Seed 2.0 모델, Pro, Lite, Mini 중 무엇을 선택해야 할까요? 이는 바이트댄스의 최신 대규모 언어 모델을 도입하려는 많은 개발자가 고민하는 핵심 질문입니다. 본 포스팅에서는 Seed 2.0 Pro, Seed 2.0 Lite 그리고 Seed 2.0 Mini 세 가지 모델을 비교하고, 벤치마크 테스트, 가격 비용, 컨텍스트 능력 등 다양한 관점에서 명확한 선택 가이드를 제시해 드립니다.
핵심 가치: 이 글을 읽고 나면 다양한 비즈니스 시나리오에서 어떤 Seed 2.0 모델 변체를 선택해야 할지, 그리고 계층화 전략을 통해 어떻게 최적의 가성비를 달성할 수 있을지 명확히 알게 될 것입니다.
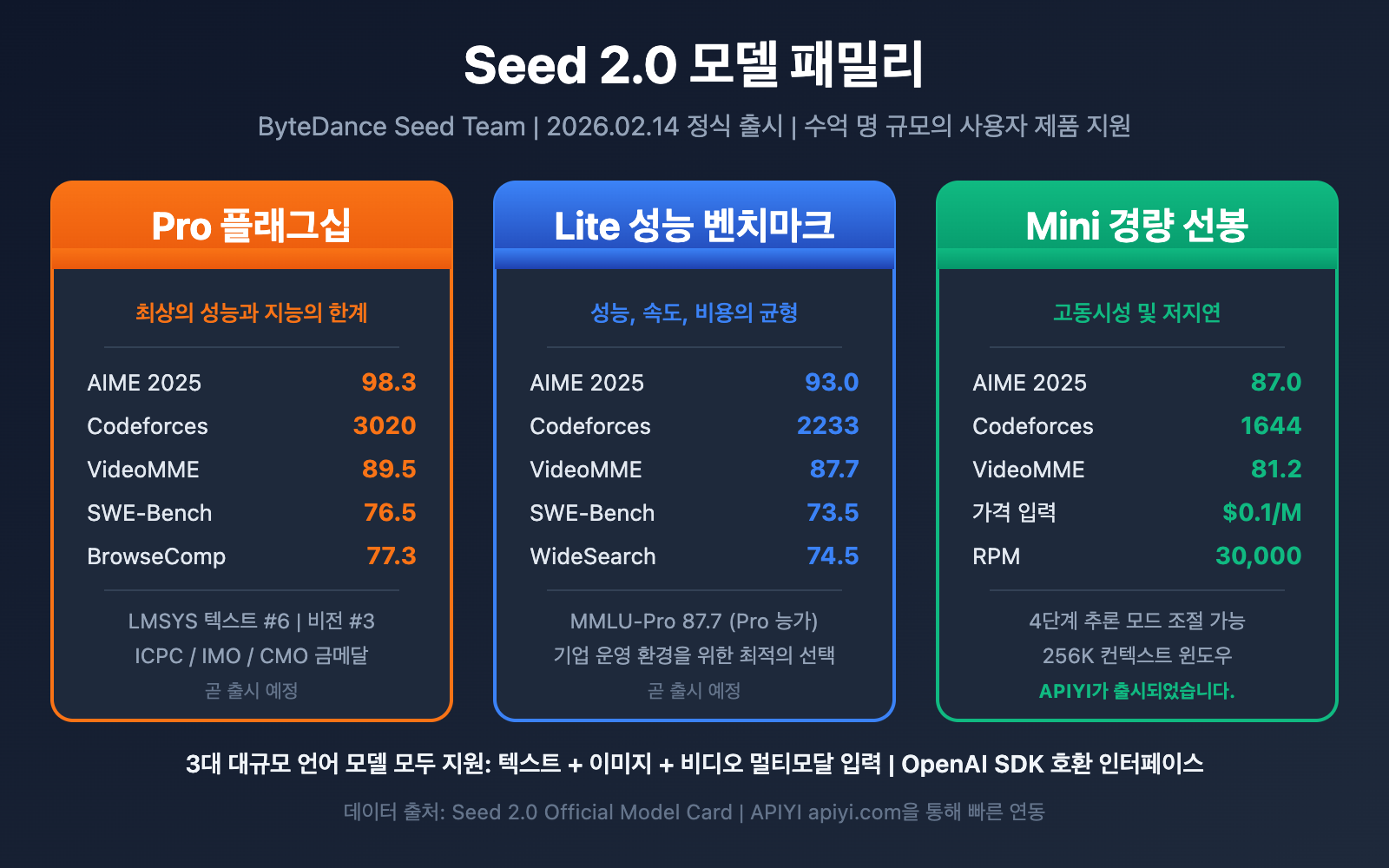
Seed 2.0 모델 가족 개요
바이트댄스(ByteDance) Seed 팀이 2026년 2월 14일, Seed 2.0 시리즈 대규모 언어 모델을 정식 출시했습니다. 이는 바이트댄스의 차세대 멀티모달 기초 모델 제품군으로, 이미 '도우바오(Doubao)' 등 억대 사용자 규모의 서비스들을 뒷받침하고 있으며, 전 세계 각종 공개 벤치마크 평가에서 업계 최상위권을 기록하고 있습니다.
Seed 2.0 가족은 명확한 포지셔닝과 목표 시나리오를 가진 세 가지 핵심 멤버로 구성됩니다.
| 모델 | 포지셔닝 | 핵심 장점 | 타겟 사용자 |
|---|---|---|---|
| Seed 2.0 Pro | 플래그십 모델 | 극한의 성능과 지능의 상한선 | 높은 복잡도와 고부가가치 전문 작업 |
| Seed 2.0 Lite | 효율성의 기준 | 성능, 속도, 비용의 균형 | 기업용 범용 생산급 모델 |
| Seed 2.0 Mini | 경량화 선구자 | 높은 동시성 및 낮은 지연 시간 | 빠른 응답과 높은 처리량이 필요한 애플리케이션 |
세 모델 모두 체계적인 최적화를 거쳐 강력한 멀티모달 이해 능력(텍스트, 이미지, 비디오 입력 지원)을 갖추고 있으며, 언어 추론, 코드 생성, 에이전트(Agent) 도구 호출 등 모든 차원에서 전면 업그레이드되었습니다.
Seed 2.0 Pro Preview 글로벌 평가 성적
Seed 2.0 Pro의 Preview 버전은 이미 세계에서 가장 권위 있는 평가 체계에서 선두적인 성적을 거두었습니다.
- LMSYS Chatbot Arena: 텍스트 아레나(Text Arena) 종합 순위 6위, 비전 아레나(Vision Arena) 3~4위 기록 (2026년 2월 기준)
- 수학 경시: AIME 2025 점수 98.3, HMMT Feb 점수 97.3 획득, ICPC, IMO, CMO 경시 금메달 수준 달성
- 100개 이상의 공개 벤치마크: 언어 추론, 시각 이해, 에이전트 능력을 아우르는 종합 평가에서 글로벌 1티어 수준 도달
🎯 기술 팁: 현재 Seed 2.0 Mini가 BytePlus 플랫폼을 통해 가장 먼저 출시되었습니다. APIYI는 BytePlus의 파트너로서 이 모델을 즉시 도입했습니다. 개발자분들은 APIYI apiyi.com 플랫폼을 통해 Seed 2.0 Mini의 모든 기능을 빠르게 체험해 보실 수 있으며, Pro와 Lite 버전도 순차적으로 출시될 예정입니다.
Seed 2.0 Pro vs Lite vs Mini 핵심 벤치마크 비교
다음은 세 가지 모델의 주요 평가 차원별 전체 점수 비교입니다. 데이터는 바이트댄스 Seed 2.0 공식 모델 카드(Model Card) 및 제3자 평가 기관의 자료를 기반으로 합니다.
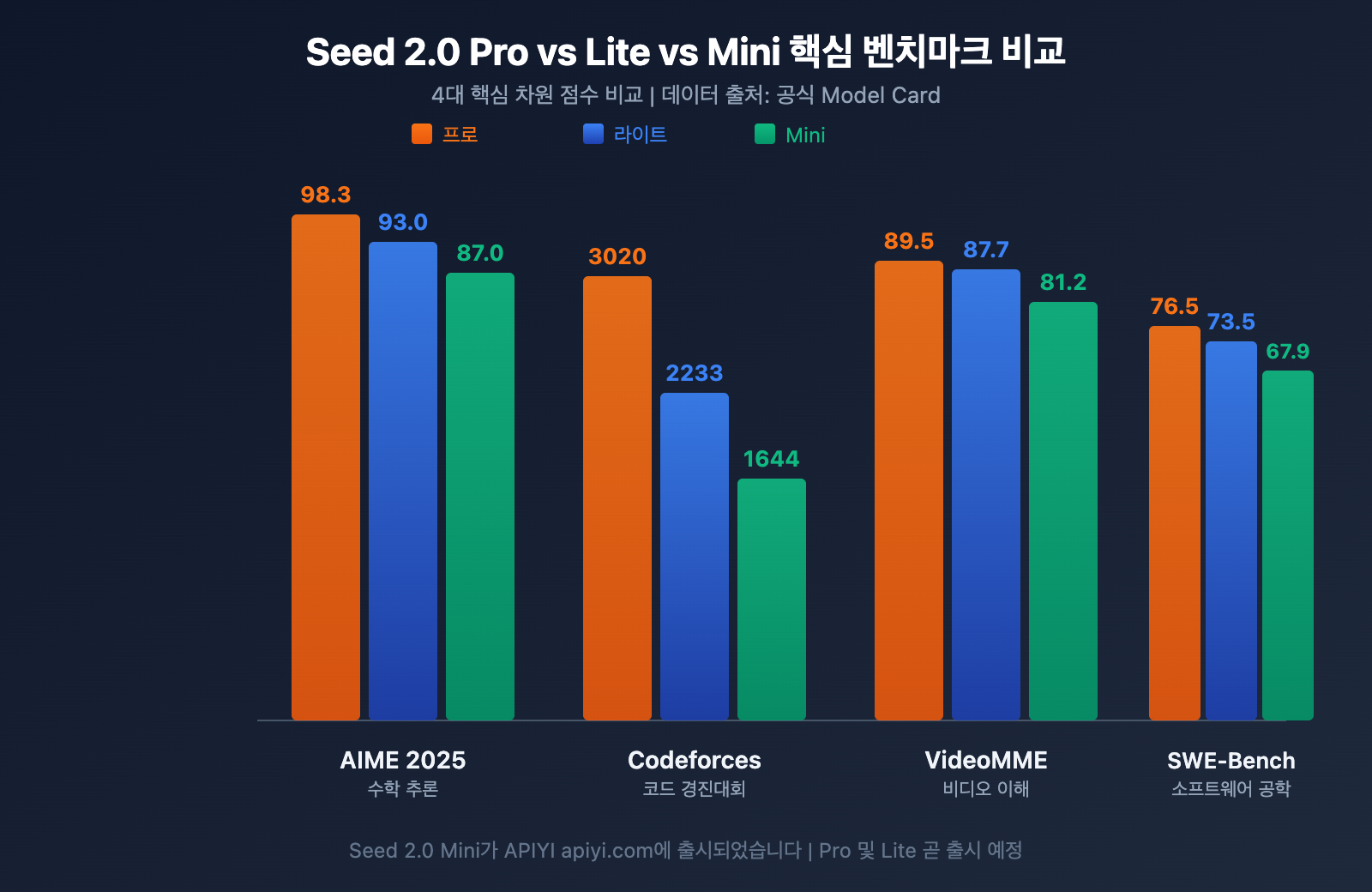
Seed 2.0 수학 및 추론 능력 비교
| 평가 항목 | Seed 2.0 Pro | Seed 2.0 Lite | Seed 2.0 Mini | 설명 |
|---|---|---|---|---|
| AIME 2025 | 98.3 | 93.0 | 87.0 | 미국 수학 초청 경시 |
| AIME 2026 | 94.2 | 88.3 | 86.7 | 최신 연도 수학 경시 |
| GPQA Diamond | 88.9 | 85.1 | 79.0 | 대학원 수준 질의응답 |
| MMLU-Pro | 87.0 | 87.7 | 83.6 | 전문 지식 이해 |
| HMMT Feb | 97.3 | 90.0 | 70.0 | 하버드-MIT 수학 토너먼트 |
| MathVision | 88.8 | 86.4 | 78.1 | 시각적 수학 추론 |
수학 추론 데이터를 보면 세 모델이 명확한 계층을 형성하고 있습니다.
- Pro 급: AIME 2025에서 98.3, HMMT에서 97.3을 기록하며 현재 대규모 언어 모델 수학 추론의 정점을 보여줍니다. GPT-5.2 및 Gemini 3 Pro와 대등하게 경쟁할 수 있는 수준입니다.
- Lite 급: AIME 2025에서 93.0을 기록했으며, MMLU-Pro에서는 87.7로 Pro의 87.0을 근소하게 앞서기도 했습니다. 이는 지식 이해형 작업에서 Lite가 이미 플래그십 수준에 근접했음을 의미합니다.
- Mini 급: AIME 2025에서 87.0을 기록했습니다. 경량화와 높은 동시성을 지향하는 소형 모델로서는 매우 뛰어난 점수입니다.
Seed 2.0 코드 및 엔지니어링 능력 비교
| 평가 항목 | Seed 2.0 Pro | Seed 2.0 Lite | Seed 2.0 Mini | 설명 |
|---|---|---|---|---|
| Codeforces | 3020 | 2233 | 1644 | 프로그래밍 경시 레이팅 |
| LiveCodeBench v6 | 87.8 | 81.7 | 64.1 | 실시간 프로그래밍 평가 |
| SWE-Bench Verified | 76.5 | 73.5 | 67.9 | 실제 소프트웨어 공학 작업 |
코드 능력 면에서 Pro의 Codeforces 3020 레이팅은 국제 경시 금메달 수준에 해당합니다. 주목할 점은 SWE-Bench Verified의 격차입니다. Pro 76.5 vs Lite 73.5 vs Mini 67.9로, 실제 소프트웨어 공학 작업에서의 격차는 경시 프로그래밍보다 훨씬 작습니다. 이는 Lite와 Mini가 일상적인 개발 시나리오에서 실용성이 매우 높다는 것을 보여줍니다.
Seed 2.0 멀티모달 및 비디오 이해 비교
| 평가 항목 | Seed 2.0 Pro | Seed 2.0 Lite | Seed 2.0 Mini | 설명 |
|---|---|---|---|---|
| MMMU | 85.4 | 83.7 | 79.7 | 멀티모달 이해 |
| MMMU-Pro | 78.2 | 76.0 | 71.4 | 전문 멀티모달 이해 |
| VideoMME | 89.5 | 87.7 | 81.2 | 비디오 콘텐츠 분석 |
| MotionBench | 75.2 | 70.9 | 64.4 | 동작 인식 |
| TempCompass | 89.6 | 87.0 | 83.7 | 시계열 추론 |
멀티모달은 Seed 2.0 시리즈의 핵심 강점 중 하나입니다. Pro는 VideoMME에서 89.5점을 기록하며 압도적인 비디오 이해 능력을 보여주었으며, 동작 인식 및 시계열 추론 능력은 인간의 기준치를 넘어서기도 했습니다. Lite 역시 비디오 이해(87.7)와 시계열 추론(87.0)에서 Pro를 바짝 추격하고 있어, 기업용 비디오 분석 시나리오에서 가성비 좋은 선택지가 될 것입니다.
Seed 2.0 에이전트(Agent) 능력 비교
| 평가 항목 | Seed 2.0 Pro | Seed 2.0 Lite | Seed 2.0 Mini | 설명 |
|---|---|---|---|---|
| BrowseComp | 77.3 | 72.1 | 48.1 | 웹 브라우징 이해 |
| Terminal Bench | 55.8 | 45.0 | 36.9 | 터미널 조작 능력 |
| WideSearch | 74.7 | 74.5 | 37.7 | 광범위 검색 작업 |
| HLE-Verified | 73.6 | 70.7 | 56.4 | 고난도 추론 검증 |
에이전트 능력은 세 모델을 구분하는 핵심 차원입니다. Pro와 Lite는 BrowseComp와 WideSearch에서 격차가 매우 작아(Pro 74.7 vs Lite 74.5), Lite가 자율 검색 및 정보 통합 분야에서 이미 플래그십 수준에 도달했음을 알 수 있습니다. 반면 Mini는 에이전트 작업 점수가 상대적으로 낮아, 에이전트 시스템 내에서 의사 결정보다는 단순 명령을 처리하는 실행단에 더 적합합니다.
Seed 2.0 Mini 모델 카드 상세 파라미터
Seed 2.0 Mini는 현재 APIYI 플랫폼을 통해 출시된 첫 번째 Seed 2.0 시리즈 모델입니다. 전체 모델 파라미터는 다음과 같습니다.
| 파라미터 항목 | 규격 |
|---|---|
| Model ID | seed-2-0-mini-260215 |
| 모델 가격 (Prompt ≤ 128K) | 입력 $0.1/M 토큰, 출력 $0.4/M 토큰 |
| 입력 유형 | 텍스트 + 이미지 + 비디오 |
| 출력 유형 | 텍스트 |
| 컨텍스트 윈도우 | 256K |
| 최대 입력 토큰 | 256K |
| 최대 출력 토큰 | 128K |
| 최대 사고(Thinking) 토큰 | 128K |
| TPM (분당 토큰 수) | 1,500K |
| RPM (분당 요청 수) | 30K |
| 추론 모드 | 4단계 조절: minimal / low / medium / hi |
| 사용 가능 플랫폼 | APIYI apiyi.com (BytePlus 파트너) |
Seed 2.0 Mini의 가격은 매우 경쟁력이 있어요. 입력 $0.1/M 토큰, 출력 $0.4/M 토큰으로 책정되었습니다. 참고로 GPT-5.2의 입력 가격은 $1.75/M 토큰, Claude Opus 4.5는 $5.0/M 토큰입니다. Seed 2.0 Mini의 입력 비용은 GPT-5.2의 1/17.5 수준으로 가성비가 매우 뛰어납니다.
💰 비용 최적화: 비용에 민감한 프로젝트라면 Seed 2.0 Mini가 최고의 선택이에요. APIYI(apiyi.com) 플랫폼을 통해 이용하면 BytePlus 공식 홈페이지와 동일한 가격으로 사용할 수 있으며, 100달러 충전 시 10% 이상 추가 증정 혜택을 받아 최대 20% 할인된 가격으로 이용하는 효과를 볼 수 있습니다.
Seed 2.0 시나리오별 모델 추천
Seed 2.0 Pro 추천 시나리오
Seed 2.0 Pro는 극강의 지능적 한계를 추구하는 플래그십 모델로, 다음과 같은 고부가가치 시나리오에 적합합니다.
- 첨단 과학 연구: 수학적 증명, 과학적 추론, 논문 작성 보조 (AIME 98.3, GPQA 88.9)
- 고난도 프로그래밍: 알고리즘 경진대회, 복잡한 시스템 아키텍처 설계 (Codeforces 3020)
- 심화 에이전트 작업: 자율 브라우징, 다단계 검색, 복잡한 도구 오케스트레이션 (BrowseComp 77.3, WideSearch 74.7)
- 전문 영상 분석: 장편 영상 이해, 동작 인식, 시계열 추론 (VideoMME 89.5)
- 의사결정 AI: 최고 수준의 추론 품질이 필요한 핵심 비즈니스 의사결정
Seed 2.0 Lite 추천 시나리오
Seed 2.0 Lite는 기업 생산 환경에서 성능과 비용의 균형이 가장 뛰어난 선택입니다.
- 기업용 범용 작업: 일상적인 코드 개발, 문서 처리, 데이터 분석 (SWE-Bench 73.5)
- 콘텐츠 생성: 비즈니스 카피라이팅, 기술 문서, 보고서 생성 (MMLU-Pro 87.7)
- 멀티모달 비즈니스: 이미지-텍스트 이해, 영상 요약, 문서 파싱 (MMMU 83.7, VideoMME 87.7)
- 에이전트 워크플로우: 검색 어시스턴트, 정보 통합, 도구 호출 (WideSearch 74.5, Pro 모델에 육박하는 성능)
- 비용 효율적 추론 작업: 고품질 성능이 필요하지만 예산이 한정된 중대형 기업
Seed 2.0 Mini 추천 시나리오
Seed 2.0 Mini는 높은 동시성과 저비용이 필요한 시나리오에 최적화되어 있습니다.
- 대량 콘텐츠 처리: 텍스트 분류, 감성 분석, 키워드 추출 (RPM 30K, TPM 1500K)
- 콘텐츠 검수: 이미지 검수, 영상 모니터링, 규정 준수 탐지 (이상 패턴 발생 40% 감소)
- 실시간 고객 응대: 높은 동시성의 대화형 서비스, FAQ 자동 응답, 스마트 라우팅
- 데이터 라벨링 보조: 대량 라벨링, 포맷 변환, 구조화된 데이터 출력
- 경량 코드 작업: 코드 완성, 간단한 버그 수정, 코드 리뷰 (SWE-Bench 67.9)
- 비용 우선 시나리오: 100만 토큰당 단 $0.1(입력)의 극강의 가성비
💡 선택 가이드: 어떤 Seed 2.0 모델을 선택할지는 작업의 복잡도와 동시성 요구 사항에 따라 달라집니다. 대부분의 기업에는 'Lite 메인 + Mini 보조'의 계층화 전략을 추천드려요. APIYI(apiyi.com) 플랫폼을 통해 현재 Seed 2.0 Mini를 가장 먼저 경험해 보실 수 있으며, 추후 Pro와 Lite 모델도 출시되는 대로 즉시 지원될 예정입니다.
Seed 2.0 모델 비교 및 도입 제안
Seed 2.0 계층별 배포 전략
품질과 비용을 동시에 고려해야 하는 기업이라면 다음과 같은 계층형 아키텍처를 도입하는 것을 추천드려요.
의사결정 계층(Pro) — 요청량의 5-10%:
복잡한 추론, 핵심 의사결정, 고가치 콘텐츠 생성 등 최고 수준의 추론 품질이 필요한 핵심 작업에 적합합니다. Pro 모델의 AIME 98.3 및 Codeforces 3020 점수는 업계 최고 수준의 결과물을 보장합니다.
실행 계층(Lite) — 요청량의 20-30%:
코드 개발, 문서 생성, 멀티모달 분석과 같은 일상적인 중간 난이도 작업을 처리합니다. Lite의 SWE-Bench 73.5 및 WideSearch 74.5 점수는 실제 업무 환경에서 매우 신뢰할 수 있음을 보여주며, 비용 또한 Pro보다 훨씬 저렴합니다.
처리량 계층(Mini) — 요청량의 60-70%:
분류 및 라벨링, 콘텐츠 검수, 형식 변환 등 빈도가 높고 표준화된 대량 작업을 처리합니다. Mini 모델은 30K RPM 및 1500K TPM의 초고속 처리 능력을 제공하며, 입력 토큰당 $0.1/M이라는 매우 경쟁력 있는 가격을 자랑합니다.
Seed 2.0 vs 경쟁 모델 가격 비교
| 모델 | 입력 가격 ($/M tokens) | 출력 가격 ($/M tokens) | 포지셔닝 |
|---|---|---|---|
| Seed 2.0 Mini | $0.10 | $0.40 | 경량 고병렬 |
| GPT-4.1 mini | $0.40 | $1.60 | 경량 범용 |
| GPT-5.2 | $1.75 | $14.00 | 플래그십 추론 |
| Claude Sonnet 4.6 | $3.00 | $15.00 | 균형 및 효율 |
| Claude Opus 4.5 | $5.00 | $25.00 | 최상위 추론 |
| Gemini 3 Pro | $1.25 | $10.00 | 멀티모달 플래그십 |
Seed 2.0 Mini의 입력 및 출력 가격은 GPT-4.1 mini의 1/4 수준에 불과해요. GPT-5.2와 비교하면 입력 비용은 17.5배, 출력 비용은 35배나 저렴하여 가성비 면에서 압도적인 우위를 점하고 있습니다.
Seed 2.0 모델 비교 관련 자주 묻는 질문(FAQ)
Q1: 현재 Seed 2.0 Mini 버전만 사용 가능한가요?
네, 2026년 2월 기준으로 Seed 2.0 Mini(모델 ID: seed-2-0-mini-260215)가 BytePlus 플랫폼을 통해 가장 먼저 출시된 Seed 2.0 시리즈 모델입니다. APIYI(apiyi.com)는 BytePlus의 파트너로서 해당 모델을 즉시 도입했으며, 공식 홈페이지와 동일한 가격으로 제공하고 있어요. Seed 2.0 Pro와 Lite 모델도 곧 출시될 예정이며, APIYI에서도 발 빠르게 지원할 계획입니다.
Q2: Seed 2.0 Lite가 Pro를 대체할 수 있는 상황은 언제인가요?
벤치마크 데이터를 보면 Lite는 여러 지표에서 Pro에 매우 근접해 있습니다. WideSearch(74.5 vs 74.7), MMLU-Pro(87.7 vs 87.0, Lite가 더 높음), SWE-Bench(73.5 vs 76.5) 등이 그 예시죠. 일상적인 개발, 문서 처리, 정보 검색 및 통합 작업에서는 Lite가 Pro를 충분히 대체할 수 있으며 비용도 크게 절감할 수 있습니다. 다만, 고난도 수학 추론(AIME 98.3 vs 93.0)이나 고난도 프로그래밍 경진대회(Codeforces 3020 vs 2233) 같은 극단적인 시나리오에서만 Pro가 확실한 우위를 점합니다.
Q3: Seed 2.0 Mini의 4단계 추론 모드는 모델 선택에 어떤 영향을 주나요?
Seed 2.0 Mini는 reasoning_effort 파라미터를 통해 minimal(추론 없음), low, medium, hi의 4단계를 지원합니다. minimal 모드에서는 전체 성능이 hi 모드의 약 85% 수준이지만, 토큰 소모량은 약 1/10에 불과해요. 즉, 깊은 추론이 필요 없는 대량의 작업(분류, 라벨링, 포맷팅)에는 Mini + minimal 모드를 사용하고, 더 높은 성능이 필요할 때는 Mini + hi 모드를 사용하여 Lite 수준의 성능을 낼 수 있습니다. APIYI(apiyi.com) 플랫폼을 이용하면 이러한 추론 모드를 유연하게 설정하여 정밀하게 비용을 관리할 수 있습니다.
Q4: Seed 2.0 시리즈는 GPT나 Claude와 비교했을 때 어떤 경쟁력이 있나요?
벤치마크 데이터상으로 Seed 2.0 Pro는 이미 GPT-5.2 및 Gemini 3 Pro 수준에 도달했으며, LMSYS Arena 순위에서도 텍스트 부문 6위, 비전 부문 3~4위를 기록하고 있습니다. 하지만 Seed 2.0의 진정한 핵심 경쟁력은 가격에 있어요. Mini의 입력 가격($0.1/M tokens)은 GPT-5.2의 1/17.5 수준이며, Pro의 가격 또한 GPT-5.2의 약 1/3.7 수준입니다. 비슷한 성능을 내면서도 압도적인 비용 효율성을 제공하는 것이 Seed 2.0 시리즈의 강점입니다.
Q5: Seed 2.0 Mini API를 빠르게 연동하려면 어떻게 해야 하나요?
Seed 2.0 Mini는 OpenAI SDK 인터페이스 규격을 완벽히 지원하므로 마이그레이션 비용이 매우 낮습니다. base_url을 https://api.apiyi.com/v1으로 변경하고, model을 seed-2-0-mini-260215로 설정하기만 하면 바로 사용할 수 있습니다. APIYI(apiyi.com) 플랫폼은 즉시 사용 가능한 통합 인터페이스를 제공하며, 여러 주요 모델을 교체하며 호출할 수 있는 기능을 지원합니다. 현재 100달러 충전 시 10% 이상 추가 증정 이벤트도 진행 중이니 참고해 보세요.
Seed 2.0 모델 비교 요약
Seed 2.0 시리즈는 바이트댄스(ByteDance) Seed 팀이 선보이는 차세대 대규모 언어 모델 제품군으로, 세 가지 핵심 모델이 각각 명확한 포지셔닝을 가지고 있습니다. Pro는 극강의 지능적 한계에 도전하고(AIME 98.3, Codeforces 3020), Lite는 성능과 비용의 균형을 맞췄으며(SWE-Bench 73.5, WideSearch 74.5), Mini는 높은 동시성 처리와 낮은 지연 시간에 집중했습니다(RPM 30K, 입력 비용 $0.1/M 토큰).
현재 Seed 2.0 Mini가 가장 먼저 출시되었으며, APIYI(apiyi.com) 플랫폼을 통해 빠르게 연동할 수 있습니다. 가격은 BytePlus 공식 홈페이지와 동일한 수준이며, 충전 시 추가 혜택까지 누릴 수 있습니다. Pro와 Lite 버전도 곧 순차적으로 출시될 예정이며, 개발자분들은 출시 후 동일한 플랫폼에서 전체 모델 시리즈를 매끄럽게 전환하며 비교해 보실 수 있습니다.
참고 자료
-
ByteDance Seed 2.0 공식 페이지: 모델 소개 및 전체 벤치마크 데이터
- 링크:
seed.bytedance.com/en/seed2 - 설명: Pro, Lite, Mini 전 시리즈의 평가 비교 데이터 포함
- 링크:
-
Seed 2.0 Model Card 기술 백서: 상세 모델 아키텍처 및 평가 방법
- 링크:
github.com/ByteDance-Seed/Seed2.0 - 설명: 훈련 방법 및 평가 데이터셋 상세 정보 포함
- 링크:
-
LMSYS Chatbot Arena: 세계 최대 규모의 인간 선호도 블라인드 테스트
- 링크:
lmarena.ai - 설명: Seed 2.0 Pro Preview 순위 – 텍스트 부문 6위, 비전 부문 3~4위 기록
- 링크:
-
Seed 2.0 Benchmarks Guide: 제3자 평가 요약
- 링크:
digitalapplied.com/blog/bytedance-seed-2-doubao-ai-model-benchmarks-guide - 설명: GPT-5.2, Claude Opus 4.5와의 비교 분석 데이터 포함
- 링크:
작성자: APIYI 팀 | 더 많은 AI 모델 API 비교 및 선정 가이드를 확인하시려면 APIYI(apiyi.com) 기술 블로그를 방문해 주세요.