Note de l'auteur : Analyse détaillée de l'architecture Thinker-Talker MoE, de la fenêtre de contexte de 256K, des capacités d'encodage audio-vidéo et de la capacité émergente "Audio-Visual Vibe Coding" du modèle multimodal natif Qwen3.5-Omni d'Alibaba.
L'équipe Qwen d'Alibaba a officiellement lancé Qwen3.5-Omni le 30 mars 2026. Il s'agit d'un modèle multimodal natif capable de traiter simultanément le texte, l'image, l'audio et la vidéo au sein d'un pipeline de calcul unique. Dans le cadre de la vague de lancements intensifs d'Alibaba entre mars et avril, Qwen3.5-Omni a atteint le SOTA sur 215 benchmarks, marquant une avancée majeure pour les acteurs chinois de l'IA dans le domaine des grands modèles de langage omnimodaux.
Valeur ajoutée : Découvrez en 3 minutes la conception de l'architecture Thinker-Talker de Qwen3.5-Omni, les stratégies de sélection parmi les trois variantes du modèle et sa capacité émergente "Audio-Visual Vibe Coding".
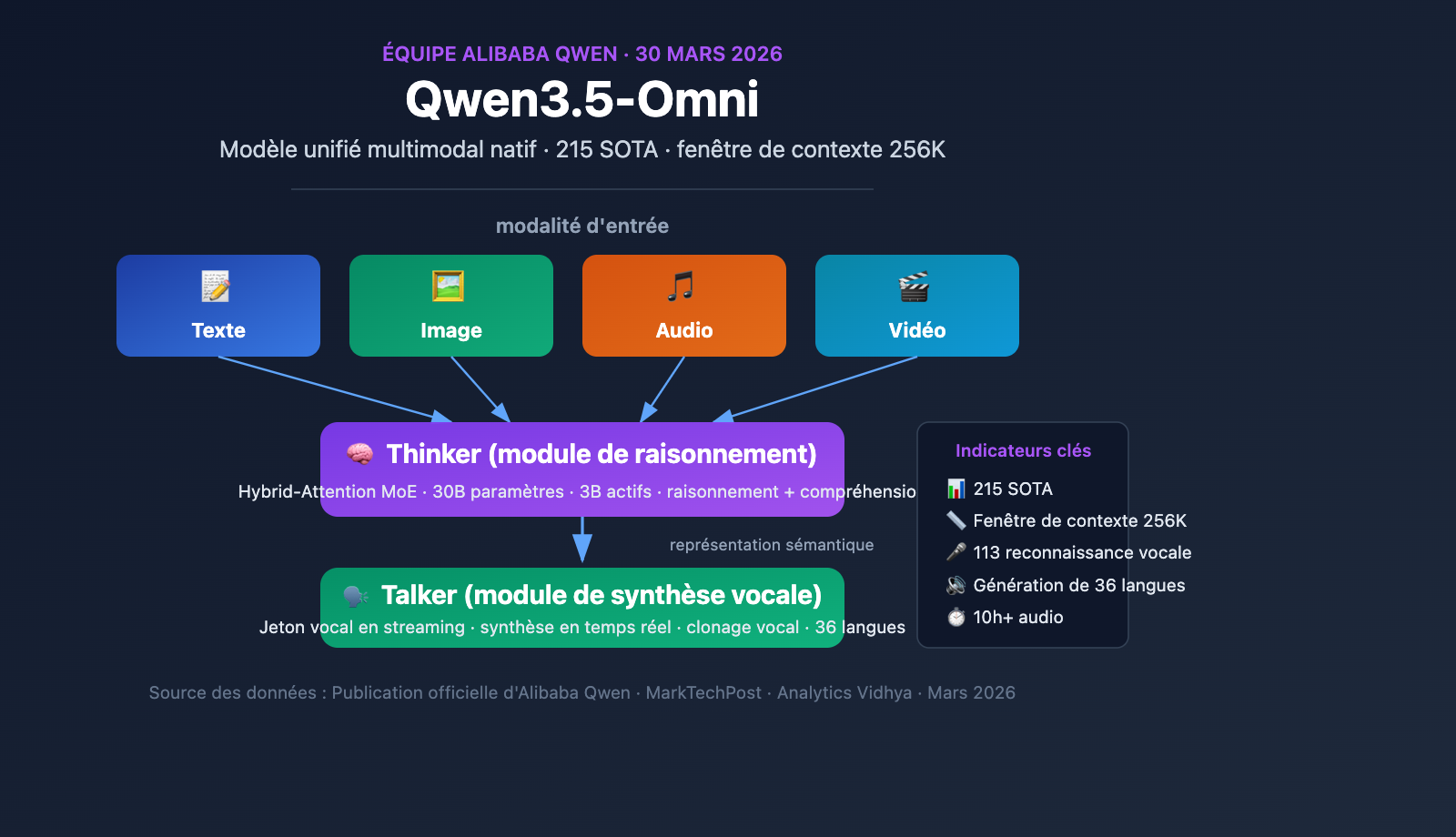
Informations clés sur le modèle multimodal Qwen3.5-Omni
Aperçu des paramètres clés de Qwen3.5-Omni
| Paramètre | Détails |
|---|---|
| Date de sortie | 30 mars 2026 |
| Éditeur | Équipe Alibaba Qwen |
| Architecture | Thinker-Talker + Hybrid-Attention MoE |
| Variantes de modèle | Plus (30B-A3B MoE), Flash (MoE léger), Light (modèle dense/poids ouverts) |
| Fenêtre de contexte | 256K jetons |
| Capacité audio | 10+ heures d'audio continu |
| Capacité vidéo | 400+ secondes de vidéo 720p (échantillonnage à 1 FPS) |
| Reconnaissance vocale | 113 langues et dialectes (contre 19 pour la génération précédente) |
| Génération vocale | 36 langues (contre 10 pour la génération précédente) |
| Données d'entraînement | Plus de 100 millions d'heures de données audio et vidéo |
| Résultats des benchmarks | SOTA sur 215 benchmarks de compréhension audio/vidéo |
Positionnement du modèle Qwen3.5-Omni
L'importance fondamentale de Qwen3.5-Omni réside dans son caractère multimodal natif : il ne s'agit pas d'un modèle textuel auquel on a greffé des modules audio et vidéo, mais d'un modèle unifié pré-entraîné dès le départ sur plus de 100 millions d'heures de données audio et vidéo. Toutes les modalités sont traitées dans le même pipeline de calcul, ce qui signifie que le modèle peut réellement comprendre les informations sémantiques contenues dans l'audio et la vidéo, plutôt que de simplement transcrire ces médias en texte avant traitement.
Par ailleurs, Qwen3.5-Omni fait partie de la série de modèles lancés intensivement par Alibaba entre mars et avril 2026. Quelques jours plus tard, le 2 avril, Alibaba a publié le modèle Qwen3.6-Plus destiné aux applications d'entreprise (prenant en charge une fenêtre de contexte de 1 million de jetons, axé sur la programmation par agents), illustrant l'investissement massif d'Alibaba dans le domaine des grands modèles de langage.
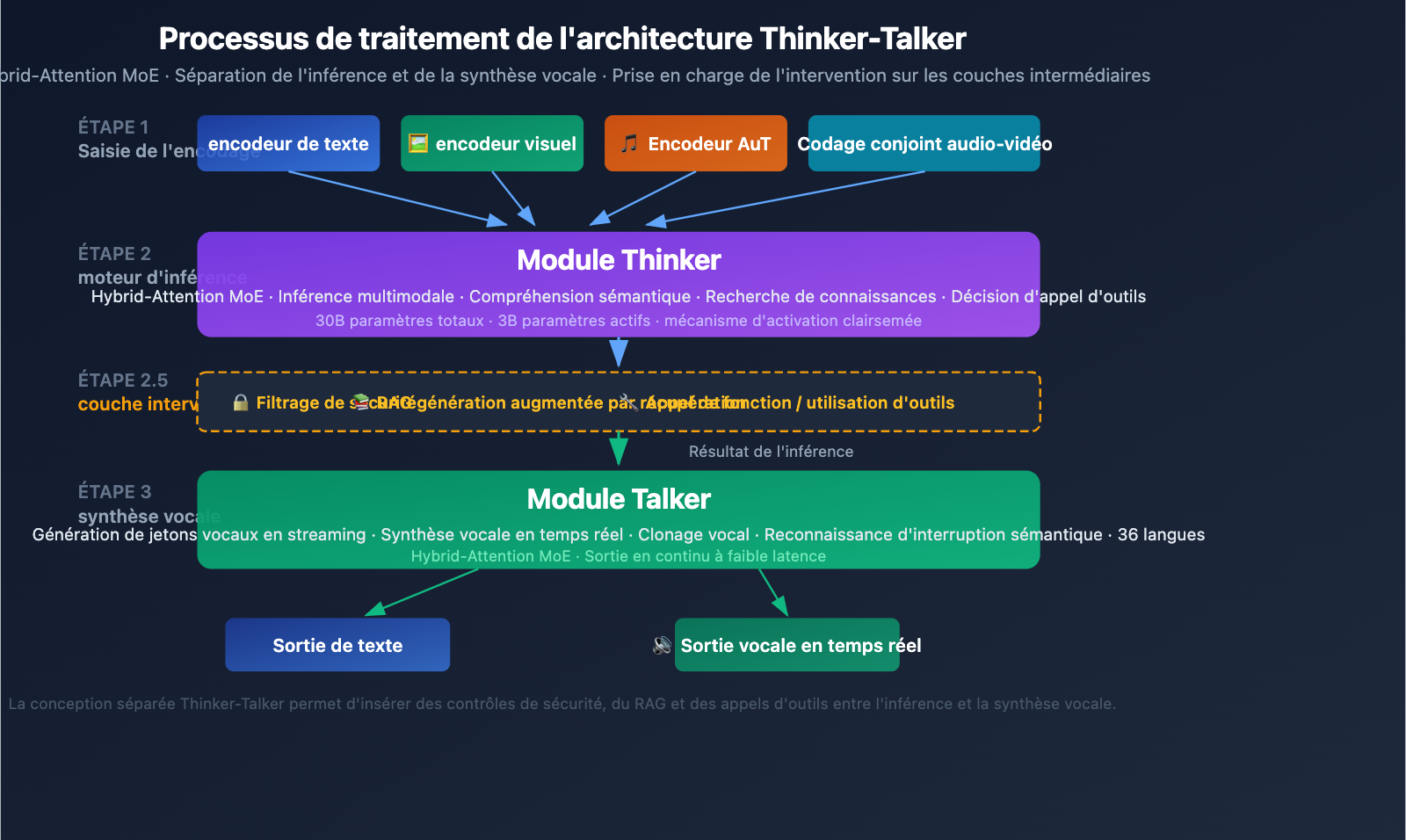
Analyse détaillée de l'architecture Qwen3.5-Omni Thinker-Talker
Conception à double module Thinker-Talker
Qwen3.5-Omni adopte une architecture unique à double module Thinker-Talker. Introduite pour la première fois avec Qwen2.5-Omni, cette conception bénéficie d'une mise à niveau majeure dans la version 3.5 : les deux modules utilisent désormais l'architecture Hybrid-Attention MoE (mélange d'experts avec attention hybride).
Module Thinker (le penseur) :
- Traite toutes les modalités d'entrée : texte, image, audio, vidéo
- Exécute les tâches de raisonnement et de compréhension
- Génère des représentations de raisonnement internes
- Utilise un encodeur Audio Transformer (AuT) natif pour traiter l'audio
- Produit des représentations sémantiques structurées
Module Talker (l'orateur) :
- Reçoit les représentations de raisonnement du Thinker
- Convertit les représentations sémantiques en jetons vocaux en flux continu
- Prend en charge la synthèse vocale en temps réel
- Permet une expression vocale naturelle (incluant l'intonation, l'émotion et les pauses)
Valeur technique de l'architecture Thinker-Talker
L'avantage principal de cette conception séparée est l'interopérabilité intermédiaire : les systèmes externes (pipelines de récupération RAG, filtres de sécurité, appels de fonction) peuvent intervenir entre la sortie du Thinker et la synthèse du Talker. Cela signifie que :
- Les entreprises peuvent ajouter des contrôles de sécurité avant la sortie vocale
- Les développeurs peuvent déclencher des appels d'outils basés sur les résultats du raisonnement
- Les systèmes RAG peuvent compléter les résultats avec des connaissances récupérées avant de répondre
Mécanisme d'activation creuse MoE
Le cœur de la conception Hybrid-Attention MoE est l'activation creuse : le modèle n'active qu'une partie de ses paramètres lors du traitement de chaque jeton (seulement 3 milliards actifs sur un total de 30 milliards). Ce mécanisme permet au modèle de maintenir une grande capacité tout en contrôlant le coût de calcul de l'invocation du modèle, ce qui est crucial pour les applications en temps réel (comme les conversations vocales).
🎯 Conseil de développement : L'architecture séparée Thinker-Talker de Qwen3.5-Omni est idéale pour construire des flux de travail IA multi-étapes. Si vous devez intégrer des capacités multimodales dans vos propres applications, vous pouvez tester rapidement les différences de performance entre Qwen3.5-Omni et d'autres grands modèles multimodaux via la plateforme APIYI apiyi.com.
Comparaison des trois variantes du modèle Qwen3.5-Omni
Guide de sélection : Plus / Flash / Light
Qwen3.5-Omni propose trois variantes de modèle adaptées à différents scénarios :
| Variante | Type d'architecture | Taille des paramètres | Mode d'accès | Scénarios d'utilisation |
|---|---|---|---|---|
| Plus | MoE (30B-A3B) | 30B total / 3B actif | API (DashScope) | Raisonnement de haute qualité, tâches multimodales complexes |
| Flash | MoE léger | Paramètres réduits | API (DashScope) | Scénarios à faible latence, conversations en temps réel |
| Light | Modèle dense | Taille réduite | Poids ouverts (HuggingFace) | Déploiement local, appareils en périphérie |
Conseils de sélection :
- Pour une performance optimale → Choisissez la variante Plus, qui obtient les meilleurs scores sur 215 tests de référence
- Pour une faible latence → Choisissez la variante Flash, adaptée aux conversations vocales en temps réel et aux interactions en flux
- Pour un déploiement local → Choisissez la variante Light, dont les poids ouverts peuvent être exécutés sur un GPU local
Méthode d'accès à l'API Qwen3.5-Omni
L'API de Qwen3.5-Omni suit le format standard /v1/chat/completions, en spécifiant le type de sortie via le paramètre modalities :
import openai
client = openai.OpenAI(
api_key="VOTRE_CLE_API",
base_url="https://api.apiyi.com/v1" # Accès unifié via APIYI
)
response = client.chat.completions.create(
model="qwen3.5-omni-plus",
modalities=["text", "audio"],
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "Veuillez analyser le contenu de cette vidéo"},
{"type": "video_url", "video_url": {"url": "https://example.com/video.mp4"}}
]
}
]
)
Voir l’exemple complet d’entrée multimodale
import openai
import base64
client = openai.OpenAI(
api_key="VOTRE_CLE_API",
base_url="https://api.apiyi.com/v1"
)
# Entrée multimodale : Image + Audio + Texte
response = client.chat.completions.create(
model="qwen3.5-omni-plus",
modalities=["text", "audio"],
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "Veuillez générer un rapport d'analyse basé sur l'image et la description vocale"},
{
"type": "image_url",
"image_url": {"url": "data:image/png;base64,..."}
},
{
"type": "input_audio",
"input_audio": {
"data": base64.b64encode(audio_bytes).decode(),
"format": "wav"
}
}
]
}
],
max_tokens=2000
)
# Récupérer la réponse textuelle
print(response.choices[0].message.content)
# Si une sortie audio a été demandée, récupérer les données vocales
if hasattr(response.choices[0].message, 'audio'):
audio_data = response.choices[0].message.audio
print(f"Format audio : {audio_data.format}")
💡 Conseil d'intégration : L'API Qwen3.5-Omni est compatible avec le format du SDK OpenAI. Si vous avez déjà du code basé sur ce SDK, il vous suffit de modifier les paramètres
base_urletmodelpour basculer rapidement. Via la plateforme APIYI apiyi.com, vous pouvez tester simultanément les performances multimodales de Qwen3.5-Omni et d'autres modèles comme GPT-4o.
Analyse des performances du benchmark Qwen3.5-Omni
Capacités de compréhension audio
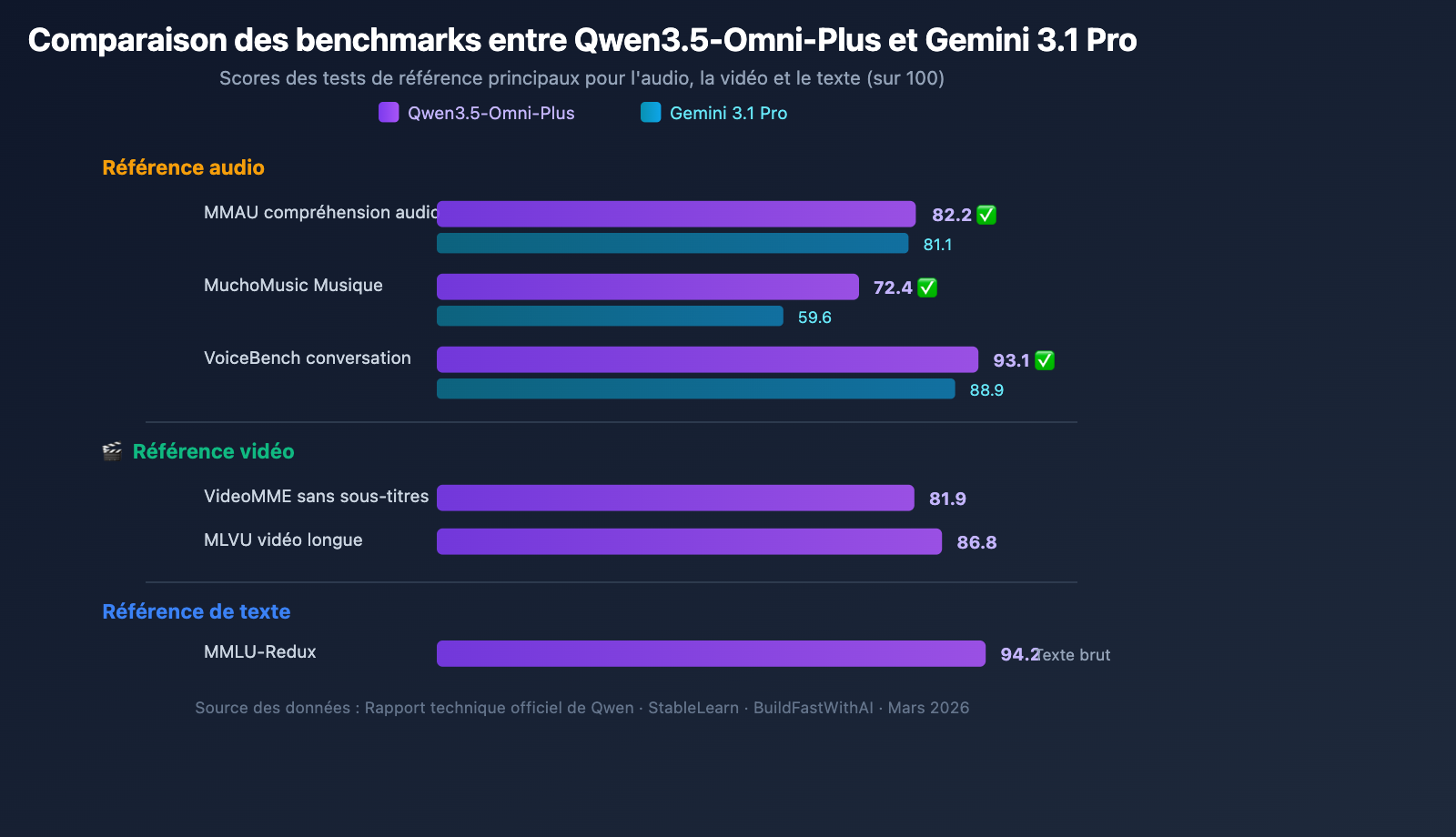
Le Qwen3.5-Omni-Plus surpasse globalement le Google Gemini 3.1 Pro dans les benchmarks liés à l'audio :
| Benchmark | Qwen3.5-Omni-Plus | Gemini 3.1 Pro | Vainqueur |
|---|---|---|---|
| Compréhension audio MMAU | 82,2 | 81,1 | Qwen |
| Compréhension musicale MuchoMusic | 72,4 | 59,6 | Qwen (+21 %) |
| Dialogue VoiceBench | 93,1 | 88,9 | Qwen |
L'avantage de Qwen3.5-Omni est particulièrement marqué en compréhension musicale (MuchoMusic), avec une avance de 21 %.
Capacités visuelles et vidéo
| Benchmark | Qwen3.5-Omni-Plus | Description |
|---|---|---|
| MMMU-Pro | 73,9 | Meilleur score en compréhension multimodale |
| RealWorldQA | 84,1 | Questions-réponses visuelles en conditions réelles |
| VideoMME (sans sous-titres) | 81,9 | Compréhension vidéo multimodale |
| MLVU | 86,8 | Compréhension de vidéos longues |
| MVBench | 79,0 | Benchmark vidéo multidimensionnel |
| LVBench | 71,2 | Benchmark vidéo longue durée |
Maintien des capacités de raisonnement textuel
Tout en acquérant des capacités multimodales complètes, les performances de raisonnement textuel de Qwen3.5-Omni ne subissent quasiment aucune baisse :
| Benchmark | Qwen3.5-Omni-Plus | Qwen3.5-Plus (texte seul) | Écart |
|---|---|---|---|
| MMLU-Redux | 94,2 | 94,3 | -0,1 |
| C-Eval | 92,0 | 92,3 | -0,3 |
| IFEval | 89,7 | 89,7 | 0 |
Cela signifie que choisir Qwen3.5-Omni ne sacrifie pas la qualité du raisonnement textuel : vous pouvez couvrir à la fois les scénarios textuels et multimodaux avec un seul modèle.
🎯 Conseil de sélection : Qwen3.5-Omni présente des avantages évidents en compréhension audio et musicale. Si votre application implique une interaction vocale ou une analyse audio, nous vous recommandons de privilégier ce modèle. Vous pouvez utiliser APIYI (apiyi.com) pour comparer rapidement les performances de Qwen3.5-Omni et de GPT-4o dans vos scénarios spécifiques.
Les 3 capacités différenciantes de Qwen3.5-Omni
Capacité 1 : Audio-Visual Vibe Coding
Qwen3.5-Omni démontre une capacité émergente que l'équipe de Qwen appelle « Audio-Visual Vibe Coding » : le modèle peut écrire du code fonctionnel en regardant une vidéo et en écoutant des instructions vocales, sans avoir été spécifiquement entraîné pour cette tâche.
Lors de tests réels, le modèle est capable de :
- Convertir des croquis dessinés à la main (capturés par caméra) en pages web React fonctionnelles.
- Écrire du code fonctionnel basé sur une démonstration vidéo et une description orale.
- Comprendre l'intention de conception visuelle et générer l'implémentation front-end correspondante.
Cette capacité est particulièrement précieuse pour le prototypage rapide et les scénarios de développement low-code.
Capacité 2 : Reconnaissance des interruptions sémantiques
Les systèmes d'interaction vocale traditionnels ne parviennent pas à distinguer les feedbacks de l'utilisateur (comme « hmm », « ah ») d'une réelle intention d'interruption. Qwen3.5-Omni introduit une reconnaissance native de l'intention de prise de parole (Turn-Taking Intent Recognition), qui permet de distinguer :
- Le feedback de soutien (Backchanneling) : comme « hmm », « d'accord », qui sont des retours sans intention d'interruption sémantique.
- L'interruption sémantique (Semantic Interruption) : lorsque l'utilisateur a une intention claire de reprendre la conversation.
Cela rend l'expérience de dialogue vocal avec Qwen3.5-Omni beaucoup plus proche d'une conversation humaine.
Capacité 3 : Clonage vocal
Les utilisateurs peuvent télécharger un enregistrement vocal ; Qwen3.5-Omni apprendra et clonera les caractéristiques de cette voix pour l'utiliser dans toutes les sorties vocales ultérieures. La voix clonée conserve sa naturel et sa stabilité, même dans des scénarios multilingues.
La place de Qwen3.5-Omni dans l'offensive IA d'Alibaba
Calendrier de lancement des modèles IA d'Alibaba (mars-avril 2026)
| Date de lancement | Modèle | Positionnement | Caractéristiques clés |
|---|---|---|---|
| 30 mars | Qwen3.5-Omni | Modèle multimodal natif | Traitement unifié texte/image/audio/vidéo |
| 2 avril | Qwen3.6-Plus | Modèle d'agent d'entreprise | Fenêtre de contexte de 1 million de jetons, programmation par agents |
| Mises à jour continues | Qwen3-TTS | Synthèse vocale | Série TTS open source, support du clonage vocal |
Ce rythme de lancement soutenu montre qu'Alibaba renforce ses capacités en matière de grands modèles de langage sur tous les fronts. Qwen3.5-Omni couvre la perception et la compréhension multimodales, tandis que Qwen3.6-Plus se concentre sur la génération de code et les capacités d'agent pour les entreprises, les deux étant complémentaires.
Il est intéressant de noter que les variantes Plus et Flash de Qwen3.5-Omni sont publiées via une API fermée, marquant une rupture avec la stratégie précédente d'Alibaba, axée sur l'open source. Des médias comme WinBuzzer estiment que cela reflète une attention accrue à la rentabilité sous la pression commerciale — le titre d'un article de Bloomberg est d'ailleurs explicite : « Alibaba lance son troisième modèle d'IA propriétaire, en se concentrant sur les profits ».
💰 Conseil coût : Si vous envisagez d'intégrer Qwen3.5-Omni dans vos produits, nous vous recommandons d'effectuer d'abord une preuve de concept via les crédits gratuits de la plateforme APIYI (apiyi.com), afin de confirmer les performances du modèle avant de passer au déploiement en production. La plateforme prend en charge l'ensemble des modèles Qwen, GPT, Claude, Gemini, etc., facilitant ainsi une sélection flexible selon vos besoins.
Foire aux questions
Q1 : Qwen3.5-Omni est-il open source ou propriétaire ?
Qwen3.5-Omni se décline en trois variantes : Plus et Flash sont actuellement disponibles uniquement via l'API DashScope d'Alibaba Cloud (propriétaire), tandis que les poids de la variante Light sont ouverts et téléchargeables sur HuggingFace (open source). La génération précédente, Qwen3-Omni, était entièrement open source sous licence Apache 2.0, mais les variantes Plus/Flash de la version 3.5 ont basculé vers un modèle API-only. Si vous avez besoin d'un déploiement local, vous pouvez opter pour la variante Light.
Q2 : Comment Qwen3.5-Omni se compare-t-il à GPT-4o ?
En matière de compréhension audio et musicale, Qwen3.5-Omni-Plus devance nettement GPT-4o. Pour ce qui est de la compréhension vidéo, les deux modèles ont leurs avantages respectifs. En termes de raisonnement textuel, Qwen3.5-Omni est pratiquement au même niveau que le modèle purement textuel de la maison, Qwen3.5-Plus. Nous vous suggérons d'effectuer des tests comparatifs sur vos cas d'usage spécifiques via la plateforme APIYI (apiyi.com), car les performances peuvent varier considérablement selon les scénarios.
Q3 : Comment démarrer rapidement avec l’API Qwen3.5-Omni ?
L'API de Qwen3.5-Omni est compatible avec le format standard du SDK OpenAI, ce qui rend l'intégration très simple. Il suffit d'installer le SDK openai, de configurer votre clé API et l'URL de base (base_url) pour commencer l'invocation du modèle. Vous pouvez obtenir des crédits de test gratuits via APIYI (apiyi.com) et utiliser les exemples de code de cet article pour vérifier rapidement les capacités d'invocation multimodale.
Résumé
Points clés du modèle multimodal Qwen3.5-Omni :
- Multimodalité native : Traitement unifié du texte, de l'image, de l'audio et de la vidéo au sein d'un pipeline unique, sans assemblage de composants disparates.
- Architecture Thinker-Talker : Séparation entre le raisonnement et la synthèse vocale, permettant une intervention sur les couches intermédiaires et l'appel d'outils.
- 3 variantes disponibles : Plus (la plus puissante), Flash (faible latence) et Light (poids ouverts pour déploiement local).
- 215 records SOTA : Avance significative sur Gemini 3.1 Pro en compréhension audio et musicale.
- Capacités émergentes : Le "Audio-Visual Vibe Coding" permet au modèle d'écrire du code à partir de vidéos et d'instructions vocales.
Qwen3.5-Omni marque une avancée majeure dans l'IA multimodale : un seul modèle couvre quatre types de données tout en conservant des capacités de raisonnement textuel quasi intactes. Pour les développeurs ayant besoin de fonctionnalités multimodales, c'est une option qui mérite une évaluation sérieuse.
Nous vous recommandons de tester rapidement Qwen3.5-Omni et d'autres modèles multimodaux de premier plan via APIYI sur apiyi.com. La plateforme offre des crédits gratuits et une interface API unifiée, facilitant ainsi la comparaison et la sélection de vos modèles.
📚 Références
-
Rapport MarkTechPost : Analyse détaillée du lancement de Qwen3.5-Omni
- Lien :
marktechpost.com/2026/03/30/alibaba-qwen-team-releases-qwen3-5-omni-a-native-multimodal-model-for-text-audio-video-and-realtime-interaction - Description : Analyse technique approfondie et décryptage de l'architecture.
- Lien :
-
Dépôt GitHub Qwen3-Omni : Code source et poids du modèle
- Lien :
github.com/QwenLM/Qwen3-Omni - Description : Code complet et documentation de la génération précédente Qwen3-Omni.
- Lien :
-
Analyse approfondie Analytics Vidhya : Analyse du rapport technique de Qwen3.5-Omni
- Lien :
analyticsvidhya.com/blog/2026/03/qwen3-5-omni-ai-model - Description : Analyse détaillée couvrant le clonage vocal, le Vibe Coding et d'autres capacités.
- Lien :
-
Rapport eWeek : Qwen3.5-Omni comme modèle multimodal le plus avancé d'Alibaba
- Lien :
eweek.com/news/qwen3-5-omni-alibaba-multimodal-ai-launch - Description : Analyse sous l'angle industriel et comparaison avec la concurrence.
- Lien :
-
Page modèle HuggingFace : Qwen3-Omni-30B-A3B-Instruct
- Lien :
huggingface.co/Qwen/Qwen3-Omni-30B-A3B-Instruct - Description : Téléchargement des poids du modèle et spécifications techniques.
- Lien :
Auteur : Équipe technique APIYI
Échanges techniques : N'hésitez pas à discuter de vos applications d'IA multimodale dans les commentaires. Pour plus de ressources sur le développement IA, consultez le centre de documentation APIYI sur docs.apiyi.com.