title: Kimi K2.5 Thinking 模式接入指南:开启深度推理与省钱秘籍
description: 详解如何通过 APIYI 平台调用 kimi-k2.5 并开启 enable_thinking 参数,享受低于官网八折的稳定价格,附 curl、Python、JavaScript 完整示例代码
작성자 주: APIYI 플랫폼을 통해 kimi-k2.5를 호출하고 enable_thinking 파라미터를 활성화하여 공식 홈페이지 대비 20% 이상 저렴한 가격으로 안정적으로 사용하는 방법을 상세히 설명합니다. curl, Python, JavaScript 예제 코드가 포함되어 있습니다.

Kimi K2.5의 Thinking(사고) 모드는 현재 오픈 소스 모델 중 가장 강력한 추론 능력을 자랑하는 기능 중 하나로, AIME 2025 수학 벤치마크에서 96.1%라는 놀라운 점수를 기록했습니다. 하지만 많은 개발자가 API 연동 시 "모델이 사고 과정을 출력하지 않는다"는 문제를 겪곤 합니다.
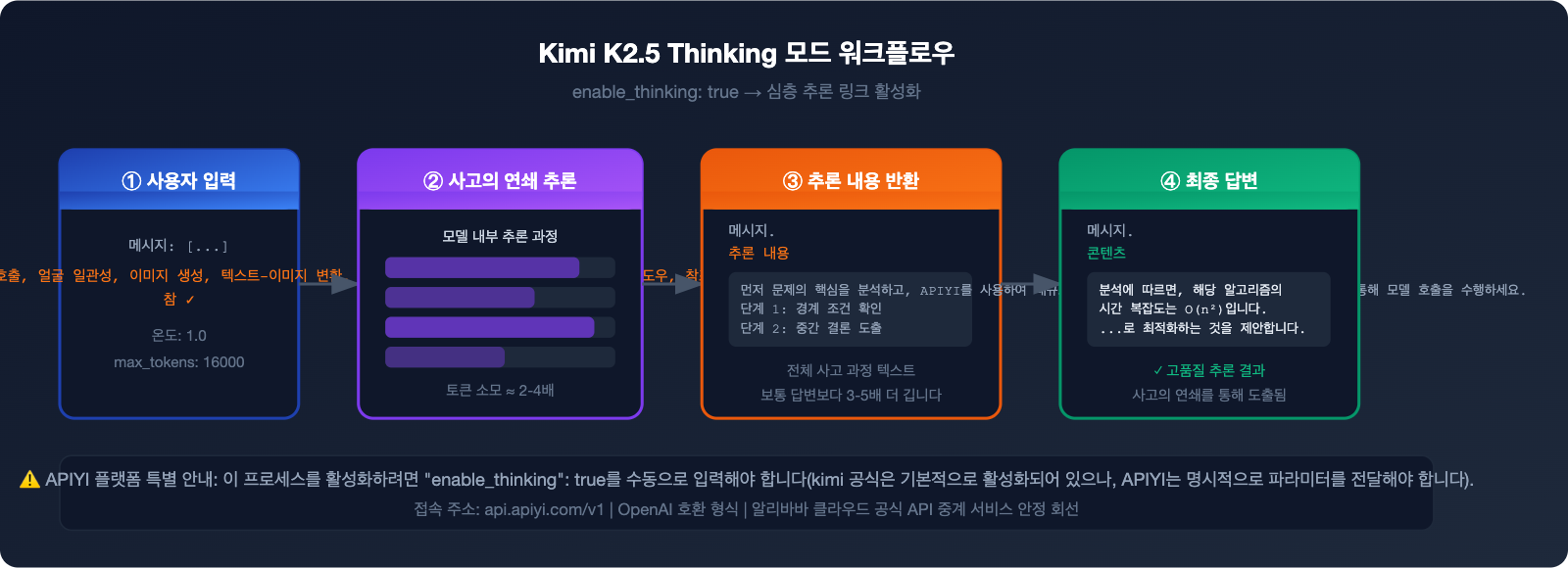
이는 APIYI 플랫폼에서 사고 모드를 활성화하려면 "enable_thinking": true 파라미터를 수동으로 추가해야 하기 때문입니다. 이번 글에서는 Kimi K2.5 사고 모드를 처음부터 끝까지 완벽하게 설정하는 방법을 안내해 드립니다.
🎯 핵심 가치: 이 글을 통해 kimi-k2.5 Thinking 모드의 전체 호출 방식을 익히고, APIYI를 통해 공식 홈페이지 대비 20% 이상 저렴한 가격으로 이 기능을 안정적으로 사용하는 방법을 확인해 보세요.
Kimi K2.5 Thinking 모드 핵심 요약
| 항목 | 설명 | 가치 |
|---|---|---|
| 활성화 파라미터 | "enable_thinking": true 추가 필요 |
심층 추론 능력 잠금 해제 |
| 권장 temperature | 1.0 (고정값) 설정 |
안정적인 사고 품질 보장 |
| 권장 max_tokens | ≥ 16000 | 사고 과정의 전체 출력 보장 |
| 가격 혜택 | 그룹가 0.88, 공식가 대비 20% 이상 절감 | 추론 비용 대폭 절감 |
| 안정성 | 알리바바 클라우드 공식 전환 수준 | 엔터프라이즈급 신뢰성 보장 |
💡 빠른 시작: APIYI 계정(apiyi.com)을 생성하고 충전하면 바로 kimi-k2.5를 호출할 수 있습니다. OpenAI 호환 인터페이스를 지원하므로 기존 코드 프레임워크를 수정할 필요가 없습니다.
Kimi K2.5란 무엇인가: 1조 파라미터 규모의 오픈 소스 추론 플래그십
Kimi K2.5는 Moonshot AI가 2026년 1월 27일에 발표한 모델로, 현재 오픈 소스 커뮤니티에서 가장 강력한 추론 능력을 갖춘 멀티모달 대규모 언어 모델 중 하나입니다.
Kimi K2.5 핵심 아키텍처 사양
| 사양 | 수치 | 설명 |
|---|---|---|
| 총 파라미터 | 1조(1T) | MoE 혼합 전문가 아키텍처 |
| 활성 파라미터 | 320억(32B) | 추론 시 실제 사용 |
| 컨텍스트 윈도우 | 256K 토큰 | 초장문 문서 처리 능력 |
| 전문가 수 | 384개 전문가 레이어 | MLA + MoE 듀얼 아키텍처 |
| 학습 데이터 | ~15조 토큰 | 텍스트 + 이미지 혼합 |
| 오픈 소스 상태 | 완전 오픈 소스 | HuggingFace에서 다운로드 가능 |
Kimi K2.5는 **다중 헤드 잠재 주의(MLA)**와 384개 전문가 MoE 구조를 채택했습니다. 총 1조 개의 파라미터를 유지하면서도 추론 시에는 320억 개의 파라미터만 활성화하여 성능과 비용 사이의 최적의 균형을 구현했습니다.
Kimi K2.5의 4가지 실행 모드
K2.5 Instant → 즉각적인 응답, 사고 과정 없음, 단순 작업에 적합
K2.5 Thinking → 심층 추론, reasoning_content 출력, 복잡한 문제에 적합
K2.5 Agent → 자율 작업 수행, 도구 호출 능력
K2.5 Agent Swarm → 멀티 에이전트 협업, 최대 100개의 하위 에이전트 병렬 실행
APIYI 플랫폼은 현재 K2.5 Thinking 모드를 지원하며, enable_thinking: true 파라미터를 통해 활성화하여 전체 추론 체인을 출력할 수 있습니다.
💡 사용 제안: APIYI apiyi.com을 통해 kimi-k2.5에 접속하는 것을 추천합니다. 안정적인 알리바바 클라우드 공식 중계 링크를 제공하므로 서비스 중단 걱정 없이 이용할 수 있습니다.
Kimi K2.5 성능 벤치마크: 사고(Thinking) 모드 실측 데이터
'Thinking' 모드를 활성화하면 Kimi K2.5의 추론 성능이 대폭 향상됩니다. 주요 벤치마크 데이터는 다음과 같습니다.
주요 벤치마크 성적
| 벤치마크 | Kimi K2.5 성적 | 비교 설명 |
|---|---|---|
| AIME 2025 (수학 추론) | 96.1% | 만점에 가까운 수준, 최고 수준의 수학 능력 |
| SWE-Bench Verified (코드) | 76.8% | 오픈소스 모델 중 선두권 |
| HLE-Full w/ tools (에이전트) | 4.7점 앞섬 | 도구 호출 작업 1위 |
| BrowseComp (웹 브라우징) | 60.6% / 78.4%* | *Agent Swarm 모드 기준 |
| 종합 지능 지수 | 47점 | 업계 평균 27점 |
참고: 위 데이터는 2026년 1월 Artificial Analysis Intelligence Index 평가 결과입니다.
Thinking 모드는 표준 모드에 비해 복잡한 수학, 다단계 추론, 코드 생성 등의 작업에서 30~50%의 뚜렷한 성능 향상을 보여줍니다. 다만, 토큰 소모량이 표준 모드의 2~4배에 달하므로, 비용 절감을 위해 max_tokens를 적절히 제어하는 것이 핵심입니다.
APIYI에서 Kimi K2.5 Thinking 모드 활성화하는 3단계
1단계: API 키 발급받기
APIYI 공식 홈페이지 apiyi.com에 접속하여 계정을 등록한 후 다음 단계를 진행하세요.
- 계정 등록 및 이메일 인증 완료
- '대시보드(控制台)' → 'API 키 관리(API Key 管理)'로 이동
- 새 API 키를 생성하고 복사하여 저장
🎯 가격 혜택: 100달러 충전 시 10달러 추가 증정, 그룹 가격 0.88(입력 토큰 기준)로 실제 사용 비용이 Kimi 공식 홈페이지 대비 20% 이상 저렴합니다. APIYI는 알리바바 클라우드 공식 전환 수준의 안정적인 회선과 기업급 신뢰성을 제공합니다.
2단계: 요청 파라미터 설정
Kimi K2.5 Thinking 모드를 활성화하려면 다음 세 가지 파라미터 설정이 중요합니다.
{
"model": "kimi-k2.5",
"enable_thinking": true,
"temperature": 1.0,
"max_tokens": 16000
}
⚠️ 중요: APIYI 플랫폼과 Kimi 공식 API의 파라미터 로직은 다릅니다.
- Kimi 공식: Thinking 모드가 기본 활성화되어 있으며, 필요 시 파라미터를 통해 비활성화해야 합니다.
- APIYI 플랫폼:
"enable_thinking": true를 직접 입력해야 활성화됩니다.
3단계: 요청 전송 및 사고 과정 확인
Thinking 모드 활성화 및 응답 파싱을 포함한 전체 호출 예시입니다.
curl 예시 (가장 빠른 확인 방법)
curl --location 'https://api.apiyi.com/v1/chat/completions' \
--header "Authorization: Bearer sk-당신의API_KEY" \
--header 'Content-Type: application/json' \
--data '{
"model": "kimi-k2.5",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "0.1 + 0.2가 컴퓨터에서 왜 0.3이 되지 않는지 단계별로 설명해줘."
}
],
"enable_thinking": true,
"temperature": 1.0,
"max_tokens": 16000
}'
Python 예시 (운영 환경 권장)
from openai import OpenAI
client = OpenAI(
api_key="sk-당신의API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="kimi-k2.5",
messages=[
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "이 코드의 시간 복잡도를 분석하고 최적화 제안을 해줘:\n\ndef find_duplicates(arr):\n result = []\n for i in range(len(arr)):\n for j in range(i+1, len(arr)):\n if arr[i] == arr[j] and arr[i] not in result:\n result.append(arr[i])\n return result"
}
],
extra_body={
"enable_thinking": True
},
temperature=1.0,
max_tokens=16000
)
# 사고 과정 파싱 (존재할 경우)
message = response.choices[0].message
# 사고 과정 출력 (reasoning_content 필드)
if hasattr(message, 'reasoning_content') and message.reasoning_content:
print("=== 사고 과정 ===")
print(message.reasoning_content)
print()
# 최종 답변 출력
print("=== 최종 답변 ===")
print(message.content)
JavaScript / Node.js 전체 예시 펼치기
import OpenAI from 'openai';
const client = new OpenAI({
apiKey: 'sk-당신의API_KEY',
baseURL: 'https://api.apiyi.com/v1',
});
async function callKimiThinking(userMessage) {
const response = await client.chat.completions.create({
model: 'kimi-k2.5',
messages: [
{
role: 'system',
content: 'You are a helpful assistant.',
},
{
role: 'user',
content: userMessage,
},
],
// extra_body를 통해 enable_thinking 파라미터 전달
// @ts-ignore
enable_thinking: true,
temperature: 1.0,
max_tokens: 16000,
});
const message = response.choices[0].message;
// 사고 과정 추출
const reasoningContent = message.reasoning_content;
if (reasoningContent) {
console.log('=== Thinking Process ===');
console.log(reasoningContent);
console.log();
}
// 최종 답변 추출
console.log('=== Final Answer ===');
console.log(message.content);
return {
thinking: reasoningContent,
answer: message.content,
};
}
// 사용 예시
callKimiThinking('소수가 무한히 많다는 것을 단계별로 증명해줘 (유클리드 증명)');
💡 연동 팁: 위 코드에서
base_url을https://api.apiyi.com/v1로 변경하기만 하면 OpenAI SDK와 완벽하게 호환되므로 추가 학습 비용이 들지 않습니다. APIYI apiyi.com은 하나의 키로 모든 주요 모델을 호출할 수 있습니다.
주요 파라미터 상세 설명: 오류 방지를 위한 올바른 설정법
파라미터 설정 대조표
| 파라미터 | 권장값 | 설명 | 잘못된 예시 |
|---|---|---|---|
model |
"kimi-k2.5" |
모델 식별자 | kimi-k2 또는 kimi-k2.5-thinking 사용 금지 |
enable_thinking |
true |
사고 모드 활성화 (APIYI 전용) | 이 파라미터가 없으면 추론 내용이 출력되지 않음 |
temperature |
1.0 |
공식 권장 고정값 | 0.7 등으로 설정 시 품질 불안정 발생 |
max_tokens |
≥ 16000 |
전체 출력 보장 | 너무 작게 설정하면 사고 내용이 잘림 |
stream |
false (초기 테스트) |
스트리밍/비스트리밍 모두 지원 | 스트리밍 시 reasoning 필드 별도 처리 필요 |
API 응답 구조 설명
{
"choices": [
{
"message": {
"role": "assistant",
"content": "최종 답변 내용...",
"reasoning_content": "모델의 사고 과정, 단계별 추론 포함..."
}
}
],
"usage": {
"prompt_tokens": 150,
"completion_tokens": 3200,
"total_tokens": 3350
}
}
reasoning_content 필드에는 전체 사고 체인 내용이 포함되어 있습니다. 보통 content 필드보다 3~5배 길며, 모델의 의사결정 과정을 이해하는 핵심 데이터입니다.
🎯 비용 절감 팁: thinking 모드 사용 시 토큰 소모량은 일반 모드의 약 2~4배입니다. APIYI(apiyi.com)를 통해 접속하시면 그룹 가격 0.88로 추론 비용을 대폭 절감할 수 있으며, 100달러 충전 시 10달러를 추가로 증정해 드립니다.
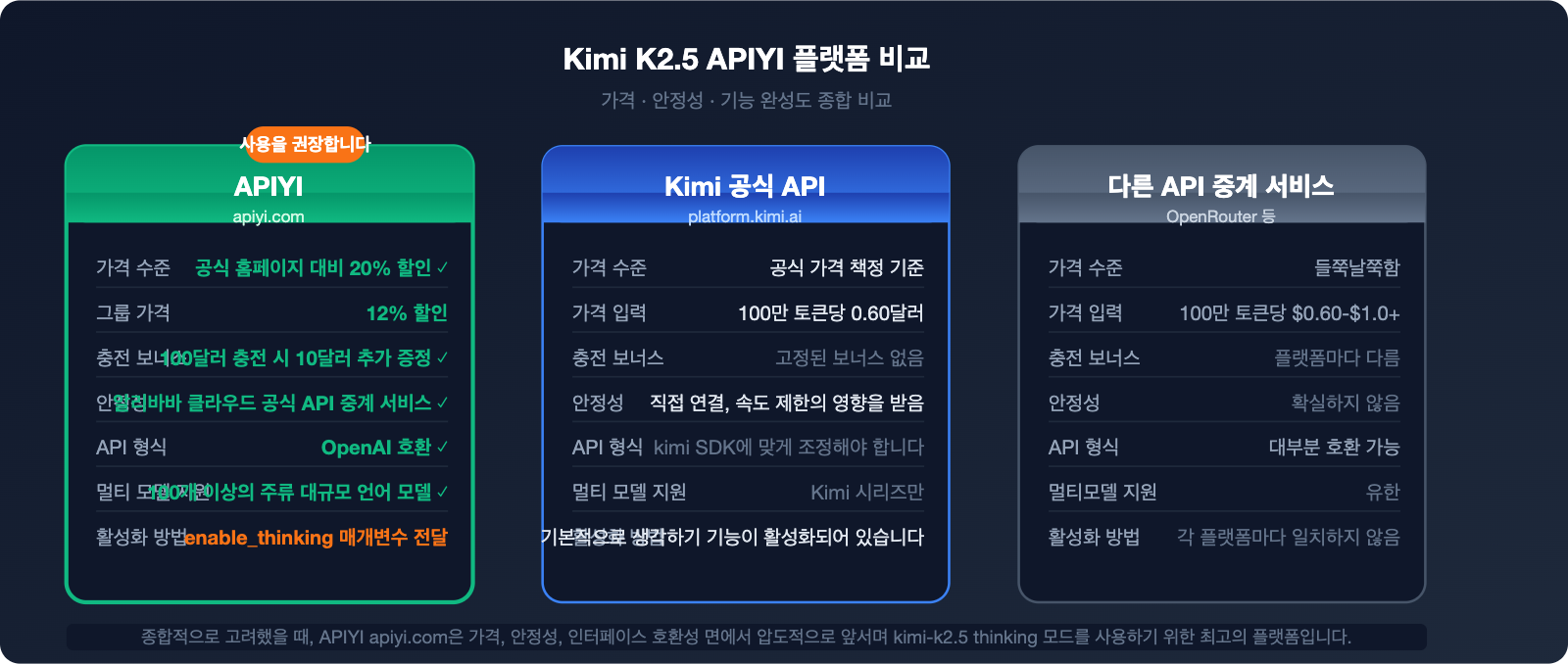
APIYI vs 공식 홈페이지: 가격 및 안정성 비교
플랫폼 비교 개요
| 비교 항목 | APIYI (apiyi.com) | Kimi 공식 API | 기타 API 중계 서비스 |
|---|---|---|---|
| 가격 수준 | 공식 대비 20% 저렴 (0.88 그룹가) | 공식 정가 | 천차만별 |
| 안정성 | 알리바바 클라우드 공식 중계 수준 | 직결, 속도 제한 영향 있음 | 불확실함 |
| 충전 혜택 | $100 충전 시 $10 증정 | 고정 혜택 없음 | 업체별 상이 |
| 인터페이스 호환성 | OpenAI 형식, 100% 호환 | Kimi SDK 적응 필요 | 대부분 호환 |
| 모델 지원 | 100개 이상의 주요 모델 | Kimi 시리즈만 지원 | 제한적 |
| 기업 지원 | 전담 고객센터 + 세금계산서 | 표준 지원 | 제한적 |
APIYI 가격 혜택 계산 예시
매월 kimi-k2.5 thinking 모드를 1,000회 호출한다고 가정할 때 (회당 평균 입력 3,000 토큰 + 출력 5,000 토큰):
# 입력 토큰 비용:
# 공식 가격 약 $0.60/1M → 1000회 × 3000 토큰 = 3M 토큰 → $1.80
# APIYI 그룹가 0.88 적용 → 약 $1.58
# 출력 토큰 비용 (추론 포함):
# 공식 가격 약 $2.50/1M → 1000회 × 5000 토큰 = 5M 토큰 → $12.50
# APIYI 그룹가 0.88 적용 → 약 $11.00
# 월간 절감액: 약 $1.72 + 충전 증정금으로 추가 약 10% 비용 절감 효과
💡 실제 혜택: APIYI의 '20% 할인'은 그룹 가격 할인(0.88)과 충전 증정금($100 충전 시 $10 증정, 즉 예산의 10% 추가 확보)이 결합된 결과입니다. 실제 종합 비용은 공식 홈페이지의 약 79-80% 수준입니다.
Kimi K2.5 Thinking 모드 최적 활용 사례
Thinking 모드 사용을 권장하는 경우
1. 복잡한 수학적 추론
# thinking 모드에 적합
prompt = "페르마의 마지막 정리를 n=3인 경우에 대해 증명하고 상세 단계를 제시해줘"
2. 코드 디버깅 및 최적화
# thinking 모드에 적합
prompt = """
다음 코드에는 숨겨진 동시성 버그가 있습니다. 찾아내서 수정해 주세요:
[복잡한 멀티스레드 코드 붙여넣기]
"""
3. 다단계 논리 분석
# thinking 모드에 적합
prompt = "이 사업 계획서의 논리적 허점을 분석하고 우선순위에 따라 나열해줘"
4. 과학적 원리 추론
# thinking 모드에 적합
prompt = "양자역학의 기본 원리로부터 수소 원자의 에너지 준위 공식을 유도해줘"
Thinking 모드가 필요 없는 경우
# 아래 상황에서는 일반 모드(enable_thinking 미사용)를 사용하면 토큰 비용을 50-70% 절감할 수 있습니다.
# 단순 질의응답
"오늘 날씨 어때?" # 추론 불필요
# 텍스트 번역
"다음 내용을 영어로 번역해줘: ..." # 추론 불필요
# 형식 변환
"다음 JSON 데이터를 보기 좋게 포맷팅해줘" # 추론 불필요
# 창의적 글쓰기
"봄에 관한 시를 한 편 써줘" # 심층 추론 불필요
🎯 사용 팁: 작업의 복잡도에 따라 모드를 유연하게 전환하는 것을 추천합니다. APIYI(apiyi.com)를 통해 접속하면 하나의 API 키로 kimi-k2.5(thinking 모드)와 다른 경량 모델을 자유롭게 호출하며 필요에 따라 혼합하여 사용할 수 있습니다.
스트리밍 출력: Thinking 모드의 실시간 응답 처리하기
Thinking 모드에서 스트리밍(streaming)을 사용할 때는 reasoning_content의 증분 조각을 별도로 처리해야 합니다.
from openai import OpenAI
client = OpenAI(
api_key="sk-당신의API_KEY",
base_url="https://api.apiyi.com/v1"
)
# 스트리밍 호출 예시
stream = client.chat.completions.create(
model="kimi-k2.5",
messages=[
{"role": "user", "content": "퀵 정렬 알고리즘의 최악의 경우 시간 복잡도를 분석해 주세요"}
],
extra_body={"enable_thinking": True},
temperature=1.0,
max_tokens=16000,
stream=True
)
thinking_buffer = []
answer_buffer = []
is_thinking = True
for chunk in stream:
delta = chunk.choices[0].delta
# 사고 내용 스트림 처리
if hasattr(delta, 'reasoning_content') and delta.reasoning_content:
thinking_buffer.append(delta.reasoning_content)
print(delta.reasoning_content, end='', flush=True)
# 최종 답변 스트림 처리
elif delta.content:
if is_thinking:
print("\n\n=== 최종 답변 ===\n")
is_thinking = False
answer_buffer.append(delta.content)
print(delta.content, end='', flush=True)
print() # 줄바꿈
💡 스트리밍 처리 핵심:
reasoning_content와content는 스트리밍에서 독립적인 필드입니다. 일반적으로reasoning_content가 먼저 완전히 출력된 후content가 출력되므로, 두 필드의 증분 데이터를 각각 모니터링해야 합니다.
자주 묻는 질문(FAQ)
Q1: 호출 후 reasoning_content 필드가 없는데, 사고 모드가 적용되지 않은 건가요?
A: 다음 세 가지를 확인해 보세요:
"enable_thinking": true파라미터가 올바르게 전달되었는지max_tokens가 16000 이상으로 설정되었는지- Python SDK 호출 시
extra_body={"enable_thinking": True}를 통해 파라미터를 전달했는지
먼저 curl로 직접 테스트하여 파라미터 형식이 올바른지 확인한 후 코드에 통합하는 것을 권장합니다. APIYI 고객센터 apiyi.com에서 기술 지원을 받으실 수 있습니다.
Q2: Thinking 모드에서 토큰 소모량이 너무 많은데, 비용을 어떻게 절감할까요?
A: 다음 방법으로 최적화할 수 있습니다:
- 단순 작업에는 Thinking 모드를 끕니다(
enable_thinking파라미터 미전달). max_tokens를 적절히 낮춥니다(최소 8000까지 가능하지만, 복잡한 추론 시 내용이 잘릴 수 있음).- 작업별로 모델을 분리합니다: 복잡한 추론은 kimi-k2.5 thinking을, 단순 작업은 gpt-4o-mini 등 경량 모델을 사용하세요.
- APIYI apiyi.com의 그룹 가격(0.88)을 통해 기본 비용을 절감하세요.
Q3: temperature를 반드시 1.0으로 설정해야 하나요?
A: 공식적으로 1.0 설정을 강력히 권장합니다. 이는 kimi-k2.5 thinking 모드에서 가장 좋은 성능을 내는 온도 파라미터입니다. 너무 낮게 설정하면(예: 0.7) 모델이 추론 시 지나치게 보수적이 되어 품질이 떨어질 수 있고, 너무 높게 설정하면(예: 1.5) 추론 체인이 일관성을 잃을 수 있습니다. 1.0을 사용하는 것이 가장 안전한 선택입니다.
Q4: APIYI의 kimi-k2.5는 공식 모델과 완전히 동일한가요?
A: 네, 그렇습니다. APIYI는 알리바바 클라우드 공식 전환 링크를 사용하므로 모델 가중치와 성능은 kimi 공식 모델과 완전히 동일합니다. 차이점은 파라미터 전달 방식뿐입니다(공식은 Thinking이 기본 활성화되어 있으나, APIYI는 enable_thinking: true를 수동으로 전달해야 함). 이는 API 중계 서비스의 표준적인 차이일 뿐, 모델 출력 품질에는 영향을 주지 않습니다.
요약: Kimi K2.5 Thinking 모드 핵심 포인트 복습
| 핵심 포인트 | 설명 |
|---|---|
| 활성화 파라미터 | 반드시 "enable_thinking": true를 전달해야 합니다 |
| 온도 설정 | temperature: 1.0으로 고정 사용 |
| 토큰 예산 | max_tokens ≥ 16000 |
| 응답 필드 | 사고 과정은 reasoning_content에, 답변은 content에 포함됨 |
| 접속 주소 | https://api.apiyi.com/v1 (OpenAI 호환) |
| 가격 혜택 | 공식 홈페이지 대비 20% 이상 저렴, $100 충전 시 $10 추가 증정 |
Kimi K2.5는 AIME 수학 추론(96.1%), 코드 생성(SWE-Bench 76.8%) 등 핵심 벤치마크에서 뛰어난 성능을 보여주며, 특히 사고 모드는 다단계 추론이 필요한 복잡한 작업을 처리하는 데 매우 적합합니다.
🎯 지금 바로 경험해보세요: APIYI 공식 홈페이지 apiyi.com에 접속하여 계정을 생성하고 API 키를 발급받으세요. 5분 안에 kimi-k2.5 thinking 모드 연동을 완료할 수 있습니다. 100달러 충전 시 10달러 보너스를 제공하며, 그룹 할인까지 더해지면 Kimi 공식 홈페이지 대비 20% 이상 저렴한 비용으로 이용 가능합니다.
본 게시물은 APIYI 기술 팀에서 작성했습니다 | 데이터 출처: Moonshot AI 공식 문서 및 Artificial Analysis 평가 보고서(2026년 1월)
기술 지원이 필요하시면 APIYI 고객 센터(help.apiyi.com)를 방문해 주세요.