Qwen3.6-Plus를 사용해 본 개발자라면 누구나 공감할 거예요. OpenRouter에서 이 모델을 호출할 때 429 Too Many Requests 오류는 거의 일상이나 다름없죠. 분명 비용을 지불했고 무료 사용자도 아닌데, 도대체 왜 이렇게까지 제한을 걸어두는지 답답할 때가 많습니다.
핵심 가치: 이 글에서는 Qwen3.6-Plus의 429 오류 근본 원인을 심층 분석하고, 실질적으로 적용 가능한 3가지 해결책을 제시합니다. 또한, 알리바바 클라우드 공식 채널을 통해 안정적이고 저렴하게 API를 호출하는 방법을 공유합니다.
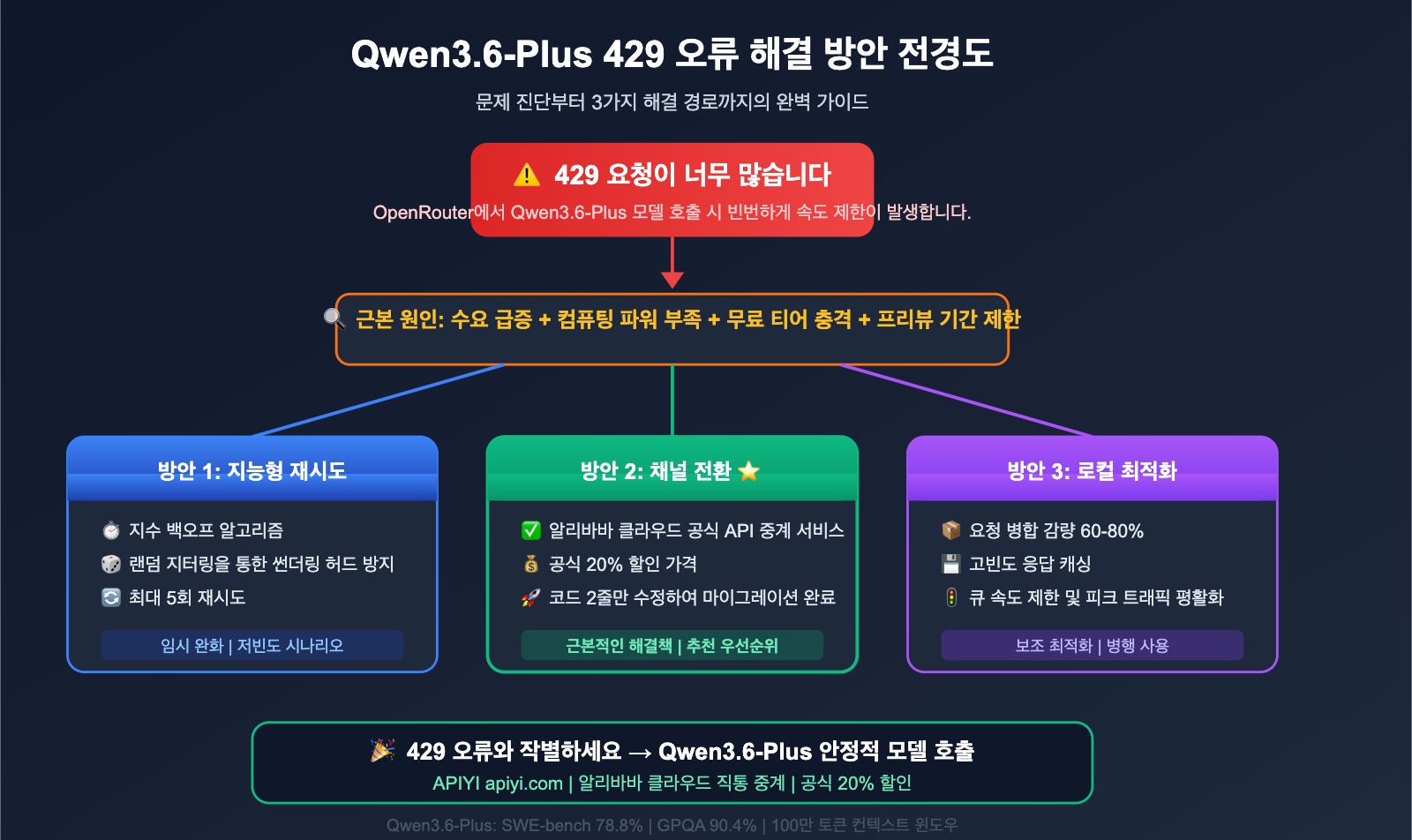
Qwen3.6-Plus 429 오류 핵심 요약
| 요점 | 설명 | 개발자 이점 |
|---|---|---|
| 429 원인 분석 | 수요 폭증 + 무료 계정 남용 + 컴퓨팅 자원 배분 정책 | 문제의 본질을 파악하고 무작정 재시도하지 않음 |
| 3가지 해결책 | 재시도 전략 / 채널 전환 / 공식 직통 연결 | 상황에 맞는 최적의 경로 선택 |
| 성능 테스트 | Qwen3.6-Plus 채널별 지연 시간 비교 | 가장 안정적인 접속 방식 선택 |
| 코드 예제 | Python/Node.js 즉시 실행 가능 | 5분 만에 마이그레이션 완료 |
Qwen3.6-Plus가 인기 있는 이유
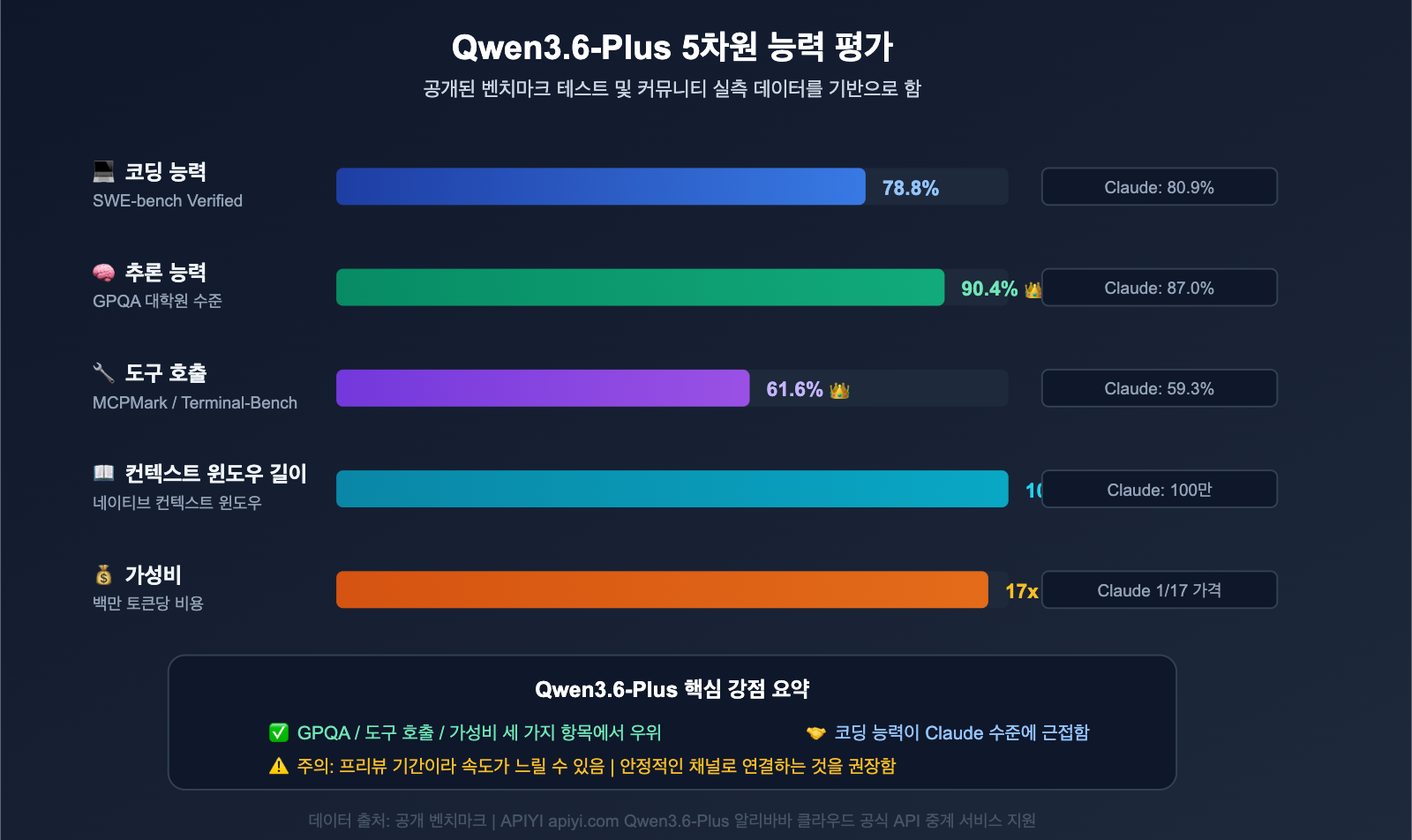
Qwen3.6-Plus는 알리바바 통이천문(通义千问) 팀이 2026년 4월에 출시한 플래그십 모델로, Claude Opus 4.5 및 GPT-5.4와 직접 경쟁합니다. 인기가 많은 이유는 간단합니다. 성능은 강력하고 가격은 저렴하기 때문이죠.
| 벤치마크 | Qwen3.6-Plus | Claude Opus 4.5 | GPT-5.4 |
|---|---|---|---|
| SWE-bench Verified | 78.8% | 80.9% | 76.2% |
| Terminal-Bench 2.0 | 61.6% | 59.3% | 57.8% |
| GPQA (대학원 수준 과학) | 90.4% | 87.0% | 88.1% |
| MCPMark (도구 호출) | 48.2% | 45.6% | 43.9% |
| 컨텍스트 윈도우 | 100만 토큰 | 100만 토큰 | 25.6만 토큰 |
| 최대 출력 | 65,536 토큰 | 32,000 토큰 | 16,384 토큰 |
Terminal-Bench와 GPQA 같은 핵심 벤치마크에서 Qwen3.6-Plus는 Claude Opus 4.5를 능가하면서도, 공식 API 가격은 Claude의 약 1/17 수준입니다. 이러한 가성비가 개발자들의 수요를 폭발시켰고, 바로 이것이 429 문제의 근본 원인이기도 합니다.
Qwen3.6-Plus 429 오류 심층 분석
429 오류란 무엇인가요?
HTTP 429 상태 코드는 명확한 의미를 담고 있습니다. 바로 Too Many Requests(요청이 너무 많음)입니다. 서버가 단위 시간 내에 처리할 수 있는 능력을 초과하거나 미리 설정된 제한을 넘어서는 요청을 받았을 때 발생하는 오류예요.
일반적인 429 오류 응답은 다음과 같습니다:
{
"error": {
"code": 429,
"message": "Rate limit exceeded. Please slow down your requests.",
"metadata": {
"provider_name": "Qwen",
"raw": "{\"error\":{\"message\":\"Rate limit reached\",\"type\":\"rate_limit_error\"}}"
}
}
}
OpenRouter에서 Qwen3.6-Plus 429 오류가 자주 발생하는 4가지 이유
이유 1: 수요가 공급을 크게 초과
Qwen3.6-Plus는 가성비가 매우 뛰어납니다. 공식 API 입문용 가격이 100만 토큰당 약 $0.29로, Claude Opus 4.5의 1/17 수준이죠. 수많은 개발자가 몰리고 있지만, 중계 플랫폼인 OpenRouter가 알리바바 클라우드로부터 확보한 연산 자원(쿼터)은 한정되어 있기 때문입니다.
이유 2: 무료 티어 사용자의 과도한 점유
OpenRouter는 qwen/qwen3.6-plus:free 모델을 제공하여 비용 부담 없는 사용자를 대거 유입시켰습니다. 이러한 무료 요청과 유료 요청이 동일한 백엔드 자원 풀을 공유하면서, 유료 사용자까지 함께 피해를 보는 상황이 발생합니다.
이유 3: 프리뷰 기간의 보수적인 자원 할당
Qwen3.6-Plus는 현재 프리뷰 단계(3월 30일 프리뷰 버전 출시, 4월 2일 정식 출시)에 있습니다. 알리바바 클라우드는 프리뷰 기간 동안 서드파티 플랫폼에 대한 자원 할당을 보수적으로 운영하며, 자사 플랫폼(DashScope / Bailian)의 서비스 품질을 우선적으로 보장합니다.
이유 4: 모델 자체의 추론 속도 병목
커뮤니티 테스트에 따르면 Qwen3.6-Plus의 처리량은 Claude Opus 4.6의 약 3배에 달하지만, 실제 사용 환경에서 100만 토큰 컨텍스트 윈도우와 MoE 아키텍처가 복잡한 에이전트 작업을 처리할 때는 응답 지연이 여전히 높은 편입니다. 즉, 각 요청이 GPU를 점유하는 시간이 길어지므로 단위 시간당 처리할 수 있는 총 요청 수가 줄어들게 됩니다.

🎯 핵심 통찰: 429 오류는 코드의 문제가 아니라 수급 불균형 때문입니다. 무한 재시도보다는 공급이 원활한 채널로 변경하는 것이 해결책입니다. APIYI(apiyi.com)를 통해 알리바바 클라우드 공식 직결 채널을 이용하면 OpenRouter의 속도 제한 문제를 효과적으로 피할 수 있습니다.
Qwen3.6-Plus 429 오류 해결책 1: 지능형 재시도 전략
지수 백오프(Exponential Backoff) 재시도
채널을 당장 변경하기 어려운 경우, 합리적인 재시도 전략으로 429 문제를 완화할 수 있습니다(근본적인 해결은 아닙니다).
import openai
import time
import random
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # APIYI 통합 인터페이스, 알리바바 클라우드 공식 직결
)
def call_qwen36_with_retry(messages, max_retries=5):
"""지수 백오프를 적용한 Qwen3.6-Plus 호출"""
for attempt in range(max_retries):
try:
response = client.chat.completions.create(
model="qwen3.6-plus",
messages=messages,
max_tokens=4096
)
return response.choices[0].message.content
except openai.RateLimitError as e:
if attempt == max_retries - 1:
raise
# 지수 백오프: 2^attempt 초 대기 + 랜덤 지터(Jitter)
wait_time = (2 ** attempt) + random.uniform(0, 1)
print(f"429 제한 발생, {attempt+1}번째 재시도, {wait_time:.1f}초 대기 중...")
time.sleep(wait_time)
# 사용 예시
result = call_qwen36_with_retry([
{"role": "user", "content": "이 코드의 성능 병목 현상을 분석해줘"}
])
print(result)
재시도 전략 파라미터 제안
| 파라미터 | 권장 값 | 설명 |
|---|---|---|
| 최대 재시도 횟수 | 3-5회 | 5회를 넘어가면 채널 자체가 불안정한 것임 |
| 초기 대기 시간 | 1-2초 | 너무 짧으면 효과가 없고, 너무 길면 비효율적임 |
| 백오프 배수 | 2배 | 지수 백오프는 업계 표준 방식 |
| 랜덤 지터(Jitter) | 0-1초 | '스탬피드 현상(Thundering Herd)' 방지 |
| 최대 타임아웃 | 30초 | 단일 요청 대기 시간은 30초를 넘기지 않음 |
재시도 전략의 한계
분명히 알아두어야 할 점은 재시도는 진통제일 뿐, 치료제가 아니라는 것입니다. OpenRouter의 Qwen3.6-Plus 백엔드가 지속적으로 과부하 상태라면 재시도 전략의 성공률은 급격히 떨어집니다. 더 근본적인 해결책은 공급이 충분한 API 채널로 전환하는 것입니다.
Qwen3.6-Plus 429 오류 해결 방법 2: API 채널 변경
왜 재시도보다 채널 변경이 더 효과적일까요?
OpenRouter에서 429 오류가 빈번하게 발생하는 근본적인 원인은 해당 채널의 Qwen3.6-Plus 연산 할당량이 부족하기 때문입니다. 알리바바 클라우드(阿里云) 연산 자원에 직접 연결되는 채널로 변경하면 문제를 근본적으로 해결할 수 있습니다.
Qwen3.6-Plus API 채널 비교
| 채널 | 안정성 | 가격 (입력/백만 토큰) | 429 빈도 | 데이터 수집 |
|---|---|---|---|---|
| OpenRouter Free | 낮음 | 무료 | 매우 높음 | 예 (학습 데이터) |
| OpenRouter Paid | 보통 | ~$0.29 | 빈번 | 예 (미리보기 기간) |
| 알리바바 백련(百炼) | 높음 | ¥2.00 | 낮음 | 약관 확인 필요 |
| APIYI (알리바바 직결) | 높음 | 공식가 20% 할인 | 낮음 | 아니요 |
💡 선택 제안: 애플리케이션의 안정성이 중요하다면 APIYI(apiyi.com)를 통해 Qwen3.6-Plus를 연동하는 것을 추천합니다. 이 플랫폼은 알리바바 클라우드 공식 직결 채널을 사용하며, 가격은 공식가의 80% 수준(그룹 가격 0.88 할인 + 100달러 충전 시 10달러 증정)입니다. 또한 OpenRouter의 속도 제한 문제도 피할 수 있습니다.
OpenRouter에서 APIYI로 전환 시 코드 2줄만 수정하세요
전환 비용은 매우 낮습니다. base_url과 api_key만 수정하면 됩니다:
import openai
# ❌ 이전: OpenRouter (잦은 429 오류)
# client = openai.OpenAI(
# api_key="sk-or-v1-xxxx",
# base_url="https://openrouter.ai/api/v1"
# )
# ✅ 현재: APIYI 알리바바 직결 (안정적, 429 오류 없음)
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="qwen3.6-plus",
messages=[
{"role": "system", "content": "당신은 전문적인 코드 리뷰 어시스턴트입니다."},
{"role": "user", "content": "이 SQL 쿼리의 성능을 최적화해 주세요."}
],
max_tokens=8192
)
print(response.choices[0].message.content)
Node.js 버전:
import OpenAI from 'openai';
const client = new OpenAI({
apiKey: 'YOUR_APIYI_KEY',
baseURL: 'https://api.apiyi.com/v1' // APIYI 통합 인터페이스
});
const response = await client.chat.completions.create({
model: 'qwen3.6-plus',
messages: [
{ role: 'user', content: '이 코드의 시간 복잡도를 분석해 주세요.' }
],
max_tokens: 4096
});
console.log(response.choices[0].message.content);
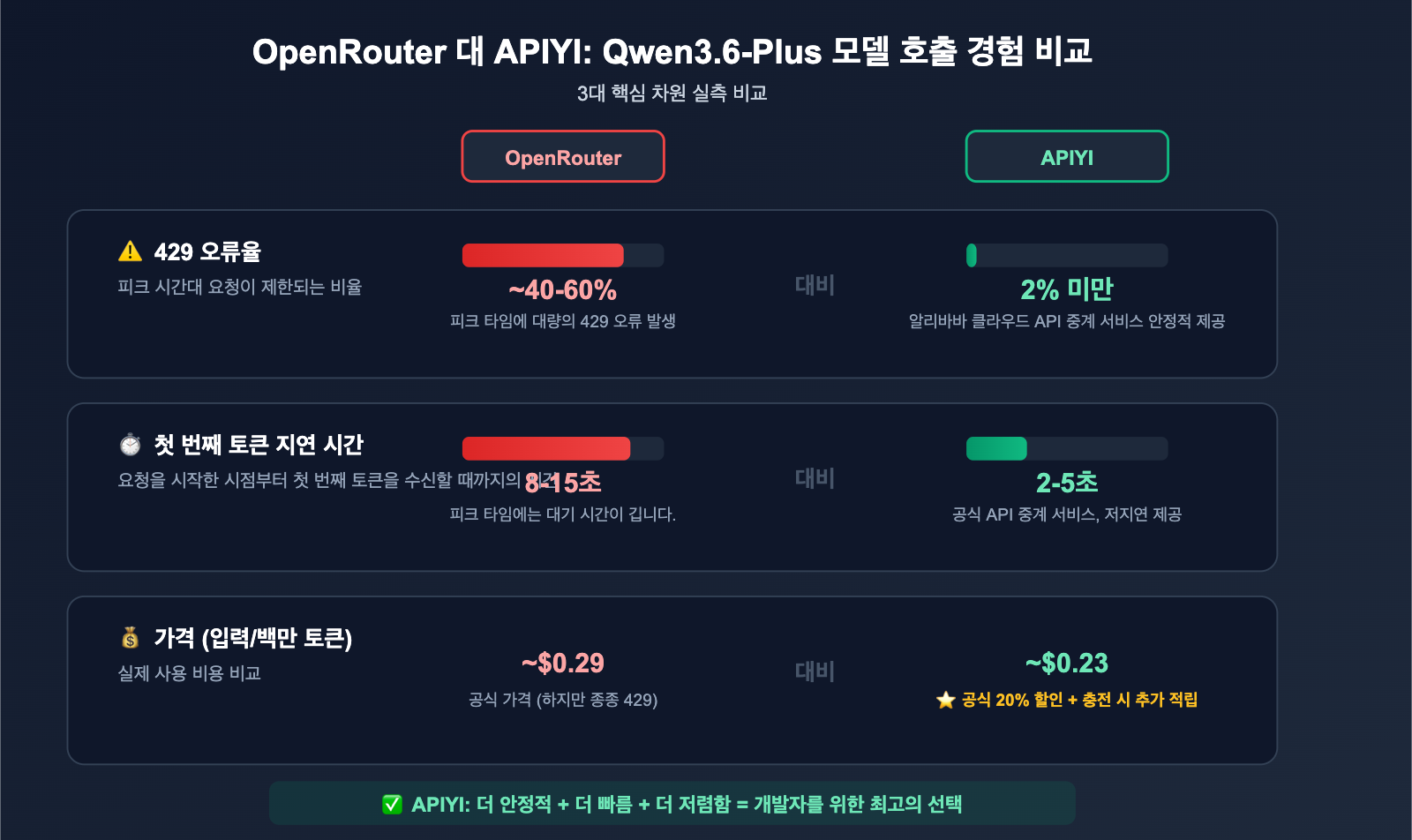
Qwen3.6-Plus 429 오류 해결 방법 3: 로컬 요청 최적화
불필요한 API 호출 줄이기
채널 변경 외에도 요청 방식을 최적화하면 429 오류 발생 확률을 낮출 수 있습니다:
1. 요청 병합
# ❌ 비효율: 건별 전송
for item in data_list:
response = client.chat.completions.create(
model="qwen3.6-plus",
messages=[{"role": "user", "content": f"분석: {item}"}]
)
# ✅ 효율: 배치 병합
batch_content = "\n".join([f"{i+1}. {item}" for i, item in enumerate(data_list)])
response = client.chat.completions.create(
model="qwen3.6-plus",
messages=[{"role": "user", "content": f"다음 내용을 순서대로 분석해 주세요:\n{batch_content}"}],
max_tokens=16384
)
2. 고빈도 응답 캐싱
import hashlib
import json
_cache = {}
def cached_qwen_call(prompt, model="qwen3.6-plus"):
cache_key = hashlib.md5(f"{model}:{prompt}".encode()).hexdigest()
if cache_key in _cache:
return _cache[cache_key]
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}]
)
result = response.choices[0].message.content
_cache[cache_key] = result
return result
3. 요청 큐 속도 제한
| 최적화 전략 | 효과 | 적용 시나리오 |
|---|---|---|
| 요청 병합 | 요청량 60-80% 감소 | 대량 데이터 처리 |
| 응답 캐싱 | 동일 요청 시 API 호출 0회 | 반복 조회 시나리오 |
| 큐 속도 제한 | 요청 피크 평탄화 | 고동시성 애플리케이션 |
| 폴백 전략 | 429 발생 시 소형 모델로 자동 전환 | 지연 시간에 민감한 서비스 |
🔧 기술 제안: 위 로컬 최적화 전략을 안정적인 API 채널과 함께 사용하면 효과가 극대화됩니다. APIYI(apiyi.com)를 통해 Qwen3.6-Plus를 연동하고, 요청 병합 및 캐싱 전략을 결합하면 안정성을 확보하면서 비용을 더욱 절감할 수 있습니다.
Qwen3.6-Plus 모델 속도 저하 원인 분석
Qwen3.6-Plus 응답이 가끔 느린 이유
많은 개발자분들이 429 에러가 발생하지 않음에도 불구하고 Qwen3.6-Plus의 응답 속도가 "이유 없이 느리다"고 피드백을 주시곤 합니다. 이는 특정 사례가 아니며, 기술적인 이유가 존재합니다.
1. MoE 아키텍처의 추론 오버헤드
Qwen3.6-Plus는 혼합 전문가(MoE) 아키텍처를 채택하고 있습니다. MoE는 학습 비용을 크게 낮출 수 있지만, 추론 단계에서는 라우팅 결정과 전문가 전환 과정에서 추가적인 오버헤드가 발생합니다. 특히 긴 컨텍스트를 처리할 때 MoE 아키텍처의 추론 효율은 동일한 파라미터 수의 Dense 모델보다 낮을 수 있습니다.
2. 100만 토큰 컨텍스트의 메모리 압박
100만 토큰의 컨텍스트 윈도우는 Qwen3.6-Plus의 핵심 셀링 포인트이지만, 이는 곧 KV 캐시가 차지하는 GPU 메모리가 엄청나다는 것을 의미합니다. 여러 사용자가 동시에 긴 컨텍스트 요청을 보낼 경우 GPU 메모리가 병목 현상을 일으켜 추론 속도가 현저히 떨어지게 됩니다.
3. 프리뷰 기간의 제한된 컴퓨팅 자원
Qwen3.6-Plus는 현재 프리뷰 단계입니다. 알리바바 클라우드는 이 단계에서 보통 정식 출시 때와 같은 규모의 컴퓨팅 자원을 투입하지 않습니다. 실제 사용 패턴을 관찰한 후 점진적으로 용량을 확장할 가능성이 높습니다.
4. Always-On 추론 체인의 추가 토큰 소모
Qwen3.6-Plus는 기본적으로 Always-On Chain-of-Thought 추론 모드가 활성화되어 있습니다. 이는 모델이 매 응답마다 내부 사고 과정을 생성한다는 뜻이며, 실제로 생성되는 토큰 수가 최종 출력보다 훨씬 많습니다. 이러한 '숨겨진 토큰'들이 추가적인 추론 시간을 차지하게 됩니다.
채널별 지연 시간 실측 참고
| 채널 | 첫 토큰 지연 시간 | 처리량 (Token/s) | 비고 |
|---|---|---|---|
| OpenRouter (피크) | 8-15s | 15-25 | 429 에러 빈번 |
| OpenRouter (저점) | 3-5s | 30-50 | 새벽 시간대 |
| 알리바바 백련(百炼) | 2-4s | 40-60 | 국내 직결 |
| APIYI (직접 중계) | 2-5s | 35-55 | 해외 안정적 접속 |
💰 비용 팁: Qwen3.6-Plus의 속도는 채널과 부하에 따라 차이가 큽니다. 지연 시간에 민감하시다면 APIYI(apiyi.com)를 통해 직접 테스트해보시는 것을 권장합니다. 플랫폼에서 제공하는 알리바바 클라우드 공식 직결 채널을 이용하면 20% 할인된 가격으로 더 안정적인 응답 속도를 경험할 수 있습니다.
Qwen3.6-Plus 빠르게 시작하기
APIYI를 사용하여 Qwen3.6-Plus 호출하는 전체 예제
import openai
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
# 기본 대화
response = client.chat.completions.create(
model="qwen3.6-plus",
messages=[
{"role": "system", "content": "당신은 숙련된 파이썬 개발 전문가입니다."},
{"role": "user", "content": "고성능 비동기 크롤러 프레임워크를 작성해줘."}
],
max_tokens=8192,
temperature=0.7
)
print(response.choices[0].message.content)
스트리밍 출력 전체 코드 보기
import openai
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
# 스트리밍 출력 - 실시간 피드백이 필요한 상황에 적합
stream = client.chat.completions.create(
model="qwen3.6-plus",
messages=[
{"role": "system", "content": "당신은 숙련된 아키텍트입니다."},
{"role": "user", "content": "백만 건의 동시 접속을 지원하는 메시지 큐 시스템을 설계해줘."}
],
max_tokens=16384,
temperature=0.7,
stream=True
)
for chunk in stream:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="", flush=True)
print() # 줄바꿈
🚀 빠른 시작: APIYI(apiyi.com) 플랫폼을 통해 API 키를 발급받아 Qwen3.6-Plus를 호출하는 것을 추천합니다. 가입 즉시 체험 가능하며, 100달러 충전 시 10달러 추가 증정 혜택과 함께 Qwen3.6-Plus를 공식 가격 대비 20% 할인된 가격으로 이용할 수 있습니다.
Qwen3.6-Plus 적용 시나리오 및 모델 선정 가이드
Qwen3.6-Plus가 특히 적합한 시나리오
| 적용 시나리오 | 추천 이유 | 대체 솔루션 |
|---|---|---|
| 에이전트 자동화 | Terminal-Bench 61.6% 기록, 네이티브 도구 호출 지원 | Claude Opus 4.5 |
| 코드 리뷰/수정 | SWE-bench 78.8%, Claude 수준의 성능 | Claude Opus 4.5 |
| 과학적 추론 | GPQA 90.4% 전체 1위 | GPT-5.4 |
| 긴 문서 처리 | 100만 토큰 컨텍스트 윈도우 | Gemini 2.5 Pro |
| 비용 효율성 | Claude 대비 약 1/17 가격 | DeepSeek V3 |
주의가 필요한 시나리오
- 지연 시간에 극도로 민감한 실시간 애플리케이션: Qwen3.6-Plus의 MoE 아키텍처는 긴 컨텍스트 처리 시 지연 시간이 다소 길어질 수 있습니다.
- 운영 환경의 핵심 경로: 프리뷰 단계의 모델이므로 예기치 않은 동작 변경이 발생할 수 있습니다.
- 엄격한 SLA 보장이 필요한 경우: 프리뷰 기간에는 공식적인 SLA가 제공되지 않습니다.
🎯 선정 가이드: 여러 모델을 동시에 사용해야 하는 프로젝트라면 APIYI(apiyi.com) 플랫폼을 통해 통합 관리하는 것을 추천합니다. 이 플랫폼은 Qwen3.6-Plus, Claude, GPT 등 주요 모델의 OpenAI 호환 인터페이스를 지원하며, 하나의 API 키로 다양한 모델을 전환할 수 있어 상황에 맞춰 유연하게 운영할 수 있습니다.
Qwen3.6-Plus 429 오류 관련 자주 묻는 질문
Q1: OpenRouter에서 결제했는데 왜 여전히 429 오류가 발생하나요?
OpenRouter는 유료 사용자와 무료 사용자가 백엔드 연산 자원을 공유하기 때문입니다. 유료 사용자라 하더라도 전체 요청량이 OpenRouter가 알리바바 클라우드로부터 확보한 연산 할당량을 초과하면 제한이 걸릴 수 있습니다. 해결책은 알리바바 클라우드 공식 직결 채널인 APIYI(apiyi.com)와 같이 공급이 충분한 채널로 전환하는 것입니다.
Q2: Qwen3.6-Plus의 429 오류는 개선될까요?
알리바바 클라우드의 자원 증설과 모델의 정식 GA(General Availability)가 진행됨에 따라 429 문제는 점차 완화될 것으로 보입니다. 하지만 OpenRouter와 같은 다중 중계 플랫폼은 상위 공급업체의 자원 배분에 제약이 있을 수밖에 없습니다. 서비스 안정성이 중요하다면 중계 플랫폼보다는 알리바바 클라우드 연산 자원을 직접 연결하는 채널을 사용하는 것을 권장합니다.
Q3: APIYI의 Qwen3.6-Plus와 OpenRouter의 차이점은 무엇인가요?
가장 큰 차이는 연산 자원의 출처입니다. APIYI(apiyi.com) 플랫폼은 알리바바 클라우드 공식 직결 채널을 사용하여, 중계가 아닌 알리바바 백련(Bailian) 플랫폼의 자원을 직접 활용합니다. 덕분에 429 오류 발생률이 훨씬 낮고 응답 속도가 안정적입니다. 가격 면에서도 공식 20% 할인(그룹 0.88 할인 + 충전 보너스) 혜택을 제공하며, OpenAI SDK 인터페이스와 호환되어 마이그레이션 비용이 거의 없습니다.
Q4: Qwen3.6-Plus의 속도가 느린 것은 정상인가요?
Qwen3.6-Plus의 MoE 아키텍처와 100만 토큰 컨텍스트는 추론 시 일반 모델보다 더 많은 자원을 소모합니다. 또한 현재 프리뷰 단계라 연산 자원 설정이 보수적이기 때문에 속도가 다소 느린 것은 일반적인 현상입니다. 다만 절대적인 처리량은 충분하므로, 스트리밍 출력(stream=True)을 사용하여 사용자 경험을 개선하는 것을 추천합니다.
Q5: Claude Code에서 Qwen3.6-Plus를 어떻게 사용하나요?
Qwen3.6-Plus는 Anthropic 프로토콜과 OpenAI 프로토콜을 모두 지원합니다. Claude Code의 API 엔드포인트 설정을 수정하여 Qwen3.6-Plus를 연결할 수 있습니다. APIYI(apiyi.com) 플랫폼을 통해 접속할 경우 표준 OpenAI SDK 형식을 사용하면 되며, 자세한 설정 방법은 플랫폼 문서를 참고해 주세요.
Qwen3.6-Plus 429 오류 해결 방안 요약
Qwen3.6-Plus에서 발생하는 429 오류는 본질적으로 수급 불균형 문제입니다. 모델 성능은 뛰어나고 가격은 저렴한데 수요는 폭발적인 반면, OpenRouter의 연산 자원 할당량이 모든 사용자의 요청을 감당하지 못하기 때문입니다.
세 가지 해결 방안과 적용 상황은 다음과 같습니다:
- 지능형 재시도(Smart Retry): 임시 방편으로, 호출 빈도가 낮은 상황에 적합합니다.
- 로컬 최적화: 요청량을 줄이는 방법으로, 모든 상황에 권장됩니다.
- 채널 전환: 근본적인 해결책으로, 안정성이 중요한 프로젝트에 필수적입니다.
Qwen3.6-Plus를 안정적으로 호출해야 하는 개발자라면 APIYI(apiyi.com) 플랫폼을 통해 알리바바 클라우드 공식 직통 채널을 이용하는 것을 추천합니다. 공식 가격 대비 20% 할인 혜택을 누리는 동시에 429 제한 문제에서 벗어나, 오류 처리가 아닌 비즈니스 로직 개발에만 집중할 수 있습니다.
📝 작성자: APIYI Team | 더 많은 AI 모델 API 연동 튜토리얼과 가이드는 APIYI 도움말 센터(help.apiyi.com)를 방문해 주세요.