Pada awal April 2026, sebuah model video AI misterius bernama HappyHorse tiba-tiba muncul di papan peringkat buta (blind test) Artificial Analysis Video Arena. Versi V1 dan V2 secara hampir bersamaan memecahkan skor Elo di kedua kategori, yaitu teks ke video (Text-to-Video) dan gambar ke video (Image-to-Video), mengungguli pemain papan atas seperti Seedance 2.0, Kling 3.0, dan PixVerse V6. Namun, hanya beberapa hari berselang, HappyHorse 1.0 tiba-tiba menghilang dari papan peringkat, hanya menyisakan beberapa tangkapan layar dan halaman resmi yang informasinya sangat minim.
Spekulasi seputar model HappyHorse langsung meledak di komunitas AI internasional: Apakah ini sekadar kedok dari Wan 2.7? Apakah ini eksperimen generasi berikutnya dari tim Seedance ByteDance? Atau mungkinkah ini gebrakan mendadak dari laboratorium Asia yang belum terungkap? Artikel ini, berdasarkan data yang dapat diverifikasi secara publik, akan mengulas secara lengkap arsitektur, performa, status open-source, dan asal-usul potensial HappyHorse 1.0 untuk membantu Anda memutuskan apakah "kuda hitam" ini layak masuk ke dalam tumpukan teknologi pembuatan video Anda.
Sekilas Informasi Inti Model HappyHorse
Sebelum membedah detail teknisnya, mari kita ringkas informasi yang diketahui ke dalam satu tabel agar Anda bisa segera memahaminya.
| Dimensi | Informasi Terkini HappyHorse 1.0 |
|---|---|
| Tipe Model | Model pembuatan video teks+gambar ke video (generasi visual dan audio gabungan) |
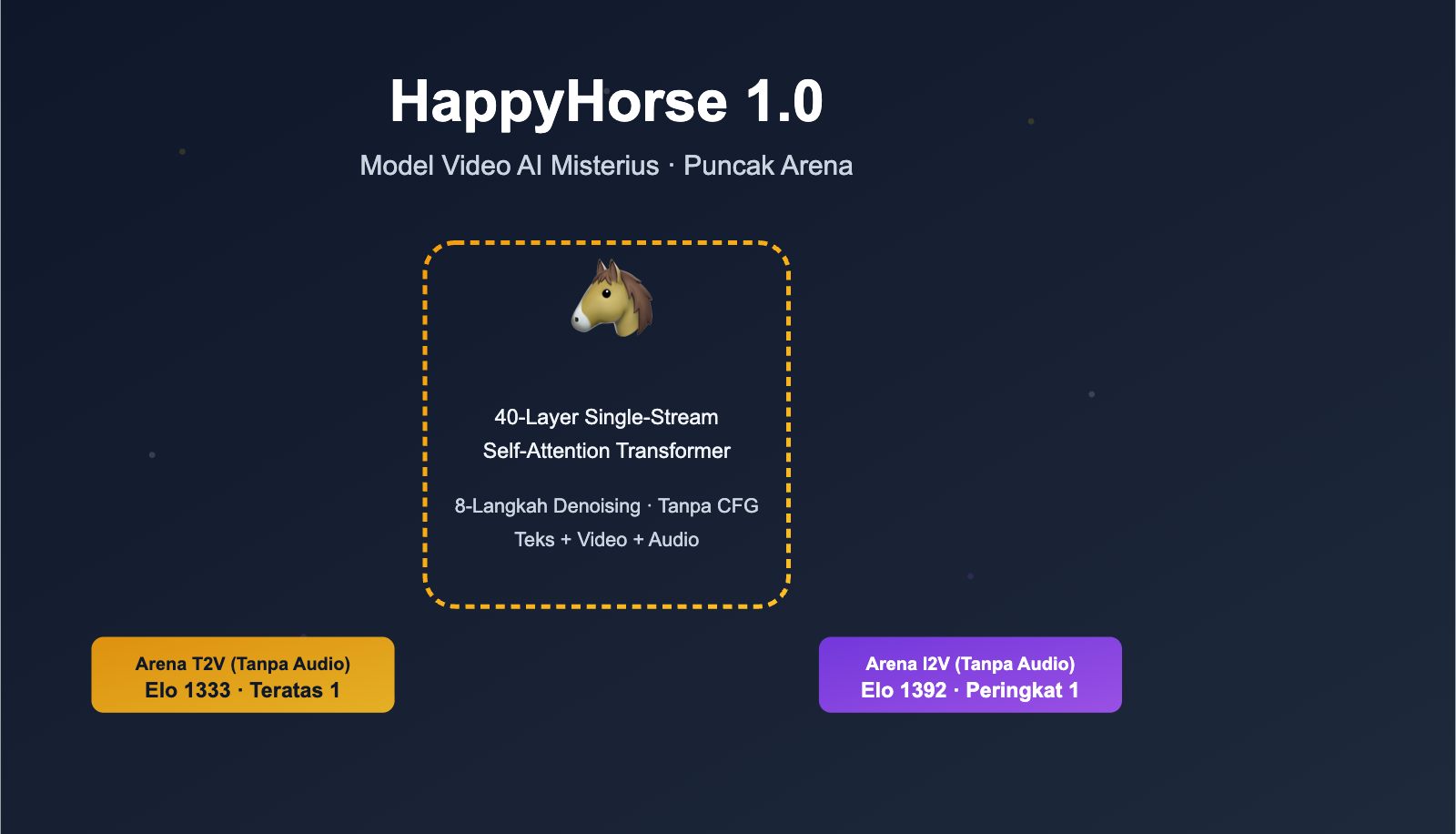
| Arsitektur | 40-layer single-stream Self-Attention Transformer, tanpa Cross-Attention |
| Langkah Inferensi | Hanya butuh 8 langkah denoising, tanpa CFG (Classifier-Free Guidance) |
| Dukungan Bahasa | Mandarin, Inggris, Jepang, Korea, Jerman, Prancis |
| Rilis | Model dasar / model distilasi / model super-resolusi / kode inferensi (klaim resmi open-source) |
| Lokasi Kemunculan | Artificial Analysis Video Arena (beberapa sumber menyebutkan jalur kompetisi video LMArena) |
| Status Saat Ini | V1/V2 telah hilang dari papan peringkat publik, situs resmi masih aktif namun GitHub/Model Hub ditandai "Coming Soon" |
| Dugaan Asal | Dari tim Asia, komunitas berspekulasi terkait dengan ekosistem Wan 2.7 / Seedance, namun belum dikonfirmasi resmi |
🎯 Saran Pengujian Cepat: Karena bobot resmi model HappyHorse belum dibuka di platform inferensi utama, jika Anda ingin segera membandingkan model video kelas atas (seperti Seedance 2.0, Kling 3.0, Veo 3.1) dalam lingkungan produksi, kami sarankan untuk menggunakan platform layanan proksi API terpadu seperti APIYI (apiyi.com) untuk melakukan pemanggilan model secara paralel. Dengan begitu, Anda bisa beralih ke HappyHorse dengan mulus setelah resmi dirilis tanpa perlu melakukan perombakan teknis berulang kali.
Linimasa Kemunculan Model HappyHorse
Untuk memahami mengapa "kuda bahagia" ini membuat komunitas AI global gempar, kita perlu melihat linimasanya secara urut.
Year of the Horse dan Kebetulan Penamaan
Tahun 2026 bertepatan dengan Tahun Kuda dalam kalender Tionghoa. Sejak perayaan Tahun Baru Imlek di bulan Februari, media internasional dan kolom seperti UX Tigers berulang kali menyebutkan bahwa komunitas AI di Tiongkok sedang melakukan serangkaian peluncuran besar-besaran bertema "kuda". Penamaan "HappyHorse" tidak hanya merujuk pada shio tersebut, tetapi juga menciptakan asosiasi dengan model lain yang muncul di periode yang sama dengan singkatan "The Horse". Ini menjadi salah satu petunjuk utama bagi komunitas bahwa model ini berasal dari tim di Asia.
Ledakan dan Hilangnya dari Arena
Berdasarkan tangkapan layar dan laporan dari pengulas video AI seperti Brent Lynch di X (sebelumnya Twitter) pada awal April, berikut adalah pola kemunculan HappyHorse 1.0:
- Kemunculan Perdana: Versi V1 muncul sebagai entri anonim di Artificial Analysis Video Arena dan dalam beberapa jam langsung menembus tiga besar dalam pengujian buta teks-ke-video;
- Peluncuran Versi V2: Hampir bersamaan, varian V2 muncul, dan kedua versi tersebut sempat menduduki peringkat pertama dan kedua di papan peringkat gambar-ke-video;
- Puncak Peringkat: Di kategori tanpa audio, HappyHorse 1.0 mengungguli model papan atas seperti Seedance 2.0 720p, Kling 3.0, dan PixVerse V6;
- Menghilang: Dalam beberapa hari, V1/V2 dihapus dari papan peringkat publik, hanya menyisakan tangkapan layar dan catatan pihak ketiga. Halaman resmi kemudian baru menampilkan keterangan bahwa "model dasar akan segera open-source".
Pola "muncul tiba-tiba → mendominasi peringkat → menghilang diam-diam" biasanya berarti dua hal: entah ada laboratorium yang sedang melakukan pengujian A/B anonim, atau pengembang di balik model tersebut sedang mempersiapkan peluncuran resmi dan menariknya setelah terekspos oleh trafik. Kedua penjelasan ini semakin menambah aura misterius dari model HappyHorse.

Analisis Arsitektur Model HappyHorse: Bagaimana Transformer Single-Stream 40-Layer Mendominasi Papan Peringkat
Meskipun makalah resminya belum dirilis, kita bisa menyimpulkan beberapa pilihan desain kunci HappyHorse 1.0 dari deskripsi di happyhorse-ai.com dan situs mirror happy-horse.net.
Self-Attention Single-Stream Menggantikan Struktur Multi-Stream yang Kompleks
Model pembuatan video tradisional (terutama model multimodal yang memproses audio, teks, dan gambar secara bersamaan) biasanya menggunakan arsitektur multi-stream, di mana teks, video, dan audio memiliki Encoder masing-masing, lalu berinteraksi melalui Cross-Attention. Struktur ini fleksibel namun boros parameter dan memerlukan pemindahan tensor antar cabang saat inferensi.
HappyHorse 1.0 menyederhanakan semuanya menjadi satu alur: satu Transformer Self-Attention 40-layer yang memproses Token teks, video, dan audio secara bersamaan, tanpa Cross-Attention di tengah, dan tanpa sub-jaringan khusus untuk modalitas tertentu. Semua modalitas dikodekan menjadi urutan Token dan dimodelkan langsung dalam ruang atensi yang sama. Desain ini memiliki beberapa keunggulan teoretis:
- Efisiensi parameter tinggi: Tidak perlu parameter redundan untuk isolasi modalitas;
- Jalur inferensi pendek: Tidak ada pemindahan data antar modalitas, sehingga Kernel lebih kontinu;
- Target pelatihan terpadu: Teks, gambar, dan audio berbagi fungsi kerugian yang sama, sehingga mudah dioptimalkan secara end-to-end;
- Dukungan alami untuk sinkronisasi audio-video: Suara dan gambar adalah Token dalam urutan yang sama, sehingga memiliki batasan sinkronisasi bawaan.
8 Langkah Denoising + Inferensi Ekstrem Tanpa CFG
Bagi pengembang yang terbiasa dengan model seperti Stable Video Diffusion, Sora, atau Kling, "puluhan langkah denoising + Classifier-Free Guidance" sudah menjadi memori otot. Deskripsi resmi HappyHorse 1.0 justru cukup agresif: hanya butuh 8 langkah denoising tanpa menggunakan CFG untuk menghasilkan kualitas gambar yang menempati peringkat pertama di Arena.
Hal ini biasanya berarti model tersebut telah melalui proses seperti Consistency Distillation / Rectified Flow / Progressive Distillation selama tahap pelatihan, yang memadatkan pengambilan sampel multi-langkah menjadi prediksi langsung dalam beberapa langkah. Bersamaan dengan "model distilasi" dan "model super-resolution" yang dirilis, seluruh tumpukan inferensi ini sangat cocok untuk target "ramah perangkat edge + throughput tinggi di sisi server".
Estimasi Skala Parameter dan Kebutuhan VRAM
Karena bobot model belum dibuka, kita tidak bisa memverifikasi jumlah parameter model HappyHorse secara langsung. Namun, jika melihat deskripsi 40-layer, single-stream, dan dukungan 6 bahasa, serta performanya di Arena, dapat diasumsikan skalanya setara dengan model publik seperti Wan 2.x, Seedance 1.x, atau Hunyuan Video, kemungkinan besar berada di kisaran 10B~30B parameter. Ini berarti untuk deployment lokal, Anda setidaknya memerlukan satu kartu grafis profesional dengan VRAM tinggi, sementara GPU konsumen biasa harus menunggu versi kuantisasi INT8/FP8.
🎯 Saran Pemilihan Arsitektur: Jika Anda sedang mengevaluasi "infrastruktur pembuatan video generasi berikutnya" untuk tim Anda, kami sarankan untuk menjadikan paradigma "Transformer Single-Stream + inferensi langkah minimal" seperti HappyHorse 1.0 sebagai objek observasi utama. Sebelum model ini sepenuhnya open-source, Anda bisa menggunakan model seperti Seedance, Kling, atau Veo melalui layanan proksi API APIYI (apiyi.com) untuk melakukan penyesuaian teknis, mematangkan petunjuk (prompt), naskah kamera, dan alur pascaproduksi, lalu beralih setelah bobot HappyHorse siap digunakan.
Data Uji Coba Model HappyHorse: Bagaimana Cara Mendominasi Papan Peringkat Arena
Setelah membahas arsitekturnya, hal yang benar-benar bisa meyakinkan tim di lapangan adalah angka. Tabel di bawah ini merangkum skor Elo hasil tes buta (blind test) HappyHorse 1.0 pada Artificial Analysis Video Arena berdasarkan catatan publik pihak ketiga, serta posisi para pesaing utamanya.
Perbandingan Elo Teks ke Video / Gambar ke Video
| Kategori | Peringkat | Model | Skor Elo |
|---|---|---|---|
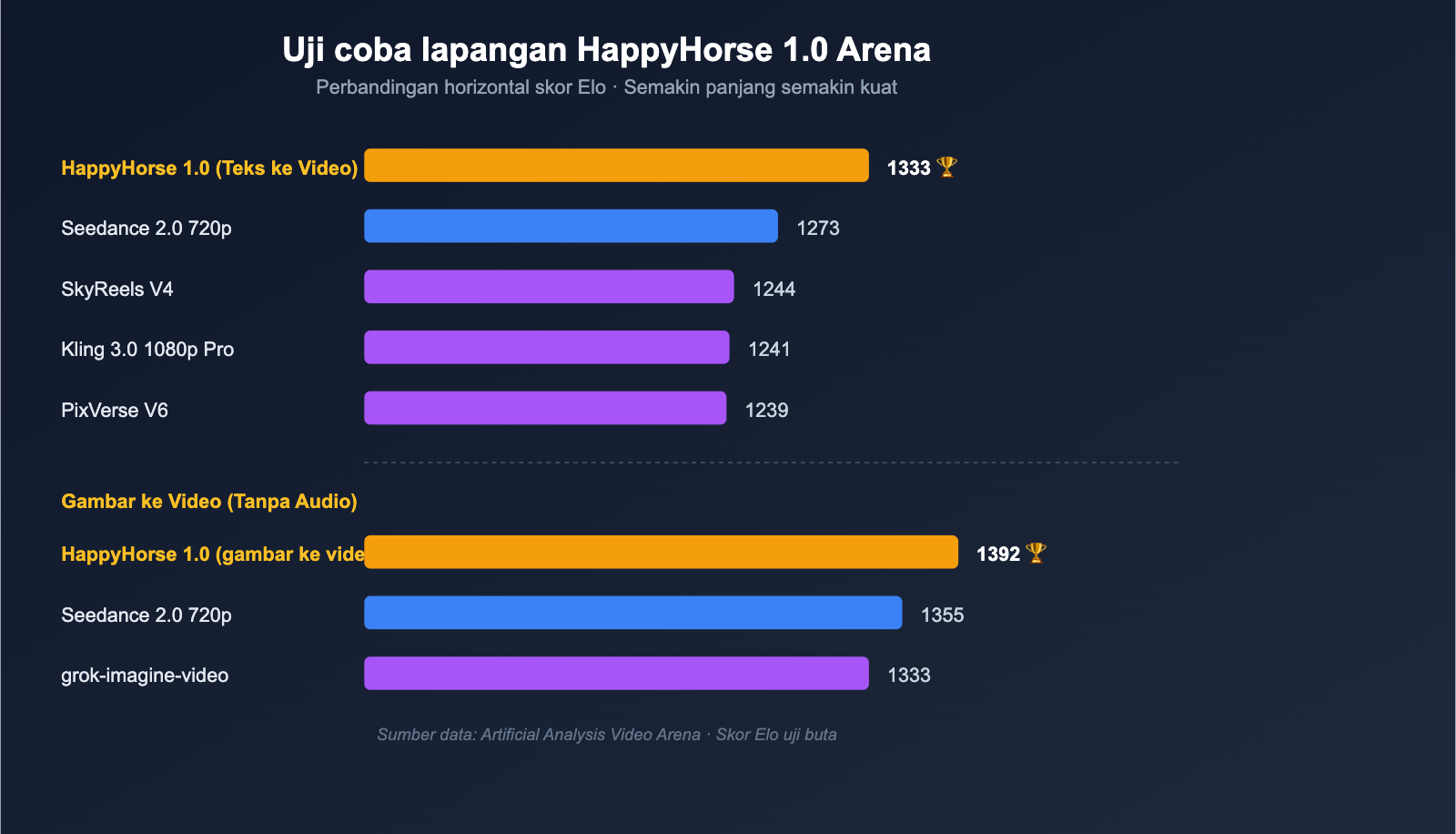
| Teks ke Video (Tanpa Audio) | 1 | HappyHorse-1.0 | 1333 |
| Teks ke Video (Tanpa Audio) | 2 | Dreamina Seedance 2.0 720p | 1273 |
| Teks ke Video (Tanpa Audio) | 3 | SkyReels V4 | 1244 |
| Teks ke Video (Tanpa Audio) | 4 | Kling 3.0 1080p (Pro) | 1241 |
| Teks ke Video (Tanpa Audio) | 5 | PixVerse V6 | 1239 |
| Teks ke Video (Dengan Audio) | 1 | Dreamina Seedance 2.0 720p | 1219 |
| Teks ke Video (Dengan Audio) | 2 | HappyHorse-1.0 | 1205 |
| Gambar ke Video (Tanpa Audio) | 1 | HappyHorse-1.0 | 1392 |
| Gambar ke Video (Tanpa Audio) | 2 | Dreamina Seedance 2.0 720p | 1355 |
| Gambar ke Video (Tanpa Audio) | 3 | PixVerse V6 | 1338 |
| Gambar ke Video (Tanpa Audio) | 4 | grok-imagine-video | 1333 |
| Gambar ke Video (Tanpa Audio) | 5 | Kling 3.0 Omni 1080p (Pro) | 1297 |
Beberapa pengamatan kunci:
- Keunggulan terbesar ada pada kategori gambar ke video: 1392 vs 1355, selisih Elo hampir 40 poin. Dalam sistem tes buta, ini adalah level di mana "pengguna bisa merasakan perbedaan secara stabil";
- Juga nomor satu untuk teks ke video murni: 1333 vs 1273, unggul 60 poin, yang berarti meskipun tanpa gambar referensi, model HappyHorse telah melampaui Seedance 2.0 dalam kemampuan dasar seperti komposisi bidikan dan gerakan karakter;
- Sementara di posisi kedua untuk kategori audio: Seedance 2.0 masih memimpin dalam sinkronisasi audio-visual, yang berkaitan dengan optimalisasi teknis mereka untuk narasi panjang ala "sutradara AI";
- Varian V2: V2 sempat terlihat memimpin dalam beberapa tangkapan layar, namun sejauh ini pihak resmi hanya merilis deskripsi 1.0. Belum dikonfirmasi apakah V2 adalah versi yang kemudian "menghilang".
Dukungan Multibahasa dan Skenario Berpusat pada Manusia
Pihak resmi menyatakan dengan jelas bahwa HappyHorse 1.0 mendukung 6 bahasa secara native: Mandarin, Inggris, Jepang, Korea, Jerman, dan Prancis, serta menekankan bahwa model ini sangat menonjol dalam skenario yang "berpusat pada manusia (human-centric)", termasuk:
- Performa wajah yang detail (facial performance);
- Koordinasi bicara yang alami (speech coordination);
- Gerakan tubuh yang realistis (body motion);
- Sinkronisasi bibir yang akurat (lip sync).
Deskripsi ini dengan jelas memposisikan model HappyHorse di jalur "manusia virtual / konten digital / drama pendek", bukan sekadar "video promosi pemandangan". Hal ini juga menjelaskan mengapa keunggulan terbesarnya ada pada kategori gambar ke video (menggerakkan foto orang) — ini adalah kebutuhan inti dari manusia digital.
Spekulasi Asal-usul Model HappyHorse: WAN 2.7? Seedance? Atau Pendatang Baru?
Saat tangkapan layar HappyHorse 1.0 mulai beredar di komunitas AI internasional, diskusi paling ramai adalah "milik siapa model ini". Dengan menggabungkan petunjuk dari komunitas, kita bisa menyusun spekulasi dalam tabel di bawah ini.
Perbandingan Tiga Spekulasi Utama
| Spekulasi Asal | Argumen Utama | Argumen Sanggahan |
|---|---|---|
| Rebranding Alibaba Wan 2.7 | Wan 2.7 dirilis pada waktu yang sama, Alibaba Tongyi Lab selalu agresif di jalur video; penamaan "Horse" merujuk pada Tahun Kuda | Deskripsi resmi Wan 2.7 lebih condong ke gambar / mode berpikir, tidak cocok dengan arsitektur 40 lapis single-stream yang ditekankan HappyHorse |
| Versi Eksperimen Tim ByteDance Seedance | Seedance 2.0 adalah pemain Tiongkok yang saat ini menduduki papan atas Arena, ByteDance punya motif tes anonim yang cukup | Tim resmi Seedance 2.0 masih memimpin di kategori audio, ByteDance tidak punya alasan untuk mengganti nama "versi yang lebih kuat" saat mengunggahnya |
| Laboratorium Tak Dikenal / Konsorsium Akademik | Rilis paket "Open Source + Model Distilasi + Model Super-resolution" lebih mirip gaya riset; penamaan aneh, situs web sangat minimalis | Kualitas model sudah mencapai level komersial papan atas, tim akademis murni sulit melatih model sebesar ini secara mandiri |
Kami pribadi cenderung pada hipotesis ketiga yang probabilitasnya terus meningkat: HappyHorse 1.0 kemungkinan besar berasal dari tim baru yang ingin mencuri perhatian melalui strategi open source. Memilih untuk anonim di Arena bertujuan membangun kredibilitas dengan data tes buta sebelum rilis resmi. Strategi "naik peringkat dulu, open source kemudian, baru rilis produk" ini telah terbukti efektif oleh banyak laboratorium di Asia dalam 18 bulan terakhir.
Namun, ini hanyalah spekulasi. Sebelum repositori GitHub dan Model Hub resmi diluncurkan, pernyataan apa pun yang menyebut "ini adalah X" tidak boleh dianggap sebagai fakta. Sikap yang lebih pragmatis bagi pengembang adalah: fokus pada kurva kemampuannya, bukan identitasnya.
🎯 Saran Bijak: Selama bobot model HappyHorse belum dibuka untuk publik dan sumbernya belum dikonfirmasi secara resmi, tidak disarankan untuk langsung mempertaruhkan bisnis produksi Anda padanya. Anda bisa menggunakan platform matang seperti APIYI apiyi.com untuk memanggil model video yang sudah terkomersialisasi seperti Seedance 2.0, Kling 3.0, atau Veo 3.1 untuk menyelesaikan proyek, sembari mengevaluasi progres open source HappyHorse secara internal.
Tiga Dampak Model HappyHorse terhadap Industri
Meskipun HappyHorse 1.0 pada akhirnya terbukti hanya sebagai kampanye promosi yang dirancang dengan matang, model ini telah meninggalkan tiga dampak yang patut dicatat bagi seluruh ekosistem pembuatan video berbasis AI.
Lapisan Pertama: Sinyal Paradigma Arsitektur
Selama dua tahun terakhir, model video arus utama masih berkutat pada jalur Diffusion multi-aliran + Cross-Attention. Model HappyHorse membuktikan dengan posisi pertama di Arena bahwa jalur "Self-Attention aliran tunggal + inferensi langkah minimal" juga bisa mencapai SOTA (State-of-the-Art), bahkan dengan rekayasa yang lebih bersih. Hal ini akan mendorong banyak tim untuk meninjau kembali: Apakah kita perlu menghemat "pajak kompleksitas" dari lapisan Cross-Attention ini?
Lapisan Kedua: Evolusi Strategi Sumber Terbuka (Open Source)
HappyHorse memilih ritme "muncul secara anonim → mengumumkan rencana open source → merilis bobot model", alih-alih metode tradisional "rilis makalah → baru rilis bobot". Ini adalah pendekatan yang lebih mirip dengan peluncuran produk konsumen, di mana "data persepsi pengguna" ditempatkan sebelum makalah teknis. Jika mereka benar-benar menepati janji untuk melakukan open source, HappyHorse 1.0 mungkin akan menjadi model dasar video berikutnya yang banyak dikembangkan ulang setelah Wan, Hunyuan Video, dan Open-Sora.
Lapisan Ketiga: Kredibilitas Papan Peringkat Buta (Blind Test)
Dari sudut pandang lain, fenomena "muncul tiba-tiba lalu menghilang" dari HappyHorse juga menjadi peringatan bagi platform pengujian buta seperti Artificial Analysis dan LMArena. Dengan semakin banyaknya entri anonim, cara membedakan "model baru yang asli" dengan "checkpoint dari model yang sudah ada" akan menjadi tantangan besar bagi pengelola papan peringkat. Bagi pengembang, ini berarti saat membaca peringkat Elo, kita perlu menggabungkannya dengan "kartu model + contoh inferensi + data bisnis nyata", bukan sekadar melihat angka.

Bagaimana Pengembang Menghadapi Kejadian "Serangan Mendadak" seperti Model HappyHorse
Bagi tim teknis dan kreator konten, daripada terjebak dalam spekulasi tentang "siapa mereka dan kapan mereka akan open source", lebih baik membangun serangkaian tindakan standar untuk menghadapi kejadian mendadak semacam ini.
Empat Langkah Alur Penanganan yang Disarankan
| Langkah | Tindakan | Tujuan |
|---|---|---|
| 1 | Gunakan antarmuka terpadu untuk menjalankan operasional pembuatan video saat ini | Memastikan peralihan mulus saat ada model baru |
| 2 | Kumpulkan petunjuk (prompt) bisnis tipikal dan materi referensi | Membentuk "set pengujian tolok ukur" internal yang independen dari Arena publik |
| 3 | Jalankan tolok ukur internal segera setelah model baru tersedia | Memvalidasi apakah skor Arena dapat direplikasi dengan data Anda sendiri |
| 4 | Evaluasi total biaya (harga API / latensi inferensi / kepatuhan) | Memutuskan apakah akan mengganti model utama |
Inti dari alur ini adalah: Jangan terikat oleh ritme rilis model tunggal mana pun, melainkan jadikan "kemampuan untuk cepat mengintegrasikan model baru" sebagai kompetensi dasar. HappyHorse 1.0 hanyalah permulaan, dan dapat diprediksi bahwa pada paruh kedua tahun 2026 akan ada lebih banyak model anonim serupa yang muncul di berbagai Arena video.
🎯 Saran Rekayasa: Bagi tim yang ingin terus mengikuti perkembangan model HappyHorse serta kompetitor seperti Seedance, Kling, dan Veo, kami menyarankan untuk mengintegrasikan pembuatan video ke layanan proksi API seperti APIYI (apiyi.com) yang mendukung pemanggilan model secara paralel; dengan begitu, siapa pun yang muncul di papan peringkat, sisi bisnis Anda hanya perlu mengganti parameter model untuk menyelesaikan perbandingan dan rilis bertahap.
FAQ Pertanyaan Umum Model HappyHorse
Q1: Apakah HappyHorse 1.0 sudah bisa diunduh dan digunakan?
Saat ini (awal April 2026), halaman resmi HappyHorse 1.0 masih melabeli repositori GitHub dan tautan Model Hub sebagai "Coming Soon". Artinya, bobot (weights) dan kode inferensi belum dirilis ke publik. Harap berhati-hati terhadap saluran mana pun yang mengklaim bahwa model tersebut "sudah bisa diunduh dan dideploy". Kami sarankan untuk terus memantau situs resminya. Sebelum bobot resmi dirilis, Anda bisa menggunakan platform seperti APIYI (apiyi.com) untuk melakukan pemanggilan model yang sudah dikomersialkan seperti Seedance 2.0 atau Kling 3.0 untuk menyelesaikan proyek Anda.
Q2: Mengapa model HappyHorse menghilang dari papan peringkat Arena?
Tidak ada penjelasan pasti mengenai alasan penghilangannya dalam informasi publik. Berdasarkan diskusi komunitas, ada dua penjelasan utama: pertama, penulis model menariknya secara sukarela untuk merapikan hasil sebelum dirilis secara resmi; kedua, pihak platform menurunkannya sementara karena identitas entri anonim tersebut belum jelas. Apapun alasannya, hal ini tidak bisa langsung diartikan sebagai "model yang buruk"—skor Elo yang diraihnya sebelum menghilang adalah data pengujian buta (blind test) yang valid.
Q3: Apakah HappyHorse 1.0 dan Wan 2.7 adalah model yang sama?
Tidak ada informasi resmi yang mengonfirmasi hal ini. Wan 2.7 adalah model gambar/video yang dirilis resmi oleh Alibaba Tongyi Lab pada April 2026, yang mengunggulkan "mode berpikir" dan rendering teks panjang; sementara model HappyHorse menekankan pada 40-layer single-stream Transformer dan inferensi denoising 8-langkah. Narasi teknis keduanya tidak konsisten. Ada spekulasi di komunitas bahwa keduanya berasal dari sumber yang sama, namun saat ini lebih terlihat seperti "dua produk di jalur yang sama pada periode yang sama", bukan kemasan berbeda dari model yang sama.
Q4: Bisakah model HappyHorse melakukan pembuatan audio-video gabungan?
Bisa. Pihak resmi menyatakan dengan jelas bahwa HappyHorse 1.0 memproses token teks, video, dan audio secara bersamaan dalam satu Transformer 40-layer, sehingga secara alami mendukung alur "input teks → output klip pendek bersuara". Di kategori Arena yang menyertakan audio, model ini saat ini berada di peringkat kedua, tepat di bawah Seedance 2.0, namun tetap termasuk dalam jajaran papan atas.
Q5: Sebagai pengembang, apa yang harus saya siapkan sekarang?
Langkah paling efisien adalah menjaga rantai alat tetap netral: integrasikan bisnis pembuatan video Anda ke platform terpadu yang mendukung pemanggilan multi-model secara paralel seperti APIYI (apiyi.com). Siapkan petunjuk (prompt), skrip kamera, dan alur peninjauan Anda terlebih dahulu. Begitu model HappyHorse resmi dirilis sebagai sumber terbuka atau tersedia melalui API, Anda hanya perlu mengganti parameter model tanpa harus menulis ulang kode untuk mengakses kuda hitam baru ini.
Q6: Skenario bisnis apa yang cocok untuk HappyHorse 1.0?
Melihat penekanan resmi pada "skenario berbasis manusia, performa wajah, sinkronisasi bibir, dan multibahasa", arah yang paling cocok untuk model HappyHorse meliputi: VTuber / video pendek tokoh digital, drama pendek AI, video promosi lintas bahasa, dan cuplikan karakter dalam iklan. Jika bisnis Anda lebih berfokus pada pemandangan atau cuplikan produk, Seedance 2.0, Veo 3.1, atau Kling 3.0 tetap menjadi pilihan yang lebih stabil dan siap pakai.
Kesimpulan: Pelajaran dari Model HappyHorse
Jika kita menyatukan semua petunjuk, HappyHorse 1.0 layak mendapatkan analisis mendalam bukan hanya karena skor Elo-nya yang impresif di Artificial Analysis Video Arena, tetapi karena ia mewakili perwujudan paradigma rilis model pembuatan video tahun 2026: Single-stream Transformer menggantikan struktur multi-stream yang kompleks, inferensi langkah minimal menggantikan denoising puluhan langkah, daftar anonim menggantikan rilis makalah terlebih dahulu, dan janji sumber terbuka menggantikan API tertutup. Keempat perubahan ini mungkin tidak revolusioner jika muncul sendiri-sendiri, namun jika digabungkan, itu berarti kita sedang menyambut ritme iterasi model video yang baru.
Saran bagi tim di lapangan sangat sederhana: Jangan terjebak dalam tebak-tebakan "siapa dia", tetapi anggap ini sebagai uji tekanan teknik—bisakah alur kerja pembuatan video Anda langsung melakukan integrasi dan evaluasi pada hari model baru muncul? Jika jawabannya ya, maka terlepas dari apakah model HappyHorse nantinya benar-benar dirilis secara terbuka, terbukti sebagai "topeng" dari vendor tertentu, atau diam selamanya, Anda tetap akan mendapatkan manfaatnya.
🎯 Saran Akhir: Jika Anda ingin merasakan semua model video AI utama selain HappyHorse 1.0 (Seedance 2.0 / Kling 3.0 / Veo 3.1 / PixVerse V6, dll.) secara instan, dan tetap memiliki kemampuan untuk beralih ke HappyHorse di masa depan, kami sarankan untuk mengaksesnya melalui platform layanan proksi API terpadu seperti APIYI (apiyi.com). Ini tidak hanya menghindari keharusan berurusan dengan SDK setiap vendor secara berulang, tetapi juga meminimalkan biaya migrasi saat model baru diluncurkan.
Penulis: Tim APIYI | Fokus pada implementasi dan praktik teknik Model Bahasa Besar AI. Untuk evaluasi video dan model multimodal lainnya, silakan kunjungi APIYI (apiyi.com).