"You've reached your rate limit. Please try again later." 이 오류 메시지 때문에 당황스러우신 적 없으신가요? 분명 이전까지는 잘 사용해 왔고 토큰도 초과하지 않았는데, 왜 갑자기 사용할 수 없게 된 걸까요?
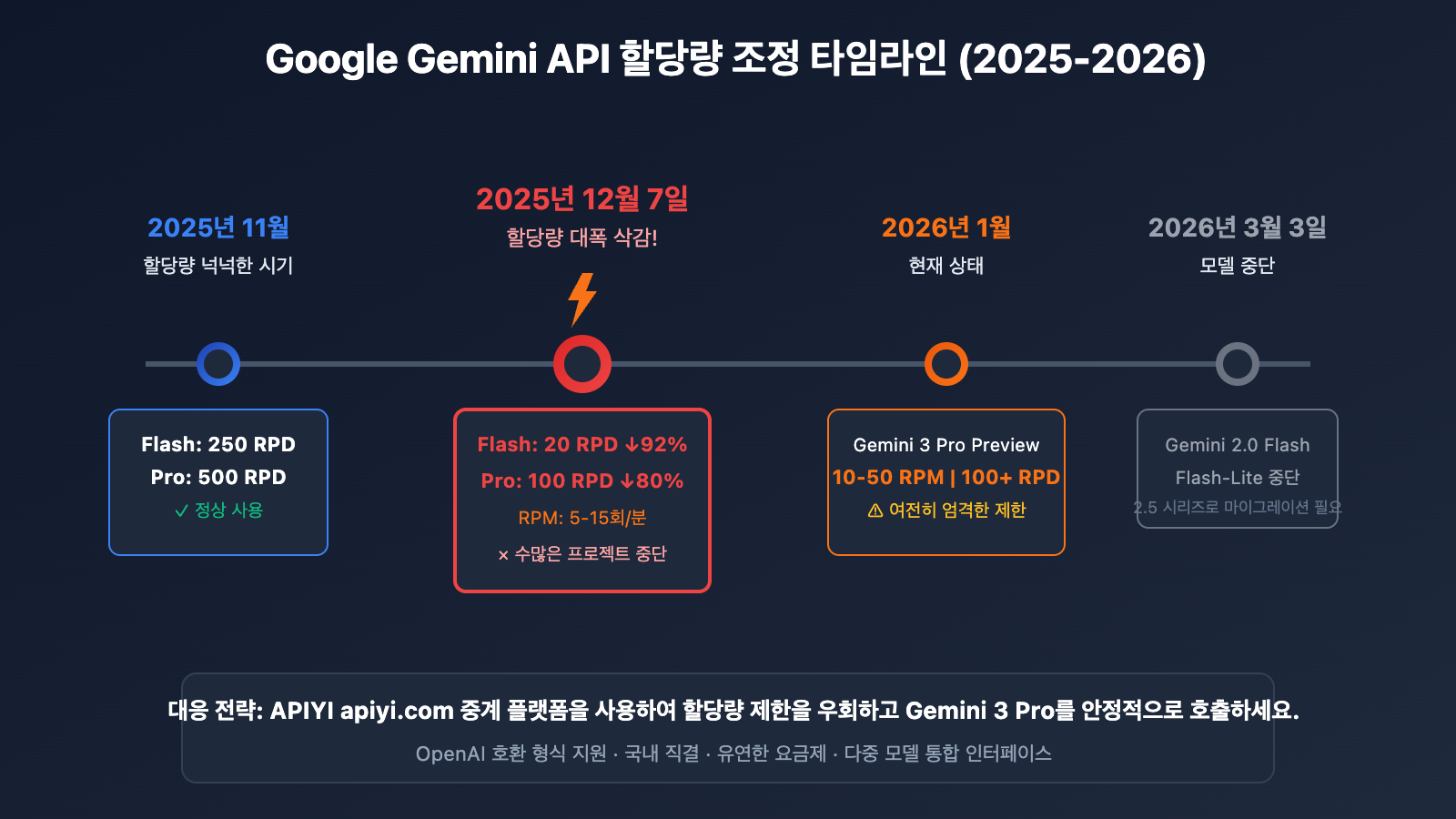
혼자만 겪는 문제가 아닙니다. AI Studio에서 Gemini 3 Pro를 사용해 텍스트를 생성하던 개인 학습 사용자라면 누구나 마주할 수 있는 상황입니다. 2025년 12월 7일, Google이 조용히 Gemini API 무료 할당량을 50%~92%까지 대폭 삭감했습니다. 이로 인해 전 세계 수만 명의 개발자가 진행하던 프로젝트가 하룻밤 사이에 중단되는 사태가 벌어졌습니다.
핵심 가치: 이 글을 끝까지 읽으시면 할당량 삭감의 진짜 원인을 파악하고, 속도 제한을 돌파하는 5가지 방법을 마스터할 수 있습니다. 또한, API 중계 플랫폼을 통해 Gemini 3 Pro를 안정적으로 사용하는 방법도 함께 알아보겠습니다.

Gemini 3 Pro 속도 제한 핵심 요점
문제를 해결하기 전에, Google이 정확히 어떤 조정을 내렸는지 이해해야 합니다.
| 항목 | 변경 전 (2025년 11월) | 변경 후 (2025년 12월 7일) | 감소폭 |
|---|---|---|---|
| Flash 모델 RPD | 250 요청/일 | 20 요청/일 | -92% |
| Pro 모델 RPD | 500 요청/일 | 100 요청/일 | -80% |
| Pro 모델 RPM | 15 요청/분 | 5 요청/분 | -67% |
| Gemini 3 Pro Preview | 제한 없음 | 10-50 RPM, 100+ RPD | 새로운 제한 추가 |
Gemini 3 Pro 속도 제한의 4가지 차원
Google의 속도 제한 시스템은 다음 4가지 차원에서 사용량을 제어합니다.
| 제한 차원 | 풀네임 | 설명 | 무료 티어 현재 값 |
|---|---|---|---|
| RPM | Requests Per Minute | 분당 요청 수 | 5-15회 |
| TPM | Tokens Per Minute | 분당 토큰 수 | 250,000 |
| RPD | Requests Per Day | 일일 요청 수 | 20-100회 |
| IPM | Images Per Minute | 분당 이미지 수 | 멀티모달 모델에 적용 |
🔑 핵심 정보: Gemini 3 Pro는 Preview 버전으로, 현재 무료 티어 제한은 약 10-50 RPM 및 100+ RPD 수준입니다. 하지만 실제 사용 중에는 문서에 명시된 것보다 훨씬 엄격한 제한을 체감한다는 사용자 피드백이 많습니다.
왜 Google은 할당량을 대폭 삭감했을까요?
Google의 공식 발표에 따르면, 이번 할당량 조정은 다음과 같은 이유로 이루어졌습니다.
- 수요의 폭발적 증가: 2025년 AI 애플리케이션 시장이 폭발하면서 API 호출량이 예상을 훨씬 초과했습니다.
- 인프라 압박: Gemini 2.0 및 3.0 모델은 구동에 매우 높은 컴퓨팅 자원을 요구합니다.
- 유료 사용자 경험 보호: 유료 티어 사용자들에게 안정적인 서비스 품질을 우선적으로 보장하기 위함입니다.
- 비즈니스 전략 조정: 무료 사용자들이 점진적으로 유료 플랜으로 전환하도록 유도하고 있습니다.
Gemini 3 Pro 속도 제한 해결을 위한 5가지 해결책
AI Studio의 속도 제한(Rate Limit) 문제로 어려움을 겪고 계신가요? 여기 검증된 5가지 해결 방법을 소개해 드립니다.
방법 1: 다른 Gemini 모델로 전환하기
가장 간단한 임시 해결책입니다. 모델마다 할당된 쿼터 제한이 다르므로 상황에 맞춰 선택할 수 있어요.
| 모델 | RPM (분당 요청 수) | RPD (일일 요청 수) | 추천 시나리오 |
|---|---|---|---|
| Gemini 2.5 Flash-Lite | 15 | 1,000 | 가벼운 작업에 최적 |
| Gemini 2.5 Flash | 10 | 500 | 균형 잡힌 성능 필요 시 |
| Gemini 2.5 Pro | 5 | 100 | 복잡한 추론 작업 |
| Gemini 3 Pro Preview | 10-50 | 100+ | 최고 성능, 엄격한 제한 |
💡 실용적인 팁: 작업에 Gemini 3 Pro의 모든 기능이 필요하지 않다면, Gemini 2.5 Flash-Lite로 전환해 보세요. 일일 최대 1,000 RPD의 할당량을 받을 수 있어 일상적인 학습용으로 충분합니다.
방법 2: 할당량 초기화 기다리기
Gemini API의 RPD(일일 요청 수) 할당량은 태평양 표준시(PST) 자정에 초기화됩니다.
할당량 초기화 시간대 안내:
- 한국 시간(KST): 오후 4:00 (썸머타임 적용 시) / 오후 5:00 (평시)
방법 3: 유료 등급으로 업그레이드하기
Gemini 3 Pro를 안정적으로 사용해야 한다면, 구글에서 권장하는 공식적인 방법인 유료 등급 업그레이드를 고려해 보세요.
| 등급 | 요구 사항 | RPM | RPD | 월평균 비용 |
|---|---|---|---|---|
| Free Tier | 없음 | 5-15 | 20-100 | $0 |
| Tier 1 | 신용카드 등록 | 150-300 | 무제한 | 사용량 기반 과금 |
| Tier 2 | 누적 소비 $250 + 30일 경과 | 1,000+ | 무제한 | 사용량 기반 과금 |
Gemini 3 Pro 가격 정책:
- 입력: $2.00 / 100만 토큰 (≤200K 컨텍스트)
- 출력: $12.00 / 100만 토큰 (≤200K 컨텍스트)
- 초장문 컨텍스트 (>200K): 가격 2배 적용
방법 4: API 중계 플랫폼 사용하기 (추천)
개인 사용자나 중소규모 팀에게는 API 중계 플랫폼을 사용하는 것이 가장 가성비 좋은 선택입니다.
# APIYI를 통한 Gemini 3 Pro 호출 - 간단한 예시
import openai
client = openai.OpenAI(
api_key="your-apiyi-key",
base_url="https://api.apiyi.com/v1" # APIYI 통합 인터페이스
)
response = client.chat.completions.create(
model="gemini-3-pro-preview",
messages=[
{"role": "user", "content": "请解释什么是 Transformer 架构"}
],
max_tokens=2000
)
print(response.choices[0].message.content)
🚀 빠른 시작: apiyi.com 플랫폼을 이용하면 Gemini 3 Pro에 빠르게 접속할 수 있습니다. 익숙한 OpenAI 형식의 인터페이스를 제공하며, 할당량 걱정 없이 5분 만에 연동이 가능해요.
전체 코드 예시 보기 (에러 처리 포함)
# Gemini 3 Pro 完整调用示例 - 通过 APIYI
import openai
from openai import OpenAI
import time
def call_gemini_3_pro(prompt: str, max_retries: int = 3) -> str:
"""
调用 Gemini 3 Pro 模型
Args:
prompt: 用户输入
max_retries: 最大重试次数
Returns:
模型响应内容
"""
client = OpenAI(
api_key="your-apiyi-key",
base_url="https://api.apiyi.com/v1" # APIYI统一接口
)
for attempt in range(max_retries):
try:
response = client.chat.completions.create(
model="gemini-3-pro-preview",
messages=[
{
"role": "system",
"content": "你是一个专业的 AI 助手,请用中文回答问题。"
},
{
"role": "user",
"content": prompt
}
],
max_tokens=4000,
temperature=0.7
)
return response.choices[0].message.content
except openai.RateLimitError as e:
print(f"请求过于频繁,等待后重试... ({attempt + 1}/{max_retries})")
time.sleep(2 ** attempt) # 指数退避
except openai.APIError as e:
print(f"API 错误: {e}")
raise
raise Exception("重试次数已用尽")
# 使用示例
if __name__ == "__main__":
result = call_gemini_3_pro("用 100 字解释大语言模型的工作原理")
print(result)
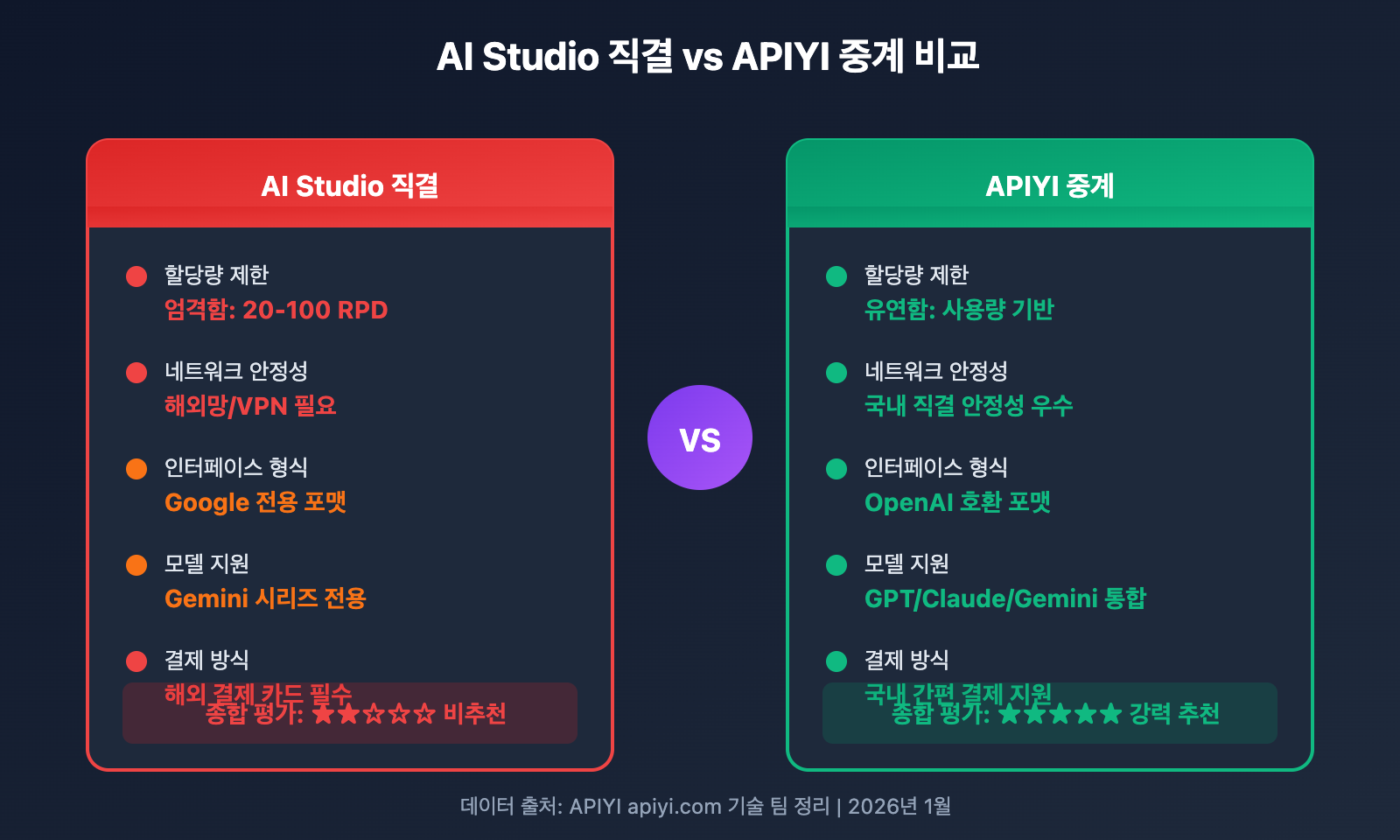
API 중계 플랫폼 사용 시 장점:
| 비교 항목 | AI Studio 직결 | APIYI 중계 |
|---|---|---|
| 할당량 제한 | 엄격 (20-100 RPD) | 유연함, 필요에 따라 사용 |
| 네트워크 안정성 | VPN 등 필요 | 국내망 직접 연결 가능 |
| 인터페이스 형식 | Google 전용 형식 | OpenAI 호환 형식 |
| 다중 모델 전환 | Gemini 시리즈만 가능 | GPT/Claude/Gemini 등 통합 지원 |
| 결제 방식 | 해외 결제 카드 필수 | 국내 간편 결제 지원 |
방법 5: 효율적인 요청 전략 세우기
무료 등급을 꼭 사용해야 한다면, 다음 전략을 통해 할당량 효율을 극대화할 수 있습니다.
1. 요청 일괄 처리(Batching)
# 여러 질문을 하나의 프롬프트로 통합
combined_prompt = """
다음 질문들에 대해 순서대로 답변해 주세요:
1. Python에서 list와 tuple의 차이점은 무엇인가요?
2. 데코레이터란 무엇인가요?
3. 싱글톤 패턴은 어떻게 구현하나요?
"""
2. 캐싱 메커니즘 활용
import hashlib
import json
# 간단한 로컬 캐시 예시
cache = {}
def cached_query(prompt: str) -> str:
cache_key = hashlib.md5(prompt.encode()).hexdigest()
if cache_key in cache:
return cache[cache_key]
result = call_gemini_3_pro(prompt) # 실제 API 호출
cache[cache_key] = result
return result
3. 혼잡 시간대 피하기
- 이용자가 몰리는 피크 시간대(미국 업무 시간 등)를 피해서 사용하세요.
- 태평양 표준시 자정 이후, 할당량이 초기화되는 시점을 노리는 것도 방법입니다.
Gemini 3 Pro 속도 제한(Rate Limit) 자주 묻는 질문
Q1: 메시지를 몇 개 보내지도 않았는데 왜 벌써 속도 제한이 걸리나요?
이것은 2025년 12월 쿼터 조정 이후 자주 발생하는 문제예요. 현재 Gemini 3 Pro Preview의 무료 티어 제한은 매우 엄격하며, 공식 문서에 명시된 수치보다 낮을 수 있습니다. 일부 사용자는 실제 RPM(분당 요청 수)이 문서의 절반 수준에 불과하다고 보고하고 있어요.
해결 방법: 지속적인 사용이 필요하다면 **APIYI (apiyi.com)**와 같은 중계 플랫폼을 통해 호출하는 것을 추천해요. Google의 무료 티어 제한을 직접적으로 겪지 않고 사용할 수 있습니다.
Q2: 유료 티어로 전환하면 제한 문제가 완전히 해결되나요?
유료 티어(Tier 1)로 업그레이드하면 RPM이 150~300으로 늘어나고, RPD(일일 요청 수) 제한은 거의 없어집니다. 하지만 다음 사항을 주의해야 해요:
- 외화 결제가 가능한 신용카드 등록 필요
- 토큰 사용량에 따른 과금
- Gemini 3 Pro의 높은 가격 (100만 토큰당 $2~12)
개인 학습 용도의 사용자라면 국내 결제 수단을 지원하면서도 더 경제적인 APIYI (apiyi.com) 같은 플랫폼을 사용하는 것이 효율적일 수 있습니다.
Q3: API 중계 플랫폼을 사용하는 것이 안전한가요?
정식 API 중계 플랫폼을 선택한다면 안전합니다. APIYI를 예로 들면:
- 사용자의 대화 내용을 저장하지 않음
- HTTPS 암호화 전송 지원
- 상세한 API 호출 로그 제공
가급적 평판이 좋고 운영 기간이 긴 플랫폼을 선택하는 것이 좋습니다.
Q4: Gemini 3 Pro와 2.5 Pro는 어떤 차이가 있나요?
| 비교 항목 | Gemini 3 Pro | Gemini 2.5 Pro |
|---|---|---|
| 추론 능력 | 최상 | 상 |
| 컨텍스트 길이 | 200K+ | 1M |
| 멀티모달 능력 | 강화됨 | 표준 |
| 무료 티어 쿼터 | 엄격함 | 100 RPD |
| 가격 | $2-12/M | $1.25-5/M |
최신 기능이 꼭 필요한 작업이 아니라면 Gemini 2.5 Pro가 가성비 면에서 더 나은 선택이 될 수 있어요.
Q5: 2026년에도 쿼터 조정이 계속될까요?
Google의 공지에 따르면, 2026년 3월 3일에 Gemini 2.0 Flash 및 Flash-Lite 모델이 중단될 예정이에요. 다음을 권장합니다:
- 가급적 빨리 Gemini 2.5 시리즈로 마이그레이션하세요.
- Google AI 개발자 포럼의 최신 소식을 주시하세요.
- 모델 전환이 자유로운 APIYI (apiyi.com) 같은 멀티 모델 지원 플랫폼 사용을 고려해 보세요.
Gemini 3 Pro 속도 제한 해결 방안 비교
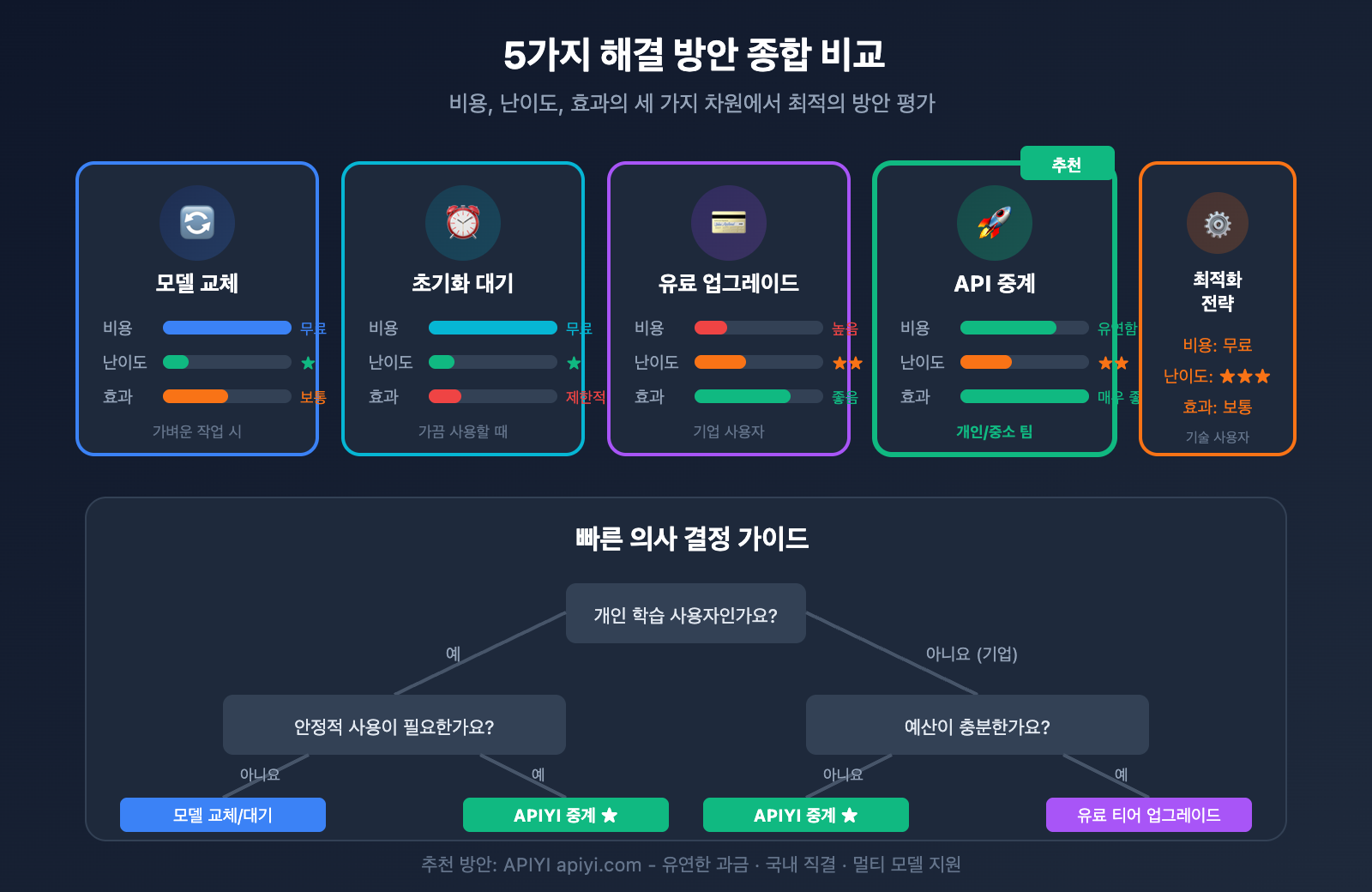
| 해결 방안 | 비용 | 도입 난이도 | 효과 | 추천 상황 |
|---|---|---|---|---|
| 모델 교체 | 무료 | ⭐ | 보통 | 요구 사양이 낮은 작업 |
| 초기화 대기 | 무료 | ⭐ | 제한적 | 가끔 사용할 때 |
| 유료 티어 업그레이드 | 높음 | ⭐⭐ | 좋음 | 기업 사용자 |
| API 중계 플랫폼 | 유연함 | ⭐⭐ | 매우 좋음 | 개인/중소 팀 |
| 요청 전략 최적화 | 무료 | ⭐⭐⭐ | 보통 | 기술 사용자 |
💡 선택 가이드: 개인 학습 사용자라면 모델 교체를 먼저 시도해보거나 API 중계 플랫폼을 사용하는 것을 권장해요. **APIYI (apiyi.com)**는 필요한 만큼만 결제하는 유연한 방식을 제공하여 쿼터 제한 걱정 없이 문제를 해결할 수 있는 효율적인 대안입니다.
요약
AI Studio의 "You've reached your rate limit" 오류는 2025년 12월 Google이 무료 티어 할당량을 대폭 축소한 데서 비롯되었습니다. 본문에서 소개해 드린 5가지 해결 방안은 각각 장단점이 있어요.
- 모델 교체 – 가장 간단하며 임시 방편으로 적합합니다.
- 초기화 대기 – 비용은 들지 않지만 효율이 낮습니다.
- 유료 업그레이드 – 확실한 효과가 있지만 비용 부담이 큽니다.
- API 중계 – 가성비가 뛰어나며 개인 사용자에게 추천합니다.
- 최적화 전략 – 기술적인 역량이 필요합니다.
대부분의 개인 학습자분들께는 **APIYI (apiyi.com)**를 통해 속도 제한 문제를 빠르게 해결하는 방법을 추천드려요. 이 플랫폼은 Gemini 3 Pro, GPT-4, Claude 3.5 등 주요 대규모 언어 모델의 통합 호출을 지원하며, 안정적인 접속과 유연한 결제 방식을 제공합니다.
참고 자료
-
Google AI – Rate Limits 공식 문서
- 링크:
ai.google.dev/gemini-api/docs/rate-limits - 설명: Gemini API 속도 제한에 대한 공식 설명
- 링크:
-
Google AI Developers Forum – Rate Limit 토론
- 링크:
discuss.ai.google.dev/t/youve-reached-your-rate-limit/35201 - 설명: 속도 제한에 관한 커뮤니티 사용자들의 논의
- 링크:
-
Gemini API Pricing 공식 가격 정책
- 링크:
ai.google.dev/gemini-api/docs/pricing - 설명: 각 모델별 가격 책정 및 할당량 정보
- 링크:
📝 작성자: APIYI Team
🔗 기술 지원: APIYI apiyi.com – 원스톱 AI 대규모 언어 모델 API 중계 플랫폼
📅 업데이트 날짜: 2026-01-24