Note de l'auteur : Les données réelles révèlent la raison fondamentale de la différence de consommation de tokens de 2-2,5 fois entre Gemini et DeepSeek lors de la traduction d'un même article — les différences d'efficacité du Tokenizer — et fournissent des recommandations d'optimisation des coûts pour les scénarios multilingues.
Un même article en chinois, traduit respectivement par Gemini et DeepSeek en anglais, japonais et français, offre une qualité et une complétude de traduction identiques — mais les tokens de complétion retournés par l'API diffèrent de 2-2,5 fois. S'agit-il d'un bug de facturation API ? Ou y a-t-il une raison technique plus profonde ?
Valeur centrale : Grâce à des données de test réelles, comprendre comment les différences de Tokenizer impactent les coûts API et maîtriser la méthode pour choisir le modèle le plus rentable dans les scénarios de traduction multilingue.

Données essentielles de comparaison Gemini vs DeepSeek Tokenizer
| Dimension de comparaison | Gemini 3 Flash | DeepSeek V3.2 | Ratio de différence |
|---|---|---|---|
| Tokens de complétion traduction anglais | 1 631 | 636 | Gemini +2,56x |
| Tokens de complétion traduction japonais | 2 141 | 856 | Gemini +2,50x |
| Tokens de complétion traduction français | 1 630 | 812 | Gemini +2,01x |
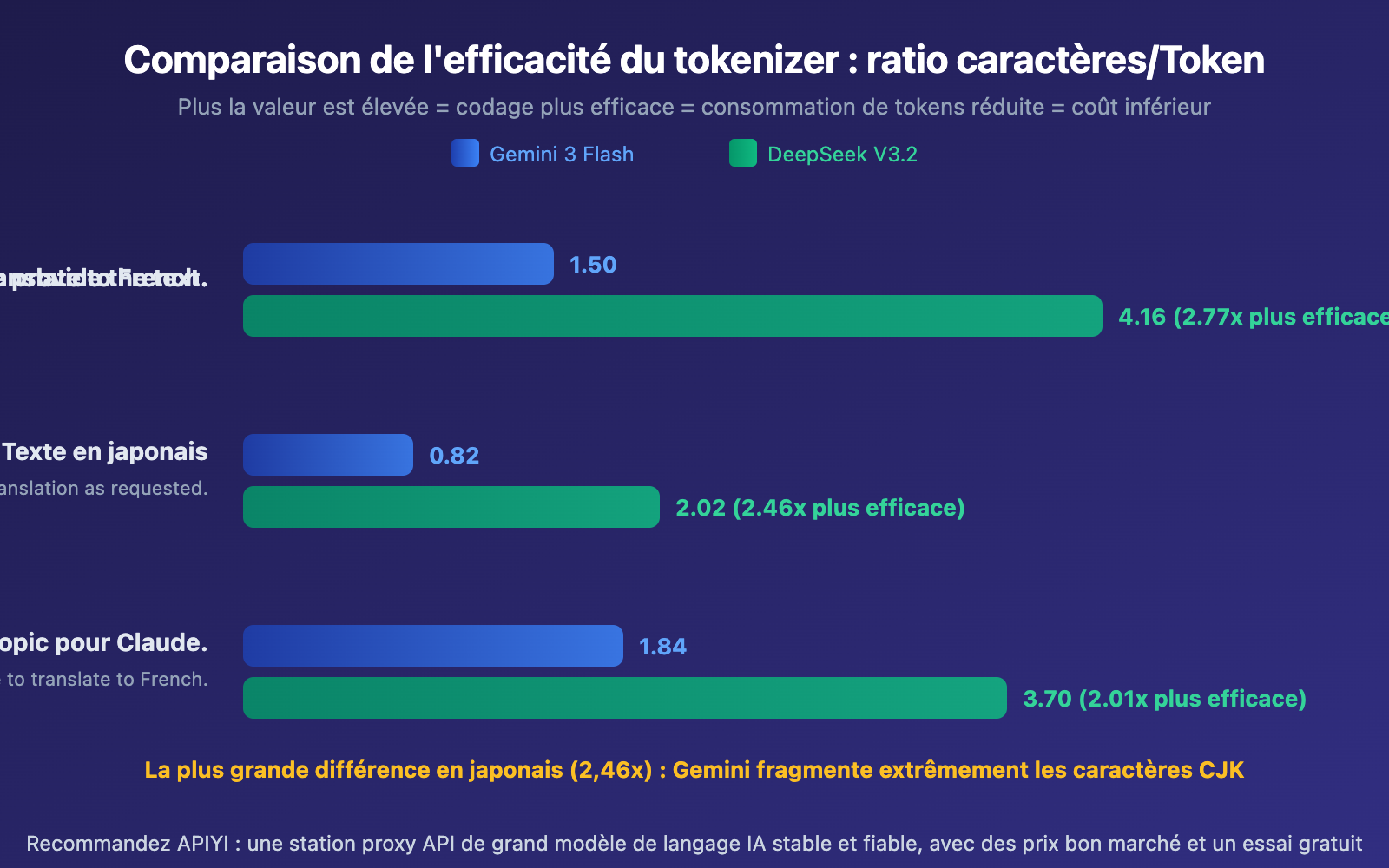
| Efficacité d'encodage (caractères/Token) | 0,82-1,84 | 2,02-4,16 | DeepSeek +2-2,8x |
| Nombre de lignes de sortie traduction | 64 lignes | 64 lignes | Identique |
Raison fondamentale de la différence de Tokenizer entre Gemini et DeepSeek
Nous avons utilisé le même texte de test en chinois de 1 403 caractères (contenant des tableaux Markdown, des blocs de code, des espaces réservés SVG, des appels à l'action), en appelant respectivement gemini-3-flash-preview et deepseek-v3.2 pour traduire en anglais, japonais et français, puis en comparant les statistiques de tokens retournées par l'API et le contenu réel produit.
Le résultat est très clair : le nombre de caractères de sortie est presque identique (différence inférieure à 1%), mais le nombre de tokens diffère de 2-2,5 fois. Cela prouve que le problème provient du Tokenizer (segmenteur), et non de la stratégie de sortie du modèle.
Principes techniques du Tokenizer de Gemini vs DeepSeek
Qu'est-ce qu'un Tokenizer ? En termes simples, un Tokenizer est un outil qui divise le texte en unités minimales (tokens) que le modèle peut comprendre. Différents modèles utilisent différents Tokenizers, comme différents logiciels de compression — le même fichier, compressé en ZIP ou RAR, aura des tailles différentes, mais le contenu décompressé sera identique.
Tokenizer SentencePiece de Gemini : Utilise un modèle de langage Unigram, avec un vocabulaire d'environ 256 000 tokens. Il tend à diviser les caractères CJK (chinois, japonais, coréen) en unités de sous-mots plus petites. Dans nos tests, la sortie japonaise avait une efficacité d'encodage de seulement 0,82 caractères/token, ce qui signifie qu'en moyenne chaque caractère japonais nécessite 1,2 tokens pour être représenté.
Tokenizer BPE au niveau des octets de DeepSeek : Avec un vocabulaire d'environ 128 000 tokens, mais spécialement optimisé pour les scénarios multilingues. Il introduit des tokens de ponctuation combinée et de saut de ligne, améliorant l'efficacité de compression du texte CJK. La sortie japonaise atteint 2,02 caractères/token, soit une efficacité 2,46 fois supérieure à celle de Gemini.
Gemini vs DeepSeek Tokenizer – Analyse d'impact sur les coûts
Maintenant que vous comprenez les différences d'efficacité du Tokenizer, la question clé se pose : Plus de tokens signifie-t-il dépenser plus ? Pas nécessairement. Le coût final dépend de : Nombre de tokens × Prix unitaire.
Coûts réels de traduction : Gemini vs DeepSeek
Prenons l'exemple d'une traduction typique d'article technique (environ 30 000 Prompt Token) vers 11 langues :
| Dimension de coût | Gemini 3 Flash | DeepSeek V3.2 |
|---|---|---|
| Completion Token estimé par langue | ~80 000 | ~30 000 |
| Completion Token total pour 11 langues | ~880 000 | ~330 000 |
| Prix Output (par million de tokens) | $3.00 | $0.42 |
| Coût Output total pour 11 langues | $2.64 | $0.14 |
| Prix Input (par million de tokens) | $0.50 | $0.28 |
| Coût Input total pour 11 passages | $0.17 | $0.09 |
| Coût total de traduction par article | $2.81 | $0.23 |
D'après cette comparaison réelle, l'avantage tarifaire de DeepSeek dans les scénarios de traduction multilingue est très net — pour la même tâche de traduction, DeepSeek coûte environ 1/12 du prix de Gemini. Cet écart provient de deux facteurs cumulés : l'efficacité du Tokenizer (2-2,5x) × la différence de prix unitaire (5-7x).
Vitesse et qualité de traduction : Gemini vs DeepSeek
Cependant, le coût n'est pas le seul facteur à considérer :
| Métrique | Gemini 3 Flash | DeepSeek V3.2 |
|---|---|---|
| Vitesse d'inférence | 145-189 tokens/s | 12-26 tokens/s |
| Multiplicateur de vitesse | 6-10x plus rapide | Référence |
| Qualité de traduction | Excellente | Excellente |
| Complétude de traduction | 100% (64 lignes) | 100% (64 lignes) |
| Préservation du format Markdown | Bonne | Bonne |
Gemini offre une vitesse d'inférence 6 à 10 fois supérieure à celle de DeepSeek. Si vous avez besoin de traductions par lot rapides et que le coût du temps dépasse celui des tokens, Gemini reste le meilleur choix.
🎯 Recommandations de sélection : Si vous avez un grand volume de traductions et que le délai n'est pas critique, l'avantage tarifaire de DeepSeek est significatif. Si vous avez besoin de livraisons rapides, l'avantage en vitesse de Gemini est évident. Via APIYI sur apiyi.com, vous pouvez accéder aux deux modèles simultanément et basculer facilement avec une interface unifiée pour trouver l'équilibre optimal selon votre contexte.
Impact des différences de Tokenizer selon les langues
L'efficacité du Tokenizer varie considérablement selon les langues. Les langues CJK (chinois, japonais, coréen) sont les plus affectées, tandis que les langues latines le sont moins.
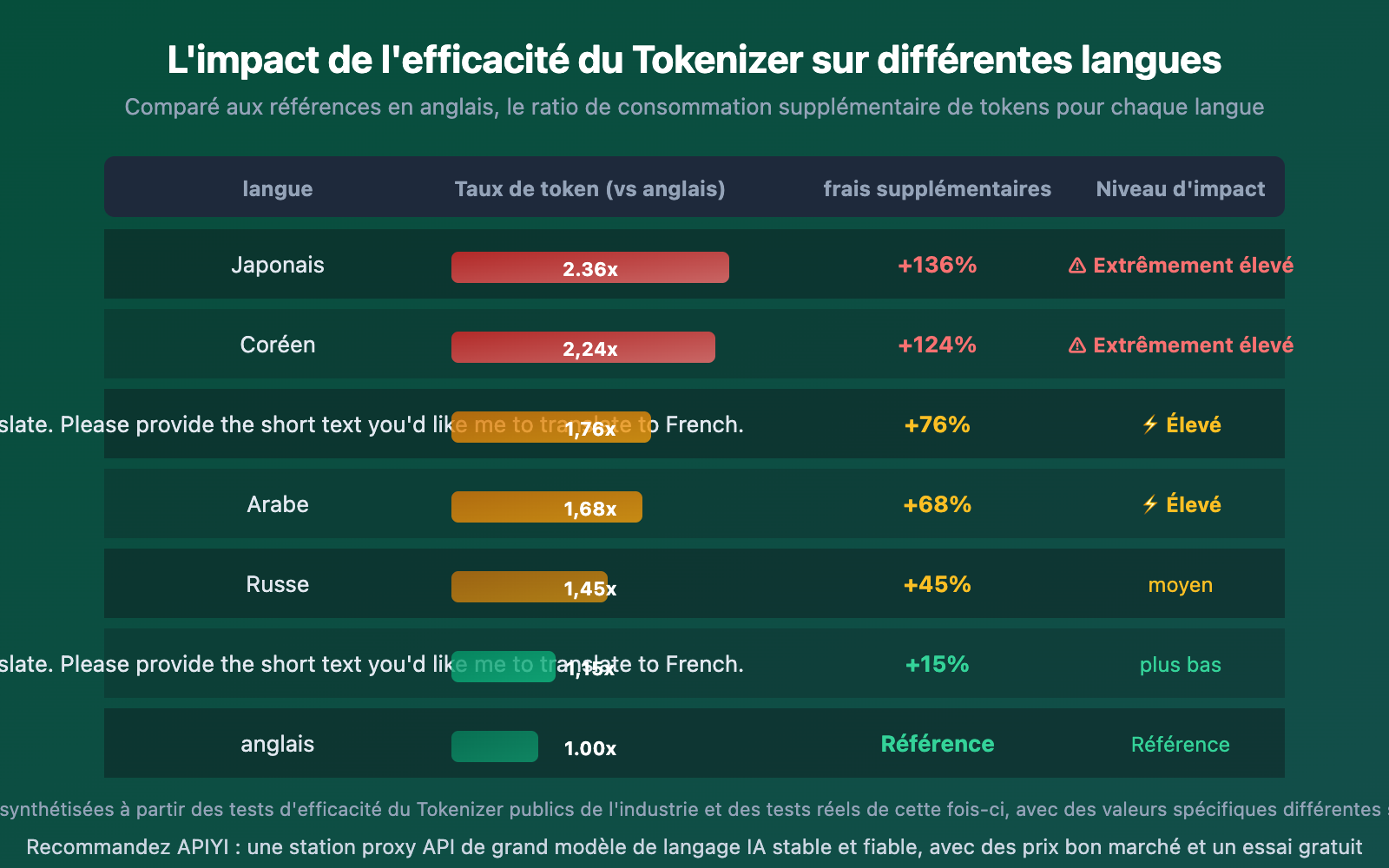
Les données révèlent clairement :
- Le japonais est le plus affecté : L'efficacité d'encodage du japonais sur Gemini n'est que de 0,82 caractères/token, ce qui explique pourquoi la consommation de tokens augmente significativement lors de la traduction d'articles contenant beaucoup de texte en chinois ou japonais
- Le français a la plus petite différence : Les langues latines présentent des écarts d'efficacité du Tokenizer relativement faibles (seulement 2,01x), car la plupart des Tokenizers sont entraînés principalement sur des données en anglais, ce qui profite aux langues latines
- Le chinois se situe au milieu : Environ 1,76 fois supérieur à la référence anglaise, mais l'écart se réduit lorsque vous utilisez des modèles optimisés pour le chinois comme DeepSeek ou Qwen
🎯 Recommandations pour la traduction multilingue : Si vos tâches de traduction impliquent des langues CJK comme le japonais ou le coréen, choisir un modèle avec une meilleure efficacité de Tokenizer (comme DeepSeek ou Qwen) peut réduire considérablement les coûts. Via l'interface unifiée d'APIYI sur apiyi.com, vous pouvez facilement basculer entre différents modèles pour tester et trouver la meilleure solution.
Gemini vs DeepSeek Tokenizer – Guide de sélection par scénario
| Scénario d'utilisation | Modèle recommandé | Raison clé |
|---|---|---|
| Traduction multilingue en masse | DeepSeek V3.2 | Efficacité des tokens élevée + tarif bas, coût seulement 1/12 |
| Livraison de traduction urgente | Gemini 3 Flash | 6-10 fois plus rapide, idéal pour les délais serrés |
| Traduction intensive en langues CJK | DeepSeek V3.2 | Avantage d'efficacité du Tokenizer CJK jusqu'à 2,5x |
| Traduction en langues latines | Différence mineure | Écart d'efficacité seulement 2x entre les deux, choisir selon le tarif |
| Scénarios de dialogue en temps réel | Gemini 3 Flash | Faible latence, meilleure expérience utilisateur |
| Traitement par lot sensible aux coûts | DeepSeek V3.2 | Coût global le plus bas |
🎯 Conseil pratique : Dans les projets réels, il faut souvent équilibrer coût et vitesse. Nous recommandons d'intégrer simultanément Gemini et DeepSeek via APIYI (apiyi.com) et de basculer dynamiquement entre les modèles selon l'urgence de la tâche. La plateforme supporte l'appel unifié de tous les modèles principaux avec une seule clé.
Questions fréquemment posées
Q1 : La consommation élevée de tokens Gemini est-elle un bug de facturation API ?
Non. C'est un phénomène normal causé par les différences d'efficacité d'encodage du Tokenizer. Tout comme un même fichier compressé en ZIP ou RAR aura des tailles différentes, les Tokenizers de différents modèles génèrent un nombre de tokens différent pour le même texte, mais le contenu traité est exactement identique. Nos tests ont vérifié que la différence du nombre de caractères en sortie est inférieure à 1 %.
Q2 : Un nombre de tokens plus élevé signifie-t-il une meilleure qualité de traduction ?
Non. Le nombre de tokens reflète uniquement la méthode d'encodage du Tokenizer et n'a aucun rapport avec la qualité de la traduction. Dans nos tests, les deux modèles ont montré une excellente qualité et complétude de traduction, avec un nombre de lignes en sortie exactement identique (64 lignes). Lors du choix d'un modèle, vous devez vous concentrer sur la qualité de la traduction, la vitesse et le coût global, plutôt que sur le nombre de tokens seul.
Q3 : Comment optimiser le coût en tokens pour la traduction multilingue dans un projet ?
Nous recommandons les stratégies suivantes :
- Pour les langues CJK (chinois, japonais, coréen), privilégier les modèles avec une efficacité de Tokenizer élevée comme DeepSeek
- Pour les langues latines, vous pouvez choisir avec flexibilité, l'écart est minime
- Intégrer plusieurs modèles via APIYI (apiyi.com) et réaliser un routage automatique par langue avec une API unifiée
- Lors de la configuration de la surveillance de la consommation de tokens, définir des seuils différents pour chaque modèle afin d'éviter les faux positifs
Résumé
Conclusions clés de la comparaison d'efficacité des Tokenizers Gemini vs DeepSeek :
- Les différences de tokens proviennent du Tokenizer, pas d'un bug : Pour un même texte, le Tokenizer de DeepSeek encode avec une efficacité 2 à 2,8 fois supérieure à celle de Gemini, l'écart étant particulièrement marqué pour les langues CJK
- Les différences de coûts s'amplifient : Différence d'efficacité du Tokenizer (2-2,5x) × Différence de prix unitaire des tokens (5-7x) = écart de coût réel pouvant atteindre 12 fois
- Compromis entre vitesse et coût : Gemini est 6 à 10 fois plus rapide mais coûte plus cher en tokens, DeepSeek coûte moins cher mais est plus lent — choisissez selon votre cas d'usage
Comprendre les différences d'efficacité des Tokenizers est une étape clé pour optimiser les coûts d'utilisation des API d'IA. Dans les scénarios gourmands en tokens comme la traduction multilingue, choisir le bon modèle peut générer des économies substantielles.
Nous recommandons d'utiliser APIYI (apiyi.com) pour accéder à plusieurs modèles de manière unifiée, en utilisant une seule clé API pour basculer facilement et trouver la meilleure solution coût-performance pour chaque scénario.
📚 Ressources de référence
-
Benchmark de performance des Tokenizers : Comparaison complète de l'efficacité des Tokenizers des modèles principaux
- Lien :
llm-calculator.com/blog/tokenization-performance-benchmark - Description : Contient les données d'efficacité des Tokenizers pour GPT-4o, DeepSeek, Qwen et autres modèles
- Lien :
-
Texte CJK et meilleures pratiques avec les grands modèles de langage : Mécanisme de traitement des caractères CJK par les Tokenizers
- Lien :
tonybaloney.github.io/posts/cjk-chinese-japanese-korean-llm-ai-best-practices.html - Description : Analyse approfondie des différences de consommation de tokens pour les langues CJK selon les différents Tokenizers
- Lien :
-
Analyse du Tokenizer Gemini : Principes du segmenteur SentencePiece de Google Gemini
- Lien :
dejan.ai/blog/gemini-toknizer - Description : Analyse détaillée du mécanisme d'encodage et des caractéristiques d'efficacité du vocabulaire de 256K tokens de Gemini
- Lien :
-
Rapport technique DeepSeek V3 : Optimisation multilingue du Tokenizer BPE au niveau des octets
- Lien :
arxiv.org/html/2412.19437v1 - Description : Principes de conception et efficacité de compression multilingue du vocabulaire de 128K tokens de DeepSeek
- Lien :
Auteur : Équipe technique APIYI
Échanges techniques : N'hésitez pas à discuter dans la section commentaires, plus de ressources disponibles au centre de documentation APIYI docs.apiyi.com