Note de l'auteur : GPT-5.4 ou Claude Opus 4.6 ? En 2026, les deux grands modèles de langage phares les plus attendus se livrent un duel au sommet. Cet article compile les derniers résultats de Chatbot Arena, SWE-bench, ARC-AGI-2 et OpenClaw PinchBench pour vous proposer des recommandations claires selon quatre critères clés : programmation, raisonnement, tâches d'agent et rapport qualité-prix.
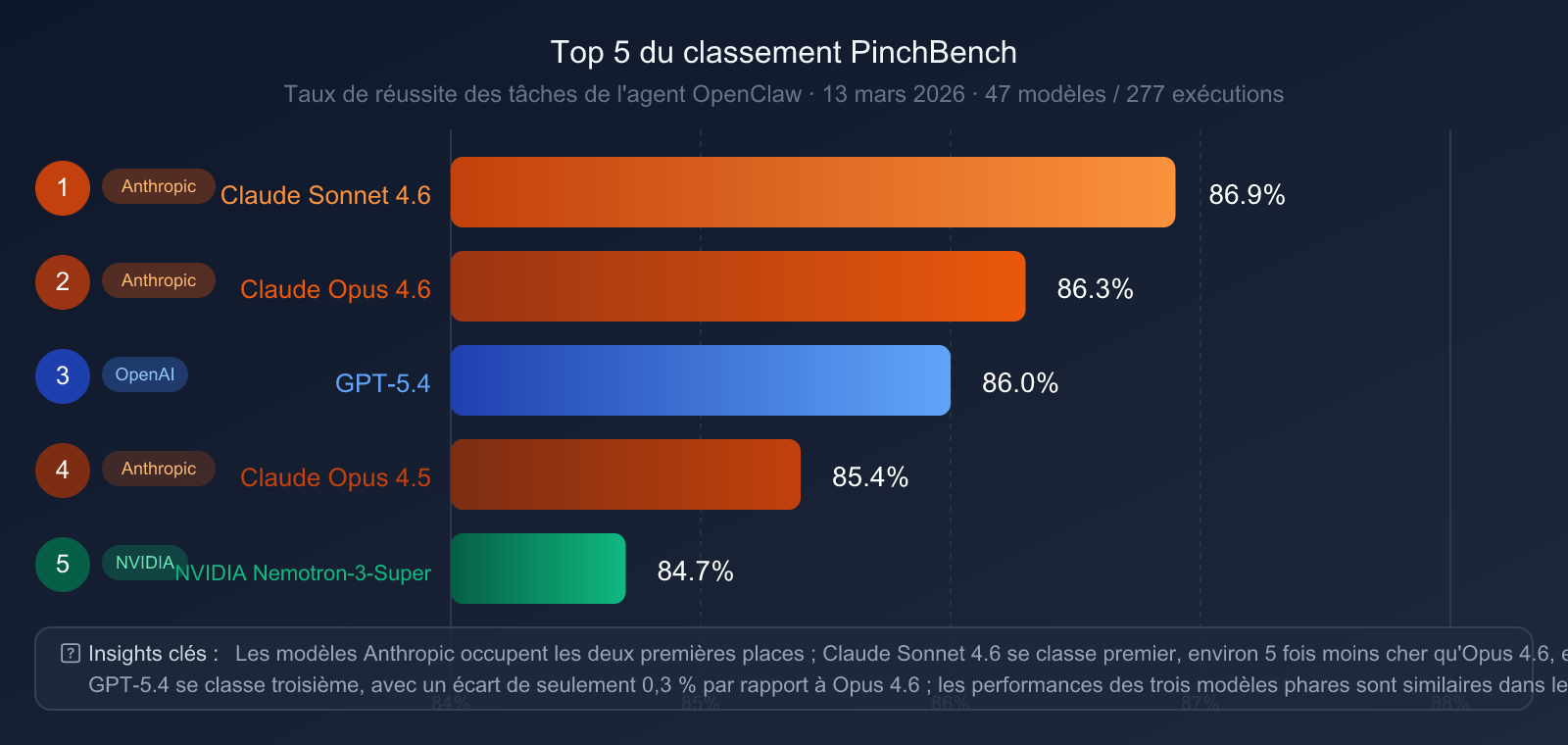
| Rang | Modèle | Taux de réussite PinchBench |
|---|---|---|
| 🥇 1 | Claude Sonnet 4.6 | 86,9 % |
| 🥈 2 | Claude Opus 4.6 | 86,3 % |
| 🥉 3 | GPT-5.4 | 86,0 % |
| 4 | Claude Opus 4.5 | 85,4 % |
| 5 | NVIDIA Nemotron-3-Super | 84,7 % |
Points clés à retenir :
- La série Claude domine le haut du panier : Sonnet 4.6 et Opus 4.6 occupent respectivement la première et la deuxième place, confirmant l'avantage systématique d'Anthropic dans l'ingénierie des agents.
- GPT-5.4 se classe troisième : Avec seulement 0,3 point de pourcentage d'écart avec Opus 4.6, la compétition est extrêmement serrée.
- Le rapport qualité-prix est frappant : Claude Sonnet 4.6 (environ 5 fois moins cher qu'Opus 4.6) obtient un meilleur score sur PinchBench, prouvant que le modèle le plus onéreux n'est pas forcément le plus performant pour ces tâches.
- Claude Sonnet 4.6, le choix de la raison : Pour des tâches d'agents de type OpenClaw, Sonnet 4.6 représente actuellement le meilleur compromis entre coût et efficacité.
🔍 Conseil pour vos projets d'agents : Si vous développez un agent IA basé sur OpenClaw, l'écart entre les trois meilleurs modèles (Sonnet 4.6, Opus 4.6, GPT-5.4) est inférieur à 1 %. Nous vous recommandons de passer par APIYI (apiyi.com) pour un accès flexible à ces modèles. Cela vous permettra de choisir dynamiquement le modèle selon le type de tâche, optimisant ainsi vos coûts tout en maintenant un taux de réussite élevé.
Chatbot Arena ELO : le modèle le plus puissant élu par les utilisateurs
Chatbot Arena (anciennement LMSYS) est actuellement le classement le plus reconnu pour évaluer les préférences des utilisateurs envers les grands modèles de langage. Il génère des scores ELO basés sur des millions de votes lors de tests à l'aveugle en conditions réelles.
Dernier classement de février 2026 (Top 5) :
| Rang | Modèle | Score ELO |
|---|---|---|
| 🥇 1 | Claude Opus 4.6 | 1503 |
| 2 | Grok-4.1-Thinking | 1482 |
| 🥉 3 | GPT-5.4 | 1463 |
| 4 | Gemini 3 Pro | ~1445 |
| 5 | Claude Sonnet 4.6 | ~1438 |
Claude Opus 4.6 devance GPT-5.4 avec un écart de 40 points ELO, se distinguant particulièrement dans les dialogues multi-tours, le contrôle du style et l'écriture créative. Dans le système d'évaluation de Chatbot Arena, un tel écart représente un avantage significatif.
GPT-4.5 (référence historique) : Lancé par OpenAI en février 2025 sous le nom de code "Orion", ce modèle se concentrait sur l'intelligence émotionnelle et la qualité des dialogues. Il a brièvement dominé le classement à sa sortie, mais il a été retiré de l'API le 14 juillet 2025 et a complètement quitté ChatGPT en août 2025. GPT-5.4 est son successeur actuel et le surpasse dans tous les domaines.
Tarifs API et rapport qualité-prix : comment choisir pour les projets sensibles aux coûts
| Poste de dépense | GPT-5.4 | Claude Opus 4.6 | Différence |
|---|---|---|---|
| Prix d'entrée (par million de tokens) | 2,50 $ | 5,00 $ | Opus 4.6 est 2x plus cher |
| Prix de sortie (par million de tokens) | 15,00 $ | 25,00 $ | Opus 4.6 est 1,67x plus cher |
| Fenêtre de contexte | ~1M tokens | 200K (1M en Beta) | Avantage GPT-5.4 |
| Longueur de sortie maximale | — | 128K tokens | Avantage Opus 4.6 |
| Support multimodal | ✅ Entrée d'image | ✅ Entrée d'image | Équivalent |
Estimation des coûts (traitement quotidien de 1 million de tokens en entrée + 200k tokens en sortie) :
- GPT-5.4 : environ 5,50 $/jour (moyenne mensuelle de 165 $)
- Claude Opus 4.6 : environ 10,00 $/jour (moyenne mensuelle de 300 $)
💰 Solution d'optimisation des coûts : Pour les projets à forte charge ou avec un budget limité, nous recommandons d'utiliser Claude Sonnet 4.6 sur APIYI (apiyi.com) pour les tâches quotidiennes. Ne faites appel à l'invocation du modèle Opus 4.6 que lorsque vous avez besoin de la puissance de raisonnement la plus élevée. Cela peut réduire vos coûts API de 60 à 75 %. APIYI propose une facturation unifiée pour plusieurs modèles sur un même compte, ce qui facilite la gestion précise des coûts.
Scénarios recommandés : GPT-5.4 ou Claude Opus 4.6, lequel choisir ?
Scénarios où privilégier GPT-5.4
✅ Tâches générales à haut rapport performance-prix
- Budget limité mais besoin de capacités de pointe.
- Création de contenu quotidienne, support client, extraction d'informations.
- Économies significatives lorsque les frais d'invocation d'API mensuels dépassent 500 $.
✅ Recherche scientifique et questions-réponses techniques
- Leader sur GPQA Diamond, plus performant pour le raisonnement scientifique de niveau doctorat.
- Questions-réponses spécialisées dans les domaines académiques comme la chimie, la physique ou la biologie.
✅ Code complexe de niveau entreprise (Leader sur SWE-bench Pro)
- Gestion de modifications architecturales sur de très larges bases de code.
- Tâches de refactorisation nécessitant une compréhension profonde des dépendances complexes.
✅ Scénarios à fenêtre de contexte ultra-longue
- Besoin de traiter des documents ou des bases de code approchant 1 million de tokens.
- La fenêtre de contexte de 1M d'Opus 4.6 est encore en phase Bêta.
Scénarios où privilégier Claude Opus 4.6
✅ Génération et correction de code de niveau production
- 80,8 % sur SWE-bench Verified, plus fiable pour la correction de bugs et le développement de fonctionnalités au quotidien.
- Capacité de recherche web de 84 % sur BrowseComp, idéal pour les applications enrichies par RAG.
✅ Projets d'agents de type OpenClaw
- Top 2 sur PinchBench, les modèles Anthropic sont systématiquement meilleurs pour les tâches d'agents réels.
✅ Produits exigeant une haute qualité de dialogue
- ELO de 1503 sur Chatbot Arena, numéro 1 mondial pour la satisfaction utilisateur.
- Meilleure cohérence dans les dialogues multi-tours et plus grande adaptabilité de style.
✅ Travail de connaissances spécialisées
- Avance de 16 points sur ARC-AGI-2, raisonnement abstrait plus puissant.
- 90,2 % sur BigLaw Bench, plus fiable pour le juridique, la conformité et l'analyse de documents.
✅ Sortie de documents longs
- Sortie maximale de 128K, parfait pour générer des rapports complets ou des documents longs.
🎯 Conseil de décision par scénario : Chaque modèle a ses forces, les différences se manifestant principalement sur des tâches spécifiques. Nous vous conseillons d'effectuer des tests A/B via la plateforme APIYI (apiyi.com) avant le déploiement officiel. La plateforme propose une interface unifiée permettant de basculer rapidement entre les modèles, vous aidant à trouver le choix optimal pour votre cas d'usage.
Accès rapide : utilisez les deux modèles via une API unique
Pas besoin de créer des comptes séparés chez OpenAI et Anthropic. Avec APIYI, accédez à tous les modèles majeurs via une interface unifiée :
from openai import OpenAI
# Via l'interface unifiée APIYI, supportant GPT-5.4 et Claude Opus 4.6
client = OpenAI(
api_key="your-apiyi-key",
base_url="https://vip.apiyi.com/v1" # Adresse d'accès unifiée APIYI
)
# Appel de Claude Opus 4.6
response_opus = client.chat.completions.create(
model="claude-opus-4-6",
messages=[
{"role": "user", "content": "Aidez-moi à analyser les bugs potentiels dans le code suivant..."}
],
max_tokens=4096
)
# Appel de GPT-5.4 (même interface, il suffit de changer le nom du modèle)
response_gpt = client.chat.completions.create(
model="gpt-5-4",
messages=[
{"role": "user", "content": "Aidez-moi à analyser les bugs potentiels dans le code suivant..."}
],
max_tokens=4096
)
print("Opus 4.6:", response_opus.choices[0].message.content)
print("GPT-5.4:", response_gpt.choices[0].message.content)
💡 Instructions d'accès : Configurez
base_urlsurhttps://vip.apiyi.com/v1et remplacezapi_keypar la clé obtenue sur APIYI (apiyi.com) pour basculer en un clic. Un bonus est offert lors de la première recharge, ce qui facilite le test des différences réelles entre les deux modèles avant la mise en production.
Correspondance des noms de modèles :
| Modèle | Nom d'invocation API | Coût mensuel moyen (100M tokens/mois) |
|---|---|---|
| Claude Opus 4.6 | claude-opus-4-6 |
Env. 500 $+ |
| Claude Sonnet 4.6 | claude-sonnet-4-6 |
Env. 100 $+ |
| GPT-5.4 | gpt-5-4 |
Env. 250 $+ |
Foire aux questions (FAQ)
Q : GPT-4.5 et GPT-5.4 sont-ils le même modèle ?
Non. GPT-4.5 (nom de code "Orion") est un modèle de transition publié par OpenAI en février 2025, axé sur l'intelligence émotionnelle et la qualité du dialogue, avec un tarif extrêmement élevé (75 $ / 150 $ par million de tokens). Il a été officiellement retiré de l'API le 14 juillet 2025. GPT-5.4 est le modèle phare actuel d'OpenAI ; ses capacités surpassent largement celles de GPT-4.5 et son prix a considérablement chuté à 2,50 $ / 15 $ par million de tokens. Pour utiliser le grand modèle de langage le plus puissant d'OpenAI, vous devez choisir GPT-5.4, accessible via le service proxy API de APIYI (apiyi.com).
Q : Qu'est-ce qu'OpenClaw ? Quelle est la différence avec Cursor ou Claude Code ?
OpenClaw est une plateforme d'agents IA open-source et auto-hébergeable. Elle prend en charge l'accès au terminal, l'édition de code multi-fichiers et l'intégration de plus de 50 outils comme WhatsApp, Telegram et Slack. Elle possède également une capacité d'"auto-évolution" pour générer de nouvelles compétences. Comparé à Cursor (un plugin IDE commercial) et Claude Code (le CLI officiel d'Anthropic), l'atout majeur d'OpenClaw est qu'il est entièrement open-source et permet un déploiement privé, ce qui est idéal pour les entreprises soucieuses de la sécurité des données. PinchBench est le benchmark spécifique utilisé pour évaluer les performances des modèles d'IA sur les tâches d'agents OpenClaw.
Q : Quel modèle est le meilleur pour les tâches de rédaction par IA ?
Selon le score ELO de Chatbot Arena, Claude Opus 4.6 se classe premier mondial avec 1503 points lors des tests de préférence des utilisateurs. Il se distingue particulièrement dans l'écriture créative, les dialogues multi-tours et l'adaptation du style rédactionnel. GPT-5.4 est également excellent pour l'écriture, mais son classement en termes de satisfaction utilisateur est légèrement inférieur. Nous vous conseillons de tester vos scénarios d'écriture spécifiques via APIYI (apiyi.com), car les résultats peuvent varier selon le style et le type de tâche.
Q : Quel est l'écart entre Claude Sonnet 4.6 et Claude Opus 4.6 ?
Si l'on regarde les tests d'agents PinchBench, Sonnet 4.6 (86,9 %) est même légèrement supérieur à Opus 4.6 (86,3 %). Sur Chatbot Arena ELO, Sonnet 4.6 obtient environ 1438 points contre 1503 pour Opus 4.6, soit un écart d'environ 65 points. Pour la plupart des tâches de programmation et d'analyse, Sonnet 4.6 est le choix le plus rentable (son prix est environ 20 % de celui d'Opus 4.6). Le passage à Opus 4.6 ne se justifie que pour le raisonnement complexe, le traitement de documents longs et les scénarios exigeant une précision extrême.
Résumé : Quel modèle phare choisir en 2026 ?
| Scénario d'utilisation | Modèle recommandé | Raison principale |
|---|---|---|
| Développement quotidien + Maîtrise des coûts | GPT-5.4 | 50 % moins cher, capacités globales solides |
| Correction de code complexe (SWE-bench) | Claude Opus 4.6 | 80,8 %, devant les 77,2 % de GPT-5.4 |
| Tâches d'agents IA (OpenClaw) | Claude Sonnet 4.6 | N°1 sur PinchBench, moins cher qu'Opus |
| Produits de chat / Satisfaction utilisateur | Claude Opus 4.6 | N°1 au classement ELO Chatbot Arena (1503) |
| Recherche scientifique / Questions académiques | GPT-5.4 | GPQA Diamond à 93,2 %, légère avance |
| Analyse de documents ultra-longs | Claude Opus 4.6 | Sortie 128K + MRCR v2 à 76 % |
| Raisonnement abstrait / Tâches AGI | Claude Opus 4.6 | ARC-AGI-2 à 68,8 % vs 52,9 % |
Points clés à retenir :
- GPT-5.4 offre le meilleur rapport qualité-prix global. Son indice d'intelligence synthétique est légèrement supérieur (57 vs 53) pour un prix environ deux fois moins élevé qu'Opus 4.6.
- Claude Opus 4.6 est le modèle avec la meilleure satisfaction utilisateur au monde (ELO 1503), avec des avantages marqués pour le code complexe, les agents et le raisonnement abstrait.
- Pour la majorité des projets réels, Claude Sonnet 4.6 est la solution la plus équilibrée : il est classé premier sur PinchBench tout en étant bien moins cher qu'Opus 4.6.
Il n'y a pas de modèle "parfait dans l'absolu", seulement celui qui convient le mieux à votre cas d'usage.
🚀 Testez dès maintenant : Sur la plateforme APIYI (apiyi.com), vous pouvez utiliser une seule clé API pour accéder simultanément à GPT-5.4, Claude Opus 4.6 et Claude Sonnet 4.6. Comparez les performances et les coûts de ces trois modèles avec vos propres données métier. Les nouveaux utilisateurs reçoivent un crédit de test lors de leur inscription pour les aider à prendre la meilleure décision avant la mise en production.
Source des données : Documentation officielle d'Anthropic, documentation API d'OpenAI, classement Chatbot Arena (février 2026), classement PinchBench (13 mars 2026), comparatifs Artificial Analysis et évaluations techniques DigitalApplied. Les données peuvent évoluer avec les mises à jour des modèles ; veuillez vous référer aux documents officiels les plus récents.
Auteur : Équipe APIYI | Publié sur AI123.dev