Récemment, un développeur a posé cette question sur notre groupe : « Est-ce que gpt-image-2 peut générer des images à partir de fichiers CSV ou Excel ? J'ai vu sur TikTok des gens utiliser des modèles d'image pour créer des présentations PPT, je voulais essayer de lire des fichiers. » La réponse est sans appel : non. Le modèle gpt-image-2, publié par OpenAI en avril 2026, n'accepte que des invites textuelles et des images. Il ne lit ni les fichiers CSV/Excel, ni ne génère de fichiers PPTX/PDF.
Cependant, cela ne signifie pas que c'est impossible. Extraire le contenu d'un fichier en texte, capturer des pages en images, puis les transmettre à gpt-image-2 est précisément le flux de travail standard actuel. Cet article clarifie les limites de gpt-image-2 en matière de téléchargement de fichiers et vous propose 5 solutions de contournement pour répondre aux besoins de vos clients.
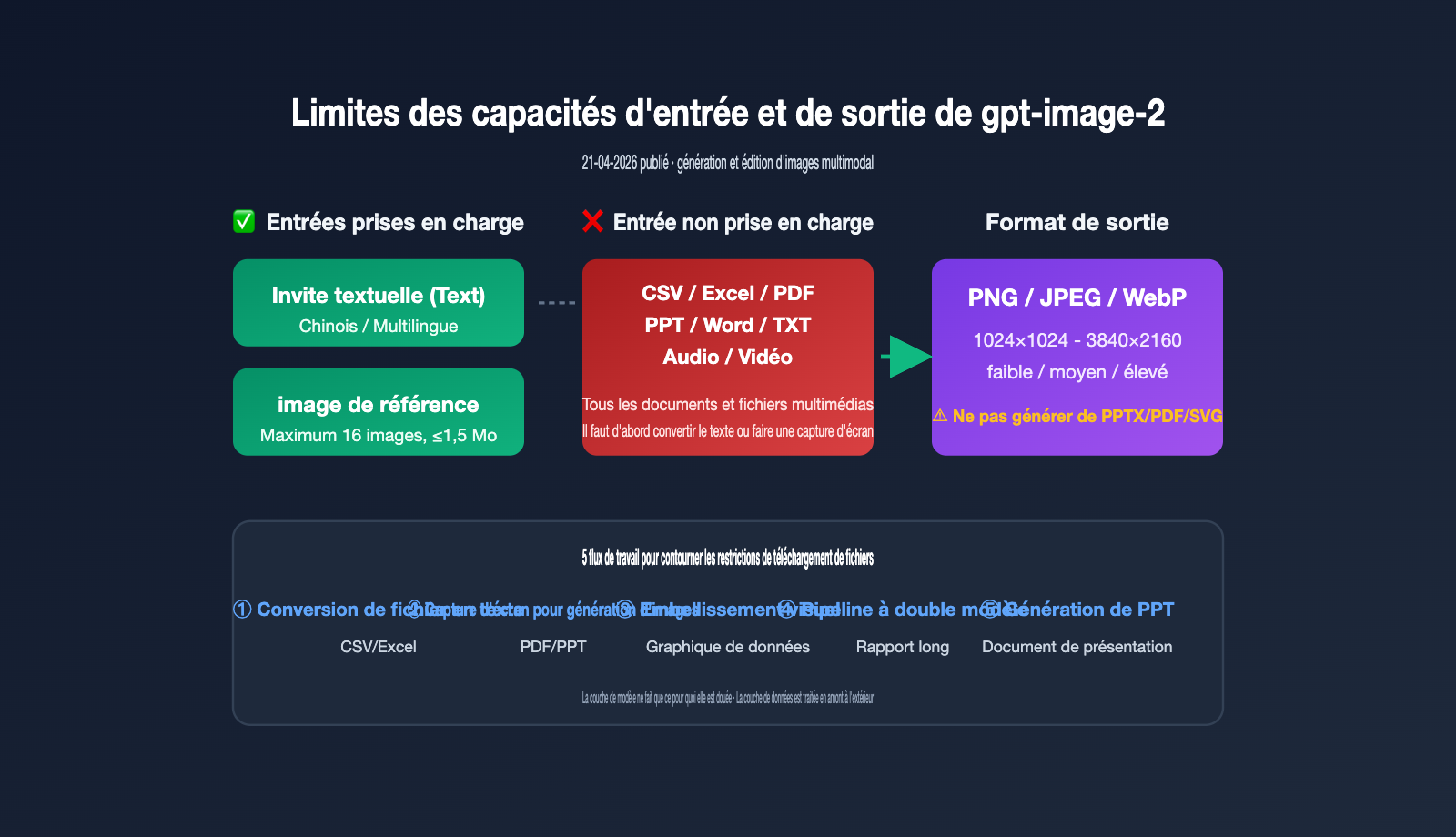
État actuel du support de fichiers dans gpt-image-2 : entrées limitées au texte et aux images
Clarifions d'abord les limites officielles. Selon la documentation développeur d'OpenAI, gpt-image-2 (snapshot gpt-image-2-2026-04-21) est un modèle multimodal natif de génération d'images. Le tableau ci-dessous détaille les types de données supportés.
| Type de modalité | Support en entrée | Support en sortie | Remarques |
|---|---|---|---|
| Texte | ✅ Oui | ❌ Non | Utilisé comme invite, support multilingue |
| Image | ✅ Oui | ✅ Oui | Utilisé pour l'édition/référence, sortie PNG/JPEG/WebP |
| Audio | ❌ Non | ❌ Non | Non pertinent pour la génération d'images |
| Vidéo | ❌ Non | ❌ Non | Non pertinent pour la génération d'images |
| Documents (CSV/Excel/PDF/Word/PPT) | ❌ Non | ❌ Non | Pas de téléchargement direct ni de sortie fichier |
En résumé, gpt-image-2 n'est pas un "cerveau universel" comme GPT-4 ; il est spécialisé dans la génération et l'édition d'images. OpenAI n'a pas prévu de canal d'analyse pour les fichiers CSV/Excel/PDF. Si vous envoyez un binaire Excel, l'API renverra une erreur 400. Si votre projet nécessite une invocation stable et à haut débit de gpt-image-2, nous vous recommandons de passer par une plateforme de service proxy API comme APIYI (apiyi.com), qui documente les validations d'entrée et les limites de paramètres pour éviter les erreurs courantes.
🎯 Concept clé : La limite de
gpt-image-2est « Texte + Image → Image ». Ne le considérez pas comme un agent tout-terrain. Les besoins liés aux fichiers doivent être gérés par des outils tiers, tandis que la couche de service proxy (comme APIYI) assure la stabilité des appels et la couche métier gère le prétraitement des données.
Pourquoi la "génération de PPT" et la "génération d'images à partir de fichiers" sont deux choses distinctes
Beaucoup de clients confondent « génération automatique de PPT par IA » et « génération d'images à partir de fichiers ». En réalité, ce sont deux flux de travail différents. Les cas d'automatisation de PPT vus sur les réseaux sociaux sont presque toujours des pipelines multi-étapes : un grand modèle de langage extrait le texte, un modèle d'image génère les illustrations, et un programme assemble le tout en PPTX.
L'étape de génération d'images utilise généralement un modèle comme gpt-image-2. Il se contente de traiter l'invite textuelle et l'image de référence reçues, sans savoir si la source est un fichier Excel ou Notion. Une fois ce point compris, les 5 solutions de contournement deviennent logiques.
Améliorations par rapport à la génération précédente (gpt-image-1)
Beaucoup d'utilisateurs demandent : « Puisqu'on ne peut toujours pas télécharger de fichiers, qu'est-ce qui change avec gpt-image-2 ? » La différence est cruciale et détermine si la stratégie de "capture d'écran vers image" est viable. La nouvelle version apporte des améliorations majeures en rendu de texte, gestion des images de référence et capacités de raisonnement.
| Dimension | gpt-image-1 | gpt-image-2 |
|---|---|---|
| Nombre max. d'images de référence | 4 | 16 (recommandé ≤ 4 pour de meilleurs résultats) |
| Rendu de texte | Anglais correct, erreurs fréquentes en CJK | Précision accrue pour le chinois, japonais, coréen, etc. |
| Capacité de raisonnement | Aucune | Mode "réflexion" intégré pour les mises en page complexes |
| Date limite de connaissances | Début 2024 | Décembre 2025 |
| Résolution de sortie | Max 1024×1024 | Max 3840×2160 (4K) |
En somme, si vos tentatives avec gpt-image-1 pour "modifier le style d'une capture d'écran" n'étaient pas satisfaisantes, gpt-image-2 vaut largement le détour, surtout pour les affiches ou les diapositives PPT nécessitant un rendu de texte précis.
5 flux de travail pour générer des images à partir de fichiers avec gpt-image-2
Ces 5 solutions répondent à des sources de données et des cas d'usage variés. Le choix dépendra du type de fichier, du format de sortie souhaité et du degré d'automatisation. Nous les avons classées de la plus légère à la plus complexe.
Solution 1 : Conversion du fichier en invite textuelle, envoyée directement à gpt-image-2
Idéal pour les données structurées comme les fichiers CSV, Excel, JSON ou le texte brut. Le processus consiste à utiliser un script (pandas, openpyxl) pour lire le fichier, extraire les en-têtes, les lignes clés et les indicateurs statistiques pour en faire une description en langage naturel, puis à appeler /v1/images/generations avec ce prompt. Par exemple, résumer des données de vente en : "Graphique en barres des ventes du T1 2026 pour trois régions : Est 12 millions, Nord 9,8 millions, Sud 7,6 millions, style professionnel sombre".
L'avantage est la simplicité, sans besoin d'entrée d'image. L'inconvénient est que l'espace dans l'invite est limité. Bien que gpt-image-2 gère bien la précision numérique, il n'est pas parfait ; il faut donc spécifier explicitement les valeurs de chaque barre, sinon le modèle risque de redistribuer les hauteurs selon une logique purement visuelle.
Solution 2 : Capture d'écran de page de fichier comme image de référence
Adapté aux PDF, PPT, rapports web, etc., soit tout ce qui possède déjà une mise en page. Convertissez la page cible en PNG (via l'aperçu macOS, pdftoppm, Puppeteer, etc.), puis téléchargez-la via le point de terminaison /v1/images/edits en tant que paramètre image, accompagné d'une invite décrivant les modifications, par exemple : "Conserver la mise en page, remplacer les titres anglais par du français, transformer le graphique en barres en style Apple".
Dans sa version 2026, gpt-image-2 accepte jusqu'à 16 images de référence, mais les recommandations officielles et communautaires suggèrent d'utiliser 1 image de référence principale + 1 ou 2 images de style. Au-delà, l'attention du modèle est diluée. Il est conseillé de limiter chaque image à 1,5 Mo pour éviter une hausse significative de la consommation de jetons en entrée.
Solution 3 : Visualisation préalable des données, puis embellissement par gpt-image-2
Idéal pour les scénarios où vous recherchez à la fois la précision et l'esthétique. Commencez par générer une version de base du graphique avec matplotlib, ECharts ou Excel, puis exportez-la en PNG. Utilisez cette image comme entrée pour gpt-image-2 avec une invite du type : "Conserver les points de données et les valeurs, appliquer un style sombre, néon et infographique".
C'est actuellement la méthode la plus fiable pour combiner graphiques de données et IA. Les valeurs brutes sont garanties par la bibliothèque de traçage, tandis que le style visuel est sublimé par gpt-image-2. Pour automatiser ce processus à grande échelle, je recommande d'utiliser APIYI apiyi.com pour invoquer gpt-image-2 ; leur service proxy API gère le routage des comptes en amont pour les scénarios à haute concurrence (5000 RPM), idéal pour des milliers d'images par jour.
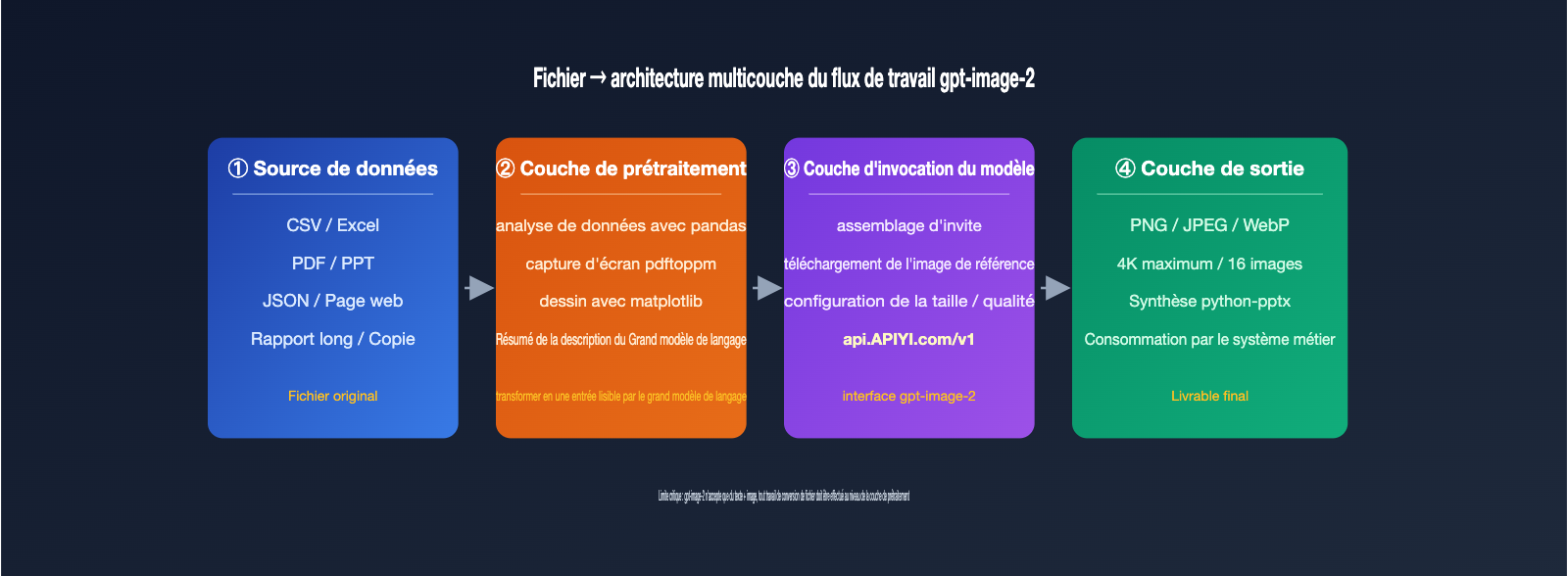
Solution 4 : Pipeline à double modèle LLM + gpt-image-2
Adapté aux fichiers complexes nécessitant une compréhension sémantique, comme les rapports longs, les contrats ou les textes marketing. Utilisez d'abord GPT-4 ou Claude 4 pour analyser le fichier, extraire 4 à 8 descriptions visuelles, puis appelez gpt-image-2 en boucle pour générer les images correspondantes.
La clé ici est de découpler la "compréhension sémantique" de la "génération d'images". Le LLM définit "ce qui doit être dessiné", et gpt-image-2 s'occupe de "générer l'image selon cette invite". L'ensemble du pipeline peut être géré avec une seule clé API sur APIYI apiyi.com, évitant ainsi la gestion fastidieuse des SDK et des clés.
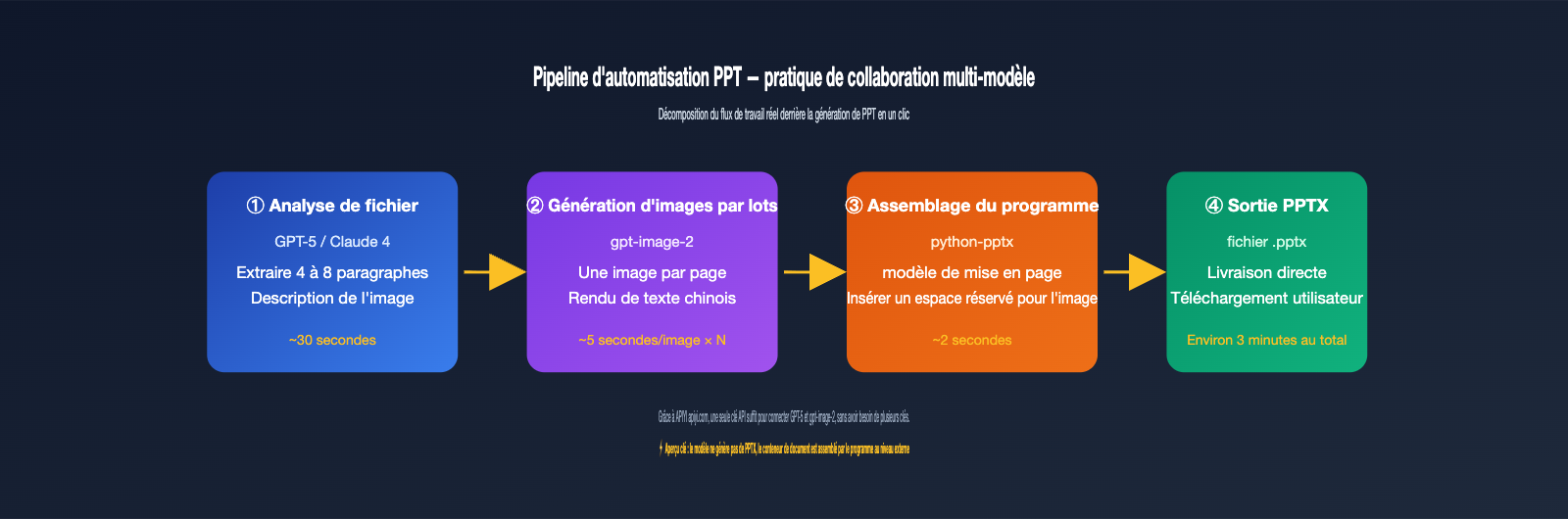
Solution 5 : Synthèse programmatique de PPT/affiches après génération par lots
C'est le secret derrière les outils de création de "PPT en un clic". Le modèle ne génère pas de fichier PPTX directement, mais il peut générer chaque image de page. Ensuite, utilisez python-pptx ou PptxGenJS pour insérer ces images dans les emplacements correspondants d'un modèle PPT.
En résumé : un PPT est essentiellement une présentation composée de plusieurs images. gpt-image-2 résout le problème de l'"image", et python-pptx celui du "conteneur de document". Une approche courante : images 4K haute qualité pour la couverture, qualité moyenne (1536×1024) pour le corps, et basse qualité pour les transitions, en ajustant le paramètre quality pour optimiser les coûts. Un PPT de 20 pages nécessite environ 20 à 30 appels, ce qui prend quelques minutes via le service proxy API à 5000 RPM.
| Solution | Type de fichier | Complexité | Qualité | Cas d'usage |
|---|---|---|---|---|
| 1. Fichier vers texte | CSV/Excel/JSON | Faible | Moyenne | Graphiques simples, illustrations |
| 2. Capture d'écran | PDF/PPT/Web | Faible | Moyenne-Haute | Réécriture de mise en page |
| 3. Pré-rendu visuel | CSV/Excel | Moyenne | Haute | Embellissement de données |
| 4. LLM + gpt-image-2 | Rapports/Textes | Moyenne-Haute | Haute | Cartes de contenu, tutoriels |
| 5. Synthèse PPT | Tout type | Haute | Haute | Automatisation de documents |
Exemple de code pour l'invocation d'API : comment transformer le contenu d'un fichier en entrée pour gpt-image-2
Passer du concept à la pratique est bien plus parlant avec du code. Voici un exemple minimal en Python, prêt à l'emploi, qui convertit un tableau Excel en une invite textuelle, puis appelle gpt-image-2 pour générer le graphique correspondant. Nous utilisons APIYI (apiyi.com) comme passerelle unifiée ; il vous suffit de remplacer base_url, le reste de la syntaxe du SDK étant identique à l'original.
from openai import OpenAI
import pandas as pd
import base64
client = OpenAI(
api_key="your-apiyi-key",
base_url="https://api.apiyi.com/v1"
)
# Lecture du fichier Excel
df = pd.read_excel("sales_q1.xlsx")
summary = df.groupby("region")["sales"].sum().to_dict()
# Création de l'invite pour le modèle
prompt_text = (
f"Générer un histogramme des ventes régionales pour le T1 2026, "
f"données : {summary}, "
f"style business sombre, titre blanc pur, étiquettes de données clairement visibles."
)
# Invocation du modèle
resp = client.images.generate(
model="gpt-image-2",
prompt=prompt_text,
size="1536x1024",
quality="high"
)
img_b64 = resp.data[0].b64_json
# Sauvegarde de l'image
with open("sales_chart.png", "wb") as f:
f.write(base64.b64decode(img_b64))
La logique est limpide : la couche métier analyse l'Excel pour en faire une description textuelle, et le modèle ne reçoit que du texte. Pour du "image vers image" (deuxième scénario), remplacez simplement client.images.generate par client.images.edit et transmettez l'image via image=open("page.png", "rb").
| Paramètre | Plage de valeurs | Description |
|---|---|---|
model |
gpt-image-2 / gpt-image-2-mini |
La version mini est plus rapide et moins coûteuse |
size |
1024×1024 / 1536×1024 / 1024×1536 / personnalisé | Côté max ≤ 3840px, doit être divisible par 16 |
quality |
low / medium / high / auto | Une haute qualité prend plus de temps et consomme plus de jetons |
n |
1–4 | Nombre d'images par génération, pour du lot, utilisez une boucle |
response_format |
png(par défaut)/ jpeg / webp | gpt-image-2 ne prend pas en charge la sortie PDF/PPTX |
🎯 Conseil technique : Pour tester ce flux rapidement, nous vous recommandons de créer un compte sur APIYI (apiyi.com). En basculant votre
base_urlvershttps://api.apiyi.com/v1, vous pourrez utiliser une interface unifiée pour appelergpt-image-2,GPT-5et la sérieClaude 4, vous évitant ainsi la contrainte de devoir intégrer chaque fournisseur séparément.

Les 4 erreurs les plus fréquentes et comment les éviter
Une fois les 5 solutions bien comprises, vous rencontrerez certainement quelques subtilités lors de la mise en œuvre. Nous avons compilé les 4 types de problèmes les plus fréquemment posés par nos utilisateurs.
Erreur n°1 : Insérer un CSV encodé en base64 dans l'invite
Certains ont eu une "idée brillante" : lire un fichier CSV, le convertir en chaîne base64 et l'insérer dans l'invite, pensant que le modèle le décoderait tout seul. Cette approche ne fonctionne absolument pas. gpt-image-2 n'exécute pas de code et ne traite pas les chaînes comme des données ; il interprétera simplement la chaîne base64 comme des caractères sans signification, produisant un résultat illisible. La bonne méthode consiste à analyser le CSV au niveau de votre couche métier pour en extraire une description textuelle (voir la solution n°1).
Erreur n°2 : Attendre de gpt-image-2 qu'il "dessine un tableau identique à Excel"
Le modèle excelle dans la cohérence visuelle et la stylisation, mais la reproduction au pixel près est une autre paire de manches. Si vous avez besoin d'un tableau strict, nous recommandons une stratégie combinée : utilisez ECharts ou matplotlib pour générer une version précise (solution n°3), puis demandez à gpt-image-2 d'en améliorer l'esthétique. Espérer qu'une simple invite permette au modèle de dessiner précisément 100 lignes de données est, pour l'instant, irréaliste.
Erreur n°3 : Vouloir des fichiers de sortie au format vectoriel SVG ou PDF
gpt-image-2 ne génère que des formats bitmap : PNG, JPEG et WebP. Il ne prend pas en charge les formats vectoriels comme SVG, PDF ou AI. Si vous avez besoin de vecteurs, utilisez Stable Diffusion avec vectorizer.ai, ou demandez directement à GPT-5 de générer le code SVG. Vérifiez le format de sortie avant de choisir votre modèle pour éviter de devoir refaire le travail.
Erreur n°4 : Envoyer systématiquement la même image de référence, faisant exploser la consommation de jetons
gpt-image-2 traite chaque image d'entrée avec une haute fidélité. Même si votre invite ne contient que des ajustements mineurs, chaque requête recalcule les jetons d'entrée. Nous vous conseillons de mettre en cache les images de référence côté client, ou d'utiliser previous_response_id pour des modifications conversationnelles (via l'API Responses), afin de réutiliser le contexte de l'image précédente.
Un détail important à noter : même si vous ne demandez qu'une vignette de 256×256, si votre image de référence est en 4K, les jetons d'entrée seront facturés sur la base du 4K. Compressez localement vos images de référence avec un bord long de 1024 pixels avant de les envoyer. Cela permet d'économiser plus de 60 % des jetons d'entrée, un point de contrôle des coûts souvent négligé dans les tâches à grand volume.
| Symptôme d'erreur | Cause profonde | Solution recommandée |
|---|---|---|
| 400 invalid_request_error | Envoi d'un fichier non image (CSV/Excel) | Convertir le fichier en texte ou capture d'écran |
| Caractères illisibles | Chaîne base64 utilisée comme invite | Utiliser une description en langage naturel |
| Données de tableau inexactes | Utilisation d'une invite pour dessiner un tableau précis | Utiliser la solution n°3 (pré-rendu visuel) |
| Besoin d'une sortie SVG | Le modèle ne supporte pas le format vectoriel | Utiliser GPT-5 pour générer du code SVG |
| Consommation de jetons excessive | Envoi répété d'images de référence haute résolution | Compresser en dessous de 1,5 Mo et activer le cache |
FAQ : Questions fréquentes
Q1 : gpt-image-2 est-il vraiment incapable d'importer des PDF ?
Il ne peut pas importer directement de PDF. Cependant, vous pouvez utiliser pdftoppm pour convertir chaque page en PNG, puis les envoyer en tant qu'images. Si vous avez besoin de "comprendre le contenu d'un PDF pour générer une image", nous suggérons d'utiliser d'abord GPT-5 pour extraire le texte du PDF, puis de transmettre cette description à gpt-image-2. Cette combinaison fonctionne parfaitement avec une seule clé API sur APIYI (apiyi.com).
Q2 : Est-il sûr d'envoyer des fichiers contenant des données sensibles au modèle ?
L'étape de conversion du fichier en texte s'effectue sur votre propre serveur ; seul le texte final de l'invite est envoyé au modèle. Vous pouvez donc anonymiser les données lors de la conversion. Si vous utilisez un service proxy API, les interfaces d'APIYI (apiyi.com) garantissent explicitement de ne pas stocker vos invites ni les contenus générés, offrant une conformité plus contrôlée qu'un accès direct via un proxy externe.
Q3 : Les outils de "génération de PPT en un clic" sur TikTok utilisent-ils gpt-image-2 ?
Parfois oui, parfois non. La logique est généralement la suivante : un LLM rédige le contenu → un modèle d'image (gpt-image-2 / Nano Banana Pro / Flux) crée les illustrations → le backend utilise python-pptx pour l'assemblage. gpt-image-2 est le plus performant pour le rendu de texte, particulièrement en chinois, ce qui le rend idéal pour les illustrations de diapositives PPT.
Q4 : Pourquoi certains disent qu'ils peuvent importer des fichiers Excel ?
Il s'agit en réalité de captures d'écran d'Excel envoyées en tant qu'images. Fondamentalement, le modèle reçoit une image et ne comprend pas la structure réelle du fichier Excel. Si les chiffres sur votre capture d'écran sont flous, le modèle ne pourra que redessiner ce flou.
Q5 : Faut-il choisir gpt-image-2 ou gpt-image-2-mini ?
La version mini est plus rapide et moins coûteuse, idéale pour les brouillons en masse et les vignettes. Utilisez la version standard pour les supports de communication officiels. Les limitations d'entrée sont identiques pour les deux versions (aucun ne supporte les documents) ; il suffit de changer l'ID du modèle dans le paramètre model, sans modifier votre code SDK.
Résumé
Le modèle gpt-image-2 ne prend pas en charge le téléchargement direct de fichiers CSV, Excel ou PPT, et ne génère pas non plus de fichiers PPTX ou PDF. Il s'agit d'une limite intrinsèque aux capacités du modèle, et non d'un mauvais paramétrage de votre part. Une fois cette limite intégrée, il suffit de prétraiter le contenu de vos fichiers — en les convertissant en texte, en captures d'écran ou en visualisations avant de les embellir — pour répondre à la grande majorité des besoins qui semblent nécessiter une entrée de fichier. Les outils de création de PPT en un clic, de conversion d'Excel en affiches ou de changement de style de PDF que l'on voit sur TikTok reposent essentiellement sur ce type de pipeline multi-étapes. Une fois que l'on distingue clairement le rôle de l'inférence du modèle de celui du traitement des données, le projet devient tout à fait réalisable.
La règle d'or pour réussir est simple : la couche modèle ne fait que ce qu'elle sait faire de mieux, tandis que la couche données est préparée en amont. Si vous souhaitez mettre en place un pipeline complet, nous vous recommandons d'utiliser APIYI (apiyi.com) pour accéder à la fois à GPT-5 (pour la compréhension textuelle) et à gpt-image-2 (pour la génération d'images). Vous utilisez une seule clé API pour tout le processus, et la capacité de haute concurrence de 5000 RPM permet de traiter vos tâches par lots de manière fluide, sans avoir à gérer plusieurs clés API ou SDK pour différents modèles.
À propos de l'auteur : L'équipe APIYI se spécialise dans l'agrégation de modèles et les infrastructures d'inférence à haute concurrence, traitant quotidiennement de nombreuses demandes sur les API de génération d'images. Cet article est basé sur la documentation officielle d'OpenAI et sur les retours de nos clients. Pour en savoir plus sur les solutions d'intégration de gpt-image-2, visitez APIYI sur apiyi.com.