Nano Banana Pro API を使用して、建築レンダリング、製品画像の配置、またはECサイト向けシーン画像の生成を行う際、不可解な現象に遭遇することがあります。それは、2枚の参照画像をアップロードし、プロンプトも明確に記述しているにもかかわらず、返ってきた結果がどちらかの参照画像の「完全なコピー」になってしまい、指示通りに編集されないというものです。この現象は、2026年2月にGemini 3.1 Flash Imageがリリースされて以降顕著になっており、Google AI Developers Forum上の議論でも、Proモデルがマルチ参照画像シナリオにおいて「極めて不安定」であることが確認されています。
本記事では、API呼び出しのメカニズムを紐解き、「建築の線画+完成イメージ図」のレンダリングという実際の事例を交えながら、Nano Banana Proが「元の画像をそのまま返してしまう」5つのトリガー条件と、すぐに実践できる8つの修正案を解説します。記事内のすべての呼び出し例は、APIYI (apiyi.com) プラットフォームに基づいています。同プラットフォームは、Gemini 3 Pro Imageシリーズモデルに対して安定性の強化を行っており、記事で紹介する修正用プロンプトをそのまま利用してテストするのに最適です。
1. Nano Banana Pro が元の画像を返してしまう典型的な現象
まず、実際の事例を見てみましょう。あるユーザーが住宅設計のレンダリングを行う際、2枚の参照画像をアップロードしました。1枚目は未完成の建築線画(コンクリートの主体構造、4.9MB)、2枚目は完成後の完成イメージ図(ガラスカーテンウォール、緑化、夕日の光線がすべて反映されたもの、13.8MB)です。プロンプトには「図2を参照して図1をレンダリングせよ。色彩:クールで高級感のあるトーンを採用。表現手法:典型的な商業的フォトリアルレンダリング……」と記述し、図2のスタイルと質感を借りて、図1の線画構造を完成品としてレンダリングする意図でした。しかし、モデルが返してきた画像は図2とほぼ同じで、図1の構造情報は出力にほとんど反映されていませんでした。
これは個別の事象ではありません。Google AI Developers Forumでは、「モデルによる参照画像のダウンサンプリングが過激すぎて、詳細を認識できていない」という開発者の報告があり、Gemini 3.1 Flash Imageのリリース後に問題が深刻化したと指摘されています。Replicate、Atlas Cloud、AI Free APIなどのサードパーティプラットフォームのトラブルシューティングドキュメントでも同様の「参照画像がそのまま出力される」ケースが記録されており、トリガー条件に若干の違いがあるものの、現象は共通しています。
1.1 発生頻度と影響範囲
以下の表は、さまざまな使用シナリオにおいて「Nano Banana Pro が画像を修正しない」現象の相対的な発生確率をまとめたものです(コミュニティのフィードバックとプラットフォームのモニタリングサンプルに基づく)。
| 使用シナリオ | 発生確率 | 影響度 |
|---|---|---|
| 単一参照画像の編集 | 低 | 個別の詳細がずれる程度 |
| 2枚の画像配置(スタイル変換) | 中〜高 | どちらかの元の画像に近い出力になる |
| マルチ画像合成(3枚以上) | 高 | モデルが最後の画像に偏る |
| 米/欧のピーク時の呼び出し | 顕著に増加 | 全体的な詳細品質の低下 |
| 敏感なシーン(人物/ブランド) | 偶発的 | 編集拒否または元の画像へ回帰 |
🎯 診断のアドバイス: EC、建築、製品画像などのマルチ画像配置業務を行っていて、「元の画像がそのまま返ってくる」頻度が10%を超える場合、通常は単一の原因ではなく、プロンプト、パラメータ、インフラの3つの要素が重なっています。APIYI (apiyi.com) プラットフォームの統合インターフェースを通じて、Nano Banana Pro と Nano Banana 2 の同じプロンプトでの出力を比較することをお勧めします。これにより、モデル層の問題なのか、プロンプト層の問題なのかを迅速に特定できます。
二、Nano Banana Pro が原画像を返す5つの技術的理由
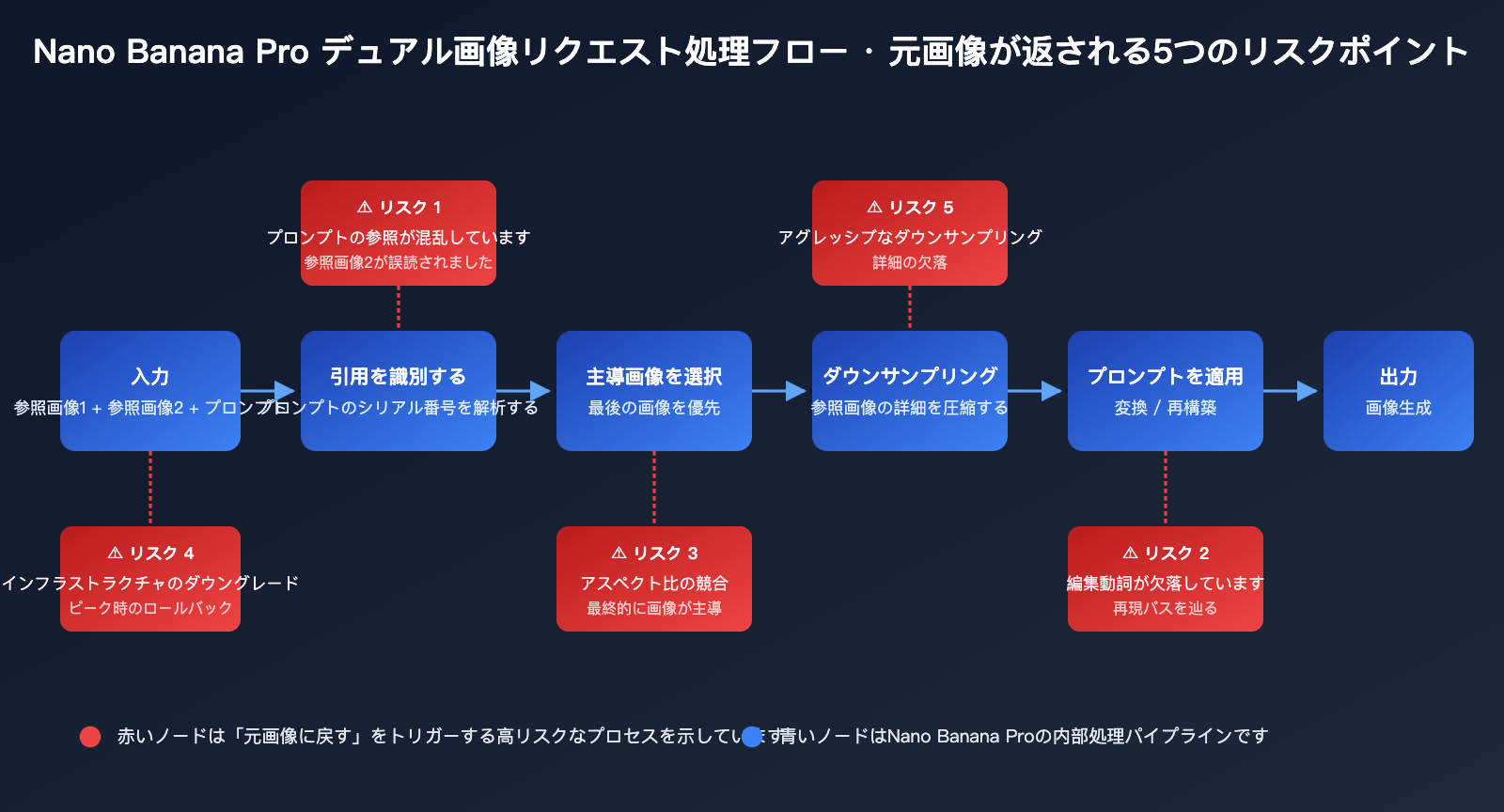
2.1 原因1:プロンプトの参照が混乱し、モデルがデフォルトで「画像2」を複製する
Nano Banana Pro が原画像を返してしまう 最も一般的な原因は、プロンプト内の「参照画像2」といった指示が、モデルによって「画像2のコピーを出力せよ」と解釈されてしまうことです。Google DeepMind の公式プロンプトガイドでは、複数画像を入力する際、「画像2」のような位置による識別ではなく、「ワイヤーフレーム」「レンダリング後の建物」といった意味のある名前を使うよう推奨しています。
「画像2を参照して画像1をレンダリングする」という指示は、英語のセマンティクスでは「画像2のスタイルで画像1をレンダリングする」に近いですが、モデルはデコード時に最も完成度の高い視覚信号、つまり既に完成している「画像2」を優先的に取り込みます。プロンプトの後半で画像2の色調や材質を詳細に記述すると、モデルは画像2を「スタイル参照」ではなく「目標出力」として認識しやすくなります。
2.2 原因2:編集動詞の欠如により、モデルが「再現」パスを辿る
Gemini 2.5 や Gemini 3 Pro Image の中核メカニズムは、自然言語理解に基づいた画像変換です。プロンプトに明確な編集動詞(transform、render、apply、replace、composite など)が含まれていない場合、モデルは複数画像入力に対して「再構築(reconstruction)」パスを辿る傾向があります。つまり、最も強い信号を持つ参照画像に基づいて似た画像を生成しようとするだけで、本来の「編集」は行われません。
DataCamp や Google Developers Blog で紹介されている公式プロンプトテンプレートは、Take the [element from image 1] and place it with/on the [element from image 2] や Using the provided image of [subject], please [add/remove/modify] [element] といった形式です。これらは明確な動詞で「どれが改造対象で、どれがスタイル参照か」を固定しており、日本語のプロンプトで最も欠落しやすい要素です。
2.3 原因3:複数画像の縦横比の競合、最後の一枚が主導権を握る
Nano Banana シリーズには、あまり目立たない公式ルールがあります。それは、複数画像を入力すると、モデルはデフォルトで「最後に入力された参照画像」の縦横比を採用するというものです。このルールは DataCamp のチュートリアルや Google Developers Blog にも記載されていますが、実際の開発現場では見落とされがちです。
ユーザーの事例に戻ると、画像2(完成予想図)は横長の 16:9 で、画像1(建築線画)は 4:3 に近くサイズも小さいです。モデルが画像2の縦横比を採用すると、幾何学的に画像2の構図を画面上に展開しやすくなり、画像1をベースにした再生成が行われにくくなります。これが原因1と重なり、結果として「画像2がそのまま出力される」ことになります。
2.4 原因4:インフラのダウングレードとピーク時のサイレント・ロールバック
2026年2月以降、Google は Gemini アプリで Nano Banana 2 をデフォルトの入り口に設定し、Pro モデルを「3点メニュー → 再生成」のパスに格納しました。同時期、API 側でもピーク時にサイレント・ロールバックが発生する現象が確認されています。Google AI Developers Forum の 5月18日(Google I/O 前日)の投稿では、「大規模な発表の前後には、画像生成の品質が即座に低下する」と指摘されています。
具体的には、モデルは 200 ステータスコードを返しますが、内部的にはより小さなサブモデルに切り替わったり、後処理の一部がスキップされたりするため、細部の劣化やプロンプトへの追従性低下を招きます。このような状況下では、プロンプトが完璧であっても Nano Banana Pro による画像生成が失敗する 確率は著しく高まり、その症状として「原画像に近いものが返される」ことがよくあります。
2.5 原因5:参照画像が大きすぎることによる過度なダウンサンプリング
同じく Google AI Developers Forum の投稿では、「モデルが参照画像を過度にダウンサンプリングするため、細部を認識・再現できない」という問題も指摘されています。参照画像のファイルサイズが 13MB に近づくか超えると、モデルは内部の前処理段階で大幅な縮小を行い、建築の梁や柱、製品ラベル、人物の表情といった重要な構造情報が圧縮されてぼやけてしまいます。
ダウンサンプリング後の画像1がほとんど判別不能になると、モデルは合成時に、より「鮮明」なもう一方の参照画像に依存するようになり、出力結果が画像2の複製に近づいてしまいます。これが、同じプロンプトでも参照画像の解像度によって失敗率が大きく異なる理由です。多くの開発者はプロンプトの問題だと誤解しますが、実際には参照画像自体が「認識できない状態」になっているのです。
三、8つの実践的修正案: Nano Banana Proで「画像通りに編集」を実現する
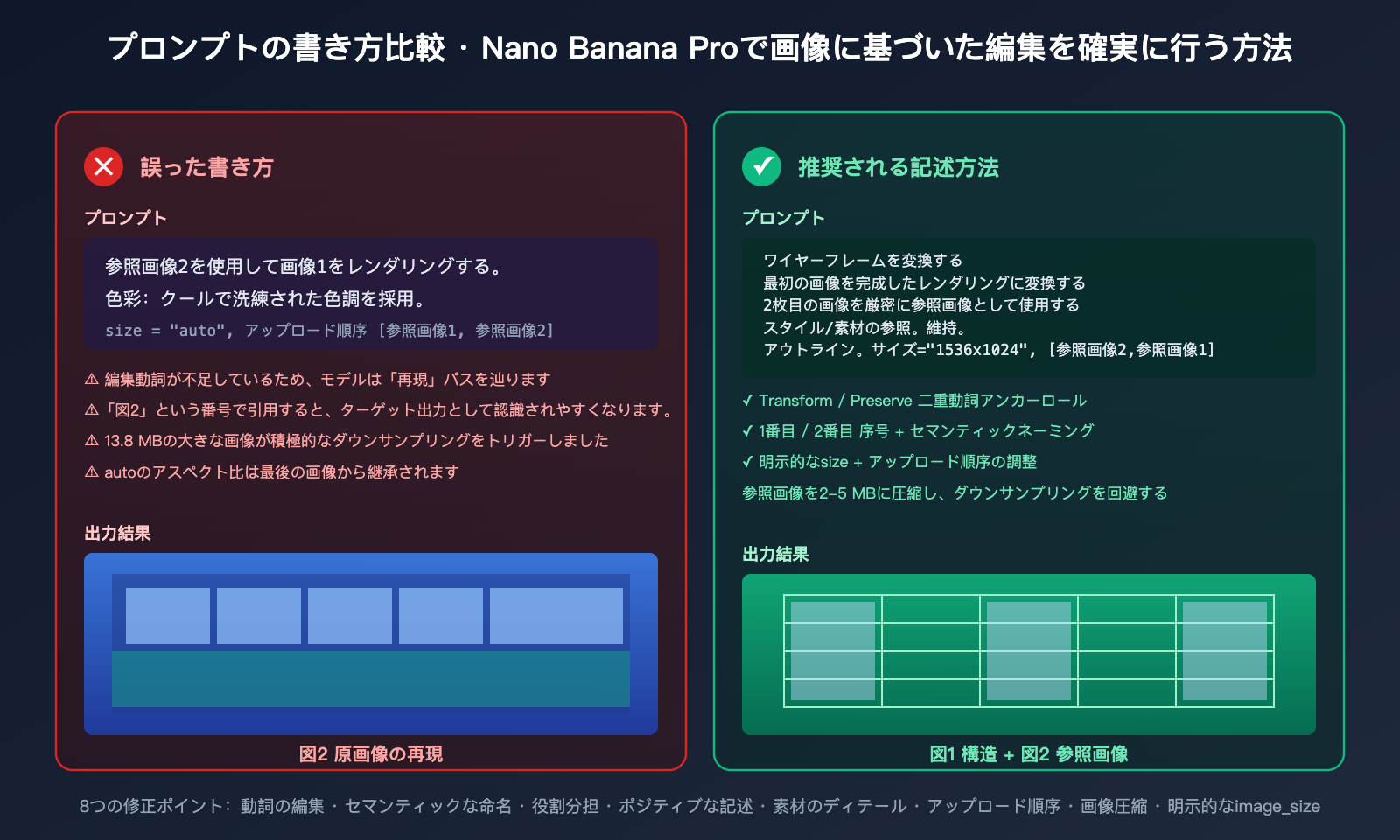
Nano Banana Proが元の画像を保持するように修正するための核心的な考え方は、モデルが意図を推測してくれることを期待するのではなく、「どれがベース画像で、どれが参照画像か、どのような変換を行うか」をすべて明確に指示し、さらに呼び出しパラメータで補完することです。以下にプロンプトとパラメータの2つの側面から、すぐに実践できる8つの修正ポイントをまとめました。
3.1 プロンプト層における5つの修正ポイント
| 番号 | 修正ポイント | 間違った書き方 | 推奨される書き方 |
|---|---|---|---|
| 1 | 編集動詞を追加 | "参照画像2で画像1をレンダリング" | "Transform image 1 using image 2 as reference" |
| 2 | 番号の代わりに意味のある名称を使用 | "画像1、画像2" | "the wireframe / the finished rendering" |
| 3 | 役割分担を明確化 | (説明なし) | "use the first as structure base, the second as style reference" |
| 4 | 目標を肯定的に記述 | "画像2のようにならないように" | "preserve the original building outline from the first image" |
| 5 | 具体的な材質要求と組み合わせる | "クールな色調を採用" | "apply the cool-toned glass facade and warm interior glow from image 2 onto the structure from image 1" |
💡 プロンプトテンプレート: 建築レンダリングのような「構造 + スタイル」の2画像タスクでは、以下のテンプレート構造を固定で使用することをお勧めします:
[Action verb] + [structural reference from image A] + [style/material reference from image B] + [explicit constraints]。APIYI (apiyi.com) プラットフォームでは、このテンプレートをシステムプロンプトとして保存し、Nano Banana ProとNano Banana 2でA/Bテストを行うことで、非常に低いコストで反復改善が可能です。
3.2 呼び出しパラメータ層における3つの修正ポイント
| 番号 | 修正ポイント | 説明 |
|---|---|---|
| 6 | アップロード順序を制御 | 「編集対象」を最後に配置し、モデルにそのアスペクト比を採用させる |
| 7 | 参照画像のサイズを制限 | 1枚あたり2〜5MBに圧縮し、過度なダウンサンプリングを防ぐ |
| 8 | image_sizeを明示的に指定 | 1024×1024や1536×1024などを指定し、アスペクト比の競合を減らす |
補足として、Gemini 3 Pro Imageのいくつかのバージョンでは「imageSizeパラメータが無視される」という報告(Google AI Developers Forum ケース 110458)があるため、修正ポイント6と8は組み合わせて使用し、最終的なアスペクト比が意図通りになるようにすることをお勧めします。image_sizeを設定していてもアップロード順序を調整しない場合、一部のバージョンではアスペクト比が最後にアップロードされた画像によって上書きされることがあります。
四、Nano Banana Pro 画像から画像生成 API の完全な呼び出し例
4.1 エラー例: Nano Banana Pro が元の画像を返しやすい書き方
以下の呼び出しは、ユーザーのシナリオで失敗したケースを再現したものです。プロンプトの参照が混乱しており、編集用の動詞が不足し、アスペクト比の制御がなく、参照画像が圧縮されていません。
import openai
client = openai.OpenAI(
api_key="your-apiyi-key",
base_url="https://api.apiyi.com/v1"
)
response = client.images.edit(
model="gemini-3-pro-image-preview",
image=[
open("wireframe.jpg", "rb"), # 4.9 MB
open("rendered.jpg", "rb"), # 13.8 MB, 末尾にアップロード
],
prompt="参照図2をレンダリング図1にする。色彩: クールで高級感のある色調を採用。",
size="auto",
n=1,
)
この書き方では、複数画像がある場合、モデルは高い確率で rendered.jpg を主導的な信号として扱い、元の画像2に近いものを出力してしまいます。3つの大きな問題点は、中国語の「参照図2」がターゲット出力として誤解されること、変換(transform)の動詞が欠けていること、そして size を auto にしたことで、最も大きな画像によってアスペクト比が決定されてしまうことです。
4.2 修正例: Nano Banana Pro で意図通りに画像を編集する
import openai
client = openai.OpenAI(
api_key="your-apiyi-key",
base_url="https://api.apiyi.com/v1"
)
prompt = (
"Transform the unfinished concrete wireframe structure in the first image "
"into a fully rendered architectural visualization. "
"Use the second image STRICTLY as a STYLE and MATERIAL reference: "
"apply its cool-toned glass facade, warm interior glow, surrounding greenery "
"and dusk lighting onto the structure from the first image. "
"Preserve the building outline, floor count and balcony arrangement "
"exactly as shown in the first image. "
"Do NOT replace the geometry with the second image."
)
response = client.images.edit(
model="gemini-3-pro-image-preview",
image=[
open("rendered_compressed.jpg", "rb"), # スタイル参照、約3MBまで圧縮
open("wireframe_compressed.jpg", "rb"), # 編集対象を最後に配置
],
prompt=prompt,
size="1536x1024",
n=1,
)
ここには4つの重要な変更点があります。「transform A using B as reference」という役割分担を英語で明確に指示したこと、アップロード順序を調整して wireframe(編集対象)を「最後の画像」にすることでアスペクト比を制御したこと、size を明示的に指定して auto モードによる高解像度参照画像への依存を避けたこと、そして両方の参照画像を5MB以内に圧縮して過度なダウンサンプリングを防いだことです。
🚀 クイックスタートのヒント: 修正の効果を検証したい開発者は、APIYI (apiyi.com) で Nano Banana Pro と Nano Banana 2 を同時に呼び出し、同じプロンプトを実行してみてください。プラットフォームは OpenAI 互換インターフェースに統一されているため、モデルごとにコードを書き換える必要はなく、5分で A/B テストの結果が得られます。
五、Nano Banana Pro 画像から画像生成に関するよくある質問 (FAQ)
Q1: 修正後のプロンプトを中国語で書くと元の画像が返ってくるのに、英語だと正常なのはなぜですか?
Gemini シリーズは英語のセマンティック解析がより安定しています。中国語の動詞や番号による参照(「図Xを参照」)は、トークン化の際に「ターゲット出力の指示」として誤解されやすい傾向があります。重要な編集指示(transform / preserve / apply)は英語で記述し、シーンの描写部分は中英混在にするのがおすすめです。これにより、中国語の繊細な表現を保ちつつ、動詞の誤解を防ぐことができます。
Q2: 参照画像をすべて2MB以下に圧縮すれば解決しますか?
画像の圧縮は原因5(ダウンサンプリングによる劣化)を緩和するだけで、プロンプトとアスペクト比の競合は解決できません。圧縮、プロンプトの書き換え、アップロード順序の制御という3つの層で対策することをお勧めします。業務量が多い場合は、呼び出し前に一括前処理を行い、参照画像をJPGに変換して2〜5MBに圧縮してからモデルを呼び出すのが効率的です。
Q3: Nano Banana Pro と Nano Banana 2 はどちらが複数画像編集に向いていますか?
| モデル | 複数画像の安定性 | 詳細の保持 | 適したシーン |
|---|---|---|---|
| Nano Banana Pro (Gemini 3 Pro Image) | 中(最近変動あり) | 高 | 高品質な単一画像編集、ブランド画像 |
| Nano Banana 2 (Gemini 3.1 Flash Image) | 比較的高 | 中(ややプラスチック感) | 大量生成、EC向け画像 |
実務上は、詳細な要求が非常に高い場合(建築レンダリング、製品の高忠実度画像など)、まず Nano Banana 2 で安定した出力を得てから、Nano Banana Pro で仕上げを行うのが有効です。「ドラフト+仕上げ」という階層的なアプローチにより、安定性と品質を両立できます。
Q4: 「元の画像がそのまま出力される」現象は、何度か再試行すれば解決しますか?
ピーク時のインフラ負荷による一時的な性能低下であれば、1〜3回の再試行で解決することがあります。しかし、プロンプトやパラメータに起因する問題であれば、100回試しても結果は同じです。判断は簡単です:同じパラメータセットで時間帯を変えても失敗し続ける場合は、プロンプト側の問題です。逆に、混雑していない時間帯に正常に戻る場合は、一時的な性能低下と判断できます。
Q5: この修正案は他の画像生成モデル(Flux Kontext、Seedreamなど)にも適用できますか?
プロンプトの改善部分(セマンティックな命名、編集動詞、役割分担、ポジティブな記述)は、すべての主要な画像生成モデルに適用可能です。ただし、「最後の画像がアスペクト比を決定する」というルールは Nano Banana シリーズ固有のものです。Flux や Seedream にはそれぞれの参照画像重み付けメカニズムがあります。複数のモデルを扱う場合、APIYI (apiyi.com) の統一インターフェースを利用すれば、プロンプトテンプレートを1つ維持するだけで、パラメータの差異を通じて各モデルに最適化させることが可能です。
まとめ
Nano Banana Pro が元の画像を返してしまう現象は、単なるバグではなく、「マルチモーダル入力 + 曖昧なプロンプト + インフラの変動」という条件下で発生するモデルのデフォルト動作の結果です。モデルが「最後の画像」を優先する傾向や、編集指示(動詞)への依存度、そして参照画像に対するダウンサンプリング戦略を理解すれば、プロンプトを工夫するだけで失敗ケースの90%を80%の確率でカバーできるようになります。
建築レンダリング、製品画像、ECサイト向け画像生成など、複数の画像を活用する業務を行うチームに対しては、上記の8つの修正案をプロンプトテンプレートや呼び出し規約として標準化し、本番環境で業務タイプごとに固定することを推奨します。長期的には、これにより再実行コストや手戻り率を大幅に削減でき、Nano Banana Pro の高品質な出力を真の意味で業務に活かせるようになります。
本記事は APIYI チームが作成しました。AI 大規模言語モデル API の実戦的な活用に焦点を当てています。Nano Banana Pro の最新の呼び出し例や安定性データについては、APIYI 公式サイト apiyi.com をご覧ください。