Recientemente, un colega desarrollador preguntó en nuestro grupo: "¿Puede gpt-image-2 generar imágenes a partir de archivos CSV o Excel? Vi en TikTok que alguien usa el modelo de imagen para generar presentaciones (PPT), así que quiero saber si puede leer información de archivos". La respuesta es directa: No puede. El modelo gpt-image-2, lanzado por OpenAI en abril de 2026, solo acepta indicaciones de texto e imágenes como entrada; no lee archivos CSV/Excel ni genera archivos PPTX/PDF.
Sin embargo, esto no significa que el camino esté cerrado. Extraer el contenido del archivo como texto, capturar las páginas del archivo como imágenes y luego enviarlas a gpt-image-2 es, precisamente, el flujo de trabajo estándar actual. En este artículo, aclararemos los límites de capacidad de carga de archivos de gpt-image-2 y presentaremos 5 soluciones alternativas para ayudarte a implementar esos requisitos que tus clientes pensaban que eran imposibles.
Estado actual del soporte de carga de archivos en gpt-image-2: solo texto e imágenes
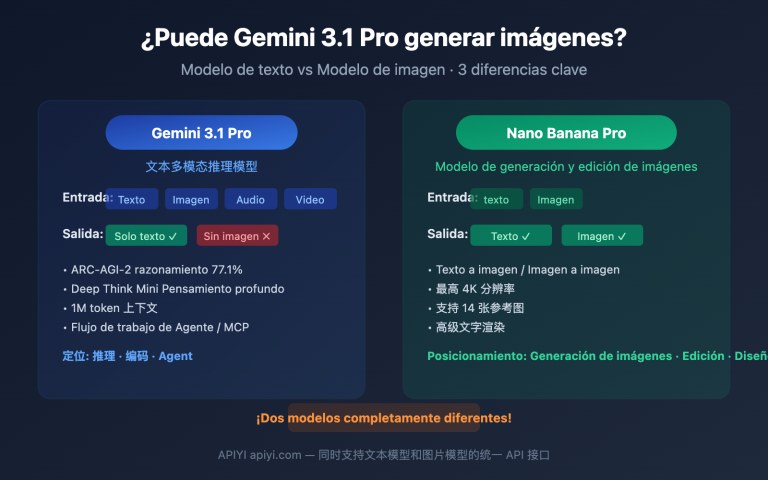
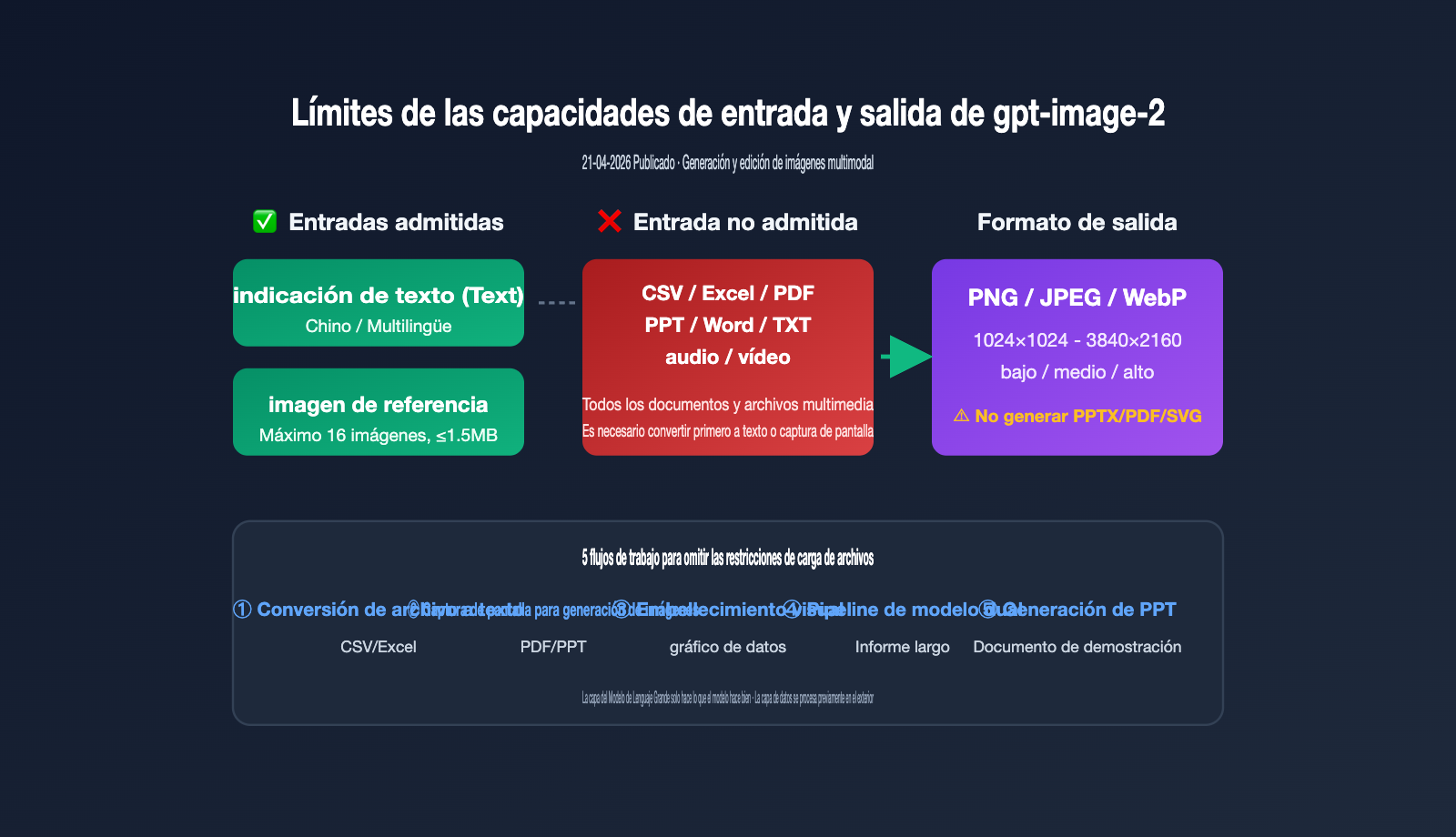
Primero, definamos los límites oficiales, ya que todas las soluciones posteriores se basan en esta restricción. Según la documentación para desarrolladores de OpenAI, gpt-image-2 (snapshot gpt-image-2-2026-04-21) es un modelo multimodal nativo de generación de imágenes. La tabla de soporte de modalidades especifica claramente los rangos de entrada y salida.
| Tipo de modalidad | ¿Soporta entrada? | ¿Soporta salida? | Nota |
|---|---|---|---|
| Texto (text) | ✅ Sí | ❌ No | Usado como indicación, admite múltiples idiomas |
| Imagen (image) | ✅ Sí | ✅ Sí | Entrada para edición/referencia, salida PNG/JPEG/WebP |
| Audio (audio) | ❌ No | ❌ No | No relacionado con la generación de imágenes |
| Video (video) | ❌ No | ❌ No | No relacionado con la generación de imágenes |
| Documentos (CSV/Excel/PDF/Word/PPT) | ❌ No | ❌ No | No se pueden cargar ni exportar como archivos |
En resumen, gpt-image-2 no es un "cerebro universal" como GPT-4; está especializado en la generación y edición de imágenes, por lo que OpenAI no implementó un canal de análisis para CSV/Excel/PDF. Si envías el binario de un Excel, la API devolverá directamente un error 400. Si tu proyecto requiere un canal de invocación del modelo estable y con alto RPM, recomendamos utilizar plataformas de servicio proxy de API como APIYI (apiyi.com), que ya ha documentado la validación de entradas y las limitaciones de parámetros del modelo, evitando que los principiantes cometan errores comunes.
🎯 Conocimiento clave: El límite de capacidad de
gpt-image-2es "Texto + Imagen → Imagen". No lo trates como un agente omnipotente. Los requisitos relacionados con archivos deben ser cubiertos por otras herramientas en la capa externa; el servicio proxy (como APIYI apiyi.com) garantiza la estabilidad de la invocación, y la capa de negocio se encarga del preprocesamiento de datos.
Por qué la "generación de PPT" y la "generación de imágenes a partir de archivos" son cosas distintas
Muchos clientes confunden la "generación de PPT con un clic" con la "generación de imágenes a partir de archivos", cuando en realidad son flujos de trabajo completamente diferentes. Los casos de automatización de PPT que se ven en redes sociales son casi siempre tuberías de varios pasos: primero se utiliza un Modelo de Lenguaje Grande para extraer datos y redactar el contenido, luego se usa un modelo de imagen para generar las ilustraciones de cada página y, finalmente, se ensambla todo en un archivo PPTX mediante programación.
El eslabón encargado de la generación de imágenes suele ser un modelo como gpt-image-2. Este solo observa la indicación de texto y la imagen de referencia que recibe, sin saber si la fuente original era un Excel o Notion. Una vez que esto queda claro, las 5 soluciones siguientes cobran sentido.
Mejoras respecto a la generación anterior, gpt-image-1
Muchos usuarios antiguos preguntarán: si no se pueden cargar archivos, ¿en qué es mejor gpt-image-2 que gpt-image-1? La diferencia es crucial y determina si el camino de "entrada de capturas de pantalla para generar imágenes" es viable. La nueva versión tiene mejoras significativas en renderizado de texto, cantidad de imágenes de referencia y capacidad de razonamiento.
| Dimensión de capacidad | gpt-image-1 | gpt-image-2 |
|---|---|---|
| Cantidad máx. de imágenes de referencia | 4 | 16 (se recomienda ≤4 para mejores resultados) |
| Renderizado de texto | Bueno en inglés, errores en otros idiomas | Precisión mejorada en chino, japonés, coreano, hindi, etc. |
| Capacidad de razonamiento | Ninguna | Modo de pensamiento integrado, maneja diseños complejos |
| Fecha de corte de conocimiento | Principios de 2024 | Diciembre de 2025 |
| Resolución de salida | Máx. 1024×1024 | Máx. 3840×2160 (4K) |
En otras palabras, si anteriormente usaste gpt-image-1 para "cambiar el estilo de una captura de pantalla" y los resultados no fueron ideales, vale la pena probar de nuevo con gpt-image-2, especialmente en escenarios como pósteres en chino o páginas internas de PPT que requieren un renderizado de texto preciso.
5 estrategias de flujo de trabajo para generar imágenes a partir de archivos con gpt-image-2
Estas 5 estrategias se adaptan a diferentes fuentes de datos y escenarios de implementación; la elección depende del tipo de archivo, el formato de salida y el nivel de automatización que busques. Las hemos ordenado de menor a mayor complejidad.
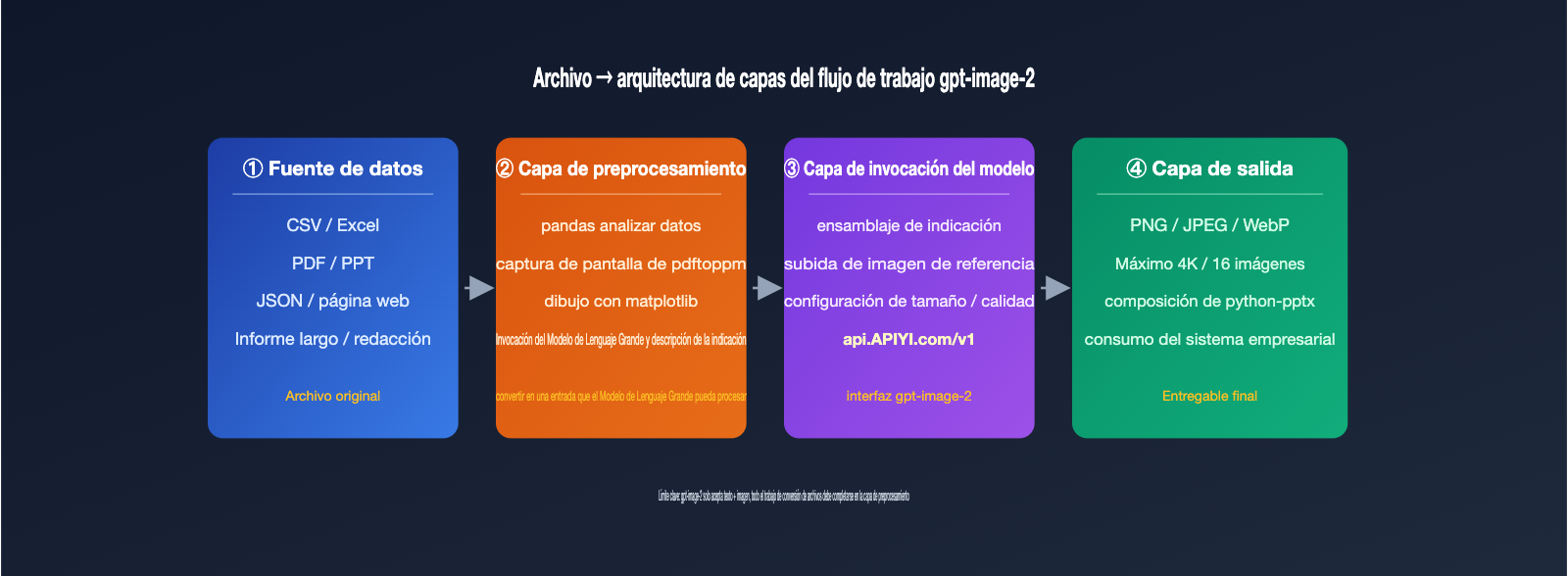
Estrategia 1: Convertir archivos a indicaciones de texto para gpt-image-2
Ideal para datos estructurados como CSV, Excel, JSON o texto plano. El flujo consiste en utilizar scripts (pandas, openpyxl) para leer el archivo, combinar encabezados, filas clave e indicadores estadísticos en una descripción en lenguaje natural y, luego, invocar /v1/images/generations usando esa indicación. Por ejemplo, resumir datos de ventas como: "Gráfico de barras de ventas del Q1 de 2026 en tres regiones: Este 12 millones, Norte 9.8 millones, Sur 7.6 millones, estilo empresarial oscuro".
La ventaja es que es simple y directo, sin necesidad de entrada de imágenes. La desventaja es que la información que cabe en la indicación es limitada. Aunque gpt-image-2 es preciso con los números, no es perfecto; debes especificar los valores de cada barra en la indicación, de lo contrario, el modelo redistribuirá las alturas basándose en la coherencia visual.
Estrategia 2: Captura de pantalla de páginas como imagen de referencia
Ideal para archivos PDF, PPT con diseño establecido, informes web, etc., es decir, "contenido que ya tiene forma de imagen". Convierte la página objetivo a PNG (usando herramientas como Vista previa en macOS, pdftoppm o Puppeteer) y súbela a través del endpoint /v1/images/edits como parámetro image, junto con una indicación que describa los cambios, por ejemplo: "Mantén el diseño, cambia los títulos en inglés a chino y convierte el gráfico de barras a un estilo Apple".
En la versión de 2026, gpt-image-2 acepta un máximo de 16 imágenes de referencia, pero tanto la comunidad como el equipo oficial recomiendan usar 1 imagen de referencia principal + 1 o 2 imágenes de estilo. Si añades más, la atención del modelo se diluye. Se recomienda que cada imagen pese menos de 1.5 MB para evitar un aumento significativo en el consumo de tokens de entrada.
Estrategia 3: Visualización previa de datos y embellecimiento con gpt-image-2
Ideal para escenarios de visualización de datos que buscan "precisión y estética". Primero, utiliza matplotlib, ECharts o los gráficos de Excel para crear una versión básica y expórtala como PNG; luego, usa esta imagen base como entrada para gpt-image-2 con una indicación como: "Mantén la posición y los valores de los puntos de datos, pero cambia el estilo del gráfico a oscuro, con resaltados de neón y estilo infográfico".
Esta es actualmente la forma más sólida de combinar gráficos de datos con el embellecimiento por IA. Los valores originales están garantizados por bibliotecas de dibujo deterministas, mientras que el estilo visual es moldeado por gpt-image-2; cada parte hace lo que mejor sabe hacer. Si necesitas ejecutar este flujo de forma masiva, te recomiendo usar gpt-image-2 a través de APIYI apiyi.com, ya que cuenta con una gestión de pool de cuentas upstream optimizada para escenarios de alta concurrencia de 5000 RPM, ideal para tareas de miles de imágenes al día.
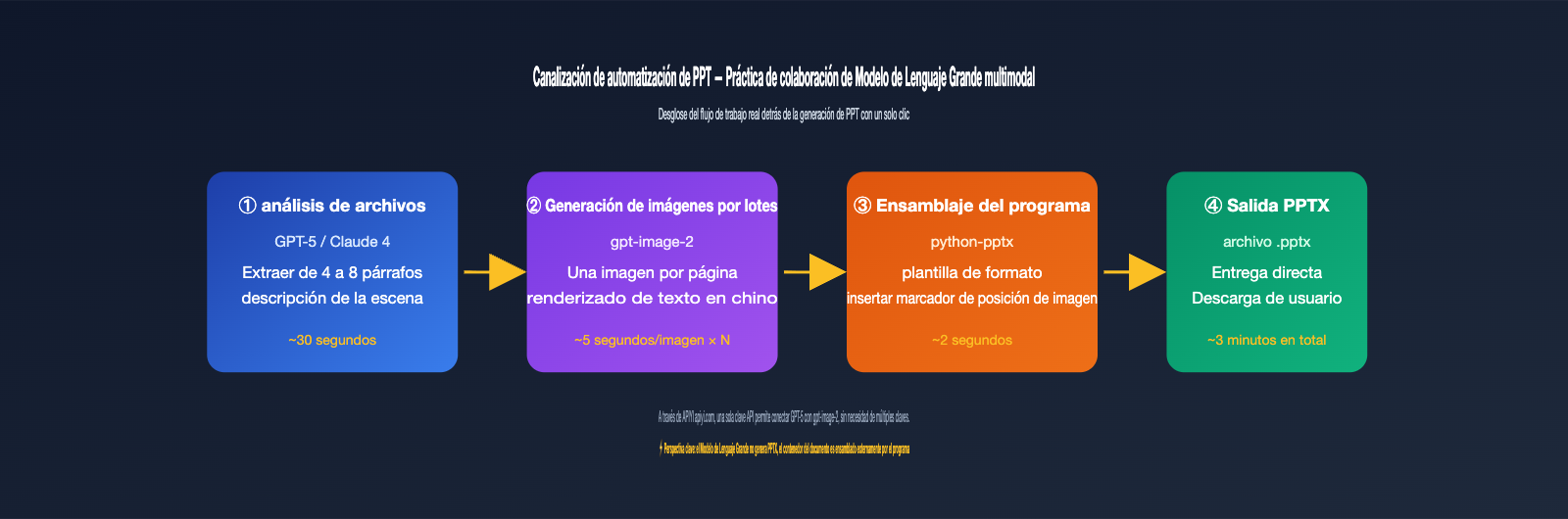
Estrategia 4: Pipeline de doble modelo LLM + gpt-image-2
Ideal para archivos con contenido complejo que requieren comprensión semántica, como informes largos, resúmenes de contratos o textos publicitarios. Primero, utiliza la serie GPT-4 o Claude 4 para entender el archivo y extraer de 4 a 8 descripciones visuales, y luego invoca cíclicamente a gpt-image-2 para generar el número correspondiente de imágenes.
La clave aquí es desacoplar la "comprensión semántica" de la "generación de imágenes". El LLM se encarga de decir "qué debería dibujarse en esta página", y gpt-image-2 se encarga de "dibujar la imagen según esa indicación". Todo el flujo puede conectarse usando la misma clave API en APIYI apiyi.com, ahorrándote la molestia de cambiar de SDK y gestionar claves.
Estrategia 5: Síntesis programática de PPT/carteles tras generación masiva
Esta es la verdad detrás de esos casos de "PPT en un clic" que ves en redes sociales. El modelo en sí no genera archivos PPTX, pero puede generar la imagen de cada página, y luego usar python-pptx o PptxGenJS en el frontend para insertar las imágenes en las posiciones correspondientes de una plantilla de PPT.
En resumen: Un PPT es esencialmente un documento de presentación compuesto por múltiples imágenes; gpt-image-2 resuelve el problema de la "imagen" y python-pptx resuelve el problema del "contenedor de documentos". Una descomposición común es: usar imágenes de alta calidad 4K para la portada, calidad media de 1536×1024 para las páginas interiores, y borradores de baja calidad para el índice y las páginas de transición, controlando los costos mediante el parámetro quality. Un PPT de 20 páginas requiere unas 20-30 invocaciones al modelo; en el canal proxy de 5000 RPM, puedes terminarlo en pocos minutos.
| Estrategia | Tipo de archivo | Esfuerzo técnico | Calidad de salida | Escenario recomendado |
|---|---|---|---|---|
| 1. Archivo a texto | CSV/Excel/JSON | Bajo | Media | Gráficos simples, ilustraciones |
| 2. Captura de pantalla | PDF/PPT/Web | Bajo | Media-Alta | Reescritura de diseño, transferencia de estilo |
| 3. Pre-renderizado | CSV/Excel | Medio | Alta | Embellecimiento de gráficos |
| 4. LLM + gpt-image-2 | Informes/Textos | Medio-Alto | Alta | Tarjetas de contenido, tutoriales |
| 5. Síntesis masiva PPT | Cualquiera | Alto | Alta | Automatización de presentaciones |
Llevar los conceptos al código hace que todo sea mucho más intuitivo. A continuación, presento un ejemplo mínimo y funcional en Python que convierte una tabla de Excel en una indicación de texto y, posteriormente, invoca a gpt-image-2 para generar el gráfico visual correspondiente. Utilizaremos APIYI (apiyi.com) como punto de entrada unificado para el servicio proxy de API; solo necesitas reemplazar la base_url, ya que el resto de la sintaxis del SDK es idéntica a la oficial.
from openai import OpenAI
import pandas as pd
import base64
client = OpenAI(
api_key="your-apiyi-key",
base_url="https://api.apiyi.com/v1"
)
df = pd.read_excel("sales_q1.xlsx")
summary = df.groupby("region")["sales"].sum().to_dict()
prompt_text = (
f"绘制 2026 年 Q1 区域销售额柱状图,"
f"数据为:{summary}, "
f"深色商务风格,纯白标题,数据标签清晰可见。"
)
resp = client.images.generate(
model="gpt-image-2",
prompt=prompt_text,
size="1536x1024",
quality="high"
)
img_b64 = resp.data[0].b64_json
with open("sales_chart.png", "wb") as f:
f.write(base64.b64decode(img_b64))
La lógica del código es clara: la capa de negocio analiza el Excel para convertirlo en una descripción textual y la capa del modelo solo recibe texto. Si se trata de imagen a imagen (segunda opción), simplemente cambia client.images.generate por client.images.edit y pasa la imagen mediante image=open("page.png", "rb").
| Parámetro | Rango de valores | Descripción |
|---|---|---|
model |
gpt-image-2 / gpt-image-2-mini |
La versión mini es más rápida y económica |
size |
1024×1024 / 1536×1024 / 1024×1536 / personalizado | Lado más largo ≤ 3840px, debe ser divisible por 16 |
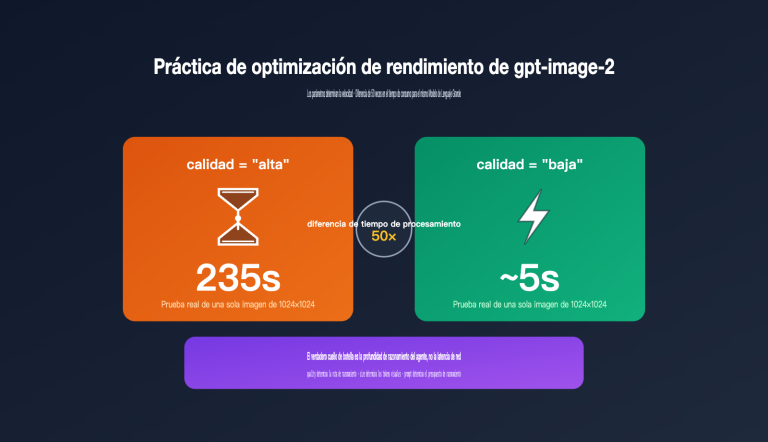
quality |
low / medium / high / auto | La alta calidad consume más tiempo y tokens |
n |
1–4 | Número de imágenes por generación; para lotes, se recomienda un bucle externo |
response_format |
png(predeterminado)/ jpeg / webp | gpt-image-2 no admite salida en PDF/PPTX |
🎯 Consejo de código: Para poner en marcha este flujo rápidamente, te recomendamos registrar una cuenta en APIYI (apiyi.com). Al configurar la
base_urlenhttps://api.apiyi.com/v1, podrás usar una interfaz unificada para invocar gpt-image-2, GPT-5 y la serie Claude 4, ahorrándote la molestia de integrar cada proveedor por separado.

Los 4 errores más comunes de los clientes y cómo evitarlos
Después de entender los 5 esquemas, al momento de la implementación real, es probable que te encuentres con algunos detalles técnicos. Hemos recopilado las 4 categorías de preguntas más frecuentes en nuestros grupos de atención al cliente.
Error 1: Insertar CSV codificado en base64 dentro de la indicación
Algunos usuarios han pensado en una "solución inteligente": leer el archivo CSV como una cadena base64 e insertarla en la indicación, asumiendo que el modelo lo decodificará por sí mismo. Este camino no funciona en absoluto. gpt-image-2 no ejecuta código ni interpreta cadenas como datos; simplemente tratará la cadena base64 como caracteres sin sentido y renderizará un montón de texto ilegible. La forma correcta es analizar el CSV en la capa de negocio y convertirlo en una descripción textual; consulta el esquema uno.
Error 2: Esperar que gpt-image-2 "dibuje tablas exactamente igual que en Excel"
El modelo es excelente en consistencia visual y estilización, pero la reproducción a nivel de píxel es otra historia. Si necesitas tablas estrictas, te recomendamos una estrategia combinada: usa ECharts/matplotlib para dibujar una versión precisa (esquema tres) y luego pide a gpt-image-2 que mejore la apariencia. Esperar que una sola indicación haga que el modelo dibuje con precisión 100 filas de datos es algo que, por ahora, no se puede lograr.
Error 3: Querer formatos vectoriales como SVG o PDF en la salida
El formato de salida de gpt-image-2 se limita a tres formatos de mapa de bits: PNG, JPEG y WebP; no admite formatos vectoriales como SVG, PDF o AI. Si necesitas gráficos vectoriales, utiliza Stable Diffusion junto con vectorizer.ai, o pide directamente a GPT-5 que genere el código SVG. Confirmar el formato de salida antes de elegir el modelo te ahorrará tener que rehacer el trabajo.
Error 4: Cargar repetidamente la misma imagen de referencia, disparando el consumo de tokens
gpt-image-2 procesa cada imagen de entrada con alta fidelidad, por lo que incluso si tu indicación es solo un ajuste fino, cada solicitud recalculará los tokens de entrada. Te sugerimos implementar caché de imágenes de referencia en el cliente, o usar directamente previous_response_id para realizar ediciones conversacionales (Responses API), reutilizando el contexto de la imagen anterior.
Otro detalle a tener en cuenta: incluso si el objetivo de salida es una miniatura de 256×256, si la imagen de referencia es una imagen 4K, los tokens de entrada se cobrarán como 4K. Comprime localmente la imagen de referencia a 1024 píxeles en su lado más largo antes de subirla; esto puede ahorrar más del 60% en tokens de entrada, siendo este el punto de control de costos más ignorado en tareas de gran volumen.
| Fenómeno de error | Causa raíz | Solución recomendada |
|---|---|---|
| 400 invalid_request_error | Se subió un binario que no es imagen (CSV/Excel) | Convertir el archivo a texto o captura de pantalla |
| Caracteres renderizados como ilegibles | Se usó una cadena base64 como indicación | Usar una descripción en lenguaje natural analizado |
| Datos de tabla inexactos | Intentar dibujar tablas precisas con una indicación | Usar el esquema tres para pre-renderizado visual |
| Se requiere salida SVG | El modelo no admite formatos vectoriales | Usar GPT-5 para generar código SVG |
| Consumo de tokens inesperado | Carga repetida de imágenes de referencia grandes | Comprimir a menos de 1.5MB y activar caché |
Preguntas frecuentes (FAQ)
P1: ¿Es cierto que gpt-image-2 no puede subir archivos PDF en absoluto?
No se pueden subir archivos PDF directamente. Sin embargo, puedes usar pdftoppm para convertir cada página a PNG y luego ingresarlas como imágenes. Si necesitas "entender el contenido del PDF para generar una imagen", te sugerimos usar primero GPT-5 para leer el PDF y extraer una descripción, y luego alimentar esa descripción a gpt-image-2. Esta combinación se puede ejecutar con una sola clave API en APIYI apiyi.com.
P2: Si el archivo contiene datos sensibles, ¿es seguro enviarlo directamente al modelo?
El proceso de conversión de archivo a texto se realiza en tu propio servidor; solo el texto final de la indicación se envía al modelo, por lo que puedes anonimizar los datos durante la conversión. Si utilizas un servicio proxy de API, las interfaces de APIYI apiyi.com garantizan explícitamente no almacenar las indicaciones ni el contenido devuelto por el usuario, lo que ofrece un mayor control en términos de cumplimiento que usar un proxy externo.
P3: ¿Las herramientas de "generación de PPT con un clic" en TikTok usan gpt-image-2?
Algunas sí, otras no. La lógica suele ser: el Modelo de Lenguaje Grande escribe el guion → el modelo de imagen (gpt-image-2 / Nano Banana Pro / Flux) crea las ilustraciones → el backend utiliza python-pptx para ensamblar todo. gpt-image-2 destaca especialmente en el renderizado de texto, sobre todo en chino, lo que lo hace ideal para ilustraciones dentro de las diapositivas de PPT.
P4: ¿Por qué hay gente que dice que se puede subir Excel?
Eso es porque convierten la captura de pantalla de Excel en una imagen; en esencia, sigue siendo una entrada de imagen, no es que el modelo entienda la estructura de Excel. Si ves que los números en la captura están borrosos, el modelo solo podrá redibujarlos basándose en esa borrosidad.
P5: ¿Cuál elegir entre gpt-image-2 y gpt-image-2-mini?
La versión mini es más rápida y económica, ideal para borradores de gran volumen y miniaturas; para materiales de publicación oficial, utiliza la versión estándar. Ambos tienen exactamente las mismas limitaciones de entrada (ninguno admite archivos de documentos), solo necesitas cambiar el ID del modelo en el parámetro model, sin necesidad de modificar el código del SDK.
Resumen
El modelo gpt-image-2 no admite la carga directa de archivos CSV, Excel o PPT, ni tampoco genera archivos PPTX o PDF. Estos son límites inherentes a las capacidades del modelo, no un problema de configuración de parámetros. Una vez que comprendes esta limitación, puedes implementar un preprocesamiento de los datos —como convertir archivos a texto, capturas de pantalla o visualizaciones previas— para satisfacer la gran mayoría de las necesidades que "parecen requerir entrada de archivos". Las soluciones que ves en redes sociales sobre convertir Excel a presentaciones o PDF a otros estilos son, en esencia, flujos de trabajo de múltiples pasos. Si separas claramente la lógica de inferencia del modelo del procesamiento de datos, cualquier proyecto se vuelve viable.
La regla de oro para la implementación es sencilla: deja que la capa del modelo haga lo que mejor sabe hacer, mientras que la capa de datos se encarga de digerir la información previamente. Si deseas ejecutar un flujo de trabajo completo, te recomendamos utilizar APIYI (apiyi.com) para integrar tanto GPT-5 (para la comprensión de texto) como gpt-image-2 (para la generación de imágenes). Podrás gestionar todo el proceso con una sola clave API y aprovechar una capacidad de alta concurrencia de 5000 RPM para que tus tareas por lotes se ejecuten sin problemas, sin tener que gestionar múltiples claves o SDKs para diferentes modelos.
Sobre el autor: El equipo de APIYI se especializa en la agregación de múltiples modelos y en infraestructura de inferencia de alta concurrencia, gestionando diariamente numerosas consultas sobre APIs de generación de imágenes. Este artículo ha sido elaborado a partir de la documentación oficial de OpenAI y consultas reales de clientes. Si necesitas conocer más sobre las soluciones de integración para gpt-image-2, visita APIYI en apiyi.com.