title: xAIのGrok 4.20 BetaシリーズがAPIYIに登場:4つの新モデルでAI活用の幅を拡大
description: xAIの最新モデル「Grok 4.20 Beta」シリーズがAPIYIプラットフォームで利用可能に。高速応答から多重エージェントによる深度推論まで、全4モデルの特長とコストパフォーマンスを徹底解説します。
xAIの「Grok 4.20 Beta」シリーズが、APIYIプラットフォームで正式に利用可能となりました。今回、4つの新モデルを一挙に追加。高速なQ&Aから、複数のAIエージェントが連携する高度なリサーチまで、あらゆるニーズをカバーします。価格は入力100万トークンあたり2ドル、出力6ドルとなっており、現在の主要フラッグシップモデルの中でも最もコストパフォーマンスに優れた選択肢の一つです。
今回追加された4モデルは、単なるバージョンアップではありません。アーキテクチャレベルでの最適化が行われており、極限の応答速度を追求するもの、深い推論に特化したもの、さらには4つのAIエージェントが同時に連携することでハルシネーション(幻覚)を65%削減するものまで、多彩なラインナップとなっています。
核心的な価値: 本記事を読めば、4つのGrok 4.20 Betaモデルそれぞれのポジショニングと最適な利用シーン、APIの呼び出し方法を理解し、最適なモデル選定ができるようになります。
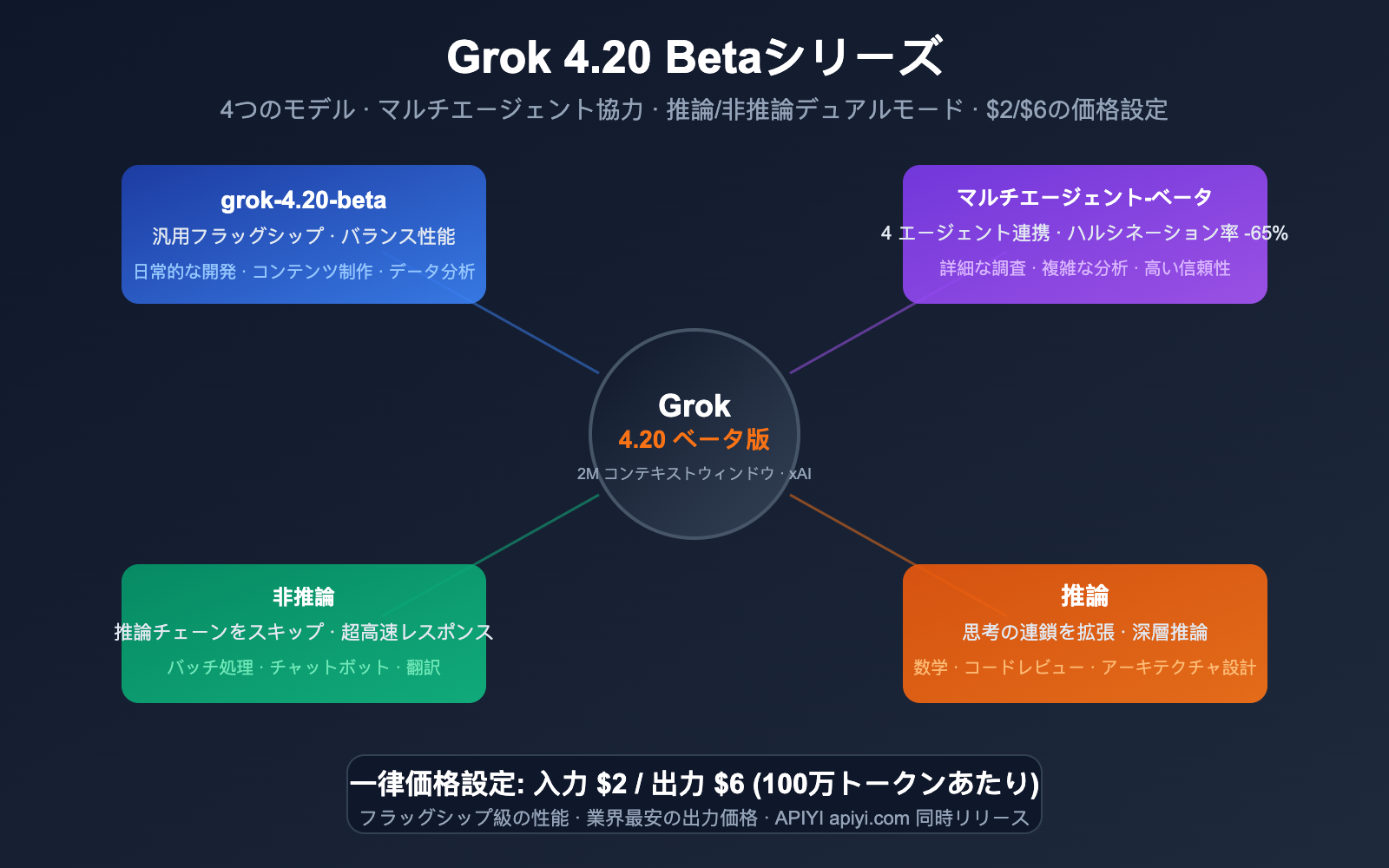
4つのモデル一覧:核心的な違いを素早くチェック
モデルマトリックス
| モデル ID | ポジショニング | 核心的な特徴 | 最適なシーン |
|---|---|---|---|
grok-4.20-beta |
汎用フラッグシップ | パフォーマンスと速度のバランス | 日常的な開発、汎用タスク |
grok-4.20-multi-agent-beta-0309 |
マルチエージェント連携 | 4つのエージェントが並行して連携 | 深度リサーチ、複雑な分析 |
grok-4.20-beta-0309-non-reasoning |
高速応答 | 推論チェーンをスキップし低遅延 | 大量バッチ処理、シンプルなQ&A |
grok-4.20-beta-0309-reasoning |
深度推論 | 思考チェーン推論を拡張 | 数学、コード分析、論理的論証 |
統一価格
| 項目 | 価格 |
|---|---|
| 入力トークン | $2.00 / 100万トークン |
| 出力トークン | $6.00 / 100万トークン |
| コンテキストウィンドウ | 200万トークン (2M) |
| バッチ処理割引 | 50% |
競合他社との価格比較:
| モデル | 入力価格 | 出力価格 | コスパ |
|---|---|---|---|
| Grok 4.20 Beta | $2.00 | $6.00 | 🟢 最適 |
| Gemini 3.1 Pro | $2.00 | $12.00 | 良好 |
| GPT-5.4 | $2.50 | $15.00 | 普通 |
| Claude Sonnet 4.6 | $3.00 | $15.00 | 普通 |
| Claude Opus 4.6 | $15.00 | $75.00 | 高め |
Grok 4.20の出力価格はClaude Sonnet 4.6の40%、Claude Opus 4.6のわずか**8%**です。コード生成や長文作成など、出力が多いタスクにおいて圧倒的なコストメリットを発揮します。
🎯 価格に関する注記: APIYI (apiyi.com) で提供されるGrok 4.20 Betaシリーズの価格はxAI公式サイトと同一(入力2ドル/出力6ドル)です。割引はプラットフォームのチャージキャンペーン等で適用されます。1つのAPIキーでGrok、Claude、GPTなど200種類以上のモデルを呼び出し可能です。
description: "Grok 4.20 シリーズの4つのモデルを徹底解説。汎用モデルからマルチエージェント、推論特化型まで、各モデルの特性と最適な活用シーンを詳しく紹介します。"
4 つのモデルの深度解析
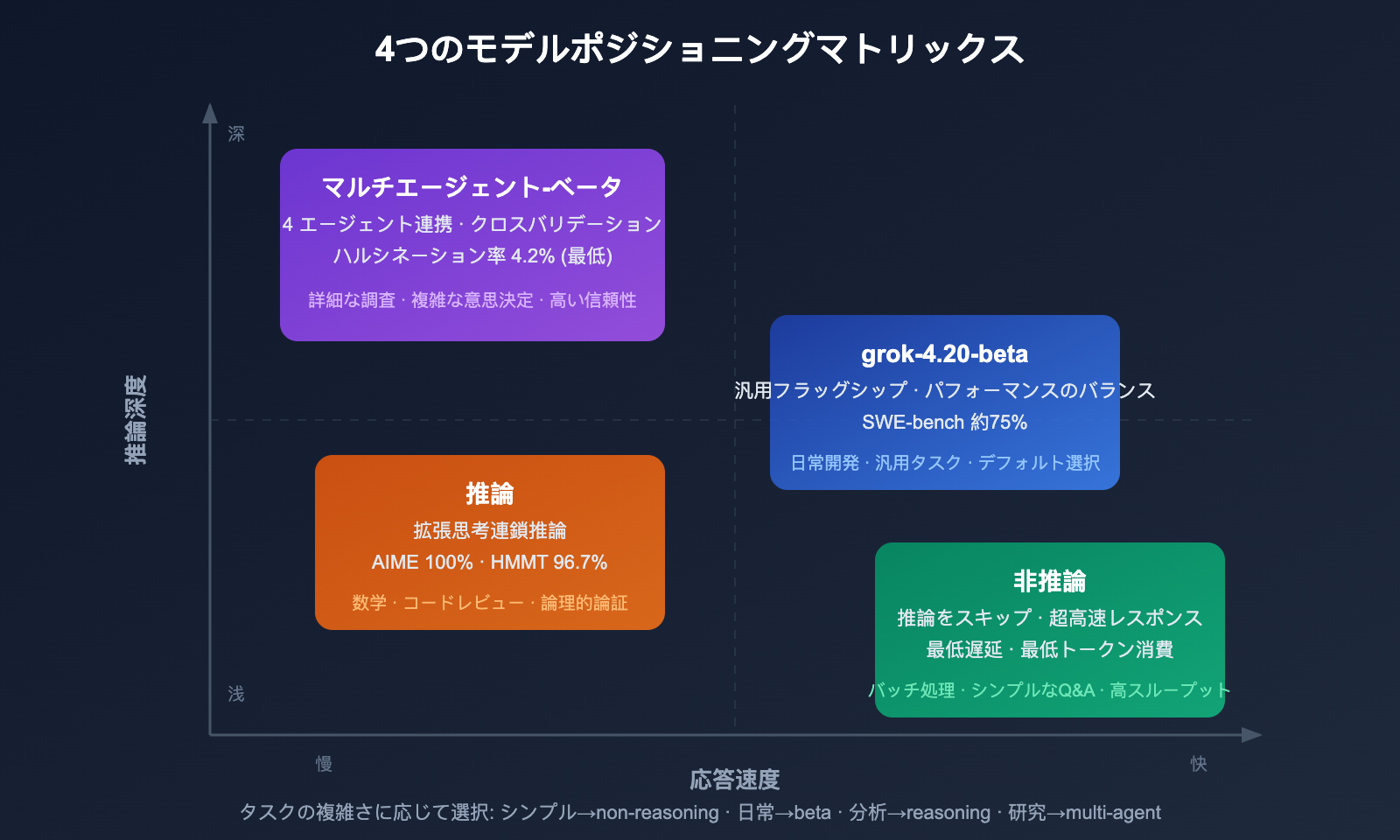
モデル1:grok-4.20-beta (汎用フラッグシップ)
Grok 4.20 シリーズの標準モデルです。パフォーマンス、速度、コストのバランスが最適化されています。
主な特徴:
- Grok 4 ファミリーの全能力を継承
- 200万トークンのコンテキストウィンドウ(欧米の最先端モデルで最大級)
- 画像入力(JPG/PNG)対応
- リアルタイムのフィードバックに基づき毎週改善
ベンチマーク:
- SWE-bench: 約75%(GPT-5の74.9%に匹敵)
- GPQA(大学院レベル): 88.4%
- Arena Elo: 約1,505-1,535
活用シーン: 日常的なプログラミング支援、コンテンツ作成、データ分析、一般的な対話
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # APIYI 統一インターフェース
)
response = client.chat.completions.create(
model="grok-4.20-beta",
messages=[
{"role": "user", "content": "PythonでLRUキャッシュを実装して"}
]
)
print(response.choices[0].message.content)
モデル2:grok-4.20-multi-agent-beta-0309 (マルチエージェント)
Grok 4.20 シリーズで最も革新的なモデルです。4つのAIエージェントが連携してリクエストを処理します。
4つのエージェントの役割:
| エージェント | 役割 | 専門分野 |
|---|---|---|
| Grok (リーダー) | コーディネーター | タスク分解、プロセス管理、出力の統合 |
| Harper | リサーチャー | リアルタイム検索、ファクトチェック(X/Twitterデータ活用) |
| Benjamin | アナリスト | 論理的推論、数学的計算、コード分析 |
| Lucas | チャレンジャー | クリエイティブ統合、反対意見の提示(他エージェントの結論を検証) |
ワークフロー:
ユーザーの質問
↓
Grok がタスクを分解 → 4つのエージェントに割り当て
↓
Harper が調査 | Benjamin が論理分析 | Lucas が反論・検証
↓
エージェント間の内部討論とクロスチェック
↓
Grok が合意形成 → 最終回答を出力
最大の強み:ハルシネーション(幻覚)率を65%低減:
| 指標 | 単一モデル | マルチエージェント | 改善率 |
|---|---|---|---|
| ハルシネーション率 | 約12% | 約4.2% | 65%低減 |
| "不明な点は回答しない"率 | — | 78% | 業界最高水準 |
Lucasの「内蔵された反対意見」が鍵です。他エージェントの結論の穴を探すこの対抗的コラボレーションにより、信頼性が飛躍的に向上しました。
活用シーン: 詳細な調査レポート、複雑な意思決定分析、高い信頼性が求められる出力
response = client.chat.completions.create(
model="grok-4.20-multi-agent-beta-0309",
messages=[
{"role": "user", "content": "2026年のAIプログラミングツール市場の競争環境とトレンドを分析して"}
]
)
モデル3:grok-4.20-beta-0309-non-reasoning (非推論)
速度とスループットを最適化したモデルです。内部的な推論チェーン(Chain-of-Thought)をスキップし、即座に回答を生成します。
主な特徴:
- 低遅延、高スループット
- 推論トークンを消費しないためコスト効率が高い
- シンプルで明確なタスクに最適
活用シーン:
- 高頻度なAPI呼び出し(バッチ処理)
- チャットボット / カスタマーサポートシステム
- コンテンツ分類、タグ抽出
- シンプルなコード補完
- 翻訳、要約
不向きなタスク: 複雑な数学的推論、多段階の論理分析、深い思考を要するアーキテクチャ設計
response = client.chat.completions.create(
model="grok-4.20-beta-0309-non-reasoning",
messages=[
{"role": "user", "content": "以下のJSONをCSV形式に変換して: ..."}
]
)
モデル4:grok-4.20-beta-0309-reasoning (推論)
非推論版とは対照的な、深層推論モデルです。拡張された思考チェーン(Extended Chain-of-Thought)を有効にし、回答前に深い内部推論を行います。
主な特徴:
- 推論トークンを拡張し、問題を深く分析
- 数学や論理的タスクで卓越した性能(AIME 2025: 100%, HMMT25: 96.7%)
- Artificial Analysis 知能指数: 48
活用シーン:
- 数学的証明と推論
- コードレビューとバグ分析
- アーキテクチャ設計のトレードオフ検討
- 複雑な論理的議論
- 学術論文の分析
response = client.chat.completions.create(
model="grok-4.20-beta-0309-reasoning",
messages=[
{"role": "user", "content": "この並行処理コードにおける競合状態とデッドロックのリスクを分析して"}
]
)
💡 モデル選定のアドバイス: 日常的なタスクには
grok-4.20-betaが最適です。高い信頼性が必要な場合はマルチエージェント版、大量処理には非推論版、複雑な分析には推論版を選びましょう。APIYI (apiyi.com) なら、1つのAPIキーでこれら4つのモデルをすべて呼び出し、必要に応じて切り替えることができます。
モデル選定デシジョンツリー
タスクタイプ別モデル選定
| タスクタイプ | 推奨モデル | 理由 |
|---|---|---|
| 日常的なプログラミング補助 | grok-4.20-beta |
性能とコストのバランスが最適 |
| 大量データ処理 | non-reasoning |
最速かつ低遅延 |
| コードレビュー/バグ分析 | reasoning |
高度な推論能力が必要 |
| 研究レポート作成 | multi-agent |
4つのエージェントによるクロス検証 |
| リアルタイムデータ分析 | multi-agent |
HarperがXのリアルタイムデータにアクセス |
| 数学/論理的推論 | reasoning |
AIMEで100%の満点を記録 |
| チャットボット | non-reasoning |
低遅延で素早いレスポンス |
| 翻訳/要約 | non-reasoning |
推論不要のシンプルなタスク |
| アーキテクチャ設計 | reasoning または multi-agent |
トレードオフの分析が必要 |
コスト感度別モデル選定
コスト重視 → non-reasoning (推論トークンなし、出力最小)
↓
日常的なコスパ重視 → grok-4.20-beta (汎用的なバランス)
↓
品質優先 → reasoning (高度な推論、出力トークン多め)
↓
最高レベルの信頼性 → multi-agent (4エージェント構成、詳細な出力)
🚀 クイックスタート: まずは
grok-4.20-betaから試してみるのがおすすめです。APIYI (apiyi.com) に登録すればすぐに APIキー を取得でき、価格は xAI 公式と同等(入力 $2 / 出力 $6)です。さらに、チャージ時のキャンペーンで割引が適用されます。
Grok 4.20 と主要モデルの比較
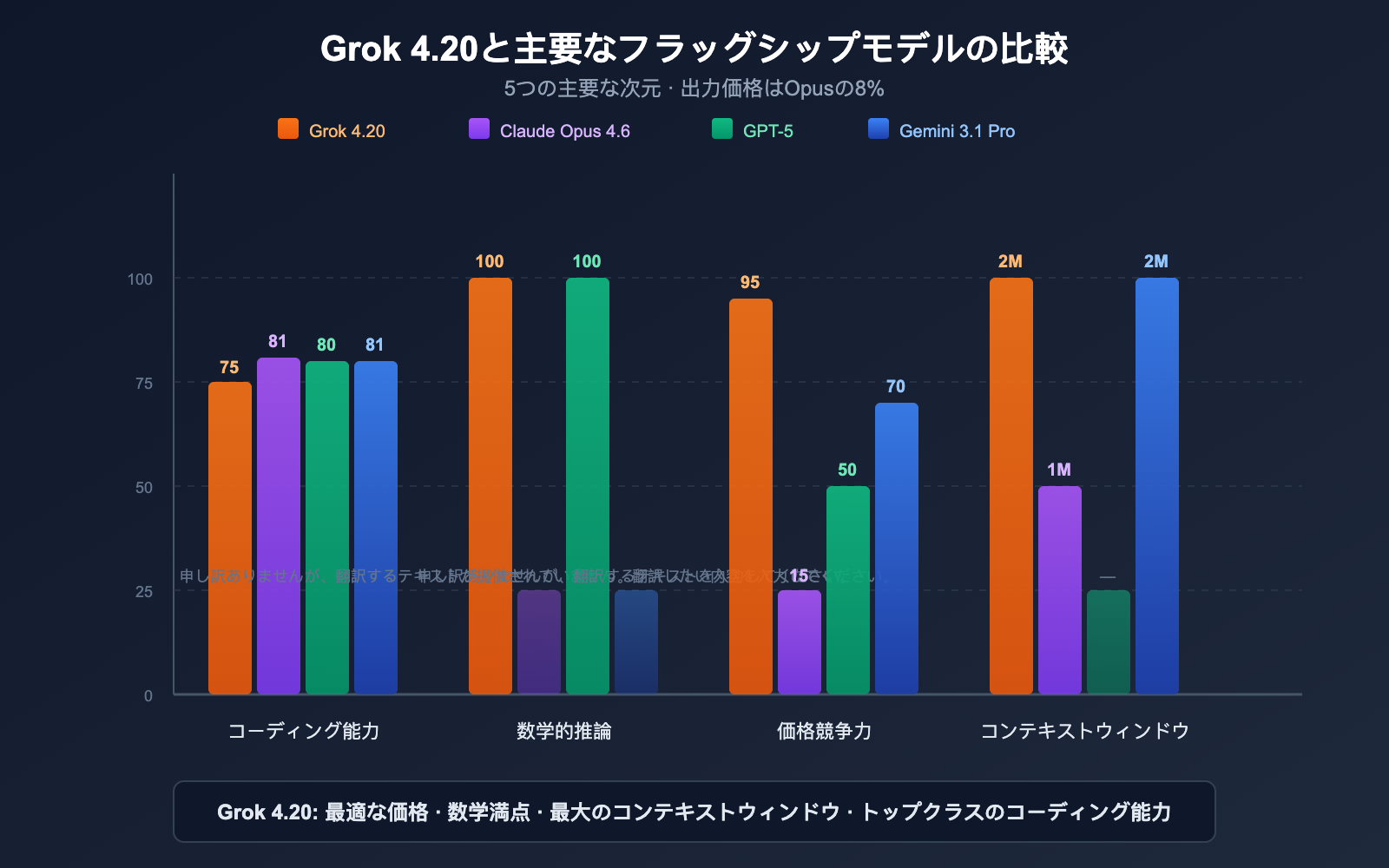
全方位比較
| 項目 | Grok 4.20 Beta | Claude Opus 4.6 | GPT-5 シリーズ | Gemini 3.1 Pro |
|---|---|---|---|---|
| SWE-bench | ~75% | 81.4% | ~80% | ~80.6% |
| 数学 (AIME) | 100% | — | 100% | — |
| GPQA | 88.4% | — | — | — |
| コンテキスト | 200万 | 100万 | モデルによる | 200万 |
| 入力価格 | $2 | $15 | $2.50 | $2 |
| 出力価格 | $6 | $75 | $15 | $12 |
| マルチエージェント | ✅ 4エージェント | ❌ | ❌ | ❌ |
| リアルタイムデータ | ✅ X/Twitter | ❌ | ✅ 検索 | ✅ 検索 |
| ハルシネーション制御 | 4.2% (最低) | 低め | 低め | 中程度 |
| 画像入力 | ✅ JPG/PNG | ✅ マルチフォーマット | ✅ マルチフォーマット | ✅ マルチフォーマット |
モデル別おすすめシーン
- Grok 4.20: 高コスパな汎用利用、詳細なリサーチ (マルチエージェント)、リアルタイムデータ分析
- Claude Opus 4.6: ソフトウェアエンジニアリング (SWE-bench最高)、超長文出力 (128K)、エンタープライズレベルの安全性
- GPT-5: 数学満点、デスクトップ自動化、最大級のユーザーエコシステム
- Gemini 3.1 Pro: Googleエコシステムとの統合、200万トークンのコンテキスト、適正なコスト
💰 コストパフォーマンス分析: Grok 4.20 の出力価格 ($6/MTok) は、Claude Opus 4.6 ($75/MTok) のわずか 8% です。長文コード生成や研究レポートなどの出力が多いタスクでは、Grok 4.20 を使うことでコストを 90% 以上削減できます。APIYI (apiyi.com) を通じれば、Grok、Claude、GPT の全シリーズを統合して利用でき、タスクに応じて柔軟に切り替え可能です。
API呼び出しの実践
基本的な呼び出し例
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # APIYI統一インターフェース
)
# 一般的なタスク → ベーシック版
response = client.chat.completions.create(
model="grok-4.20-beta",
messages=[
{"role": "system", "content": "あなたは熟練したPython開発者です。"},
{"role": "user", "content": "非同期タスクキューを実装してください"}
],
max_tokens=4096
)
print(response.choices[0].message.content)
タスクに応じた自動モデル選択
def choose_grok_model(task_type):
"""タスクタイプに基づいて最適なGrokモデルを自動選択"""
model_map = {
"quick": "grok-4.20-beta-0309-non-reasoning",
"general": "grok-4.20-beta",
"analysis": "grok-4.20-beta-0309-reasoning",
"research": "grok-4.20-multi-agent-beta-0309"
}
return model_map.get(task_type, "grok-4.20-beta")
# 使用例
model = choose_grok_model("analysis")
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": "このコードのパフォーマンスのボトルネックを分析して..."}]
)
マルチモデル比較テストコードを表示
import openai
import time
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
models = [
"grok-4.20-beta",
"grok-4.20-beta-0309-non-reasoning",
"grok-4.20-beta-0309-reasoning",
"grok-4.20-multi-agent-beta-0309"
]
prompt = "Pythonでクイックソートを実装し、時間計算量を分析してください"
for model in models:
try:
start = time.time()
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": prompt}],
max_tokens=2048
)
elapsed = time.time() - start
tokens = response.usage.total_tokens
print(f"{model}")
print(f" 所要時間: {elapsed:.1f}s | トークン数: {tokens}")
print(f" プレビュー: {response.choices[0].message.content[:80]}...")
print()
except Exception as e:
print(f"{model} | エラー: {e}")
time.sleep(1)
🎯 実践アドバイス: まずは
grok-4.20-betaでベンチマークを実行し、複雑なタスクにおいてreasoning版と出力品質にどれほどの差があるか比較することをお勧めします。APIYI (apiyi.com) を通じてこれら4つのモデルすべてを呼び出すことができ、価格設定は公式サイトと同じですが、チャージキャンペーン等で割引が適用されます。
よくある質問
Q1: 4つのモデルの価格は同じですか?
はい、4つのモデルは一律で、入力100万トークンあたり2ドル、出力100万トークンあたり6ドルです。ただし、実際のコストはモデルによって異なります。推論モデルはより多くの推論トークン(出力としてカウント)を生成し、マルチエージェント版は4つのエージェントが連携するため、より多くのトークンを消費する可能性があります。非推論版は推論チェーンをスキップし、出力トークンが最小限になるため、最もコスト効率が良いです。APIYI (apiyi.com) を通じた呼び出し価格はxAI公式サイトと同じで、割引はプラットフォームのチャージキャンペーンで提供されます。
Q2: マルチエージェント版と推論版の違いは何ですか?
推論版は単一のエージェントが深く思考するため、明確な答えがある分析タスク(数学、コードレビュー)に適しています。マルチエージェント版は4つのエージェントが協力して議論するため、多角的な分析が必要なオープンな問題(市場調査、意思決定分析)に適しています。マルチエージェント版の最大の利点は、相互検証によってハルシネーション率を低減(12%から4.2%へ)できることです。
Q3: Grok 4.20 は Claude の代わりにコードレビューを行えますか?
一部のシナリオでは可能です。Grok 4.20 推論版は SWE-bench で約75%を達成しており、Claude Opus 4.6 の 81.4% には及びませんが、価格はわずか8%です。セキュリティが重要でない日常的なコードレビューであれば、Grok 4.20 推論版は非常にコストパフォーマンスの高い選択肢です。ただし、セキュリティ監査や大規模なアーキテクチャレビューには、依然として Claude Opus 4.6 の方が信頼性が高いです。APIYI (apiyi.com) を利用すれば、両方のモデルを統合し、タスクに応じて柔軟に切り替えることができます。
Q4: 200万トークンのコンテキストウィンドウにはどのような実用性がありますか?
200万トークンは、約1500ページの技術書に相当します。実用的な用途としては、(1) 中・大規模なコードベース全体を一度に読み込ませて分析する、(2) 超長文のドキュメント(法的契約書、学術論文集)を処理する、(3) 長時間の対話履歴を保持する、などが挙げられます。これは、現在の主要なAIモデルの中でも最大級のコンテキストウィンドウです。
Q5: APIYIプラットフォームでこれらのモデルを呼び出すにはどうすればよいですか?
APIYI (apiyi.com) に登録してAPIキーを取得した後、OpenAI互換形式で呼び出すだけです。base_url を https://api.apiyi.com/v1 に設定し、model に対応するモデルID(例: grok-4.20-beta)を指定してください。コード例は上記を参照してください。4つのモデルの価格は公式サイトと同じで、割引はチャージキャンペーンを通じて提供されます。
まとめ:4つのモデルの最適活用戦略
Grok 4.20 Betaシリーズは、さまざまなシナリオに合わせて最適なモデルを選択できるよう設計されています。核心となる戦略は、タスクの複雑さに応じてモデルを使い分けることです。
| 複雑度 | 推奨モデル | コスト |
|---|---|---|
| 🟢 単純/高頻度 | non-reasoning |
最低 |
| 🟡 日常汎用 | grok-4.20-beta |
中程度 |
| 🟠 深層分析 | reasoning |
高め |
| 🔴 最高信頼度 | multi-agent |
最高 |
$2/$6 という価格設定により、Grok 4.20は現在市場で出力コストが最も低いフラッグシップモデルとなっています。200万トークンのコンテキストウィンドウとマルチエージェントシステムを組み合わせることで、リサーチ、分析、高スループットが求められるシナリオにおいて非常に高い競争力を発揮します。
Grok 4.20 Beta全シリーズへのアクセスには、APIYI (apiyi.com) の一括導入がおすすめです。公式サイトと同等の価格設定であり、チャージキャンペーンを通じてさらにお得に利用可能です。1つのAPIキーでGrok、Claude、GPTなど200種類以上のモデルを呼び出すことができます。
参考資料
-
xAI 公式ドキュメント: Grokモデルおよび価格設定について
- リンク:
docs.x.ai/developers/models
- リンク:
-
Artificial Analysis: Grok 4.20 Beta ベンチマーク評価
- リンク:
artificialanalysis.ai/models/grok-4-20
- リンク:
-
xAI マルチエージェントドキュメント: マルチエージェント機能の詳細
- リンク:
docs.x.ai/developers/model-capabilities/text/multi-agent
- リンク:
-
OpenRouter: Grok 4.20 Beta モデルページ
- リンク:
openrouter.ai
- リンク:
著者: APIYI Team | 最新のAIモデルをいち早く提供しています。ぜひAPIYI (apiyi.com) にアクセスして、Grok 4.20 Beta全シリーズを体験してください。