. 첫째, 모델이 항상 일관된 규칙에 따라 답변하므로 결과가 더 안정적입니다. 둘째, System Prompt Caching이 활성화되면 입력 비용을 최대 10배까지 절감할 수 있어, 장기적인 이미지 인식 배치 작업에 매우 유용합니다. APIYI(apiyi.com) 관리자 페이지에서는 모델 ID별로 캐시 적중률을 확인할 수 있어 최적화 효과를 쉽게 모니터링할 수 있습니다.
Gemini API 이미지 인식 팁 4: 코드 실행(code execution)을 활성화하여 모델이 "이미지를 확대해서 보게" 하세요
Google은 Gemini 3 Flash의 Agentic Vision 발표에서 명확한 데이터를 제시했습니다. 기본 모델에 코드 실행 도구를 추가하면 이미지 인식 작업의 품질이 평균 5%~10% 향상된다는 점입니다. 원리는 모델이 내부적으로 파이썬 코드를 생성하여 이미지 자르기, 확대, 회전, 픽셀 읽기 등의 작업을 수행한 뒤, 처리된 하위 이미지를 다시 분석하는 방식입니다. 이는 웹 버전에서 기본적으로 수행하는 방식이기도 합니다.
API에서는 기본적으로 코드 실행이 활성화되어 있지 않으므로 명시적으로 선언해야 합니다.
config = types.GenerateContentConfig(
media_resolution="MEDIA_RESOLUTION_HIGH",
thinking_level="high",
tools=[types.Tool(code_execution=types.ToolCodeExecution())]
)
resp = client.models.generate_content(
model="gemini-3.5-flash",
contents=[image_part, "이미지 내의 모든 빨간색 버튼 개수를 세고 위치를 나열하세요"],
config=config
)
개수 세기, 공간 추론, 복잡한 UI 분석 등 공식적으로 '코드 실행 효과가 큰' 작업에 있어 가장 가성비 높은 최적화 방법입니다. APIYI(apiyi.com)에서 확인한 결과, 코드 실행을 활성화하면 전체적인 지연 시간(latency)이 다소 증가할 수 있습니다. 따라서 비동기 작업에는 기본적으로 활성화하고, 동기 작업에서는 필요에 따라 선택적으로 사용하는 것을 권장합니다.
Gemini API 识图技巧 5:大图请用 File API,别再用 base64 内联了
对于体积超过几 MB 的图像,很多团队习惯直接用 base64 编码将其嵌入到请求体中。这种做法在处理小图时确实方便,但当总请求大小超过 20MB 时,就会触发 Gemini 的限制。此时,部分图像会被系统静默压缩,导致识别质量明显下降。
官方给出的判定边界非常清晰:
| 이미지 크기 | 권장 전송 방식 | 이유 |
|---|---|---|
| 5MB 미만 | base64 인라인 | 가벼운 요청, 간편한 호출 |
| 5~20MB | File API 업로드 | 요청 크기 비대화 방지 |
| 20MB 초과 | File API 필수 | base64 인코딩 시 요청 파손 |
| 여러 번 재사용 | File API 권장 | 한 번 업로드 후 여러 번 참조하여 토큰 절약 |
File API의 또 다른 장점은 동일한 이미지를 여러 요청에서 재사용할 수 있어, 중복 업로드 비용을 아낄 수 있다는 점입니다. APIYI(apiyi.com) 게이트웨이를 사용하면 File API 엔드포인트가 동일한 인증 정보를 공유하므로, 이미지 업로드를 위해 별도의 Google Cloud 계정을 생성할 필요가 없습니다.

Gemini API 识图技巧六:自己搭一条 Agent 链路做多步验证
走完前 5 个技巧后,你的单次 API 调用效果已经非常接近官网体验了。但网页版还有一个杀手锏:多步验证。它会在生成回答后,利用第二次推理来校验关键事实,如果遇到不确定的回答,还会自动触发“重答”。这个能力在 API 中没有现成的开关,需要你自己搭建一条简单的 Agent 链路。
一个最小可用的两步链路是:
- 第一次调用:让
gemini-3.5-flash生成结构化识别结果(JSON 输出)。 - 第二次调用:将第一次的结果与原图同时回灌,询问模型:“基于这张图,下列结论是否每条都成立?”
如果第二次调用挑出任何“不成立”的字段,再触发第三次“重答”。这套链路在 APIYI (apiyi.com) 上可以直接用同一份 base_url 与 API 키를 串联起来,无需额外服务。对于识别准确率要求极高的业务(如合同识别、医疗影像辅助标注、安全合规审查),多步验证是将准确率从 90% 提升至 98% 的关键一步。
| 任务类型 | 建议链路 | 单步参数 |
|---|---|---|
| 通用识图问答 | 单步 | high + thinking_high |
| 文档抽取 | 单步 + JSON 校验 | ultra high + thinking_high |
| 复杂计数 | 两步 + code execution | high + thinking_high + tools |
| 高准确率业务 | 三步链路(识别 → 校验 → 重答) | ultra high + thinking_high + tools |
实战参数模板:把 6 个技巧串成一次可复用调用
为了方便你直接套用,下面提供一份“识图任务默认模板”,已经将前面 6 个技巧整合到位,非常适合作为大多数业务的起点:
from google import genai
from google.genai import types
client = genai.Client(
api_key="YOUR_APIYI_KEY",
http_options={"base_url": "https://api.apiyi.com"}
)
SYSTEM = (
"你是严谨的图像分析助手。仅引用图像中明确可见的内容,"
"不要凭空推断。输出严格 JSON,字段 entities/attributes/text。"
)
config = types.GenerateContentConfig(
media_resolution="MEDIA_RESOLUTION_HIGH",
thinking_level="high",
system_instruction=SYSTEM,
tools=[types.Tool(code_execution=types.ToolCodeExecution())],
response_mime_type="application/json"
)
resp = client.models.generate_content(
model="gemini-3.5-flash",
contents=[image_part, "按 SYSTEM 要求识别这张图"],
config=config
)
print(resp.text)
实际部署时,建议在 APIYI (apiyi.com) 侧将模板抽离成统一的 SDK 调用层,业务方只需传入图片与提问,参数由网关统一注入,避免每个业务都重复踩坑。

자주 묻는 질문(FAQ): Gemini API 이미지 인식과 웹 버전의 차이점
Q1: 이 매개변수들을 모두 설정하면 API가 웹 버전보다 여전히 성능이 떨어질까요?
대부분의 업무에서는 공식 웹사이트와 대등한 성능을 낼 수 있습니다. 다만, 매우 작은 글씨, 저조도 환경, 특수한 예술 스타일 이미지와 같은 고난도 작업에서는 여전히 약간의 차이가 발생할 수 있습니다. 웹 버전은 공개되지 않은 내부 강화 파이프라인을 추가로 호출하기 때문입니다. 이러한 시나리오에서는 APIYI(apiyi.com)에서 다른 업체의 비전 모델을 활용해 교차 검증을 수행하고, 가장 적합한 모델을 찾아보시는 것을 추천합니다.
Q2: thinking_level=high를 설정하면 비용이 두 배가 되나요?
내부 추론 토큰 사용량이 증가하지만, 출력 단계에만 영향을 미치며 이미지 인식 업무의 전체 비용에서는 보통 이미지 토큰이 더 큰 비중을 차지합니다. thinking을 high로 설정하여 얻는 정확도 향상은 증가하는 비용보다 훨씬 가치가 큽니다. 특히 사람이 직접 검수하는 과정을 대체하는 업무에서는 더욱 그렇습니다.
Q3: base_url은 어떻게 수정하나요? Google 공식 SDK를 사용 중입니다.
google-genai SDK는 http_options={"base_url": "https://api.apiyi.com"} 설정을 통해 요청을 APIYI(apiyi.com) 게이트웨이로 전환할 수 있습니다. API 키는 APIYI 백엔드에서 생성한 것을 사용하면 되며, 별도의 Google Cloud 프로젝트를 생성할 필요가 없습니다.
Q4: 프롬프트 최적화만으로 문제를 해결할 수 있나요?
프롬프트만 조정하는 것에는 명확한 한계가 있습니다. 해상도, 추론 깊이, 도구 호출과 같은 '모델 외부'의 역량까지 커버할 수는 없기 때문입니다. 본문의 6가지 팁 중 세 번째 항목만 프롬프트와 관련이 있으며, 나머지 5가지는 엔지니어링 차원의 레버리지입니다.
Q5: 웹 버전에서는 인식되는 '이미지 속 한글 워터마크'를 API에서는 자꾸 놓치는데 어떻게 하죠?
워터마크와 같은 세부 사항은 고해상도 설정과 코드 실행을 통한 크롭(잘라내기) 조합에 크게 의존합니다. media_resolution을 ultra high로 설정하고 code execution을 활성화한 뒤, 2단계 검증 링크를 통해 확인하면 보통 안정적으로 인식됩니다.
요약: 웹 버전의 엔지니어링 역량을 API 호출에 더하기
처음 질문으로 돌아가 보겠습니다. 왜 Gemini API의 이미지 인식 효과가 웹 버전보다 떨어질까요? 답은 모델이 약해진 것이 아니라, 웹 버전이 갖춘 엔지니어링 기반이 매우 두텁기 때문입니다. 직접 gemini-1.5-flash API를 호출할 때는 프롬프트 재작성, 해상도 단계, 추론 예산, 도구 호출, 결과 검증 등을 모두 직접 구현해야 합니다. 이 점을 이해하고 나면, 6가지 팁의 본질은 결국 "웹 버전이 대신 해주던 일을 여러분의 API 호출 체인으로 옮겨오는 것"임을 알 수 있습니다.
실무 적용 경로는 명확합니다. 먼저 media_resolution과 thinking_level을 최대로 높이고, 지시사항을 system_instruction으로 옮긴 뒤 캐싱을 활성화하세요. 복잡한 이미지 인식 작업에는 code execution을 켜고, 큰 이미지는 File API를 사용하며, 마지막으로 2~3단계 에이전트 체인을 통해 높은 정확도를 유지하세요. 이 조합을 적용한 뒤 APIYI(apiyi.com) 백엔드에서 적중률과 지연 시간을 비교해 보면, 대부분의 팀이 '웹 vs API' 간의 인식 성능 차이를 눈으로 구분하기 어려울 정도로 줄일 수 있을 것입니다.
📌 작성자: 본 문서는 APIYI(apiyi.com) 기술팀에서 정리했습니다. Gemini, Claude, GPT 시리즈 모델의 연동 실전 사례와 파라미터 튜닝 가이드는 APIYI 도움말 센터에서 확인하실 수 있습니다.