일상적인 업무 흐름에 OpenClaw를 활용하고 계신가요? 하지만 매달 날아오는 API 청구서를 볼 때마다 가슴이 철렁하시죠? $300, $500, 심지어 $600 이상까지…
이건 여러분의 잘못이 아닙니다. 바로 OpenClaw의 아키텍처 설계 때문입니다. 최적화되지 않은 OpenClaw 인스턴스는 매 작업을 수행할 때마다 대량의 '불필요한 내용'을 AI 모델로 전송하여 토큰을 헛되이 소모하게 됩니다.
다행히도 몇 가지 핵심 설정만으로 청구 금액을 80~90%까지 낮출 수 있습니다. 특히 대부분의 사용자가 잘 모르는 가장 효과적인 방법은 바로 OpenAI 호환 모드가 아닌 Claude 네이티브 형식 인터페이스를 사용하는 것입니다.
이번 포스팅에서는 OpenClaw의 토큰 소모량이 왜 그렇게 높은지 근본 원인을 심층 분석하고, 올바른 인터페이스 사용법, 캐싱 설정, 그리고 적절한 API 채널 선택을 통해 월간 청구액을 $600에서 $60로 줄이는 방법을 차근차근 알려드릴게요.
1. OpenClaw의 토큰 소모가 많은 3가지 핵심 이유
이유 1: 매 요청마다 전체 대화 기록을 다시 전송
이것은 가장 간과하기 쉽지만, 영향력이 가장 큰 원인입니다.
OpenClaw는 설계상 '전체 컨텍스트' 원칙을 따릅니다. AI 모델에 요청을 보낼 때마다 대화 시작부터의 모든 히스토리 메시지를 한꺼번에 보냅니다. 그래야만 모델이 이전에 무엇을 했고 어떤 말을 했는지 '기억'할 수 있기 때문이죠.
예를 들어보겠습니다:
1라운드: 사용자 50 tokens, AI 응답 200 tokens → 이번 전송량 250 tokens
2라운드: 사용자 50 tokens, AI 응답 200 tokens → 이번 전송량 500 tokens (1라운드 포함)
3라운드: 사용자 50 tokens, AI 응답 200 tokens → 이번 전송량 750 tokens (1+2라운드 포함)
...
10라운드: 이번에 실제 추가된 건 250 tokens뿐이지만, 전송량은 이미 2,500 tokens에 달함
복잡한 작업을 처리하는 OpenClaw 워크플로우에서 이러한 '눈덩이 효과'는 토큰 소모를 기하급수적으로 늘립니다. 일반적으로 컨텍스트 히스토리가 전체 토큰 소모의 40~50%를 차지합니다.
이유 2: 시스템 프롬프트의 반복 전송
OpenClaw의 시스템 프롬프트(System Prompt)는 에이전트의 정체성, 능력 범위, 사용 가능한 도구 목록, 행동 규범 등 핵심 내용을 정의하며, 보통 5,000~10,000 토큰 사이입니다.
핵심 문제: 이 거대한 시스템 프롬프트가 매번 API를 호출할 때마다 통째로 다시 전송된다는 점입니다.
만약 하루에 OpenClaw로 50개의 작업을 처리하고, 매번 시스템 프롬프트가 8,000 토큰이라고 가정해 봅시다:
일일 시스템 프롬프트 소모량 = 50 × 8,000 = 400,000 tokens
월간 소모량 ≈ 12,000,000 tokens (시스템 프롬프트만!)
Claude Sonnet 3.5의 입력 가격($3/백만 토큰)으로 계산하면, 시스템 프롬프트 하나만으로도 매달 $36가 나갑니다. 대화 내용과 출력 비용은 포함하지도 않았는데 말이죠.
이유 3: 추론 모드로 인한 토큰 10~50배 폭증
OpenClaw가 복잡한 작업을 만나면 '사고의 사슬' 또는 '추론 모드'(Thinking/Reasoning)를 활성화합니다. 이 모드는 AI가 "먼저 충분히 생각한 뒤 답변"하게 하여 출력 품질을 높여주지만, 그 대가로 토큰 소모가 엄청나게 늘어납니다.
추론 토큰 소모의 특징:
- 사고 과정에서 대량의 중간 토큰이 발생함 (보통 보이지 않지만 과금됨)
- 복잡한 작업의 추론 과정은 10,000~50,000 토큰까지 발생할 수 있음
- 제어하지 않으면 복잡한 작업 몇 개만으로도 하루 예산을 다 써버릴 수 있음
| 토큰 소모 시나리오 | 일반 모드 | 추론 모드 | 배수 차이 |
|---|---|---|---|
| 간단한 질의응답 | ~500 tokens | ~2,000 tokens | 4배 |
| 이메일 처리 프로세스 | ~2,000 tokens | ~15,000 tokens | 7.5배 |
| 코드 분석 작업 | ~5,000 tokens | ~80,000 tokens | 16배 |
| 복잡한 다단계 연구 | ~10,000 tokens | ~200,000 tokens | 20배 이상 |
🎯 빠른 진단: OpenClaw 요금이 비정상적으로 높다면, 먼저 토큰 로그에서 추론 모드 사용 현황을 확인해 보세요.
불필요한 작업의 추론 모드를 끄는 것이 가장 즉각적인 절약 방법 중 하나입니다.
또한 적절한 모델로 교체하는 것도 비용을 크게 낮출 수 있습니다. APIYI (apiyi.com)를 통해 다양한 모델 간의 성능과 비용을 빠르게 테스트해 보세요.
3대 원인별 소모 비중
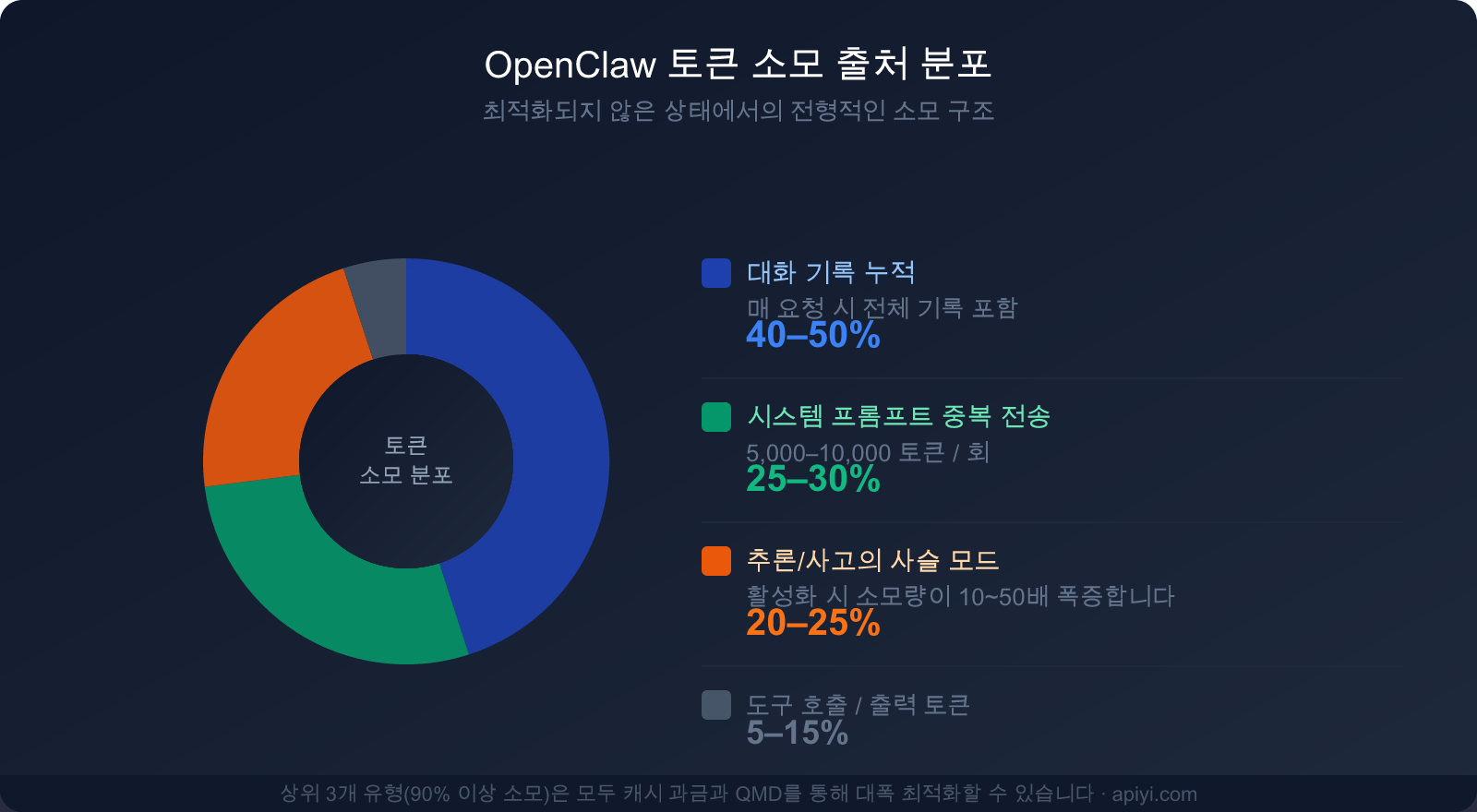
이 세 가지 주요 소모 원인을 이해하는 것이 비용 절감 전략을 세우는 첫걸음입니다.
| 소모 원인 | 전체 소모 비중 | 최적화 가능 여부 | 주요 최적화 수단 |
|---|---|---|---|
| 대화 기록 (컨텍스트 누적) | 40-50% | ✅ 매우 높음 | 캐싱, 정기적인 정리, QMD 적용 |
| 시스템 프롬프트 반복 전송 | 25-30% | ✅ 매우 높음 | 프롬프트 캐싱 (최대 90% 절감) |
| 추론/사고의 사슬 모드 | 20-25% | ✅ 필요 시에만 사용 | 복잡한 작업에만 선별적 활성화 |
| 도구 호출 및 출력 | 5-15% | ⚡ 제한적 최적화 | 도구 설명 간소화 |
2. 가장 간과하기 쉬운 비용 절감 치트키: Claude 캐시 과금
Claude 캐시 과금이란?
Claude의 프롬프트 캐싱(Prompt Caching)은 Anthropic이 2024년 말에 출시한 네이티브 기능입니다. 핵심 로직은 자주 반복해서 보내는 내용을 서버 측에 캐싱해 두고, 이후 호출 시 다시 처리하는 대신 캐시에서 직접 읽어오는 방식입니다.
캐시 읽기 가격: 정상 입력 가격의 10% 불과 (90% 절감)
즉, 매번 8,000 토큰의 시스템 프롬프트를 보낼 때, 캐싱을 활성화하면 캐시 히트 시 800 토큰만큼의 비용만 지불하면 됩니다. 매일 수십 번씩 요청을 보내는 OpenClaw 사용자라면, 이 최적화 하나만으로 월 수백 달러를 아낄 수 있습니다.
캐시 과금의 전체 가격 체계
| 캐시 유형 | 비용 배수 | 유효 시간 | 적용 시나리오 |
|---|---|---|---|
| 일반 입력 토큰 | 1× 기본 가격 | 캐싱 안 함 | 매번 새로 처리 |
| 캐시 쓰기 (최초) | 1.25× | 5분 TTL | 캐시 생성 시 |
| 캐시 쓰기 (장기) | 2× | 1시간 TTL | 빈번한 호출 시나리오 |
| 캐시 읽기 (히트) | 0.1× (90% 절감) | 유효 기간 내 | 반복 요청 시 |
실제 비용 절감 계산 예시:
시나리오: OpenClaw 시스템 프롬프트 8,000 토큰
하루 50회 호출, 그중 48회 캐시 히트 발생
캐시 미사용 시: 50 × 8,000 = 400,000 토큰
비용 = 400,000 × $3/1M = 하루 $1.20 = 월 $36
캐시 사용 시: 쓰기 2회: 2 × 8,000 × 1.25 = 20,000 토큰 = $0.06
히트 48회: 48 × 8,000 × 0.1 = 38,400 토큰 = $0.12
하루 비용 ≈ $0.18 → 월 비용 ≈ $5.40
절감액: $36 - $5.40 = 월 $30.60 (시스템 프롬프트 항목에서만)
절감 비율: 85%
OpenClaw에서 캐시 과금을 활성화하는 방법
캐시 과금을 활성화하기 위한 필수 전제 조건이 있습니다. 바로 OpenAI 호환 모드(/v1/chat/completions)가 아닌 Anthropic 네이티브 형식 인터페이스(/v1/messages)를 사용해야 한다는 점입니다.
올바른 설정 방식 (Python SDK 예시):
import anthropic
# OpenAI SDK가 아닌 Anthropic 네이티브 SDK를 사용해야 합니다.
client = anthropic.Anthropic(
api_key="your-api-key",
base_url="https://api.apiyi.com/v1" # APIYI는 Anthropic 네이티브 형식을 지원합니다.
)
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=4096,
system=[
{
"type": "text",
"text": "당신은 전문 AI 비서입니다...[8000 토큰 분량의 시스템 프롬프트]",
"cache_control": {"type": "ephemeral"} # ← 핵심: 이 내용을 캐싱 대상으로 마킹
}
],
messages=[
{"role": "user", "content": "오늘 받은 메일 정리해 줘"}
]
)
캐싱 기술 제약 사항:
- 최대 4개의 캐시 중단점(
cache_control마킹) 설정 가능 - Sonnet 시리즈: 최소 캐싱 가능 용량 ≥ 1,024 토큰
- Opus / Haiku 4.5: 최소 캐싱 가능 용량 ≥ 4,096 토큰
- 캐싱 지원 모델: Claude Opus 4, Sonnet 4.6, Sonnet 4.5, Sonnet 4, Sonnet 3.7, Haiku 4.5, Haiku 3.5, Haiku 3 등
🎯 중요 팁: APIYI(apiyi.com)는
cache_control파라미터를 포함한 Anthropic 네이티브 형식 호출을 완벽하게 지원합니다. APIYI에서 네이티브 형식으로 Claude 모델을 호출하면, 캐시 과금(최대 90% 절감) + APIYI 20% 할인 혜택을 동시에 누릴 수 있어 중첩 효과가 매우 큽니다.
3. 핵심 인지 사항: 왜 OpenAI 호환 모드로는 토큰을 아낄 수 없을까?
이 부분은 대부분의 OpenClaw 사용자가 가장 실수하기 쉬운 지점입니다.
두 인터페이스 형식의 본질적인 차이
많은 서드파티 AI 도구와 API 중계 서비스는 사용자 편의를 위해 OpenAI 호환 모드를 제공합니다. 즉, OpenAI의 /v1/chat/completions 인터페이스 형식으로 Claude 같은 비 OpenAI 모델을 호출할 수 있게 해주는 것이죠.
겉보기에는 "코드 하나로 모든 모델을 호출"할 수 있어 편리해 보이지만, 치명적인 단점이 있습니다.
/v1/chat/completions 인터페이스 형식에는 cache_control 파라미터가 들어갈 자리가 없습니다. 이는 Anthropic만의 고유한 네이티브 기능이기 때문입니다.
OpenAI 호환 형식을 통해 Claude를 호출할 경우:
- 사용자의 요청이 OpenAI 형식으로 변환됩니다.
- 중계 서비스/프록시가 이를 다시 Anthropic 네이티브 형식으로 변환합니다.
- 하지만 첫 번째 단계에서 이미
cache_control정보가 유실됩니다. - Claude 서버가 받는 요청에는 캐시 마킹이 없으므로, 매번 전체 토큰 비용이 청구됩니다.
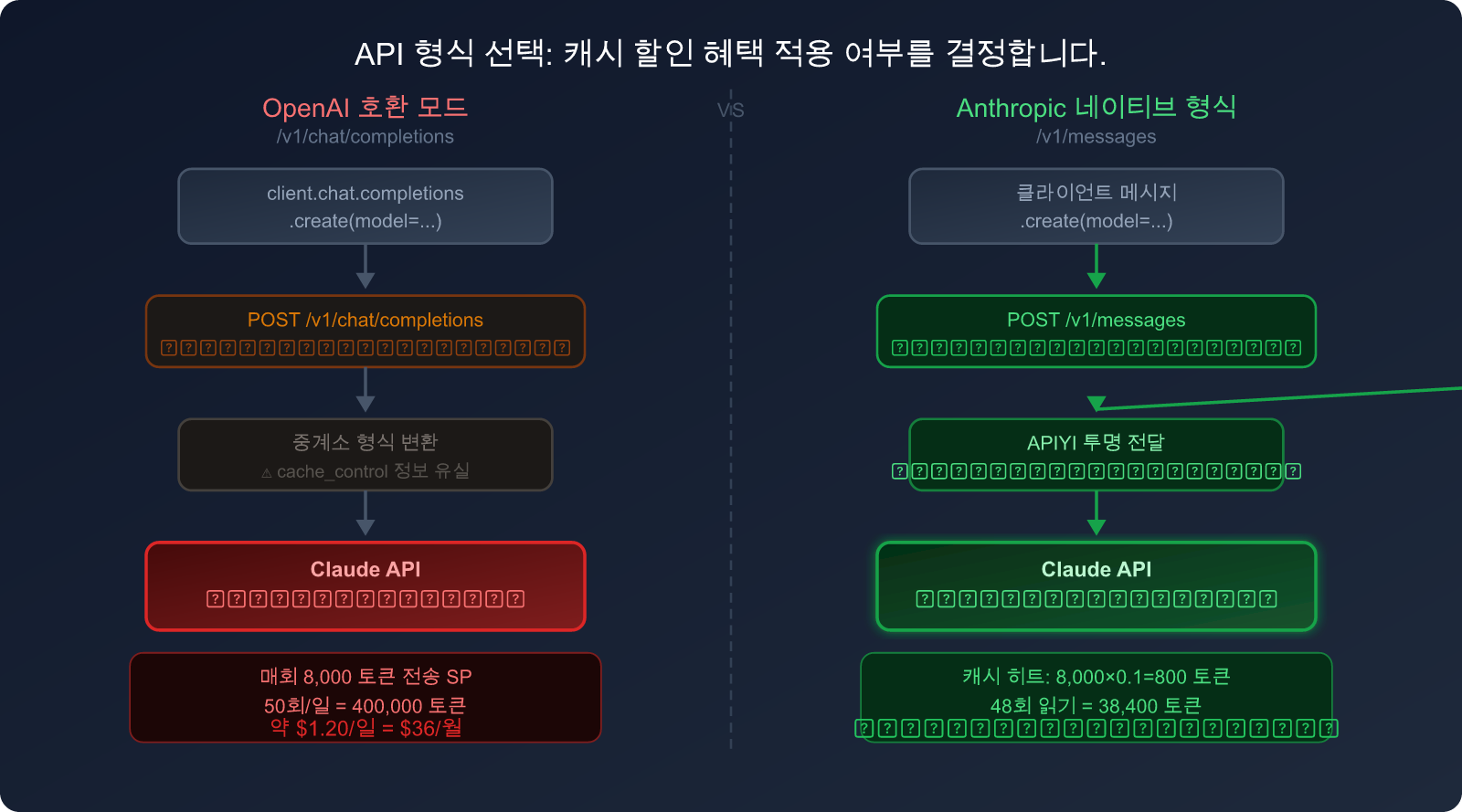
OpenAI 호환 모드 vs Anthropic 네이티브 형식 비교
| 비교 항목 | OpenAI 호환 모드 | Anthropic 네이티브 형식 |
|---|---|---|
| 인터페이스 경로 | /v1/chat/completions |
/v1/messages |
| Claude 캐시 지원 | ❌ 미지원 | ✅ 완벽 지원 |
cache_control 파라미터 |
❌ 해당 필드 없음 | ✅ 4개 중단점 지원 |
| 시스템 프롬프트 과금 | 💸 전액 (1× 가격) | 💰 캐시 읽기 (0.1× 가격) |
| 코드 복잡도 | 낮음 (범용 코드) | 보통 (Anthropic SDK 필요) |
| 비용 절감 효과 (고빈도) | 0% | 최대 90% |
비순정 API 배포의 추가적인 문제
인터페이스 형식 문제 외에도 혼동하기 쉬운 상황이 하나 더 있습니다. 클라우드 업체가 배포한 '동일 이름'의 모델이 반드시 순정 API와 같지는 않다는 점입니다.
GLM-5(Zhipu AI)를 예로 들어보겠습니다:
- z.ai 공식 순정 API: Zhipu가 자체 개발한 캐시 과금 기능을 지원합니다.
- 알리운 / 텐센트 클라우드 등에 배포된 GLM-5: 클라우드 업체의 API 게이트웨이를 사용하므로, 순정 캐시 과금 기능이 없습니다.
이는 GLM-5만의 문제가 아니라 비순정 배포 방식의 공통적인 한계입니다. 클라우드 업체는 모델을 호스팅할 때 보통 표준 대화 API만 노출하며, 모델 제조사의 고유 특성(캐시 과금 등)까지 그대로 전달하지 않는 경우가 많습니다.
비유하자면: 대리점을 통해 구매한 제품은 제조사 공식 센터의 특별 애프터서비스를 받지 못하는 것과 비슷합니다.
실제 영향:
시나리오: 하루 50회 호출, 시스템 프롬프트 6,000 토큰
순정 API (캐시 지원):
쓰기: 2회 × 6,000 × 1.25 = 15,000 토큰
읽기: 48회 × 6,000 × 0.1 = 28,800 토큰
등가 소모량 ≈ 하루 43,800 토큰
비순정 API (캐시 미지원):
전액: 50회 × 6,000 = 하루 300,000 토큰
차이: 캐시가 없을 때의 소모량이 캐시가 있을 때보다 6.85배 더 많음
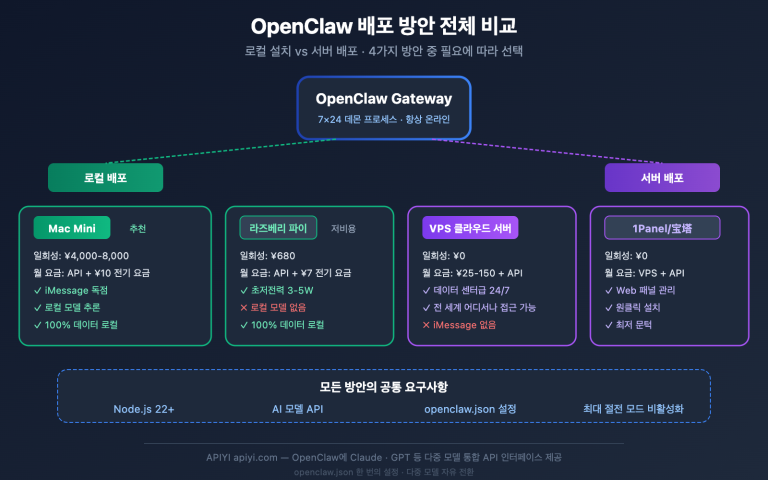
4. 원본 API 비교: OpenClaw에 가장 적합한 연동 방안 선택하기
네 가지 연동 방안 비교
| 연동 방식 | 가격 (원가 대비) | 캐시 지원 | 멀티 모델 지원 | 추천 상황 |
|---|---|---|---|---|
| Anthropic 공식 API | 100% (원가) | ✅ 전체 지원 | ❌ Claude 전용 | 예산이 충분한 순수 Claude 사용자 |
| APIYI (Anthropic 네이티브 형식) | 80% (20% 할인) | ✅ 전체 지원 | ✅ 멀티 모델 | 추천: 비용 절감 + 유연한 전환 |
| 일반 API 중계 서비스 (OpenAI 호환) | 85-95% 내외 | ❌ 지원 안 함 | ✅ 멀티 모델 | Claude 캐시를 사용하지 않을 때 |
| 클라우드 업체 비순정 배포 | 90-110% 내외 | ❌ 지원 안 함 | ❌ 단일 모델 | 기업 보안 및 컴플라이언스 요구 시 |
APIYI의 이중 비용 절감 논리
Claude 모델에서 APIYI가 가진 강점은 Anthropic 네이티브 형식 지원과 20% 할인된 가격을 동시에 제공한다는 점입니다.
이 두 가지가 결합되면 다음과 같은 차이가 발생합니다.
일반 사용자 (원가 + OpenAI 호환 방식, 캐시 없음):
월간 System Prompt Token 소모량: 12,000,000 tokens
비용 = 12,000,000 × $3/1M = $36
APIYI 사용자 (20% 할인 + 네이티브 형식 + 캐시 적용):
실제 과금 Token ≈ 1,440,000 tokens (캐시 적용 후)
비용 = 1,440,000 × $3×0.8/1M = $3.46
종합 절감액 = ($36 - $3.46) / $36 ≈ 90%
🎯 선택 가이드: OpenClaw를 사용하면서 주로 Claude 모델을 선택하신다면,
APIYI(apiyi.com)를 통해 Anthropic 네이티브 형식으로 연동하는 것을 강력히 추천드려요.
20% 기본 할인에 캐시로 절약되는 90%가 더해지면 전체 청구 비용을 85~90%까지 낮출 수 있습니다.
또한 APIYI는 GLM-5, GPT 등 다양한 모델을 지원하므로 언제든 성능을 비교하며 전환하기 편리합니다.
5. OpenClaw 비용 절감 완벽 가이드: 즉시 실행 가능한 5단계
1단계: Anthropic 네이티브 형식 인터페이스로 전환하기
이것은 가장 중요한 단계로, 캐시 과금 혜택을 받을 수 있는지 여부를 직접 결정합니다.
OpenClaw 설정 방법:
OpenClaw의 모델 설정(config.json)에서 models.providers 필드를 찾아 아래 형식으로 APIYI를 제공자로 추가하세요. 핵심은 api 필드를 "anthropic-messages"로 설정하는 것입니다. 그래야만 Anthropic 네이티브 형식을 사용하여 캐시 과금을 지원받을 수 있습니다.
{
"models": {
"providers": {
"apiyi": {
"baseUrl": "https://api.apiyi.com",
"apiKey": "sk-여기에_토큰_입력",
"api": "anthropic-messages",
"headers": {
"anthropic-version": "2023-06-01",
"anthropic-beta": ""
},
"models": [
{
"id": "claude-sonnet-4-6",
"name": "claude-sonnet-4-6",
"reasoning": false,
"input": ["text"],
"contextWindow": 200000,
"maxTokens": 16384
},
{
"id": "claude-sonnet-4-6-thinking",
"name": "claude-sonnet-4-6-thinking",
"reasoning": false,
"input": ["text"],
"contextWindow": 200000,
"maxTokens": 16384
}
]
}
}
}
}
설정 포인트 설명:
"api": "anthropic-messages"← 가장 중요,/v1/chat/completions호환 형식이 아닌/v1/messages네이티브 형식을 사용하도록 지정합니다."baseUrl": "https://api.apiyi.com"← APIYI의 베이스 URL입니다. (OpenClaw가 자동으로 경로를 연결하므로/v1은 생략해도 됩니다.)"anthropic-version": "2023-06-01"← Anthropic API 버전 헤더입니다. 이 헤더가 없으면 요청이 실패할 수 있습니다.contextWindow: 200000← Claude Sonnet 4.6은 200K 컨텍스트 윈도우를 지원합니다.
캐시 활성화 확인 방법:
API 응답 헤더나 로그에서 cache_read_input_tokens 및 cache_creation_input_tokens 필드를 확인하세요. 값이 있다면 캐시가 정상적으로 작동하고 있는 것입니다.
# 캐시 응답 확인
response = client.messages.create(...)
# usage 필드 확인
print(response.usage)
# 출력 예시:
# Usage(
# input_tokens=150, # 이번에 새로 추가된 토큰
# cache_creation_input_tokens=8000, # 처음 캐시에 기록됨 (1.25배 과금)
# cache_read_input_tokens=0, # 이후 캐시 적중 (0.1배 과금)
# output_tokens=300
# )
🎯 연동 방법: APIYI(apiyi.com)에서 가입 후 API 키를 발급받으세요.
base_url을https://api.apiyi.com/v1로 설정하면 바로 Anthropic 네이티브 형식을 사용할 수 있으며,
별도의 코드 수정 없이 Claude 캐시 과금이 즉시 적용됩니다.
2단계: 합리적인 캐시 중단점 배치
캐시 중단점(cache_control)의 위치가 매우 중요합니다. "용량이 크고 고정적인" 내용을 캐시해야 합니다.
# 베스트 프랙티스: 시스템 프롬프트 + 도구 정의 캐싱
response = client.messages.create(
model="claude-sonnet-4-6",
system=[
{
"type": "text",
"text": SYSTEM_PROMPT, # 5,000~10,000 토큰 분량의 메인 시스템 프롬프트
"cache_control": {"type": "ephemeral"} # 중단점 1
},
{
"type": "text",
"text": TOOL_DEFINITIONS, # 도구 목록 (보통 용량이 큼)
"cache_control": {"type": "ephemeral"} # 중단점 2
}
],
messages=conversation_history, # 대화 기록 (매번 변하므로 캐싱하지 않음)
...
)
캐시 전략 요점:
- ✅ 캐싱 권장: 시스템 프롬프트, 도구 정의, 대용량 정적 문서, RAG 검색 문서 내용
- ❌ 캐싱 비권장: 현재 사용자 메시지, 동적으로 생성되는 내용, 매번 바뀌는 데이터
- ⚠️ 주의 사항: 캐시는 접두사 매칭 방식이므로, 정적인 내용은 반드시 메시지 시퀀스의 앞부분에 배치해야 합니다.
3단계: QMD 활성화로 컨텍스트 길이 줄이기
QMD(Quick Memory Database)는 OpenClaw의 로컬 시맨틱 검색 기능입니다. 작동 원리는 다음과 같습니다.
기존 방식:
매번 [전체 대화 기록] 전송 → 대량의 토큰 소모
QMD 방식:
로컬에 벡터 데이터베이스 구축 → 가장 관련 있는 대화 조각 검색
매번 [가장 관련 있는 3~5개 기록]만 전송 → 토큰 60-97% 절감
QMD의 실제 절감 효과: OpenClaw 공식 문서에 따르면, QMD를 통해 대화 기록의 양과 작업 유형에 따라 60~97%의 토큰 절감이 가능합니다.
활성화 방법 (OpenClaw 설정 화면):
- Settings → Memory → Enable QMD 활성화
- QMD 저장 경로 설정 (로컬 저장, 데이터 외부 유출 없음)
- 관련성 임계값(Relevance Threshold) 설정 (노이즈 방지를 위해 0.7 이상 추천)
4단계: 작업 유형에 맞는 적절한 모델 선택
모든 작업에 가장 강력한 모델이 필요한 것은 아닙니다. 정확한 모델 배분이 비용 관리의 핵심입니다.
작업 등급별 전략:
단순 작업 (일정 알림, 형식 변환, 단순 검색)
→ Claude Haiku 4.5 사용 (가장 빠르고 저렴)
→ Sonnet 가격의 약 1/5 수준
중간 작업 (이메일 처리, 파일 정리, 코드 리뷰)
→ Claude Sonnet 4.6 사용 (균형 잡힌 성능)
→ 성공률 86.9% (PinchBench 1위)
복잡한 작업 (아키텍처 분석, 다단계 연구, 복잡한 추론)
→ Claude Opus 4.6 사용 (최강의 추론 능력)
→ 정말로 추론 모드가 필요할 때만 활성화
5단계: 주기적인 컨텍스트 정리
대화 기록은 토큰 소모의 가장 큰 원인 중 하나(40~50%)입니다. 다음을 권장합니다.
- 최대 대화 턴 수 설정: 15~20턴이 넘으면 자동으로 요약하고 기록 정리
- 작업 완료 후 수동 정리: 새로운 작업을 시작하기 전 컨텍스트 초기화
- OpenClaw의 세션 압축 기능 활용: AI를 사용하여 긴 기록을 요약본으로 압축
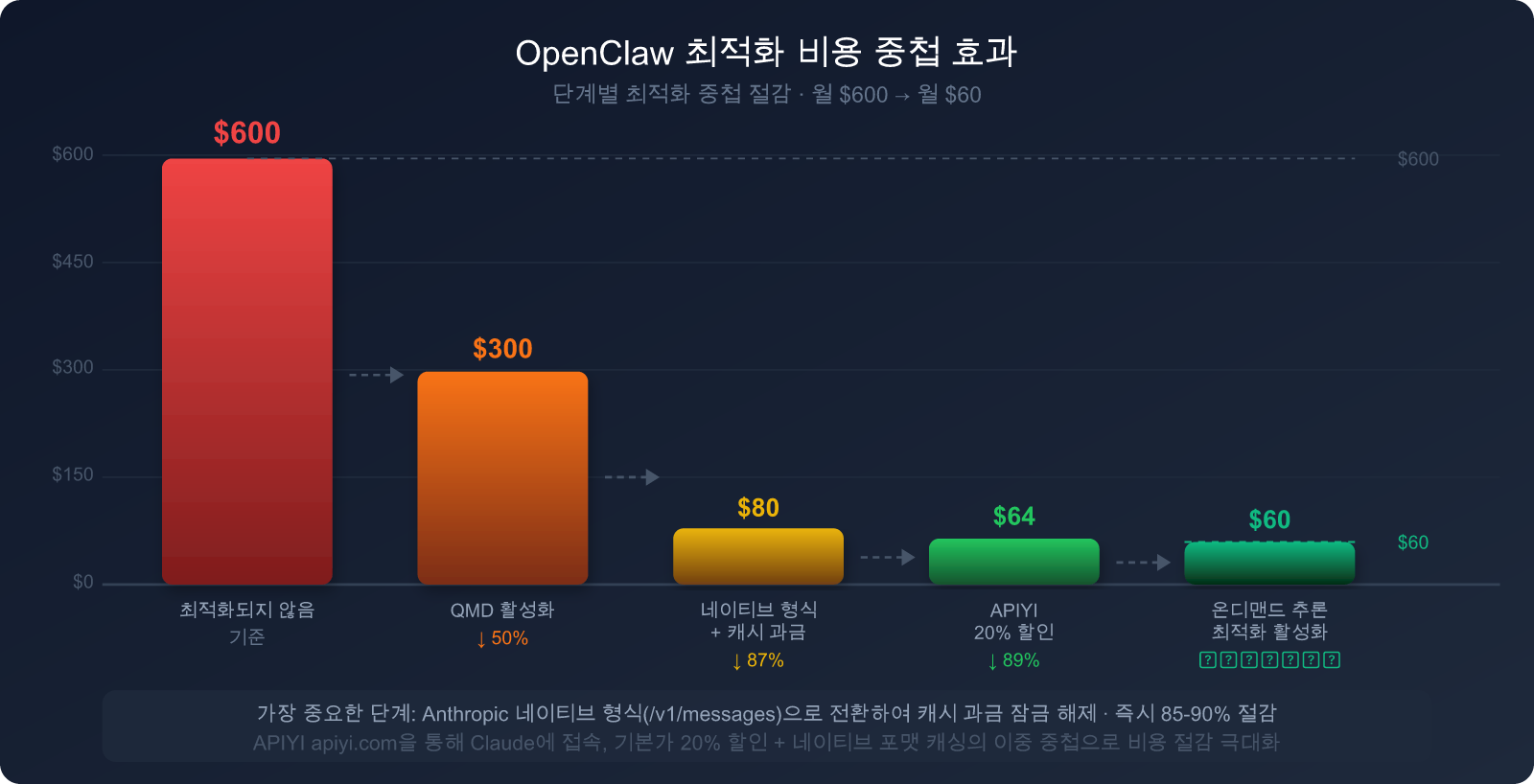
5단계 최적화의 종합 효과 예상
OpenClaw를 보통 수준으로 사용하는 사용자(최적화 전 월 비용 약 $300-600)를 기준으로, 위 5단계를 실행했을 때의 예상 효과입니다.
| 최적화 단계 | 대상 비용 항목 | 예상 절감 비율 | 실행 난이도 |
|---|---|---|---|
| 1. 네이티브 형식 전환 | System Prompt 중복 과금 | 85-90% 절감 (SP 부분) | ⭐ 낮음 (base_url 수정) |
| 2. 캐시 중단점 설정 | 도구 정의 + 정적 문서 | 80-90% 절감 (도구 부분) | ⭐⭐ 낮음~중간 |
| 3. QMD 활성화 | 대화 기록 토큰 | 60-97% 절감 (기록 부분) | ⭐⭐ 낮음~중간 |
| 4. 작업별 모델 배분 | 전체 토큰 비용 | 30-70% 절감 (모델 단가 차이) | ⭐⭐⭐ 중간 |
| 5. 주기적 컨텍스트 정리 | 누적되는 기록 비용 | 20-40% 절감 (장기적 이득) | ⭐ 낮음 |
🎯 실행 우선순위 제안: 1단계(네이티브 형식 전환)와 3단계(QMD 활성화)는 효과가 가장 크면서도 조작이 간단한 두 단계입니다.
이 두 단계를 먼저 완료하는 것을 추천하며, 이것만으로도 보통 청구 비용을 60~80% 즉시 낮출 수 있습니다.
APIYI(apiyi.com)를 통해 Claude를 연동하면 1단계는base_url설정 한 줄만 수정하면 되므로 5분 안에 끝낼 수 있습니다.
6. 실전 설정: OpenClaw + APIYI + Claude 캐싱 전체 예시
대부분의 사용자가 바로 복사해서 사용할 수 있도록 최적화된 OpenClaw 설정 예시를 준비했습니다.
import anthropic
# APIYI를 통해 Anthropic 네이티브 형식 사용
client = anthropic.Anthropic(
api_key="sk-your-apiyi-key", # APIYI 키 (apiyi.com에서 가입 후 획득)
base_url="https://api.apiyi.com/v1"
)
# 시스템 프롬프트 정의 (대용량 콘텐츠, 캐싱에 적합)
SYSTEM_PROMPT = """
당신은 OpenClaw 플랫폼에서 실행되는 전문 AI 스마트 비서입니다.
당신의 역할은 일정 관리, 이메일 처리, 파일 정리, 코드 개발 지원 등을 포함합니다...
[보통 5,000~10,000 토큰 분량의 상세 설명]
"""
# 도구 목록 정의 (이것 역시 대용량 고정 콘텐츠로 캐싱에 적합)
TOOL_DEFINITIONS = """
사용 가능한 도구: calendar_api, email_api, file_system, code_runner...
[도구 상세 설명, 보통 2,000~5,000 토큰]
"""
def call_openclaw_with_cache(conversation_history: list, user_message: str):
"""캐싱이 활성화된 최적화된 OpenClaw API 호출"""
response = client.messages.create(
model="claude-sonnet-4-6", # PinchBench 랭킹 1위
max_tokens=4096,
# 시스템 프롬프트: 캐시 중단점(Checkpoint) 표시
system=[
{
"type": "text",
"text": SYSTEM_PROMPT,
"cache_control": {"type": "ephemeral"} # 캐시 중단점 1
},
{
"type": "text",
"text": TOOL_DEFINITIONS,
"cache_control": {"type": "ephemeral"} # 캐시 중단점 2
}
],
# 대화 기록 + 새 메시지
messages=[
*conversation_history, # 이전 메시지 (캐싱 안 함, 매번 변경됨)
{"role": "user", "content": user_message}
]
)
# 토큰 사용량 출력 (최적화 효과 모니터링용)
usage = response.usage
print(f"입력 토큰: {usage.input_tokens}")
print(f"캐시 생성(쓰기): {usage.cache_creation_input_tokens}")
print(f"캐시 읽기: {usage.cache_read_input_tokens}")
print(f"출력 토큰: {usage.output_tokens}")
return response.content[0].text
🎯 빠른 시작: 위 코드의
api_key를 APIYI(apiyi.com) 가입 후 받은 키로 바꾸기만 하면 됩니다. 다른 수정 없이 Anthropic 네이티브 형식 + 캐시 과금 + APIYI의 20% 할인 혜택을 즉시 누릴 수 있습니다.
자주 묻는 질문(FAQ)
Q: APIYI가 정말 Anthropic 네이티브 형식(/v1/messages)을 지원하나요?
네, APIYI(apiyi.com)는 두 가지 인터페이스 형식을 모두 지원합니다.
- Anthropic 네이티브 형식:
/v1/messages(캐시 과금 지원) - OpenAI 호환 형식:
/v1/chat/completions(범용 코드 사용 시 편리)
Claude 모델의 경우, 캐시 과금 혜택을 받으려면 Anthropic 네이티브 형식을 사용하는 것을 강력히 권장합니다. anthropic Python SDK를 사용하고 base_url을 APIYI 주소로 지정하기만 하면 됩니다.
🎯 APIYI(apiyi.com)에 접속하여 계정을 등록하면, 대시보드에서 두 가지 형식의 연동 예시 코드를 확인할 수 있습니다.
Q: 캐시의 5분 TTL로 충분할까요? 1시간 TTL이 필요한지 어떻게 판단하나요?
이는 호출 빈도에 따라 다릅니다.
- OpenClaw 호출 간격이 5분 이내라면(예: 지속적인 작업 흐름 처리), 기본 5분 TTL로 충분합니다.
- 호출 간격이 5분에서 1시간 사이라면(예: 한 차례 작업을 마친 후 휴식), 1시간 TTL을 고려해 보세요. (비용은 쓰기 가격의 2배지만 캐시 적중률이 높아집니다.)
- 호출 간격이 1시간 이상이라면 캐싱의 의미가 크지 않으므로 매번 새로 쓰는 것이 낫습니다.
Q: GLM-5 등 중국산 모델을 사용할 때 비용을 아끼는 팁이 있나요?
GLM-5의 캐싱 기능은 Zhipu AI 공식 홈페이지(z.ai)의 네이티브 API 호출을 통해 사용해야 하며, 알리바바 클라우드 등 제3자 배포판에서는 사용이 어려울 수 있습니다.
APIYI 역시 GLM-5 등 중국산 모델을 지원하며, 가격이 20% 이상 저렴합니다. 테스트 단계에서 통일된 인터페이스로 각 모델의 효과를 비교해 보기에 편리합니다. 특정 시나리오에 적합한 모델을 확정한 후, APIYI를 계속 쓸지 원천사에 직접 연결할지 결정하시면 됩니다.
Q: 이미 다른 API 중계 서비스를 사용 중인데, 네이티브 형식을 지원하는 플랫폼으로 옮기기 어렵나요?
마이그레이션 비용은 매우 낮습니다. 코드에서 다음 두 가지 파라미터만 수정하면 됩니다.
# 이전 (OpenAI 호환 형식)
from openai import OpenAI
client = OpenAI(api_key="sk-xxx", base_url="기존 중계 서비스 주소")
response = client.chat.completions.create(model="claude-sonnet-4-6", ...)
# 변경 후 (Anthropic 네이티브 형식, 캐싱 지원)
import anthropic
client = anthropic.Anthropic(
api_key="sk-새로운APIYI키", # ← APIYI 키로 교체
base_url="https://api.apiyi.com/v1" # ← APIYI 주소로 교체
)
response = client.messages.create(model="claude-sonnet-4-6", ...)
# 그 후 system 파라미터에 cache_control을 추가하면 캐싱이 활성화됩니다.
주요 작업은 chat.completions.create를 messages.create로 바꾸는 것입니다. 메시지 형식에 미세한 차이가 있지만(role/content 구조는 동일하나 system이 문자열에서 객체 리스트로 변경), 보통 반나절이면 마이그레이션을 완료할 수 있습니다.
Q: 내 OpenClaw 인스턴스에 캐싱이 성공적으로 적용되었는지 어떻게 확인하나요?
가장 확실한 방법은 연속으로 두 번 호출했을 때 API 응답의 usage 객체를 확인하는 것입니다.
- 첫 번째 호출:
cache_creation_input_tokens에 값이 있음 (캐시 쓰기) - 두 번째 호출:
cache_read_input_tokens에 값이 있음 (캐시 적중)
만약 두 번째 호출의 cache_read_input_tokens가 시스템 프롬프트의 토큰 수와 같다면 캐싱이 완벽하게 작동하고 있는 것입니다.
Q: 추론/사고 모드(Extended Thinking)를 반드시 꺼야 하나요?
반드시 끌 필요는 없지만, 필요에 따라 사용해야 합니다. 권장 전략은 다음과 같습니다.
- 단순 작업 (이메일 분류, 일정 예약): 추론 모드 끄기
- 중간 난이도 작업 (코드 리뷰, 정보 요약): 기본적으로 끄되, 복잡할 때만 켜기
- 복잡한 작업 (아키텍처 결정, 다단계 연구): 켜되, 합리적인
budget_tokens상한 설정하기
Claude API에서는 thinking: {"type": "enabled", "budget_tokens": 5000}를 통해 추론 모드의 최대 토큰 소모량을 제한할 수 있습니다.
요약: OpenClaw 비용 절감의 핵심 로직
모든 절감 수단을 한 장의 그림으로 정리해 보겠습니다.
이번 포스팅의 핵심 요점을 다시 한번 살펴볼까요?
3대 고비용 원인:
- 대화 기록 매번 재전송 (소모량의 40~50% 차지)
- System Prompt 매번 재전송 (25~30% 차지)
- 무분별한 추론 모드 사용 (20~25% 차지)
가장 효율적인 비용 절감 수단:
- 🥇 Claude 캐시 과금: 최대 90% 절감 (Anthropic 네이티브 형식 사용 필수)
- 🥈 QMD 로컬 시맨틱 검색: 과거 컨텍스트 토큰의 60~97% 절감
- 🥉 작업별 모델 계층화: 가벼운 작업은 Haiku, 무거운 작업은 Sonnet/Opus 사용
- API 채널은 APIYI 선택: 20% 기본 할인 + 네이티브 형식 완벽 지원
가장 중요한 핵심 포인트:
OpenAI 호환 형식(/v1/chat/completions)은
cache_control을 전달할 수 없습니다.
즉, 중계 서비스를 통해 Claude를 호출하더라도 캐시 할인을 받을 수 없다는 뜻이죠.
비용을 아끼려면 반드시 Anthropic 네이티브 형식(/v1/messages)을 사용해야 합니다.
🎯 지금 바로 시작하기: APIYI(apiyi.com)에 가입하여 Anthropic 네이티브 형식을 지원하는 API 키를 발급받으세요.
base_url을https://api.apiyi.com/v1로 바꾸기만 하면 3분 만에 설정을 마칠 수 있습니다.
당장 오늘부터 토큰 청구서가 눈에 띄게 줄어드는 것을 경험해 보세요. Claude 모델 20% 할인과 다중 모델 통합 인터페이스는 OpenClaw 사용자에게 최고의 선택입니다.
본문의 모든 API 가격 데이터는 2026년 3월 공개 자료를 기준으로 하며, 실제 가격은 각 플랫폼의 공식 공지사항을 확인하시기 바랍니다.
작성자: APIYI Team | 더 많은 OpenClaw 사용 팁은 APIYI(apiyi.com) 고객센터를 방문해 주세요.