Para el año 2026, el 41% de las confirmaciones de código ya serán generadas con asistencia de IA; sin embargo, la tasa de defectos en el código generado por IA es 1.7 veces mayor que la del código humano. La generación de código es cada vez más rápida, pero la capacidad de revisión de código es insuficiente, y se prevé que para 2026 exista una brecha de calidad del 40%.
La revisión de código mediante IA no es una cuestión de "si debemos hacerlo", sino de "cómo hacerlo bien". En este artículo, presentaremos 7 mejores prácticas validadas y analizaremos a fondo por qué los modelos Claude Opus 4.6 y Sonnet 4.6 son actualmente los más adecuados para la revisión de código.
Valor central: Al terminar de leer este artículo, dominarás el flujo de trabajo completo de revisión de código con IA y entenderás cómo elegir el modelo más apropiado para mejorar la calidad del código de tu equipo.

El estado actual de la revisión de código con IA: Por qué es vital prestarle atención ahora
Desafíos de la revisión de código en 2026
| Desafío | Datos | Impacto |
|---|---|---|
| Auge del código generado por IA | El 41% de los commits son asistidos por IA | Sobrecarga en la revisión |
| Tasa de defectos en IA | 1.7 veces mayor que en código humano | Requiere revisiones más estrictas |
| Brecha de calidad | Se prevé un 40% para 2026 | La capacidad de revisión no sigue el ritmo |
| Riesgos de seguridad | El 45% del código IA introduce vulnerabilidades OWASP Top 10 | La revisión de seguridad es urgente |
| Tasa de adopción de sugerencias | Sugerencias de IA: 16.6%, humanas: 56.5% | La calidad de la revisión por IA debe mejorar |
Revisión de código por IA vs. Revisión humana
La IA no viene a reemplazar a los revisores humanos, sino a potenciar su capacidad. Los equipos que utilizan revisión de código con IA reportan:
- Reducción del tiempo de revisión en un 40-60%
- Mayor tasa de detección de defectos, especialmente en vulnerabilidades de seguridad y casos borde.
- Mejora significativa en la consistencia del estilo de código.
Sin embargo, la revisión por IA tiene límites claros:
- ❌ No entiende los plazos de entrega ni el contexto del proyecto.
- ❌ No percibe las concesiones históricas de los sistemas heredados.
- ❌ No puede asumir la responsabilidad final de la revisión.
- ❌ No puede realizar mentoría ni transmitir conocimiento del equipo.
🎯 Mejor estrategia: La IA realiza el primer escaneo (estilo, bugs, seguridad) y los humanos toman la decisión final (arquitectura, intención, riesgos). Al utilizar la plataforma APIYI (apiyi.com) para invocar la API de Claude Opus 4.6 o Sonnet 4.6, puedes integrar rápidamente la revisión de código por IA en tus flujos de CI/CD existentes.
7 mejores prácticas para la revisión de código con IA
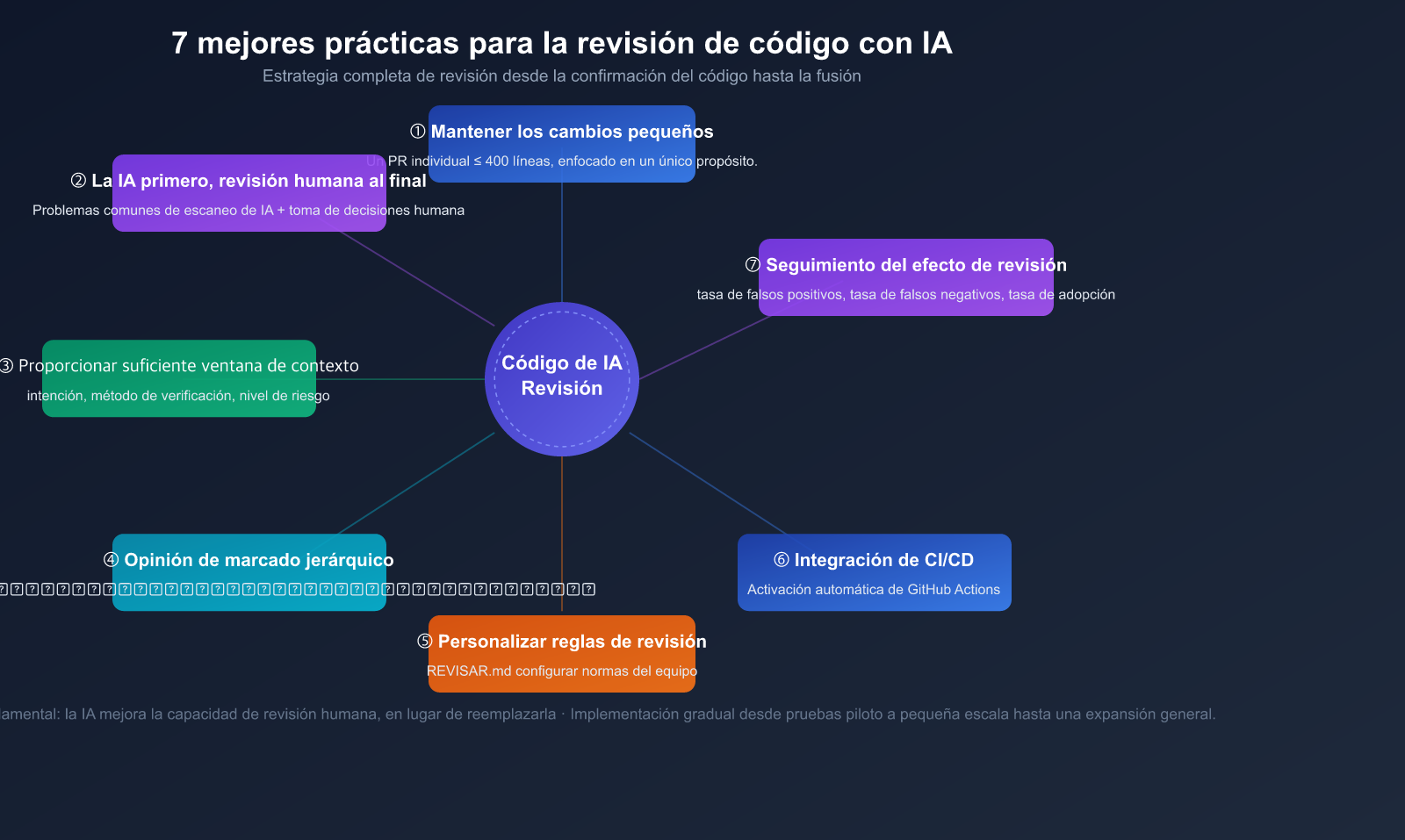
Práctica 1: Mantener los cambios pequeños y enfocados
Los revisores de IA pierden coherencia significativamente después de que un diff supera las 1000 líneas. Aunque Claude Opus 4.6 posee una ventana de contexto de 1 millón de tokens, la calidad de la revisión en cambios grandes sigue siendo inferior a la de los cambios pequeños.
Cómo hacerlo:
- Mantén cada PR entre 200 y 400 líneas.
- Divide las refactorizaciones grandes en varios PR independientes lógicamente.
- Haz que cada PR se encargue de una sola cosa.
Práctica 2: IA primero, revisión humana al final
El flujo de trabajo más efectivo es el modelo de "revisión de doble capa":
Envío de código → Revisión automática por IA (primera pasada)
↓
Marcar problemas + Clasificar por nivel de gravedad
↓
Revisor humano se enfoca en áreas de alto riesgo (revisión final)
↓
Fusionar o rechazar
La IA se encarga de escanear todos los problemas rutinarios (estilo, nombres, código muerto, bugs simples), mientras que el humano se enfoca en:
- La razonabilidad de la arquitectura.
- La corrección de la lógica de negocio.
- Decisiones críticas de seguridad.
- Evaluación del impacto en el rendimiento.
Práctica 3: Proporcionar suficiente contexto
Cuanta más información le des al revisor de IA, mayor será la calidad de la revisión. Se recomienda incluir en la descripción del PR:
# Contexto del PR
- Objetivo: [Breve descripción]
- Ticket relacionado: [Link a Jira/GitHub Issue]
- Áreas de riesgo: [Componentes críticos afectados]
Intención del cambio
Explica en 1 o 2 frases "por qué se realiza este cambio".
Método de verificación
- Pruebas unitarias superadas
- Prueba manual realizada en el escenario XX
- Sin regresiones de rendimiento
Nivel de riesgo
Bajo/Medio/Alto + Explicación
Declaración de asistencia por IA
En este cambio, la sección XX ha sido generada por IA; por favor, revísela con especial atención.
Áreas de enfoque manual
Por favor, presta especial atención a los cambios en la lógica de permisos dentro del directorio src/auth/.
### Práctica 4: Clasificación de comentarios de revisión
Un problema común en la revisión mediante IA es el "exceso de ruido": mezclar sugerencias de estilo con errores graves, lo que provoca que los desarrolladores ignoren los comentarios importantes.
**Niveles de severidad recomendados**:
| Etiqueta | Significado | Acción |
|------|------|----------|
| 🔴 **Bug** | Defecto que debe corregirse antes de fusionar | Bloquea la fusión |
| 🟡 **Nit** | Problema menor, recomendable pero no bloqueante | Corrección opcional |
| 🟣 **Pre-existing** | Problema antiguo no introducido en este cambio | Registrar, no bloquear |
| 💡 **Suggestion** | Sugerencia de mejora | Decidir tras debatir |
La funcionalidad nativa de revisión de código de Claude Code ya implementa este sistema de clasificación (Rojo/Amarillo/Morado).
### Práctica 5: Personalización de las reglas de revisión
Es posible que la revisión genérica de la IA no se ajuste a las normas de tu equipo. Puedes personalizar el comportamiento de la revisión mediante un archivo de configuración:
```markdown
# REVIEW.md (ubicado en la raíz del proyecto)
## Verificaciones obligatorias
- Todas las consultas a la base de datos deben utilizar sentencias parametrizadas.
- Los endpoints de la API deben incluir middleware de autenticación.
- Toda entrada de usuario debe ser validada.
Se puede omitir
- Estilo de nomenclatura de clases CSS (formateado automáticamente con prettier)
- Orden de importaciones (procesado automáticamente con ruff)
- Idioma de los comentarios (se aceptan tanto chino como inglés)
Acuerdos del equipo
- Priorizar la composición sobre la herencia
- Utilizar el patrón Result para el manejo de errores
- Niveles de registro: INFO para eventos de negocio, DEBUG para depuración
### Práctica 6: Integración en el flujo de CI/CD
La revisión de código mediante IA debe ser automatizada, no activada manualmente.
**Forma de integración recomendada**:
```yaml
# Ejemplo de GitHub Actions
name: AI Code Review
on:
pull_request:
types: [opened, synchronize]
jobs:
ai-review:
runs-on: ubuntu-latest
steps:
- uses: anthropics/claude-code-action@v1
with:
anthropic_api_key: ${{ secrets.ANTHROPIC_API_KEY }}
review_mode: "auto"
También puedes realizar revisiones personalizadas invocando directamente al modelo Claude mediante la API:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Interfaz unificada de APIYI
)
diff_content = open("pr_diff.patch").read()
response = client.chat.completions.create(
model="claude-opus-4-6",
messages=[
{"role": "system", "content": """Eres un experto en revisión de código.
Por favor, analiza los siguientes cambios de código y clasifícalos por nivel de gravedad:
- 🔴 Bug: Debe corregirse
- 🟡 Nit: Se sugiere corregir
- 💡 Suggestion: Sugerencia de mejora
Indica el número de línea específico y la solución para cada problema."""},
{"role": "user", "content": f"Por favor, revisa los siguientes cambios de código:\n\n{diff_content}"}
],
max_tokens=8192
)
print(response.choices[0].message.content)
Práctica 7: Seguimiento de la eficacia de la revisión
La revisión de código por IA no termina al desplegar. Es necesario realizar un seguimiento continuo de métricas clave:
- Tasa de falsos positivos: Cuántos de los problemas marcados por la IA son problemas reales.
- Tasa de falsos negativos: Cuántos de los bugs detectados tras el despliegue no fueron identificados por la IA.
- Tasa de adopción: Proporción de sugerencias de la IA que los desarrolladores realmente aplican.
- Cambios en el tiempo de revisión: Si el tiempo promedio de revisión de los revisores humanos ha disminuido.
💡 Consejo de implementación: Si tu equipo está empezando con la revisión de código mediante IA, te sugiero comenzar con PRs de rutas no críticas. Utiliza Claude Sonnet 4.6 a través de APIYI (apiyi.com) para las pruebas iniciales; el costo es solo 1/5 del de Opus, con una calidad de revisión cercana, lo que lo convierte en la opción más rentable para empezar.
Por qué recomendamos Claude Opus 4.6 y Sonnet 4.6 para la revisión de código
Entre la gran variedad de modelos de IA, la serie Claude 4.6 destaca con ventajas únicas en escenarios de revisión de código.
Comparativa de parámetros clave de los modelos Claude 4.6
| Parámetro | Claude Opus 4.6 | Claude Sonnet 4.6 |
|---|---|---|
| ID del modelo | claude-opus-4-6 |
claude-sonnet-4-6 |
| Fecha de lanzamiento | 5 de febrero de 2026 | 17 de febrero de 2026 |
| Ventana de contexto | 1 millón de tokens (beta) | 1 millón de tokens (beta) |
| Salida máxima | 128K tokens | 64K tokens |
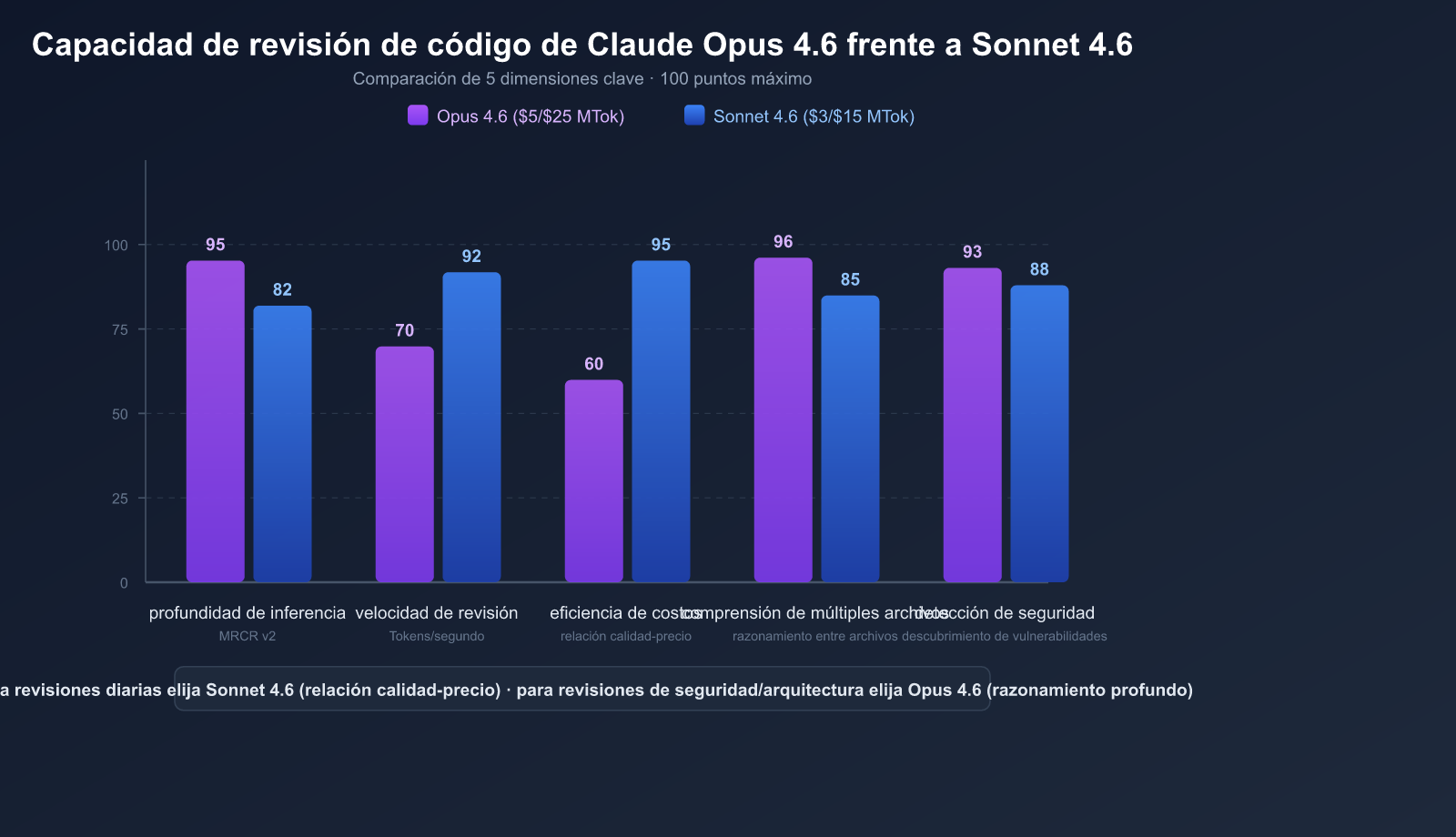
| SWE-bench Verified | 81.42% | 79.6% |
| Precio (Entrada/Salida) | $5/$25 por millón de tokens | $3/$15 por millón de tokens |
| Escenarios de uso | Revisión de arquitectura compleja, auditoría de seguridad | Revisión diaria de PR, comprobación de estilo |
| Precio en APIYI | Más económico | Más económico |
Ventaja 1: Ventana de contexto de 1 millón de tokens
Esta es la ventaja técnica más crítica en escenarios de revisión de código.
Un PR en proyectos grandes puede involucrar decenas de archivos. Las limitaciones de la ventana de contexto de los modelos de IA tradicionales obligan a truncar el código, lo que impide que el revisor vea el contexto completo.
La ventana de contexto de 1 millón de tokens de Claude 4.6 permite incluir de una sola vez:
- El diff completo del PR (normalmente de cientos a miles de líneas)
- Todo el código de los archivos relacionados (cadena de importaciones, funciones llamadas)
- Diagramas de dependencias y definiciones de tipos
- Archivos de prueba y configuración
- Documentación de arquitectura y README del proyecto
Esto significa que la IA puede realizar revisiones como un desarrollador senior, comprendiendo el contexto completo.
Ventaja 2: Capacidad superior de razonamiento entre archivos
Lo más valioso de la revisión de código no es encontrar errores de sintaxis, sino descubrir problemas lógicos entre archivos.
Claude Opus 4.6 obtuvo una puntuación del 76% en la prueba MRCR v2 (razonamiento de recuperación multi-archivo), mientras que Sonnet 4.5 solo alcanzó el 18.5%. Esto significa que Opus 4.6 destaca en escenarios como:
- Detectar que un archivo A modificó una interfaz, pero la llamada en el archivo B no se actualizó.
- Descubrir la falta de validación en todo el flujo de datos, desde la entrada hasta la base de datos.
- Identificar condiciones de carrera en escenarios de concurrencia.
Caso real: En pruebas, Claude Opus 4.6 descubrió una condición de carrera en un PR de migración de base de datos de 2400 líneas, un defecto en la lógica de rollback que solo se activaba si la migración se interrumpía a mitad de camino. Este es un escenario que las pruebas automatizadas no pueden cubrir.
Ventaja 3: Profundidad de pensamiento adaptativa
Claude 4.6 introduce el modo adaptive thinking: la IA decide automáticamente "qué tan profundamente pensar" según la complejidad del problema.
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Interfaz unificada de APIYI
)
response = client.chat.completions.create(
model="claude-opus-4-6",
messages=[
{"role": "system", "content": "Revisa este cambio de código en busca de problemas de seguridad."},
{"role": "user", "content": diff_content}
],
# Pensamiento adaptativo de Claude 4.6: juzga rápido problemas simples, analiza a fondo los complejos
extra_body={"thinking": {"type": "adaptive"}}
)
- Ante problemas de estilo simples → juzga rápidamente, ahorrando tokens.
- Ante problemas complejos de concurrencia o seguridad → razona profundamente y ofrece un análisis exhaustivo.
Ventaja 4: Detección de vulnerabilidades de seguridad muy superior a las herramientas tradicionales
Los estudios demuestran que los LLM de nivel Claude superan significativamente a las herramientas de análisis estático tradicionales en la revisión de código de seguridad:
| Dimensión de comparación | Claude (LLM) | CodeQL (SAST tradicional) |
|---|---|---|
| Vulnerabilidades detectadas | 55 | 27 |
| Descubrimiento de vulnerabilidades desconocidas | 4 vulnerabilidades zero-day | 0 |
| Categorías de detección | Más de 10 (inyección, autenticación, filtración de datos, cifrado, defectos lógicos, etc.) | Basado en coincidencia de patrones |
| Soporte de lenguaje | Cualquier lenguaje de programación | Lenguajes específicos |
| Filtrado de falsos positivos | Filtrado automático por IA | Requiere filtrado manual |
Tipos de vulnerabilidades de seguridad que Claude puede detectar:
- Inyecciones SQL/comando/LDAP/XPath/NoSQL
- Defectos de autenticación y autorización
- Claves codificadas (hardcoded), registros de datos sensibles
- Algoritmos de cifrado débiles, gestión inadecuada de claves
- Condiciones de carrera (TOCTOU)
- Configuraciones predeterminadas inseguras, CORS
- RCE por deserialización, inyección pickle/eval
- XSS (reflejado, almacenado, basado en DOM)
Ventaja 5: Flexibilidad de costos
El precio de Sonnet 4.6 es solo 1/5 del de Opus 4.6, pero en SWE-bench solo queda 1-2 puntos porcentuales por detrás.
Estrategia de selección recomendada:
| Escenario | Modelo recomendado | Motivo |
|---|---|---|
| Revisión diaria de PR | Sonnet 4.6 | Mejor relación calidad-precio, calidad cercana a Opus |
| Código crítico de seguridad | Opus 4.6 | Razonamiento más profundo, sin pasar por alto problemas graves |
| Revisión de refactorización grande | Opus 4.6 | Mayor capacidad de razonamiento entre archivos |
| Comprobación de estilo y normas | Sonnet 4.6 | Tareas simples que no requieren Opus |
| Revisión automática en CI/CD | Sonnet 4.6 | Costo controlable, ideal para activar en cada commit |
🚀 Consejo de selección: La recomendación oficial de Anthropic es "usar Sonnet 4.6 por defecto y actualizar a Opus 4.6 solo cuando se necesite el razonamiento más profundo". En las pruebas internas de Claude Code, la tasa de preferencia de los desarrolladores por Sonnet 4.6 fue un 70% mayor que la de la generación anterior Sonnet 4.5, e incluso un 59% mayor que la del antiguo buque insignia Opus 4.5. Al invocar ambos modelos a través de APIYI (apiyi.com), puedes disfrutar de precios más favorables.
Flujo de trabajo completo de revisión de código con IA
Resumen del flujo de trabajo
El desarrollador envía un PR
↓
Revisión automática por IA (Sonnet 4.6)
↓
┌─── Cambios de bajo riesgo ──→ La IA marca detalles menores, aprobación automática
│
├─── Cambios de riesgo medio ──→ La IA marca problemas, confirmación humana rápida
│
└─── Cambios de alto riesgo ──→ Escalado a Opus 4.6 para revisión profunda
↓
Revisión final por experto en seguridad
↓
Fusión o rechazo
Ejemplo de código: Configuración de un sistema de revisión de IA personalizado
import openai
import subprocess
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Interfaz unificada de APIYI
)
def get_pr_diff(pr_number):
"""Obtiene el contenido diff del PR"""
result = subprocess.run(
["gh", "pr", "diff", str(pr_number)],
capture_output=True, text=True
)
return result.stdout
def review_code(diff, risk_level="medium"):
"""Selecciona el modelo para la revisión según el nivel de riesgo"""
model = "claude-opus-4-6" if risk_level == "high" else "claude-sonnet-4-6"
response = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": REVIEW_PROMPT},
{"role": "user", "content": f"Revisa los siguientes cambios:\n\n{diff}"}
],
max_tokens=8192
)
return response.choices[0].message.content
# Ejemplo de uso
diff = get_pr_diff(123)
review = review_code(diff, risk_level="high")
print(review)
Ver plantilla completa de la indicación de revisión
REVIEW_PROMPT = """Eres un ingeniero de software senior con amplia experiencia realizando revisiones de código.
## Puntos clave de la revisión
1. **Corrección lógica**: ¿El código implementa la funcionalidad esperada? ¿Faltan condiciones de borde?
2. **Seguridad**: ¿Existen riesgos de seguridad como inyecciones, XSS, CSRF, claves API codificadas, etc.?
3. **Rendimiento**: ¿Hay consultas N+1, asignaciones de memoria innecesarias u operaciones bloqueantes?
4. **Mantenibilidad**: ¿Los nombres son claros? ¿La complejidad es controlable? ¿Hay código duplicado?
5. **Manejo de errores**: ¿Las excepciones se capturan y manejan correctamente?
6. **Seguridad en concurrencia**: ¿Existen riesgos de condiciones de carrera o bloqueos mutuos (deadlocks)?
Aquí tienes la traducción técnica del contenido solicitado:
Formato de salida
Clasifica la salida según el nivel de gravedad:
🔴 Debe corregirse (Bug/Seguridad)
- [Nombre del archivo:número de línea] Descripción del problema
- Impacto: …
- Sugerencia de corrección: …
🟡 Se recomienda corregir (Nit)
- [Nombre del archivo:número de línea] Descripción del problema
- Sugerencia: …
💡 Sugerencias de mejora (Suggestion)
- [Nombre del archivo:número de línea] Punto de mejora
- Explicación: …
Si la calidad del código es buena y no se encontraron problemas, indícalo claramente como "Revisión aprobada, no se encontraron problemas".
No inventes problemas inexistentes solo por cumplir con el formato de salida.
💰 Optimización de costes: Realiza revisiones de código invocando al modelo Claude 4.6 a través de APIYI (apiyi.com) a un precio más competitivo que el oficial. La plataforma permite alternar de forma flexible entre Opus 4.6 y Sonnet 4.6, permitiéndote elegir el modelo con la mejor relación calidad-precio según el nivel de riesgo del PR.
Limitaciones y precauciones de la revisión de código con IA
5 limitaciones que debes conocer
- Tasa de recuperación de aproximadamente el 50%: Las vulnerabilidades detectadas por los Modelos de Lenguaje Grande suelen ser reales (precisión ~80%), pero suelen pasar por alto cerca de la mitad de las vulnerabilidades existentes.
- Riesgo de inyección de indicación: Las herramientas de revisión por IA corren el riesgo de sufrir inyecciones al procesar PRs de fuentes no confiables.
- Puntos ciegos de contexto: La IA no puede comprender el contexto comercial del proyecto, las capacidades del equipo ni las decisiones históricas.
- Acumulación de costes: Si se activa una revisión en cada confirmación (commit), los costes en repositorios de alta frecuencia pueden ser elevados.
- Riesgo de dependencia excesiva: Los miembros del equipo podrían relajar gradualmente el rigor de la revisión manual.
Estrategias de mitigación
| Limitación | Estrategia de mitigación |
|---|---|
| Alta tasa de omisión | Doble garantía: revisión por IA + revisión manual |
| Inyección de indicación | Revisar únicamente PRs de fuentes confiables |
| Falta de contexto | Proporcionar el contexto del proyecto en un archivo REVIEW.md |
| Costes elevados | Usar Sonnet 4.6 para el día a día y Opus 4.6 para rutas críticas |
| Dependencia excesiva | Establecer un sistema de "Sugerencias de IA + Decisión humana" |
Preguntas frecuentes
Q1: ¿Puede la revisión de código por IA reemplazar completamente a la revisión humana?
No. La revisión de código por IA es un "complemento", no un "reemplazo". La IA es excelente detectando problemas basados en patrones (estilo, errores comunes, vulnerabilidades conocidas), pero no puede comprender la intención del negocio, las compensaciones detrás de las decisiones arquitectónicas ni el conocimiento implícito del trabajo en equipo. La mejor práctica es que la IA realice un primer escaneo y los humanos tomen la decisión final. Al utilizar el servicio proxy de API de APIYI (apiyi.com) para invocar el modelo Claude 4.6, puedes configurar rápidamente un flujo de trabajo de revisión por IA, permitiendo que los revisores humanos se enfoquen en tareas de mayor valor.
Q2: ¿Debo elegir Opus 4.6 o Sonnet 4.6 para la revisión de código?
Para la mayoría de los escenarios, elige Sonnet 4.6. En SWE-bench, su rendimiento es solo 1-2 puntos porcentuales menor que el de Opus, pero su costo es apenas una quinta parte. Solo deberías actualizar a Opus 4.6 si estás revisando código crítico de seguridad, realizando grandes refactorizaciones arquitectónicas o si necesitas un razonamiento profundo entre múltiples archivos. A través de APIYI (apiyi.com), puedes alternar entre ambos modelos de forma flexible según tus necesidades.
Q3: ¿Cuál es el costo aproximado de la revisión de código por IA?
La función de revisión nativa de Claude Code cuesta en promedio entre $15 y $25 por sesión, dependiendo del tamaño del PR y la complejidad del repositorio. Si construyes tu propio sistema de revisión mediante API, el costo dependerá del consumo de tokens. Tomando como ejemplo a Sonnet 4.6, revisar un PR de 500 líneas (aprox. 2000 tokens de entrada + 1000 tokens de salida) cuesta alrededor de $0.02. Además, puedes disfrutar de precios aún más competitivos a través de APIYI (apiyi.com).
Q4: ¿Cómo evaluar la efectividad de la revisión de código por IA?
Sugerimos realizar un seguimiento de 4 métricas clave: (1) Tasa de falsos positivos: la proporción de problemas marcados por la IA que son realmente errores; (2) Tasa de falsos negativos: la proporción de errores encontrados tras el despliegue que la IA no marcó; (3) Tasa de adopción: la proporción de sugerencias de la IA que los desarrolladores realmente aceptan; (4) Cambio en el tiempo de revisión: si el tiempo promedio de revisión de los revisores humanos ha disminuido. Recomendamos hacer una revisión semanal durante los primeros dos meses.
Q5: ¿Cómo empezar rápidamente a probar la revisión de código por IA?
La forma más sencilla es seguir tres pasos: (1) Regístrate en APIYI (apiyi.com) para obtener tu clave API; (2) Realiza una prueba de revisión en un PR reciente utilizando Sonnet 4.6; (3) Decide si integrar la automatización en tu CI/CD según los resultados. Comienza con proyectos piloto en rutas de código no críticas y expande gradualmente a todo el sistema.
Resumen: La revisión de código por IA es un multiplicador de eficiencia para los equipos
La revisión de código por IA no es una opción, sino una capacidad esencial para los equipos de desarrollo de software en 2026. Claude Opus 4.6 y Sonnet 4.6, con su ventana de contexto de 1 millón de tokens, una puntuación superior al 81% en SWE-bench, razonamiento adaptativo y potentes capacidades de detección de seguridad, son actualmente la mejor opción para escenarios de revisión de código.
Sugerencias de selección:
- Revisión diaria: Sonnet 4.6 por defecto, el rey de la relación costo-beneficio.
- Revisión de seguridad/arquitectura: Actualiza a Opus 4.6 para una profundidad de razonamiento sin concesiones.
Te recomendamos acceder rápidamente a toda la serie de modelos Claude 4.6 a través de APIYI (apiyi.com) para establecer capacidades de revisión de código por IA en tu equipo al mejor costo.
Referencias
-
Oficial de Anthropic: Anuncio de lanzamiento de Claude Opus 4.6 y Sonnet 4.6
- Enlace:
anthropic.com/news
- Enlace:
-
Documentación de revisión de código de Claude Code: Guía de uso de la función de revisión nativa
- Enlace:
code.claude.com/docs/en/code-review
- Enlace:
-
Claude Code Security Review: Acción de GitHub para revisión de seguridad de código abierto
- Enlace:
github.com/anthropics/claude-code-security-review
- Enlace:
-
Mejores prácticas de revisión de código con IA 2026: Análisis integral de la industria
- Enlace:
verdent.ai/guides
- Enlace:
-
Documento de investigación IRIS: Detección de vulnerabilidades mediante análisis estático asistido por Modelos de Lenguaje Grandes
- Enlace:
arxiv.org
- Enlace:
Autor: Equipo de APIYI | Exploramos las mejores prácticas para el desarrollo de software impulsado por IA. Te invitamos a visitar APIYI en apiyi.com para obtener acceso a la API de toda la serie de modelos Claude 4.6 y soporte técnico.