作者注:深度对比 2026 年 2 月同期发布的 MiniMax-M2.5 和 GLM-5 两大开源模型,从编码、推理、智能体、速度、价格和架构 6 个维度解析各自擅长领域
2026 年 2 月 11-12 日,两大中国 AI 公司几乎同时发布了各自的旗舰模型:智谱 GLM-5(744B 参数)和 MiniMax-M2.5(230B 参数)。两者都采用 MoE 架构、MIT 开源协议,但在能力侧重上形成了鲜明的差异化定位。
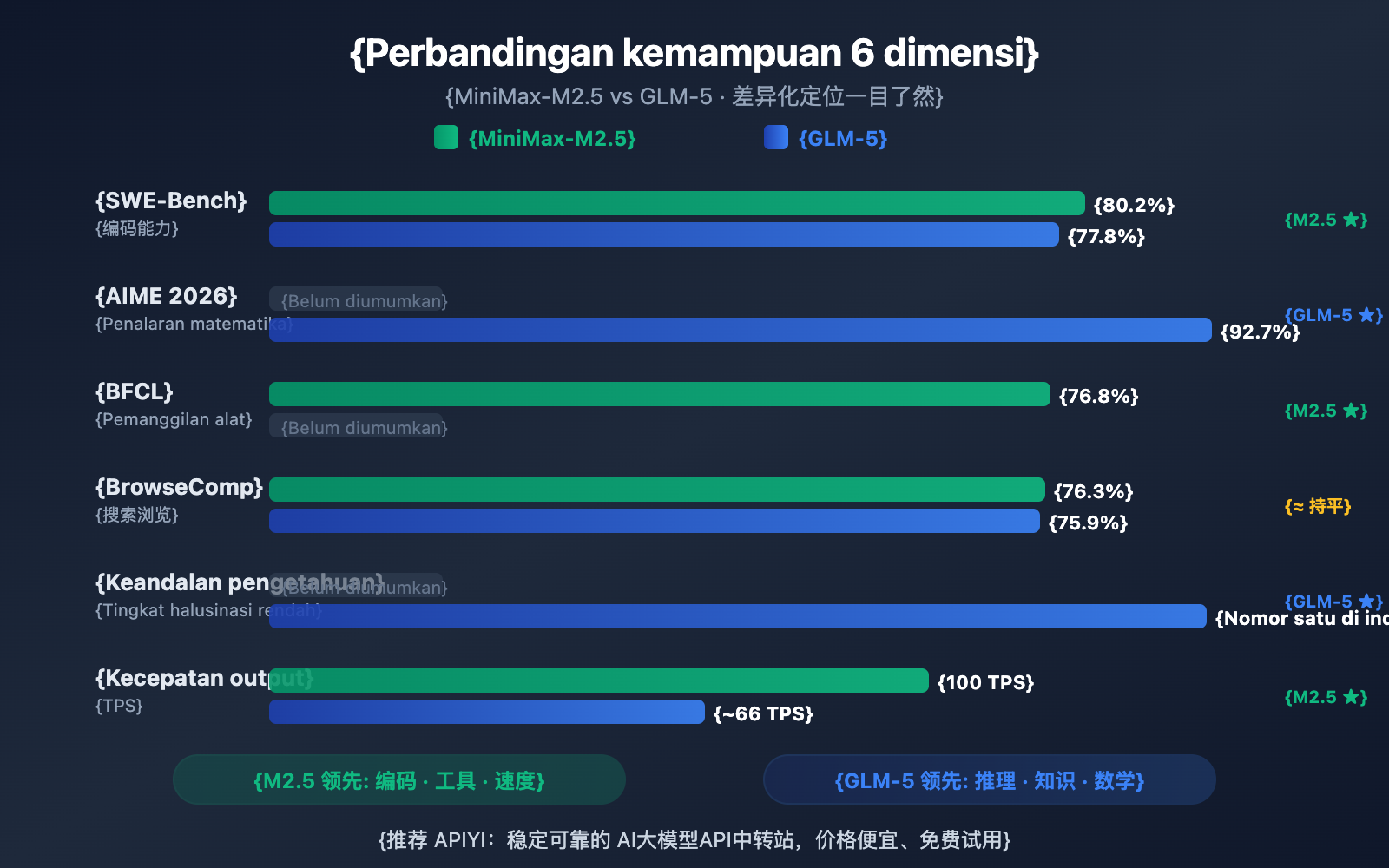
核心价值: 看完本文,你将清楚了解 GLM-5 擅长推理和知识可靠性,MiniMax-M2.5 擅长编码和智能体工具调用,从而在具体场景中做出最优选择。

Ikhtisar Perbedaan Inti MiniMax-M2.5 vs GLM-5
| Dimensi Perbandingan | MiniMax-M2.5 | GLM-5 | Keunggulan |
|---|---|---|---|
| Pengodean SWE-Bench | 80.2% | 77.8% | M2.5 unggul 2.4% |
| Penalaran Matematika AIME | — | 92.7% | GLM-5 lebih unggul |
| Pemanggilan Alat BFCL | 76.8% | — | M2.5 lebih unggul |
| Pencarian BrowseComp | 76.3% | 75.9% | Hampir setara |
| Harga Output/M token | $1.20 | $3.20 | M2.5 lebih murah 2,7x |
| Kecepatan Output | 50-100 TPS | ~66 TPS | M2.5 Lightning lebih cepat |
| Total Parameter | 230B | 744B | GLM-5 lebih besar |
| Parameter Aktif | 10B | 40B | M2.5 lebih ringan |
Keunggulan Utama MiniMax-M2.5: Pengodean dan Agen AI
MiniMax-M2.5 menunjukkan performa yang menonjol dalam benchmark pengodean. Skor 80.2% pada SWE-Bench Verified tidak hanya mengungguli GLM-5 yang sebesar 77.8%, tetapi juga melampaui GPT-5.2 (80.0%), dan hanya sedikit tertinggal dari Claude Opus 4.6 yang meraih 80.8%. Dalam Multi-SWE-Bench yang melibatkan kolaborasi multi-file, model ini meraih skor 51.3%, dan pada BFCL Multi-Turn untuk pemanggilan alat, skornya mencapai 76.8%.
Arsitektur MoE pada M2.5 hanya mengaktifkan 10B parameter (4,3% dari total 230B), menjadikannya pilihan "paling ringan" di antara model Tier 1 dengan efisiensi inferensi yang sangat tinggi. Versi Lightning bahkan bisa mencapai 100 TPS, menjadikannya salah satu model mutakhir tercepat saat ini.
Keunggulan Utama GLM-5: Penalaran dan Keandalan Pengetahuan
GLM-5 memiliki keunggulan signifikan dalam tugas penalaran dan pengetahuan. Skor penalaran matematika AIME 2026 mencapai 92.7%, penalaran sains GPQA-Diamond sebesar 86.0%, dan pada Humanity's Last Exam (dengan alat), skor 50.4 poinnya berhasil mengungguli Claude Opus 4.5 yang meraih 43.4 poin.
Kemampuan GLM-5 yang paling menonjol adalah keandalan pengetahuan—meraih tingkat memimpin industri dalam evaluasi halusinasi AA-Omniscience, meningkat 35 poin dari generasi sebelumnya. Untuk skenario yang membutuhkan output fakta dengan presisi tinggi, seperti penulisan dokumentasi teknis, bantuan penelitian akademik, dan pembangunan basis pengetahuan, GLM-5 adalah pilihan yang lebih andal. Selain itu, jumlah parameter 744B dan data pelatihan sebanyak 28,5 triliun token memberikan cadangan pengetahuan yang lebih mendalam bagi GLM-5.
Perbandingan Detail Kemampuan Coding: MiniMax-M2.5 vs GLM-5
Kemampuan coding adalah salah satu dimensi yang paling diperhatikan oleh para pengembang saat memilih model AI. Dalam hal ini, kedua model menunjukkan perbedaan yang cukup mencolok.
| Tolok Ukur Coding | MiniMax-M2.5 | GLM-5 | Claude Opus 4.6 (Referensi) |
|---|---|---|---|
| SWE-Bench Verified | 80.2% | 77.8% | 80.8% |
| Multi-SWE-Bench | 51.3% | — | 50.3% |
| SWE-Bench Multilingual | — | 73.3% | 77.5% |
| Terminal-Bench 2.0 | — | 56.2% | 65.4% |
| BFCL Multi-Turn | 76.8% | — | 63.3% |
MiniMax-M2.5 unggul 2,4 poin persentase di atas GLM-5 pada SWE-Bench Verified (80,2% vs 77,8%). Selisih ini termasuk perbedaan yang signifikan dalam tolok ukur coding—kemampuan coding M2.5 berada di level Opus 4.6, sementara GLM-5 lebih mendekati level Gemini 3 Pro.
GLM-5 memiliki data pada coding multibahasa (SWE-Bench Multilingual 73,3%) dan coding lingkungan terminal (Terminal-Bench 56,2%), yang menunjukkan kemampuan coding dari berbagai sudut pandang. Namun, pada SWE-Bench Verified yang menjadi inti pengujian, keunggulan M2.5 terlihat jelas.
M2.5 juga menunjukkan performa luar biasa dalam efisiensi coding: menyelesaikan tugas tunggal SWE-Bench hanya dalam 22,8 menit, meningkat 37% dibandingkan generasi sebelumnya, M2.1. Hal ini berkat gaya coding "Spec-writing" yang unik—melakukan dekomposisi arsitektur terlebih dahulu, baru kemudian mengimplementasikannya secara efisien, sehingga mengurangi siklus coba-coba yang tidak perlu.
🎯 Saran Skenario Coding: Jika kebutuhan utama Anda adalah bantuan coding AI (perbaikan bug, peninjauan kode, implementasi fitur), MiniMax-M2.5 adalah pilihan yang lebih baik. Melalui APIYI (apiyi.com), Anda dapat mengakses kedua model secara bersamaan untuk melakukan pengujian perbandingan secara langsung.
Perbandingan Detail Kemampuan Penalaran (Reasoning): MiniMax-M2.5 vs GLM-5
Kemampuan penalaran adalah keunggulan utama GLM-5, terutama di bidang matematika dan penalaran ilmiah.
| Tolok Ukur Penalaran | MiniMax-M2.5 | GLM-5 | Keterangan |
|---|---|---|---|
| AIME 2026 | — | 92.7% | Penalaran matematika tingkat olimpiade |
| GPQA-Diamond | — | 86.0% | Penalaran ilmiah tingkat PhD |
| Humanity's Last Exam (w/tools) | — | 50.4 | Melampaui 43.4 milik Opus 4.5 |
| HMMT Nov. 2025 | — | 96.9% | Mendekati 97.1% milik GPT-5.2 |
| τ²-Bench | — | 89.7% | Penalaran di bidang telekomunikasi |
| Keandalan Pengetahuan AA-Omniscience | — | Memimpin Industri | Tingkat halusinasi terendah |
GLM-5 menggunakan metode pelatihan baru yang disebut SLIME (Infrastruktur Pembelajaran Penguatan Asinkron), yang secara signifikan meningkatkan efisiensi pasca-pelatihan. Hal ini membuat GLM-5 mencapai lompatan besar dalam tugas-tugas penalaran:
- Skor AIME 2026 sebesar 92,7%, mendekati 93,3% milik Claude Opus 4.5, jauh melampaui level era GLM-4.5.
- GPQA-Diamond 86,0%, menunjukkan kemampuan penalaran ilmiah tingkat PhD yang mendekati 87,0% milik Opus 4.5.
- Humanity's Last Exam 50,4 poin (dengan alat bantu), melampaui 43,4 poin milik Opus 4.5 dan 45,5 poin milik GPT-5.2.
Kemampuan paling unik dari GLM-5 adalah keandalan pengetahuannya. Dalam evaluasi halusinasi AA-Omniscience, GLM-5 meningkat 35 poin dibandingkan generasi sebelumnya, mencapai level terdepan di industri. Ini berarti GLM-5 lebih jarang "mengarang" konten saat menjawab pertanyaan faktual, yang sangat berharga untuk skenario yang membutuhkan output informasi dengan presisi tinggi.
Data penalaran MiniMax-M2.5 kurang banyak dipublikasikan, karena fokus pelatihan pembelajaran penguatannya (reinforcement learning) lebih dipusatkan pada skenario coding dan agen pintar. Kerangka kerja Forge RL pada M2.5 lebih menitikberatkan pada dekomposisi tugas dan optimalisasi pemanggilan alat dalam lebih dari 200 ribu lingkungan nyata, bukan sekadar kemampuan penalaran murni.
Penjelasan Perbandingan: Jika kebutuhan inti Anda adalah penalaran matematika, analisis ilmiah, atau tanya jawab pengetahuan yang membutuhkan keandalan tinggi, GLM-5 lebih unggul. Disarankan untuk mencoba langsung perbedaan performa keduanya pada tugas penalaran spesifik Anda melalui platform APIYI (apiyi.com).
MiniMax-M2.5 vs GLM-5: Perbandingan Kemampuan Agent dan Pencarian
| Benchmark Agent | MiniMax-M2.5 | GLM-5 | Pihak yang Unggul |
|---|---|---|---|
| BFCL Multi-Turn | 76.8% | — | M2.5 (Pemanggilan tool unggul) |
| BrowseComp (w/context) | 76.3% | 75.9% | Hampir setara |
| MCP Atlas | — | 67.8% | GLM-5 (Koordinasi multi-tool) |
| Vending Bench 2 | — | $4,432 | GLM-5 (Perencanaan jangka panjang) |
| τ²-Bench | — | 89.7% | GLM-5 (Penalaran domain) |
Kedua model ini menunjukkan perbedaan yang cukup signifikan dalam kemampuan agent mereka:
MiniMax-M2.5 sangat ahli sebagai Agent "Tipe Eksekusi": Model ini tampil luar biasa dalam skenario yang membutuhkan pemanggilan tool yang sering, iterasi cepat, dan eksekusi yang efisien. Skor BFCL 76.8% menunjukkan bahwa M2.5 mampu melakukan function calling, operasi file, dan interaksi API dengan sangat presisi. Selain itu, jumlah putaran pemanggilan tool-nya berkurang 20% dibandingkan generasi sebelumnya. Di internal MiniMax sendiri, 80% kode baru sudah dihasilkan oleh model ini, dan 30% tugas harian mereka sudah diselesaikan secara otomatis olehnya.
GLM-5 sangat ahli sebagai Agent "Tipe Keputusan": Model ini lebih unggul dalam skenario yang membutuhkan penalaran mendalam, perencanaan jangka panjang, dan pengambilan keputusan yang kompleks. Skor MCP Atlas 67.8% menunjukkan kemampuan koordinasi tool skala besar yang mumpuni. Hasil simulasi pendapatan sebesar $4.432 di Vending Bench 2 membuktikan kemampuan perencanaan bisnis jangka panjangnya, sementara skor τ²-Bench 89.7% menunjukkan penalaran mendalam di bidang-bidang tertentu.
Untuk kemampuan browsing dan pencarian web, keduanya hampir setara—BrowseComp 76.3% vs 75.9%—dan keduanya merupakan pemimpin di bidang ini.
🎯 Saran Skenario Agent: Pilih M2.5 untuk pemanggilan tool frekuensi tinggi dan coding otomatis; pilih GLM-5 untuk pengambilan keputusan kompleks dan perencanaan jangka panjang. Platform APIYI (apiyi.com) mendukung kedua model ini secara bersamaan, sehingga Anda bisa beralih secara fleksibel sesuai kebutuhan skenario Anda.
MiniMax-M2.5 vs GLM-5: Perbandingan Arsitektur dan Biaya
| Arsitektur & Biaya | MiniMax-M2.5 | GLM-5 |
|---|---|---|
| Total Parameter | 230B | 744B |
| Parameter Aktif | 10B | 40B |
| Rasio Aktivasi | 4,3% | 5,4% |
| Data Pelatihan | — | 28,5 Triliun Token |
| Context Window | 205K | 200K |
| Output Maksimal | — | 131K |
| Harga Input | $0,15/M (Edisi Standar) | $1,00/M |
| Harga Output | $1,20/M (Edisi Standar) | $3,20/M |
| Kecepatan Output | 50-100 TPS | ~66 TPS |
| Chip Pelatihan | — | Huawei Ascend 910 |
| Framework Pelatihan | Forge RL | SLIME Asynchronous RL |
| Mekanisme Atensi | — | DeepSeek Sparse Attention |
| Lisensi Open Source | MIT | MIT |
Analisis Keunggulan Arsitektur MiniMax-M2.5
Keunggulan inti dari arsitektur M2.5 terletak pada sifatnya yang "sangat ringan" — hanya dengan mengaktifkan 10B parameter, ia mampu mencapai kemampuan coding yang mendekati Opus 4.6. Hal ini menghasilkan:
- Biaya Inferensi Sangat Rendah: Harga output hanya $1,20/M, atau sekitar 37% dari harga GLM-5.
- Kecepatan Inferensi Sangat Tinggi: Versi Lightning mencapai 100 TPS, 52% lebih cepat dibandingkan GLM-5 yang berada di angka ~66 TPS.
- Ambang Batas Deployment Lebih Rendah: Dengan 10B parameter aktif, ada kemungkinan model ini bisa dijalankan pada GPU kelas konsumen.
Analisis Keunggulan Arsitektur GLM-5
Total parameter sebesar 744B dan 40B parameter aktif memberikan GLM-5 kapasitas pengetahuan dan kedalaman penalaran yang lebih kuat:
- Cadangan Pengetahuan Lebih Besar: Dilatih dengan 28,5 triliun token data, jauh melampaui generasi sebelumnya.
- Kemampuan Penalaran Lebih Dalam: 40B parameter aktif mendukung rantai penalaran (reasoning chain) yang lebih kompleks.
- Kemandirian Komputasi Domestik: Seluruh proses pelatihan menggunakan chip Huawei Ascend, mewujudkan kemandirian dalam daya komputasi.
- DeepSeek Sparse Attention: Menangani context panjang hingga 200K secara efisien.
Saran: Untuk skenario pemanggilan frekuensi tinggi yang sensitif terhadap biaya, keunggulan harga M2.5 sangat mencolok (harga output hanya 37% dari GLM-5). Disarankan untuk melakukan pengujian langsung melalui platform APIYI (apiyi.com) guna melihat perbandingan performa dan harga pada tugas spesifik Anda.
Akses Cepat API MiniMax-M2.5 vs GLM-5
Melalui platform APIYI, Anda dapat menggunakan satu interface terpadu untuk memanggil kedua model secara bersamaan, sehingga memudahkan perbandingan cepat:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
# Pengujian tugas coding - M2.5 lebih unggul
code_task = "Implementasikan lock-free concurrent queue dengan Rust"
m25_result = client.chat.completions.create(
model="MiniMax-M2.5",
messages=[{"role": "user", "content": code_task}]
)
# Pengujian tugas penalaran - GLM-5 lebih unggul
reason_task = "Buktikan bahwa semua bilangan genap yang lebih besar dari 2 dapat dinyatakan sebagai jumlah dari dua bilangan prima (alur verifikasi Konjektur Goldbach)"
glm5_result = client.chat.completions.create(
model="glm-5",
messages=[{"role": "user", "content": reason_task}]
)
Saran: Dapatkan kuota uji coba gratis melalui APIYI (apiyi.com) untuk menguji kedua model ini pada skenario spesifik Anda. Coba M2.5 untuk tugas coding dan GLM-5 untuk tugas penalaran (reasoning) guna menemukan solusi yang paling tepat bagi Anda.
Pertanyaan Umum (FAQ)
Q1: MiniMax-M2.5 dan GLM-5 masing-masing paling unggul dalam hal apa?
MiniMax-M2.5 sangat mahir dalam pengodean (coding) dan pemanggilan alat agen (agent tool calling) — skor SWE-Bench 80,2% mendekati Opus 4.6, dan BFCL 76,8% merupakan yang terbaik di industri. Sementara itu, GLM-5 unggul dalam penalaran (reasoning) dan keandalan pengetahuan — dengan skor AIME 92,7%, GPQA 86,0%, serta tingkat halusinasi terendah di industri. Singkatnya: pilih M2.5 untuk menulis kode, dan pilih GLM-5 untuk tugas penalaran.
Q2: Berapa selisih harga antara kedua model ini?
Harga output MiniMax-M2.5 versi standar adalah $1,20/M token, sedangkan GLM-5 adalah $3,20/M token, yang berarti M2.5 sekitar 2,7 kali lebih murah. Jika Anda memilih versi M2.5 Lightning yang super cepat ($2,40/M), harganya mendekati GLM-5 namun dengan kecepatan yang jauh lebih tinggi. Anda juga bisa menikmati promo isi ulang dengan mengaksesnya melalui platform APIYI apiyi.com.
Q3: Bagaimana cara cepat membandingkan performa nyata dari kedua model ini?
Kami merekomendasikan penggunaan platform APIYI apiyi.com untuk akses terpadu:
- Daftar akun untuk mendapatkan API Key dan kuota gratis.
- Siapkan 2 jenis tugas pengujian: kategori pengodean dan kategori penalaran.
- Panggil MiniMax-M2.5 dan GLM-5 untuk menjalankan tugas yang sama secara bergantian.
- Bandingkan kualitas output, kecepatan respons, dan konsumsi Token.
- Gunakan antarmuka yang kompatibel dengan OpenAI, sehingga Anda cukup mengubah parameter
modeluntuk berganti model.
Kesimpulan
Berikut adalah poin-poin utama perbandingan MiniMax-M2.5 vs GLM-5:
- Pilihan Utama untuk Pengodean adalah M2.5: Skor SWE-Bench 80,2% vs 77,8% (M2.5 unggul 2,4%), dan pemanggilan alat BFCL 76,8% adalah yang terbaik di industri.
- Pilihan Utama untuk Penalaran adalah GLM-5: Skor AIME 92,7%, GPQA 86,0%, dan Humanity's Last Exam 50,4 poin, melampaui Opus 4.5.
- Keandalan Pengetahuan Dipimpin oleh GLM-5: Peringkat pertama dalam evaluasi halusinasi AA-Omniscience, membuat output faktualnya lebih tepercaya.
- Rasio Performa-Harga M2.5 Lebih Unggul: Harga output hanya 37% dari harga GLM-5, dan versi Lightning menawarkan kecepatan yang lebih tinggi.
Kedua model ini menggunakan lisensi sumber terbuka MIT dan arsitektur MoE, namun dengan posisi yang sangat berbeda: M2.5 adalah "Raja Agen Pengodean dan Eksekusi", sedangkan GLM-5 adalah "Pelopor Penalaran dan Keandalan Pengetahuan". Kami menyarankan Anda untuk fleksibel beralih di antara keduanya melalui platform APIYI apiyi.com sesuai kebutuhan proyek Anda, dan manfaatkan promo isi ulang untuk mendapatkan harga yang lebih hemat.
📚 Referensi
-
Pengumuman Resmi MiniMax M2.5: Kemampuan coding inti M2.5 dan detail pelatihan Forge RL
- Tautan:
minimax.io/news/minimax-m25 - Penjelasan: Data benchmark lengkap seperti SWE-Bench 80.2%, BFCL 76.8%, dll.
- Tautan:
-
Rilis Resmi GLM-5: Arsitektur MoE 744B dan teknologi pelatihan SLIME dari Zhipu GLM-5
- Tautan:
docs.z.ai/guides/llm/glm-5 - Penjelasan: Mencakup data benchmark penalaran seperti AIME 92.7%, GPQA 86.0%, dll.
- Tautan:
-
Evaluasi Independen Artificial Analysis: Pengujian benchmark standar dan peringkat untuk kedua model
- Tautan:
artificialanalysis.ai/models/glm-5 - Penjelasan: Data independen seperti Intelligence Index, pengujian kecepatan nyata, perbandingan harga, dll.
- Tautan:
-
Analisis Mendalam BuildFastWithAI: Pengujian benchmark komprehensif GLM-5 dan perbandingan dengan kompetitor
- Tautan:
buildfastwithai.com/blogs/glm-5-released-open-source-model-2026 - Penjelasan: Tabel perbandingan mendetail dengan Opus 4.5 dan GPT-5.2.
- Tautan:
-
MiniMax HuggingFace: Bobot model open-source M2.5
- Tautan:
huggingface.co/MiniMaxAI - Penjelasan: Lisensi MIT, mendukung deployment vLLM/SGLang.
- Tautan:
Penulis: Tim APIYI
Diskusi Teknis: Jangan ragu untuk berbagi hasil pengujian perbandingan model Anda di kolom komentar. Untuk tutorial integrasi API Model Bahasa Besar lainnya, kunjungi komunitas teknis APIYI di apiyi.com.





