Note de l'auteur : Je vous explique pas à pas comment intégrer gpt-image-2 dans Chatbox via un point de terminaison personnalisé, et pourquoi Chatbox ne permet pas, contrairement à l'interface web de ChatGPT, de modifier des images via une conversation continue. Tout repose sur la différence d'architecture entre les trois points de terminaison : images/generations, chat/completions et l'API Responses.
De nombreux utilisateurs configurent leur clé API OpenAI dans le client Chatbox et tentent d'utiliser gpt-image-2 pour générer des images, mais se retrouvent face à des erreurs ou des caractères illisibles. Cet article vous apporte deux réponses : premièrement, la méthode correcte pour connecter gpt-image-2 à Chatbox (en configurant le point de terminaison personnalisé sur https://api.apiyi.com/v1/images/generations) ; deuxièmement, et c'est le plus important, pourquoi Chatbox ne peut pas "générer une image puis la modifier par la discussion" comme le fait ChatGPT.
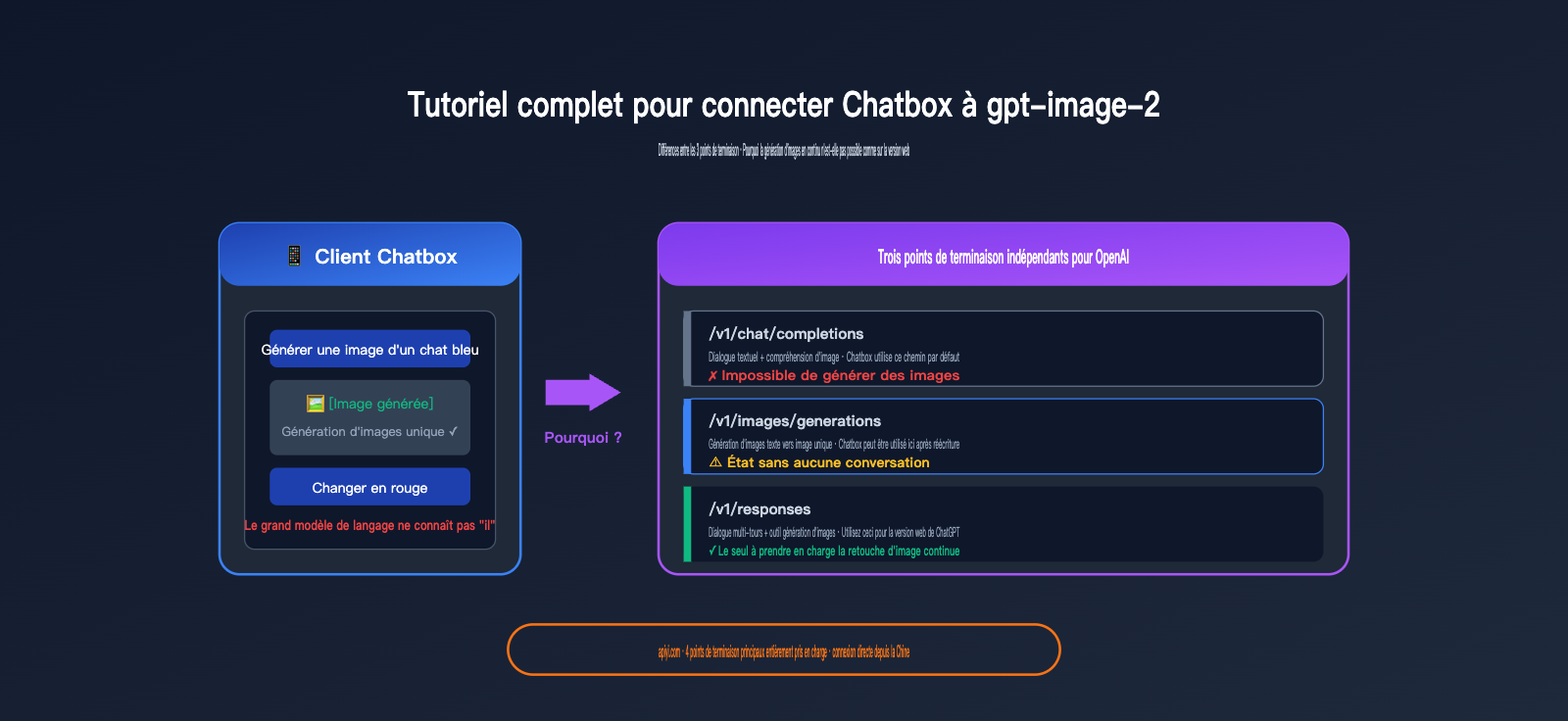
Ce n'est pas un bug de Chatbox, mais le fait qu'OpenAI a réparti la génération d'images, la complétion de chat et l'édition multi-tours sur trois points de terminaison API totalement distincts. Le chemin par défaut utilisé par Chatbox ne prend tout simplement pas en charge l'édition d'images en continu.
Valeur ajoutée : Après avoir lu cet article, vous comprendrez parfaitement les limites et les différences de capacités des trois points de terminaison principaux d'OpenAI. Vous saurez quand Chatbox suffit, quand il est nécessaire de basculer vers l'API Responses, et comment utiliser le service proxy API d'APIYI pour invoquer n'importe quel point de terminaison de manière stable en Chine.
Quelle est la bonne manière d'intégrer gpt-image-2 dans Chatbox ?
Commençons par le plus pratique : si vous voulez que Chatbox puisse générer des images avec gpt-image-2 immédiatement, suivez ces étapes et vous aurez terminé en 5 minutes.
Configuration essentielle pour intégrer gpt-image-2 dans Chatbox
Par défaut, Chatbox appelle l'API via la méthode de "complétion de chat" (le point de terminaison /v1/chat/completions), mais gpt-image-2 n'est pas un modèle de conversation, c'est un modèle pur de génération d'images, dont le point de terminaison est /v1/images/generations. Vous devez donc utiliser la fonction "Point de terminaison personnalisé" de Chatbox pour remplacer l'adresse par défaut.
Étapes de configuration complètes :
| Étape | Action | Paramètre clé |
|---|---|---|
| 1 | Ouvrir les paramètres de Chatbox → Fournisseur de modèle → Ajouter un fournisseur personnalisé | Choisir le mode compatible OpenAI API |
| 2 | Hôte API | https://api.apiyi.com |
| 3 | Chemin API (modification cruciale) | /v1/images/generations |
| 4 | Clé API | Jeton Bearer obtenu dans la console APIYI |
| 5 | Champ Modèle | gpt-image-2 |
| 6 | Délai d'expiration | Régler sur ≥ 360 secondes |
Exemple d'appel minimal pour gpt-image-2 dans Chatbox
Voici l'exemple d'appel curl recommandé officiellement, vous pouvez l'utiliser pour vérifier si votre clé API est fonctionnelle :
curl --request POST \
--url https://api.apiyi.com/v1/images/generations \
--header 'Authorization: Bearer sk-your-apiyi-key' \
--header 'Content-Type: application/json' \
--data '{
"model": "gpt-image-2",
"prompt": "Format paysage 16:9, vieux phare au bord de la mer au crépuscule"
}'
Une fois ce curl validé, retournez dans Chatbox et modifiez le point de terminaison par /v1/images/generations, et le tour est joué.
🎯 Conseil de configuration : Lors de la première configuration d'un point de terminaison personnalisé dans Chatbox, il est conseillé de vérifier d'abord la clé API et le chemin du point de terminaison avec curl. Nous vous suggérons d'utiliser la plateforme APIYI apiyi.com pour obtenir un crédit de test ; le crédit gratuit est suffisant pour effectuer toute la vérification de configuration.
Erreurs de configuration fréquentes avec gpt-image-2 dans Chatbox
Voici les 5 pièges les plus courants rencontrés par les utilisateurs :
| Symptôme d'erreur | Cause profonde | Solution |
|---|---|---|
Retourne model not found |
Utilisation du point de terminaison /v1/chat/completions |
Remplacer par /v1/images/generations |
Retourne invalid prompt format |
Utilisation du format messages du chat |
Utiliser le champ prompt (chaîne de caractères) |
| Délai d'expiration après 60s | Délai par défaut trop court | Augmenter à ≥ 360s (nécessaire pour la haute qualité) |
| L'image ne s'affiche pas | Chatbox ne décode pas le b64_json |
Configurer la réponse au format url |
| Erreur avec prompt en chinois | Problème d'encodage | Vérifier Content-Type: application/json; charset=utf-8 |
Pourquoi Chatbox ne permet-il pas de modifier des images en continu avec gpt-image-2 ?
C'est le point technique crucial de cet article. De nombreux utilisateurs, après avoir configuré l'outil, demandent : « Pourquoi, lorsque je génère une image dans Chatbox et que je demande ensuite "change le ciel en bleu", le modèle ne comprend-il absolument rien ? Alors que la version web de ChatGPT permet des modifications continues illimitées ? »
La réponse n'est pas un bug de Chatbox, mais une limitation inhérente aux points de terminaison (endpoints) eux-mêmes.
Limitations de l'architecture des points de terminaison de Chatbox avec gpt-image-2
Pour bien comprendre ce problème, il faut distinguer les trois points de terminaison indépendants fournis officiellement par OpenAI :
| Point de terminaison | Chemin | Objectif de conception | Génération d'images | État de la conversation |
|---|---|---|---|---|
| Chat Completions | /v1/chat/completions |
Complétion de texte | ❌ Entrée image seule | ❌ Géré par le client |
| Image Generations | /v1/images/generations |
Génération unique | ✅ Génération seule | ❌ Sans état |
| Image Edits | /v1/images/edits |
Édition/Image vers image | ✅ Édition | ❌ Sans état |
| Responses API | /v1/responses |
Dialogue + outils | ✅ Appel d'outils | ✅ Géré par le serveur |
La vérité en bref :
- Chatbox utilise par défaut
/v1/chat/completions— ce point de terminaison ne prend pas en charge la génération d'images. - Si vous modifiez le chemin vers
/v1/images/generations, vous pouvez générer des images, mais ce point de terminaison est totalement sans état : chaque requête est isolée. - La version web de ChatGPT utilise en coulisses
/v1/responses: elle intègre l'appel à l'outilimage_generationet gère l'état de la conversation côté serveur.

Pourquoi la version web de ChatGPT peut-elle modifier les images en continu ?
Le flux de travail de la version web de ChatGPT est le suivant :
- Vous saisissez "Dessine un chat bleu".
- ChatGPT appelle le point de terminaison
/v1/responses, le modèle décide d'appeler l'outilimage_generation. - L'outil renvoie un ID d'image (par exemple
ig_abc123) et l'enregistre dans l'état de la session côté serveur. - Vous dites ensuite "Change-le en rouge".
- ChatGPT appelle à nouveau
/v1/responsesen transmettant leprevious_response_id. - Le modèle identifie, grâce au contexte, que "le" fait référence à l'image précédente et appelle l'action
editde l'outilimage_generation. - L'outil effectue l'édition sur la base de l'image précédente et renvoie la nouvelle image.
La clé de tout ce processus réside dans le trio previous_response_id + état de la conversation côté serveur + outil image_generation intégré — trois capacités dont le point de terminaison /v1/images/generations est totalement dépourvu.
Les limites de l'architecture actuelle de Chatbox
Chatbox est un client de type Chat Completions : son modèle de données central est un "tableau de messages" (messages système / utilisateur / assistant multi-tours). Son mécanisme de fonctionnement est le suivant :
- Ajouter chaque message de l'utilisateur au tableau de messages.
- Appeler un point de terminaison de style chat (par défaut
/v1/chat/completions). - Ajouter la réponse au tableau de messages.
- Boucler.
Lorsque vous modifiez le point de terminaison vers /v1/images/generations, Chatbox change simplement le chemin de la requête, mais le tableau de messages continue d'être envoyé au format chat, et le point de terminaison n'accepte qu'une invite unique : l'état de la conversation ne peut absolument pas être transmis.
💡 Analyse technique : La conception centrale de Chatbox repose sur l'hypothèse que "le point de terminaison est de style chat", alors qu'OpenAI a conçu la génération et l'édition d'images comme des points de terminaison de ressources RESTful indépendants. Il s'agit d'une incompatibilité au niveau de l'architecture. Nous vous suggérons de tester d'abord la génération unique via
/v1/images/generationssur la plateforme APIYI (apiyi.com). Une fois les résultats validés, vous pourrez planifier une éventuelle migration vers l'API Responses.
Limites et alternatives pour l'intégration de gpt-image-2 dans Chatbox
Maintenant que nous connaissons les restrictions, voici une liste claire de ce qui est possible ou non.
Ce que Chatbox + gpt-image-2 peut faire
| Scénario | Supporté | Remarques |
|---|---|---|
| Générer une image à partir d'une seule invite | ✅ | Utilisation standard |
| Invites en chinois et en anglais | ✅ | Support natif par gpt-image-2 |
| Définir la taille/le ratio | ✅ | Via le paramètre size |
| Définir la qualité (standard/high) | ✅ | Via le paramètre quality |
| Sortie URL ou base64 | ✅ | Via le paramètre response_format |
Ce que Chatbox + gpt-image-2 ne peut pas faire
| Scénario | Supporté | Alternative |
|---|---|---|
| Modifier une image après génération (ex: "mets-la en rouge") | ❌ | Passer à l'API Responses |
| Ajuster les détails via des itérations multiples | ❌ | Passer à l'API Responses |
| Édition locale avec image + invite | ❌ Chatbox non supporté | Passer à /v1/images/edits ou API Responses |
| Fusionner plusieurs images de référence | ❌ Chatbox non supporté | Passer à l'API Responses |
| Historique de conversation côté serveur | ❌ | Passer à l'API Responses |
Code minimal pour une génération d'images continue avec l'API Responses
Si vous avez besoin d'une "modification d'image conversationnelle", vous devez abandonner le client Chatbox et écrire votre propre code pour appeler le point de terminaison /v1/responses :
from openai import OpenAI
client = OpenAI(
api_key="sk-your-apiyi-key",
base_url="https://api.apiyi.com/v1",
timeout=600.0
)
# Première itération : générer l'image initiale
resp1 = client.responses.create(
model="gpt-5", # L'API Responses nécessite la série gpt-5
input="Dessine un chat bleu qui se promène au clair de lune, style réaliste",
tools=[{"type": "image_generation"}]
)
response_id_1 = resp1.id
print("Première image :", resp1.output[-1])
# Deuxième itération : modification basée sur la précédente (le point clé est previous_response_id)
resp2 = client.responses.create(
model="gpt-5",
previous_response_id=response_id_1, # Chaînage de l'état de la conversation
input="Change sa couleur en orange, et remplace le fond par un lever de soleil",
tools=[{"type": "image_generation"}]
)
print("Après modification :", resp2.output[-1])
Points importants à noter :
- Vous devez utiliser
gpt-5ou un modèle plus récent (gpt-image-2 ne peut pas être appelé directement comme modèle de conversation). - Vous devez transmettre
tools=[{"type": "image_generation"}]pour activer les outils. - Vous devez utiliser
previous_response_idpour lier l'historique de la conversation, sinon le modèle ne saura pas à quoi fait référence "sa".
🚀 Conseil d'intégration : Lors de l'utilisation de l'API Responses pour une génération continue, réglez
base_urlsurhttps://api.apiyi.com/v1. Les champs sont strictement identiques à ceux d'OpenAI ; il suffit de modifier une ligne debase_urldans votre code SDK OpenAI existant pour basculer. Nous recommandons de passer par APIYI (apiyi.com) pour une connexion stable et directe depuis la France.
Guide pratique de configuration pour intégrer gpt-image-2 dans Chatbox
Maintenant que les bases théoriques sont posées, voici un guide complet "pas à pas" pour vous lancer.
Étape 1 : Obtenir votre clé API sur la plateforme APIYI
- Connectez-vous à la console APIYI sur
api.apiyi.com - Une fois connecté, accédez à la page « Jetons API » (API Tokens).
- Créez un nouveau jeton (il est recommandé d'utiliser un jeton distinct pour chaque projet).
- Copiez l'intégralité du jeton Bearer (commençant par
sk-).
Étape 2 : Configurer le fournisseur personnalisé dans Chatbox
Dans Chatbox, procédez comme suit :
- Ouvrez les « Paramètres » → « Fournisseur de modèle ».
- Cliquez sur « Ajouter » → sélectionnez « Fournisseur compatible OpenAI personnalisé ».
- Remplissez les champs suivants :
Nom : APIYI - Génération d'images
Hôte API : https://api.apiyi.com
Chemin API : /v1/images/generations # Crucial ! Doit être modifié
Clé API : sk-votre-clé-apiyi
Modèle par défaut : gpt-image-2
- Paramètres avancés :
- Délai d'expiration de la requête : 600 secondes
- Nombre de tentatives : 2
- Encodage des caractères : UTF-8
Étape 3 : Envoyer une invite de test
Dans la zone de discussion de Chatbox, saisissez :
Format cinéma 16:9, vieux phare au bord de la mer au crépuscule,
tons chauds et doux, brume sur la mer, résolution 2K
Si la configuration est correcte, vous devriez recevoir l'image générée en 1 à 3 minutes.
Étape 4 : Dépannage rapide
| Problème | Point à vérifier |
|---|---|
| Aucun contenu retourné | Vérifiez que la clé API est complète et dispose des droits de génération d'images |
| Code d'erreur 401 | Clé API incorrecte ou expirée, générez-en une nouvelle |
| Code d'erreur 404 | Erreur de saisie dans le chemin API, confirmez /v1/images/generations |
| Code d'erreur 429 | Limite de débit atteinte, attendez quelques minutes avant de réessayer |
| Délai d'expiration (timeout) | Délai trop court, augmentez à 600 secondes |
💡 Conseil avancé : Si vous devez intégrer gpt-image-2 dans votre propre application plutôt que dans un client de bureau, nous vous recommandons d'utiliser directement le SDK officiel d'OpenAI pour appeler
/v1/images/generations— c'est beaucoup plus flexible que Chatbox. Nous suggérons de passer par APIYI apiyi.com en remplaçantbase_urlparhttps://api.apiyi.com/v1.
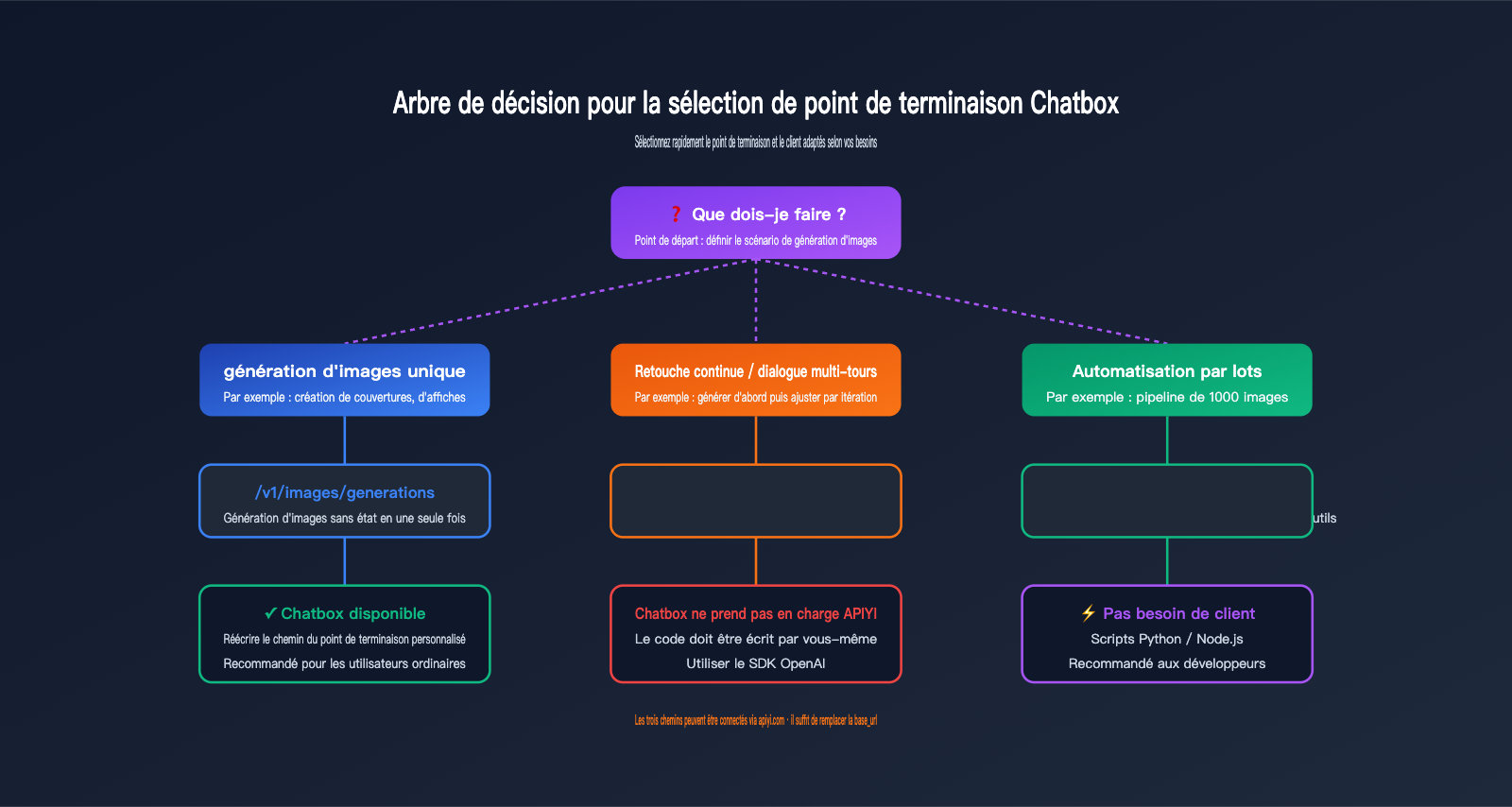
Guide de décision pour le choix des points de terminaison
Ce tableau décisionnel vous aidera à déterminer rapidement quel point de terminaison utiliser selon votre scénario :
| Vos besoins | Point de terminaison recommandé | Client adapté |
|---|---|---|
| Génération d'image simple (ex: image de couverture) | /v1/images/generations |
Chatbox / curl / SDK |
| Édition d'image simple (avec masque) | /v1/images/edits |
curl / SDK (non supporté par Chatbox) |
| Modification d'image par dialogue continu | /v1/responses |
Code personnalisé (non supporté par Chatbox) |
| Dialogue textuel uniquement | /v1/chat/completions |
Chatbox / tout client de chat |
| Dialogue textuel + compréhension d'image | /v1/chat/completions |
Supporté par Chatbox |

FAQ : Intégration de gpt-image-2 dans Chatbox
Question 1 : Pourquoi Chatbox ne prend-il pas en charge nativement la génération d'images en continu avec gpt-image-2 ?
Ce n'est pas un défaut de conception de Chatbox, mais une limitation inhérente aux clients de type chat. Le modèle de données de Chatbox repose sur un tableau messages (style chat), tandis que celui de l'API Responses repose sur un previous_response_id couplé à un état de conversation côté serveur. Ce sont deux paradigmes fondamentalement incompatibles. Pour que Chatbox prenne en charge cette fonctionnalité, il faudrait réécrire l'intégralité du moteur de dialogue.
Question 2 : Après avoir configuré un point de terminaison personnalisé dans Chatbox, puis-je uploader une image pour que gpt-image-2 la modifie ?
En théorie oui, mais en pratique c'est complexe. Le point de terminaison /v1/images/edits exige un upload au format multipart/form-data, alors que la zone de saisie de Chatbox ne supporte que le texte. Une configuration forcée entraînera une erreur 415. Alternative recommandée : utilisez curl, Postman ou un script personnalisé pour appeler /v1/images/edits.
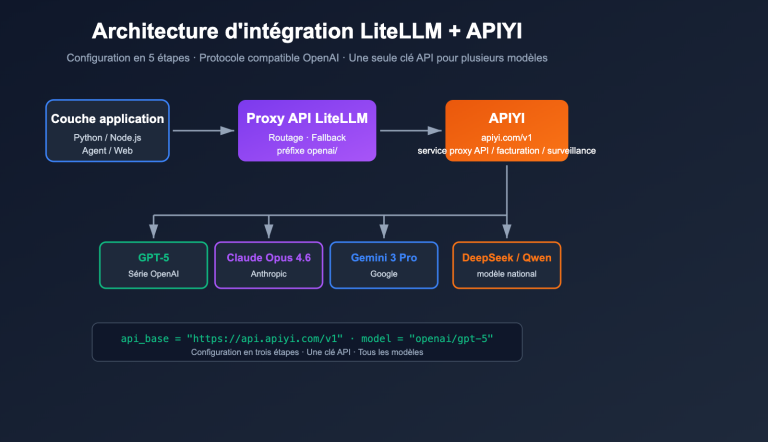
Question 3 : Le service proxy API APIYI prend-il en charge l'API Responses ?
Absolument. APIYI est un service proxy officiel ; les champs de requête et de réponse sont synchronisés à 100 % avec ceux d'OpenAI, incluant les 4 points de terminaison principaux : /v1/responses, /v1/images/generations, /v1/images/edits et /v1/chat/completions. Nous recommandons d'utiliser APIYI (apiyi.com) pour appeler l'API Responses et réaliser des générations d'images en continu, avec une connexion stable en Chine sans avoir besoin de proxy.
Question 4 : Quelle est la longueur maximale de l'invite (prompt) lors de l'utilisation de gpt-image-2 via Chatbox ?
OpenAI limite officiellement le champ de l'invite à 32 000 caractères. En pratique, nous recommandons de rester en dessous de 1 000 caractères : une invite trop longue a tendance à disperser l'attention du modèle, ce qui réduit la qualité de la génération.
Question 5 : Peut-on configurer à la fois un modèle de chat et un modèle de génération d'images dans Chatbox ?
Oui, Chatbox permet de configurer plusieurs « fournisseurs personnalisés ». Nous vous suggérons d'en créer deux :
APIYI - Chat→ Point de terminaison/v1/chat/completions→ Modèlegpt-5/claude-sonnet-4-6, etc.APIYI - Image→ Point de terminaison/v1/images/generations→ Modèlegpt-image-2
Il suffit de basculer entre les fournisseurs pour passer d'un mode à l'autre.
Question 6 : En cas d'échec de l'invocation du modèle gpt-image-2 via Chatbox, comment savoir si le problème vient de Chatbox ou de l'API ?
La méthode la plus rapide est de tester l'API directement avec curl. Si curl fonctionne, le problème vient de votre configuration Chatbox ; si curl échoue également, le problème vient de votre clé API ou de votre réseau. Vous pouvez copier directement l'exemple curl fourni au début de cet article.
Question 7 : Quelle est la différence entre l'utilisation via APIYI et l'API officielle OpenAI ?
Les champs sont identiques, car APIYI est un service proxy officiel. Les différences résident principalement dans trois domaines : connexion directe sans besoin de proxy, support technique dédié en chinois et facturation transparente. Nous recommandons aux développeurs en Chine de passer par APIYI (apiyi.com) pour accéder à gpt-image-2 afin d'éviter les problèmes de stabilité réseau.
Question 8 : Quand faut-il abandonner Chatbox pour écrire son propre code avec l'API Responses ?
Voici trois signes clairs :
- Vous avez besoin d'une "édition d'image conversationnelle" (générer une fois, puis ajuster plusieurs fois).
- Vous avez besoin d'une sortie mixte texte+image (expliquer un concept, générer une image, puis continuer l'explication).
- Vous développez un produit et non un usage personnel, ce qui nécessite une gestion de l'état de la conversation côté serveur.
Si l'une de ces conditions est remplie, il est temps de passer à l'API Responses.
Points clés : Intégration de gpt-image-2 dans Chatbox
- Chatbox utilise par défaut
/v1/chat/completions: ce point de terminaison ne supporte pas la génération d'images, il doit être remplacé par/v1/images/generations. /v1/images/generationsest un point de terminaison sans état : chaque requête est indépendante, ce qui empêche les "modifications en continu".- La capacité de génération en continu de ChatGPT provient de l'API Responses : elle utilise l'outil
image_generation+ l'état de conversationprevious_response_id. - L'incapacité de Chatbox à gérer la génération en continu n'est pas un bug : c'est une différence fondamentale entre les clients de type chat et le paradigme de l'API Responses.
- Alternative : pour la génération en continu, utilisez le SDK OpenAI pour appeler
/v1/responsesavec les modèles de la série gpt-5. - Conseil pour une utilisation en Chine : passez par APIYI (apiyi.com), qui supporte les 4 points de terminaison principaux ; il suffit de remplacer l'URL de base (
base_url). - Dépannage rapide : en cas d'échec, vérifiez d'abord avec curl. Si curl fonctionne, le problème vient du client et non de l'API.
Résumé
Le problème de « configuration » lors de l'intégration de gpt-image-2 dans Chatbox n'est que la partie émergée de l'iceberg. Ce que les développeurs doivent réellement comprendre, c'est l'architecture des trois points de terminaison (endpoints) indépendants d'OpenAI. Ils sont conçus pour des cas d'utilisation distincts et leurs capacités diffèrent radicalement :
- Chat Completions : C'est le point de terminaison pour le « dialogue textuel + compréhension d'image », il ne peut pas générer d'images.
- Images Generations / Edits : C'est un point de terminaison « sans état » pour la « génération/édition d'image unique ». C'est simple et direct, mais ne permet pas d'itérations multi-tours.
- Responses API : C'est le point de terminaison pour le « dialogue multi-tours + appel d'outils », le seul moyen d'implémenter une « retouche d'image conversationnelle ».
Comme Chatbox est un client orienté « chat », il ne peut s'adapter parfaitement qu'à l'un des deux premiers modes : en personnalisant le point de terminaison pour prendre en charge la génération d'images unique. Cependant, pour obtenir le niveau de « modification conversationnelle infinie » de la version web de ChatGPT, vous devez abandonner les outils clients et écrire votre propre code pour appeler l'API Responses.
Une fois ce point compris, votre choix de flux de travail devient clair :
- Petite échelle, génération unique, usage personnel → Chatbox +
/v1/images/generations - Besoin de retouches continues, intégration de niveau produit → Responses API + code personnalisé
- Génération par lots, pipelines automatisés → Appel direct du SDK vers
/v1/images/generations
✨ Dernier conseil : Pour les développeurs, quelle que soit la voie choisie, nous recommandons de passer par la plateforme APIYI (apiyi.com). Les 4 points de terminaison principaux sont entièrement pris en charge, avec une compatibilité à 100 % des champs officiels d'OpenAI, une connexion stable et une facturation transparente au jeton (token). Les nouveaux utilisateurs bénéficient d'un crédit de test gratuit, suffisant pour valider à la fois la configuration de Chatbox et l'API Responses.
Auteur : Équipe APIYI
Dernière mise à jour : 02/05/2026