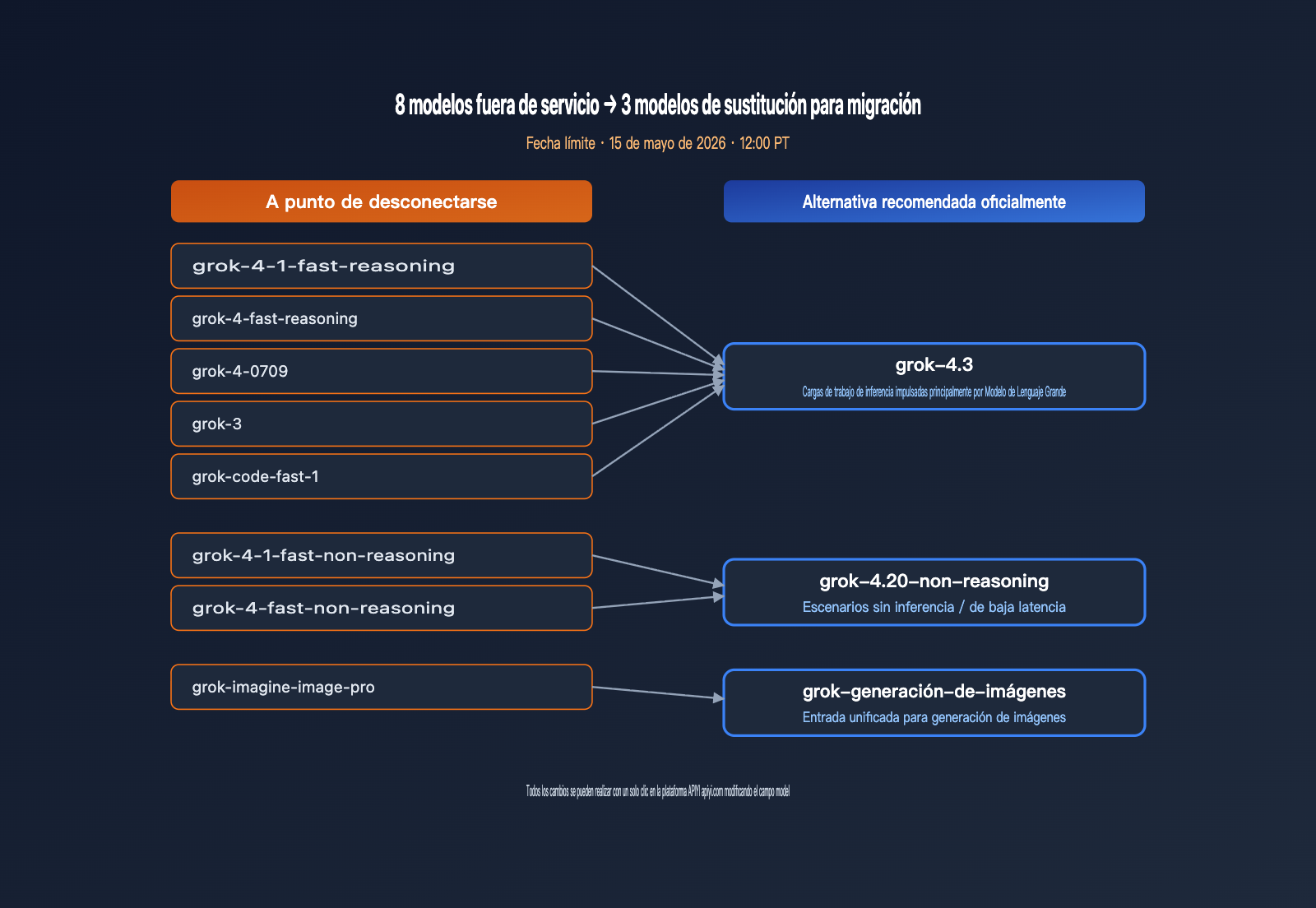
El 6 de mayo de 2026, xAI envió un correo electrónico masivo a todos los usuarios de su API con el asunto "Grok 4.3 release and xAI API model retirement". El mensaje contenía dos noticias cruciales para los desarrolladores: Grok 4.3 ya está disponible en la API y, simultáneamente, ocho modelos antiguos (grok-4-fast, grok-4-0709, grok-3, grok-code-fast-1, grok-imagine-image-pro, entre otros) serán retirados el 15 de mayo de 2026 a las 12:00 PT. Este anuncio no solo marca una importante actualización de versión, sino que también inicia una cuenta regresiva de 9 días para completar la migración.
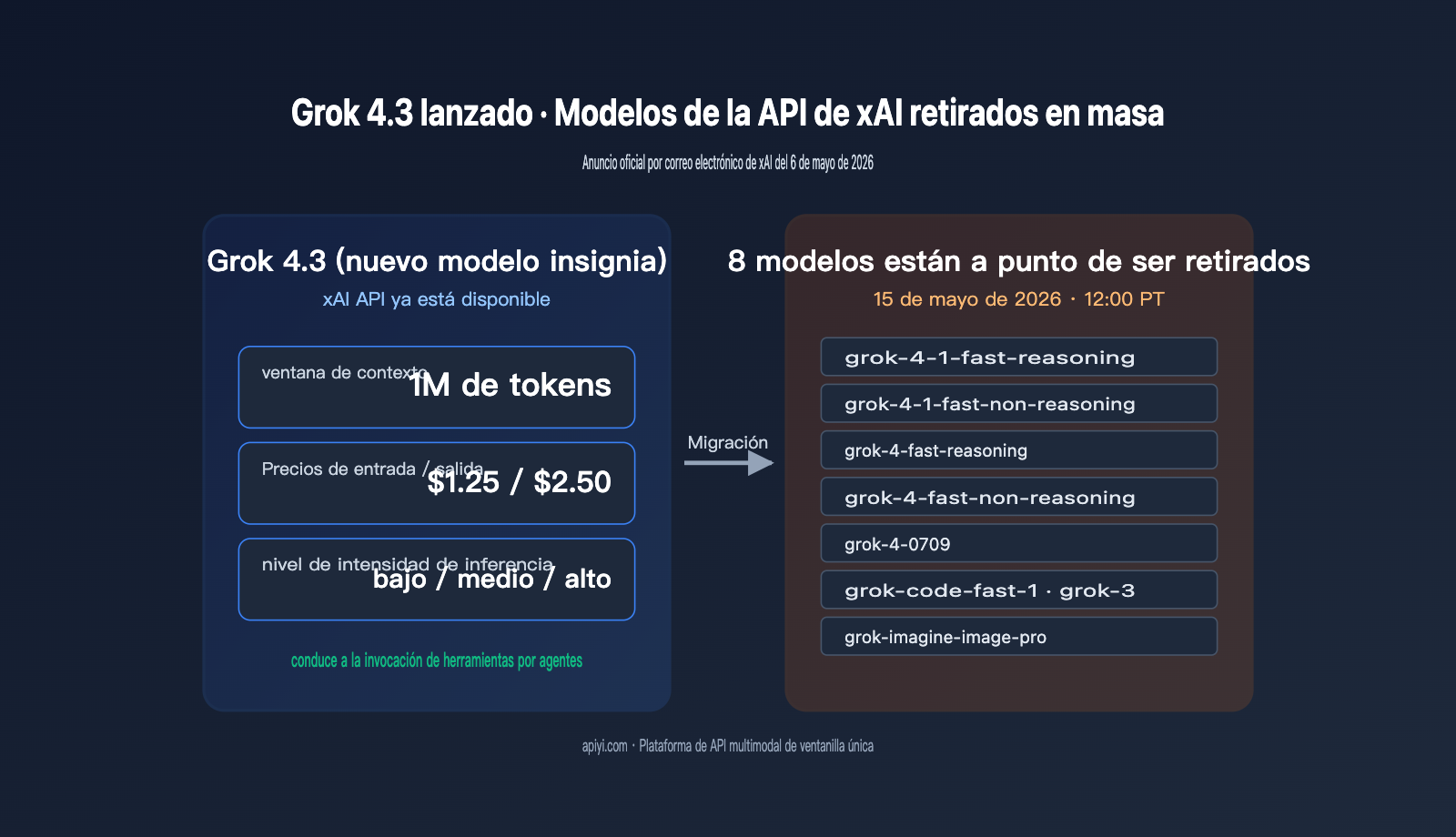
Lo más destacado del lanzamiento de Grok 4.3 no es solo el cambio de nombre, sino su ventana de contexto de 1M de tokens, su estructura de precios de $1.25/$2.50 y la combinación de 3 niveles de intensidad de razonamiento ajustables. Este rango de precios sitúa a Grok 4.3 directamente en el segmento competitivo de modelos de razonamiento principales como Gemini 3.1 Pro y GPT-5.4, manteniendo la ventaja característica de xAI en cuanto a alta velocidad de procesamiento de tokens. Recomendamos a los equipos que dependen de la serie Grok que realicen pruebas de integración a través de la plataforma APIYI (apiyi.com) lo antes posible; su interfaz compatible con OpenAI permite minimizar los costes de migración al cambiar entre modelos.
Análisis detallado de las especificaciones y precios de Grok 4.3
Grok 4.3 es la última generación de modelos insignia de xAI, descrita en el correo como "el modelo más rápido e inteligente que hemos construido". Encabeza las listas de clasificación en llamadas a herramientas (tool calling) y seguimiento de instrucciones, posicionándose como un modelo insignia de propósito general para código, agentes y razonamiento complejo. En cuanto a especificaciones, Grok 4.3 amplía la ventana de contexto de los 256K de la era de Grok 4 a 1M de tokens, equiparándose a Gemini 3 Pro y Claude 4.7, lo que permite procesar bases de código completas o documentos técnicos extensos en una sola consulta.
La siguiente tabla resume los parámetros clave de Grok 4.3 en la API de xAI, con datos basados en el correo oficial y las pruebas de Artificial Analysis.
| Parámetro | Valor en Grok 4.3 | Notas |
|---|---|---|
| Ventana de contexto | 1,000,000 tokens | Entrada + Salida compartida |
| Precio de entrada | $1.25 / 1M tokens | 50% más barato que GPT-5.4, igual que Gemini 3.1 Pro |
| Precio de salida | $2.50 / 1M tokens | Reducción de aprox. 83% respecto a los $15 de Grok 4 |
| Intensidad de razonamiento | 3 niveles: bajo / medio / alto | Controla el presupuesto de razonamiento profundo |
| Modalidad de entrada | Texto + Imagen | Soporta comprensión visual |
| Modalidad de salida | Texto | No genera imágenes directamente |
| Llamada a herramientas | Llamada a funciones nativa | Soporta salida estructurada y llamadas paralelas |
| Velocidad de salida | ~207 tokens/s | Según pruebas de Artificial Analysis |
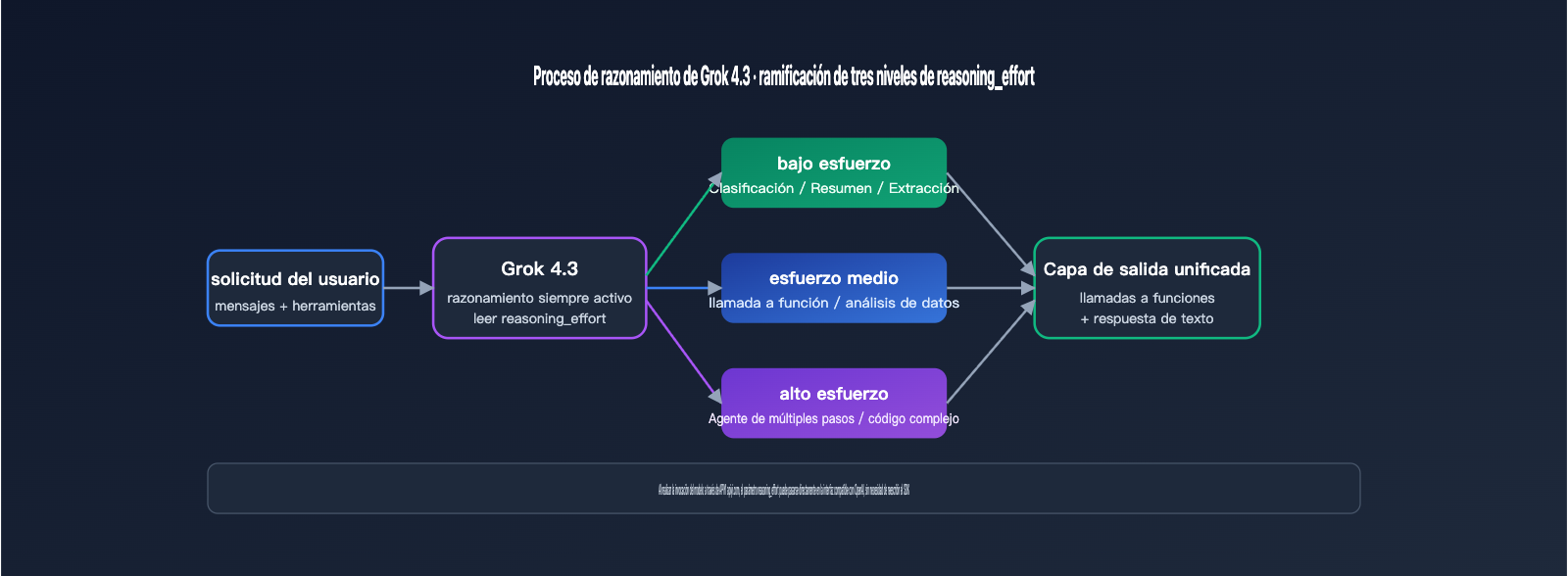
Los 3 niveles de intensidad de razonamiento (reasoning effort) son la característica clave que diferencia a Grok 4.3 de la generación anterior. Permiten a los desarrolladores ajustar la profundidad de "pensamiento" del modelo según la complejidad de la tarea, lo que afecta directamente a la latencia y al coste. Este mecanismo se inspira en el diseño de reasoning_effort de OpenAI, pero xAI ha configurado el razonamiento como un estado "siempre activo", permitiendo simplemente ajustar su profundidad. La siguiente tabla detalla los escenarios típicos y el impacto de cada nivel.
| Intensidad | Escenario típico | Latencia | Impacto en coste |
|---|---|---|---|
| Bajo | Clasificación simple, resúmenes, extracción | Cercana a modelos sin razonamiento | Mínima cantidad de tokens de salida |
| Medio | Llamadas a funciones, análisis de datos, autocompletado | Equilibrio entre latencia y calidad | Nivel recomendado por defecto |
| Alto | Agentes multietapa, matemáticas complejas, código largo | Fase de pensamiento más larga | Aumento significativo de tokens de salida |
🎯 Consejo de integración: Para los equipos que no estén seguros de qué nivel elegir, recomendamos realizar una prueba con un conjunto de datos real en la plataforma APIYI (apiyi.com) utilizando el nivel "medio", y luego decidir si es necesario subir al nivel "alto" basándose en la precisión y el retorno de inversión. La interfaz unificada permite cambiar el parámetro
reasoning_effortentre diferentes modelos con un solo clic, sin necesidad de reescribir el SDK.
Rendimiento de Grok 4.3 en los rankings de agentes e instrucción
La razón por la que xAI enfatizó en su correo que Grok 4.3 "encabeza los rankings en llamadas a herramientas de agentes y seguimiento de instrucciones" se basa en datos clave de plataformas independientes como Artificial Analysis, τ²-Bench, IFBench y GDPval-AA. El índice de inteligencia de Artificial Analysis le otorga una puntuación global de 53.2, con un coste total de evaluación de unos 395 dólares, lo que supone un ahorro de aproximadamente el 20% respecto a Grok 4.20. En τ²-Bench Telecom (que simula llamadas a herramientas bidireccionales en atención al cliente), el escenario más cercano a un agente real, Grok 4.3 obtuvo un 98%, una mejora de 5 puntos porcentuales frente a Grok 4.20, igualando a GLM-5.1.
Para los desarrolladores, lo más relevante es GDPval-AA, el ranking que mide el valor económico real de los flujos de trabajo. Grok 4.3 alcanzó 1500 ELO en GDPval-AA, superando por 321 puntos a la generación anterior (Grok 4.20 0309 v2, con 1179 ELO) y dejando atrás a modelos como Gemini 3.1 Pro Preview, Muse Spark, GPT-5.4 mini (xhigh) y Kimi K2.5. En cuanto al seguimiento de instrucciones, Grok 4.3 mantiene un 81% en IFBench, igualando a su predecesor.
| Benchmark | Puntuación Grok 4.3 | Comparativa | Capacidad principal |
|---|---|---|---|
| AA Intelligence Index | 53.2 | Superior al 98% | Inteligencia global |
| AA Coding Index | 41.0 | Superior al 89% | Codificación y refactorización |
| τ²-Bench Telecom | 98% | Igual a GLM-5.1 | Llamada a herramientas + Colaboración |
| IFBench | 81% | Igual a Grok 4.20 | Seguimiento de instrucciones complejas |
| GDPval-AA | ELO 1500 | Supera a Gemini 3.1 Pro Preview | Valor de flujo de trabajo real |
Es importante notar que la fortaleza de Grok 4.3 reside en los flujos de trabajo de agentes y la invocación de herramientas, no en competencias de algoritmos puros. Para aplicaciones como agentes de código, agentes de navegación o bots de atención al cliente que requieren una salida JSON estable y múltiples rondas de llamadas a herramientas, la fiabilidad de Grok 4.3 es notablemente superior. Sin embargo, si el escenario principal de su equipo es la síntesis de código puro tipo SWE-bench, recomendamos probar Grok 4.3, Claude 4.7 Opus y GPT-5.4 en la misma suite de pruebas a través de la plataforma APIYI (apiyi.com) y decidir el modelo principal según la tasa de éxito.
Lista de modelos retirados de la API de xAI y recomendaciones de migración
xAI retirará simultáneamente 8 modelos, abarcando razonamiento de texto, modelos de código y generación de imágenes, limpiando prácticamente todo el catálogo de la era Grok 4. Para los equipos que tienen nombres de modelos "hard-coded" en sus sistemas, esta es una fecha límite obligatoria para actualizar el código en los próximos 9 días. La siguiente tabla resume los modelos afectados y las rutas de sustitución recomendadas.
| Modelo a retirar | Tipo | Sustitución oficial | Notas de migración |
|---|---|---|---|
| grok-4-1-fast-reasoning | Razonamiento | grok-4.3 | Mejor calidad, menor precio |
| grok-4-1-fast-non-reasoning | No razonamiento | grok-4.20-non-reasoning | Mantiene baja latencia |
| grok-4-fast-reasoning | Razonamiento | grok-4.3 | Incluye 1M de ventana de contexto |
| grok-4-fast-non-reasoning | No razonamiento | grok-4.20-non-reasoning | Compatible con la API |
| grok-4-0709 | Razonamiento | grok-4.3 | Retirada de snapshot antiguo |
| grok-code-fast-1 | Código | grok-4.3 | Unificación en 4.3 |
| grok-3 | General | grok-4.3 | Fin de la era Grok 3 |
| grok-imagine-image-pro | Imagen | grok-imagine-image | Simplificación de SKU |
La fecha de retirada es el 15 de mayo de 2026 a las 12:00 PT (16 de mayo a las 03:00 hora de Pekín). Una vez pasada, todas las peticiones a estos 8 IDs devolverán error. Desde el aviso del 6 de mayo, los desarrolladores tienen una ventana de 9 días, un plazo ajustado para proyectos medianos y grandes. Recomendamos dividir la migración en 3 pasos: primero, localizar todos los IDs hard-coded; segundo, realizar pruebas de carga en la plataforma APIYI (apiyi.com); y tercero, cambiar el campo model mediante variables de entorno en lugar de modificar la lógica de negocio.
Como recordatorio especial, grok-code-fast-1 ha sido el modelo predeterminado para muchos proyectos de agentes de código en el último medio año. Su retirada significa que todas las herramientas tipo Cursor, plugins de IDE y agentes CLI que dependen de este ID deberán migrar a grok-4.3. En escenarios de código, la estabilidad de las llamadas a herramientas de Grok 4.3 es superior a la de grok-code-fast-1, aunque el coste por token es ligeramente mayor, por lo que será necesario reevaluar el presupuesto de llamadas.
Comparativa: Grok 4.3 frente a GPT-5.4, Claude 4.7 y Gemini 3.1 Pro
Con el lanzamiento de Grok 4.3 en el segundo trimestre de 2026, el mercado de los Modelos de Lenguaje Grande atraviesa uno de sus periodos de competencia más intensos. Claude Opus 4.7 mantiene el liderazgo con un 87,6% en SWE-bench Verified, Gemini 3.1 Pro alcanza un 94,3% en GPQA Diamond, y GPT-5.4 sigue siendo la referencia base en estabilidad de razonamiento para textos largos. El posicionamiento de Grok 4.3 es claro: "inteligencia equilibrada + precio extremadamente bajo + cadena de herramientas para agentes", ideal para escenarios de alta frecuencia sensibles a los costes.
La siguiente tabla compara los datos clave de estos cuatro modelos insignia en dimensiones comunes. Los precios están expresados en dólares por millón de tokens.
| Modelo | Precio entrada | Precio salida | Ventana de contexto | Escenarios principales |
|---|---|---|---|---|
| Grok 4.3 | $1.25 | $2.50 | 1M | Cadena de herramientas para agentes, llamadas frecuentes, razonamiento medio |
| GPT-5.4 | $2.50 | $15.00 | 400K | Consistencia en textos largos, planificación compleja |
| Claude 4.7 Opus | $15.00 | $75.00 | 1M | Programación de alto nivel, redacción, análisis profundo |
| Gemini 3.1 Pro | $2.00 | $12.00 | 2M | Multimodal, comprensión de vídeo, documentos extensos |
De esta tabla se desprende un hecho evidente: el precio de los tokens de salida de Grok 4.3 es 30 veces más barato que el de Claude 4.7 Opus y unas 4,8 veces más económico que el de Gemini 3.1 Pro. Para tareas como agentes de atención al cliente de alta frecuencia, linters de código o limpieza masiva de datos, la ventaja de costes de Grok 4.3 es abrumadora. Sin embargo, en escenarios que requieren una calidad de codificación extrema o una comprensión multimodal avanzada, Claude 4.7 Opus y Gemini 3.1 Pro siguen siendo insustituibles.
🎯 Consejo de estrategia multimodelo: Recomendamos utilizar Grok 4.3 para la capa general de alta frecuencia, Claude 4.7 Opus para la capa de código complejo y redacción de documentos, y Gemini 3.1 Pro para la capa multimodal. Al utilizar la interfaz unificada de APIYI (apiyi.com) en la capa de enrutamiento de negocio, podrás aprovechar la rentabilidad de Grok 4.3 y, al mismo tiempo, acceder a modelos más potentes en los nodos críticos.
Guía de migración y ejemplos de código para Grok 4.3
La migración a Grok 4.3 es muy directa a nivel de ingeniería. xAI proporciona una interfaz de chat completions compatible con OpenAI, por lo que la mayor parte del trabajo consiste simplemente en modificar los campos base_url y model. Para proyectos que ya utilizan el SDK de OpenAI, el siguiente ejemplo minimalista en Python es todo lo que necesitas.
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1",
)
resp = client.chat.completions.create(
model="grok-4.3",
messages=[
{"role": "user", "content": "Explica en una frase qué es el esfuerzo de razonamiento (reasoning effort)"},
],
extra_body={"reasoning_effort": "medium"},
)
print(resp.choices[0].message.content)
Al apuntar la base_url a la plataforma APIYI (apiyi.com), tu negocio dispondrá de un punto de entrada unificado para Grok 4.3, Claude 4.7, GPT-5.4 y Gemini 3.1 Pro. Cambiar de modelo en el futuro solo requerirá ajustar el parámetro model, sin necesidad de reescribir el código de autenticación o enrutamiento. Esta abstracción unificada reduce significativamente los riesgos de migración antes de la fecha límite del 15 de mayo.
Para la migración de modelos antiguos, hemos preparado una tabla de cambios mínimos para pasar de los IDs antiguos a los nuevos, que puedes aplicar directamente en tu código.
| Campo model antiguo | Campo model nuevo | ¿Requiere otros parámetros? |
|---|---|---|
| grok-3 | grok-4.3 | Opcional: añadir reasoning_effort |
| grok-4-0709 | grok-4.3 | Opcional: añadir reasoning_effort |
| grok-4-fast-reasoning | grok-4.3 | Opcional: añadir reasoning_effort |
| grok-4-fast-non-reasoning | grok-4.20-non-reasoning | No requiere otros cambios |
| grok-code-fast-1 | grok-4.3 | Recomendado: reasoning_effort=high |
| grok-imagine-image-pro | grok-imagine-image | El endpoint de la API de imágenes se mantiene igual |
Preguntas frecuentes (FAQ) sobre Grok 4.3
P1: ¿Grok 4.3 realmente admite una ventana de contexto de 1M? ¿El rendimiento disminuye con textos largos?
Sí, Grok 4.3 ofrece oficialmente una ventana de contexto de 1M de tokens a través de la API de xAI, situándose al mismo nivel que Claude 4.7 Opus. Sin embargo, al igual que ocurre con todos los modelos de contexto largo, la comprensión de las instrucciones puede sufrir cierta degradación después de los 600K tokens. Recomendamos colocar la información clave en la primera mitad del documento. Puedes utilizar la plataforma APIYI (apiyi.com) para realizar una prueba de tasa de recuperación con documentos reales de tu negocio antes de decidir si adoptar Grok 4.3 como tu modelo principal para textos largos.
P2: ¿Cómo elegir entre las intensidades de razonamiento low / medium / high?
Utiliza low para tareas de bajo riesgo (clasificación, resúmenes, extracción de reglas), medium para tareas habituales (atención al cliente, invocación de funciones, análisis de datos) y high para razonamientos complejos (agentes de múltiples pasos, cadenas de código largas, matemáticas complejas). El nivel high aumentará significativamente los tokens de salida y la latencia, por lo que recomendamos evaluar esto en función de tu presupuesto y los SLA de latencia.
P3: Después del 15 de mayo a las 12:00 PT, ¿se podrán seguir usando los modelos antiguos?
No. El correo electrónico de xAI especifica claramente: "Después del 15 de mayo de 2026, las solicitudes a estos modelos dejarán de funcionar". Las solicitudes a modelos caducados devolverán un error directamente. Todo el código que tenga IDs de modelos antiguos "hardcodeados" debe actualizarse antes de la fecha límite.
P4: ¿Cómo minimizar los costes de migración?
La forma más segura es abstraer el campo model en tus variables de entorno o archivos de configuración, en lugar de escribirlos directamente en el código. Al utilizar la interfaz compatible con OpenAI de APIYI (apiyi.com), la migración se reduce a un simple cambio de configuración y una prueba de regresión.
P5: ¿Es Grok 4.3 adecuado para un Agente de programación (Coding Agent)?
Sí, lo es. Grok 4.3 obtuvo un 98% en τ²-Bench Telecom; su estabilidad en la invocación de herramientas y en conversaciones de múltiples turnos es superior a la de grok-code-fast-1. Además, su coste unitario es extremadamente bajo, lo que lo hace ideal para plugins de IDE, agentes CLI y scripts de automatización de operaciones que requieren invocaciones frecuentes.
Resumen: Puntos clave sobre el lanzamiento de Grok 4.3 y la migración a la API de xAI
Lo más destacado del lanzamiento de Grok 4.3 no es solo que sea "más potente", sino que es "más potente y a la vez más barato". Con un precio de $1.25/$2.50, xAI ha llevado la ventana de contexto de 1M y la invocación de herramientas de alta calidad al mismo rango de precios que Gemini 3.1 Pro, redefiniendo directamente la relación coste-rendimiento para el uso general de alta frecuencia. Al mismo tiempo, la retirada de 8 modelos antiguos el 15 de mayo recuerda a todos los equipos que los IDs de los modelos no deben estar "hardcodeados" en el código, sino abstraídos detrás de una capa de enrutamiento configurable.
Recomendamos utilizar Grok 4.3 como pilar para las invocaciones frecuentes y las cadenas de herramientas de agentes, realizando la migración a través de la interfaz unificada de APIYI (apiyi.com). Esto reducirá los costes de cambio al mínimo, manteniendo al mismo tiempo la capacidad de combinar múltiples modelos como Claude 4.7 Opus, GPT-5.4 y Gemini 3.1 Pro, permitiéndote realizar una programación dinámica según la tarea para obtener el mejor equilibrio global entre coste y calidad.
Equipo técnico de APIYI · Enfocados en contenido práctico sobre APIs de modelos de IA y herramientas para desarrolladores. Para más artículos técnicos, visita apiyi.com