Nota del autor: Respondiendo a la pregunta más frecuente de los desarrolladores: ¿Pueden las APIs de Modelos de Lenguaje Grande recibir PDFs directamente? La respuesta es que la gran mayoría no lo soporta. Este artículo detalla 3 soluciones prácticas: extracción de texto, comprensión de imágenes y procesamiento del lado del cliente.
"¿Puedo pasar un archivo PDF directamente a la API del Modelo de Lenguaje Grande?" — Esta es una de las preguntas más recurrentes en nuestro grupo de soporte. Muchos desarrolladores, acostumbrados a la función de "arrastrar y soltar PDF para conversar" en las versiones web de ChatGPT o Claude, asumen que la API funciona de la misma manera.
La realidad es: La gran mayoría de las APIs de Modelos de Lenguaje Grande no admiten la entrada directa de archivos PDF. Incluso proveedores líderes como OpenAI o Anthropic tienen interfaces API cuyo formato de entrada principal sigue siendo texto e imágenes; el PDF no está dentro de los formatos estándar soportados. Más importante aún, plataformas proxy de API de terceros como APIYI tampoco admiten la carga directa de PDF, porque el protocolo subyacente simplemente no lo soporta.
Pero no te preocupes, en realidad hay 3 soluciones maduras para procesar PDFs. Este artículo te ayudará a entender el porqué de esta limitación y a elegir el método más adecuado para ti.
Valor clave: Al terminar este artículo, comprenderás por qué las APIs de Modelos de Lenguaje Grande no soportan PDFs y cómo resolver eficientemente la necesidad de entrada de PDFs usando 3 esquemas de preprocesamiento.

Puntos clave sobre la entrada de PDF en APIs de Modelos de Lenguaje Grande
| Punto clave | Explicación | Impacto |
|---|---|---|
| Las APIs no aceptan PDF directamente | La entrada estándar para las APIs de modelos principales como GPT, DeepSeek, Llama, Qwen es texto e imágenes | Requiere un flujo de preprocesamiento previo |
| Versión web ≠ API | La carga de PDF en ChatGPT, Claude web es un preprocesamiento del frontend antes de llamar a la API | No equipares la experiencia web con las capacidades de la API |
| Las plataformas de terceros tampoco lo soportan | Servicios proxy de API como APIYI transmiten el protocolo API original; si la capa base no lo soporta, la plataforma tampoco | No esperes que las plataformas proxy procesen PDF adicionalmente |
| 3 esquemas de preprocesamiento son maduros y confiables | Extracción de texto, comprensión de imágenes y procesamiento en cliente tienen sus propios escenarios de aplicación | Elegir el esquema correcto es más práctico que buscar "APIs que soporten PDF" |
¿Por qué las APIs de Modelos de Lenguaje Grande no soportan entrada de PDF?
Muchos desarrolladores se preguntan: si la versión web puede subir PDF, ¿por qué la API no? La razón es simple: la función de "subir PDF" en la versión web no es el modelo procesando el PDF, sino que el frontend/backend realiza un preprocesamiento que no ves:
- Extracción de texto: El frontend extrae el texto del PDF, lo convierte a texto plano y luego lo envía al modelo
- Renderizado de páginas: Cada página del PDF se renderiza como imagen, permitiendo que el modelo la comprenda mediante capacidades de visión
- Recuperación RAG: El contenido del PDF se vectoriza y almacena; durante la conversación solo se recuperan y envían al modelo los fragmentos relevantes
Estos pasos de preprocesamiento están encapsulados en los productos web, y el usuario no los percibe. Pero cuando llamas directamente a la API, tú mismo debes completar este preprocesamiento.
Consulta rápida del soporte de PDF en APIs de Modelos de Lenguaje Grande
| Modelo | Envío directo de PDF por API | Formato de entrada estándar | Recomendación para procesar PDF |
|---|---|---|---|
| GPT-4o / GPT-4.1 | No soportado | Texto + imágenes (Base64) | Primero extraer texto o convertir a imagen |
| Claude | Soporte parcial (Beta) | Texto + imágenes | Se recomienda seguir el flujo de preprocesamiento para mayor estabilidad |
| Gemini | Soporte parcial | Texto + imágenes | Se recomienda seguir el flujo de preprocesamiento para mayor control |
| DeepSeek | No soportado | Texto plano | Primero se debe extraer el texto |
| Llama / Qwen | No soportado | Texto (algunos soportan imágenes) | Primero se debe extraer el texto |
| APIYI y otros terceros | No soportado | Transmiten el protocolo original | Requiere preprocesamiento propio antes de la llamada |
🎯 Nota importante: Aunque la documentación oficial de las APIs de Claude y Gemini menciona la funcionalidad de entrada de PDF, esta presenta incertidumbres en compatibilidad y estabilidad, y no se soporta el envío directo de PDF al llamar a través de plataformas proxy de terceros como APIYI. Recomendamos seguir un esquema de preprocesamiento unificado, que ofrece la mejor compatibilidad y estabilidad.
Esquema 1 para procesar PDF en APIs de Modelos de Lenguaje Grande: Extracción de texto previa
Este es el esquema más universal, de menor costo y compatible con todos los modelos. La idea central: primero usar una biblioteca de Python para convertir el PDF a Markdown o texto plano, luego enviar el texto como indicación (prompt) a la API.
Comparación de herramientas para extracción de texto de PDF
| Herramienta | Velocidad | Mejor escenario | Características |
|---|---|---|---|
| PyMuPDF4LLM | ~0.14s/documento | Extracción de texto general + tablas | Mejor equilibrio velocidad-calidad, salida en Markdown |
| pdfplumber | Media | Extracción de datos tabulares | Alta precisión en extracción de tablas a nivel de coordenadas |
| Marker-PDF | ~11s/documento | Conversión fiel de diseños complejos | Mejor preservación de estructura, velocidad más lenta |
| PyPDF2 | Rápida | PDF de texto plano simple | Ligera, adecuada para extracción básica |
Ejemplo de código para extracción de texto de PDF
A continuación, el esquema más utilizado: extraer el texto del PDF y enviarlo a la API del Modelo de Lenguaje Grande:
import pymupdf4llm
import openai
# Paso 1: PDF a Markdown
md_text = pymupdf4llm.to_markdown("report.pdf")
# Paso 2: Enviar texto plano a cualquier Modelo de Lenguaje Grande
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": f"Por favor, resume los puntos clave de este informe:\n\n{md_text}"}]
)
print(response.choices[0].message.content)
Escenarios de aplicación: PDF principalmente textuales como contratos, tesis, informes, documentación técnica. Mientras el PDF tenga una capa de texto incrustada (no sea un documento escaneado), la extracción funciona bien.
Recomendación: El esquema de extracción de texto es compatible con todos los Modelos de Lenguaje Grande: GPT, Claude, DeepSeek, Llama, Qwen. Obtén una clave API en APIYI apiyi.com, una sola clave te permite llamar a todos los modelos para realizar pruebas comparativas.
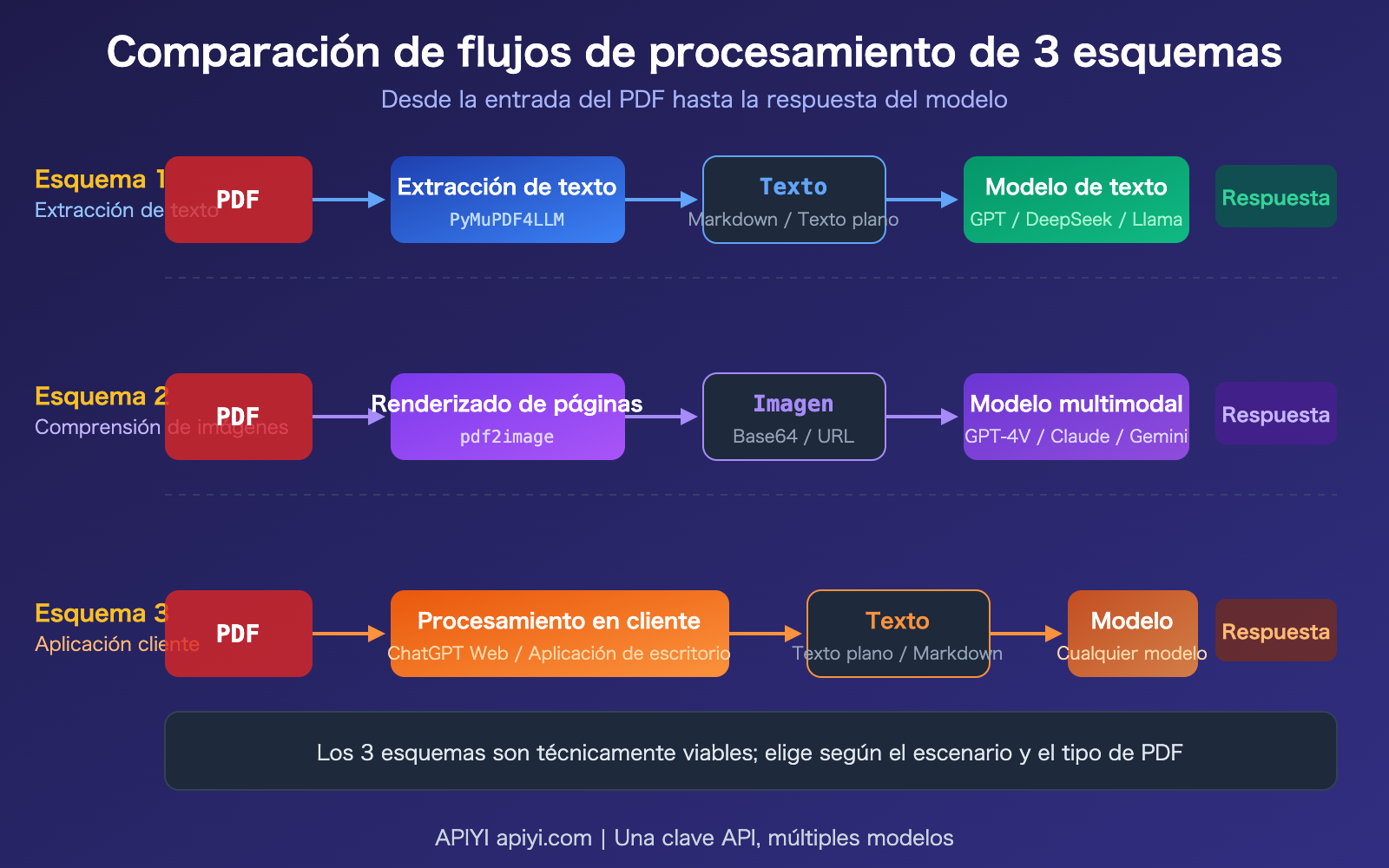
Solución 2 para procesar PDFs con API de Modelos de Lenguaje Grande: Convertir a imagen + Comprensión visual
Cuando un PDF contiene información visual como gráficos, documentos escaneados o diseños complejos, la extracción de texto puro pierde estos contenidos. En estos casos, es necesario renderizar cada página del PDF como una imagen y utilizar un modelo con capacidades de visión para comprenderla.
Ejemplo de código: Convertir PDF a imágenes
import fitz # PyMuPDF
import base64
import openai
# Paso 1: Convertir cada página del PDF a una imagen PNG
doc = fitz.open("report.pdf")
images = []
for page in doc:
pix = page.get_pixmap(dpi=200)
b64 = base64.b64encode(pix.tobytes("png")).decode()
images.append(b64)
Ver código completo: Enviar imágenes a la API de Visión
import fitz
import base64
import openai
def pdf_to_vision(pdf_path, question, max_pages=10):
"""Convertir PDF a imágenes y enviarlas a la API de Visión"""
doc = fitz.open(pdf_path)
# Construir mensaje con múltiples imágenes (controlar páginas para evitar exceder tokens)
content = [{"type": "text", "text": question}]
for i, page in enumerate(doc):
if i >= max_pages:
break
pix = page.get_pixmap(dpi=150)
b64 = base64.b64encode(pix.tobytes("png")).decode()
content.append({
"type": "image_url",
"image_url": {"url": f"data:image/png;base64,{b64}"}
})
client = openai.OpenAI(
api_key="TU_CLAVE_API",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": content}]
)
return response.choices[0].message.content
# Ejemplo de uso
result = pdf_to_vision(
"financial_report.pdf",
"Analiza los gráficos de tendencias en este informe financiero y resume los datos clave",
max_pages=5 # Controlar páginas, cada una consume ~765 tokens
)
print(result)
Casos de uso: Informes de investigación con gráficos, documentos escaneados, facturas, planos de arquitectura y otros PDFs ricos en información visual.
Recordatorio de costos: Cada página de imagen consume aproximadamente 765 tokens (resolución estándar de GPT-4o). Un PDF de 10 páginas supone unos 7,650 tokens solo en imágenes, más la pregunta y respuesta, pudiendo superar los 10,000 tokens. Es crucial controlar el número de páginas.
🎯 Consejo para controlar costos: No envíes todas las páginas de un PDF de una vez. Primero usa la Solución 1 para extraer texto y hacer una selección preliminar, identifica las páginas clave, y luego aplica la Solución 2 solo a esas páginas específicas. Puedes monitorear el consumo de tokens en tiempo real desde el panel de uso de APIYI en apiyi.com.
Solución 3 para procesar PDFs con API de Modelos de Lenguaje Grande: Clientes de IA
Si no quieres escribir código y solo necesitas "preguntar sobre el contenido de un PDF" en conversaciones diarias, usar un cliente de IA es la opción más sencilla.
Cómo funcionan clientes como Cherry Studio para procesar PDFs
Estos clientes básicamente automatizan el trabajo de las Soluciones 1 y 2:
- Vectorización automática: Extraen el contenido del PDF, lo dividen en fragmentos y los almacenan en una base de datos vectorial local.
- Búsqueda semántica: Cuando haces una pregunta, el cliente primero recupera los fragmentos de contenido más relevantes.
- Envío preciso: Solo envía los fragmentos relevantes (no el documento completo) a la API del Modelo de Lenguaje Grande.
- Ahorro de tokens: La técnica de RAG (Retrieval-Augmented Generation) reduce drásticamente la cantidad de contenido enviado al modelo.
Consideraciones al usar clientes para procesar PDFs
- Configurar la clave API: Introduce tu clave API de APIYI (apiyi.com) en el cliente para acceder a todos los modelos con una sola clave.
- Controlar el tamaño del archivo: Los PDFs muy grandes (cientos de páginas) tardan más en vectorizarse; se recomienda dividirlos antes de procesarlos.
- Atención al costo en tokens: Aunque RAG comprime el contenido, los documentos largos aún pueden generar costos considerables.
- Elegir el modelo adecuado: Para preguntas simples usa modelos económicos (como GPT-4o-mini), para análisis complejos usa modelos más potentes.
Comparación de 3 Soluciones para Procesar PDFs con APIs de Modelos de Lenguaje Grande

| Solución | Costo en Tokens | Soporte de Gráficos | Dificultad de Desarrollo | Compatibilidad del Modelo | Mejor Caso de Uso |
|---|---|---|---|---|---|
| Extracción Textual | Mínimo (300-1500/página) | No soportado | Media | Todos los modelos | PDFs de texto puro, grandes volúmenes |
| Conversión a Imagen + Comprensión | Alto (~765/página) | Soporte completo | Media | Requiere modelo con Visión | Gráficos, documentos escaneados |
| Procesamiento en Cliente | Medio (compresión RAG) | Depende del cliente | Cero código | Todos los modelos | Conversación diaria, sin desarrollo |
Nota de la comparación: Las tres soluciones no son mutuamente excluyentes; en proyectos reales a menudo se combinan. Por ejemplo, primero usar la solución uno para extraer texto y hacer un filtro grueso, luego usar la solución dos en páginas clave para comprensión de imágenes. A través de APIYI apiyi.com puedes acceder de manera unificada a todos los modelos.
Preguntas frecuentes
Q1: ¿Por qué ChatGPT en la web permite subir PDFs, pero la API no lo soporta?
La función de "subir PDF" en la versión web es una capa de producto que realiza un preprocesamiento por ti: extrae texto, renderiza imágenes, crea índices de búsqueda y luego llama a la API subyacente. El formato de entrada central de la API en sí es texto e imágenes. El PDF, como un formato de contenedor de documentos complejo, no está dentro de los formatos soportados de manera estándar. Cuando llamas a la API, necesitas completar estos pasos de preprocesamiento por tu cuenta.
Q2: ¿Pueden plataformas intermedias como APIYI ayudarme a procesar PDFs?
No. La esencia de plataformas intermedias como APIYI es retransmitir las solicitudes de la API. Si el protocolo subyacente no soporta PDF, la plataforma tampoco puede procesarlo. Necesitas completar el preprocesamiento del PDF (extracción de texto o conversión a imágenes) antes de llamar a la API, y luego enviar el texto o las imágenes procesadas a través de APIYI apiyi.com al Modelo de Lenguaje Grande.
Q3: ¿Cómo controlar el costo en tokens al procesar PDFs?
Algunos consejos prácticos:
- Prioriza la opción 1 (extracción de texto), es la de menor costo.
- Procesa solo las páginas necesarias, no envíes todo el documento de una vez.
- Utiliza técnicas RAG para dividir y recuperar, enviando solo los fragmentos relevantes al modelo.
- Usa modelos económicos (como GPT-4o-mini) para preguntas simples y modelos de gama alta para análisis complejos.
- Monitorea el consumo en tiempo real desde el panel de uso de APIYI apiyi.com.
Resumen
Puntos clave sobre la entrada de PDFs en la API de Modelos de Lenguaje Grande:
- La gran mayoría de las APIs no soportan entrada directa de PDF: La entrada central de los modelos grandes es texto e imágenes. Los PDFs requieren preprocesamiento antes de poder usarse.
- Las plataformas de terceros tampoco lo soportan: Plataformas intermedias como APIYI retransmiten el protocolo original y no pueden procesar PDFs de manera adicional.
- Elige entre 3 opciones según la necesidad: PDFs de solo texto usa extracción de texto (más económico), PDFs con imágenes conviértelos a imágenes para comprensión (más fiel), y para conversaciones diarias usa el cliente (más sencillo).
No te preocupes por "qué API soporta PDF", sino concéntrate en elegir el esquema de preprocesamiento correcto; ese es el enfoque adecuado.
Te recomendamos obtener créditos gratuitos a través de APIYI apiyi.com, preprocesar tu PDF y luego usar una sola clave API para probar y comparar todos los modelos principales como GPT, Claude, DeepSeek, etc.
📚 Referencias
-
Documentación de PyMuPDF4LLM: Herramienta de extracción de texto de PDF
- Enlace:
pymupdf.readthedocs.io/en/latest/pymupdf4llm - Descripción: La herramienta más rápida para convertir PDF a Markdown, recomendada como primera opción
- Enlace:
-
Documentación de pdfplumber: Herramienta especializada para extracción de tablas
- Enlace:
github.com/jsvine/pdfplumber - Descripción: La herramienta con mayor precisión para extraer datos de tablas en PDF
- Enlace:
-
Cherry Studio: Cliente de IA de código abierto
- Enlace:
github.com/CherryHQ/cherry-studio - Descripción: Cliente gratuito que soporta arrastrar y soltar PDF en conversaciones, configurable con APIYI como backend
- Enlace:
-
Documentación de la plataforma APIYI: Acceso unificado a APIs de grandes modelos
- Enlace:
docs.apiyi.com - Descripción: Obtención de claves API, lista de modelos y ejemplos de invocación
- Enlace:
Autor: Equipo técnico de APIYI
Intercambio técnico: Bienvenido a discutir en la sección de comentarios, más recursos disponibles en el centro de documentación de APIYI docs.apiyi.com