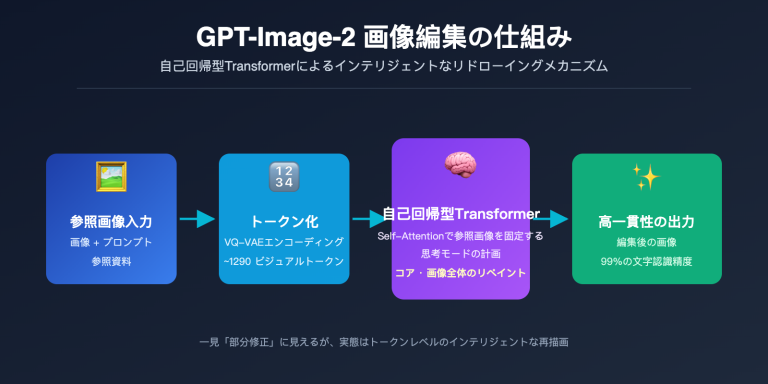
小紅書(RED)の運営において、最も頭を悩ませるのは投稿文の作成ではなく、実は「画像作成」です。表紙画像には、タイトル、サブタイトル、セールスポイント、ブランドロゴ、装飾要素など、インフォグラフィック並みの情報密度が求められます。Canvaでのコラージュ、Figmaでのレイアウト、Photoshopでのレタッチ……これら一連の作業を行うと、あっという間に2時間が過ぎてしまいます。
OpenAIが2026年4月にリリースした gpt-image-2 は、この状況を一変させました。画像内の文字レンダリング精度を95%以上に引き上げただけでなく、業界初となる「Web検索+推論による画像生成」というエージェント能力を搭載しました。「最新のiPhone 17のカラーバリエーション比較画像を作って」と指示するだけで、公式情報を検索し、正確なモデル名、カラー、スペックを盛り込んだ高密度なインフォグラフィックを自動生成してくれます。
本記事では、gpt-image-2 を活用した小紅書コンテンツ制作の完全な方法論を解説します。コア機能の分析から5ステップの実践フロー、プロンプトテンプレート、そしてFAQまでを網羅し、画像制作時間を2時間から5分へと劇的に短縮する方法を伝授します。
なぜ gpt-image-2 は小紅書のコンテンツ制作で突出しているのか
gpt-image-2 以前、小紅書のクリエイターがAI画像生成を利用する際には、**「文字レンダリングの不正確さ」「情報密度の不足」「知識の鮮度の欠如」**という3つの大きな壁がありました。バズる表紙には通常50〜100文字程度のテキストが必要ですが、初期のモデル(gpt-image-1やMidjourney v6など)では、誤字、脱字、文字化けが頻発し、そのまま使用することは困難でした。
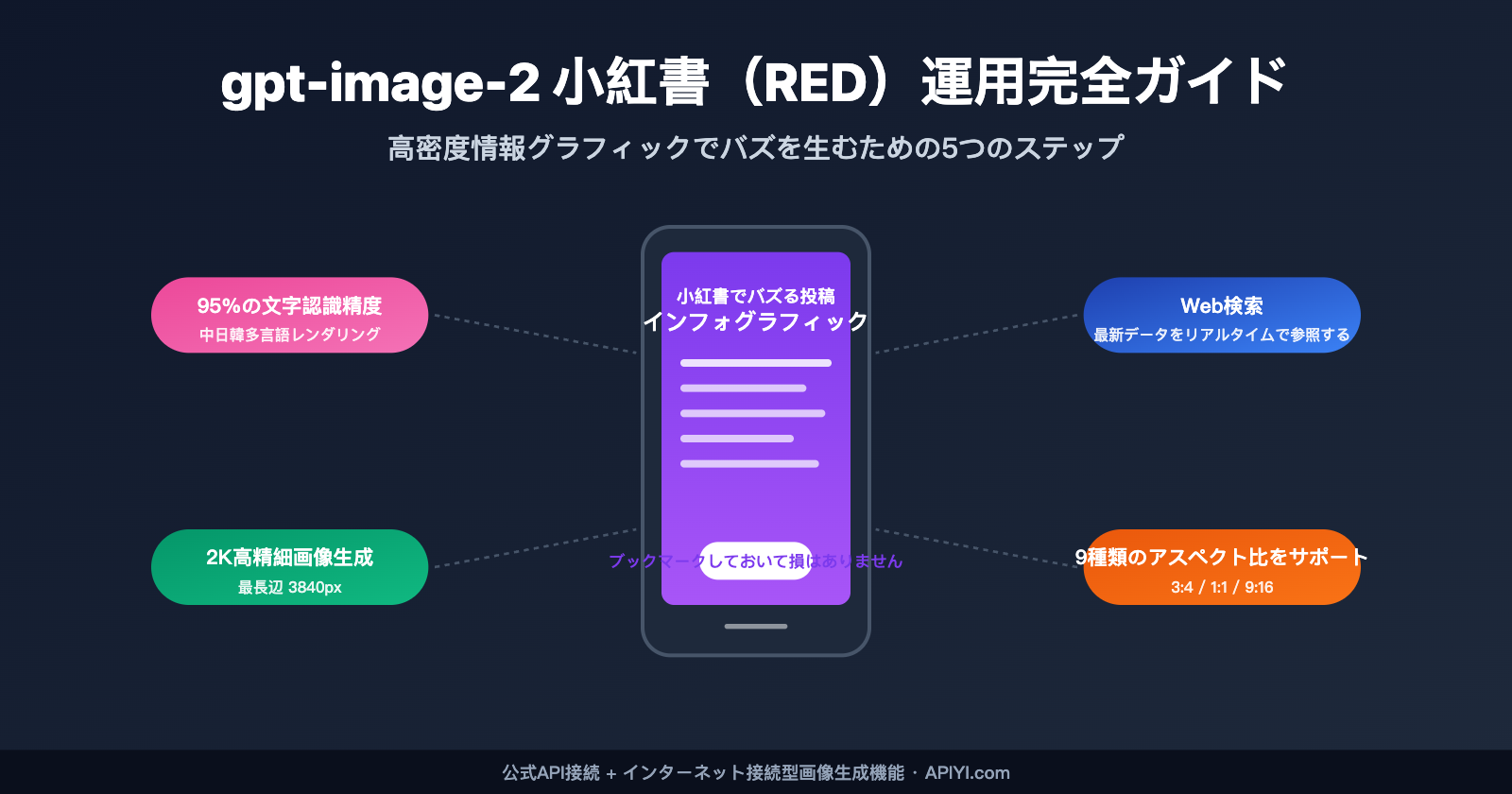
gpt-image-2 は、3つの技術的ブレイクスルーによってこの現状を完全に塗り替えました。第一に、文字レンダリングエンジンの全面的なアップグレードです。OpenAIの公式テストによると、日本語、中国語、韓国語、ヒンディー語、ベンガル語などの非ラテン文字における高精度なレンダリング成功率は95%を超えており、小さなフォントや曲面、密集したレイアウトでも安定した出力を実現しています。
第二に、Agentic Reasoning(エージェント推論)アーキテクチャです。gpt-image-2 は、業界初となる「思考→検索→生成→検証」という完全な推論ループを備えた画像モデルであり、生成前に構成の計画、参考資料の検索、品質の評価を自律的に行います。
第三に、Web検索知識の内蔵です。最新製品、ブランドロゴ、人物像、トレンドイベントなどに関する画像を生成する際、学習データ(2025年12月時点)に頼るのではなく、リアルタイムでインターネットを検索して情報を取得します。
💡 プラットフォーム推奨: gpt-image-2 のWeb検索・画像生成能力を直接体験したい場合は、APIYI (apiyi.com) が提供する gpt-image-2-all モデルをご利用ください。これは公式ChatGPTのWeb版からリバースエンジニアリングされたバージョンで、デフォルトでWeb検索が有効になっており、追加のパラメータ設定なしで「知識の鮮度」が求められる小紅書のコンテンツ制作に最適です。
gpt-image-2 の小紅書(RED)における核心能力:3つの側面から徹底解説
gpt-image-2 がなぜ小紅書(RED)のコンテンツ制作に最適なのか。その理由は、モデルの能力と小紅書のコンテンツ形式の相性の良さにあります。以下の表では、小紅書の主要な利用シーンにおいて、gpt-image-2 が前世代の gpt-image-1 と比較してどのように進化したかをまとめました。
| 能力項目 | gpt-image-1 | gpt-image-2 | 小紅書での活用価値 |
|---|---|---|---|
| 中国語のテキスト描画 | 60-70%(誤字や欠けが多い) | 95%+(正確、曲面も安定) | カバー画像や図解にそのまま利用可能 |
| 一括出力枚数 | 1 枚 | 1-10 枚から選択可能 | 9枚のカルーセル投稿を一括生成 |
| 最大解像度 | 1024×1024 | 2K(長辺 3840px) | 3:4 の高画質カバー画像に対応 |
| アスペクト比 | 3 種類 | 9 種類(3:4 を含む) | 小紅書の推奨比率に完全適合 |
| 検索・最新知識 | なし | Web検索機能内蔵 | 最新の商品情報やトレンドを反映 |
| 推論生成 | なし | エージェント型推論 | 複雑な図解のレイアウトを自動計画 |
gpt-image-2 の強み 1:高密度な情報図の生成
小紅書の「図解」「まとめ」「解説画像」はエンゲージメント率が高いコンテンツです。これらは1枚の画像に80〜150文字のテキストを盛り込み、明確な階層、色使い、アイコンが必要です。gpt-image-2 は以下の3点でこのニーズに応えます。
- フォントサイズの階層化:「メインタイトル60pt+サブタイトル32pt+本文18pt」といった指示を理解し、適切なバランスで出力します。
- レイアウトの余白制御:エージェント型の推論により、描画前に「仮想レイアウト」を作成し、文字の重なりや端切れを防ぎます。
- アイコンとテキストの混排:指定した位置に適切なアイコン(✓、★、→、数字バッジなど)を挿入し、テキストと綺麗に整列させます。
gpt-image-2 の強み 2:Web検索による情報の正確性
これは gpt-image-2 の最も過小評価されている能力です。従来の AI は学習データに基づいた知識しか持ちません。そのため、「最新の iPhone 17 のカラー比較」「2026年のコーヒーブランドランキング」といった内容を生成すると、高確率で誤った情報を捏造(ハルシネーション)してしまいます。
gpt-image-2 は、内部の「思考」プロセスにおいて外部情報の必要性を判断します。必要な場合は自動で Web 検索を行い、検索結果の正確なデータ(製品スペック、ロゴの形状、公式色など)を生成プロセスに反映します。これにより、インフルエンサーは AI による「情報の捏造」を心配することなく、商品比較やおすすめ情報の投稿を作成できます。
🎯 API 接続のアドバイス: gpt-image-2 の検索機能を利用するには、フル API 能力をサポートする API 中継サービスが必要です。APIYI(api.apiyi.com)経由で
gpt-image-2-allモデルに接続することをお勧めします。このモデルは公式のリバースチャネルを経由しており、デフォルトでWeb検索能力を備えています。また、直結よりもコスト効率が高く、大量の画像制作を行うコンテンツクリエイターに最適です。
gpt-image-2 の強み 3:多様なアスペクト比と複数枚出力
小紅書のカバー画像の標準比率は 3:4(縦型)であり、正方形(1:1)は図解カードに、9:16 はショート動画のカバーに適しています。gpt-image-2 はこれら3種類を含む計9種類(1:1、2:3、3:2、4:3、4:5、16:9、21:9など)をネイティブサポートしており、後からのトリミングは不要です。
さらに重要なのは、一度のリクエストで1〜10枚の画像を生成できる点です。小紅書の投稿は6〜9枚の画像構成がアルゴリズム的に最も評価が高くなります。投稿者はテーマを指定するだけで、デザインの一貫性を保ったまま一括でカルーセル画像を作成できます。
gpt-image-2 小紅書コンテンツ適応マトリックス
小紅書のコンテンツタイプによって、画像に求められる要件は異なります。以下の表で、各コンテンツ形式における gpt-image-2 の適合度と推奨パラメータを素早く判断できます。
| コンテンツタイプ | 推奨比率 | 枚数 | 文字密度 | gpt-image-2 適合度 | 推奨 quality |
|---|---|---|---|---|---|
| 知識解説図 | 3:4 | 6-9 枚 | 高(80-150 字/枚) | ⭐⭐⭐⭐⭐ | high |
| 製品レビューカード | 3:4 | 6-9 枚 | 中(40-80 字/枚) | ⭐⭐⭐⭐⭐ | high |
| チュートリアル手順図 | 3:4 | 4-9 枚 | 中(50-100 字/枚) | ⭐⭐⭐⭐⭐ | medium-high |
| データ可視化 | 3:4 / 1:1 | 1-3 枚 | 高(100+ 字/枚) | ⭐⭐⭐⭐⭐ | high |
| グルメ/ファッション紹介 | 3:4 | 6-9 枚 | 低(タグ中心) | ⭐⭐⭐⭐ | medium |
| Vlog 表紙 | 9:16 | 1 枚 | 中(タイトル中心) | ⭐⭐⭐⭐ | high |
| スタンプ/ネタ画像 | 1:1 | 1 枚 | 低 | ⭐⭐⭐ | low-medium |
適合度からわかるように、gpt-image-2 は文字密度が中〜高の情報型コンテンツを得意としており、これこそが小紅書のアルゴリズムで最も重視される「高保存率」コンテンツです。小紅書が公開している CES アルゴリズムの重み付けによると、保存アクションは 1 ポイントで「いいね」と同等に重要であり、コメントとシェアはそれぞれ 4 ポイントの価値があります。インフォグラフィック、チュートリアル、レビュー系コンテンツはその「実用価値」から保存率が他のタイプより著しく高く、アルゴリズムによる配信でより多くの自然流入を獲得できます。
gpt-image-2 小紅書画像コンテンツ制作 5 ステップ実践フロー
それでは実践編です。gpt-image-2 を使った小紅書画像制作の完全フローは 5 つのステップに分かれており、各ステップで再利用可能なテクニックがあります。
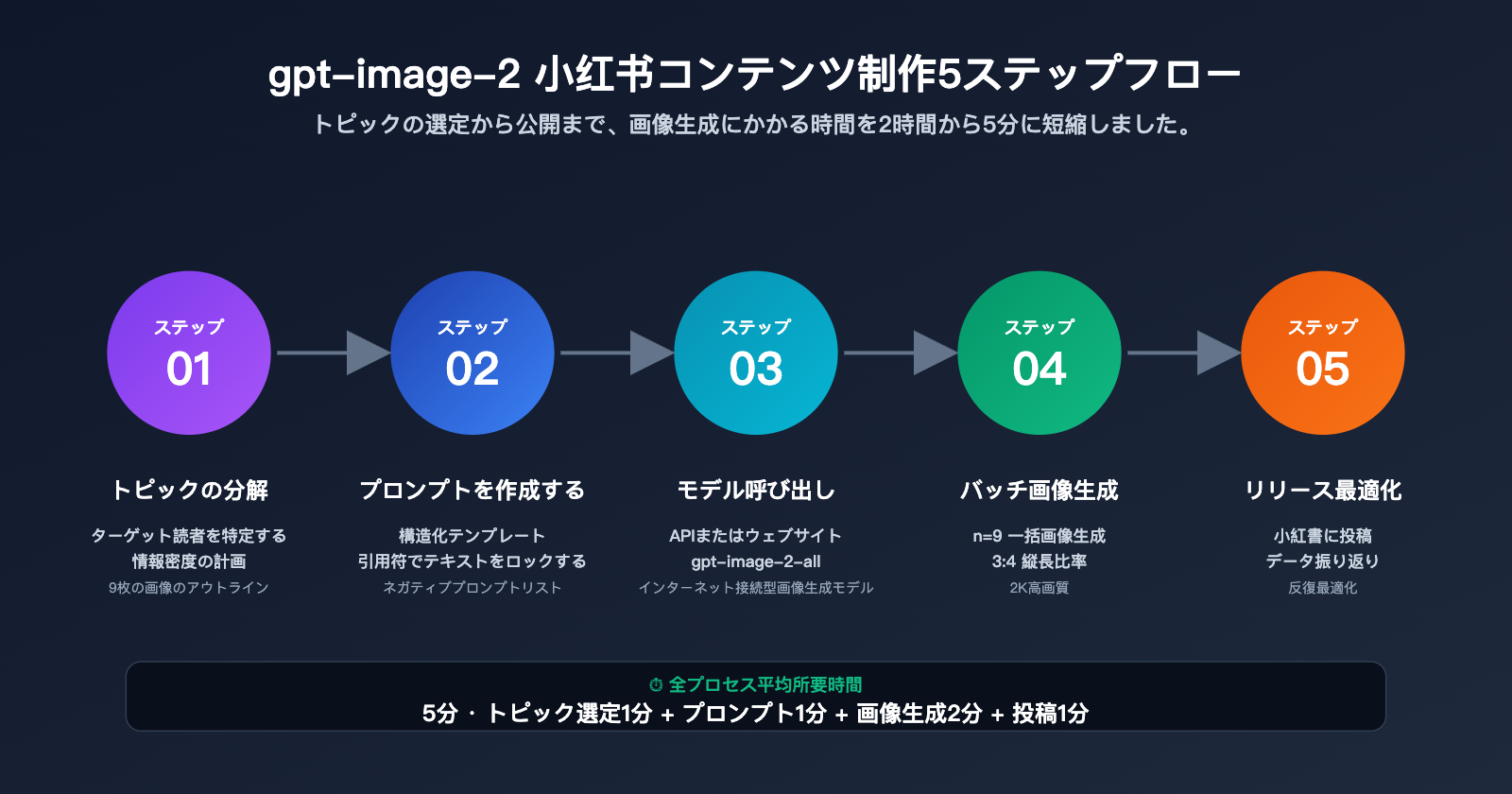
Step 1: トピックの分解と情報密度の計画
gpt-image-2 を開く前に、まずは 5 分かけてトピックを分解しましょう。優れた小紅書のインフォグラフィックノートは、以下の 3 つの問いに答える必要があります。
- ターゲット読者は誰か (初心者 / 中級者 / 意思決定者)
- コア情報はいくつあるか (3 つ / 5 つ / 7 つ)
- 1 枚の画像にどれだけの情報を載せるか (1 枚 1 視点 / 1 枚で比較)
例:「2026 年 AI 画像生成ツール比較」というノートを作る場合、9 枚に分解できます:表紙 1 枚 + 概要表 1 枚 + ツール紹介 5 枚(各ツール 1 枚)+ 推奨結論 1 枚 + アクション誘導 1 枚。各画像のコア情報は 80 字以内に抑えます。
Step 2: 構造化された gpt-image-2 小紅書用プロンプトの作成
gpt-image-2 のプロンプト作成には、公式推奨の構造があります:背景/シーン → 主体 → 重要な詳細 → 文字内容 → スタイル制約。小紅書用の画像を安定して生成するには、4 つの核心ルールを守りましょう:
- 表示させたい中国語のテキストは、必ず中国語の二重引用符「」または英語の引用符 "" で囲むこと。これによりモデルが正確にレンダリングします。
- プロンプト内で文字サイズの階層を明示する(例:「メインタイトル 64pt 太字、サブタイトル 28pt」)
- "high-fidelity"(高忠実度)、"ultra-detailed"(超詳細)、"crisp typography"(鮮明なタイポグラフィ) などのキーワードを使用して詳細度を高める
- 否定制約をリストアップする(例:「no watermark, no extra text, no duplicate words」)ことで、余計な描画を防ぐ
Step 3: gpt-image-2 API を呼び出して画像を生成
基本的な API 呼び出しのスキルがあれば、OpenAI 標準インターフェースを使って直接 gpt-image-2 を呼び出せます。以下は 3:4 の小紅書表紙を生成する最小限のコード例です:
from openai import OpenAI
client = OpenAI(
api_key="your_apiyi_key",
base_url="https://api.apiyi.com/v1"
)
response = client.images.generate(
model="gpt-image-2-all",
prompt='小紅書スタイルのインフォグラフィック表紙,3:4 縦長,メインタイトル 「2026 AI 画像生成ツール TOP 5」 64pt 白色太字,サブタイトル 「ブロガー必見,保存推奨」 28pt 薄灰色,中央に 5 つのツールロゴのサムネイルを表示,ピンクから紫へのグラデーション背景,high-fidelity typography, crisp text, no watermark',
size="1024x1536",
quality="high",
n=1
)
print(response.data[0].url)
📌 base_url 設定の説明: 上記のコードは APIYI の
api.apiyi.com/v1を接続エンドポイントとして使用しています。モデル名gpt-image-2-allは公式の逆コンパイル版で、デフォルトでウェブ検索機能が有効になっています。一般ユーザーはgpt-image-2標準モデル(検索機能なし)も使用でき、より安価です。
Step 4: 9 枚の画像をバッチ生成してカルーセル投稿
小紅書の画像ノートは 6-9 枚が最適ですが、手動で 1 枚ずつプロンプトを書くのは非効率です。gpt-image-2 の n パラメータは 1-10 をサポートしているため、一度に 9 枚の画像を生成できます。
ここで重要なテクニックがあります:モデルに無関係な 9 枚をバラバラに生成させるのではなく、プロンプトで「シリーズ画像」を生成するように誘導することです。例:
response = client.images.generate(
model="gpt-image-2-all",
prompt='''一連の 9 枚の小紅書向け解説カルーセル画像を生成してください,3:4 縦長,
統一された濃い紫の背景 + 白文字,テーマ「AI 画像生成初心者が学ぶべき 5 つのプロンプト公式」,
画像 1: 表紙ページ,タイトル 「AI 画像生成必修」 サブタイトル 「5 つのプロンプト公式」,
画像 2-6: 各画像で 1 つの公式を紹介,上部に番号 01-05,中央に公式名,下部に 30 字の解説,
画像 7: 公式比較表,
画像 8: 実践事例の展示,
画像 9: フォロー誘導ページ,テキスト 「いいねと保存をお願いします」 ''',
size="1024x1536",
quality="high",
n=9
)
Step 5: コードが書けない場合?Web ツール imagen.apiyi.com を活用
純粋なコンテンツクリエイターで、Python や API 呼び出しの経験がない場合は、コードのステップを完全にスキップできます。imagen.apiyi.com という Web 版画像生成ツールを推奨します。これは gpt-image-2、Nano Banana、Seedream など複数の主要画像モデルを統合しており、フォーム入力形式で簡単に操作できます。比率選択、枚数制御、一括ダウンロードに対応しており、5 分で使いこなせます。
🎨 ツールの選択アドバイス: コンテンツ制作に専念したい場合は、直接 imagen.apiyi.com Web ツールを使用することをお勧めします。コードを書く必要も API 設定も不要で、モデル(gpt-image-2 または gpt-image-2-all を推奨)と比率(3:4)を選ぶだけで生成可能です。バッチ処理や自動化が必要なスタジオの場合は、APIYI (apiyi.com) を通じて API を呼び出し、独自の SaaS ツールや飛書(Lark)テーブルに連携させることを推奨します。
gpt-image-2 小紅書(RedNote)でバズるプロンプトテンプレート集
実証済みの小紅書でよく使われるコンテンツタイプを網羅した、6つのプロンプトテンプレートをご紹介します。すべてのテンプレートはテキストレンダリング命令を最適化済みですので、そのままコピーし【】の中身をあなたのテーマに合わせて書き換えてご使用ください。
テンプレート 1: 知識解説カード(情報密度重視)
小紅書スタイルの知識解説カード、3:4の縦長サイズ、
上部タイトルバー:濃い紫の背景、白色の太字中国語タイトル「【あなたのメインタイトル、15文字以内】」フォントサイズ56pt、
サブタイトル「【一言での価値説明、20文字以内】」フォントサイズ24pt、薄紫、
中部コンテンツエリア:5つの番号付き要点、各要点には数字のバッジ+タイトル+30文字の解説、
下部:ピンク色のCTAボタン「保存して見返そう」、
配色:メインカラーは濃い紫 #2D1B69、アクセントカラーは鮮やかなピンク #FF6B9D、
high-fidelity Chinese typography, crisp text rendering, no watermark, no duplicate text
テンプレート 2: 製品比較レビューカード
小紅書スタイルの製品比較レビューカード、3:4の縦長サイズ、白色背景、
上部:左右に2つの製品画像+製品名「【製品A】」vs「【製品B】」、
中部:5行の比較表、各行には比較項目名+Aの評価+Bの評価、
評価には5つ星アイコン(★)を使用、
下部:おすすめの結論「総合おすすめ:【製品名】」、
フォントは鮮明でシャープ、表の線は1pxの薄いグレー、メインタイトルは太字48pt、
high-fidelity, ultra-detailed, no extra elements
テンプレート 3: チュートリアル手順図
小紅書スタイルのチュートリアル手順図、3:4の縦長サイズ、ベージュの温かみのある背景、
上部メインタイトル「【テーマ】3分で完了」黒色の太字56pt、
中部:3つのステップブロックを垂直に配置、
各ブロック:左側に大きなステップ数字(01/02/03)、右側に手順タイトル+25文字の説明、
下部:成果物の画像+テキスト「完成!」、
手書きイラスト風のアイコン、アクセントカラーは温かみのあるオレンジイエロー、
crisp typography, clear hierarchy, no watermark
テンプレート 4: データ可視化図
小紅書スタイルのデータカード、3:4の縦長サイズ、濃い青のグラデーション背景、
上部タイトル「【データテーマ】2026年最新データ」白色52pt、
中部:画面の高さの40%を占める核心となる大きな数字「【主要な数字】」、
数字の下:データソースの注釈12pt、薄い青色、
中部から下部:3行の補足データ、各行にはアイコン+データ+簡潔な説明、
下部:薄い色のCTA「同僚にシェアしよう」、
配色:濃い青 #0F172A から #1E40AF へのグラデーション、白色の高コントラストテキスト、
high-fidelity typography, crisp small text, no extra words
テンプレート 5: お役立ちリスト図
小紅書のお役立ちリストの表紙、3:4の縦長サイズ、
上部:蛍光グリーンの横帯、黒色の太字「【数字】個の【テーマ】」60pt、
サブタイトル「ブロガーの秘蔵リスト、見たらそのまま真似できる」24pt、
中部:【数字】個のリスト項目、各項目には✓アイコン+項目名、
レイアウトはコンパクトながら適切な余白を確保、フォントサイズの緩急を明確に、
下部:ピンク色の枠線+テキスト「完全リストは次へ」、
スタイル:シンプルでモダン、Notion風のレイアウト、
high-fidelity Chinese text, crisp icons, no decorative noise
テンプレート 6: ネット接続による画像生成(gpt-image-2-all 専用)
小紅書の新製品紹介カード、3:4の縦長サイズ、
テーマ:【最新の製品名、例:iPhone 17 Pro Max】の紹介、
ネット検索で当該製品の最新の公式カラー、主要スペック、発売日を調べてください。
上部:製品のリアルな外観レンダリング画像、
中部:製品名+3行の主な売り点(カラー/容量/価格)、
下部:紹介文「買う価値ある?見てから決めて」、
スタイル:Appleスタイル、シンプル、白色背景、
high-fidelity, accurate product details from web search, no fictional specs
💡 テンプレート活用のコツ: 上記のテンプレートはすべて中国語のテキストレンダリング用に最適化されています。初めて使用する場合は、まず
quality="medium"で構成を確認し、レイアウトが整っていることを確認してからquality="high"に切り替えて最終画像を出力すると、コストを30〜40%節約できます。大量生産が必要な場合は、APIYI(apiyi.com)経由で接続すると、直結よりも安定性と速度が向上します。
gpt-image-2 と従来の作画ツールとの能力比較
多くのクリエイターから「Canva、Figma、Photoshopがあるのに、なぜ gpt-image-2 に乗り換えるのか?」という質問をいただきます。以下の表は、小紅書運用の核心的なシーンにおいて、4つのツールの効率を比較したものです。
| 比較項目 | gpt-image-2 | Canva | Figma | Photoshop |
|---|---|---|---|---|
| 単体画像制作時間 | 30秒-1分 | 15-30分 | 30-60分 | 1-2時間 |
| 9枚スライド作成 | 5分 (n=9) | 3-4時間 | 4-6時間 | 8時間以上 |
| 中国語レンダリング | 95%+ 正確 | 100% (手入力) | 100% (手入力) | 100% (手入力) |
| 創造性・発散力 | 高 (AI生成) | 中 (テンプレート) | 低 (白紙から) | 低 (白紙から) |
| ネット検索能力 | ✅ 内蔵 | ❌ | ❌ | ❌ |
| 学習コスト | 低 (中国語で指示) | 低 | 中 | 高 |
| 月額コスト | $5-30 (従量課金) | $12.99 定額 | $15 定額 | $22.99 定額 |
| 適したシーン | 大量作成、インフォグラフィックス | テンプレート利用 | チーム共同作業 | 商業用精密レタッチ |
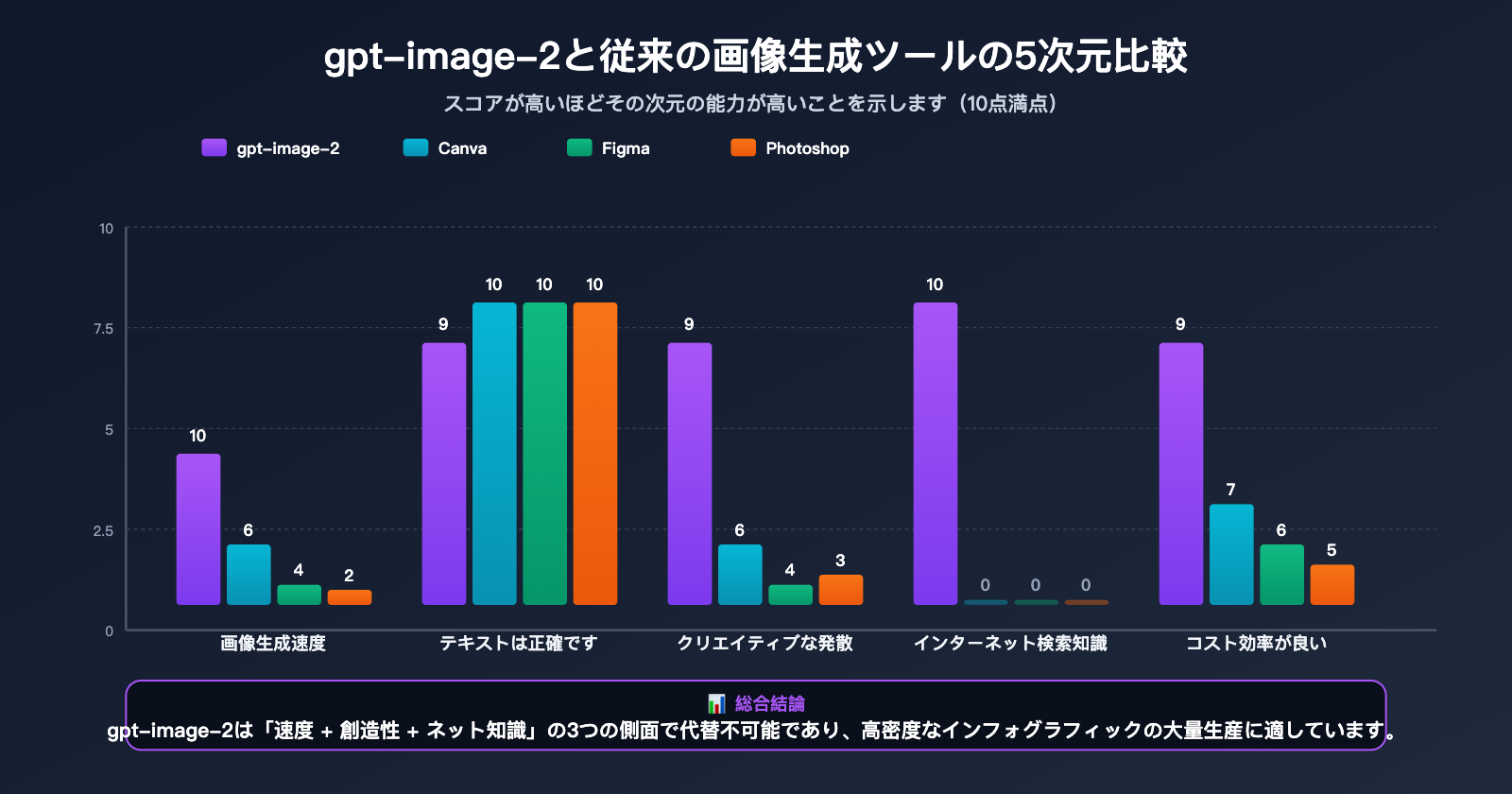
比較表からわかるように、gpt-image-2 は Canva や Figma を完全に置き換えるものではありません。「クリエイティブの拡散+大量画像作成+ネット知識」という3つの要素を統合した、全く新しいシーンをカバーするツールです。もしあなたの小紅書アカウントで毎週安定して3〜5件の図解ノートを投稿する必要があるなら、gpt-image-2 を活用することで、画像制作の時間を8〜10時間から1時間以内に短縮することが可能です。
gpt-image-2 小紅書(RED)運用に関するよくある質問(FAQ)
Q1: gpt-image-2 で生成した小紅書用の画像、中国語の表示は本当に大丈夫ですか?
実測での正確率は 95% 以上です。OpenAI は公式ブログで gpt-image-2 を「ポリグロット(多言語)」モデルと位置づけており、中国語、日本語、韓国語などの非ラテン文字圏の言語において大幅な性能向上が見られます。ただし、2点注意が必要です。第一に、プロンプト内の中国語テキストは引用符で囲んでください(例:「ここの文字」)。そうしないと、モデルが「意味を解釈」してしまい、正確な「コピー」にならない場合があります。第二に、難読漢字や繁体字はまだ誤字が発生する可能性があるため、提出前に重要な箇所は必ずチェックすることをおすすめします。
Q2: gpt-image-2 で小紅書用の 3:4 画像を 1 枚生成するのにいくらかかりますか?
公式価格に基づくと、1024×1536(3:4)の高品質な画像生成で 1 枚あたり約 $0.20〜$0.25 です。9 枚のカルーセル投稿を作成する場合、約 $1.8〜$2.3(日本円で約 270〜350 円前後)となります。APIYI(apiyi.com)の API 中継サービスを経由して利用すれば、コストをさらに抑えることができ、日本円での決済や請求書対応も可能なため、国内のクリエイターが大量生成を行う際に最適です。
Q3: gpt-image-2 の「ネット検索機能(联网生图)」はどうやって使いますか?
ネット検索機能は ChatGPT のウェブ版ではデフォルトで有効(Thinking モード)になっていますが、API を利用する場合は、ネット検索に対応したモデルバリアントを使用する必要があります。APIYI(apiyi.com)を通じて gpt-image-2-all モデルを呼び出す場合、ネット検索はデフォルトで有効です。プロンプト内で必要なリアルタイム情報(例:「最新のリリース情報」「公式のカラー設定」「実際のスペック」など)を指定するだけで、モデルが自動的にウェブ検索を行い、その結果を画像生成に反映させます。
Q4: プログラミングができませんが、gpt-image-2 で小紅書を運用できますか?
全く問題ありません。imagen.apiyi.com というウェブツールをおすすめします。API の設定や Python 環境は不要で、ウェブ上のフォームからモデル(gpt-image-2 または gpt-image-2-all)を選択し、プロンプトを入力し、比率(3:4)と枚数を選んで「生成」ボタンを押すだけです。中国語インターフェース、一括ダウンロード、履歴管理に対応しており、コンテンツ制作に集中したい方に最適です。
Q5: gpt-image-2 で生成した小紅書の画像は、「AI 生成」として制限(シャドウバン)されますか?
現時点で小紅書の公式から「AI 生成画像」に対する制限ルールは公開されていません。アルゴリズムが評価するのは、インタラクション率(いいね、保存、コメント、シェア、フォロー)です。画像の情報密度が高く、読者にとって価値があるものであれば、自然とポジティブな反応が得られます。透明性を高めるために、投稿文の中に画像ソース(「AI 補助制作」など)を明記しておくことをおすすめします。
Q6: gpt-image-2 で一度に生成できる画像は何枚までですか?
API 経由では 1 回のリクエストで最大 10 枚(n=10)、ChatGPT のウェブ版では最大 8 枚まで生成可能です。小紅書の 9 枚カルーセル投稿であれば、API を使えば一度のリクエストで完結できるため、他のモデルよりも効率的です。ただし、n の値が大きいほど待ち時間や処理時間が長くなるため、大量生産時には非同期タスクとして設定することをおすすめします。
Q7: gpt-image-2 と Nano Banana Pro / Seedream は、小紅書運用においてどれが適していますか?
簡単に言うと、gpt-image-2 は「情報密度が高く、文字が多い」コンテンツ(解説画像、レビューカード、データ図)に向いています。Nano Banana Pro は「クリエイティブなシーンやキャラクターの一貫性」(シリーズもの、ストーリー仕立て)に、Seedream は「東洋的な美学や中国語のレンダリング」(漢服、国風、水墨画)に適しています。これら 3 つのモデルはすべて imagen.apiyi.com で試用できるため、A/B テストを行ってから主力モデルを決めるのが良いでしょう。
Q8: gpt-image-2 で生成する複数枚の画像のスタイルを統一するには?
3 つの重要なコツがあります。第一に、n=9 で一度に生成すること。モデルが自動的にスタイルの一貫性を保ちます。第二に、プロンプトで配色を明確に固定すること(例:「#2D1B69 の紫と #FF6B9D のピンクを統一して使用」)。第三に、レイアウト構造を固定すること(例:「すべての画像で、上部にタイトル、中央にコンテンツ、下部に CTA を配置する」)。もしキャラクターやシーンのより強い一貫性が必要な場合は、gpt-image-2 の画像編集機能を使って、参照画像に基づいた生成を検討してください。
まとめ:gpt-image-2 で小紅書を運用する 3 つの基本ロジック
ここまでで、gpt-image-2 を活用した小紅書コンテンツ制作の 3 つの基本ロジックを整理できます。
第一に、画像生成を「お絵描き」ではなく「プロダクトデザイン」と捉えること。gpt-image-2 のエージェント推論機能により、モデルは「思考するデザイナー」のように振る舞います。プロンプトが設計要件定義書(目標、情報の階層、視覚的な制約)に近いほど、出力は正確になります。
第二に、「情報密度」を差別化の武器にすること。小紅書のアルゴリズムは保存率の高いコンテンツを優遇しますが、保存率の本質は「実用的な価値」です。gpt-image-2 の文字レンダリングとレイアウト能力を活かせば、Canva のテンプレートでは作れない「高密度なインフォグラフィック」を作成でき、これが新しいアカウントが急成長するための最適なルートとなります。
第三に、「ネット検索の知識」をコンテンツの鮮度維持に使うこと。最新の製品、トレンドイベント、公式データに関するコンテンツは、必ず gpt-image-2-all のようなネット検索対応モデルを使用し、AI による情報の捏造(ハルシネーション)を防ぎましょう。
🚀 アクションプラン: もし gpt-image-2 を小紅書のワークフローに組み込むなら、2 つの入り口から始めることをおすすめします。クリエイターの方は imagen.apiyi.com のウェブツールから。3 分で最初の画像が完成します。技術力のあるスタジオの方は APIYI の api.apiyi.com から gpt-image-2-all モデルを接続し、大量生産ラインを構築してください。どちらもネット検索に対応しており、コストパフォーマンスが良く、国内の制作チームが規模を拡大するのに最適です。
gpt-image-2 を使いこなしたからといって、すぐに小紅書でバズるわけではありません。しかし、画像生成にかかる時間を 90% 削減することで、企画立案、文章の推敲、コミュニティ運営といった、データに直接影響を与える重要な作業に集中できるようになります。これこそが、AI ツールがクリエイターにもたらす最大の価値です。
執筆者: APIYI 技術チーム — AI 大規模言語モデルの API 接続とコンテンツ制作ツールの開発に注力。モデルの評価、プロンプトテンプレート、開発ガイドについては apiyi.com をご覧ください。