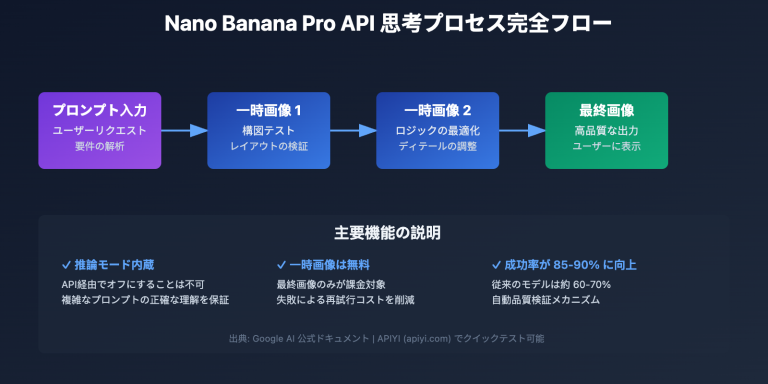
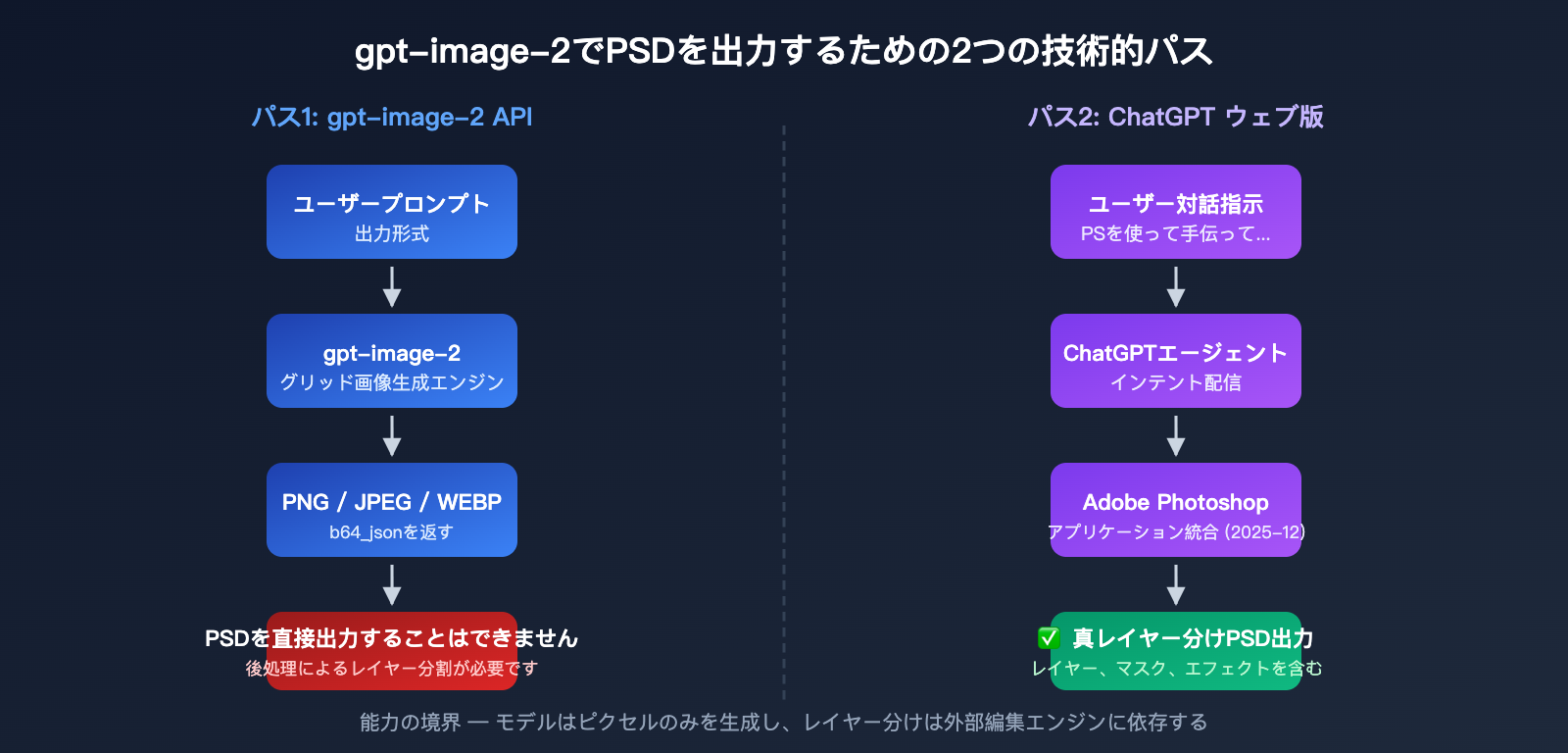
デザイナーや開発者の多くが gpt-image-2 を利用する際、必ずと言っていいほど直面する疑問があります。それは**「直接 PSD レイヤーファイルを出力できるのか?」**という点です。答えは二段構えになります。ChatGPT のウェブ版であれば Adobe Photoshop との統合機能を使ってレイヤー編集が可能ですが、gpt-image-2 API 自体は通常の PNG/JPEG/WEBP 形式しか出力できません。
本記事では、gpt-image-2 による PSD 出力の現実的な境界線を明確にし、実務で使える3つのワークフローを提案します。個人のクリエイターからチーム開発者まで、自身のシナリオに最適な解決策を見つけてください。

gpt-image-2 による PSD 出力の核心的な理解
作業を始める前に、一つの重要な事実を理解しておく必要があります。それは、gpt-image-2 は画像生成モデルであり、画像編集ソフトではないということです。モデル自体には「レイヤーファイル」を生成する能力はなく、PSD 出力には外部ツールの協力が不可欠です。
出力能力の根本的な違い
OpenAI が定義する gpt-image シリーズの出力形式は非常に明確で、モデルは以下の3種類のラスタライズされた画像形式のみをサポートしています。
| 出力形式 | ファイル拡張子 | レイヤーの有無 | 透明チャンネル | 典型的なシナリオ |
|---|---|---|---|---|
| PNG | .png |
❌ なし | ✅ 対応 | デフォルト形式、透過背景が必要な素材向け |
| JPEG | .jpg |
❌ なし | ❌ 非対応 | ファイルサイズが小さく、写真向け |
| WEBP | .webp |
❌ なし | ✅ 対応 | モダンな Web 形式、サイズと品質のバランスが良い |
| PSD | .psd |
✅ あり | ✅ 対応 | API は非対応、後処理が必要 |
🎯 結論: gpt-image-2 API は
output_formatパラメータでpng、jpeg、webpの3つのみを受け付けます。直接 PSD ファイルを出力させるパラメータは存在しません。企業プロジェクトで gpt-image-2 を安定して利用したい場合は、APIYI (apiyi.com) の API 中継サービスを通じて統合することをお勧めします。このプラットフォームは OpenAI の公式インターフェース仕様に準拠しており、上記3形式の全パラメータをサポートしています。
なぜ API は直接 PSD を出力できないのか
PSD は Adobe Photoshop 独自のレイヤー形式であり、レイヤー、マスク、ブレンドモード、調整レイヤーなどの複雑な構造を含んでいます。真の PSD を生成するには、画像生成モデルではなく「画像編集エンジン」が必要です。これが以下の理由となります。
- gpt-image-2 API: 一括でフラット化されたラスター画像を出力するため、「レイヤー」という概念を理解できません。
- ChatGPT ウェブ版: Adobe Photoshop アプリとの統合により、実際に Photoshop がレイヤー処理を行っています。
これらは全く異なるシステムです。以下では、それぞれの仕組みについて詳しく解説します。
gpt-image-2 で PSD を出力する 3 つの比較プラン
「どうしても PSD ファイルが必要だ」というニーズに対し、現在 3 つの実行可能なパスが存在し、それぞれ異なるシーンに適しています。以下の表は、主要な特徴を比較したものです。
| プラン | 実装方法 | PSD の真のレイヤー構造 | 自動化レベル | 対象ユーザー |
|---|---|---|---|---|
| プラン A: ChatGPT + Photoshop 統合 | Web 版で Adobe プラグインを呼び出し | ✅ あり | 半自動 | 個人デザイナー、軽量なニーズ |
| プラン B: API 生成 + Photoshop 手動変換 | API で PNG を出力後、手動で PS にインポート | ⚠️ 擬似レイヤー(単一レイヤー) | 完全手動 | バッチ生成が必要な開発者 |
| プラン C: API 生成 + サードパーティ製レイヤー分割ツール | API で画像生成後、スクリプト/AI ツールで分割 | ✅ あり(アルゴリズム推定) | 完全自動 | エンジニアリングシーン、パイプライン |
🎯 選択のアドバイス: レイヤー分けされた画像をたまに必要とする程度であれば、プラン A が最も簡単です。もし製品に画像生成機能を組み込む必要がある場合は、APIYI (apiyi.com) を通じて gpt-image-2 API を呼び出し、バックエンドでプラン B または C を統合する方が、より制御しやすくおすすめです。
プラン A: ChatGPT Web 版 + Photoshop 統合による PSD 出力
これは OpenAI が 2025 年 12 月に正式リリースした機能です。Adobe と OpenAI の提携により、Adobe Photoshop、Adobe Express、Adobe Acrobat が ChatGPT に統合され、8 億人のユーザーがチャット内で直接プロフェッショナルな画像編集機能を利用できるようになりました。
Photoshop for ChatGPT を有効にする手順
このプロセスの鍵は、ChatGPT が「総合エージェント」として機能することです。ユーザーの自然言語による意図を解釈して gpt-image-2 で画像を生成し、それを Adobe Photoshop アプリに渡してレイヤー処理を行います。
ユーザー入力 → ChatGPT が意図を解析
├─ gpt-image-2 を呼び出して原画を生成
└─ Photoshop アプリを呼び出してレイヤー処理を実行
↓
ダウンロード可能な PSD ファイルを出力
具体的な操作フロー:
- ChatGPT Web 版 (chatgpt.com) にログインし、画像機能が含まれるバージョンであることを確認します。
- 入力ボックスで 「+」 → 「その他」 → 「Adobe Photoshop」 アプリを選択します。
- プロンプトを入力します。例: 「Adobe Photoshop を使って夜景の都市イラストを生成してください。前景の人物、中景の建物、遠景の空をそれぞれ別のレイヤーに分けてください」
- ChatGPT が自動的に gpt-image-2 を呼び出し、ベースとなる画像を生成します。
- 続いて Photoshop アプリを呼び出し、レイヤー分割、調整、合成操作を行います。
- 完了後、チャット内のダウンロードボタンをクリックすると、レイヤー分けされた PSD ファイルを取得できます。
Photoshop for ChatGPT の機能範囲
Adobe 公式のヘルプドキュメントには、統合版でサポートされている主な操作が記載されています。
| 操作タイプ | サポート状況 | 説明 |
|---|---|---|
| 部分的な調整 | ✅ | 画像の特定部分の明るさやコントラストを調整可能 |
| クリエイティブエフェクト | ✅ | Glitch、Glow などの内蔵フィルター |
| 背景のぼかし/置換 | ✅ | Adobe Firefly を利用 |
| レイヤー分離 | ✅ | 被写体、前景、背景をレイヤーに分割 |
| マスクと選択範囲 | ⚠️ 一部 | 複雑な選択範囲はデスクトップ版を推奨 |
| スマートオブジェクト | ❌ | 編集可能なスマートオブジェクトの作成は非対応 |
| 高度な描画モード | ❌ | 基本的な描画モードのみサポート |
🎯 機能のヒント: ChatGPT 内の Photoshop は軽量な編集に適しており、フル機能は依然として Photoshop デスクトップ版にあります。高頻度かつバッチで PSD を生成する必要がある場合は、APIYI (apiyi.com) を経由して gpt-image-2 API で PNG を出力し、それをデスクトップ版 Photoshop に渡すワークフローが最も効率的です。
プラン A の制限事項
ChatGPT + Photoshop の統合は非常にスムーズですが、知っておくべきいくつかの制限があります。
- API 呼び出し不可: Web 版限定の機能であり、独自のプログラムでこのワークフローを再現するための公開 API インターフェースはありません。
- 生成速度が遅い: 1 回の生成+レイヤー処理に通常 60〜120 秒かかります。
- 制御性が低い: レイヤーの数、命名、順序は ChatGPT が独自に決定し、プロンプトによる強制的な指定は受け付けません。
- クォータ制限: 無料ユーザーは 1 日の呼び出し回数に制限があり、Plus ユーザーにも上限があります。
これらの制限により、プラン A は「インスピレーションの探索」や「単発の制作」には適していますが、安定した生産環境には不向きです。

方案 B: gpt-image-2 API + Photoshop 手动转 PSD
如果您的需求是“通过程序批量生成图片,再人工筛选后转为 PSD”,方案 B 是最直接的选择。这条路径将 AI 生成与图层处理过程完全解耦。
gpt-image-2 API 调用极简示例
以下是通过 API 生成图片的最简可运行代码,使用 OpenAI 兼容接口:
import requests
import base64
response = requests.post(
"https://api.apiyi.com/v1/images/generations",
headers={"Authorization": "Bearer YOUR_API_KEY"},
json={
"model": "gpt-image-2",
"prompt": "夜のサイバーパンク都市、ネオンライト、雨の夜のストリート",
"size": "1024x1024",
"quality": "high",
"output_format": "png"
}
)
data = response.json()["data"][0]
image_bytes = base64.b64decode(data["b64_json"])
with open("output.png", "wb") as f:
f.write(image_bytes)
📦 完全な Python サンプル(エラー処理、パラメータ説明付き)
import os
import base64
import requests
from typing import Optional
def generate_image(
prompt: str,
output_path: str,
size: str = "1024x1024",
quality: str = "high",
output_format: str = "png",
background: Optional[str] = None
) -> dict:
"""
gpt-image-2 を呼び出して画像を生成する
Args:
prompt: 画像の説明
output_path: 出力ファイルのパス
size: 1024x1024 / 1024x1536 / 1536x1024
quality: low / medium / high
output_format: png / jpeg / webp
background: transparent / opaque (png/webp のみ)
"""
api_key = os.getenv("APIYI_API_KEY")
if not api_key:
raise ValueError("環境変数 APIYI_API_KEY を設定してください")
payload = {
"model": "gpt-image-2",
"prompt": prompt,
"size": size,
"quality": quality,
"output_format": output_format,
}
if background:
payload["background"] = background
response = requests.post(
"https://api.apiyi.com/v1/images/generations",
headers={
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
},
json=payload,
timeout=180
)
response.raise_for_status()
result = response.json()
image_data = result["data"][0]["b64_json"]
with open(output_path, "wb") as f:
f.write(base64.b64decode(image_data))
return {
"path": output_path,
"usage": result.get("usage", {}),
"size": size
}
if __name__ == "__main__":
info = generate_image(
prompt="未来的な都市のイラスト、製品宣伝ポスター用",
output_path="hero.png",
size="1536x1024",
quality="high",
background="transparent"
)
print(f"生成成功: {info}")
🎯 接続のヒント: APIYI (apiyi.com) を使用して gpt-image-2 を呼び出す際、インターフェースの URL は OpenAI 公式の
api.openai.comをapi.apiyi.comに置き換えるだけで済みます。その他のパラメータは完全に互換性があり、output_formatで png/jpeg/webp の 3 種類の出力をサポートしています。
PNG を Photoshop に読み込み PSD に変換する
API から返された PNG を取得した後、Photoshop で PSD に変換する標準的な手順は以下の通りです:
- Photoshop デスクトップ版で PNG ファイルを開く (
ファイル→開く) - この時点では画像は単一レイヤーであり、通常は「背景」レイヤーとして表示されます
- レイヤーをダブルクリックしてロックを解除し、編集可能なレイヤーに変換します
- 必要に応じて被写体を切り分けます:
- オブジェクト選択ツール を使用して被写体を自動認識
- 生成塗りつぶし を使用して背景を再描画
- アルファチャンネル を使用して透明領域を抽出
- PSD として保存:
ファイル→別名で保存→Photoshop (.PSD)
方案 B の真のレイヤー分割能力
注意点として、PNG から直接 PSD に変換した場合、デフォルトではレイヤーは 1 つだけです。真のマルチレイヤー PSD を得るには、追加のレイヤー分割作業が必要です。一般的な手法は以下の通りです:
| 分割方法 | 操作の複雑さ | 分割品質 |
|---|---|---|
| 手動選択範囲 + レイヤーコピー | 高 | 非常に高い |
| AI 切り抜きツール (Remove.bg 等) | 低 | 中程度 |
| Photoshop オブジェクト選択 + 生成塗りつぶし | 中 | 高 |
| Photoshop ニューラルフィルター深度推定 | 低 | 中程度 (擬似 3D 分割) |
gpt-image-2 で PSD を出力する際のプロンプトエンジニアリングのコツ
方案 B の分割効率を最大化するには、プロンプトの段階で後のレイヤー分割の可能性を考慮する必要があります。以下は実践で検証済みのプロンプトテンプレートです:
[テーマ]: 製品宣伝ポスター、被写体は未来的なスニーカー
[構図の要件]:
- 被写体は中央に配置し、画面の 60% を占めること
- 背景は単色またはシンプルなグラデーションにし、後処理での切り抜きを容易にする
- 被写体と背景の間に明確な色差と被写界深度の分離を持たせる
- 背景に被写体と類似した要素を入れないこと
[出力パラメータ]:
- 解像度: 1536x1024
- 背景: transparent (サポートされている場合)
- スタイル: 商業写真の質感
このようなプロンプトの書き方をすることで、生成された PNG は後のレイヤー分割時に扱いやすくなり、切り抜きツールの認識精度が大幅に向上します。
| プロンプトのキーワード | 分割への影響 |
|---|---|
pure background / solid color background |
切り抜きの縁がより綺麗になる |
clear subject separation |
被写体と背景の境界が明確になる |
centered composition |
被写体の位置を自動検出しやすくなる |
studio lighting |
影の投射を減らし、誤判定を低減する |
no overlapping elements |
レイヤー同士の重なりを避ける |
🎯 効率アップ: APIYI (apiyi.com) の gpt-image-2 に接続する際、システムレベルのプロンプトテンプレートを使用してこれらの制約をプリセットしておけば、チーム全員が生成する画像が後の PSD ワークフローに適したものになります。
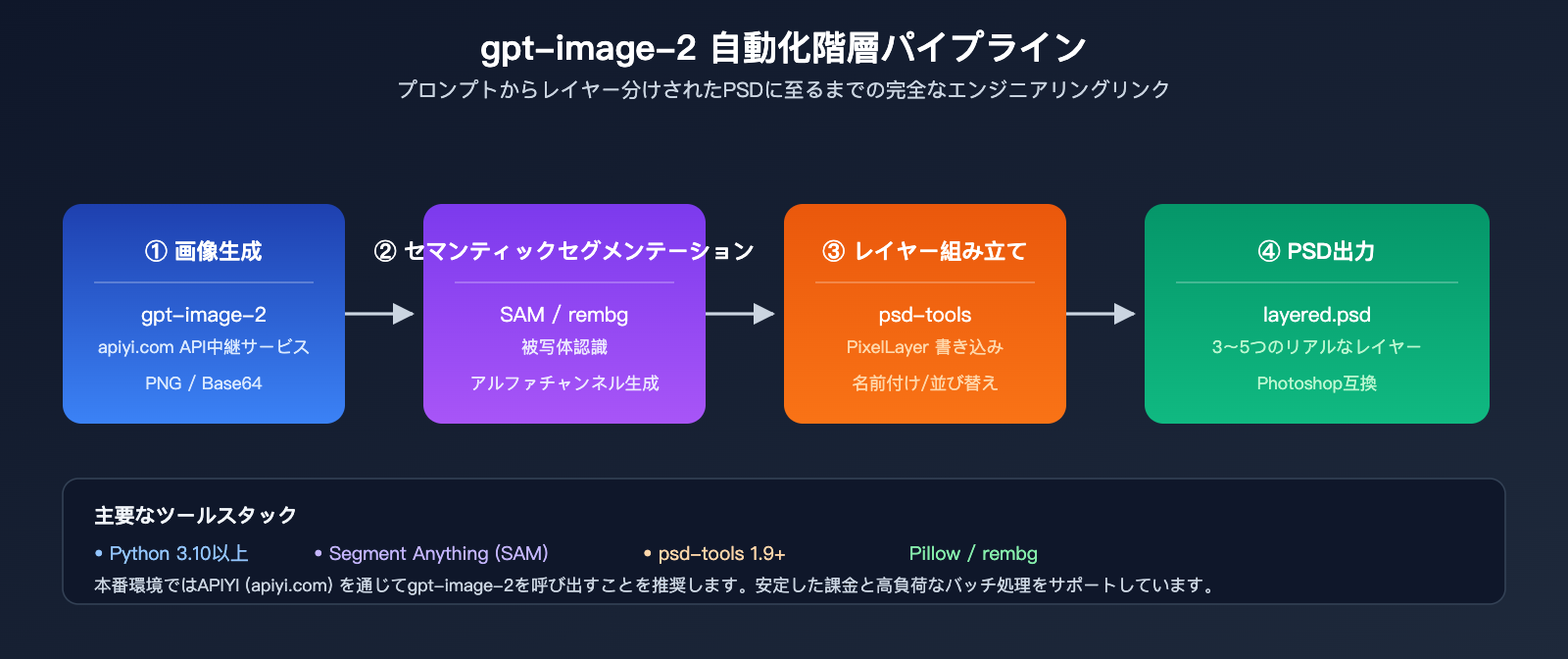
方案 C: API + サードパーティ製分割ツールによる自動 PSD 出力
製品化のシナリオ(EC サイトの素材自動生成、広告パイプラインなど)では、Photoshop を手動で操作するのは現実的ではありません。この場合、自動レイヤー分割ツールの導入が必要です。
自動化ワークフローのアーキテクチャ
[ユーザー入力プロンプト]
↓
[gpt-image-2 API で原画を生成]
↓
[セマンティックセグメンテーションモデルで領域を認識] (例: SAM、Florence)
↓
[アルファチャンネルで各レイヤーを生成]
↓
[psd-tools / photoshop-python-api で PSD に書き込み]
↓
[マルチレイヤー PSD ファイルを出力]
このパイプライン全体をコードで実装できるため、Photoshop クライアントを開く必要はありません。
主要なツール構成
| ツール | 役割 | 推奨度 |
|---|---|---|
| psd-tools (Python) | PSD ファイル構造の読み書き | ⭐⭐⭐⭐⭐ |
| Pillow | 基本的な画像処理 | ⭐⭐⭐⭐⭐ |
| SAM (Segment Anything) | Meta のセマンティックセグメンテーション | ⭐⭐⭐⭐⭐ |
| rembg | ワンクリック切り抜き、背景削除 | ⭐⭐⭐⭐ |
| MiDaS | 深度推定、前後景の分割 | ⭐⭐⭐⭐ |
| Photopea API | オンライン PSD 編集 | ⭐⭐⭐ |
自動レイヤー分割のサンプルコード
from psd_tools import PSDImage
from psd_tools.api.layers import PixelLayer
from PIL import Image
from rembg import remove
original = Image.open("gpt_image_2_output.png")
foreground = remove(original)
background = Image.new("RGBA", original.size, (255, 255, 255, 0))
psd = PSDImage.new(mode="RGBA", size=original.size)
psd.append(PixelLayer.frompil(background, psd, "Background"))
psd.append(PixelLayer.frompil(foreground, psd, "Foreground"))
psd.save("layered_output.psd")
🎯 エンジニアリングの提案: 本番環境では、「gpt-image-2 の呼び出し → 切り抜き → PSD 書き込み」をマイクロサービスとしてカプセル化することをお勧めします。APIYI (apiyi.com) を通じて gpt-image-2 API を呼び出すと、高並列処理と安定した課金に対応しており、画像パイプラインの上流能力として最適です。
方案 C の注意点
- レイヤーの品質はセグメンテーションモデルに依存: SAM は rembg よりも正確ですが、推論コストが高くなります
- PSD の互換性: psd-tools で生成された PSD は主要な Photoshop バージョンで良好に動作しますが、ごく一部の古いバージョンではメタデータが失われる可能性があります
- バッチ処理の計算コスト: すべての画像でセグメンテーションモデルを実行すると、GPU コストが大幅に上昇します
- 混合案が現実的: API での画像出力 + シンプルな背景分離 + 少量の人間による修正、という組み合わせが現実的です
応用: マルチキャラクター分割の実践コード
人物、商品、テキストなど、複数のセマンティックオブジェクトを独立したレイヤーに配置する必要がある場合は、SAM (Segment Anything Model) を組み合わせてより精細な分割を行うことができます:
📦 SAM + psd-tools マルチセマンティックオブジェクト分割の完全サンプル
import torch
import numpy as np
from PIL import Image
from segment_anything import SamPredictor, sam_model_registry
from psd_tools import PSDImage
from psd_tools.api.layers import PixelLayer
def gpt_image_to_layered_psd(image_path: str, output_psd: str, points: list):
"""
gpt-image-2 が出力した PNG を、複数のセマンティックオブジェクトレイヤーを持つ PSD に分割する
Args:
image_path: gpt-image-2 が生成した PNG のパス
output_psd: 出力する PSD ファイルのパス
points: 分割したいオブジェクトの中心点リスト [(x, y, label), ...]
"""
image = Image.open(image_path).convert("RGBA")
image_np = np.array(image)
sam = sam_model_registry["vit_h"](checkpoint="sam_vit_h.pth")
sam.to("cuda" if torch.cuda.is_available() else "cpu")
predictor = SamPredictor(sam)
predictor.set_image(image_np[:, :, :3])
psd = PSDImage.new(mode="RGBA", size=image.size)
for idx, (x, y, label) in enumerate(points):
masks, scores, _ = predictor.predict(
point_coords=np.array([[x, y]]),
point_labels=np.array([1]),
multimask_output=False
)
mask = masks[0]
layer_array = image_np.copy()
layer_array[~mask] = [0, 0, 0, 0]
layer_image = Image.fromarray(layer_array, "RGBA")
psd.append(PixelLayer.frompil(layer_image, psd, label))
background_array = image_np.copy()
background_image = Image.fromarray(background_array, "RGBA")
background_layer = PixelLayer.frompil(background_image, psd, "Background")
psd.insert(0, background_layer)
psd.save(output_psd)
print(f"✅ マルチレイヤー PSD を生成しました: {output_psd}")
if __name__ == "__main__":
gpt_image_to_layered_psd(
image_path="gpt_image_2_poster.png",
output_psd="layered_poster.psd",
points=[
(512, 400, "Subject"),
(200, 600, "ProductLeft"),
(800, 600, "ProductRight"),
]
)
このフローを通じて、gpt-image-2 が生成したポスターを 3〜5 つの真のレイヤーを持つ PSD に分割でき、各レイヤーを Photoshop で個別に編集できるようになります。
エラー処理とトラブルシューティング
エンジニアリングの現場では、gpt-image-2 の呼び出しと後の分割処理の両方でエラーが発生する可能性があります。以下の表は、頻出する問題と対処法をまとめたものです:
| 現象 | 根本原因 | 対処法 |
|---|---|---|
API が invalid output_format を返す |
サポートされていない psd などの値を誤って渡した |
png/jpeg/webp のみを使用する |
b64_json フィールドが空 |
コンテンツ審査によるブロック | プロンプトを最適化し、機密性の高い記述を避ける |
| 切り抜き後の縁にギザギザがある | セグメンテーションモデルの精度不足 | SAM + エッジのフェザー処理(後処理)に変更する |
| Photoshop で PSD が開けない | psd-tools のメタデータ書き込みが不完全 | psd-tools を 1.9+ バージョンにアップグレードする |
| 分割後にレイヤーがずれる | RGBA チャンネルが揃っていない | キャンバスサイズを統一してから書き込む |
| 呼び出し速度が遅い | 高並列によるレート制限 | APIYI (apiyi.com) のマルチチャネルルーティングで分散する |
🎯 安定性のヒント: 本番環境では、API 呼び出し層にリトライとフォールバックのロジックを追加することをお勧めします。APIYI (apiyi.com) を経由するリクエストは、OpenAI のレート制限レスポンスを自動的に識別し、インテリジェントな切り替えをサポートしているため、バッチタスクの失敗率を低減できます。
gpt-image-2 での PSD 出力に関するよくある質問
実際の利用シーンで頻出する疑問について、まとめて回答します。
Q1: gpt-image-2 API は本当に PSD を直接出力できないのですか?
出力できません。 OpenAI の公式ドキュメントでは、output_format パラメータで指定できる値は png、jpeg、webp の3つに限定されています。「API で直接 PSD を出力できる」と謳うサービスは、本質的には自社サーバー側で「案C(レイヤー分解プロセス)」を実行し、その結果を PSD にパッケージ化して返しているに過ぎません。これは gpt-image-2 モデル自体の能力ではありません。
🎯 認識の整理: OpenAI 公式の gpt-image-2 を安定して利用したい場合は、APIYI (apiyi.com) のような OpenAI 公式インターフェース互換の API 中継サービスを利用することをお勧めします。これにより、パラメータの挙動が OpenAI と完全に一致し、中間層による「勝手な改変」を防ぐことができます。
Q2: ChatGPT Web版が出力する PSD は、本当にレイヤー分けされていますか?
はい、本当です。 Web版の裏側では実際の Adobe Photoshop アプリケーションが編集操作を実行しているため、生成された PSD には実際のレイヤー、マスク、エフェクトが含まれています。ただし、レイヤーの数や命名を正確に制御することはできません。多くの場合、3〜5つのレイヤー(背景、被写体、前景、調整レイヤーなど)に分かれます。
Q3: gpt-image-2 と gpt-image-2-all で出力形式に違いはありますか?
わずかな違いがあります。gpt-image-2-all は ChatGPT Web版と同等のリバースチャネルを経由するため、返される b64_json フィールドには data:image/png;base64, というプレフィックスが含まれます。一方、gpt-image-2 は OpenAI Images API に直接接続するため、プレフィックスのない純粋な base64 文字列が返されます。どちらも PSD 出力には対応していません が、プログラム側での文字列処理には注意が必要です。
Q4: 透明背景の PNG さえあれば良い場合、PSD は不要ですか?
多くのケースではその通りです。 gpt-image-2 API は background: "transparent" パラメータをサポートしており、透明背景の PNG を直接生成できます。これは以下のような用途に適しています。
- ECサイトの商品切り抜き
- ロゴ、アイコン、ステッカー素材
- UI 要素
非主体部分も含めて後からレイヤーごとに調整したい場合のみ、PSD ワークフローが必要になります。
Q5: PSD を大量生成する場合のコスト管理はどうすればいいですか?
コストは主に以下の3つの要素で構成されます。
| コスト項目 | gpt-image-2 API 部分 | 後処理部分 |
|---|---|---|
| 単価 | 約 $0.03 – $0.20/枚 | 切り抜き GPU 演算コスト ~$0.001 |
| 時間コスト | 60-120 秒 | 5-30 秒 |
| 安定性 | OpenAI の制限に依存 | 自社リソースで制御可能 |
🎯 コスト削減戦略: 大量生成が必要な場合は、質の高い候補画像に対してのみレイヤー分解を行うことを推奨します。まず gpt-image-2 の低品質パラメータ (
quality=low) でプレビュー画像を素早く生成し、APIYI (apiyi.com) の一括管理画面で消費量を確認してから、満足のいくものだけを high 品質で再生成してレイヤー分解パイプラインに回すのが効率的です。
Q6: gpt-image-2 で既存の PSD ファイルを直接編集できますか?
できません。 gpt-image-2 の画像編集インターフェースは PNG/JPEG/WEBP の入力しか受け付けず、PSD 内部のレイヤー構造を認識できません。「PSD の特定のレイヤーに対して AI で描き直したい」という場合の標準的な手順は以下の通りです。
- Photoshop で対象レイヤーを PNG(アルファ付き)として書き出す
- gpt-image-3 の編集インターフェースとマスク機能を使って描き直す
- 結果を新しいレイヤーとして元の PSD に戻す
gpt-image-2 で PSD を活用する業界別実戦事例
業界によって PSD 出力への要求は大きく異なります。業務シナリオに合わせて最適な手法を選びましょう。以下に3つの典型的なワークフローを紹介します。
事例 1: ECサイトの商品ポスター大量生産
ある越境ECチームでは、毎日300枚以上の商品ポスターを生成しています。要件は「商品主体レイヤー、背景レイヤー、文字レイヤー」に分かれていることで、運営担当者が市場に合わせて素早く文言を差し替えられるようにすることです。
ワークフロー設計:
- 商品アップロード後、運営が管理画面で訴求キーワードを入力
- gpt-image-2 API を呼び出し、メイン画像を生成 (
output_format=png,background=transparent) - rembg を使用して切り抜きの境界を再確認
- psd-tools を使用して3層構造を生成:
- Layer 1: 商品主体(透明背景)
- Layer 2: AI 生成の背景
- Layer 3: プレースホルダー文字レイヤー
- デザイナーは PSD 上で文字を修正するだけで公開可能
効率化のメリット: ポスター1枚あたりの制作時間が30分から2分に短縮され、デザイナーは最終確認のみに集中できます。
🎯 シナリオ選定: このような繰り返し作業が多いシーンでは、APIYI (apiyi.com) の gpt-image-2 インターフェースと企業向け料金プランを組み合わせることで、コストの予測可能性を高め、生産能力を柔軟に拡張できます。
事例 2: ゲーム UI アセットの高速プロトタイプ
ゲーム美術チームはプロトタイプ段階で、ボタン、アイコン、バナーなどの「仮置き用」UIアセットを大量に必要とします。後から精緻化できるよう、PSD 形式が求められます。
ワークフロー設計:
gpt-image-2 でビジュアルのベースを生成
↓
SAM で主体形状を自動分割
↓
複数の PNG (フレーム、アイコン、発光など) を書き出し
↓
psd-tools でレイヤー分けされた PSD に統合
↓
美術担当者が PS で最終調整
| アセットタイプ | gpt-image-2 出力 | 後処理アクション | 最終レイヤー数 |
|---|---|---|---|
| ボタン | 透明 PNG | 状態切り出し(デフォルト/ホバー/押下) | 3 |
| アイコン | 透明 PNG | ハイライト/影の分離 | 2-4 |
| バナー | RGB PNG | 主体/背景/光エフェクトの分解 | 3-5 |
| カード | RGB PNG | 枠線/ベース画像/角の装飾分解 | 3-4 |
事例 3: マーケティングコンテンツの多言語展開
広告運用チームは、1つのメインビジュアルを10言語分に展開する必要があります。文字レイヤーは独立させ、画像レイヤーは固定することが核心的な要件です。
重要な操作:
- gpt-image-2 で「文字なし」のメインビジュアルを生成(プロンプトで
no text、no lettersと明記) - psd-tools を通じて文字レイヤーのプレースホルダーを作成
- その後、文字レイヤーのみを修正して10言語分を出力
このワークフローの利点は、メインビジュアルは一度生成するだけで済み、文字レイヤーは完全に制御可能なため、AI が多言語を生成する際によくあるスペルミスを防げる点です。
🎯 多言語に関する注意: gpt-image-2 は英語の生成には比較的信頼性がありますが、中国語、日本語、韓国語の生成では誤字が発生しがちです。APIYI (apiyi.com) を通じて gpt-image-2 を呼び出す際は、プロンプトで文字の生成を明示的に除外し、PSD の文字レイヤーで一元管理することをお勧めします。
事例 4: 漫画やイラストの絵コンテ補助
イラストレーターは絵コンテ作成時に gpt-image-2 で草案のインスピレーションを得て、Photoshop で仕上げを行うことがよくあります。「AI による着想 + 人手による仕上げ」という混合フローでは、レイヤー構造が重要になります。
典型的なレイヤー構成:
- ラフ層: gpt-image-2 の出力画像をそのまま参照用最下層として保持
- 線画層: ラフを元に線を引く
- 下塗り層: 面で塗りつぶす
- 影層: 暗部を描き込む
- ハイライト層: 明部を強調
- エフェクト層: 装飾要素
操作のポイント:
1. gpt-image-2 で 1024x1536 の縦長構図を出力
2. Photoshop でその画像を Layer 0 (ロックして編集不可) に設定
3. その上に 5-6 個の空レイヤーを作成して描画
4. 完成後、PSD として保存してアーカイブ
このプロセスにより、AI の草案が「使い捨ての画像」ではなく「継続的に創作可能な資産」へと変わります。
gpt-image-2 と他の画像フォーマットの比較
PSD がワークフローの中でどのような位置付けにあるのかをより深く理解するために、他の一般的な出力フォーマットと横並びで比較してみましょう。
| フォーマット | ファイルサイズ | 編集のしやすさ | ソフトウェア互換性 | gpt-image-2 後処理への適合性 |
|---|---|---|---|---|
| PNG | 中 | 低(フラット) | ✅ 非常に良い | ⭐⭐⭐⭐⭐ デフォルトで推奨 |
| JPEG | 小 | 非常に低い | ✅ 非常に良い | ⭐⭐⭐ プレビュー用のみ |
| WEBP | 小 | 低 | ⚠️ Web向け | ⭐⭐⭐ Webシーン向け |
| PSD | 大 | ✅ 非常に高い | ⚠️ Adobeエコシステム | ⭐⭐⭐⭐ 後処理が必要 |
| TIFF | 非常に大 | 中 | ✅ 印刷向け | ⭐⭐ 印刷シーン向け |
| SVG | 小 | ✅ 非常に高い(ベクター) | ✅ Web/印刷 | ❌ gpt-image-2 は非対応 |
この表からわかるように、**PSD の核心的な価値は「編集のしやすさ」**であり、他のフォーマットでは代替が困難です。後から編集する必要がない場合は、通常 PNG の方が適しています。
gpt-image-2 での PSD 出力に関するベストプラクティスまとめ
冒頭の疑問に戻りましょう。gpt-image-2 で PSD ファイルを出力するにはどうすればよいでしょうか? 全体像を整理すると、核心的な結論は以下の3点に集約されます。
- API パスから直接 PSD を出力することはできない: gpt-image-2 API は PNG / JPEG / WEBP の3つのラスター形式のみをサポートしており、これがモデル自体の能力の境界線です。
- ChatGPT Web版では Photoshop を介して真のレイヤー付き PSD を出力可能: Adobe Photoshop アプリがレイヤー処理を引き継ぐため、個人デザイナーの軽量なニーズに適しています。
- エンジニアリングシーンでは「API 生成 + 後処理」の組み合わせが必要: SAM や rembg などのツールで自動的にレイヤーを分割し、psd-tools でファイルに書き出すことで、バッチ処理の自動化を実現します。
| ユーザーの役割 | 推奨プラン | ツール構成 |
|---|---|---|
| 個人デザイナー | プラン A | ChatGPT + Photoshop 統合 |
| 中小チーム | プラン B | gpt-image-2 API + デスクトップ版 Photoshop での手動レイヤー分け |
| 企業開発者 | プラン C | gpt-image-2 API + 自動レイヤー分割パイプライン |
🎯 最終的なアドバイス: まずは ChatGPT Web版で Photoshop 統合を体験し、レイヤー分けのプロセスを理解してから、API パイプラインを構築するかどうかを決定することをお勧めします。エンジニアリングへの統合を検討される場合は、APIYI (apiyi.com) を通じて gpt-image-2 を統一的に接続してください。同プラットフォームは、国内からアクセス可能な OpenAI 互換インターフェースを提供しており、企業レベルの安定性と透明性の高い課金体系を実現しています。
この gpt-image-2 での PSD 出力に関する完全ガイドが、皆様の遠回りを防ぐ一助となれば幸いです。gpt-image-2 での PSD ファイル出力の真の難しさは API そのものではなく、適切なワークフローをいかに選択するかにあります。自身の規模、予算、自動化のニーズに合わせてプラン A/B/C を選択すれば、通常1週間以内に完全なフローを構築できるはずです。
著者: APIYI 技術チーム | apiyi.com — 企業向け AI 大規模言語モデル API 中継サービスプラットフォーム