Gemini API を活用して画像認識サービスを構築する多くのチームが、共通の悩みを抱えています。gemini.google.com のウェブ版で同じ画像とプロンプトを入力すると、モデルは詳細を正確に認識し、構造化された回答を返してくれるのに、gemini-3.5-flash API に切り替えて同じことを行うと、結果が明らかに粗くなり、重要な情報が欠落してしまうという現象です。この「ウェブ版は強力で、API は弱い」という体感差は、モデルそのものの性能が低下したわけではなく、ウェブ版と API の間にある「エンジニアリング層の差」が表面化しているに過ぎません。
本記事では、一つの核心的な結論を解説します。ウェブ版 Gemini は、プロンプトの最適化、多段階推論、ツール呼び出し、結果の検証を自動で行う「総合的なエージェント」であるのに対し、API 呼び出しは「生のモデル」を直接叩くため、入力したものがそのまま出力されるという違いがあります。この差を理解した上で、単なる「プロンプト調整」にとどまらない 6 つの API 改善テクニックを実践すれば、画像認識の精度をウェブ版と同等のレベルまで安定させることが可能です。

なぜ Gemini API の画像認識はウェブ版より劣るのか:エージェントと生のモデルの差
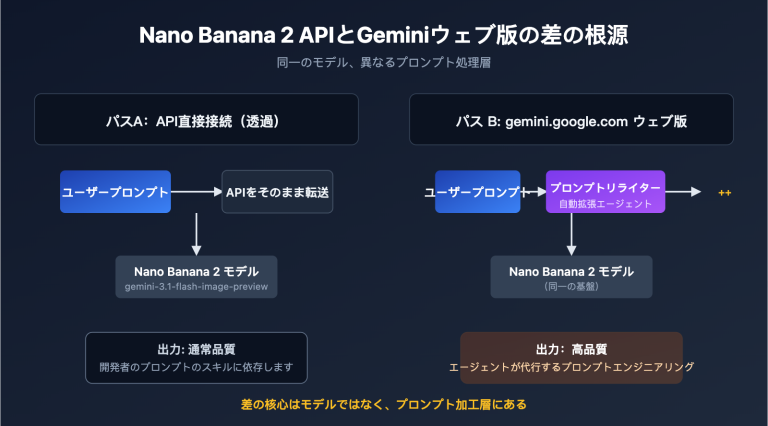
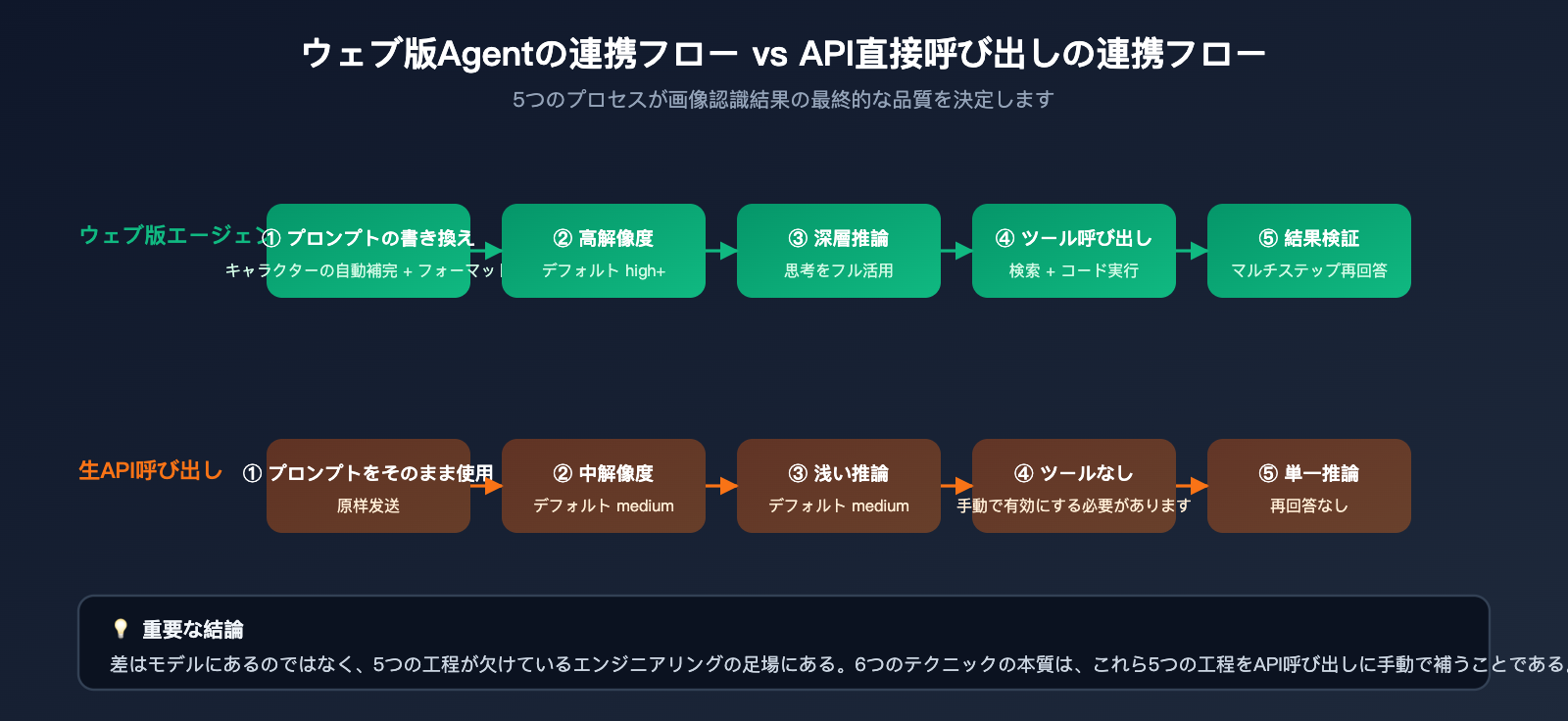
この差を明確にするために、まず gemini.google.com が画像を送信してから最終的な回答を得るまでに、裏側でどれほど多くの処理を行っているかを理解する必要があります。Google が公開している Agentic Vision(エージェント型ビジョン)のドキュメントや、APIYI (apiyi.com) で観測したウェブ版と API の応答差から見ると、ウェブ版は本質的に基盤モデルを中心に構築された「製品レベルのエージェント」であり、ユーザーが明示的に要求しなくても、少なくとも以下の 5 つの処理を自動で行っています。
- プロンプトの自動書き換え: 「この画像を識別して」という指示を、役割、タスク、出力形式を含んだ完全な命令へと補完する。
- 高解像度処理: 内部でより高い解像度設定で画像を処理し、詳細がぼやけたピクセルに圧縮されないようにする。
- 推論予算の最適化: デフォルトで高強度の推論予算(thinking_level=high に相当)を割り当て、モデルに「思考」する時間を与える。
- ツール呼び出し: 必要に応じてコード実行やウェブ検索などの組み込みツールを呼び出し、詳細の真実性をクロスチェックする。
- 結果の検証と再試行: 出力結果に対してフォーマットの確認や「再回答」の判断を行い、曖昧な回答があればモデルに再度問いかける。
一方、API を直接呼び出す場合、これらの 5 つの処理は自動的には行われません。言い換えれば、あなたは「完全な機能を持つモデル」を呼び出しているつもりでも、実際には「エンジニアリング上の足場(フレームワーク)」を失った状態で運用しているのです。以下の表は、両者の使用方法における主要なリンクの差異をまとめたものです。
| 比較項目 | gemini.google.com ウェブ版 | gemini-3.5-flash API |
|---|---|---|
| プロンプト処理 | 自動書き換え、役割と形式の補完 | ユーザー入力をそのまま使用 |
| 画像解像度 | デフォルトで高解像度 | デフォルトで中解像度(手動調整が必要) |
| 推論予算 | 高強度、上限なし | デフォルトは中程度(thinking_level で設定可能) |
| ツール呼び出し | 検索、コード実行を標準搭載 | デフォルトはオフ(明示的な有効化が必要) |
| 結果検証 | エージェントによる多段階検証 | 単一推論、検証なし |
| 課金の透明性 | 月額プランに含まれる | トークンごとの従量課金 |
APIYI (apiyi.com) のような集約ゲートウェイを利用し、同じ画像とプロンプトで gemini-3.5-flash API、Claude Opus、GPT-5.5 の画像認識結果を並べて比較することをお勧めします。これにより、現在のタスクが「モデルの能力」によって制限されているのか、それとも「エンジニアリング上のプロセス」によって制限されているのかを迅速に判断できるようになります。
Gemini API 識図テクニック 1:media_resolution パラメータの引き上げ
Gemini 3 シリーズから導入された media_resolution パラメータは、API が画像を「見る」ためにどれだけのトークンを割り当てるかを直接制御します。このパラメータには low、medium、high、ultra high の 4 段階があり、デフォルトは通常 medium に設定されています。小さな文字、領収書、回路図、UI スクリーンショットなど、詳細情報が密集した画像の場合、medium では不十分なことが多く、モデルが画像を粗い特徴マップに圧縮してしまい、細部が失われてしまいます。
以下の表は、4 段階の実際の違いを示しています。タスクの種類に応じて選択する際の参考にしてください。
| 解像度設定 | トークン消費量 | 推奨シーン | よくある問題 |
|---|---|---|---|
| low | 最低 | サムネイル、ロゴ認識 | 小さな文字がほぼ消失 |
| medium(デフォルト) | 中程度 | 通常の写真、人物 | 細部がぼやける |
| high | やや高い | ドキュメント、表、領収書 | 情報が概ね読み取り可能 |
| ultra high | 最高 | 複雑な図面、密集したUI | 公式サイトの認識精度に近い |
識図業務においては、このパラメータを medium から high に変更するだけで、認識精度が一段階向上することがほとんどです。予算に余裕があり、かつタスクで小さな文字や密集した表を扱う場合は、迷わず ultra high を選択するのも合理的な判断です。
# APIYI を経由して gemini-3.5-flash を呼び出し、メディア解像度を high に明示的に設定
from google import genai
from google.genai import types
client = genai.Client(
api_key="YOUR_APIYI_KEY",
http_options={"base_url": "https://api.apiyi.com"}
)
resp = client.models.generate_content(
model="gemini-3.5-flash",
contents=[image_part, "画像内のすべての可視テキストを抽出し、表形式で出力してください"],
config=types.GenerateContentConfig(
media_resolution="MEDIA_RESOLUTION_HIGH"
)
)
print(resp.text)
APIYI (apiyi.com) 経由で呼び出す場合、パラメータはそのまま下層へ透過されるため、ゲートウェイによる二次的なパッケージングは行われません。公式ドキュメントに従って値を設定して問題ありません。
Gemini API 識図テクニック 2:thinking_level=high の明示的な有効化
Gemini 3.5 Flash に導入された thinking_level パラメータは、モデルが回答を生成する前の内部的な推論の深さを制御します。識図タスクにおいて、「十分に時間をかけて考える」ことと「十分に注意深く考える」ことは、細部を正確に捉えられるかどうかの分かれ目となります。API のデフォルト設定は品質よりも速度を優先しているため、識図業務では明示的に high に設定し、Web 版のように空間推論やカウントに十分な時間を与えることを推奨します。
| thinking_level | 推奨シーン | 体感の違い |
|---|---|---|
| low | シンプルな会話、スタイル判定 | 速度が速い、認識が粗い |
| medium | 通常の質疑応答 | 平均的なレベル |
| high(識図推奨) | ドキュメント、領収書、カウント、空間推論 | 公式サイトに近い体感 |
公式ドキュメントでは、直感に反する重要なポイントとして、「thinking_level=high を使用する場合は、プロンプトをより直接的かつ簡潔に書くべきである」と強調されています。「ステップバイステップで推論してください」「あらゆる状況を考慮してください」といった従来の Chain-of-Thought(思考の連鎖)手法は、古いモデルの能力を補うためのものであり、Gemini 3 シリーズに対しては「過剰分析」を招く原因となります。
🎯 パラメータ設定のヒント:
media_resolution=HIGHとthinking_level=highを識図タスクのデフォルトの組み合わせとして、APIYI (apiyi.com) の呼び出しテンプレートに組み込んでおきましょう。その後、業務の体感に合わせて ultra high や low へ微調整することで、リクエストごとにパラメータを試行錯誤する手間を省くことができます。
Gemini API 画像認識テクニック 3:指示は user prompt ではなく system_instruction に記述する
API利用時によくある誤解として、役割設定、タスクの説明、出力形式、ユーザーの質問など、すべてを user prompt に詰め込んでしまうケースがあります。これでは、モデルが毎回コンテキストを読み直す必要があり非効率です。Web版の「システムプロンプト」と同様に、キャッシュを再利用する仕組みを活用しましょう。
正しいアプローチは、「不変の指示」を system_instruction に含めることです。
config = types.GenerateContentConfig(
media_resolution="MEDIA_RESOLUTION_HIGH",
thinking_level="high",
system_instruction=(
"あなたは厳格な画像分析アシスタントです。"
"回答する際は、画像内に明確に確認できる詳細のみを引用し、推測で語らないでください。"
"出力は構造化されたJSON形式とし、フィールドは entities/attributes/text に固定してください。"
)
)
こうすることで、2つのメリットが得られます。1つ目は、モデルが常に統一されたルールに従うため、回答の安定性が増すこと。2つ目は、System Prompt Caching(システムプロンプトキャッシュ)が有効になり、入力コストを最大10倍削減できることです。これは、長期的なバッチ処理を行う画像認識業務において非常に価値があります。APIYI(apiyi.com)の管理画面では、モデルIDごとにキャッシュヒット率を確認できるため、最適化の効果を簡単にモニタリングできます。
Gemini API 画像認識テクニック 4:コード実行を有効にしてモデルに「画像を拡大して見せる」
Googleは「Gemini 3 Flash」のAgentic Visionに関する発表の中で、明確なデータを提示しています。それは、ネイティブモデルにコード実行ツールを組み合わせることで、画像認識タスクの品質が平均5%〜10%向上するというものです。その仕組みは、モデルが内部でPythonコードを生成し、画像の切り抜き、拡大、回転、ピクセル読み取りなどを行い、処理後のサブ画像を再度自分自身に分析させるというものです。これはまさに、Web版でデフォルトで行われている処理です。
APIではコード実行はデフォルトで無効になっているため、明示的に宣言する必要があります。
config = types.GenerateContentConfig(
media_resolution="MEDIA_RESOLUTION_HIGH",
thinking_level="high",
tools=[types.Tool(code_execution=types.ToolCodeExecution())]
)
resp = client.models.generate_content(
model="gemini-3.5-flash",
contents=[image_part, "画像内のすべての赤いボタンの数を数え、その位置をリストアップしてください"],
config=config
)
カウント、空間推論、高密度なUI解析など、公式に「コード実行で精度が向上する」と認められているタスクにおいて、これは最も費用対効果の高い最適化手法です。APIYI(apiyi.com)での観測によると、コード実行を有効にすると全体的なレイテンシがわずかに上昇する傾向があります。そのため、非同期処理の業務ではデフォルトで有効にし、同期処理が必要な業務では必要に応じて有効にすることをおすすめします。
Gemini API 識図テクニック 5:大きな画像は base64 インラインではなく File API を使おう
数MBを超えるような大きな画像を扱う際、多くの開発チームが base64 形式でリクエストボディに直接埋め込む方法をとっています。この手法は小さな画像であれば問題ありませんが、リクエスト全体のサイズが 20MB を超えると Gemini の制限に抵触してしまいます。その結果、一部の画像が自動的に圧縮され、認識精度が低下する原因となります。
公式が推奨する使い分けの基準は以下の通りです。
| 画像サイズ | 推奨される転送方法 | 理由 |
|---|---|---|
| 5MB 未満 | base64 インライン | リクエストが軽量で呼び出しが簡単 |
| 5〜20MB | File API アップロード | リクエストサイズの肥大化を回避 |
| 20MB 超 | File API 必須 | base64 エンコードはリクエストを破壊するため |
| 複数回利用 | File API 推奨 | 一度のアップロードで複数回参照でき、トークンを節約 |
File API を使うもう一つのメリットは、同じ画像を複数のリクエストで再利用できるため、アップロードの手間とコストを省ける点です。APIYI(apiyi.com)のゲートウェイ経由であれば、File API のエンドポイントは共通の認証情報で利用できるため、画像アップロードのためにわざわざ Google Cloud のアカウントを別途用意する必要はありません。

Gemini API 画像認識テクニック 6:Agent リンクを構築して多段階検証を行う
ここまでの 5 つのテクニックをマスターすれば、API 呼び出しの精度は公式サイトの体感値にかなり近づいているはずです。しかし、Web 版にはもう一つ「必殺技」があります。それが「多段階検証」です。これは、回答を生成した後に 2 回目の推論を行って重要な事実をチェックし、不確かな回答があれば「再回答」を行うという仕組みです。この機能は API には標準搭載されていないため、簡単な Agent リンクを自分で構築する必要があります。
最小構成の 2 ステップ・リンクは以下の通りです:
- 1 回目の呼び出し:
gemini-3.5-flashに構造化された認識結果(JSON 出力)を生成させる。 - 2 回目の呼び出し: 1 回目の結果と元の画像を同時にモデルへ渡し、「この画像に基づき、以下の結論はすべて正しいか?」と問いかける。
もし 2 回目の呼び出しで「正しくない」と判断された項目があれば、3 回目の「再回答」をトリガーします。この一連のリンクは、APIYI(apiyi.com)を利用すれば、同じ base_url と API キーでシームレスに連携できるため、追加のサービス構築は不要です。契約書の読み取り、医療画像の補助アノテーション、セキュリティコンプライアンス審査など、高い認識精度が求められる業務において、多段階検証は精度を 90% から 98% へ引き上げるための重要なステップとなります。
| タスクタイプ | 推奨リンク | 単ステップパラメータ |
|---|---|---|
| 一般的な画像認識・質問 | 単ステップ | high + thinking_high |
| 文書抽出 | 単ステップ + JSON 検証 | ultra high + thinking_high |
| 複雑なカウント | 2 ステップ + コード実行 | high + thinking_high + tools |
| 高精度業務 | 3 ステップ(認識 → 検証 → 再回答) | ultra high + thinking_high + tools |
実践パラメータテンプレート:6 つのテクニックを 1 つの再利用可能な呼び出しにまとめる
すぐに活用できるよう、これまでの 6 つのテクニックを網羅した「画像認識タスク用デフォルトテンプレート」を作成しました。ほとんどの業務でスタート地点として最適です。
from google import genai
from google.genai import types
# APIYIのAPIキーとベースURLを設定
client = genai.Client(
api_key="YOUR_APIYI_KEY",
http_options={"base_url": "https://api.apiyi.com"}
)
# システムプロンプトの設定
SYSTEM = (
"あなたは厳格な画像分析アシスタントです。画像内で明確に確認できる内容のみを引用し、"
"推測で回答しないでください。出力は厳密な JSON 形式とし、entities/attributes/text フィールドを含めてください。"
)
# 設定の定義
config = types.GenerateContentConfig(
media_resolution="MEDIA_RESOLUTION_HIGH",
thinking_level="high",
system_instruction=SYSTEM,
tools=[types.Tool(code_execution=types.ToolCodeExecution())],
response_mime_type="application/json"
)
# モデル呼び出し
resp = client.models.generate_content(
model="gemini-3.5-flash",
contents=[image_part, "SYSTEM の指示に従ってこの画像を認識してください"],
config=config
)
print(resp.text)
実際の運用時には、APIYI(apiyi.com)側でテンプレートを共通の SDK 呼び出し層として抽象化することをお勧めします。業務側は画像と質問を渡すだけで、パラメータはゲートウェイ側で一括注入するようにすれば、業務ごとに同じトラブルを繰り返すリスクを回避できます。

よくある質問(FAQ):Gemini APIの画像認識とWeb版の差について
Q1:これらのパラメータをすべて有効にすれば、APIはWeb版よりも劣ることはなくなりますか?
ほとんどの業務において公式サイトと同等の精度を実現できますが、極めて難易度の高いタスク(極小文字、低照度、特殊なアートスタイルの画像など)では、依然としてわずかに劣る可能性があります。これは、Web版が公開されていない内部の拡張パイプラインを呼び出しているためです。このようなケースでは、APIYI(apiyi.com)上で他のベンダーのビジョンモデルと横並びで比較し、最適なモデルを見つけることをお勧めします。
Q2:thinking_level=high にするとコストは倍増しますか?
内部的な推論トークン使用量は増加しますが、これは出力段階のみに影響します。また、画像認識業務の全体コストにおいて、画像トークンが占める割合の方が通常は大きいです。thinking を high に設定することで得られる精度の向上は、増加するコストを大きく上回ります。特に、人間の確認作業を代替するような業務では非常に有効です。
Q3:base_url はどう変更すればいいですか?Google公式SDKを使用しています。
google-genai SDKでは、http_options={"base_url": "https://api.apiyi.com"} を指定することで、リクエストをAPIYI(apiyi.com)のゲートウェイに転送できます。APIキーはAPIYIの管理画面で生成したものを使用すればよく、Google Cloudプロジェクトを別途作成する必要はありません。
Q4:プロンプトの最適化だけで解決できますか?
プロンプトの調整だけで解決できる範囲には限界があり、解像度、推論の深さ、ツール呼び出しといった「モデル外部」の能力をカバーすることはできません。本記事で紹介した6つのテクニックのうち、プロンプトに関連するのは3番目のみで、残りの5つはエンジニアリング層でのレバレッジ(テコ入れ)となります。
Q5:Web版では認識できる「画像内の日本語の透かし(ウォーターマーク)」を、APIでは見逃してしまいます。どうすればいいですか?
透かしのような細かいディテールは、多くの場合、高解像度設定とコード実行によるトリミングの組み合わせに依存します。media_resolution を ultra high に設定し、code execution を有効にした上で、2段階の検証リンクでチェックを行うと、安定して認識できるようになります。
まとめ:Web版のエンジニアリング能力をAPI呼び出しに補完する
冒頭の問いに戻りましょう。なぜGemini APIの画像認識結果はWeb版に及ばないのでしょうか?その答えは「モデルが弱いから」ではなく、「Web版が強力なエンジニアリングの足場(スカフォールド)を備えているから」です。Gemini-3.5-Flash APIを直接呼び出す際は、プロンプトの書き換え、解像度の段階設定、推論予算、ツール呼び出し、結果の検証といった工程をすべて自分自身で補う必要があります。この点を理解すれば、6つのテクニックの本質は「Web版が裏で行っていることを、自分のAPI呼び出しチェーンに移植すること」であると分かります。
実践的な手順は明確です。まず media_resolution と thinking_level を最大化し、指示を system_instruction に移してキャッシュを有効にします。複雑な画像認識タスクには code execution を有効にし、大きな画像はFile API経由で処理し、最後に2〜3ステップのエージェントチェーンで高い精度を担保します。この一連の組み合わせを実装した上で、APIYI(apiyi.com)の管理画面でヒット率や遅延を比較すれば、多くのチームが「Web版 vs API」の差を肉眼ではほとんど分からないレベルまで縮めることができるはずです。
📌 著者:本記事はAPIYI(apiyi.com)技術チームが作成しました。Gemini、Claude、GPTシリーズモデルの接続実践やパラメータ調整ガイドについては、APIYIヘルプセンターをご覧ください。