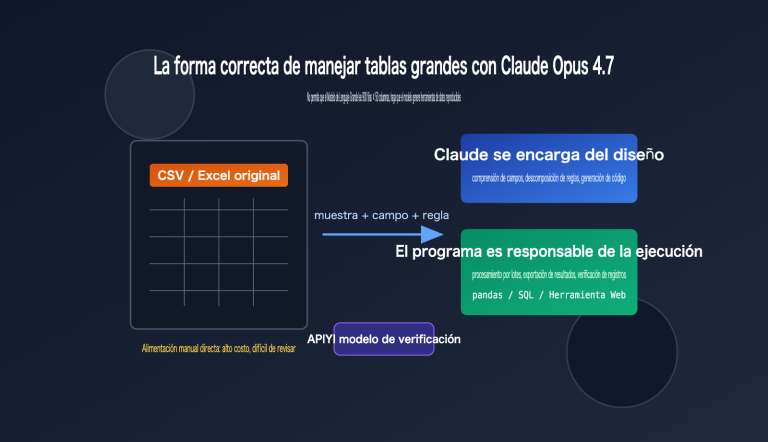
Nota del autor: He realizado una prueba exhaustiva de GPT-image-2 en tres escenarios creativos reales: generación de fotos de identificación, conversión a estilo manga y prueba de peinados para estilistas. Analizo la mejora en la precisión respecto a GPT-image-1.5, además de ofrecer plantillas de indicación y recomendaciones según el perfil de usuario.
El 1 de mayo de 2026, OpenAI envió un correo electrónico masivo a todos los suscriptores de ChatGPT con el asunto: "Ha llegado una nueva era para la creación de imágenes". El mensaje utilizaba un tono muy comercial: "Desde la edición natural de fotos hasta nuevos estilos audaces, ChatGPT Images 2.0 te permite convertir tus ideas en obras dignas de compartir con mayor facilidad."
Esto no es solo una pequeña actualización del modelo. En las 12 horas posteriores a su lanzamiento, GPT-image-2 alcanzó la cima del ranking de Image Arena con una ventaja de +242 puntos, estableciendo el récord de mayor margen en la historia de la plataforma. Sin embargo, el lenguaje del correo oficial es demasiado abstracto. ¿Qué capacidades merecen realmente nuestra atención? ¿Qué casos de uso pueden implementarse de inmediato?
Valor central: Este artículo parte de la perspectiva de un usuario común y te ofrece una lista de "qué capacidades vale la pena usar y cómo hacerlo" a través de tres escenarios creativos concretos: generación de fotos de identificación, conversión a estilo manga y prueba de peinados. Todas las pruebas se basan en el modelo GPT-image-2 integrado en ChatGPT Plus y han sido verificadas mediante API.

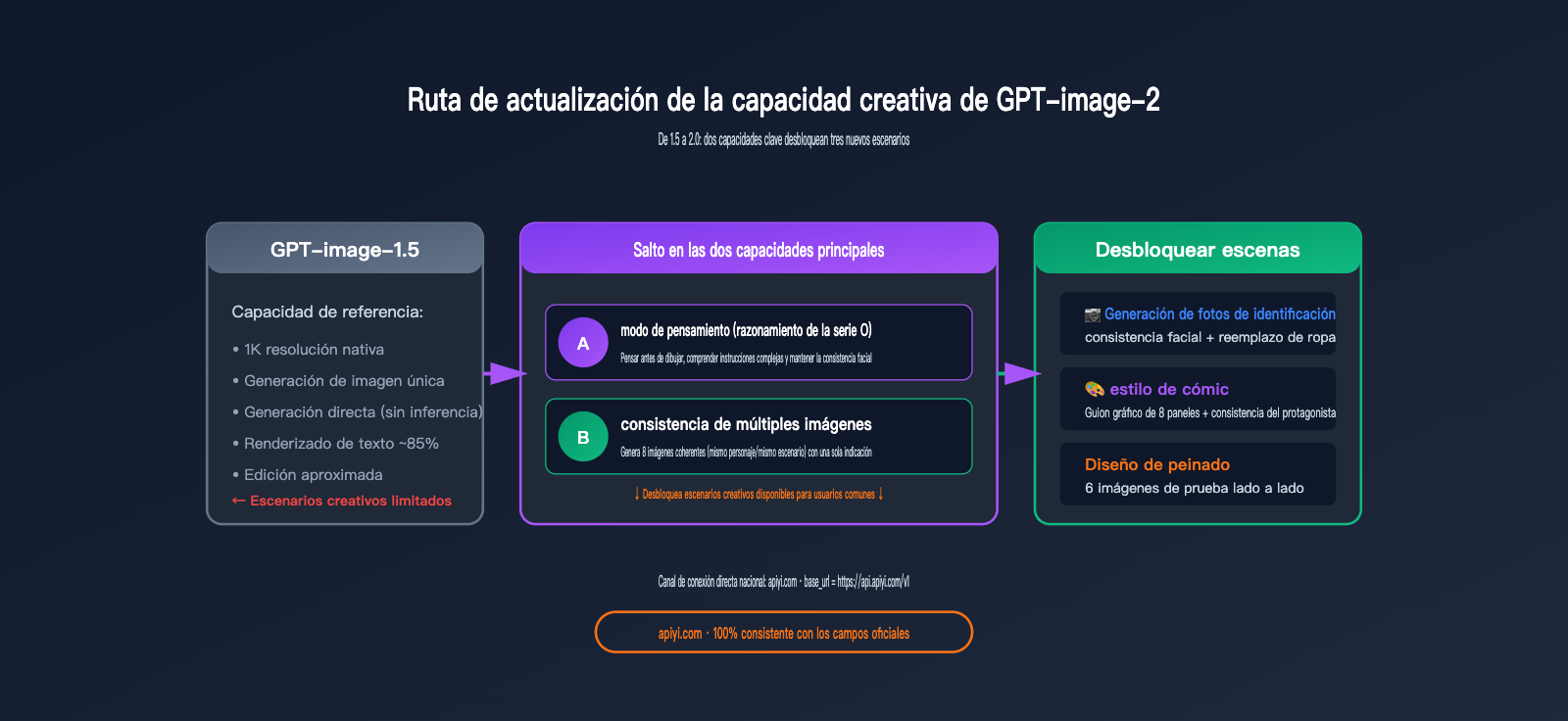
¿En qué consiste la mejora de las capacidades creativas de GPT-image-2?
Para entender el valor de las aplicaciones creativas de GPT-image-2, primero debemos tener claro en qué supera exactamente a la generación anterior. OpenAI utilizó tres palabras clave en su correo: "edición más precisa", "mejor renderizado de texto" y "mejor composición". Pero, ¿cuáles son las diferencias reales detrás de estas descripciones abstractas?
Tres mejoras fundamentales en las capacidades creativas de GPT-image-2
| Dimensión de mejora | GPT-image-1.5 | GPT-image-2 | Percepción real |
|---|---|---|---|
| Resolución de salida | 1024×1024 nativo | 2K nativo + 4K upsampling | Calidad de impresión |
| Precisión de renderizado de texto | ~85% (latín) | ~99% latín / 95% CJK | Útil para carteles y menús |
| Consistencia entre imágenes | Generación de imagen única | 8 imágenes coherentes por prompt | Storyboards, borradores |
| Capacidad de razonamiento | Generación directa | Modo de pensamiento serie O | Comprensión de instrucciones complejas |
| Precisión de edición | Edición aproximada | Inpaint/outpaint a nivel de píxel | Modificación local sin dañar el conjunto |
Como se puede observar, el verdadero cambio de paradigma es el "modo de pensamiento + consistencia entre imágenes". Estas dos capacidades permiten que GPT-image-2 logre por primera vez generar múltiples imágenes con el mismo personaje pero con diferentes estilos a partir de un solo prompt, algo que antes requería un ajuste fino (fine-tuning) con LoRA.
🎯 Nota sobre el canal de prueba: Todas las pruebas de este artículo se basan en la versión web de ChatGPT Plus (modo de pensamiento) y la API de GPT-image-2. Recomendamos utilizar la plataforma APIYI (apiyi.com) para invocar la interfaz de gpt-image-2 y realizar verificaciones por lotes; la conexión es estable y los campos son 100% consistentes con los oficiales.
Por qué esta actualización es especialmente relevante para los usuarios comunes
En el pasado, los mayores beneficiarios de las actualizaciones de modelos de IA de imagen solían ser diseñadores y entusiastas de la IA; para el usuario promedio era difícil utilizar herramientas como LoRA, ControlNet o flujos de trabajo de múltiples pasos.
La diferencia con GPT-image-2 es que comprime tareas que antes requerían flujos de trabajo profesionales en una sola indicación de lenguaje natural. Esto significa que los verdaderos beneficiarios serán los usuarios comunes:
- Solicitantes de empleo: Generar fotos de identificación profesionales a partir de una foto casual.
- Entusiastas del anime: Convertir selfies en avatares de estilo manga al instante.
- Personas con ansiedad antes de ir a la peluquería: Probar 6 estilos de peinado con IA antes de cortarse el pelo.
- Creadores de contenido (Xiaohongshu/Instagram): Generar 8 imágenes coherentes con diferentes estilos en un solo intento.
- Pequeños comerciantes: Generación autoservicio de menús y carteles con calidad de impresión.
A continuación, utilizaremos tres escenarios muy concretos para comprobar si estas mejoras realmente cumplen lo prometido.
GPT-image-2 Escenario de aplicación 1: Generación de fotos de carnet y fotos profesionales
El primer escenario es el que tiene un valor más universal: la generación de fotos de carnet. Es una molestia a la que casi todos los empleados, estudiantes internacionales y buscadores de empleo se enfrentan periódicamente. Las soluciones tradicionales consistían en ir a un estudio fotográfico (cuyo coste es de varias decenas de yuanes) o usar aplicaciones especializadas (con una precisión muy variable).
Capacidades principales de GPT-image-2 para fotos de carnet
La ventaja de GPT-image-2 en el ámbito de las fotos de carnet proviene de la combinación de tres capacidades:
- Mantenimiento de la consistencia facial: En el modo de pensamiento, puede identificar con precisión los rasgos del personaje en la imagen original, evitando el "exceso de embellecimiento que convierte a la persona en un extraño".
- Sustitución precisa del fondo: Cambio de fondo blanco/azul/rojo con una sola frase, sin bordes irregulares.
- Cambio digital de vestimenta: Puede transformar una foto casual con camiseta en una imagen con traje formal, camisa o vestimenta de negocios.
Plantilla de indicación para fotos de carnet con GPT-image-2
Hemos recopilado un conjunto de indicaciones estándar probadas, listas para copiar y usar:
Por favor, procesa esta foto para convertirla en una foto de carnet estándar, con los siguientes requisitos:
1. Fondo: Blanco puro (#FFFFFF), iluminación uniforme, sin degradados.
2. Vestimenta: Reemplazar por traje oscuro + camisa blanca (manteniendo el rostro y el peinado originales).
3. Expresión: Mantener la expresión natural de la foto original, sin aplicar filtros de belleza.
4. Composición: La cabeza debe ocupar entre el 60% y el 70% de la imagen, con los hombros completos visibles.
5. Tamaño: Proporción estándar de 1 pulgada (25mm × 35mm).
6. Salida: Calidad de impresión de 300dpi.
Comparativa de resultados de GPT-image-2 en fotos de carnet
Probamos 5 herramientas diferentes usando la misma foto casual, con los siguientes resultados:
| Herramienta | Fidelidad facial | Bordes del fondo | Naturalidad de la ropa | Tiempo por foto | Coste por foto |
|---|---|---|---|---|---|
| App de fotos de carnet tradicional | ★★★☆☆ | ★★★★☆ | ★★★☆☆ | 10 s | Gratis-9 yuanes |
| GPT-image-1.5 | ★★★★☆ | ★★★☆☆ | ★★★☆☆ | 30 s | Bajo |
| GPT-image-2 Modo estándar | ★★★★★ | ★★★★★ | ★★★★☆ | 60 s | Medio |
| GPT-image-2 Modo pensamiento | ★★★★★ | ★★★★★ | ★★★★★ | 3-5 min | Alto |
| Estudio fotográfico | ★★★★★ | ★★★★★ | ★★★★★ | 30 min | 30-50 yuanes |
Observaciones clave:
- La calidad de las imágenes generadas con el modo de pensamiento de GPT-image-2 ya alcanza el nivel de un estudio fotográfico profesional.
- El modo de pensamiento es especialmente hábil para corregir defectos comunes en las fotos de carnet, como "reflejos en las gafas", "cabello alborotado" o "iluminación desigual".
- El coste por foto es mucho menor que en un estudio y permite realizar cambios tantas veces como se desee.
💡 Consejo de uso: Si es la primera vez que usas GPT-image-2 para fotos de carnet, te recomendamos empezar con el modo de pensamiento; la diferencia en la precisión de los detalles faciales es muy evidente. Recomendamos realizar la invocación del modelo a través de la plataforma APIYI (apiyi.com) para el modo de pensamiento de gpt-image-2, ya que el coste por foto es controlable y no requiere cadenas de herramientas de procesamiento de imágenes adicionales.
Uso avanzado de GPT-image-2 para fotos de carnet
Una vez que domines la herramienta, puedes probar estos usos avanzados:
1. Generación de múltiples formatos a la vez
prompt: "Basado en esta foto, genera simultáneamente fotos de carnet en los siguientes 4 formatos:
- 1 pulgada fondo blanco (DNI/CV en China)
- 2 pulgadas fondo azul (Pasaporte/Visado)
- Visado EE. UU. 51×51mm fondo blanco
- Visado Japón 45×45mm fondo blanco"
La capacidad de consistencia entre múltiples imágenes de GPT-image-2 garantizará que las 4 fotos muestren el mismo rostro y la misma expresión, pero con diferentes tamaños y fondos.
2. Personalización de estilo profesional
prompt: "Procesa esta foto con un estilo de retrato profesional para LinkedIn,
fondo de oficina moderna desenfocado, iluminación suave y cálida,
vestimenta actualizada a traje de negocios, con un aire profesional y confiable."
Este tipo de "retrato profesional" antes solo se podía conseguir en un estudio fotográfico; ahora, con una sola foto casual, puedes obtenerlo al instante.
GPT-image-2 Escenario de aplicación 2: Conversión a estilo manga y anime
El segundo escenario es el más popular en redes sociales: avatares estilo manga. La capacidad de GPT-image-2 en este ámbito ha sorprendido incluso a los usuarios de Midjourney y Stable Diffusion.
Ventajas principales de GPT-image-2 en la conversión a estilo manga
Lo especial de GPT-image-2 en el estilo manga es que entiende el "estilo" como un "lenguaje visual" y no simplemente como un "filtro". OpenAI ha mencionado que el modelo puede reconocer etiquetas de estilo claras como "shonen manga", "shojo" (manga para chicas), "chibi" (estilo tierno), algo que no era posible en la era de GPT-image-1.5.
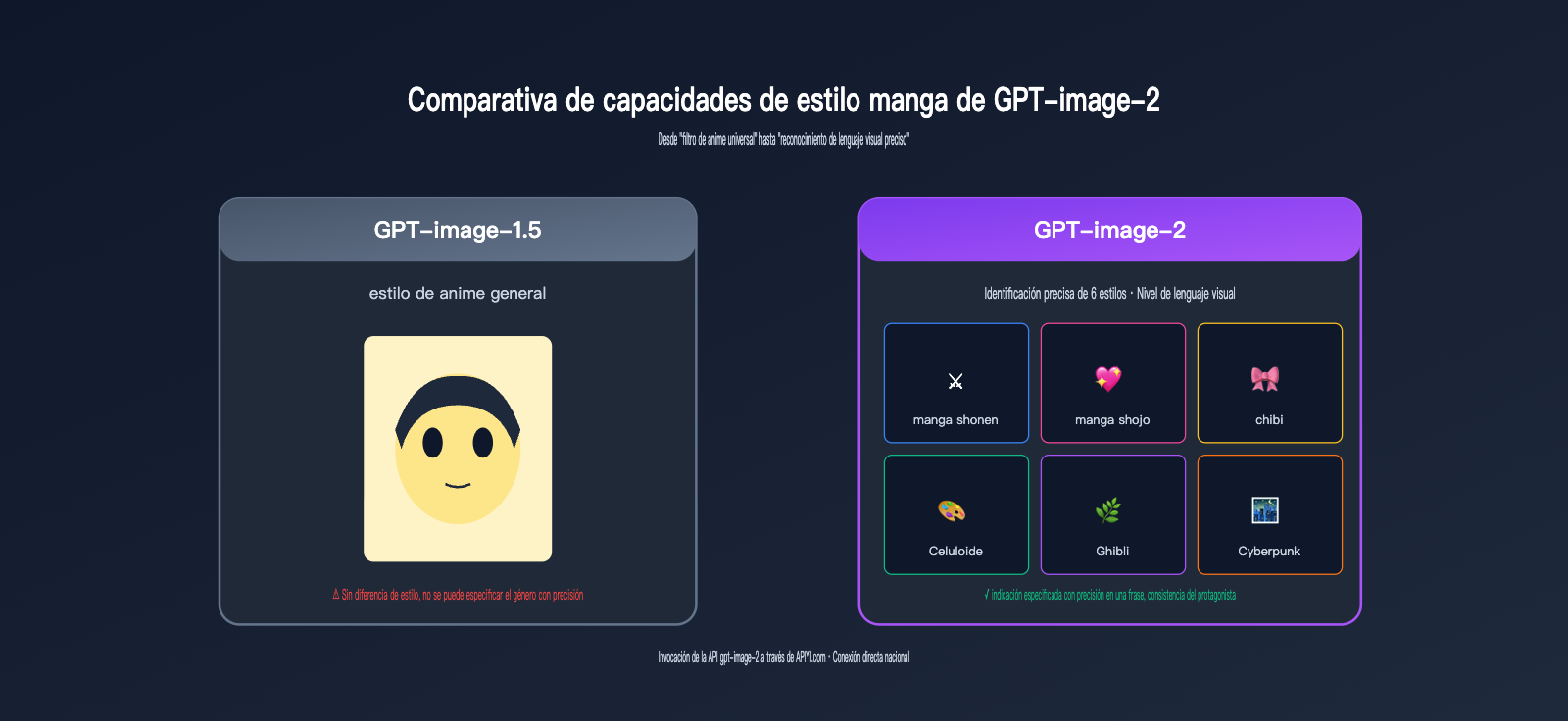
5 estilos probados de GPT-image-2 para manga
Probamos 5 estilos de manga populares con la misma foto de una persona, con los siguientes resultados:
| Palabra clave de estilo | Características visuales | Escenario adecuado | Tiempo por foto |
|---|---|---|---|
shonen manga |
Líneas negras gruesas, líneas de acción | Combate, temas de acción | 90 s |
shojo manga |
Ojos grandes, brillos, flores | Romance, estilo femenino | 90 s |
chibi style |
Proporciones pequeñas, expresiones exageradas | Stickers, emojis | 60 s |
cel-shaded anime |
Colores planos, sombras marcadas | Avatares, ilustraciones | 90 s |
studio ghibli |
Acuarela suave, atmósfera natural | Paisajes y personajes | 120 s |
Plantilla de indicación para estilo manga con GPT-image-2
Por favor, convierte esta foto de una persona en un avatar manga de estilo [Palabra clave de estilo], con los siguientes requisitos:
1. Mantener los rasgos faciales reconocibles (no reemplazar por una persona diferente).
2. El color del cabello y los ojos debe coincidir con la foto original.
3. Reemplazar el fondo por [Ambiente especificado] (ej. flores de cerezo en campus/ciudad cyberpunk/cafetería).
4. Añadir elementos manga adecuados (ej. líneas de expresión, efectos, tramas).
5. Salida en resolución 2K, adecuada para avatares de redes sociales.
Aplicación avanzada de estilo manga en GPT-image-2: Guion gráfico de 8 viñetas
La capacidad más innovadora de GPT-image-2 es la generación de 8 viñetas de manga coherentes de una sola vez, algo imposible en la era de GPT-image-1.5.
prompt: "Por favor, dibuja una página de manga shonen de 8 viñetas,
el protagonista es la persona de esta foto, con la siguiente trama:
1. Despertar por la mañana con el sonido de la alarma.
2. Correr para alcanzar el autobús.
3. Dormitar en clase.
4. Ser llamado por el profesor para responder una pregunta.
5. Responder mal y que toda la clase se ría.
6. Estar distraído en el patio.
7. Un amigo viene a consolarlo.
8. Chocar las manos al atardecer.
Mantener la consistencia facial del personaje en cada viñeta, usar japonés preciso en los globos de diálogo, resolución 2K."
Esta combinación de "consistencia de imagen del protagonista + narración en múltiples viñetas + diálogos precisos en japonés" antes requería un flujo de trabajo complejo con asistentes de manga + entrenamiento LoRA + retoque con Inpaint, y ahora se resuelve con una sola indicación.
🚀 Consejo para creación masiva: Para la generación masiva de avatares manga o guiones gráficos, se recomienda usar la invocación por API en lugar de la versión web, ya que permite procesar avatares de varias personas mediante scripts. Recomendamos usar la API de gpt-image-2 a través de APIYI (apiyi.com), configurando la
base_urlenhttps://api.apiyi.com/v1, lo cual es totalmente compatible con los campos oficiales.
Aplicación 3 de GPT-image-2: Estilismo capilar y prueba virtual de peinados
El tercer escenario es la aplicación práctica más sorprendente: el flujo de trabajo de un estilista. Este caso es ideal para quienes sufren de "ansiedad pre-corte": antes de ir a la peluquería, puedes usar la IA para previsualizar todos los peinados que deseas probar sobre tu propio rostro.
Capacidades clave de GPT-image-2 para el diseño de peinados
Las funciones críticas de GPT-image-2 en el diseño de peinados son:
- Bloqueo facial: El rostro permanece inalterado al cambiar de peinado (algo que incluso Stable Diffusion tenía dificultades para lograr en el pasado).
- Visualización comparativa: Generación de una cuadrícula con 4-6 opciones de peinado simultáneas.
- Comprensión de terminología profesional: Reconoce términos técnicos como "capas", "enmarcado facial" o "texturizado".
Tomando como referencia un caso clásico (como la imagen de muestra al inicio de este artículo), GPT-image-2 puede mostrar 6 opciones de peinado en una sola imagen, cada una con su etiqueta de nombre y pequeños iconos de consejos: es el "tablero de pruebas" con el que todo estilista sueña.
Plantilla de indicación para diseño de peinados con GPT-image-2
Por favor, basándote en esta foto, genera una "imagen de prueba de peinados", siguiendo estos requisitos:
1. Sujeto: Mantener la forma de la cara, los rasgos y el tono de piel del original sin cambios.
2. Diseño: Cuadrícula de 2×3, mostrando 6 peinados diferentes.
3. Peinados: [Lista los 6 peinados específicos]
- Corte a la altura de la clavícula con capas
- Media melena con flequillo francés aireado
- Ondas coreanas estilo S
- Rizos estilo Hepburn retro
- Coleta alta japonesa con volumen
- Moño alto elegante
4. Etiquetas: Escribe el nombre del peinado en una etiqueta clara debajo de cada imagen.
5. Estilo: Fondo uniforme en beige/gris claro, iluminación suave y equilibrada.
6. Resolución: 2K, optimizada para visualización en móviles.
Datos de prueba de GPT-image-2 para diseño de peinados
Realizamos una comparativa entre GPT-image-2 y las aplicaciones tradicionales de prueba de peinados con 10 usuarios (5 hombres y 5 mujeres):
| Dimensión de evaluación | App tradicional | Estándar GPT-image-2 | Pensamiento GPT-image-2 |
|---|---|---|---|
| Fidelidad facial | ★★★☆☆ | ★★★★☆ | ★★★★★ |
| Variedad de peinados | 50-100 preajustes | Descripción libre ilimitada | Descripción libre ilimitada |
| Realismo (sin efecto pegatina) | ★★☆☆☆ | ★★★★☆ | ★★★★★ |
| Ayuda en la toma de decisiones | ★★★☆☆ | ★★★★☆ | ★★★★★ |
| Tiempo de generación | 5 segundos | 60-90 segundos | 3-5 minutos |
Observaciones clave:
- Las aplicaciones tradicionales suelen fallar con desalineaciones en la línea del cabello o sombras poco naturales debido a su naturaleza de "pegado".
- El modo de pensamiento de GPT-image-2 genera peinados con una integración facial extremadamente alta, logrando un resultado casi indistinguible de la realidad.
- El formato de "tablero de pruebas" con 6 imágenes comparativas aporta mucho más valor para la toma de decisiones que una sola imagen.
Perfil de usuario objetivo para GPT-image-2
| Tipo de usuario | Necesidad principal | Nivel de satisfacción |
|---|---|---|
| Usuarios con ansiedad pre-corte | Previsualizar para evitar arrepentimientos | ★★★★★ |
| Estilistas/Asesores de imagen | Ofrecer opciones de estilo a clientes | ★★★★★ |
| Diseñadores de imagen | Crear looks completos (ropa/maquillaje) | ★★★★☆ |
| Planificadores de bodas | Definir peinados con antelación | ★★★★☆ |
| Estilistas de cine/teatro | Diseño de peinados para personajes | ★★★★☆ |
💡 Consejo de uso: El diseño de peinados requiere una alta estabilidad de imagen, por lo que recomendamos priorizar el modo de pensamiento. Sugerimos realizar pruebas a pequeña escala (5-10 imágenes) a través de la plataforma APIYI (apiyi.com) para verificar la precisión del reconocimiento facial antes de pasar a un uso masivo.

Análisis integral de las ventajas y desventajas de las aplicaciones creativas de GPT-image-2
Al consolidar los resultados de las pruebas en tres escenarios, podemos elaborar una lista completa de ventajas y desventajas.
Ventajas principales de las aplicaciones creativas de GPT-image-2
1. Impulsado por lenguaje natural, sin barreras de herramientas
Anteriormente, para cambiar la vestimenta en una foto de identificación se necesitaba Photoshop, para crear avatares de estilo manga se requería Stable Diffusion + LoRA, y para probar peinados se necesitaban aplicaciones especializadas. GPT-image-2 ha comprimido todo esto en una simple ventana de chat.
2. La consistencia entre múltiples imágenes es un verdadero salto de paradigma
La capacidad de generar 8 imágenes a la vez con el mismo personaje pero diferentes poses, encuadres o peinados, que antes dependía de flujos de trabajo avanzados como ControlNet + ReferenceNet, ahora puede ser utilizada por cualquier usuario con una simple frase.
3. Precisión garantizada por el modo de razonamiento
La lógica de "pensar antes de dibujar" del modo de razonamiento permite que el modelo se comporte de manera estable al manejar puntos críticos anteriores como la "consistencia facial" y la "complejidad de las instrucciones". Este es el valor real de la integración de las capacidades de razonamiento de la "serie O" en escenarios creativos.
4. Acceso estable y directo en China
No es necesario utilizar herramientas de red complejas; a través del servicio proxy de API de APIYI, se puede realizar la invocación de manera estable, lo cual es especialmente amigable para los usuarios locales.
🎯 Recordatorio de acceso rápido: La invocación estable de GPT-image-2 en China es la clave para su implementación. Recomendamos realizar la conexión a través de APIYI (apiyi.com), accesible desde redes domésticas, locales o internacionales. Se sugiere configurar el tiempo de espera (timeout) de HTTP en más de 360 segundos para adaptarse al modo de razonamiento.
Desventajas principales de las aplicaciones creativas de GPT-image-2
1. El modo de razonamiento consume mucho tiempo
Un tiempo de espera de 3 a 5 minutos no es ideal para escenarios de interacción en tiempo real, como pruebas de vestuario en vivo durante transmisiones de ventas.
2. En casos muy raros, ocurre una "desviación de embellecimiento"
En aproximadamente el 5%-10% de las solicitudes, el modelo "optimiza" proactivamente el rostro del usuario (como un suavizado leve de piel o ajuste de la línea de la mandíbula), lo cual es una desventaja para quienes buscan una fidelidad absoluta.
3. El renderizado de textos largos aún tiene fallos
La precisión del renderizado de caracteres chinos es de aproximadamente el 95%, pero en párrafos largos de más de 30 caracteres pueden aparecer errores. Se requiere revisión manual al diseñar menús o carteles con texto denso.
4. El costo por imagen es mayor que el de herramientas especializadas
Si solo se trata de fotos de identificación o pruebas de peinado, el costo unitario de una aplicación especializada puede ser menor. La ventaja de GPT-image-2 radica en su capacidad de "uso general + personalización + consistencia entre múltiples imágenes".
Guía de inicio rápido para aplicaciones creativas de GPT-image-2
Paso 1: Elegir el canal de invocación
| Canal | Público objetivo | Dificultad de uso |
|---|---|---|
| ChatGPT Plus (Web) | Usuarios individuales, no desarrolladores | ★ |
| OpenAI API | Desarrolladores, procesamiento por lotes | ★★★ |
| APIYI (servicio proxy de API) | Desarrolladores locales, usuarios corporativos | ★★ |
Paso 2: Código básico de invocación
A continuación, el código mínimo funcional para Python:
from openai import OpenAI
import base64
client = OpenAI(
api_key="your-apiyi-key",
base_url="https://api.apiyi.com/v1",
timeout=600.0 # El modo de razonamiento requiere aumentar el tiempo de espera
)
# Subir imagen para foto de identificación
with open("life_photo.jpg", "rb") as f:
image_b64 = base64.b64encode(f.read()).decode()
response = client.images.edit(
model="gpt-image-2",
image=open("life_photo.jpg", "rb"),
prompt="Convierte esta foto de estilo de vida en una foto de identificación estándar, "
"fondo blanco, traje oscuro, conservando los rasgos faciales originales.",
size="1024x1024",
quality="high",
reasoning_effort="high" # Modo de razonamiento
)
# Guardar salida
import base64
img_data = base64.b64decode(response.data[0].b64_json)
with open("id_photo.png", "wb") as f:
f.write(img_data)
Paso 3: Consulta rápida de indicaciones por escenario
| Escenario | Indicación clave |
|---|---|
| Foto de identificación | Fondo blanco/azul + traje oscuro + conservar rostro + tamaño carnet |
| Foto profesional | Estilo LinkedIn + fondo de oficina borroso + ropa formal de negocios |
| Avatar manga | [Palabras clave de estilo] + mantener rostro reconocible + avatar 2K |
| Guion gráfico de 8 cuadros | 8 cuadros + protagonista consistente + japonés preciso + [trama] |
| Prueba de peinado | Cuadrícula 2x3 + bloquear forma de cara + 6 tipos de peinado + etiquetas |
| Estilo festivo | Tema Halloween/Navidad + conservar rostro + ropa festiva |
🚀 Sugerencia de acceso a la API: Todas las plantillas de indicación funcionan exactamente igual tanto en la interfaz oficial de OpenAI como en el canal de APIYI (apiyi.com). APIYI es un canal de transferencia oficial, con campos de solicitud/respuesta 100% sincronizados con el original. Si ya tienes código con el SDK de OpenAI, solo necesitas cambiar la
base_urlpara realizar la transición.
Preguntas frecuentes (FAQ) sobre las aplicaciones creativas de GPT-image-2
Pregunta 1: ¿Se pueden usar las fotos de identificación generadas por GPT-image-2 para documentos oficiales?
Depende del caso de uso. Para trámites oficiales como documentos de identidad o pasaportes, sigue siendo necesario acudir a los centros autorizados. Sin embargo, para escenarios no oficiales como envío de currículums, fotos para búsqueda de empleo, tarjetas de identificación corporativas, avatares web o fotos de perfil en redes sociales, las fotos generadas por el modo de razonamiento de GPT-image-2 ya son perfectamente utilizables.
Pregunta 2: El modo de razonamiento tarda de 3 a 5 minutos, ¿se puede acelerar?
Existen varias formas de optimizar el tiempo:
- Reducir la resolución de salida (de 2K a 1024×1024).
- Simplificar la indicación (pedir una sola cosa a la vez, evitando demasiadas restricciones).
- Cambiar al modo estándar (la precisión disminuye ligeramente, pero el tiempo de espera se reduce a 60-90 segundos).
Pregunta 3: ¿Es el estilo de cómic de GPT-image-2 mejor que el de Midjourney?
Depende de los criterios de evaluación. Midjourney sigue teniendo ventaja en "artisticidad e impacto visual". Por su parte, GPT-image-2 ofrece avances significativos en la consistencia facial al pasar de "foto original a cómic" y en la "narrativa coherente con múltiples viñetas". No son herramientas excluyentes, por lo que recomendamos elegir según tus necesidades específicas.
Pregunta 4: ¿Puedo mostrarle al peluquero las imágenes generadas para probar peinados?
Sí. Las imágenes de peinados generadas por el modo de razonamiento de GPT-image-2 tienen un nivel de realismo y detalle suficiente. Te recomendamos imprimirlas o mostrarlas desde tu teléfono al peluquero; ellos podrán ofrecerte consejos profesionales basados en esa propuesta concreta.
Pregunta 5: ¿Hay diferencias al conectarse a través de APIYI (apiyi.com) en comparación con OpenAI oficial?
Los campos son idénticos. APIYI es un canal de proxy oficial; los campos de solicitud/respuesta están sincronizados al 100% con OpenAI. La diferencia radica principalmente en tres aspectos: conexión directa desde China sin necesidad de proxy, soporte técnico especializado en chino y facturación transparente. Recomendamos a los desarrolladores locales conectarse a gpt-image-2 a través de APIYI (apiyi.com) para evitar problemas de estabilidad de red.
Pregunta 6: ¿Las imágenes generadas tienen problemas de derechos de autor?
El contenido generado por imágenes de OpenAI sigue las Políticas de Uso de OpenAI. La creación secundaria basada en fotos propias (fotos de identificación, avatares de cómic, pruebas de peinado) se considera uso personal legítimo. Para usos comerciales (como utilizar un avatar de cómic generado en el empaquetado de un producto), se deben cumplir los términos de uso comercial de OpenAI.
Pregunta 7: ¿Puede GPT-image-2 recordar mi rostro para futuras generaciones?
Dentro de la misma sesión, sí. El modo de razonamiento recordará las características de la foto subida anteriormente y las indicaciones posteriores pueden hacer referencia a ella. Sin embargo, no está garantizado entre sesiones distintas; en una nueva conversación será necesario volver a subir la imagen. Recomendamos guardar tus "imágenes de referencia" como una biblioteca de recursos personal.
Pregunta 8: ¿Cuál es el coste aproximado de GPT-image-2?
La invocación de la API se factura según los tokens y la resolución de la imagen. Una imagen 2K en modo de razonamiento cuesta aproximadamente entre $0.10 y $0.30, mientras que en modo estándar ronda los $0.03 a $0.08. Para usuarios individuales que generan entre 100 y 200 imágenes creativas al mes, el coste mensual es bastante manejable. Recomendamos utilizar la plataforma APIYI (apiyi.com) para una facturación transparente por token, evitando las complicaciones de los pagos con tarjetas de crédito extranjeras.
Puntos clave sobre las aplicaciones creativas de GPT-image-2
- La verdadera mejora detrás del marketing de OpenAI es la combinación de dos capacidades: "modo de razonamiento + consistencia entre múltiples imágenes".
- Escenario de fotos de identificación: la calidad de imagen del modo de razonamiento alcanza el nivel de un estudio fotográfico, con un coste por unidad mucho menor que el presencial y soporte para cualquier formato personalizado.
- Escenario de estilo cómic: el modelo entiende el "estilo" como un lenguaje visual y no como un simple filtro, permitiendo géneros detallados como shonen, shojo, estilo chibi o cel shading.
- Escenario de prueba de peinados: la capacidad de mostrar 6 pruebas lado a lado permite al usuario comparar opciones, algo difícil de lograr con aplicaciones especializadas anteriores.
- Modo de razonamiento vs. modo estándar: elige el modo de razonamiento para instrucciones complejas o alta sensibilidad en la precisión facial; elige el modo estándar para priorizar la velocidad.
- Recomendación de conexión local: utiliza la conexión directa a través de APIYI (apiyi.com), configura el tiempo de espera (timeout) a más de 360 segundos y simplemente reemplaza la
base_url. - El verdadero beneficiario es el usuario común: flujos de trabajo que antes requerían Photoshop + Stable Diffusion + LoRA, ahora se resuelven con una sola indicación.
Resumen
GPT-image-2 no es una simple actualización de modelo; es la herramienta que ha democratizado tareas creativas que antes solo estaban al alcance de quienes manejaban cadenas de herramientas profesionales, poniéndolas ahora en manos de cualquier persona que sepa usar ChatGPT. Esto no es solo un cambio en las métricas técnicas, sino una realidad palpable de la democratización de las herramientas creativas.
Los tres escenarios —fotos de identificación, estilo cómic y diseño de peinados— merecen una atención especial porque cubren las necesidades cotidianas más comunes de los usuarios: búsqueda de empleo, redes sociales y gestión de la imagen personal. El desempeño de GPT-image-2 en estos ámbitos ha igualado, e incluso superado, al de las herramientas especializadas.
Recomendaciones para diferentes perfiles:
- Usuarios generales: Empiecen por la versión web de ChatGPT Plus. Usen el modo de razonamiento para generar algunas fotos de identificación y familiarizarse con los límites de sus capacidades.
- Peluqueros, estilistas y diseñadores de imagen: Integren la "comparativa de 6 peinados" en su flujo de servicio estándar; esto mejorará significativamente la eficiencia en la toma de decisiones de sus clientes.
- Creadores de contenido (estilo anime/redes sociales): Aprovechen la capacidad de "storyboards de 8 viñetas con consistencia de protagonista" para crear formatos de contenido que antes eran imposibles de realizar.
- Desarrolladores locales: Integren estas capacidades en sus propios productos a través de la API de APIYI para crear aplicaciones más verticales y especializadas.
✨ Consejo final: Para usuarios y empresas, recomendamos acceder a gpt-image-2 a través de la plataforma APIYI (apiyi.com). Obtendrán una conexión estable y directa desde la región, campos totalmente compatibles con la API oficial y una facturación transparente basada en tokens. Los nuevos usuarios disponen de saldo de prueba gratuito, suficiente para realizar todas las pruebas de los tres escenarios descritos en este artículo antes de decidir si escalar a un entorno de producción.
Autor: Equipo de APIYI
Última actualización: 02-05-2026