作者注:深度对比 Kimi K2.5 与 Claude Opus 4.5 在编程、推理、Agent 能力等维度的表现,分析 9 倍价差背后的性价比差异,帮你做出最佳选择
Kimi K2.5 对比 Claude Opus 4.5 到底怎么样?这是 2026 年开发者最关心的选型问题之一。本文从 基准测试、实际能力、价格成本、适用场景 四个维度进行深度对比,给出明确的选择建议。
核心结论:Claude Opus 4.5 在代码质量上略胜一筹 (SWE-Bench 80.9% vs 76.8%),但 Kimi K2.5 在 Agent 自动化、视觉编程、数学推理上更强,且成本仅为 Claude 的 1/9。

Kimi K2.5 vs Claude Opus 4.5 核心对比
| 对比维度 | Kimi K2.5 | Claude Opus 4.5 | 胜出方 |
|---|---|---|---|
| SWE-Bench Verified | 76.8% | 80.9% | Claude +4.1% |
| AIME 2025 数学 | 96.1% | 92.8% | Kimi +3.3% |
| LiveCodeBench v6 | 83.1% | 64.0% | Kimi +19.1% |
| BrowseComp 网页交互 | 60.2% | 24.1% | Kimi +36.1% |
| Agent Swarm | ✅ 100 并行 | ❌ 不支持 | Kimi |
| 视觉编程 | ✅ 原生支持 | ❌ 仅文本 | Kimi |
| 上下文窗口 | 256K | 200K | Kimi +28% |
| API 价格 | $0.60/$3.00 | $5.00/$25.00 | Kimi 便宜 ~9x |
一句话总结
- 追求极致代码质量 → 选 Claude Opus 4.5
- 追求性价比和多功能 → 选 Kimi K2.5
- 需要 Agent 自动化 → 必选 Kimi K2.5
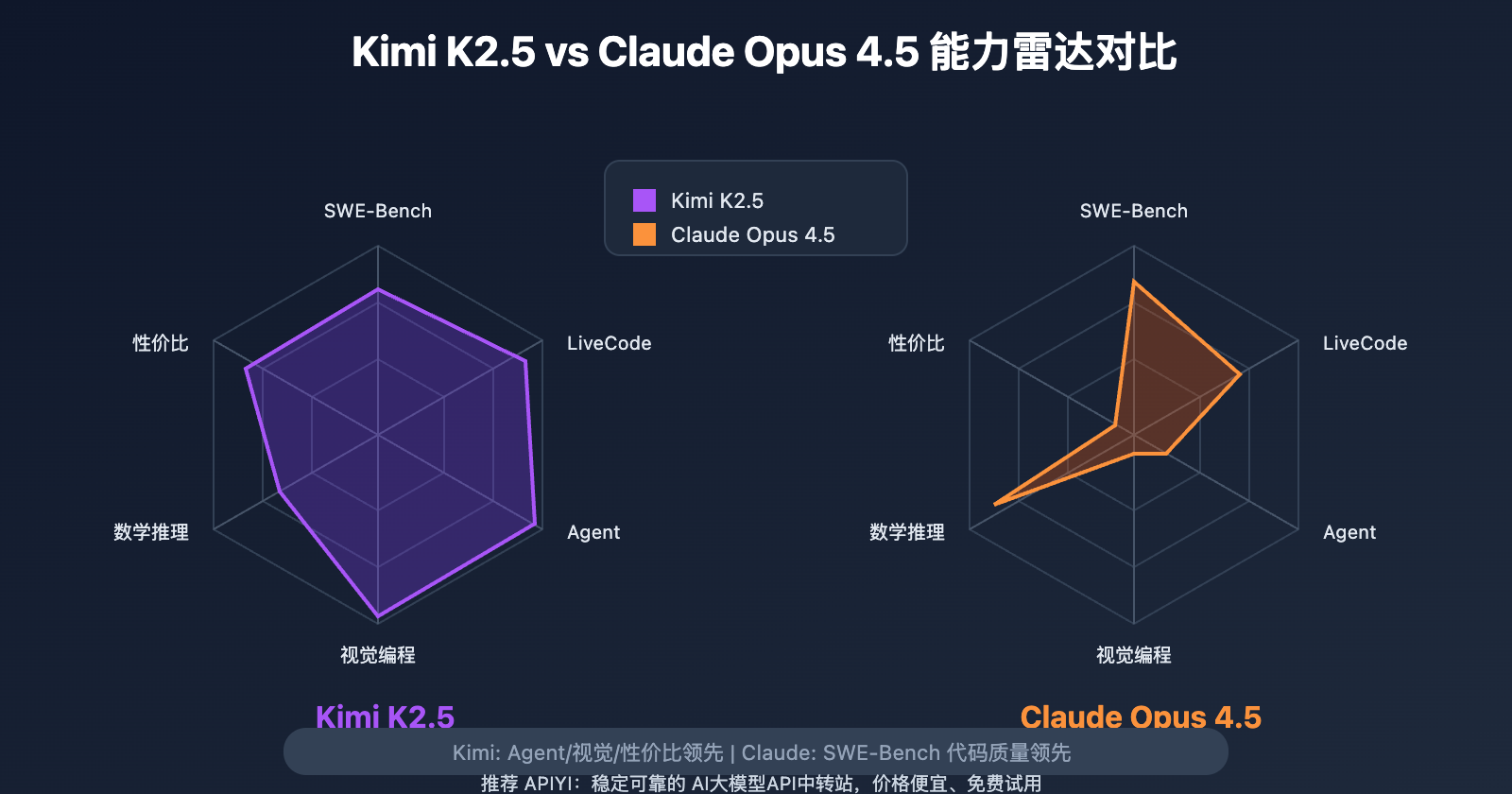
Kimi K2.5 vs Claude Opus 4.5 编程能力详解
代码修复能力 (SWE-Bench)
SWE-Bench Verified 是衡量模型修复真实 GitHub Issue 能力的权威基准:
| 模型 | SWE-Bench Verified | SWE-Bench Multi | Terminal-Bench |
|---|---|---|---|
| Claude Opus 4.5 | 80.9% | – | 59.3% |
| Kimi K2.5 | 76.8% | 73.0% | 50.8% |
| GPT-5.2 | 80.0% | – | 54.0% |
Claude Opus 4.5 在 SWE-Bench 上以 80.9% 的成绩领先,这意味着在修复复杂代码 Bug 时,Claude 的成功率更高,调试周期更短。
Claude 的优势场景:
- 关键系统的代码审查
- 复杂的重构任务
- 需要极低容错率的生产代码
实时交互编程 (LiveCodeBench)
LiveCodeBench v6 测试模型在实时交互环境下的编程能力:
| 模型 | LiveCodeBench v6 | 说明 |
|---|---|---|
| GPT-5.2 | 87.0% | 最强 |
| Kimi K2.5 | 83.1% | 开源最强 |
| Claude Opus 4.5 | 64.0% | 明显落后 |
在实时编程对话场景中,Kimi K2.5 以 83.1% 大幅领先 Claude 的 64.0%,这说明 Kimi 更擅长在交互式开发中快速响应和迭代。
前端与视觉编程
| 能力 | Kimi K2.5 | Claude Opus 4.5 |
|---|---|---|
| UI 设计转代码 | ✅ 原生支持 | ❌ 不支持 |
| 视频转代码 | ✅ 支持 | ❌ 不支持 |
| 复杂动画生成 | ✅ 强 | ⚠️ 一般 |
Kimi K2.5 的 Vibe Coding 能力是 Claude 完全不具备的——直接从 Figma 设计稿或操作视频生成完整前端代码。
Kimi K2.5 vs Claude Opus 4.5 推理能力对比
数学推理 (AIME/GPQA)
| 基准 | Kimi K2.5 | Claude Opus 4.5 | GPT-5.2 |
|---|---|---|---|
| AIME 2025 | 96.1% | 92.8% | 100% |
| GPQA-Diamond | 87.6% | – | 92.4% |
| HMMT 2025 | 95.4% | – | 93.3% |
在数学竞赛级别的推理任务中,Kimi K2.5 (96.1%) 超越了 Claude Opus 4.5 (92.8%),展现出更强的逻辑推理能力。
工具增强推理
当模型可以使用搜索和代码执行工具时:
| 模型 | 无工具 | 有工具 | 提升幅度 |
|---|---|---|---|
| Kimi K2.5 | 31.5% | 51.8% | +20.1% |
| Claude Opus 4.5 | – | – | +12.4% |
| GPT-5.2 | – | – | +11.0% |
Kimi K2.5 在工具增强推理上的提升幅度 (+20.1%) 远超 Claude (+12.4%),这得益于其 Agent Swarm 架构对工具调用的优化。
Kimi K2.5 vs Claude Opus 4.5 Agent 能力
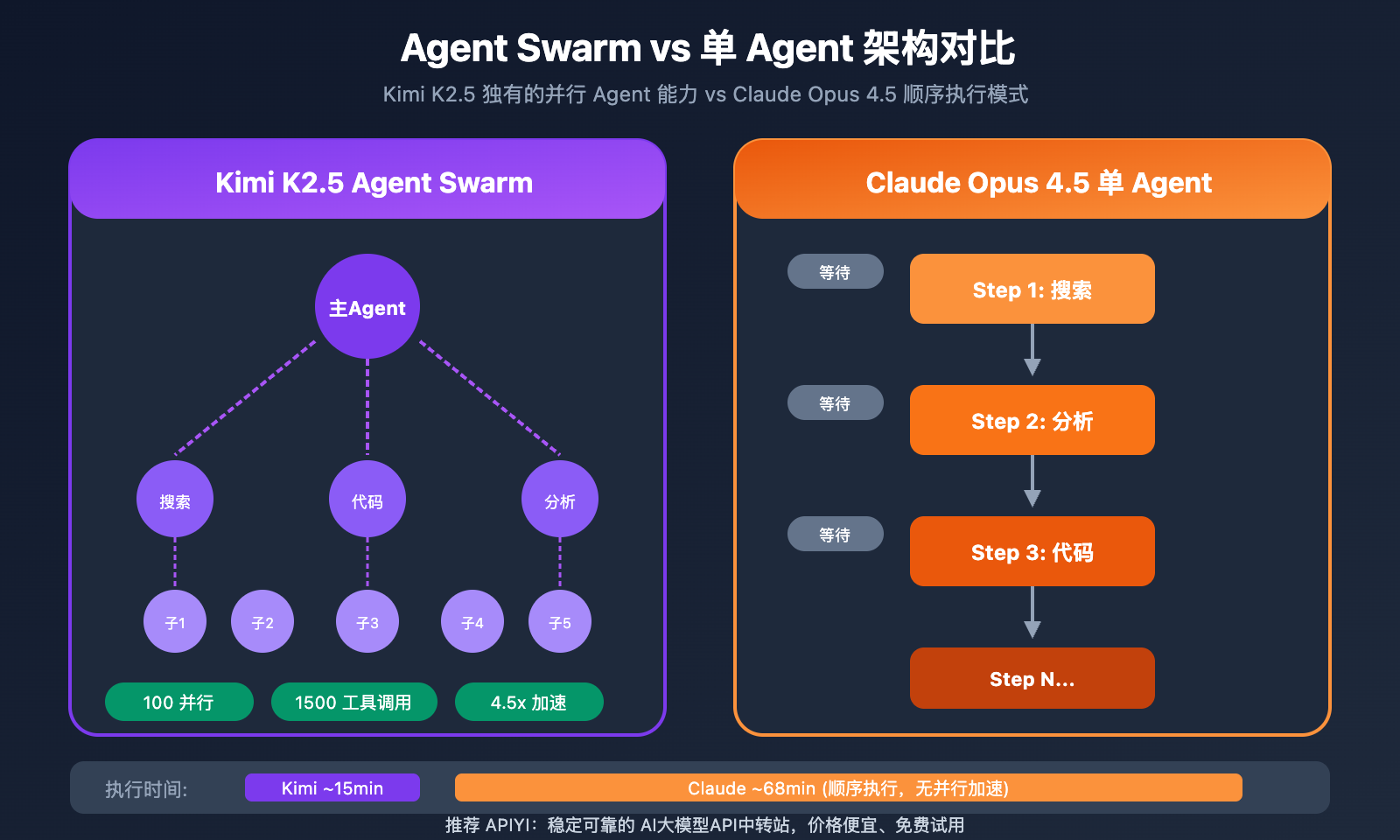
Agent Swarm:Kimi K2.5 独有优势
| 能力 | Kimi K2.5 | Claude Opus 4.5 |
|---|---|---|
| 并行 Agent | 最多 100 个 | 单 Agent |
| 工具调用 | 最多 1500 次/任务 | 受限 |
| 执行效率 | 4.5x 加速 | 基准 |
| 自动任务拆分 | ✅ 无需预设 | ❌ 需手动编排 |
Kimi K2.5 的 Agent Swarm 是其最大差异化优势:
- 自动将复杂任务拆分为并行子任务
- 动态实例化专业子 Agent
- 无需预定义角色或工作流
- 复杂研究任务完成时间缩短至 1/4.5
实际案例:一个需要数小时的跨领域市场调研任务,Kimi K2.5 可以在十几分钟内完成,而 Claude 需要顺序执行多轮对话。
Kimi K2.5 vs Claude Opus 4.5 价格成本对比
API 定价对比
| 模型 | 输入价格 | 输出价格 | 相对成本 |
|---|---|---|---|
| Kimi K2.5 | $0.60/M | $3.00/M | 基准 |
| Claude Opus 4.5 | $5.00/M | $25.00/M | ~9x |
| GPT-5.2 | $0.90/M | $3.80/M | ~1.4x |
年度成本估算 (100 万请求,5K 输出/请求)
| 模型 | 年成本 | 对比 |
|---|---|---|
| Kimi K2.5 | ~$13,800 | 基准 |
| GPT-5.2 | ~$56,500 | 4.1x |
| Claude Opus 4.5 | ~$150,000 | 10.9x |
Claude Opus 4.5 的年成本是 Kimi K2.5 的 10 倍以上。对于预算有限的团队,这个差距足以影响技术选型。
成本效益分析
| 场景 | 推荐模型 | 原因 |
|---|---|---|
| 初创公司 | Kimi K2.5 | 成本仅 $13,800/年,性能够用 |
| 大型企业关键系统 | Claude Opus 4.5 | 代码质量优先,成本可接受 |
| 高频 Agent 任务 | Kimi K2.5 | Agent Swarm + 低成本 |
| 前端开发 | Kimi K2.5 | 视觉编程独家优势 |
成本建议:大多数场景下,Kimi K2.5 的 76.8% SWE-Bench 成绩已经足够优秀,4% 的差距不值得 9 倍的溢价。可通过 APIYI apiyi.com 同时接入两个模型,关键任务用 Claude,日常开发用 Kimi。
Kimi K2.5 vs Claude Opus 4.5 选择指南
选择 Kimi K2.5 的场景
| 场景 | 原因 |
|---|---|
| 预算敏感项目 | 成本仅为 Claude 的 1/9 |
| Agent 自动化工作流 | Agent Swarm 独家能力 |
| 前端开发、UI 还原 | 视觉编程原生支持 |
| 数学推理任务 | AIME 96.1% > Claude 92.8% |
| 需要超长上下文 | 256K > 200K |
| 高频 API 调用 | 成本效益更高 |
选择 Claude Opus 4.5 的场景
| 场景 | 原因 |
|---|---|
| 关键系统代码审查 | SWE-Bench 80.9% 最高 |
| 复杂后端重构 | 代码质量更稳定 |
| 企业级合规要求 | Anthropic 安全声誉 |
| 对错误零容忍 | 调试周期更短 |
빠른 연동 예시
APIYI를 통해 두 모델을 동시에 연동하기
import openai
# 클라이언트 생성 - APIYI로 설정
client = openai.OpenAI(
api_key="YOUR_API_KEY", # apiyi.com에서 발급받으세요
base_url="https://vip.apiyi.com/v1"
)
# 일상적인 개발용 Kimi K2.5 (높은 가성비)
response_kimi = client.chat.completions.create(
model="kimi-k2.5",
messages=[{"role": "user", "content": "React 장바구니 컴포넌트 구현해 줘"}]
)
# 핵심 코드 리뷰용 Claude (고품질)
response_claude = client.chat.completions.create(
model="claude-opus-4-5-20251101",
messages=[{"role": "user", "content": "이 결제 인터페이스 코드의 보안성을 검토해 줘..."}]
)
연동 팁: APIYI(apiyi.com)에서 무료 테스트 크레딧을 받아보세요. 하나의 API Key로 Kimi K2.5와 Claude Opus 4.5를 동시에 호출하며, 상황에 맞춰 모델을 전환해 비용을 효율적으로 관리할 수 있습니다.
자주 묻는 질문 (FAQ)
Q1: Kimi K2.5와 Claude Opus 4.5의 코딩 능력은 얼마나 차이가 나나요?
SWE-Bench Verified 벤치마크에서는 Claude(80.9%)가 Kimi(76.8%)보다 4.1% 높게 나타났습니다. 하지만 LiveCodeBench 실시간 대화형 코딩에서는 Kimi(83.1%)가 Claude(64.0%)를 크게 앞섰죠. 결론적으로 Claude는 복잡한 코드 수정에, Kimi는 빠른 반복 개발에 더 적합하다고 할 수 있습니다.
Q2: 9배의 가격 차이, Claude Opus 4.5는 그만한 가치가 있을까요?
사용 환경에 따라 다릅니다. 높은 연봉을 받는 엔지니어 팀에게는 Claude의 4% 더 높은 코드 품질이 디버깅 시간을 단축해 주어 투자 대비 효율(ROI)이 더 좋을 수 있습니다. 하지만 예산이 한정적인 스타트업이나 API 호출 빈도가 높은 경우에는 Kimi K2.5의 가성비가 훨씬 뛰어납니다. 권장 사항: 핵심 코드 검토는 Claude를, 일상적인 개발 작업은 Kimi를 사용하는 것이 좋습니다.
Q3: Kimi K2.5와 Claude Opus 4.5를 동시에 사용하려면 어떻게 해야 하나요?
APIYI(apiyi.com)를 통한 통합 연동을 추천합니다:
- 회원가입 후 API Key를 발급받습니다.
base_url을https://vip.apiyi.com/v1로 설정합니다.model파라미터를 통해 모델을 전환합니다:kimi-k2.5또는claude-opus-4-5-20251101- 작업 유형에 따라 동적으로 모델을 선택하여 비용을 유연하게 조절해 보세요.
总结
Kimi K2.5 对比 Claude Opus 4.5 的核心结论:
- 代码质量:Claude 略优 (SWE-Bench 80.9% vs 76.8%),但差距仅 4%
- 综合性价比:Kimi K2.5 成本仅为 Claude 的 1/9,大多数场景更划算
- 独家能力:Kimi 拥有 Agent Swarm、视觉编程等 Claude 不具备的能力
- 推荐策略:日常开发用 Kimi K2.5,关键代码审查用 Claude Opus 4.5
两个模型均已上线 APIYI apiyi.com,建议通过平台获取免费额度,实际测试后根据业务需求选择。
参考资料
⚠️ 链接格式说明: 所有外链使用
资料名: domain.com格式,方便复制但不可点击跳转,避免 SEO 权重流失。
-
Kimi K2.5 官方技术报告: 完整基准测试数据
- 链接:
kimi.com/blog/kimi-k2-5.html - 说明: 获取 SWE-Bench、AIME 等官方测试结果
- 链接:
-
Claude Opus 4.5 模型卡: Anthropic 官方性能数据
- 链接:
anthropic.com/claude - 说明: 查看 Claude 的官方基准成绩
- 链接:
-
AI Model Benchmarks 2026: 第三方独立评测
- 链接:
artificialanalysis.ai - 说明: 多模型横向对比数据
- 链接:
-
Four Giants Comparison 深度评测: 详细场景对比分析
- 链接:
medium.com(搜索 "Kimi K2.5 vs Claude Opus 4.5") - 说明: 实际使用体验和成本分析
- 链接:
作者: 技术团队
技术交流: 欢迎在评论区分享你的模型选型经验,更多对比评测可访问 APIYI apiyi.com 技术社区