2026年5月6日、xAIはすべてのAPIユーザーに対し、「Grok 4.3 release and xAI API model retirement(Grok 4.3のリリースとxAI APIモデルの廃止)」というタイトルの公式メールを一斉送信しました。このメールには、開発者に最も大きな影響を与える2つの重要なニュースが含まれていました。Grok 4.3がAPIでフルリリースされたこと、そしてgrok-4-fast、grok-4-0709、grok-3、grok-code-fast-1、grok-imagine-image-proを含む8つの旧モデルが、2026年5月15日12:00(太平洋標準時)をもって一斉に廃止されるというものです。このメールの背後には、大規模なバージョンアップと同時に、9日間で完了させなければならない移行のカウントダウンが始まっています。

Grok 4.3の今回のリリースで最も注目すべきは、名称のアップグレードではなく、1Mトークンのコンテキストウィンドウ、1.25ドル/2.50ドルの入出力価格設定、そして3段階で調整可能な推論強度の組み合わせです。この価格帯により、Grok 4.3はGemini 3.1 ProやGPT-5.4と同等のメインストリーム推論モデルの競争領域に直接参入しましたが、xAI特有の高いトークン処理速度という強みは維持されています。Grokシリーズに依存しているチームは、APIYI(apiyi.com)プラットフォームを通じて早めに接続テストを行うことをお勧めします。OpenAI互換の統一インターフェースを利用することで、複数モデル間の切り替えに伴う移行コストを最小限に抑えることができます。
Grok 4.3の主要スペックと価格設定の完全解説
Grok 4.3は、xAIがメールの中で「私たちがこれまで構築した中で最も高速で、最もインテリジェントなモデル」と明言した最新世代のフラッグシップモデルです。エージェントによるツール呼び出し(agentic tool calling)と指示追従(instruction following)の両ランキングで上位に位置しており、コード、エージェント、複雑な推論をカバーする汎用フラッグシップとして位置付けられています。スペック面では、コンテキストウィンドウをGrok 4時代の256Kから1Mトークンへと直接拡張しており、Gemini 3 ProやClaude 4.7と同等クラスです。これは、コードベース全体や長文の技術ドキュメントを一度に読み込めることを意味します。
以下の表は、xAI APIにおけるGrok 4.3の主要パラメータをまとめたものです。すべてのデータは、xAIの公式メールおよびArtificial Analysisのサードパーティ実測ページに基づいています。
| パラメータ項目 | Grok 4.3の値 | 備考 |
|---|---|---|
| コンテキストウィンドウ | 1,000,000トークン | 入力+出力共有 |
| 入力価格 | 1.25ドル / 1Mトークン | GPT-5.4より50%安く、Gemini 3.1 Proと同等 |
| 出力価格 | 2.50ドル / 1Mトークン | Grok 4時代の15ドルから約83%値下げ |
| 推論強度 | low / medium / highの3段階 | パラメータで深い推論の予算を制御 |
| 入力モダリティ | テキスト + 画像 | 視覚理解をサポート |
| 出力モダリティ | テキスト | 直接的な画像生成は不可 |
| ツール呼び出し | ネイティブ function calling | 構造化出力と並列呼び出しをサポート |
| 出力速度 | 約207トークン/秒 | Artificial Analysisによる実測値 |
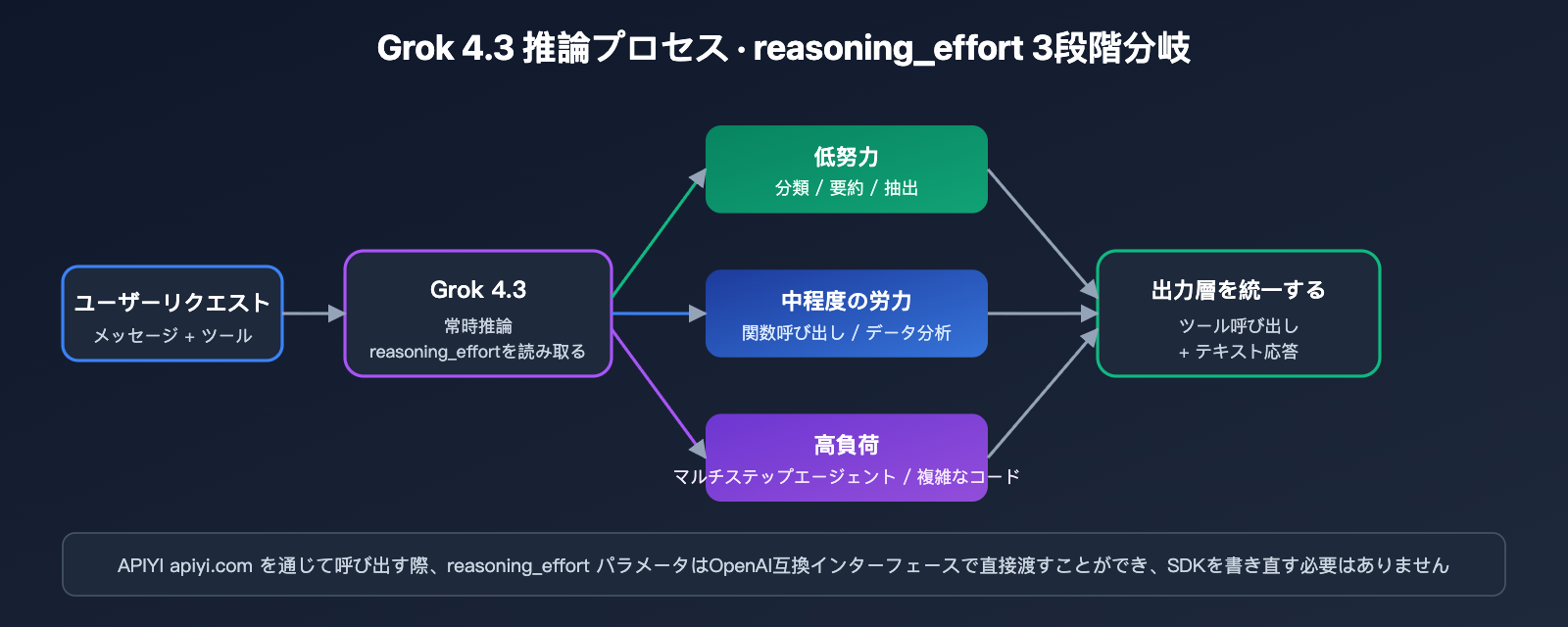
3段階の推論強度(reasoning effort)は、Grok 4.3が前世代と一線を画す重要な新機能です。これにより、開発者はタスクの複雑さに応じてモデルの「思考」の深さを調整でき、遅延とコストに直接影響を与えます。このメカニズムはOpenAIのreasoning_effort設計を参考にしていますが、xAIは推論自体を「常時オン(always-on)」の状態とし、その深さを調整できるようにしています。以下の表は、3段階の強度における典型的な適用シナリオと影響をまとめたものです。
| 推論強度 | 典型的なシナリオ | 遅延特性 | コストへの影響 |
|---|---|---|---|
| low | 単純な分類、要約、ルールベースの抽出 | 非推論モデルに近い | 出力トークン量が最小 |
| medium | 関数呼び出し、データ分析、コード補完 | 遅延と品質のバランス | 推奨されるデフォルト設定 |
| high | マルチステップエージェント、複雑な数学、長距離コード | 長い思考フェーズ | 出力トークンが大幅に増加 |
🎯 接続のアドバイス: どのレベルを選択すべきか迷っているチームは、まずAPIYI(apiyi.com)プラットフォーム上でmedium設定を使用して実際の業務サンプルをテストし、その後の精度とコスト対効果に基づいてhigh設定へのアップグレードを検討することをお勧めします。統一インターフェースにより、SDKを書き直すことなく、モデル間でreasoning_effortパラメータをワンクリックで切り替えることができます。
Grok 4.3 のエージェント機能および指示追従ランキングにおける実測パフォーマンス
Grok 4.3 が xAI から「エージェントによるツール呼び出しと指示追従においてリーダーボードのトップに立つ」と強調された背景には、Artificial Analysis、τ²-Bench、IFBench、GDPval-AA といった第三者機関による評価データがあります。Artificial Analysis Intelligence Index における総合スコアは 53.2 で、評価実行コストは約 395 ドルと、Grok 4.20 から約 20% のコスト削減を実現しています。実際のエージェントシナリオに最も近いとされる「τ²-Bench Telecom(電気通信カスタマーサービスの双方向ツール呼び出しシミュレーション)」では、Grok 4.3 は 98% のスコアを獲得し、Grok 4.20 から 5 ポイント向上させ、GLM-5.1 と同等の水準に達しました。
開発者にとって特に注目すべきは、実際の経済価値を伴うワークフローを測定する「GDPval-AA」です。Grok 4.3 は GDPval-AA で 1500 ELO を獲得しました。これは前世代の Grok 4.20 0309 v2 の 1179 ELO から 321 ポイントもの大幅な上昇であり、Gemini 3.1 Pro Preview、Muse Spark、GPT-5.4 mini (xhigh)、Kimi K2.5 などのモデルを上回っています。指示追従(Instruction Following)の面では、IFBench で 81% のスコアを維持しており、Grok 4.20 0309 v2 と同等のパフォーマンスを維持しています。
| ベンチマーク | Grok 4.3 スコア | 同クラス比較 | 主な評価項目 |
|---|---|---|---|
| AA Intelligence Index | 53.2 | 上位 98% | 総合知能 |
| AA Coding Index | 41.0 | 上位 89% | コーディングとリファクタリング |
| τ²-Bench Telecom | 98% | GLM-5.1 と同等 | ツール呼び出し + ユーザー連携 |
| IFBench | 81% | Grok 4.20 と同等 | 複雑な指示追従 |
| GDPval-AA | ELO 1500 | Gemini 3.1 Pro Preview を上回る | 実際のワークフロー価値 |
注意点として、Grok 4.3 の強みは純粋なアルゴリズム競技ではなく、エージェントワークフローやツール呼び出しにあります。コードエージェント、ブラウザエージェント、カスタマーサービスボットなど、安定した JSON 出力や多段階のツール呼び出しが必要なアプリケーションにおいて、Grok 4.3 の信頼性は前世代から大幅に向上しています。ただし、チームの主要なシナリオが SWE-bench のような純粋なコード合成である場合は、APIYI (apiyi.com) プラットフォーム上で Grok 4.3、Claude 4.7 Opus、GPT-5.4 を同じテストセットで実行し、通過率に基づいて主力モデルを決定することをお勧めします。
xAI API モデル終了リストと移行の推奨事項
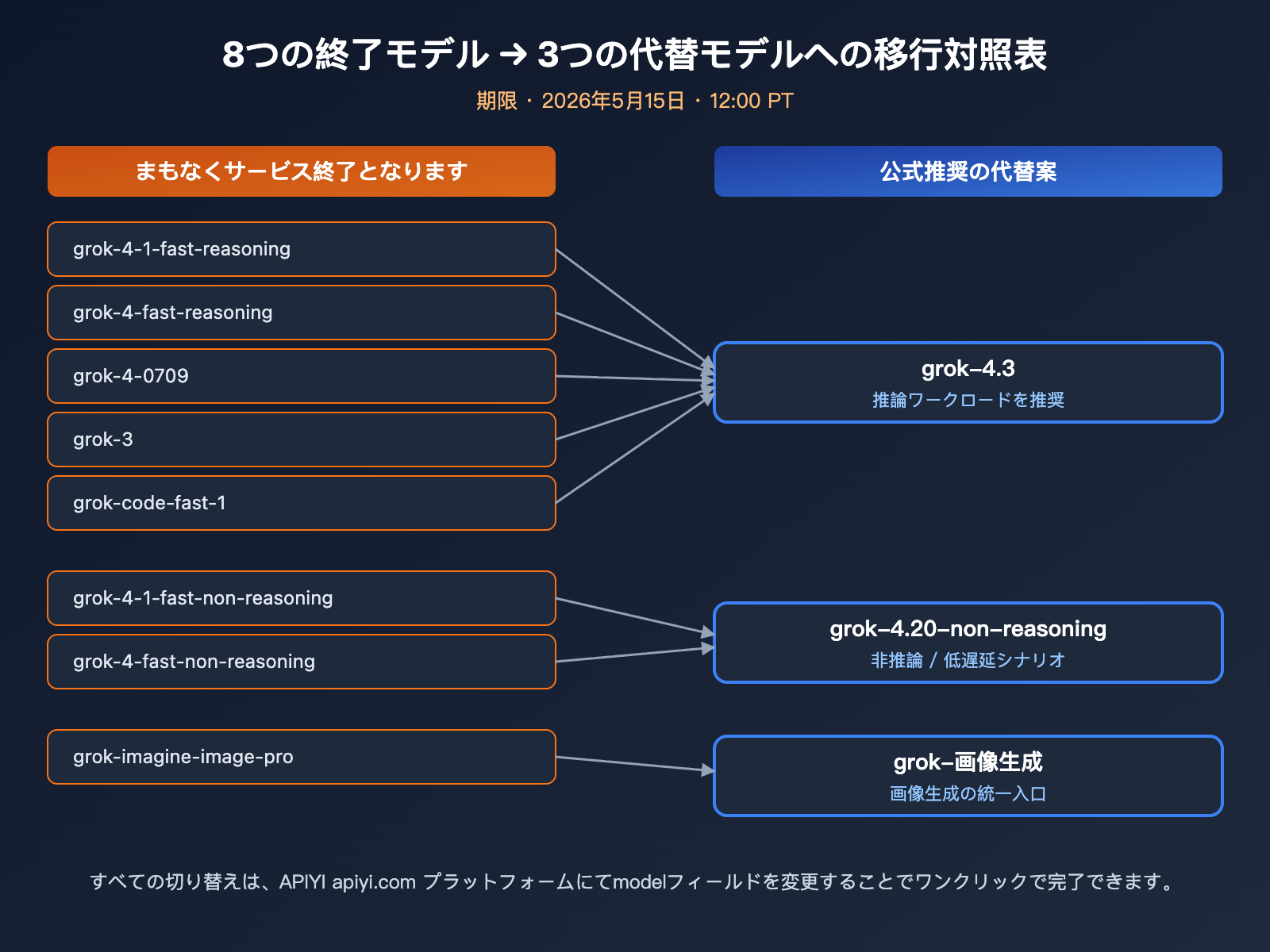
xAI は今回、テキスト推論、コードモデル、画像生成を含む計 8 つのモデルの提供を終了します。これは実質的に Grok 4 時代の SKU を一掃するものです。業務コード内でモデル名をハードコードしているチームにとっては、9 日以内にコード改修を完了させる必要がある重要な期限となります。以下の表に、影響を受けるモデルと公式が推奨する移行先をまとめました。
| 終了予定モデル | タイプ | 公式推奨の代替 | 移行の注意点 |
|---|---|---|---|
| grok-4-1-fast-reasoning | 推論 | grok-4.3 | 推論品質向上、価格低下 |
| grok-4-1-fast-non-reasoning | 非推論 | grok-4.20-non-reasoning | 低遅延特性を維持 |
| grok-4-fast-reasoning | 推論 | grok-4.3 | 1M コンテキストウィンドウ利用可能 |
| grok-4-fast-non-reasoning | 非推論 | grok-4.20-non-reasoning | API 形態の互換性を維持 |
| grok-4-0709 | 推論 | grok-4.3 | 初期 Grok 4 スナップショットの終了 |
| grok-code-fast-1 | コード | grok-4.3 | コード関連は 4.3 に統合 |
| grok-3 | 汎用 | grok-4.3 | Grok 3 時代の正式な終了 |
| grok-imagine-image-pro | 画像生成 | grok-imagine-image | 画像生成 SKU の簡素化 |
終了日時は 2026 年 5 月 15 日 12:00 PT(日本時間 5 月 16 日午前 4 時)です。期限を過ぎると、これら 8 つのモデル ID へのリクエストはすべてエラーとなります。5 月 6 日の通知から計算すると、開発者に残された期間は 9 日間であり、中規模以上の業務にとっては非常にタイトなスケジュールです。移行作業は以下の 3 ステップで行うことを推奨します。1. コード内のハードコードされたモデル ID をすべて特定する、2. APIYI (apiyi.com) プラットフォーム上でグレーテスト(段階的テスト)を実行する、3. ビジネスロジックを直接変更するのではなく、環境変数でモデルフィールドを切り替えられるようにする。
特に留意すべき点として、grok-code-fast-1 は過去半年間、多くのコードエージェントプロジェクトでデフォルトモデルとして使用されてきました。この終了は、この ID に依存する Cursor 系のツール、IDE プラグイン、CLI エージェントなどがすべて grok-4.3 への移行を必要とすることを意味します。コード関連のシナリオにおいて、Grok 4.3 は grok-code-fast-1 よりもツール呼び出しの安定性が向上していますが、トークンあたりのコストがわずかに高くなる可能性があるため、呼び出し予算の再評価が必要です。
Grok 4.3 と GPT-5.4、Claude 4.7、Gemini 3.1 Pro の比較分析
2026年第2四半期にリリースされた Grok 4.3 により、最先端の大規模言語モデル市場は史上最も激しい競争期を迎えています。Claude Opus 4.7 は SWE-bench Verified で 87.6% という圧倒的なスコアを維持し、Gemini 3.1 Pro は GPQA Diamond で 94.3% を記録しました。また、GPT-5.4 は長文推論の安定性において依然として基準となるモデルです。Grok 4.3 の立ち位置は「中程度の知能 + 極めて低価格 + 強力な Agent ツールチェーン」であり、コストに敏感な高頻度呼び出しシナリオに特化しています。
以下の表は、4つの主要モデルの主要な指標を比較したものです。価格の単位は、100万トークンあたりの米ドルです。
| モデル | 入力単価 | 出力単価 | コンテキスト | 主な強み・適したシナリオ |
|---|---|---|---|---|
| Grok 4.3 | $1.25 | $2.50 | 1M | Agent ツールチェーン、高頻度呼び出し、中程度の推論 |
| GPT-5.4 | $2.50 | $15.00 | 400K | 長文の一貫性、複雑なプランニング |
| Claude 4.7 Opus | $15.00 | $75.00 | 1M | 高度なコーディング、ドキュメント作成、詳細分析 |
| Gemini 3.1 Pro | $2.00 | $12.00 | 2M | マルチモーダル、動画理解、超長文ドキュメント |
この比較表から明らかなように、Grok 4.3 の出力トークン単価は Claude 4.7 Opus よりも30倍、Gemini 3.1 Pro よりも約4.8倍安価です。高頻度で呼び出されるカスタマーサポート Agent、コード Linter、大量データのクリーニングといった業務において、Grok 4.3 のコストパフォーマンスは圧倒的です。一方で、極めて高いコーディング品質やマルチモーダルな理解が求められる場面では、依然として Claude 4.7 Opus や Gemini 3.1 Pro に軍配が上がります。
🎯 マルチモデル戦略の提案: 高頻度な汎用タスクには Grok 4.3、複雑なコード生成やドキュメント作成には Claude 4.7 Opus、マルチモーダル処理には Gemini 3.1 Pro を使用することをお勧めします。APIYI (apiyi.com) の統合インターフェースを通じてビジネス層でモデルを振り分けることで、Grok 4.3 の低コストメリットを享受しつつ、重要な局面ではより強力なモデルを活用することが可能です。
Grok 4.3 API 移行ガイドとコード例
Grok 4.3 への移行はエンジニアリングの観点から非常にスムーズです。xAI は OpenAI 互換のチャット補完インターフェースを提供しているため、移行作業のほとんどは base_url と model フィールドの書き換えだけで完了します。すでに OpenAI SDK を使用しているプロジェクトであれば、以下のシンプルな Python サンプルコードで即座に導入可能です。
from openai import OpenAI
# APIYI を経由したクライアント設定
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1",
)
resp = client.chat.completions.create(
model="grok-4.3",
messages=[
{"role": "user", "content": "reasoning effort について一言で説明して"},
],
extra_body={"reasoning_effort": "medium"},
)
print(resp.choices[0].message.content)
base_url を APIYI (apiyi.com) プラットフォームに向けることで、Grok 4.3、Claude 4.7、GPT-5.4、Gemini 3.1 Pro を一つの入り口から呼び出せるようになります。モデルの切り替えは model パラメータを変更するだけで済み、認証やルーティングコードを書き直す必要はありません。この抽象化により、5月15日の旧モデル終了期限に向けた移行リスクを大幅に低減できます。
旧モデルから新モデルへの移行用に、最小限の変更で済むモデルIDの対応表を作成しました。コードに直接適用してください。
| 旧 model フィールド | 新 model フィールド | 他のパラメータの変更 |
|---|---|---|
| grok-3 | grok-4.3 | 必要に応じて reasoning_effort を追加 |
| grok-4-0709 | grok-4.3 | 必要に応じて reasoning_effort を追加 |
| grok-4-fast-reasoning | grok-4.3 | 必要に応じて reasoning_effort を追加 |
| grok-4-fast-non-reasoning | grok-4.20-non-reasoning | 変更不要 |
| grok-code-fast-1 | grok-4.3 | reasoning_effort=high を推奨 |
| grok-imagine-image-pro | grok-imagine-image | 画像 API エンドポイントは共通 |
Grok 4.3 よくある質問(FAQ)
Q1: Grok 4.3 は本当に 1M のコンテキストに対応していますか?長文での性能低下はありますか?
はい、Grok 4.3 は xAI API 上で正式に 1M トークンのコンテキストウィンドウを提供しており、Claude 4.7 Opus と同等のスペックです。ただし、すべての長文対応モデルと同様に、600K を超えるとニーズの理解に一定の低下が見られる場合があります。重要な情報はドキュメントの前半に配置することをお勧めします。APIYI(apiyi.com)プラットフォームを通じて、実際の業務で使用する長文ドキュメントで検索・抽出精度のテストを行い、Grok 4.3 を長文処理の主力として採用するかどうかを判断するのが良いでしょう。
Q2: 推論強度(low / medium / high)はどのように選べばよいですか?
低リスクのタスク(分類、要約、ルール抽出)には「low」、一般的な業務(カスタマーサポート、関数呼び出し、データ分析)には「medium」、複雑な推論(マルチステップの Agent、長いコードの解析、複雑な数学)には「high」を選択してください。「high」は出力トークン数とレイテンシを大幅に増加させるため、予算とレイテンシの SLA(サービス品質保証)を考慮して評価することをお勧めします。
Q3: 2026 年 5 月 15 日 12:00 PT 以降、古いモデルは引き続き使用できますか?
いいえ、使用できません。xAI からのメールには「2026 年 5 月 15 日以降、これらのモデルへのリクエストは機能しなくなります」と明記されており、期限を過ぎたリクエストは直接エラーが返されます。古いモデル ID をハードコードしているすべてのコードは、期限までに切り替えを完了させる必要があります。
Q4: 移行コストを最小限に抑えるにはどうすればよいですか?
最も安全な方法は、モデル名をコードに直接書き込むのではなく、環境変数や設定項目として抽象化しておくことです。APIYI(apiyi.com)の OpenAI 互換エンドポイントを活用すれば、移行作業は設定の変更と回帰テストを 1 回行うだけで完了します。
Q5: Grok 4.3 は Coding Agent に適していますか?
適しています。Grok 4.3 は τ²-Bench Telecom で 98% を達成しており、ツール呼び出しや多回対話の安定性は grok-code-fast-1 よりも向上しています。さらに単位コストが非常に低いため、高頻度で呼び出される IDE プラグイン、CLI Agent、自動運用スクリプトに最適です。
まとめ:Grok 4.3 リリースと xAI API 移行の重要ポイント
今回の Grok 4.3 リリースの最大の注目点は「より強力になった」ことだけでなく、「より安価になった」ことにあります。1M のコンテキストと高品質な Agent ツール呼び出しを Gemini 3.1 Pro と同価格帯($1.25/$2.50)で提供することで、高頻度な汎用モデルのコストパフォーマンスの基準を塗り替えました。同時に、8 つの旧モデルが 5 月 15 日に一斉終了することは、すべてのチームに対して「モデル ID を業務コードにハードコードせず、設定可能なルーティング層の背後に抽象化すべきである」という教訓を与えています。
私たちは、Grok 4.3 を高頻度呼び出しや Agent ツールチェーンの主力として活用し、APIYI(apiyi.com)の統一インターフェースを通じて移行することで、切り替えコストを最小限に抑えることを推奨します。また、Claude 4.7 Opus、GPT-5.4、Gemini 3.1 Pro といった複数のモデルを組み合わせ、タスクに応じて動的にスケジューリングすることで、コストと品質の最適なバランスを実現してください。
APIYI 技術チーム · AI モデル API と開発者ツールに関する実戦的な情報を発信しています。その他の技術記事は apiyi.com をご覧ください。