¿Te resulta confuso encontrarte con el error "You've reached your rate limit. Please try again later."? Todo funcionaba bien, no te habías pasado del límite de tokens, ¿por qué de repente dejó de funcionar?
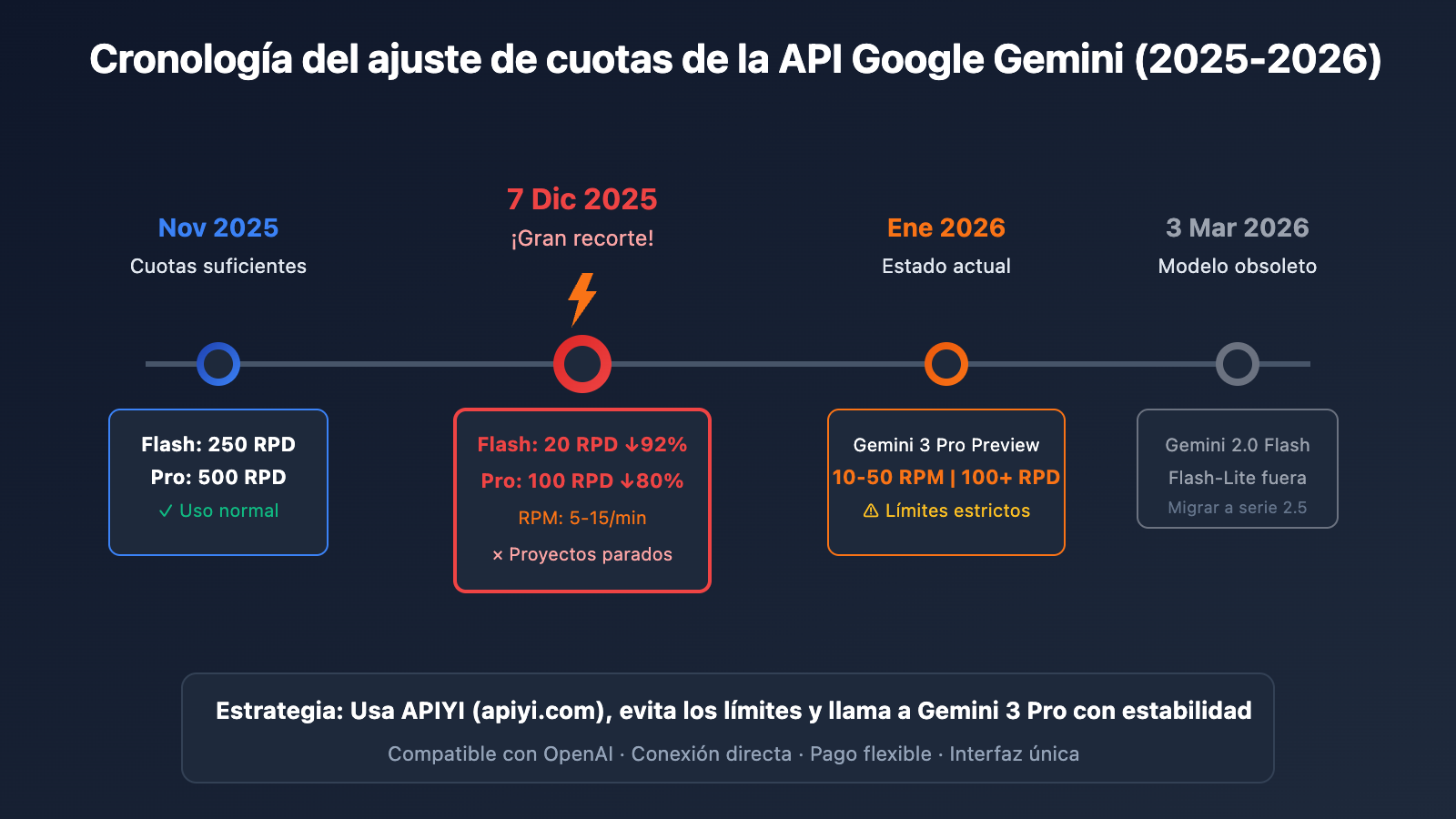
Si eres un usuario individual o estudiante y te has topado con este problema al usar Gemini 3 Pro para generación de texto en AI Studio, no estás solo. El 7 de diciembre de 2025, Google redujo silenciosamente las cuotas gratuitas de la API de Gemini entre un 50% y un 92%, un cambio que paralizó los proyectos de miles de desarrolladores en todo el mundo de la noche a la mañana.
Valor central: Al terminar de leer este artículo, entenderás la razón real del recorte de cuotas, dominarás 5 formas de superar el límite de velocidad y aprenderás a usar Gemini 3 Pro de forma estable a través de una plataforma intermediaria de API.

Puntos clave del límite de velocidad en Gemini 3 Pro
Antes de solucionar el problema, necesitamos entender qué ajustes hizo Google exactamente.
| Ítem ajustado | Antes (Nov 2025) | Después (7 Dic 2025) | Reducción |
|---|---|---|---|
| RPD Modelo Flash | 250 peticiones/día | 20 peticiones/día | -92% |
| RPD Modelo Pro | 500 peticiones/día | 100 peticiones/día | -80% |
| RPM Modelo Pro | 15 peticiones/min | 5 peticiones/min | -67% |
| Gemini 3 Pro Preview | Ilimitado | 10-50 RPM, 100+ RPD | Nuevo límite |
Las 4 dimensiones del límite de velocidad de Gemini 3 Pro
El sistema de límites de Google controla el uso desde 4 dimensiones:
| Dimensión | Siglas | Descripción | Valor actual (Nivel Gratis) |
|---|---|---|---|
| RPM | Requests Per Minute | Peticiones por minuto | 5-15 veces |
| TPM | Tokens Per Minute | Tokens por minuto | 250,000 |
| RPD | Requests Per Day | Peticiones por día | 20-100 veces |
| IPM | Images Per Minute | Imágenes por minuto | Para multimodal |
🔑 Información clave: Al ser Gemini 3 Pro una versión Preview, el límite actual del nivel gratuito es de aproximadamente 10-50 RPM y 100+ RPD, pero en la práctica muchos usuarios informan que las restricciones son mucho más estrictas de lo que indica la documentación.
¿Por qué Google recortó las cuotas drásticamente?
Según el comunicado oficial de Google, los ajustes se deben a:
- Crecimiento explosivo de la demanda: En 2025, las aplicaciones de IA explotaron y el volumen de llamadas a la API superó con creces las expectativas.
- Presión en la infraestructura: Los modelos Gemini 2.0/3.0 requieren una potencia de cómputo altísima.
- Protección de la experiencia del usuario de pago: Priorizar la calidad del servicio para quienes pagan.
- Ajuste de estrategia comercial: Incentivar a los desarrolladores a migrar a planes de pago.
5 soluciones para los límites de velocidad de Gemini 3 Pro
Para resolver los problemas de límite de velocidad (rate limit) en AI Studio, aquí tienes 5 soluciones probadas:
Solución 1: Cambiar a otros modelos de Gemini
Esta es la solución temporal más sencilla. Cada modelo tiene diferentes límites de cuota:
| Modelo | RPM | RPD | Escenario recomendado |
|---|---|---|---|
| Gemini 2.5 Flash-Lite | 15 | 1,000 | Ideal para tareas ligeras |
| Gemini 2.5 Flash | 10 | 500 | Rendimiento equilibrado |
| Gemini 2.5 Pro | 5 | 100 | Razonamiento complejo |
| Gemini 3 Pro Preview | 10-50 | 100+ | Máxima capacidad, límites estrictos |
💡 Consejo práctico: Si tu tarea no requiere todo el potencial de Gemini 3 Pro, cambiar a Gemini 2.5 Flash-Lite te permite obtener una cuota de hasta 1,000 RPD, suficiente para el aprendizaje y uso diario.
Solución 2: Esperar al restablecimiento de la cuota
La cuota RPD (solicitudes diarias) de la API de Gemini se restablece a medianoche, hora del Pacífico (PT).
Tabla de correspondencia para el reinicio de cuota:
- Ciudad de México: 02:00 AM (Horario estándar)
- Madrid: 09:00 AM (Horario estándar)
- Buenos Aires: 05:00 AM (Horario estándar)
Solución 3: Actualizar al nivel de pago (Paid Tier)
Si necesitas usar Gemini 3 Pro de forma estable, actualizar al nivel de pago es la opción recomendada oficialmente:
| Nivel | Requisitos | RPM | RPD | Coste mensual estimado |
|---|---|---|---|---|
| Free Tier | Ninguno | 5-15 | 20-100 | $0 |
| Tier 1 | Vincular tarjeta de crédito | 150-300 | Ilimitado | Pago por uso |
| Tier 2 | Consumo acumulado $250 + 30 días | 1,000+ | Ilimitado | Pago por uso |
Precios de Gemini 3 Pro:
- Entrada: $2.00 / Millón de Tokens (contexto ≤200K)
- Salida: $12.00 / Millón de Tokens (contexto ≤200K)
- Contexto extralargo (>200K): El precio se duplica
Solución 4: Usar una plataforma intermediaria de API (Recomendado)
Para usuarios individuales y equipos pequeños o medianos, usar una plataforma intermediaria de API es la opción con mejor relación calidad-precio:
# Llamada a Gemini 3 Pro a través de APIYI - Ejemplo minimalista
import openai
client = openai.OpenAI(
api_key="tu-llave-apiyi",
base_url="https://api.apiyi.com/v1" # Interfaz unificada de APIYI
)
response = client.chat.completions.create(
model="gemini-3-pro-preview",
messages=[
{"role": "user", "content": "Por favor, explica qué es la arquitectura Transformer"}
],
max_tokens=2000
)
print(response.choices[0].message.content)
🚀 Comienzo rápido: Recomendamos usar la plataforma APIYI (apiyi.com) para acceder rápidamente a Gemini 3 Pro. Ofrece una interfaz compatible con el formato de OpenAI, eliminando las preocupaciones por los límites de cuota y permitiendo la integración en solo 5 minutos.
Ver ejemplo de código completo (con manejo de errores)
# Ejemplo completo de llamada a Gemini 3 Pro - a través de APIYI
import openai
from openai import OpenAI
import time
def call_gemini_3_pro(prompt: str, max_retries: int = 3) -> str:
"""
Llama al modelo Gemini 3 Pro
Args:
prompt: Entrada del usuario
max_retries: Número máximo de reintentos
Returns:
Contenido de la respuesta del modelo
"""
client = OpenAI(
api_key="tu-llave-apiyi",
base_url="https://api.apiyi.com/v1" # Interfaz unificada de APIYI
)
for attempt in range(max_retries):
try:
response = client.chat.completions.create(
model="gemini-3-pro-preview",
messages=[
{
"role": "system",
"content": "Eres un asistente de IA profesional, responde en español."
},
{
"role": "user",
"content": prompt
}
],
max_tokens=4000,
temperature=0.7
)
return response.choices[0].message.content
except openai.RateLimitError as e:
print(f"Demasiadas solicitudes, reintentando... ({attempt + 1}/{max_retries})")
time.sleep(2 ** attempt) # Retroceso exponencial
except openai.APIError as e:
print(f"Error de API: {e}")
raise
raise Exception("Se agotaron los intentos de reintento")
# Ejemplo de uso
if __name__ == "__main__":
result = call_gemini_3_pro("Explica en 100 palabras cómo funciona un Modelo de Lenguaje Grande")
print(result)
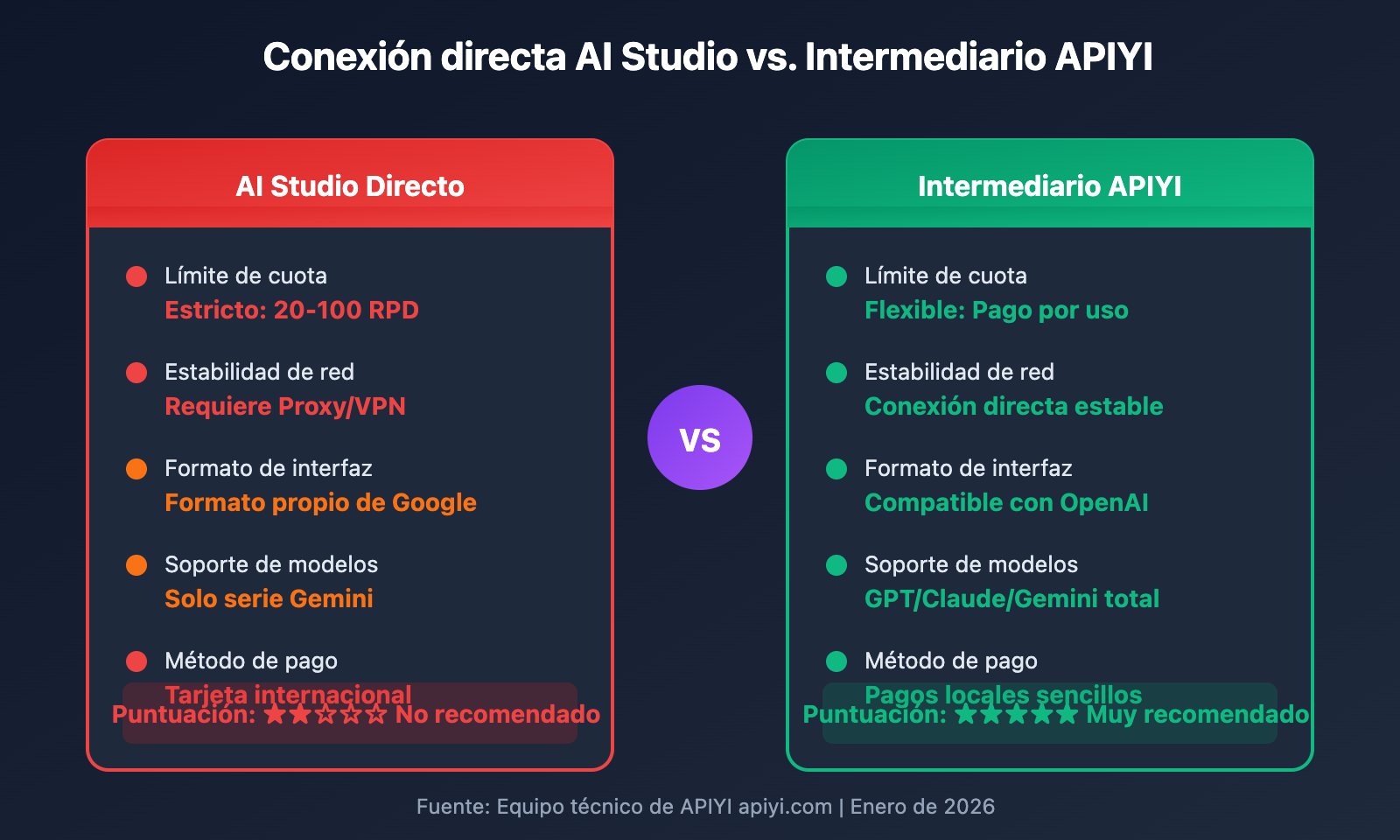
Ventajas de usar una plataforma intermediaria de API:
| Ítem de comparación | AI Studio Directo | Intermediario APIYI |
|---|---|---|
| Límite de cuota | Estricto (20-100 RPD) | Flexible, según necesidad |
| Estabilidad de red | Requiere Proxy/VPN | Conexión directa local |
| Formato de interfaz | Formato propio de Google | Compatible con OpenAI |
| Cambio de modelos | Solo serie Gemini | Soporta GPT/Claude/Gemini, etc. |
| Método de pago | Requiere tarjeta extranjera | Métodos de pago locales |
Solución 5: Planificar una estrategia de solicitudes razonable
Si debes usar el nivel gratuito, las siguientes estrategias pueden maximizar tu cuota:
1. Procesamiento de solicitudes por lotes
# Combinar varias preguntas pequeñas en una sola solicitud
combined_prompt = """
Responde a las siguientes preguntas en orden:
1. ¿Cuál es la diferencia entre list y tuple en Python?
2. ¿Qué es un decorador?
3. ¿Cómo se implementa el patrón Singleton?
"""
2. Usar un mecanismo de caché
import hashlib
import json
# Caché local simple
cache = {}
def cached_query(prompt: str) -> str:
cache_key = hashlib.md5(prompt.encode()).hexdigest()
if cache_key in cache:
return cache[cache_key]
result = call_gemini_3_pro(prompt) # Llamada real a la API
cache[cache_key] = result
return result
3. Uso en horas de menor actividad
- Evita las horas pico (horario laboral de EE. UU.).
- Aprovecha el reinicio de cuota justo después de la medianoche, hora del Pacífico.
Preguntas frecuentes sobre los límites de velocidad de Gemini 3 Pro
Q1: ¿Por qué se activa el límite de velocidad después de enviar solo unos pocos mensajes?
Este es un problema común tras el ajuste de cuotas de diciembre de 2025. Actualmente, las restricciones del nivel gratuito de Gemini 3 Pro Preview son muy estrictas y pueden ser inferiores a los valores indicados en la documentación oficial. Algunos usuarios informan que el RPM (peticiones por minuto) real es solo la mitad de lo documentado.
Solución: Si necesitas un uso continuo, te sugerimos realizar las llamadas a través de plataformas intermediarias como APIYI (apiyi.com), lo que te permite evitar los límites directos del nivel gratuito de Google.
Q2: ¿El nivel de pago soluciona completamente el problema de las restricciones?
Al actualizar al nivel de pago (Tier 1), el RPM aumenta a 150-300 y las restricciones de RPD (peticiones por día) prácticamente desaparecen. Sin embargo, ten en cuenta lo siguiente:
- Requiere vincular una tarjeta de crédito internacional.
- Se factura según el uso de tokens.
- El precio de Gemini 3 Pro es elevado ($2-12 por millón de tokens).
Para usuarios individuales o de aprendizaje, utilizar plataformas como APIYI (apiyi.com) suele ser más económico y práctico, además de admitir métodos de pago locales.
Q3: ¿Es seguro utilizar un intermediario de API?
Elegir una plataforma intermediaria de API legítima es seguro. Tomando a APIYI como ejemplo:
- No almacena el contenido de las conversaciones de los usuarios.
- Soporta transmisión cifrada mediante HTTPS.
- Proporciona registros completos de las llamadas a la API.
Se recomienda elegir plataformas con buena reputación y un tiempo considerable de operación.
Q4: ¿Qué diferencia hay entre Gemini 3 Pro y 2.5 Pro?
| Elemento de comparación | Gemini 3 Pro | Gemini 2.5 Pro |
|---|---|---|
| Capacidad de razonamiento | La más potente | Potente |
| Longitud de contexto | 200K+ | 1M |
| Capacidad multimodal | Mejorada | Estándar |
| Cuota nivel gratuito | Muy estricta | 100 RPD |
| Precio | $2-12/M | $1.25-5/M |
Si tu tarea no requiere las capacidades más punteras, Gemini 2.5 Pro ofrece una mejor relación calidad-precio.
Q5: ¿Seguirán ajustándose las cuotas en 2026?
Según los comunicados de Google, el 3 de marzo de 2026 se dejarán de usar los modelos Gemini 2.0 Flash y Flash-Lite. Recomendaciones:
- Migra lo antes posible a la serie Gemini 2.5.
- Mantente atento a las últimas novedades en el foro de desarrolladores de Google AI.
- Considera usar plataformas como APIYI (apiyi.com) que soportan múltiples modelos para facilitar una transición rápida.
Comparativa de soluciones para los límites de velocidad de Gemini 3 Pro
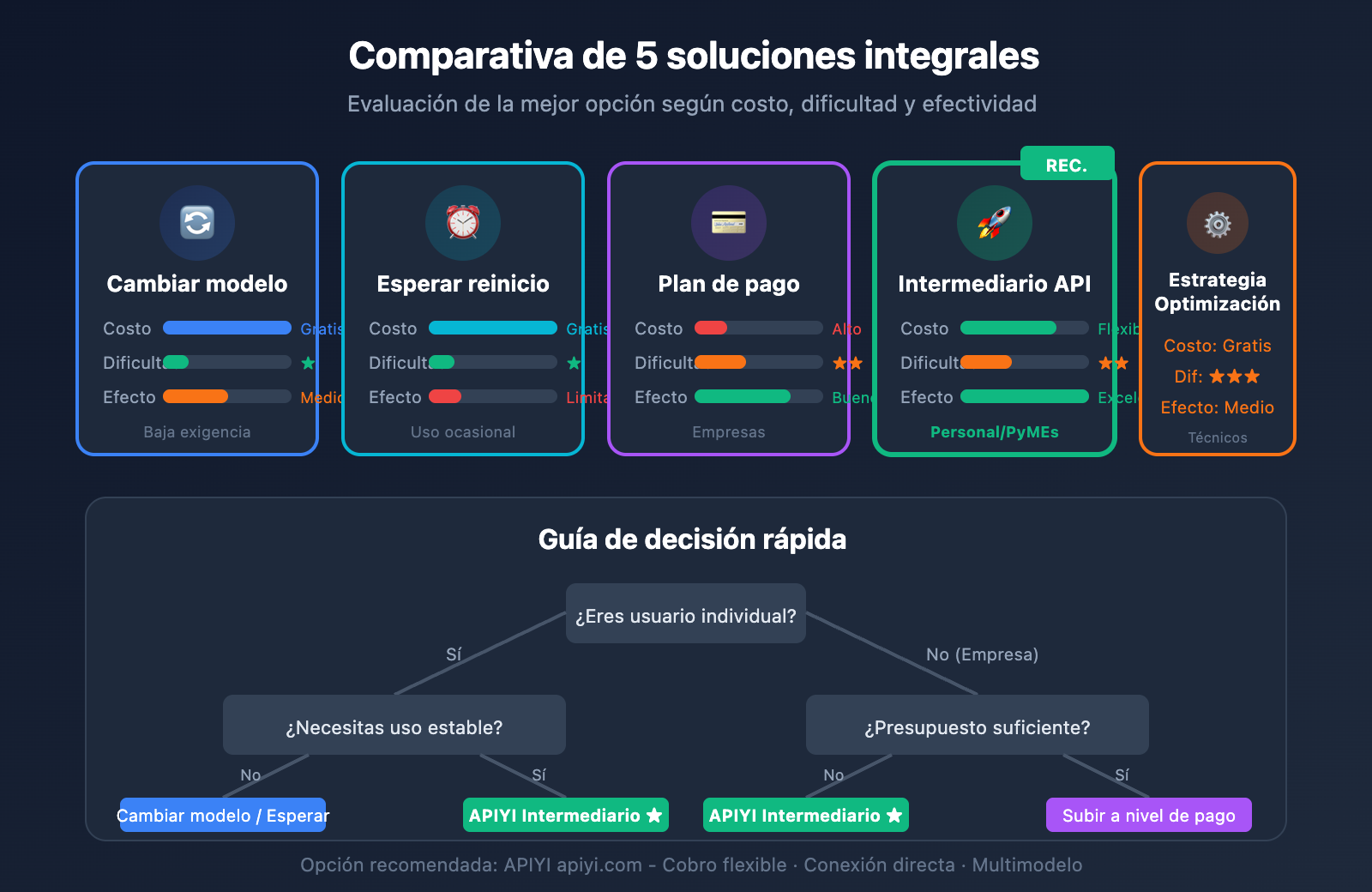
| Solución | Costo | Dificultad | Efectividad | Escenario recomendado |
|---|---|---|---|---|
| Cambiar modelo | Gratis | ⭐ | Media | Tareas poco exigentes |
| Esperar reinicio | Gratis | ⭐ | Limitada | Uso ocasional |
| Nivel de pago | Alto | ⭐⭐ | Buena | Usuarios corporativos |
| Plataforma APIYI | Flexible | ⭐⭐ | Excelente | Personal / PyMEs |
| Optimización de peticiones | Gratis | ⭐⭐⭐ | Media | Usuarios técnicos |
💡 Sugerencia de selección: Para usuarios individuales, recomendamos probar primero cambiar de modelo o utilizar una plataforma intermediaria de API. APIYI (apiyi.com) ofrece una facturación flexible por uso, eliminando las preocupaciones por las cuotas, lo que la convierte en una solución eficiente para superar los límites de velocidad.
Resumen
El error "You've reached your rate limit" en AI Studio se debe al drástico recorte que Google realizó en las cuotas del nivel gratuito en diciembre de 2025. Las 5 soluciones presentadas en este artículo tienen sus pros y sus contras:
- Cambiar de modelo: Lo más sencillo, ideal para necesidades temporales.
- Esperar al restablecimiento: Sin coste, pero poco eficiente.
- Pasar al plan de pago: Excelente rendimiento, pero con un coste elevado.
- Intermediario de API: Alta relación calidad-precio, recomendado para usuarios individuales.
- Optimizar estrategias: Requiere habilidades técnicas.
Para la mayoría de los usuarios particulares, recomendamos usar APIYI (apiyi.com) para resolver rápidamente los problemas de límites de velocidad. Esta plataforma permite el acceso unificado a modelos principales como Gemini 3 Pro, GPT-4 y Claude 3.5, ofreciendo una conexión estable y métodos de pago flexibles.
Referencias
-
Documentación oficial de Google AI – Rate Limits
- Enlace:
ai.google.dev/gemini-api/docs/rate-limits - Descripción: Explicación oficial sobre los límites de velocidad de la API de Gemini.
- Enlace:
-
Foro de desarrolladores de Google AI – Discusión sobre Rate Limit
- Enlace:
discuss.ai.google.dev/t/youve-reached-your-rate-limit/35201 - Descripción: Discusión de la comunidad de usuarios sobre los límites de velocidad.
- Enlace:
-
Tarifas oficiales de la API de Gemini
- Enlace:
ai.google.dev/gemini-api/docs/pricing - Descripción: Información sobre precios y cuotas para cada modelo.
- Enlace:
📝 Autor: APIYI Team
🔗 Soporte técnico: APIYI apiyi.com – Plataforma integral de intermediación para APIs de Modelos de Lenguaje Grande
📅 Fecha de actualización: 2026-01-24