2026年、あるオーストリアのインディー開発者が週末に作り上げたオープンソースプロジェクトが、わずか2ヶ月で24.7万ものGitHubスターを獲得し、シリコンバレーや中国企業がこぞって導入するAIエージェントプラットフォームとなりました。
このプロジェクトはOpenClawと呼ばれています。
同時に、一つの疑問が浮かび上がりました。OpenClawのような実際のAgentシナリオにおいて、一体どのAIモデルが最高のパフォーマンスを発揮するのでしょうか?
これこそがPinchBenchが解決しようとしている問題です。PinchBenchはOpenClawの公式評価ベンチマークであり、kilo.aiチームがRustで開発しました。合成テストではなく実際のタスクを用いることで、開発者に信頼できるモデル選択の根拠を提供します。
本記事では、OpenClawの台頭の物語から始まり、PinchBenchの評価システムを深く掘り下げて解説します。AIベンチマークの真の意味を理解し、評価データに基づいて自身のAgentワークフローに最適なモデルを選択する方法を学ぶのに役立つでしょう。
一、OpenClawとは:1ヶ月で3度名前を変えたオープンソース現象
OpenClawの誕生と命名騒動
OpenClawの物語は2025年11月に遡ります。
オーストリアのデベロッパー、Peter Steinberger氏は、余暇を利用してAIエージェントプラットフォームを構築しました。当初はClawdbotと名付けられ、そのプロジェクトの核となる理念はシンプルでした。AIを単なるチャットツールではなく、メールの読み込み、コードの記述、カレンダー管理、情報検索といったデジタルワークフローを実際に引き継ぐものにする、というものです。
しかし、AIエージェントという概念自体は目新しいものではありません。なぜOpenClawは一夜にして爆発的な人気を博したのでしょうか?
鍵は、タイミングとオープンソースという二重の恩恵にありました。2026年1月下旬、Moltbookプロジェクトの爆発的な普及に伴い、「AIに実際に仕事をさせる」という技術コミュニティ全体の願望が頂点に達し、Clawdbotはその流れに乗って注目を集めました。
しかし、すぐにAnthropic社から商標異議申し立て通知が届きました。Clawdbotの「Clawd」がAnthropicの内部製品名と混同されるリスクがあると判断されたのです。プロジェクトは2026年1月27日に急遽Moltbotへと改名せざるを得なくなりました。これは同時期に人気を博したMoltbookプロジェクトへの敬意を表したものでした。
ところが3日後、Steinberger氏はGitHub上で「新しい名前は『どうもしっくりこない』("never quite rolled off the tongue")」と率直に述べ、プロジェクトは再びOpenClawへと改名され、現在に至っています。
この命名騒動は、皮肉にもプロジェクトにとって最高の「無料マーケティング」となり、OpenClawは開発者コミュニティで広く知られることになりました。
2026年3月2日現在、OpenClawはGitHubで以下の実績を上げています。
- ⭐ 24.7万 Stars(Reactフレームワークの同時期におけるStarsのほぼ半分に相当)
- 🍴 4.77万 Forks
- 🌍 シリコンバレー、ヨーロッパ、中国企業で大規模に導入
OpenClawの核となる技術アーキテクチャ
OpenClawの設計哲学は、ローカル実行、モデル非依存、メッセージングアプリ連携です。
これら3つの特徴が、他のAIエージェントフレームワークとの根本的な違いを決定づけています。
ローカル実行とは、ユーザーのデータが第三者のサーバーを経由しないことを意味します。ほとんどのSaaS形式のAIアシスタントとは異なり、OpenClawはユーザー自身のデバイスにデプロイされ、モデル呼び出しもプライベートエンドポイントを指すことができます。
モデル非依存とは、OpenClaw自体がいかなる大規模言語モデル(LLM)にも縛られないことを意味します。これは「脳の殻」のようなもので、Claude、GPT、DeepSeekなど、あらゆる主要モデルを接続でき、開発者はタスクの種類やコスト予算に応じて自由に切り替えることができます。
メッセージングアプリ連携は、OpenClawの最も特徴的な設計です。一般ユーザーは専用アプリを開く必要がなく、Signal、Telegram、Discord、WhatsAppなどのメッセージングアプリで直接メッセージを送信するだけで、AIエージェントの機能を利用できます。これにより、利用の敷居が大幅に下がり、非技術系のユーザーも恩恵を受けられるようになりました。
| 設計の側面 | OpenClawの選択 | 主要な代替案 | 相違点 |
|---|---|---|---|
| デプロイ場所 | ローカル実行 | クラウドSaaS | データプライバシーがより強力ですが、自己管理が必要です |
| モデル結合 | 完全非依存 | 特定モデルに結合 | 柔軟に切り替え可能ですが、自己設定が必要です |
| ユーザーインターフェース | メッセージングアプリ | 専用Web/アプリ | 導入の敷居は低いですが、機能はメッセージアプリに制限されます |
| 権限範囲 | 広範なアクセス | サンドボックス制限 | 機能は強力ですが、セキュリティリスクは高くなります |
| オープンソースライセンス | 完全オープンソース | クローズドソース/一部オープンソース | コミュニティ主導ですが、サポート保証は限定的です |
🎯 利用のヒント: OpenClawをデプロイするには、高品質なLLMバックエンドを設定する必要があります。
APIYI (apiyi.com) を介してClaude Sonnet 4.6またはGPT-5.4を接続することをお勧めします。
これら2つのモデルはPinchBenchで優れたパフォーマンスを示しており、APIYIは統一インターフェースでの切り替えをサポートしているため、
OpenClawのコア設定を変更することなく、異なるモデルの効果を素早く比較できます。
OpenClawの機能範囲
OpenClawがサポートする機能範囲は非常に広範ですが、それゆえにセキュリティ上の懸念も引き起こしています。
アクセス可能なデータソース:
- メールアカウント(読み込み、分類、返信の草稿作成)
- カレンダーシステム(スケジュールの表示、作成、変更)
- ファイルシステム(ファイルの閲覧、読み込み、作成、移動)
- コードリポジトリ(コードの読み込み、テスト実行、変更のコミット)
- メッセージングプラットフォーム(クロスプラットフォームメッセージの集約と応答)
- Web情報(検索、要約、構造化抽出)
典型的な使用シナリオ:
ユーザーがTelegramで送信:"今日のメールを整理して、
今日中に返信が必要なものにマークを付け、返信内容の草稿を作成して"
OpenClawエージェントの実行フロー:
1. メールツールを呼び出し、今日の未読メールを読み込む
2. LLMを使用して各メールの緊急度を判断する
3. 今日中に返信が必要なメールのリストをフィルタリングする
4. 各メールの返信草稿を生成する
5. Telegramで整理結果と草稿プレビューを返す
このような「実際に仕事を完遂する」能力が、OpenClawと単純なチャットボットとの本質的な違いです。
Steinberger氏のOpenAI入社とプロジェクトの未来
2026年2月14日、あるニュースがオープンソースコミュニティ全体を揺るがしました。Steinberger氏がGitHub上でOpenAIに入社し、プロジェクトを独立したオープンソース財団に移管すると発表したのです。
これはOpenClawに二重の影響をもたらしました。一方で、プロジェクトはより専門的な運営と法的保証を得ましたが、他方で、OpenAIがこの創設者を買収した背後にある動機、すなわち技術吸収のためか、潜在的な競合他社の出現を防ぐためか、という憶測が広がり始めました。
現在、OpenClaw財団は設立され、プロジェクトは完全オープンソースを維持していますが、開発ロードマップの優先順位は明らかに調整されています。エンタープライズレベルのセキュリティ機能と権限管理システムが次のバージョンの重点となっています。
セキュリティ上の懸念:強力な能力がもたらすリスク
OpenClawがシステム権限を広範に必要とすることは、当初からサイバーセキュリティ研究者の注目を集めていました。
2026年3月、中国当局は国有企業および政府機関がオフィスPCでOpenClawを運用することを制限すると発表しました。主な懸念事項は以下の通りです。
- LLM API呼び出しを通じてデータが海外サービスプロバイダーに漏洩する可能性
- 広範な権限が不適切に設定された場合に攻撃の入り口となる可能性
- 企業内部の機密情報がエージェントによってシステム間で伝達される可能性
この出来事は、すべての企業開発者に対し、強力なエージェントツールを導入する際には、最小権限の原則と監査ログが不可欠なセキュリティ基盤であることを改めて認識させました。
二、AI業界におけるベンチマークの真の役割:試験から実戦へ
AI業界がベンチマークなしでは成り立たない理由
もしあなたが2つのAIモデルの能力を比較しようとしたことがあるなら、おそらくある困難に直面したことがあるでしょう。ベンダーは皆、自社のモデルが「最強」だと言いますが、「強い」とはどういう意味でしょうか?どのようなタスクにおいて?どのようなベースラインと比較して?
**ベンチマーク(評価基準)**は、この問題を解決するために生まれた標準化されたテストシステムです。
AI業界において、優れたベンチマークは3つの条件を満たす必要があります。
- 再現性:誰でも同じテストセットを使用すれば同じ結果が得られること
- 代表性:テスト内容が実際の使用シナリオにおける能力要件を反映していること
- 公平性:テストセットがモデル開発者のトレーニングデータによって汚染されていないこと
2026年には、業界全体で15以上の主要なベンチマークが活発に使用されていますが、実際に本番環境でのパフォーマンスを予測できるものは、業界の推定では約4つに過ぎません。

従来のベンチマークの限界
PinchBenchの価値を理解するには、まず従来のベンチマークがなぜ「不十分」なのかを理解する必要があります。
MMLU(大規模多タスク言語理解)
MMLUは現在最も広く引用されている汎用知識評価で、57の分野をカバーし、約14,000問の選択問題が含まれています。問題は医学、法律、歴史、数学、プログラミングなどの領域に及びます。
問題は、これが選択問題であるということです。モデルは4つの選択肢から1つを選ぶだけで済みます。実際のエージェントシナリオでは、モデルは自律的に回答を生成し、さらには情報を取得するためにツールを呼び出す必要があります。これは「4つの選択肢から1つを選ぶ」とはまったく異なります。
HumanEval(コード生成テスト)
HumanEvalはコード生成能力を測る象徴的なベンチマークで、164のPythonプログラミング問題が含まれています。しかし、その問題は比較的固定されており、モデルがトレーニング時に類似の問題に触れたことがある可能性があるため、「対策学習効果」が生じ、高得点が実際のプログラミング能力を反映しないことがあります。
合成テストの一般的な問題点:
| 問題の種類 | 具体的な内容 | 評価結果への影響 |
|---|---|---|
| データ汚染 | トレーニングセットにテスト問題が含まれる | 高得点が真の汎化能力を意味しない |
| 対策学習効果 | モデルが特定のベンチマークに合わせて最適化される | ランキングが実力よりも高く、実際の能力は向上していない |
| シナリオの乖離 | 選択問題と実際の使用状況が大きく異なる | ランキングの予測力が低い |
| 静的データセット | 問題が固定されており、更新できない | 新しい能力を評価できない |
| 単一軸評価 | 正確性のみを重視 | 速度、コスト、信頼性を無視する |
AIエージェント評価の5つの核となる側面
AIシステムが「質問に答える」から「タスクを完了する」へと進化するにつれて、評価システムも同期してアップグレードされる必要があります。
OpenClawのようなAIエージェントプラットフォームの場合、評価は以下の5つの主要な側面をカバーする必要があります。
側面1:タスク完了率(Task Completion Rate)
タスクの受領から最終的な完了までの全体的な成功率。これは最も直感的な指標ですが、最も複雑でもあります。「完了」の定義自体が評価設計の核となる課題です。
テスト方法:エージェントに3〜5ステップからなる複合タスクを与え、完全に成功、部分的に成功、失敗の割合を統計します。
側面2:ツール呼び出しの正確性(Tool Call Accuracy)
エージェントは、数十の利用可能なツールの中から正しいものを選択し、正しいパラメータで呼び出す必要があります。誤ったツール呼び出しは失敗だけでなく、副作用(ファイル誤削除、誤ったメール送信など)を引き起こす可能性もあります。
テスト方法:特定のツールシーケンスを必要とするタスクを設計し、ツール選択エラー率とパラメータエラー率を統計します。
側面3:多段階推論の一貫性(Multi-step Reasoning Coherence)
タスクを完了するには5〜10ステップが必要となることが多く、エージェントはプロセス全体を通じて目標を明確に認識し続ける必要があり、「途中でどこへ行くべきか忘れてしまう」ことがあってはなりません。
テスト方法:10ステップ以上の長いプロセスを必要とするタスクを設計し、途中で目標の逸脱や論理の破綻がないかを観察します。
側面4:ターンをまたいだコンテキスト保持(Cross-turn Context Retention)
複数ターンの会話において、エージェントは以前に交換された情報を記憶している必要があります。「前回、水曜日に会議があると言いましたね」といった情報は、OpenClawのワークフローにおいて非常に重要です。
テスト方法:5ターン以上前の情報を参照する必要があるタスクシナリオを設計し、コンテキスト喪失率を統計します。
側面5:ハルシネーション頻度(Hallucination Rate)
エージェントが、存在しないファイル、存在しない連絡先、誤った日付などを捏造するハルシネーションは、チャットでは些細な問題ですが、エージェントシナリオでは実際の損失(誤った内容のメール送信など)を引き起こす可能性があります。
テスト方法:実際のデータ(ファイル名、メールアドレス、日付)を参照する必要があるタスクを設計し、ハルシネーションの出現頻度を統計します。
🎯 開発者へのヒント: エージェントモデルを選択する際、タスク完了率とツール呼び出しの正確性が最も重要な2つの指標です。
APIYI (apiyi.com) プラットフォームを利用して複数のモデルを素早く接続し、上記の5つの側面で実際のタスクにおける効果を検証することをお勧めします。
単純にランキングの数字に頼るのではなく、APIYIは従量課金制をサポートしており、小規模なA/Bテストを行ってから最終的な選定を行うのに適しています。
三、PinchBench 深度解析:OpenClaw の公式評価基準
PinchBench 誕生の背景
PinchBench は、kilo.ai チームが Rust を使用して開発した、OpenClaw シナリオに特化した評価ベンチマークであり、GitHub(pinchbench/skill リポジトリ)でオープンソースとして公開されています。
PinchBench が解決する核心的な問題は、汎用モデルランキングが実際の Agent 性能を予測する能力が非常に低いことです。
研究によると、MMLU で上位 5% のスコアを持つモデルが、OpenClaw のメール分類と会議スケジューリングの複合タスクにおいて、MMLU ランキングでは中程度でもツール呼び出しに特化して最適化されたモデルよりもはるかに劣るパフォーマンスを示すことがあります。
PinchBench の登場により、開発者は Agent ワークフローに特化した信頼できる評価基準を初めて手に入れることができました。
PinchBench の 23 のタスクカテゴリ
PinchBench は合成された問題ではなく実際のタスクを使用し、OpenClaw ユーザーの実際の利用シナリオに対応する23 のタスクカテゴリをカバーしています。
主要タスクカテゴリ(6大カテゴリ):
| タスクカテゴリ | 具体的なテスト内容 | 関連ツール | 評価難易度 |
|---|---|---|---|
| スケジュール管理 | 会議のスケジュール設定、競合解決、タイムゾーン処理、定期的なリマインダー | カレンダーAPI、タイムゾーンツール | ★★★☆☆ |
| コード作成 | 機能実装、バグ修正、コードのリファクタリング、単体テスト | コード実行、ファイルシステム | ★★★★☆ |
| メール処理 | 分類、優先順位付け、自動返信ドラフト、添付ファイル処理 | メールクライアントAPI | ★★★☆☆ |
| 情報調査 | ウェブ検索、情報集約、要約生成、情報源の確認 | 検索エンジン、ブラウザ | ★★★★☆ |
| ファイル管理 | 整理整頓、形式変換、一括操作、バージョン管理 | ファイルシステム、変換ツール | ★★☆☆☆ |
| 複数ツール連携 | クロスプラットフォームデータ連携、ツールチェーンオーケストレーション、条件トリガー | 複数ツール組み合わせ | ★★★★★ |
PinchBench の評価方法論
PinchBench は二重評価メカニズムを採用しており、客観性と品質評価の両方を考慮しています。
自動検証(Automated Checks)
検証可能な客観的基準に使用されます。
- コードがすべてのテストケースに合格するかどうか
- ファイルが指定された場所に正しく移動されたかどうか
- カレンダーイベントが正しい時間に作成されたかどうか
- API呼び出しが期待される形式で返されるかどうか
LLMジャッジ(LLM Judge)
主観的判断が必要な定性的評価に使用されます。
- メール返信のトーンとプロフェッショナリズム
- 調査レポートの情報正確性と完全性
- タスク理解の正確性(ユーザーの意図を真に理解しているか)
- エッジケースの処理戦略の妥当性
この組み合わせ方式は、効率性(自動チェックは大規模に実行可能)と品質(LLMジャッジは人間が定量化しにくい詳細を捉える)の両方を兼ね備えています。
三次元評価指標マトリックス:
┌─────────────────────────────────────────────────┐
│ PinchBench 三次元評価体系 │
├─────────────────────────────────────────────────┤
│ 成功率 (Success Rate) │
│ → タスク完了の品質を総合的に測定 │
│ → 主要なランキング軸 │
│ → 自動検証 + LLMジャッジを組み合わせる │
├─────────────────────────────────────────────────┤
│ 速度 (Speed) │
│ → タスク完了の平均時間(秒/分) │
│ → リアルタイム応答シナリオにとって非常に重要 │
│ → API遅延と推論時間を含む │
├─────────────────────────────────────────────────┤
│ コスト (Cost) │
│ → タスク完了に消費されるトークン費用(USD) │
│ → 高頻度使用シナリオの主要指標 │
│ → ROI計算とモデル選定の意思決定を支援 │
└─────────────────────────────────────────────────┘
2026年3月13日現在、PinchBench の公開ランキングデータ:
- 📊 49 のモデルが評価を完了し、主要な商用およびオープンソースモデルをカバー
- 🔄 327 回の実行記録があり、継続的に更新中
- 🌐 公開ランキング:pinchbench.com(リアルタイム更新)
- 📁 オープンソースリポジトリ:github.com/pinchbench/skill(タスク定義は公開)
🎯 PinchBench 利用のヒント: ランキングを見る際は、成功率、速度、コストの3つのビューを切り替えて、
自身の実際のニーズ(リアルタイム性 vs 品質 vs コスト)に基づいて最適なモデルを絞り込むことをお勧めします。
APIYI apiyi.com を通じて統合アクセスすれば、同じビジネスシナリオで異なるモデルの実際のコストを簡単に比較できます。
四、PinchBench ランキングの深掘り解説とモデル選定ガイド
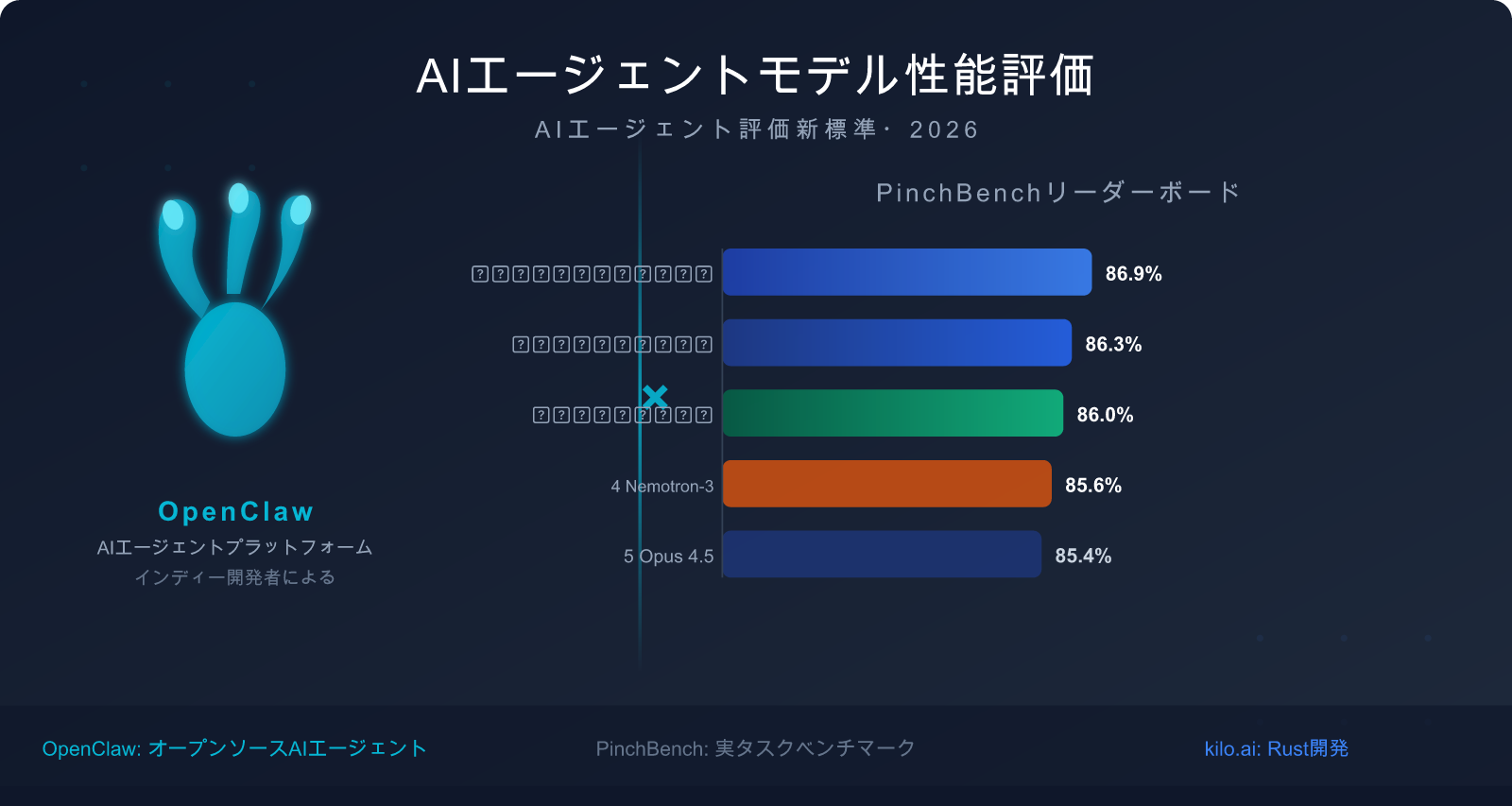
現在の成功率トップ5ランキング(2026年3月13日データ)
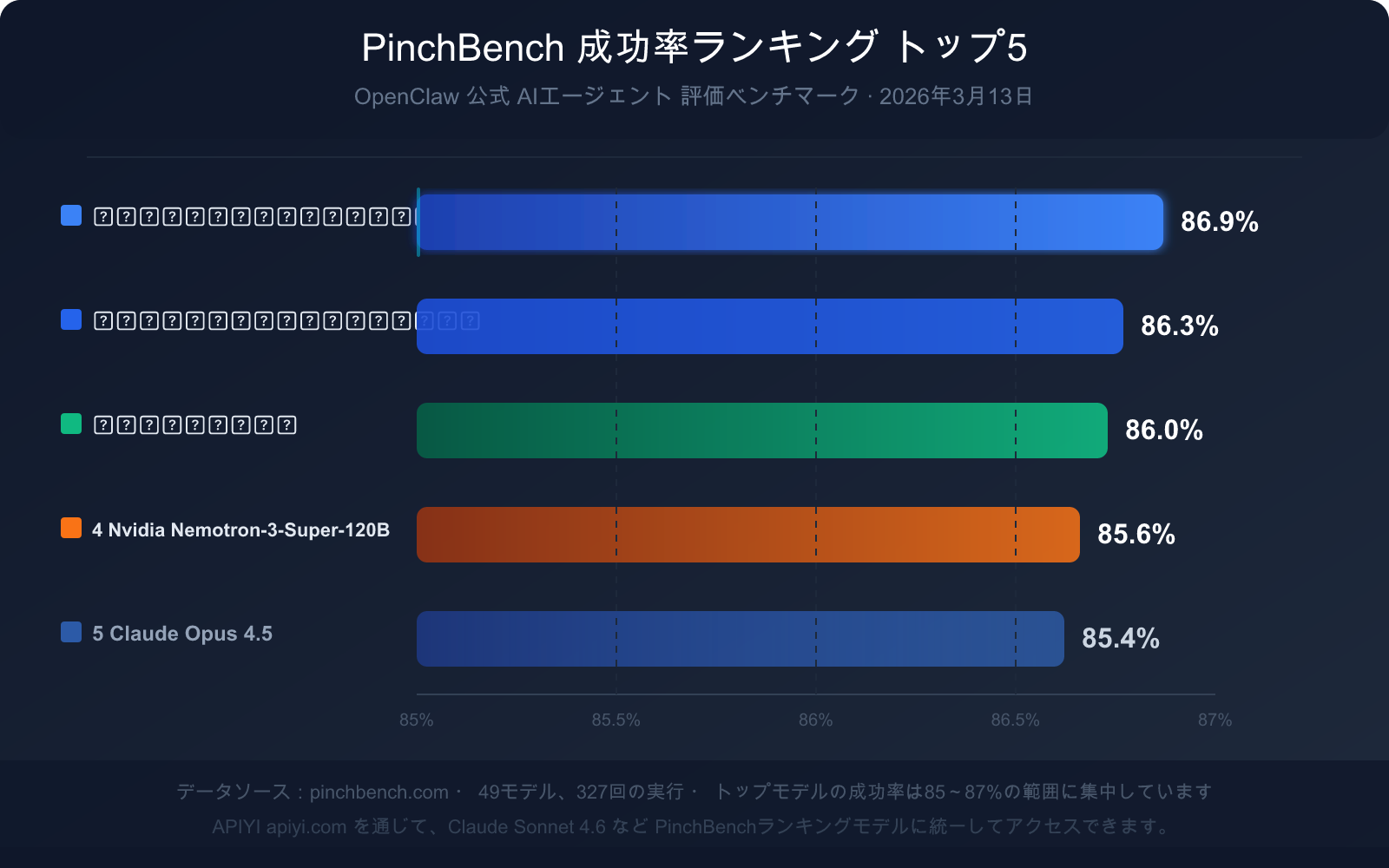
| ランキング | モデル名 | 成功率 | モデルタイプ | 主要な強み |
|---|---|---|---|---|
| 🥇 1 | Claude Sonnet 4.6 | 86.9% | 商用クローズドソース | 成功率が最も高く、速度と品質のバランスが良い |
| 🥈 2 | Claude Opus 4.6 | 86.3% | 商用クローズドソース | 複雑な推論能力が最も高い |
| 🥉 3 | GPT-5.4 | 86.0% | 商用クローズドソース | ツール呼び出しの安定性が高い |
| 4 | Nvidia Nemotron-3-Super-120B | 85.6% | オープンソースでデプロイ可能 | オープンソースモデルの中で最高のパフォーマンス |
| 5 | Claude Opus 4.5 | 85.4% | 商用クローズドソース | 前世代のフラッグシップで、依然として競争力がある |
主要データ分析:85% の成功率が意味するものとは?
トップモデルの PinchBench における成功率は 85%〜87% の範囲に集中しており、満点に近いわけではありません。この数字自体が3つの重要なシグナルを伝えています。
シグナル 1:AI Agent タスクは依然として難易度の高い問題である
ランキング1位の Claude Sonnet 4.6(86.9%)でさえ、100のタスクのうち約13のタスクで失敗します。これはモデルの能力不足ではなく、現実世界のタスクに固有の複雑性、すなわち曖昧な指示、不完全な情報、ツール呼び出しのエッジケースなどが失敗の原因となります。
シグナル 2:Agent 開発においてフォールトトレラント設計は不可欠である
13% の失敗率が「トップレベル」である場合、人間によるレビューポイントがない完全自動エージェントプロセスは、本番環境ではハイリスクです。最善のプラクティスは、リスクの高い操作(メール送信、コード提出など)には人間による確認ステップを残すことです。
シグナル 3:モデル間の差はごくわずかであり、タスク設計がより重要である
ランキング1位と5位の差はわずか 1.5パーセントポイント(86.9% vs 85.4%)です。これは、どのモデルを選択するかの影響よりも、プロンプトの設計方法、ツールインターフェースの定義方法、エラー状況の処理方法の方がはるかに重要であることを意味します。
三次元指標の総合分析
成功率だけを見るのでは不十分です。以下に3つの指標を総合的に考慮するフレームワークを示します。
| 利用シーン | 優先指標 | 副次指標 | 推奨モデルの方向性 |
|---|---|---|---|
| 高頻度軽量タスク(メール分類、リマインダー) | 速度 + コスト | 成功率 | Claude Haiku 4.5 などの軽量モデル |
| 複雑なエンジニアリングタスク(コードのリファクタリング、調査) | 成功率 | 速度 | Claude Sonnet 4.6 / GPT-5.4 |
| リアルタイム応答シナリオ(インスタントアシスタント) | 速度 | 成功率 | 速度ランキング上位モデル |
| コスト重視型アプリケーション | コスト | 成功率 | オープンソース自己デプロイ / API低価格モデル |
| 企業セキュリティとコンプライアンス | 成功率 + 制御性 | コスト | プライベートデプロイのオープンソースモデル |
🎯 総合的なモデル選定のヒント: PinchBench のデータによると、Claude Sonnet 4.6 は現在の OpenClaw シナリオにおいて成功率が最も高い総合的な選択肢です。
コストに敏感な高頻度シナリオでは、まず Claude Sonnet 4.6 でタスク成功率のベースラインを確立し、
その後、より軽量なモデルで許容される成功率の範囲内でコストを大幅に削減できるかをテストすることをお勧めします。
これらのテストはすべて、APIYI apiyi.com の統合APIインターフェースを通じて完了でき、複数のサービスプロバイダーアカウントを個別に登録する必要はありません。
オープンソースモデルの競争力分析
Nvidia Nemotron-3-Super-120B は 85.6% の成功率で4位にランクインしており、1位との差はわずか1.3パーセントポイントです。これはオープンソースモデルとしては非常に素晴らしい成績です。
オープンソースモデルの強み:
- データ主権:モデルとデータは自己管理環境にあり、コンプライアンス要件を満たします
- コスト構造:一度限りのGPU投資で、その後のAPI呼び出し費用は不要(大量利用シナリオの場合)
- カスタマイズの余地:特定のタスク向けにファインチューニングが可能
オープンソースモデルの限界:
- デプロイコスト:120B パラメータモデルには 4〜8 枚の A100/H100 GPU が必要です
- メンテナンス負担:モデル更新、バージョン管理には専任の運用保守が必要です
- 初期テストコスト:オープンソースモデルが自身のシナリオに適していることを確認する前に、商用APIを通じてプロトタイプ検証を行う方が経済的である場合が多いです
五、実践ガイド:OpenClawで最適なモデルを構成する方法
Claude Sonnet 4.6 を OpenClaw に迅速に接続する
以下は、APIYI を介して PinchBench ランキング1位のモデルを接続するための完全な設定例です。
ステップ 1:APIキーの取得
APIYI 公式サイト apiyi.com にアクセスしてアカウントを登録し、コンソールでAPIキーを取得します。APIYI は OpenAI 互換インターフェースを提供し、Anthropic ネイティブ SDK もサポートしています。
ステップ 2:OpenClaw のモデルバックエンドを構成する
# OpenClaw 設定ファイル例(config.yaml)
model:
provider: anthropic
name: claude-sonnet-4-6
api_key: "${APIYI_API_KEY}"
base_url: "https://api.apiyi.com/v1"
agent:
max_steps: 20 # 最大実行ステップ数
tool_timeout: 30 # ツール呼び出し1回あたりのタイムアウト(秒)
retry_on_error: true # ツール呼び出し失敗時に自動でリトライ
human_review:
enabled: true
trigger: ["send_email", "commit_code", "delete_file"] # 高リスク操作には手動確認が必要
ステップ 3:設定効果の検証
# Anthropic SDK を使用して接続をテスト
import anthropic
client = anthropic.Anthropic(
api_key="your-apiyi-key",
base_url="https://api.apiyi.com/v1"
)
# テストリクエストを送信
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1024,
messages=[{
"role": "user",
"content": "OpenClaw で実行できるタスクの種類を3つ挙げてください。"
}]
)
print(response.content[0].text)
ステップ 4:複数モデルのA/Bテスト設定
# 同じタスクで異なるモデルを比較(本番デプロイ前に実行することを推奨)
models_to_test = [
"claude-sonnet-4-6", # PinchBench ランキング1位
"gpt-5.4-turbo", # PinchBench ランキング3位(OpenAI 形式と互換性あり)
"claude-opus-4-5", # 前世代のフラッグシップモデル、コスト比較用
]
# APIYI は上記すべてのモデルの統一インターフェース呼び出しをサポート
# base_url は変更せず、model パラメータのみを変更
for model_name in models_to_test:
result = run_benchmark_task(
model=model_name,
task="schedule_weekly_team_meeting",
base_url="https://api.apiyi.com/v1"
)
print(f"{model_name}: 成功率={result.success_rate}, 所要時間={result.avg_time}s, コスト=${result.cost_per_task}")
🎯 クイックスタート: APIYI apiyi.com にアクセスして登録すると、テスト用のクレジットが提供されます。
Claude Sonnet 4.6、GPT-5.4 など、PinchBench ランキングに掲載されているモデルへの統一APIアクセスをサポートしており、
複数のプロバイダーに個別にアクセス許可を申請する必要がなく、モデルテストの初期ハードルを大幅に下げることができます。
PinchBenchの5つの側面でAgentを自己テストする
本番環境にデプロイする前に、以下の自己テストチェックリストでAgentの設定を評価することをお勧めします。
PinchBench に着想を得た Agent 自己テストチェックリスト
□ 側面1 - タスク完了率
Agent に3ステップ以上の複合タスクを10個与える
完全に成功 / 部分的に成功 / 失敗の数を記録する
目標:完全成功率 ≥ 80%
□ 側面2 - ツール呼び出しの正確性
ツール呼び出しログをチェックし、以下のエラータイプを統計する:
- ツール選択エラー(誤ったツールを選択した)
- パラメータ形式エラー(パラメータの型または形式が正しくない)
- パラメータ値エラー(パラメータの型は正しいが値が不適切)
目標:ツールエラー率 ≤ 5%
□ 側面3 - 多段階推論の一貫性
15ステップ以上の長いプロセスを必要とするタスクを設計する
途中で目標の逸脱(最初の目標を忘れる)が発生しないか観察する
目標:長いプロセスを要するタスクで目標の逸脱がないこと
□ 側面4 - コンテキスト保持
1回目のラウンドで重要な情報を提供し、8回目のラウンドでその情報を参照する
Agent が正しく参照できるかチェックする
目標:ラウンドをまたいだ参照の正確性 ≥ 90%
□ 側面5 - ハルシネーション検出
実際のデータ(ファイル名/連絡先/日付)を参照する必要があるタスクを設計する
Agent が存在しないデータを捏造しないかチェックする
目標:ハルシネーション発生率 ≤ 2%
六、AIベンチマークの未来:単一評価からエコシステム評価へ
現在のベンチマークシステムの進化トレンド
2026年、AIベンチマーク分野は深い変革を経験しています。この変革の核心は、評価対象が単一モデルから完全なAgentシステムへと拡大していることです。
従来のベンチマークの考え方は、「モデルに問題を出して、正しく答えられるかを見る」というものでした。しかし、OpenClawのようなAgentプラットフォームが普及するにつれて、本当に重要な問題は「モデルがシステム全体の『頭脳』として、そのシステムに仕事を完遂させられるか?」に変わりました。
この問いの答えは、モデルの知識量だけでなく、以下の要素にも左右されます。
- ツール記述に対するモデルの理解能力
- 不確実な情報下でのモデルの意思決定戦略
- エラーの識別と回復におけるモデルの能力
- ユーザーの意図を長期的に追跡するモデルの能力
PinchBenchの価値は、これらの側面を定量化し、公開している点にあります。
AIベンチマークデータの正しい利用方法
ベンチマークデータは価値がありますが、誤用されやすいものでもあります。以下にいくつかの一般的な誤解と正しい実践方法を示します。
誤解 1:「ランキングが最も高いモデルが必ずしも最高」と考える
正しい実践方法:ランキングはPinchBenchの特定のタスクセットに基づいています。あなたのタスクでは異なる重み付けがあるかもしれません。まず自分のタスクでテストしてから、モデル選定を行いましょう。
誤解 2:成功率だけを見て、速度とコストを無視する
正しい実践方法:3つの指標(成功率、速度、コスト)はどれも欠かせません。バッチ処理のシナリオでは、速度が50%異なるとコストも50%削減できることを意味します。リアルタイム応答のシナリオでは、速度が2秒異なるとユーザー体験が著しく低下する可能性があります。
誤解 3:1%の成功率の差は取るに足らないと考える
正しい実践方法:小規模なテストでは1%の成功率の差は取るに足らないように見えますが、高頻度の本番シナリオでは毎日数百回の失敗につながる可能性があります。実際のタスク量と合わせて、その影響を評価する必要があります。
誤解 4:静的なベンチマークデータで長期計画を立てる
正しい実践方法:AIモデルのイテレーション速度は非常に速く、2026年には主要ベンダーが平均して四半期ごとに重要なアップデートをリリースしています。モデルのパフォーマンス評価を定期的な技術レビューに含め、「一度選定したら終わり」という考え方を避けましょう。
企業向けAgent評価のベストプラクティス
企業でOpenClawまたは類似のAgentプラットフォームを導入する技術チーム向けに、以下に実践可能な評価のベストプラクティスを示します。
ステップ 1:ベースラインタスクセットの確立
実際の業務から、日常的な高頻度操作と偶発的な複雑なシナリオをカバーする20〜50個の代表的なタスクを選びます。このタスクセットは、純粋な技術的視点による評価の偏りを避けるため、ビジネス側と技術側が共同で定義すべきです。
ステップ 2:3つの指標の継続的な追跡
企業内Agent評価指標体系の推奨
コア指標(毎週統計):
- タスク完了率:目標 ≥ 85%(PinchBenchのトップモデル水準に匹敵)
- ツール呼び出しエラー率:目標 ≤ 5%
- 平均タスク所要時間:ビジネスSLAに基づいて定義
補助指標(毎月統計):
- タスクあたりのトークンコスト:運用コストの管理
- 手動介入率:手動での対応が必要なタスクの割合
- エラータイプ分布:改善方向の分析
警告指標(リアルタイム監視):
- 高リスク操作の失敗率:メール送信/ファイル削除などの失敗は即座にアラート
- ハルシネーションイベント:情報の捏造があった場合は即座に記録し分析
ステップ 3:モデルの定期的な再評価
四半期ごとに、現在デプロイされているモデルと新しくリリースされた候補モデルを、内部タスクセットを使用して再評価することをお勧めします。PinchBenchの最新公開データと合わせて、モデルのアップグレードや切り替えが必要かどうかを判断します。
ステップ 4:ドメイン知識の蓄積
一般的なベンチマークでは、各企業の特殊なシナリオをすべてカバーすることはできません。利用を重ねるにつれて、自社のビジネスに適したタスクセットと評価基準を徐々に構築していくことが、AIベンダーを選定する上で重要なフィルタリングツールとなります。
🎯 企業選定の推奨: Agentプラットフォーム導入の初期段階では、APIYI apiyi.com を通じて従量課金制で複数の候補モデルを接続し、
3〜4週間の実測テストを自社の内部タスクセットで行ってから、月額プランへの移行を決定することをお勧めします。
APIYI は Claude、GPT、Gemini など主要な大規模言語モデルの統一インターフェースをサポートしており、
テスト段階で複数のプロバイダーアカウントを個別に登録する必要がなく、評価管理コストを大幅に削減できます。
よくある質問
Q: OpenClaw と AutoGPT、AutoGen の主な違いは何ですか?
OpenClaw の核となる違いは、アクセス方法と利用のしやすさにあります。メッセージングアプリ(Signal、WhatsAppなど)を通じてAgentインターフェースを提供するため、一般ユーザーは専用アプリのインストールや技術的な詳細を理解する必要がありません。技術アーキテクチャの観点から見ると、OpenClaw は「個人AI秘書」に近く、AutoGen などのフレームワークは、開発者が複雑なマルチAgentシステムを構築するのに適しています。OpenClaw は「すぐに使えるコンシューマー向け体験」を重視し、AutoGen は「柔軟なエンタープライズ向け開発フレームワーク」を重視しています。
🎯 どのAgentフレームワークを選択する場合でも、APIYI (apiyi.com) を通じてバックエンドモデルに一元的にアクセスできるため、各フレームワークごとに個別にAPIキーを設定する手間を省けます。
Q: PinchBench の成功率ランキングはどのくらいの頻度で更新されますか?
PinchBench のランキングはリアルタイムで更新されます。新しいモデルの評価が完了するたびに、データはすぐに pinchbench.com に反映されます。主要ベンダーが継続的に新バージョンをリリースしているため、ランキングは頻繁に変動します。正式なモデル選定を行う前に、最新のデータを確認することをお勧めします。本記事のデータは、2026年3月13日時点のスナップショット(49モデル、327回の実行記録)に基づいています。
Q: OpenClaw に最適なモデルを選ぶにはどうすればよいですか?
3段階のモデル選定方法をお勧めします。
- PinchBench の成功率を確認する:タスク完了率の上位5モデルを絞り込みます。
- 速度とコストの側面を確認する:タスクの種類(リアルタイム vs バッチ処理、高頻度 vs 低頻度)に基づいて、さらに絞り込みます。
- 実際のA/Bテストを行う:2~3の候補モデルを実際の業務タスクで比較します。
APIYI (apiyi.com) を通じて、同じ
base_urlを使用して異なるモデルを素早く切り替え、A/Bテストを行った上で最終的な決定を下すことができます。
Q: オープンソースモデルは、OpenClaw を動かす商用モデルを完全に代替できますか?
PinchBench のデータを見ると、Nvidia Nemotron-3-Super-120B(85.6%)とトップクラスの商用モデル(86.9%)との差は約1.3ポイントです。一般的なAgentタスクであれば、この差は許容範囲内と言えるでしょう。ただし、120Bパラメーターモデルを自己デプロイするには、4~8枚のハイエンドGPUが必要となり、初期のハードウェア投資と運用コストは安くありません。まずは商用APIを使用してAgent設計の実現可能性を検証し、その後、自己デプロイのオープンソースモデルへの移行が費用対効果に見合うかを評価することをお勧めします。
Q: OpenClaw のセキュリティリスクはどのように回避できますか?
核となる原則は最小権限の原則です。OpenClaw には、タスクを完了するために必要な最小限の権限のみを付与してください。具体的な推奨事項は以下の通りです。
- メールは読み取り専用権限(読み書き削除の全権限ではなく)
- コードリポジトリは読み取り専用+PR作成権限(メインブランチへの直接プッシュではなく)
- ファイルシステムは特定の作業ディレクトリに限定(ファイルシステム全体ではなく)
- リスクの高い操作(メール送信、ファイル削除など)には、必ず手動での確認ステップを追加する
企業でデプロイする際には、完全な操作監査ログも設定し、Agent の各操作が追跡可能であることを確認する必要があります。
Q: PinchBench と他のAgentベンチマークとの違いは何ですか?
PinchBench の最大の特徴はシナリオ特化性です。これは、汎用的なAgent評価ではなく、OpenClaw の使用シナリオに特化して設計されています。そのため、OpenClaw ユーザーにとっては参考価値が高いですが、他のAgentフレームワークのモデル選定を直接評価するのには適していません。その他の有名なAgentベンチマークには、AgentBench(多様な環境をカバー)、SWE-Bench(コードタスクに特化)などがあり、それぞれに重点が置かれています。
まとめ:OpenClaw + PinchBench がAgent時代に新たな標準を確立
OpenClaw は、あるオーストリア人開発者の週末プロジェクトから、わずか2ヶ月で世界で最も人気のあるAIエージェントプラットフォームへと成長しました。これは、「AIが実際に何かを成し遂げる」ことに対する業界全体の強い願望を反映しています。
そしてPinchBenchの登場は、Agent評価分野における重要な空白を埋めました。ついに、Agentの能力を専門的に測定する「物差し」を手に入れたのです。
主要な結論の概要:
- Claude Sonnet 4.6 は、現在のOpenClawシナリオにおける総合的な最適解です(成功率86.9%、PinchBenchランキング1位)。
- トップモデルの成功率は85~87%に集中しており、Agentタスクは依然として挑戦的であり、フォールトトレラントな設計が不可欠です。
- 速度とコストも同様に重要であり、高い成功率のモデルがすべてのシナリオに適しているとは限りません。三次元的な総合評価が必要です。
- PinchBench はAI評価の未来の方向性を示しています:実際のシナリオタスクが合成テストに取って代わりつつあります。
- **モデル選択による差は約1~2%**であり、タスク設計とプロンプトエンジニアリングの影響の方が大きい場合がほとんどです。
OpenClaw エコシステムを深く活用したい開発者や企業にとって、今は絶好の機会です。
オープンソースコミュニティは活発で、評価ツールも充実しており、主要モデルのAPIアクセスコストも継続的に低下しています。「完璧なソリューション」を待つ必要はありません。今すぐに小規模なタスクでAgentワークフローの実現可能性を検証できます。
🎯 今すぐ行動しましょう:OpenClaw ベースのAIワークフローを構築しているなら、APIYI (apiyi.com) を通じた一元的なアクセスをお勧めします。
プラットフォームは、Claude Sonnet 4.6(PinchBench 1位)、GPT-5.4(3位)などの主要モデルをサポートしています。
同じAPIインターフェースで、複数のサービスプロバイダーに個別に登録する必要がなく、従量課金制をサポートしているため、小規模なテストから始めて段階的に拡張するのに適しています。
APIYI 公式サイト apiyi.com にアクセスして登録すれば、すぐに体験を開始できます。
本記事のデータは2026年3月の公開資料に基づいてまとめられています。PinchBench のリアルタイムランキングデータは pinchbench.com で最新版をご確認ください。
著者:APIYI Team | AIモデルのAPIアクセスについては、APIYI (apiyi.com) にアクセスして詳細をご確認ください。