Model Bahasa Besar (LLM) open-source domestik mencapai titik penting pada tahun 2026. Model unggulan Moonshot AI, Kimi K2.6, kini resmi tersedia dalam bentuk open-source. Pada benchmark SWE-Bench Pro, model ini meraih skor 58,6, melampaui GPT-5.4 (57,7) dan Claude Opus 4,6 (53,4), menjadikannya model yang paling andal dalam menyelesaikan issue GitHub secara nyata.
Artikel ini akan mengupas tuntas proses integrasi API Kimi K2.6, membahas arsitektur 1T MoE, jendela konteks 256K, kemampuan Function Call, serta prefix caching. Kami juga menyertakan contoh kode lengkap agar Anda dapat menyelesaikan integrasi API dalam waktu kurang dari 5 menit. Selain itu, dibandingkan dengan harga resmi, APIYI (apiyi.com) menawarkan harga $0,60 untuk input dan $2,40 untuk output per 1 juta token melalui kanal resmi Huawei Cloud, atau sekitar 60% lebih hemat dibandingkan harga standar ¥6,5 / ¥27.
Nilai Utama: Setelah membaca artikel ini, Anda akan menguasai cara pemanggilan API Kimi K2.6, pengaturan alat Function Call, teknik optimalisasi prefix caching, serta memahami kapan waktu terbaik untuk menggunakan K2.6 agar mendapatkan efisiensi biaya paling optimal.

Poin Utama API Kimi K2.6
Kimi K2.6 adalah model open-source unggulan generasi terbaru yang dirilis oleh Moonshot AI pada April 2026. Dengan tetap mengusung arsitektur MoE seri Kimi K2, model ini membawa peningkatan signifikan dalam hal pengodean, jendela konteks yang panjang, dan pemanggilan alat (tool calling). Tabel di bawah ini merangkum spesifikasi inti yang paling diperhatikan oleh pengembang:
| Poin | Spesifikasi Detail | Nilai Aktual |
|---|---|---|
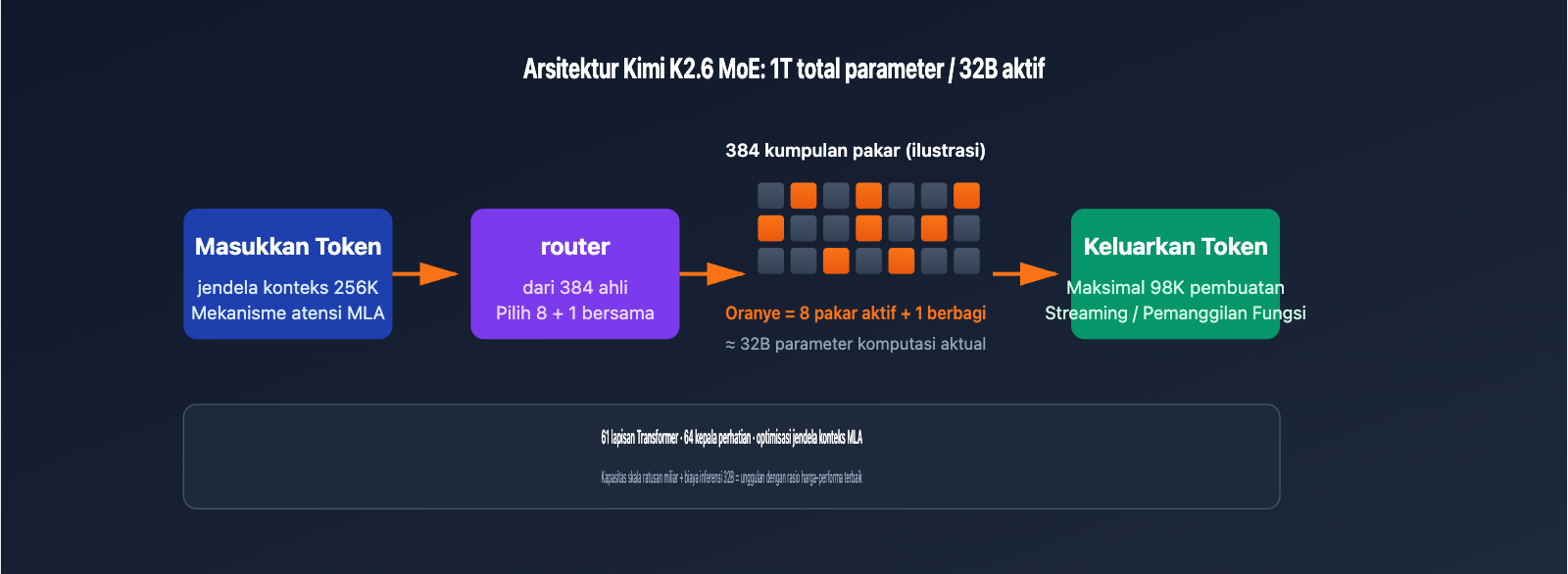
| Arsitektur MoE | 1T total parameter / 32B aktif / 384 pakar (8 dipilih+1 bersama) | Kemampuan skala ratusan miliar, biaya inferensi setara model 32B |
| Jendela Konteks | 256K token (tepatnya 262.144) | Memproses repositori kode panjang atau dokumen hukum sekaligus |
| Output Maksimal | Output sekali jalan hingga 98.304 token | Mendukung skenario refactoring kode panjang dan pembuatan dokumen |
| Kemampuan Multimodal | Encoder visual MoonViT 400M terintegrasi | Mendukung input gambar dan video secara native |
| Orkestrasi Agen | Agent Swarm mendukung 300 sub-agen / 4.000 langkah koordinasi | Mampu menangani alur pengembangan multi-langkah yang kompleks |
| Lisensi Open-Source | Modified MIT License | Ramah untuk penggunaan komersial, tanpa batasan berarti |
Penjelasan Mendalam Kemampuan API Kimi K2.6
Dibandingkan generasi sebelumnya (K2.5), K2.6 mengalami peningkatan lompatan di tiga dimensi: Pertama, skor SWE-Bench Pro menembus 58,6, untuk pertama kalinya melampaui GPT-5.4 dan Claude Opus 4,6 dalam tugas penyelesaian issue repositori open-source secara nyata; Kedua, jumlah sub-agen Agent Swarm meningkat dari 100 menjadi 300, dengan langkah koordinasi yang naik dari 1.500 menjadi 4.000, sehingga mampu menangani tugas pengembangan dengan alur yang lebih panjang; Ketiga, jendela konteks 256K terbuka untuk seluruh seri, dan dengan teknologi Multi-head Latent Attention (MLA), biaya penggunaan VRAM dan latensi untuk inferensi konteks panjang berhasil ditekan secara signifikan.
🎯 Saran Teknis: Dalam pengembangan praktis, kami menyarankan untuk memanggil Kimi K2.6 langsung melalui platform APIYI (apiyi.com). Platform ini terhubung ke model resmi melalui kanal Huawei Cloud, antarmukanya sepenuhnya kompatibel dengan OpenAI SDK, sehingga Anda dapat beralih model tanpa perlu mengubah kode yang ada.
Penjelasan Mendalam Arsitektur Teknis API Kimi K2.6
Memahami arsitektur dasar Kimi K2.6 akan membantu Anda membuat pilihan yang tepat dalam berbagai skenario bisnis. Desain arsitekturnya menyeimbangkan antara "kapasitas parameter skala ratusan miliar" dan "biaya inferensi skala puluhan miliar".
Mekanisme Aktivasi Jarang (Sparse Activation) MoE
Kimi K2.6 menggunakan arsitektur Mixture of Experts (MoE) dengan 1 triliun parameter, yang terdiri dari 384 jaringan pakar (expert networks). Saat inferensi untuk setiap token, hanya 8 pakar (ditambah 1 pakar bersama) yang diaktifkan, artinya hanya 32B parameter yang dilibatkan dalam perhitungan. Desain ini memungkinkan model memiliki keluasan pengetahuan layaknya model dengan ratusan miliar parameter, namun tetap mempertahankan kecepatan inferensi level 32B, menjadikannya salah satu model unggulan dengan biaya pemanggilan API paling optimal saat ini.
Optimasi Konteks Panjang
| Komponen Teknis | Fungsi | Konfigurasi K2.6 |
|---|---|---|
| Multi-head Latent Attention (MLA) | Mengurangi volume KV cache untuk inferensi konteks panjang | 64 head perhatian |
| Jumlah Layer Jaringan | Menentukan kedalaman inferensi model | 61 Layer Transformer |
| Jendela Konteks | Jumlah token maksimum dalam satu input | 262,144 token (256K) |
| Encoding Posisi | Teknologi kunci untuk mendukung urutan super panjang | Pelatihan khusus konteks panjang |
| Cache Prefiks | Menggunakan cache untuk prompt berulang, mengurangi biaya | Biaya input berkurang ~75% setelah hit |
💡 Wawasan Arsitektur: Dalam skenario dialog multi-ronde atau system prompt tetap, cache prefiks dapat secara signifikan mengurangi biaya input. Disarankan untuk menjaga system prompt tetap stabil di lingkungan produksi guna memaksimalkan rasio hit cache.
Perbandingan Tolok Ukur Performa API Kimi K2.6
Menentukan apakah sebuah model layak diintegrasikan memerlukan tolok ukur sebagai bukti paling objektif. Berikut adalah perbandingan performa antara Kimi K2.6, GPT-5.4, dan Claude Opus 4.6 pada lima tolok ukur otoritatif.
Kemampuan Pemrograman dan Rekayasa Perangkat Lunak
| Tolok Ukur | Kimi K2.6 | GPT-5.4 | Claude Opus 4.6 | Model Unggulan |
|---|---|---|---|---|
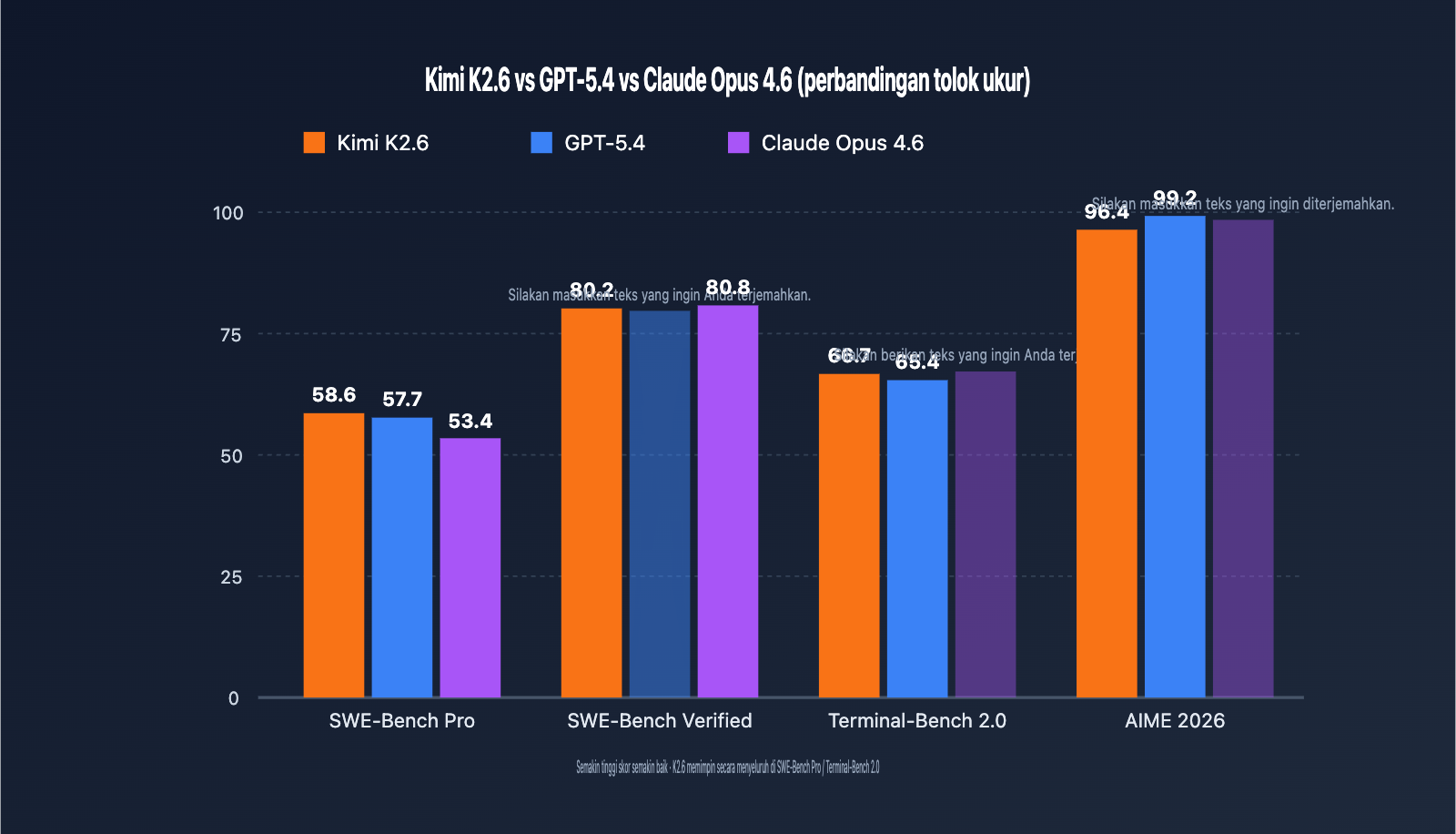
| SWE-Bench Pro | 58.6 | 57.7 | 53.4 | Kimi K2.6 |
| SWE-Bench Verified | 80.2 | – | 80.8 | Claude Opus 4.6 |
| Terminal-Bench 2.0 | 66.7 | 65.4 | – | Kimi K2.6 |
| HLE (with tools) | 54.0 | – | 53.0 | Kimi K2.6 |
| AIME 2026 | 96.4 | 99.2 | – | GPT-5.4 |
| GPQA-Diamond | 90.5 | – | – | – |
Interpretasi Penting:
- SWE-Bench Pro mengukur kemampuan penyelesaian end-to-end untuk isu GitHub asli. K2.6 meraih skor 58.6, menandai pertama kalinya model sumber terbuka mengungguli model tertutup unggulan pada tolok ukur ini, yang berarti tugas pemeliharaan kode dan perbaikan bug dapat diprioritaskan menggunakan K2.6.
- SWE-Bench Verified adalah versi yang lebih sederhana, Claude Opus 4.6 sedikit unggul (80.8 vs 80.2), menunjukkan bahwa Claude masih memiliki keunggulan pada tugas-tugas kode standar.
- Terminal-Bench 2.0 menguji kemampuan pengaturan perintah terminal, di mana skor 66.7 dari K2.6 memimpin, cocok untuk skenario DevOps dan otomasi运维.
- AIME / HMMT dan penalaran matematika murni tetap menjadi keunggulan GPT-5.4, sehingga untuk skenario matematika murni tetap disarankan mempertahankan opsi GPT-5.4.
🎯 Saran Skenario: Disarankan untuk melakukan pengujian A/B lintas model pada tugas yang berbeda — prioritas K2.6 untuk pemeliharaan kode, GPT-5.4 untuk penalaran matematika, dan Anda bisa tetap menyimpan opsi Claude untuk penulisan kreatif panjang.
Memulai Cepat API Kimi K2.6
Selanjutnya, kita akan mendemonstrasikan cara memanggil Kimi K2.6 melalui kode lengkap. Rangkaian API Kimi sepenuhnya kompatibel dengan protokol SDK OpenAI. Jika Anda sudah memiliki kode pemanggilan OpenAI, Anda cukup mengganti base_url dan model.
Contoh Minimalis (Python)
from openai import OpenAI
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="kimi-k2.6",
messages=[
{"role": "system", "content": "Anda adalah insinyur Python senior."},
{"role": "user", "content": "Gunakan asyncio untuk mengimplementasikan kumpulan permintaan konkuren (concurrency pool) dengan batas maksimum 10."}
],
temperature=0.3,
max_tokens=2048
)
print(response.choices[0].message.content)
Lihat contoh pemanggilan streaming asinkron lengkap (termasuk penanganan error)
import asyncio
from openai import AsyncOpenAI
from openai import APIError, RateLimitError
client = AsyncOpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1",
max_retries=3,
timeout=120.0
)
async def call_kimi_k26_stream(prompt: str, system: str = "") -> str:
"""Memanggil Kimi K2.6 secara streaming dan mencetak token secara real-time"""
messages = []
if system:
messages.append({"role": "system", "content": system})
messages.append({"role": "user", "content": prompt})
full_response = ""
try:
stream = await client.chat.completions.create(
model="kimi-k2.6",
messages=messages,
stream=True,
temperature=0.3,
max_tokens=8192
)
async for chunk in stream:
if chunk.choices[0].delta.content:
token = chunk.choices[0].delta.content
print(token, end="", flush=True)
full_response += token
except RateLimitError:
print("\n[Mengalami limit rate, disarankan untuk mengonfigurasi retry atau meningkatkan paket]")
raise
except APIError as e:
print(f"\n[Error API: {e}]")
raise
return full_response
async def main():
result = await call_kimi_k26_stream(
prompt="Jelaskan bagaimana arsitektur MoE dapat mengurangi biaya inferensi",
system="Anda adalah ahli arsitektur AI, jawablah dengan singkat dan profesional"
)
print(f"\n\n[Jumlah token total: {len(result)}]")
if __name__ == "__main__":
asyncio.run(main())
🚀 Memulai dengan Cepat: Setelah mendapatkan kunci API melalui platform APIYI apiyi.com, cukup atur
base_urlkehttps://api.apiyi.com/v1. Semua SDK ekosistem OpenAI (Python/Node.js/Go) dapat langsung digunakan, integrasi selesai dalam 5 menit.
Pemanggilan Node.js / TypeScript
import OpenAI from "openai";
const client = new OpenAI({
apiKey: process.env.APIYI_KEY,
baseURL: "https://api.apiyi.com/v1",
});
const completion = await client.chat.completions.create({
model: "kimi-k2.6",
messages: [
{ role: "user", content: "Tulis fungsi debounce menggunakan TypeScript dengan dukungan generik" }
],
temperature: 0.2,
});
console.log(completion.choices[0].message.content);
Pemanggilan Langsung cURL
curl https://api.apiyi.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer YOUR_APIYI_KEY" \
-d '{
"model": "kimi-k2.6",
"messages": [
{"role": "user", "content": "Halo, Kimi K2.6"}
],
"max_tokens": 1024
}'
Praktik Pemanggilan Alat (Function Call)
Kemampuan Function Call dari K2.6 adalah peningkatan signifikan dibandingkan seri K2, dengan kinerja luar biasa di Berkeley Function-Calling Leaderboard. Berikut adalah contoh lengkap "cek cuaca" untuk menunjukkan alur orkestrasi alat.
Definisi dan Pemanggilan Alat
from openai import OpenAI
import json
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
tools = [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "Mencari cuaca real-time di kota tertentu",
"parameters": {
"type": "object",
"properties": {
"city": {"type": "string", "description": "Nama kota"},
"unit": {"type": "string", "enum": ["celsius", "fahrenheit"]}
},
"required": ["city"]
}
}
}
]
def get_weather(city: str, unit: str = "celsius") -> dict:
"""Simulasi antarmuka pencarian cuaca"""
return {"city": city, "temperature": 22, "unit": unit, "condition": "cerah"}
messages = [{"role": "user", "content": "Bantu saya cek cuaca di Beijing dan Shanghai"}]
response = client.chat.completions.create(
model="kimi-k2.6",
messages=messages,
tools=tools,
tool_choice="auto"
)
assistant_msg = response.choices[0].message
messages.append(assistant_msg)
if assistant_msg.tool_calls:
for tool_call in assistant_msg.tool_calls:
args = json.loads(tool_call.function.arguments)
result = get_weather(**args)
messages.append({
"role": "tool",
"tool_call_id": tool_call.id,
"content": json.dumps(result, ensure_ascii=False)
})
final_response = client.chat.completions.create(
model="kimi-k2.6",
messages=messages
)
print(final_response.choices[0].message.content)
Penulisan Awal (Partial Mode)
K2.6 mendukung "penulisan awal" ala OpenAI, di mana kita memasukkan awal pesan ke dalam pesan asisten, dan model akan melanjutkan pembuatan dari posisi tersebut. Sering digunakan untuk memaksa output JSON atau batasan format tertentu:
response = client.chat.completions.create(
model="kimi-k2.6",
messages=[
{"role": "user", "content": "Kembalikan data PDB Beijing (2023) dalam format JSON"},
{"role": "assistant", "content": '{"city": "Beijing", "year": 2023, "gdp":'}
],
max_tokens=200
)
print(response.choices[0].message.content)
💰 Optimalisasi Biaya: Untuk skenario dengan petunjuk sistem panjang (seperti RAG, Agen), harga input turun menjadi sekitar 25% setelah cache awalan terkena hit, cocok untuk dialog multi-putaran dan bisnis dengan templat tetap frekuensi tinggi. Disarankan untuk mengaktifkan pemantauan cache tingkat akun di platform apiyi.com untuk melihat rasio hit secara real-time.
Praktik Kemampuan Lanjut API Kimi K2.6
Di luar Function Call, K2.6 juga menyediakan tiga kemampuan lanjut: orkestrasi multi-agen Agent Swarm, jendela konteks 256K, dan multimodalitas asli, yang membentuk keunggulan kompetitif dalam skenario pengodean, otomatisasi R&D, dan analisis dokumen.
Orkestrasi Multi-Agen Agent Swarm
Salah satu kemampuan paling diferensiatif dari K2.6 adalah Agent Swarm — satu tugas dapat menjadwalkan hingga 300 sub-agen paralel untuk melakukan 4.000 langkah tindakan koordinasi. Fitur ini membuat K2.6 unggul dalam skenario seperti refaktorisasi basis kode besar, analisis referensi silang multi-dokumen, dan alur kerja R&D yang kompleks.
Mode Penjadwalan Sub-Agen
Agent Swarm K2.6 mendukung tiga mode orkestrasi tipikal:
| Mode Orkestrasi | Skenario yang Berlaku | Jumlah Sub-Agen | Langkah Koordinasi |
|---|---|---|---|
| Paralel Tunggal | Ringkasan batch dokumen, tinjauan kode | 10-50 | < 200 |
| Penjadwalan Bertingkat | Refaktorisasi kode multi-modul | 50-150 | 500-1500 |
| Kolaborasi Mendalam | Alur kerja Agen lintas repositori | 150-300 | 1500-4000 |
Contoh Penjadwalan Agen Sederhana
Berikut mendemonstrasikan cara menggunakan K2.6 untuk mengoordinasikan 5 sub-agen paralel dalam menyelesaikan tugas tinjauan kode:
from openai import OpenAI
import asyncio
import json
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
async def review_module(module_name: str, code: str) -> dict:
"""Sub-agen tinjauan modul tunggal"""
response = client.chat.completions.create(
model="kimi-k2.6",
messages=[
{"role": "system", "content": "Anda adalah ahli tinjauan kode, fokus pada keamanan dan performa."},
{"role": "user", "content": f"Tinjau modul {module_name}:\n{code}"}
],
temperature=0.2
)
return {
"module": module_name,
"review": response.choices[0].message.content
}
async def parallel_review(modules: dict) -> list:
"""Menjadwalkan beberapa sub-agen secara paralel"""
tasks = [review_module(name, code) for name, code in modules.items()]
return await asyncio.gather(*tasks)
# Alur utama: Mengoordinasikan 5 sub-agen untuk meninjau 5 modul
modules = {
"auth.py": "...",
"database.py": "...",
"api_routes.py": "...",
"cache.py": "...",
"logger.py": "..."
}
results = asyncio.run(parallel_review(modules))
for r in results:
print(f"[{r['module']}] {r['review'][:100]}...")
Praktik Terbaik Utama Agent Swarm
- Kontrol Granularitas Tugas: Satu sub-agen menangani 5K-20K token, terlalu besar akan menyebabkan overhead koordinasi;
- Isolasi Error: Setiap sub-agen memiliki try/except independen untuk menghindari kegagalan beruntun;
- Agregasi Hasil: Siapkan "agen utama" untuk mengumpulkan hasil sub-agen secara terpadu dan melakukan verifikasi silang;
- Manajemen Timeout: Timeout sub-agen tunggal 60-120 detik, total timeout agen utama 10-30 menit;
- Kontrol Laju: Gunakan semaphore untuk membatasi konkurensi maksimum guna menghindari limit rate API.
Praktik Konteks Panjang 256K
Jendela konteks 256K (262.144 token) adalah keunggulan utama K2.6. Ini setara dengan sekitar 400.000-500.000 karakter dalam bahasa Mandarin, yang dapat menampung basis kode besar atau seluruh buku teknis sekaligus.
Penggunaan Tipikal Konteks Panjang
import os
from openai import OpenAI
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
def load_repo_files(repo_path: str, extensions=(".py", ".ts", ".md")) -> str:
"""Memuat semua file dengan akhiran tertentu di dalam repositori"""
contents = []
for root, _, files in os.walk(repo_path):
for f in files:
if f.endswith(extensions):
full_path = os.path.join(root, f)
with open(full_path, "r", encoding="utf-8") as fp:
contents.append(f"## {full_path}\n```\n{fp.read()}\n```")
return "\n\n".join(contents)
repo_text = load_repo_files("./my_project")
print(f"Estimasi total token repositori: {len(repo_text) // 2}") # 1 token Mandarin ≈ 2 karakter
response = client.chat.completions.create(
model="kimi-k2.6",
messages=[
{"role": "system", "content": "Anda adalah arsitek senior, ahli dalam analisis basis kode besar."},
{"role": "user", "content": f"Analisis arsitektur proyek berikut, berikan saran refaktorisasi:\n{repo_text}"}
],
temperature=0.3,
max_tokens=8192
)
print(response.choices[0].message.content)
Trade-off Biaya dan Performa Konteks Panjang
| Skala Input | Estimasi Biaya/Per-panggilan | Latensi Token Pertama | Skenario yang Berlaku |
|---|---|---|---|
| 8K | $0.005 | 1-2 detik | Analisis satu file |
| 32K | $0.019 | 3-5 detik | Tinjauan tingkat modul |
| 100K | $0.06 | 8-15 detik | Analisis repositori menengah |
| 200K | $0.12 | 18-30 detik | Repositori besar / Seluruh buku |
| 256K (Penuh) | $0.154 | 25-40 detik | Skenario dokumen ekstrem panjang |
🎯 Tips Optimalisasi Dokumen Panjang: Untuk skenario konteks panjang, disarankan untuk membagi petunjuk sistem menjadi dua bagian: "instruksi tetap + dokumen dinamis". Setelah bagian tetap terkena hit cache awalan, pemanggilan berikutnya hanya dikenakan biaya berdasarkan bagian yang berubah. Pengujian menunjukkan bahwa dalam skenario RAG, total biaya 100 pemanggilan dapat berkurang 40%-60%.
Pemanggilan Visual Multimodal
K2.6 memiliki enkoder visual MoonViT 400M parameter yang terintegrasi, yang secara asli mendukung input gambar dan video. Antarmuka multimodal juga kompatibel dengan protokol OpenAI:
from openai import OpenAI
import base64
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
def encode_image(image_path: str) -> str:
with open(image_path, "rb") as f:
return base64.b64encode(f.read()).decode("utf-8")
image_b64 = encode_image("./architecture_diagram.png")
response = client.chat.completions.create(
model="kimi-k2.6",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "Analisis diagram arsitektur ini, identifikasi potensi kegagalan titik tunggal (single point of failure)"},
{
"type": "image_url",
"image_url": {"url": f"data:image/png;base64,{image_b64}"}
}
]
}
],
max_tokens=2048
)
print(response.choices[0].message.content)
Skenario yang Berlaku untuk Multimodal:
- Analisis diagram arsitektur/diagram alur dan saran modifikasi
- Tinjauan draf desain UI dan pembuatan kode
- Pemahaman tangkapan layar dokumen teknis
- Ekstraksi konten grafik data
- Identifikasi visual pemeriksaan kualitas industri
Migrasi API Kimi K2.6 dan Optimalisasi Performa
Jika proyek Anda saat ini menggunakan OpenAI, K2.5, atau model dari vendor lain, proses migrasi ke K2.6 biasanya hanya memerlukan perubahan 3-5 baris kode. Selain itu, strategi konkurensi dan caching yang tepat dapat memaksimalkan keuntungan biaya dari K2.6.
Migrasi dari Seri OpenAI GPT
# Kode asal (OpenAI)
client = OpenAI(api_key="OPENAI_KEY")
response = client.chat.completions.create(
model="gpt-5.4",
messages=[...]
)
# Migrasi ke K2.6 (hanya ubah base_url dan model)
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="kimi-k2.6",
messages=[...]
)
Migrasi dari Kimi K2 / K2.5
Seri K2 memiliki ID model yang berbeda, namun protokol API yang digunakan sepenuhnya sama:
| ID Model Lama | ID Model Baru | Jadwal Penghentian |
|---|---|---|
kimi-k2 |
kimi-k2.6 |
25-05-2026 |
kimi-k2.5 |
kimi-k2.6 |
Masih didukung, disarankan upgrade |
moonshot-v1-128k |
kimi-k2.6 |
Dalam tahun 2026 |
Pemeriksaan Kompatibilitas Sebelum Migrasi
Sebelum melakukan migrasi, disarankan untuk memeriksa poin-poin berikut:
- Batas max_tokens: K2.6 mendukung output hingga 98K dalam sekali jalan. Jika kode Anda menggunakan batasan 8K, Anda bisa melonggarkannya.
- Rentang temperature: Untuk K2.6, disarankan menggunakan rentang 0,1-0,7. Nilai yang terlalu tinggi dapat memengaruhi kualitas kode.
- stop sequences: K2.6 mendukung karakter berhenti (stop sequences) kustom, sama seperti OpenAI.
- Perilaku tool_choice: Mode
autopada K2.6 lebih condong untuk melakukan pemanggilan alat (tool). Jika butuh perilaku lebih konservatif, ubah kenoneatau tentukan secara eksplisit. - Protokol streaming: Format SSE sepenuhnya sama, sehingga tidak perlu ada perubahan pada kode sisi depan (front-end).
Praktik Terbaik Optimalisasi Performa
Optimalisasi Kecepatan Pemanggilan
| Item Optimalisasi | Metode Implementasi | Peningkatan yang Diharapkan |
|---|---|---|
| Request Konkuren | Gunakan AsyncOpenAI + asyncio.gather | Throughput 3-10x lipat |
| Streaming Output | Aktifkan stream=True | Latensi awal berkurang 70% |
| Caching Prefiks | Gunakan system prompt tetap | Biaya input turun 75% |
| max_tokens yang wajar | Atur batas sesuai kebutuhan tugas | Latensi per permintaan turun 30% |
| Kontrol Temperatur | Untuk tugas kode temp=0.2 | Output lebih stabil |
Saran Penanganan Error
from openai import OpenAI, APIError, RateLimitError, APITimeoutError
import time
def call_with_retry(prompt: str, max_retries: int = 3):
client = OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com/v1",
timeout=120.0
)
for attempt in range(max_retries):
try:
return client.chat.completions.create(
model="kimi-k2.6",
messages=[{"role": "user", "content": prompt}]
)
except RateLimitError:
wait = 2 ** attempt
print(f"Limit terlampaui, mencoba lagi dalam {wait} detik")
time.sleep(wait)
except APITimeoutError:
print(f"Waktu habis, percobaan ke-{attempt+1}")
except APIError as e:
print(f"Kesalahan API: {e}")
if attempt == max_retries - 1:
raise
raise Exception("Mencapai jumlah percobaan maksimum")
Keunggulan Harga dan Pilihan Skenario API Kimi K2.6
Harga adalah faktor krusial dalam memilih model. Tabel berikut membandingkan harga resmi Kimi K2.6 di berbagai kanal (satuan: per 1 juta tokens):
| Kanal Pemanggilan | Harga Input | Harga Output | Catatan |
|---|---|---|---|
| Platform Resmi Kimi | ¥6,5 (~$0,95) | ¥27 (~$4,00) | Penagihan resmi domestik |
| APIYI (Reseller Huawei Cloud) | $0,60 | $2,40 | Sekitar 60% dari harga resmi |
| OpenRouter (Parasail) | $0,60 | $2,40+ | Kanal non-resmi |
| GPT-5.4 (Referensi) | $2,50 | $15,00 | 4-6x lebih mahal dari K2.6 |
| Claude Opus 4.6 (Referensi) | $15,00 | $75,00 | 25x lebih mahal dari K2.6 |
Estimasi Biaya Aktual
Sebagai contoh skenario asisten pengkodean sehari-hari (asumsi sesi tunggal: 5K tokens input / 2K tokens output), dengan 100 ribu panggilan per bulan:
| Model | Biaya Input Bulanan | Biaya Output Bulanan | Total Biaya Bulanan |
|---|---|---|---|
| Kimi K2.6 (APIYI) | $300 | $480 | $780 |
| GPT-5.4 | $1.250 | $3.000 | $4.250 |
| Claude Opus 4.6 | $7.500 | $15.000 | $22.500 |
Kesimpulan: Dalam skenario coding, Agen, dan konteks panjang, performa K2.6 setara dengan GPT-5.4/Claude Opus 4.6, namun dengan biaya hanya 1/5 hingga 1/30. Ini sangat ramah bagi tim kecil dan pengembang individu yang sensitif terhadap anggaran.
🎯 Saran Pemilihan: Memilih model bergantung pada skenario aplikasi dan kebutuhan kualitas Anda. Kami menyarankan untuk melakukan pengujian aktual melalui platform APIYI (apiyi.com) agar Anda dapat membuat pilihan terbaik. Platform ini mendukung antarmuka terpadu untuk berbagai model utama seperti Kimi K2.6, GPT-5.4, dan Claude Opus 4.6, sehingga memudahkan perbandingan dan peralihan model secara cepat.
Rekomendasi Skenario Aplikasi
Tingkat kecocokan K2.6 bervariasi tergantung skenario bisnis. Tabel berikut memberikan saran pilihan yang jelas:
| Skenario Aplikasi | Rekomendasi | Alasan |
|---|---|---|
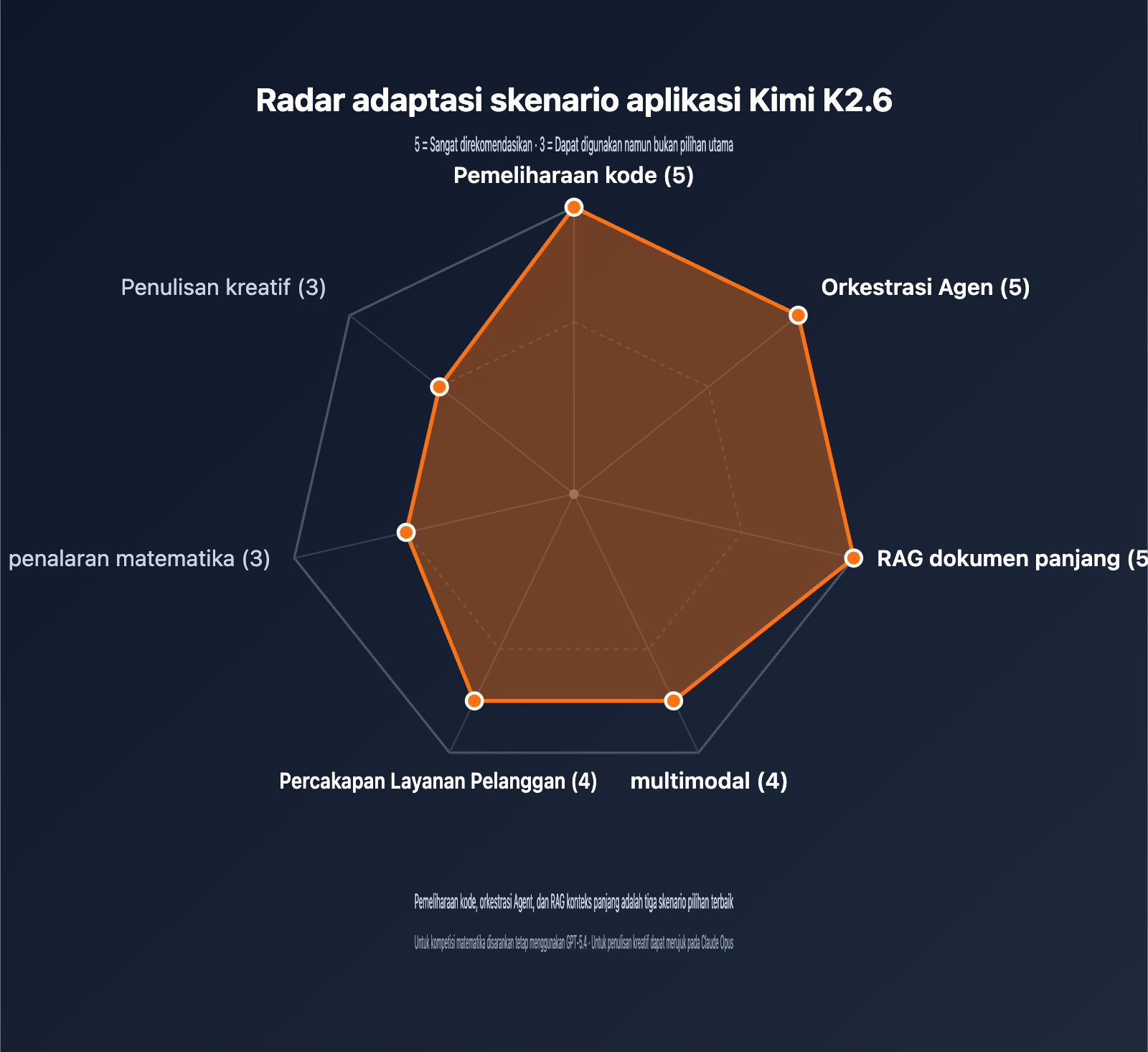
| Pemeliharaan & Refactoring Kode | ⭐⭐⭐⭐⭐ | Peringkat 1 SWE-Bench Pro, 256K mampu memuat repositori besar |
| Orkestrasi Agen | ⭐⭐⭐⭐⭐ | 300 sub-agen / 4000 langkah, mendukung alur pengembangan kompleks |
| Analisis Dokumen Panjang | ⭐⭐⭐⭐⭐ | 256K konteks + optimalisasi MLA, biaya dokumen panjang terkontrol |
| Pemahaman Multimodal | ⭐⭐⭐⭐ | MoonViT bawaan, input gambar dan video siap pakai |
| Layanan Pelanggan & Percakapan | ⭐⭐⭐⭐ | Function Call luar biasa, caching prefiks menekan biaya |
| Penalaran Matematika Murni | ⭐⭐⭐ | Nilai AIME 96,4 cukup baik, namun GPT-5.4 lebih unggul |
| Penulisan Kreatif | ⭐⭐⭐ | Ekspresi bahasa Mandarin alami, namun tugas penyesuaian gaya sedikit di bawah Claude |
Pertanyaan Umum
Q1: Apa perbedaan utama antara API Kimi K2.6 dengan K2.5 / K2?
K2.6 mendapatkan peningkatan signifikan di tiga aspek: 1) SWE-Bench Pro melonjak dari 53 poin di K2.5 menjadi 58,6, melampaui GPT-5.4 dan Claude Opus 4.6 untuk pertama kalinya; 2) Sub-agen Agent Swarm meningkat dari 100 menjadi 300, dengan langkah koordinasi yang naik dari 1500 menjadi 4000; 3) Dukungan jendela konteks 256K dibuka untuk seluruh seri (varian awal K2 hanya mendukung 128K). Pengumuman resmi Kimi menunjukkan bahwa versi awal K2 akan dihentikan pada 25 Mei 2026. Proyek baru harus langsung menggunakan K2.6 dengan ID model kimi-k2.6 yang sepenuhnya kompatibel dengan OpenAI SDK.
Q2: Apakah API Kimi K2.6 sepenuhnya kompatibel dengan OpenAI SDK?
Ya. Saat dipanggil melalui APIYI atau saluran serupa, protokol API sepenuhnya kompatibel dengan antarmuka chat completions OpenAI, termasuk parameter seperti streaming, tools (Function Call), tool_choice, temperature, top_p, dan max_tokens. SDK populer seperti Python, Node.js, atau Go hanya perlu mengubah parameter base_url dan model untuk beralih. Perlu dicatat bahwa output token maksimum K2.6 adalah 98.304, jauh lebih tinggi dibandingkan GPT-5 yang hanya 16K.
Q3: Bagaimana dengan latensi dan biaya jendela konteks 256K K2.6 saat digunakan secara nyata?
K2.6 mengoptimalkan volume KV cache untuk konteks panjang secara signifikan melalui Multi-head Latent Attention (MLA). Berdasarkan pengujian pada skenario input 100K, latensi token pertama berkisar antara 8-15 detik (tergantung beban server), diikuti dengan pengembalian streaming untuk token berikutnya. Dari sisi biaya, input 256K dihitung sebesar $0,60/1M, atau sekitar $0,15 per pemanggilan. Jika terdapat percakapan multi-putaran dengan system prompt yang sama, biaya input turun sekitar 25% setelah prefix cache hit. Sebelum produksi, disarankan untuk melakukan pengujian end-to-end pada prompt khas Anda dan pantau log konsumsi token untuk mengoptimalkan biaya.
Q4: Apa perbedaan Function Call K2.6 dibandingkan dengan pemanggilan alat di GPT-5 / Claude?
Secara antarmuka, protokolnya identik (protokol tools ala OpenAI), namun kemampuan internalnya memiliki fokus berbeda: 1) K2.6 mendukung 300 sub-agen secara bersamaan, memberikan keunggulan bawaan dalam mengatur banyak alat sekaligus; 2) K2.6 berada di peringkat teratas pada Berkeley Function-Calling Leaderboard, mendekati level GPT-5; 3) K2.6 mendukung penulisan lanjutan awalan (Partial Mode) yang dapat memaksa format output JSON, sehingga mengurangi tingkat kegagalan saat pemanggilan alat. Untuk alur kerja agen yang kompleks, K2.6 adalah pilihan dengan rasio harga-performa terbaik.
Q5: Apakah panggilan K2.6 melalui APIYI resmi? Apakah keamanan data terjamin?
APIYI terhubung ke model resmi Kimi melalui saluran resmi Huawei Cloud, yang merupakan kanal resmi yang patuh terhadap regulasi. Bobot model dan hasil inferensi sama dengan yang resmi. Transmisi data menggunakan enkripsi HTTPS dan platform tidak menyimpan konten permintaan. Untuk pengguna tingkat perusahaan, kami menyediakan fitur keamanan seperti sub-akun independen, klasifikasi hak akses kunci API, dan batas konsumsi. Jika Anda memiliki persyaratan ketat mengenai kepatuhan data, silakan tinjau kebijakan rinci di halaman penjelasan kepatuhan apiyi.com.
Q6: K2.6 cocok untuk jenis proyek apa? Kapan harus memilih GPT-5.4 atau Claude?
Skenario prioritas K2.6: Asisten kode, tugas berbasis SWE, RAG konteks panjang, pengaturan alur kerja agen, dan proyek skala kecil-menengah yang sensitif terhadap biaya. Skenario prioritas GPT-5.4: Kompetisi matematika tingkat tinggi (AIME/HMMT) dan tugas penelitian yang memerlukan kedalaman penalaran tingkat atas. Skenario prioritas Claude Opus 4.6: Penulisan kreatif panjang, pembuatan dokumen kontrak/hukum dengan kepatuhan format yang ketat. Disarankan untuk merancang desain antarmuka yang memungkinkan perpindahan antar model agar Anda dapat melakukan pengujian perbandingan sebelum menentukan model produksi.
Kesimpulan
Kimi K2.6 adalah tonggak penting dalam dunia Model Bahasa Besar open-source di tahun 2026 — membuktikan bahwa arsitektur MoE berskala ratusan miliar parameter dapat bersaing langsung dengan model flagship closed-source dalam bidang pengkodean, agen, dan konteks panjang. Skor 58,6 pada SWE-Bench Pro, ditambah kemampuan teknis jendela konteks 256K dan 300 sub-agen, menjadikannya model pilihan utama untuk asisten kode dan proyek otomatisasi riset.
Ringkasan Poin Utama:
- Keunggulan Arsitektur: 1T MoE / 32B aktif, kemampuan setara ratusan miliar parameter dengan biaya inferensi 32B.
- Unggul di Benchmark: Peringkat pertama di SWE-Bench Pro, Terminal-Bench 2.0, dan HLE.
- Keunggulan Harga: Saluran APIYI sebesar $0,60 / $2,40, sekitar 60% dari harga situs resmi.
- Ramah Ekosistem: Kompatibel sepenuhnya dengan OpenAI SDK, migrasi selesai dalam 5 menit.
- Kemampuan Teknis: Konteks 256K + 300 sub-agen + prefix caching.
Bagi tim yang ingin membangun produk AI di tahun 2026, API Kimi K2.6 adalah pilihan yang sangat kompetitif dari segi performa, biaya, dan ekosistem. Direkomendasikan untuk memvalidasi performanya secara cepat melalui platform APIYI apiyi.com guna membandingkan hasil nyata di skenario bisnis Anda dan membuat keputusan pemilihan yang paling optimal.
Penulis: Tim Teknis APIYI | Terus memantau dinamika Model Bahasa Besar AI. Silakan lakukan pertukaran teknis dan konsultasi solusi melalui APIYI apiyi.com.