Qwen3-Maxを使用してAIアプリケーションを開発している際、頻繁に遭遇する 429 You exceeded your current quota エラーは、多くの開発者にとって大きな悩みです。この記事では、Aliyun Qwen3-Maxの速度制限メカニズムを詳細に分析し、5つの実用的な解決策を提示することで、クォータ不足の悩みから完全に解放されるお手伝いをします。
この記事の価値: 本記事を読み終える頃には、Qwen3-Maxの速度制限の仕組みを理解し、複数の解決策の中から自分に最適な方法を選択して、万億パラメータの大規模言語モデルを安定して呼び出せるようになります。
Qwen3-Max 速度制限問題の概要
典型的なエラーメッセージ
アプリケーションでQwen3-Max APIを頻繁に呼び出すと、以下のようなエラーに遭遇することがあります。
{
"error": {
"message": "You exceeded your current quota, please check your plan and billing details.",
"type": "insufficient_quota",
"code": "insufficient_quota"
},
"status": 429
}
このエラーは、Aliyun Model Studio(旧DashScope)のクォータ制限に達したことを意味します。
Qwen3-Max 速度制限問題の影響範囲
| 影響シーン | 具体的な現象 | 深刻度 |
|---|---|---|
| Agent開発 | マルチターン会話が頻繁に中断される | 高 |
| バッチ処理 | タスクが完了しない | 高 |
| リアルタイムアプリ | ユーザー体験(UX)の低下 | 高 |
| コード生成 | 長いコード出力が途中で途切れる | 中 |
| テスト・デバッグ | 開発効率の大幅な低下 | 中 |
Qwen3-Max レート制限メカニズム詳細解説
Alibaba Cloud公式クォータ制限
Alibaba Cloud Model Studioの公式ドキュメントによると、Qwen3-Maxのクォータ(割り当て)制限は以下の通りです:
| モデルバージョン | RPM (リクエスト/分) | TPM (トークン/分) | RPS (リクエスト/秒) |
|---|---|---|---|
| qwen3-max | 600 | 1,000,000 | 10 |
| qwen3-max-2025-09-23 | 60 | 100,000 | 1 |
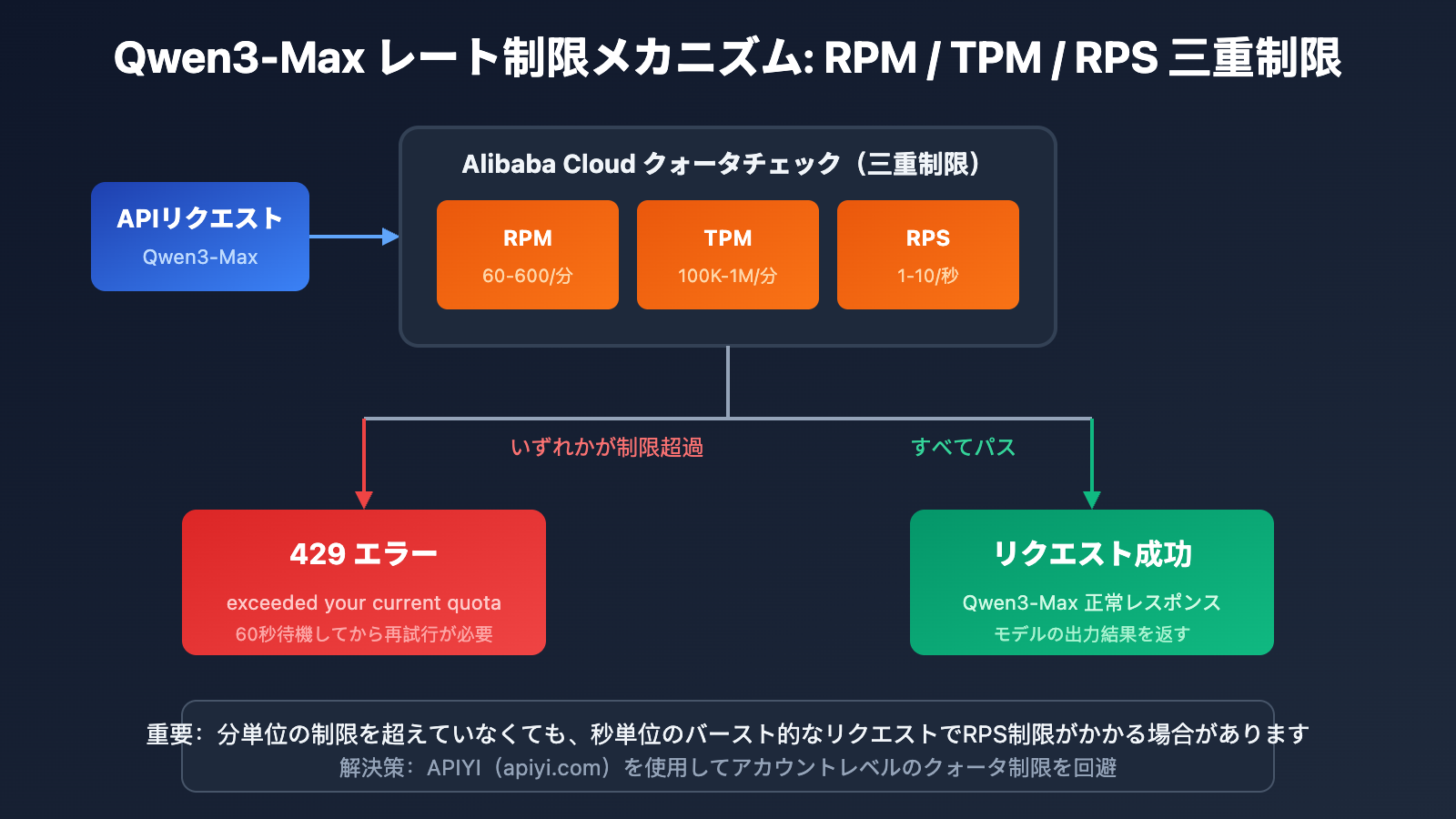
Qwen3-Max レート制限が発生する 4 つのケース
Alibaba CloudはQwen3-Maxに対して二重の制限メカニズムを導入しており、いずれかの条件に触れると429エラーが返されます:
| エラータイプ | エラーメッセージ | 発生原因 |
|---|---|---|
| リクエスト頻度超過 | Requests rate limit exceeded | RPM/RPSが制限を超過 |
| トークン消費量超過 | You exceeded your current quota | TPM/TPSが制限を超過 |
| 突発的なトラフィック保護 | Request rate increased too quickly | 瞬時的なリクエストの急増 |
| 無料枠の使い切り | Free allocated quota exceeded | 試用枠を使い切った |
レート制限の計算式
実際の制限 = min(RPM 制限, RPS × 60)
= min(TPM 制限, TPS × 60)
重要なヒント: 分単位の制限を超えていなくても、秒単位の突発的なリクエストがレート制限(RPS)をトリガーする可能性があります。
Qwen3-Max レート制限問題を解決する 5 つの方法
解決策の比較概要
| 解決策 | 実施の難易度 | 効果 | コスト | 推奨シーン |
|---|---|---|---|---|
| APIプロキシサービス | 低 | 根本解決 | 安価 | すべてのシーン |
| リクエスト平滑化戦略 | 中 | 緩和 | なし | 軽微な制限時 |
| 複数アカウントのローテーション | 高 | 緩和 | 高 | 企業ユーザー |
| 代替モデルへのフォールバック | 中 | 保険 | 中 | 非コア業務 |
| クォータ引き上げの申請 | 低 | 限定的 | なし | 長期ユーザー |
解決策1:APIプロキシサービスの使用(推奨)
これはQwen3-Maxのレート制限問題を解決する最も直接的で効果的な方法です。APIプロキシプラットフォーム経由で呼び出すことで、Alibaba Cloudのアカウント単位のクォータ制限を回避できます。
なぜAPIプロキシがレート制限を解決できるのか
| 比較項目 | Alibaba Cloudに直接接続 | APIYI経由 |
|---|---|---|
| クォータ制限 | アカウント単位のRPM/TPM制限 | プラットフォームレベルの共有プール |
| 制限の頻度 | 頻繁に429が発生 | 基本的に制限なし |
| 価格 | 公式定価 | デフォルトで12%OFF(0.88倍) |
| 安定性 | アカウントのクォータに依存 | マルチチャネルによる安定稼働 |
シンプルなコード例
from openai import OpenAI
# APIYIプロキシサービスを使用して、レート制限の悩みから解放
client = OpenAI(
api_key="your-apiyi-key",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="qwen3-max",
messages=[
{"role": "user", "content": "MoEアーキテクチャの動作原理を説明してください"}
]
)
print(response.choices[0].message.content)
🎯 推奨プラン: APIYI(apiyi.com)経由でQwen3-Maxを呼び出すと、レート制限問題を根本的に解決できるだけでなく、12%OFFのお得な価格で利用できます。APIYIはAlibaba Cloudとチャネル提携しており、より安定したサービスと低価格を提供しています。
完全なコードを表示(リトライとエラー処理を含む)
import time
from openai import OpenAI
from openai import APIError, RateLimitError
class Qwen3MaxClient:
"""Qwen3-Max クライアント。APIYI経由で呼び出すため、レート制限の心配がありません"""
def __init__(self, api_key: str):
self.client = OpenAI(
api_key=api_key,
base_url="https://api.apiyi.com/v1" # APIYI プロキシインターフェース
)
self.model = "qwen3-max"
def chat(self, message: str, max_retries: int = 3) -> str:
"""
メッセージを送信して返信を取得
APIYI経由での呼び出しは、基本的にレート制限にかかりません
"""
for attempt in range(max_retries):
try:
response = self.client.chat.completions.create(
model=self.model,
messages=[{"role": "user", "content": message}],
max_tokens=4096
)
return response.choices[0].message.content
except RateLimitError as e:
# APIYIを使用する場合、この例外はほとんど発生しません
if attempt < max_retries - 1:
wait_time = 2 ** attempt
print(f"リクエストが制限されました。{wait_time}秒後に再試行します...")
time.sleep(wait_time)
else:
raise e
except APIError as e:
print(f"APIエラー: {e}")
raise e
return ""
def batch_chat(self, messages: list[str]) -> list[str]:
"""一括処理。レート制限を気にせず実行可能"""
results = []
for msg in messages:
result = self.chat(msg)
results.append(result)
return results
# 使用例
if __name__ == "__main__":
client = Qwen3MaxClient(api_key="your-apiyi-key")
# 単発呼び出し
response = client.chat("Pythonでクイックソートのアルゴリズムを書いてください")
print(response)
# 一括呼び出し - APIYIならレート制限に悩まされません
questions = [
"MoEアーキテクチャとは何か説明してください",
"TransformerとRNNを比較してください",
"アテンションメカニズムとは何ですか"
]
answers = client.batch_chat(questions)
for q, a in zip(questions, answers):
print(f"Q: {q}\nA: {a}\n")
解決策2:リクエスト平滑化戦略
Alibaba Cloudに直接接続し続ける場合は、リクエストを平滑化することで制限を緩和できます。
指数バックオフによる再試行
import time
import random
def call_with_backoff(func, max_retries=5):
"""指数バックオフ再試行戦略"""
for attempt in range(max_retries):
try:
return func()
except Exception as e:
if "429" in str(e) and attempt < max_retries - 1:
# 指数バックオフ + ランダムジッター
wait_time = (2 ** attempt) + random.uniform(0, 1)
print(f"レート制限が発生。{wait_time:.2f} 秒待機して再試行します...")
time.sleep(wait_time)
else:
raise e
リクエストキューによるバッファリング
import asyncio
from collections import deque
class RequestQueue:
"""リクエストキュー。Qwen3-Maxの呼び出し頻度を平滑化します"""
def __init__(self, rpm_limit=60):
self.queue = deque()
self.interval = 60 / rpm_limit # リクエスト間隔
self.last_request = 0
async def throttled_request(self, request_func):
"""制限付きリクエスト"""
now = time.time()
wait_time = self.interval - (now - self.last_request)
if wait_time > 0:
await asyncio.sleep(wait_time)
self.last_request = time.time()
return await request_func()
注意: リクエスト平滑化はあくまで「緩和」であり、根本的な解決にはなりません。高並列なシーンでは、APIYIプロキシサービスの使用をお勧めします。
解決策3:複数アカウントのローテーション
企業ユーザーは、複数のアカウントをローテーションさせることで、全体のクォータを増やすことができます。

from itertools import cycle
class MultiAccountClient:
"""複数アカウントのローテーションクライアント"""
def __init__(self, api_keys: list[str]):
self.clients = cycle([
OpenAI(api_key=key, base_url="https://dashscope.aliyuncs.com/compatible-mode/v1")
for key in api_keys
])
def chat(self, message: str) -> str:
client = next(self.clients)
response = client.chat.completions.create(
model="qwen3-max",
messages=[{"role": "user", "content": message}]
)
return response.choices[0].message.content
| アカウント数 | 等価 RPM | 等価 TPM | 管理の複雑度 |
|---|---|---|---|
| 1 | 600 | 1,000,000 | 低 |
| 3 | 1,800 | 3,000,000 | 中 |
| 5 | 3,000 | 5,000,000 | 高 |
| 10 | 6,000 | 10,000,000 | 非常に高い |
💡 比較アドバイス: 複数アカウントの管理は複雑でコストもかさみます。APIYI(apiyi.com)のプロキシサービスを利用すれば、単一の設定でプラットフォーム全体の巨大なクォータプールを共有できるため、管理の手間が一切ありません。
解決策4:代替モデルへのフォールバック
Qwen3-Maxでレート制限が発生した際、自動的に代替モデルへ切り替えることができます。
class FallbackClient:
"""フォールバック対応の Qwen クライアント"""
MODEL_PRIORITY = [
"qwen3-max", # 第一選択
"qwen-plus", # 予備 1
"qwen-turbo", # 予備 2
]
def __init__(self, api_key: str):
self.client = OpenAI(
api_key=api_key,
base_url="https://api.apiyi.com/v1" # APIYI を使用
)
def chat(self, message: str) -> tuple[str, str]:
"""(返信内容, 実際に使用されたモデル) を返す"""
for model in self.MODEL_PRIORITY:
try:
response = self.client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": message}]
)
return response.choices[0].message.content, model
except Exception as e:
if "429" in str(e):
print(f"{model} が制限中のため、ダウングレードを試行します...")
continue
raise e
raise Exception("すべてのモデルが利用不可能です")
解決策5:クォータ引き上げの申請
長期的に安定して利用するユーザーは、Alibaba Cloudに対してクォータの引き上げを申請できます。
申請ステップ:
- Alibaba Cloudコンソールにログイン
- Model Studioのクォータ管理(配额管理)ページへ移動
- クォータ引き上げ申請を提出
- 審査を待機(通常1〜3営業日)
申請要件:
- アカウントの実名認証が完了していること
- 未払いの料金がないこと
- 利用シーンの説明を提供すること
Qwen3-Max 速度制限問題のコスト比較
価格比較分析
| サービスプロバイダー | 入力価格 (0-32K) | 出力価格 | 速度制限の状況 |
|---|---|---|---|
| Alibaba Cloud(直結) | $1.20/M | $6.00/M | 厳格な RPM/TPM 制限 |
| APIYI (12%割引) | $1.06/M | $5.28/M | 基本的に制限なし |
| 差額 | 12% 節約 | 12% 節約 | – |
総合コスト計算
月間コール数を 1,000 万トークン(入力と出力が半分ずつ)と仮定した場合:
| プラン | 月額料金 | 速度制限の影響 | 総合評価 |
|---|---|---|---|
| Alibaba Cloud(直結) | $36.00 | 頻繁に中断し、再試行が必要 | 実質的なコストはより高くなる |
| APIYI 経由 | $31.68 | 安定しており中断なし | コスパ最強 |
| 複数アカウント運用 | $36.00+ | 管理コストが高い | 非推奨 |
💰 コスト最適化: APIYI(apiyi.com)は Alibaba Cloud とチャネル提携しており、デフォルトで 12% 割引が適用されるだけでなく、速度制限の問題も完全に解決できます。中〜高頻度の利用シーンでは、総合的なコストをさらに抑えることが可能です。
よくある質問
Q1: 使い始めたばかりなのに、なぜ Qwen3-Max で速度制限が発生するのですか?
Alibaba Cloud Model Studio(百錬)の新規アカウント向け無料枠には限りがあり、新バージョン qwen3-max-2025-09-23 のクォータはさらに低く設定されています(RPM 60, TPM 100,000)。スナップショット版を使用している場合、制限はより厳格になります。
APIYI(apiyi.com)経由で呼び出すことで、アカウントレベルのクォータ制限を回避することをお勧めします。
Q2: 速度制限がかかった場合、どれくらいで回復しますか?
Alibaba Cloud の速度制限はスライディングウィンドウ方式を採用しています:
- RPM 制限:約 60 秒待機で回復
- TPM 制限:約 60 秒待機で回復
- バースト保護:さらに長い待機時間が必要な場合があります
APIYI プラットフォームを利用すれば、頻繁な待機を避け、開発効率を向上させることができます。
Q3: APIYI 経由サービスの安定性はどのように保障されていますか?
APIYI は Alibaba Cloud とチャネル提携関係にあり、プラットフォーム級の大規模なプールクォータ(配分枠)モデルを採用しています:
- マルチチャネル・ロードバランシング
- 自動フェイルオーバー
- 99.9% の可用性保障
個人アカウントのクォータ制限と比較して、プラットフォームレベルのサービスはより安定しており、信頼性も高くなっています。
Q4: APIYI を使用するために、多くのコード修正が必要ですか?
ほとんど必要ありません。APIYI は OpenAI SDK の形式と完全に互換性があるため、以下の 2 箇所を変更するだけです:
# 変更前 (Alibaba Cloud 直結)
client = OpenAI(
api_key="sk-xxx",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
# 変更後 (APIYI 経由)
client = OpenAI(
api_key="your-apiyi-key", # APIYI の API キーに差し替え
base_url="https://api.apiyi.com/v1" # APIYI のアドレスに差し替え
)
モデル名やパラメータ形式は完全に一致しているため、その他の変更は不要です。
Q5: Qwen3-Max 以外に、APIYI はどのようなモデルをサポートしていますか?
APIYI プラットフォームは、200 以上の主要な AI モデルの統合呼び出しをサポートしています。これには以下が含まれます:
- Qwen 全シリーズ: qwen3-max, qwen-plus, qwen-turbo, qwen-vl など
- Claude シリーズ: claude-3-opus, claude-3-sonnet, claude-3-haiku
- GPT シリーズ: gpt-4o, gpt-4-turbo, gpt-3.5-turbo
- その他: Gemini, DeepSeek, Moonshot など
すべてのモデルが統合インターフェースに対応しており、1 つの API キーですべてのモデルを呼び出せます。
Qwen3-Max 速度制限問題の解決策まとめ
解決策の選択決定ツリー
Qwen3-Maxで429エラーが発生した場合
│
├─ 根本的に解決したい → APIYI 中継を使用 (推奨)
│
├─ 軽度の制限 → リクエストの平滑化 + 指数バックオフ
│
├─ 企業規模の大規模な呼び出し → 複数アカウントのローテーション または APIYI エンタープライズ版
│
└─ 非コアタスク → バックアップモデルへのフォールバック
核心ポイントの振り返り
| ポイント | 説明 |
|---|---|
| 制限の原因 | Alibaba Cloud の RPM/TPM/RPS による三重の制限 |
| 最適なソリューション | APIYI 中継サービス、根本的に解決 |
| コストの優位性 | 0.88折(大幅割引)、直結よりも低コスト |
| 移行コスト | base_url と api_key を変更するのみ |
APIYI (apiyi.com) を通じて Qwen3-Max の速度制限問題を迅速に解決し、安定したサービスと魅力的な価格を享受することをお勧めします。
参考文献
-
Alibaba Cloud Rate Limits ドキュメント: 公式の速度制限に関する説明
- リンク:
alibabacloud.com/help/en/model-studio/rate-limit
- リンク:
-
Alibaba Cloud Error Codes ドキュメント: エラーコードの詳細
- リンク:
alibabacloud.com/help/en/model-studio/error-code
- リンク:
-
Qwen3-Max モデルドキュメント: 公式技術仕様
- リンク:
alibabacloud.com/help/en/model-studio/what-is-qwen-llm
- リンク:
テクニカルサポート: Qwen3-Max の使用に関する問題については、APIYI (apiyi.com) までお気軽にお問い合わせください。