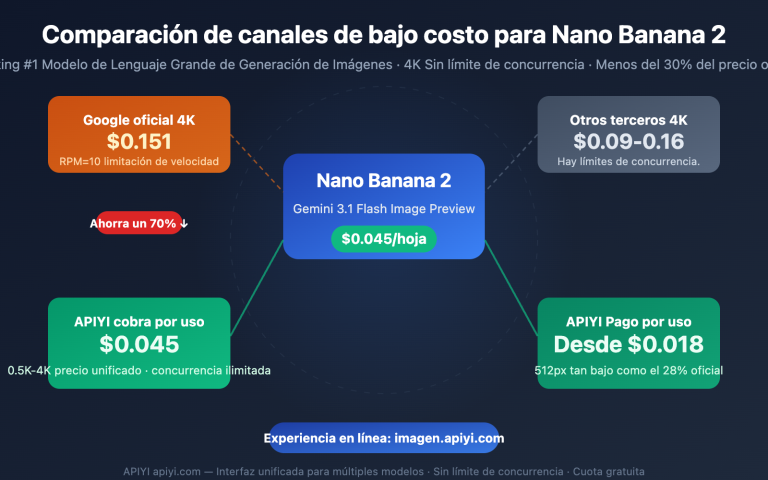
Estás usando OpenClaw para tus flujos de trabajo diarios, pero cada mes, al ver la factura de la API, sientes un nudo en el estómago: ¿$300, $500 o incluso más de $600?
No es culpa tuya, es por el diseño de la arquitectura de OpenClaw. Una instancia de OpenClaw sin optimizar envía una gran cantidad de "contenido innecesario" al modelo de IA en cada tarea, desperdiciando tokens sin motivo.
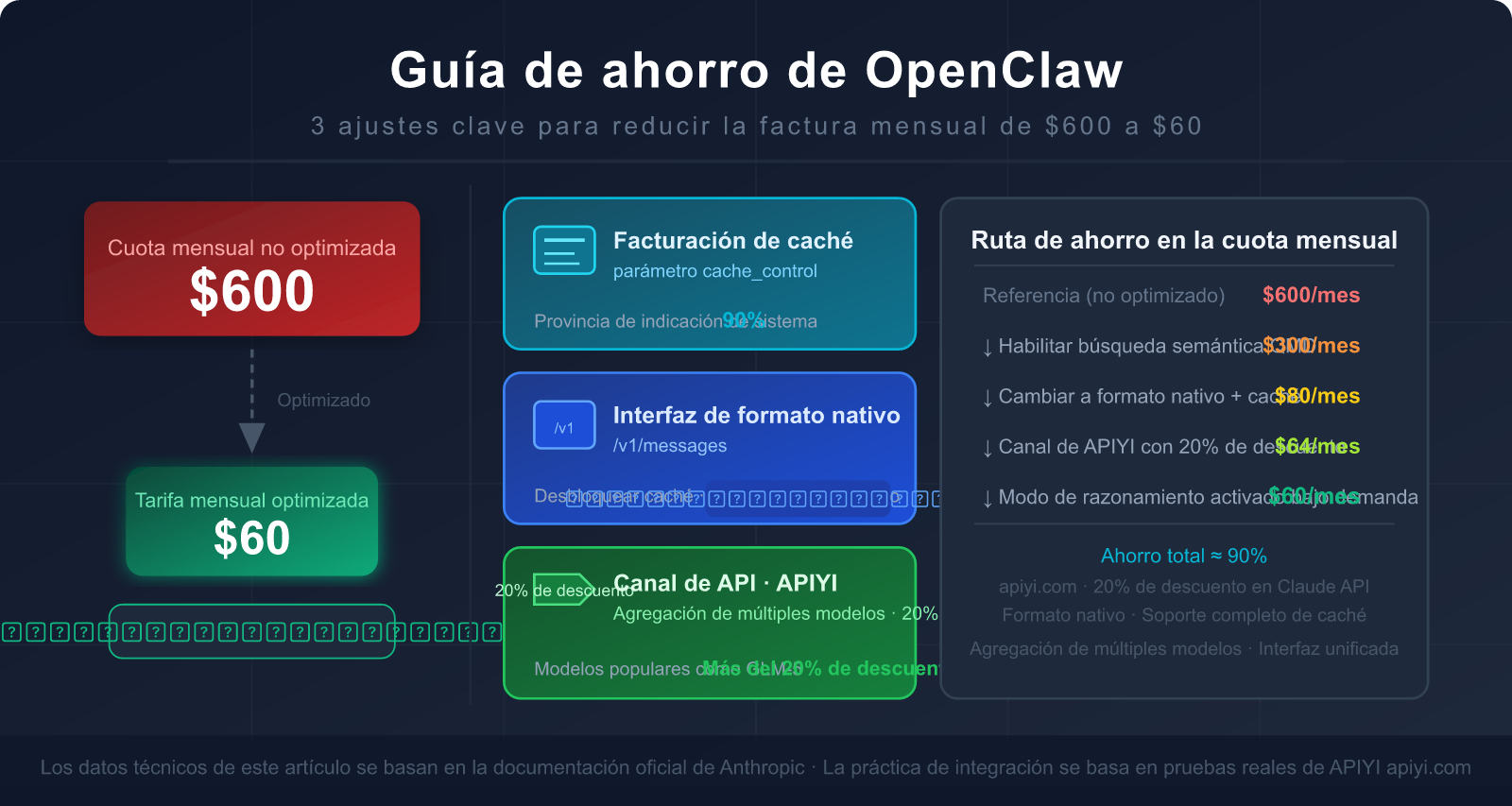
La buena noticia es que unos pocos ajustes clave pueden reducir la factura entre un 80% y un 90%, y la mayoría de la gente desconoce el truco más efectivo: usar la interfaz de formato nativo de Claude en lugar del modo de compatibilidad con OpenAI.
En este artículo, analizamos a fondo las causas fundamentales del alto consumo de tokens en OpenClaw y te enseñamos paso a paso cómo usar las interfaces correctas, configurar la caché y elegir los canales de API adecuados para bajar tu factura mensual de $600 a $60.
I. Por qué OpenClaw consume tantos Tokens: 3 razones fundamentales
Razón 1: Se reenvía todo el historial de la conversación en cada solicitud
Este es el motivo más ignorado, pero el que tiene un mayor impacto.
OpenClaw está diseñado bajo el principio de "contexto completo": cada vez que se envía una solicitud al modelo de IA, se incluyen todos los mensajes históricos desde el inicio de la conversación. De esta forma, el modelo puede "recordar" qué se hizo y qué se dijo anteriormente.
Veamos un ejemplo:
Ronda 1: El usuario envía 50 tokens, la IA responde 200 tokens → Total enviado: 250 tokens
Ronda 2: El usuario envía 50 tokens, la IA responde 200 tokens → Total enviado: 500 tokens (incluye la ronda 1)
Ronda 3: El usuario envía 50 tokens, la IA responde 200 tokens → Total enviado: 750 tokens (incluye rondas 1+2)
...
Ronda 10: En esta ronda solo se añaden 250 tokens nuevos, pero el volumen enviado ya es de 2,500 tokens
En un flujo de trabajo de OpenClaw que maneja tareas complejas, este "efecto bola de nieve" hace que el consumo de tokens crezca de forma exponencial. El historial de contexto suele representar entre el 40% y el 50% del consumo total de tokens.
Razón 2: El System Prompt se reenvía en cada ocasión
El System Prompt (indicación del sistema) de OpenClaw define la identidad del Agente, sus límites de capacidad, la lista de herramientas disponibles y las normas de comportamiento. Por lo general, ocupa entre 5,000 y 10,000 tokens.
El problema clave: este enorme System Prompt se envía íntegramente en cada invocación del modelo.
Supongamos que usas OpenClaw para procesar 50 tareas al día, y cada System Prompt es de 8,000 tokens:
Consumo diario de System Prompt = 50 × 8,000 = 400,000 tokens
Consumo mensual ≈ 12,000,000 tokens (¡solo en System Prompt!)
Tomando como referencia el precio de entrada de Claude Sonnet 3.5 ($3 por millón de tokens), solo el System Prompt te costaría $36 al mes. Y eso sin contar el contenido de la conversación ni la salida generada.
Razón 3: El modo de razonamiento dispara el consumo entre 10 y 50 veces
Cuando OpenClaw se enfrenta a tareas complejas, activa la "cadena de pensamiento" o el "modo de razonamiento" (Thinking/Reasoning). Este modo permite que la IA "piense antes de hablar", lo que mejora la calidad de la respuesta, pero a costa de un aumento masivo en el consumo de tokens.
Características del consumo de tokens de razonamiento:
- El proceso de pensamiento genera una gran cantidad de tokens intermedios (que suelen ser invisibles, pero se facturan).
- El razonamiento de una tarea compleja puede generar entre 10,000 y 50,000 tokens.
- Si no se controla, unas pocas tareas complejas pueden agotar el presupuesto de todo un día.
| Escenario de consumo de tokens | Modo normal | Modo de razonamiento | Diferencia |
|---|---|---|---|
| Tarea simple de Q&A | ~500 tokens | ~2,000 tokens | 4 veces |
| Flujo de gestión de emails | ~2,000 tokens | ~15,000 tokens | 7.5 veces |
| Tarea de análisis de código | ~5,000 tokens | ~80,000 tokens | 16 veces |
| Investigación compleja de varios pasos | ~10,000 tokens | ~200,000 tokens+ | 20 veces o más |
🎯 Diagnóstico rápido: Si tu factura de OpenClaw es inusualmente alta, revisa primero el uso del modo de razonamiento en los registros de tokens.
Desactivar el modo de razonamiento para tareas que no lo requieran es una de las formas más efectivas de ahorrar.
Cambiar a un modelo más adecuado también puede reducir drásticamente los costes; a través de APIYI (apiyi.com) puedes alternar y probar rápidamente entre diferentes modelos.
Distribución del consumo por las tres causas principales
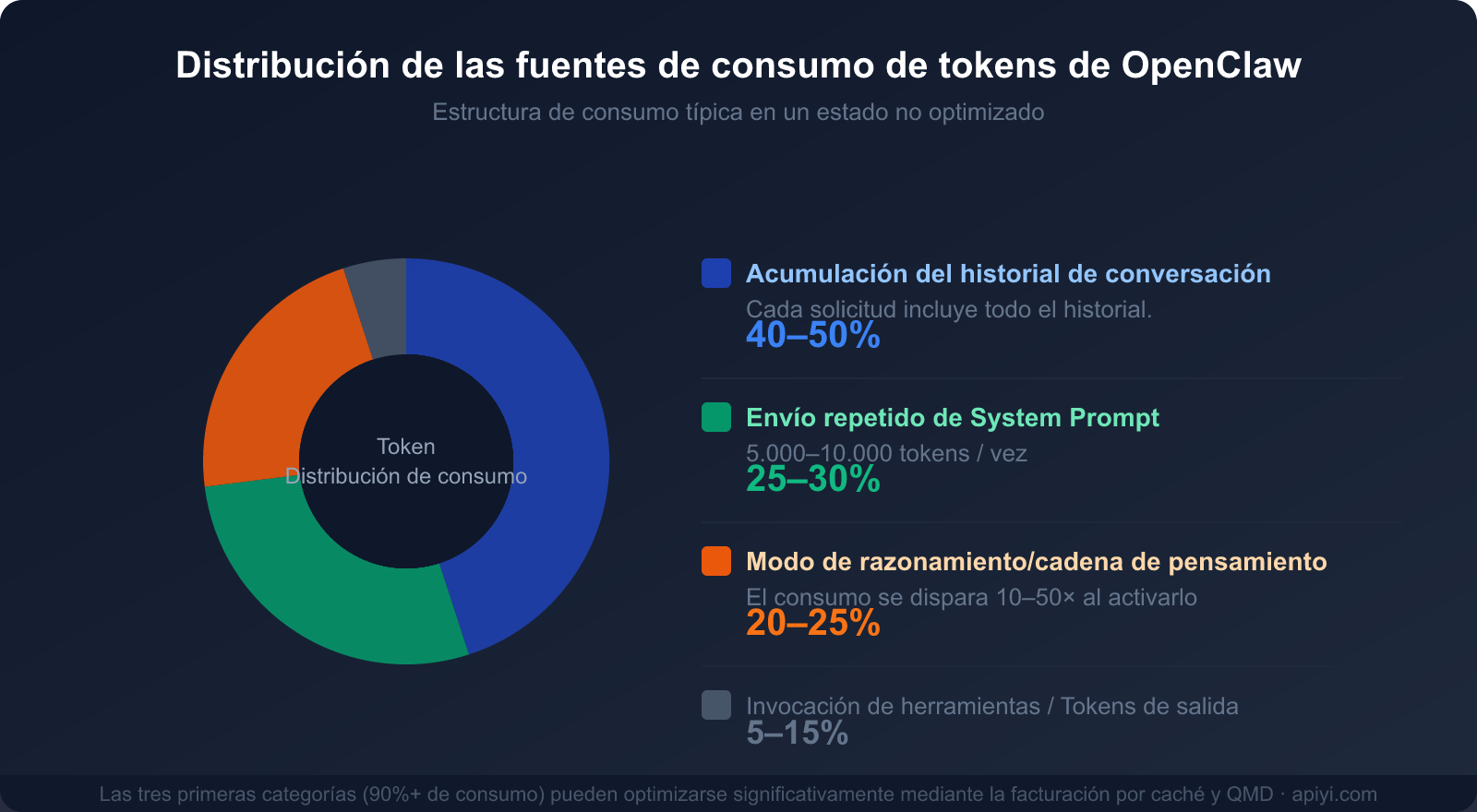
Comprender estas tres fuentes de consumo es el primer paso para diseñar una estrategia de ahorro:
| Fuente de consumo | % del consumo total | ¿Es optimizable? | Principal método de optimización |
|---|---|---|---|
| Historial de conversación (acumulación de contexto) | 40-50% | ✅ Muy optimizable | Caché, limpieza periódica, QMD |
| Envío repetido del System Prompt | 25-30% | ✅ Muy optimizable | Facturación por caché (ahorro del 90%) |
| Modo de razonamiento / Cadena de pensamiento | 20-25% | ✅ Según necesidad | Activar solo para tareas complejas |
| Llamadas a herramientas y salida | 5-15% | ⚡ Optimización limitada | Simplificar descripciones de herramientas |
II. La joya más ignorada para ahorrar dinero: Facturación por caché de Claude
¿Qué es la facturación por caché de Claude?
El Prompt Caching (caché de indicaciones) de Claude es una funcionalidad nativa lanzada por Anthropic a finales de 2024. Su lógica central es: almacenar en el servidor el contenido que se envía con frecuencia para que, en las siguientes invocaciones, se lea directamente de la caché en lugar de procesarlo de nuevo.
El precio de lectura de caché: solo el 10% del precio de entrada normal (ahorras un 90%).
Esto significa que, si envías un System Prompt de 8,000 tokens, una vez cacheado, las repeticiones que coincidan solo se facturarán como 800 tokens. Para un usuario de OpenClaw que envía decenas de solicitudes al día, esta optimización puede suponer un ahorro de cientos de dólares al mes.
Sistema completo de precios de la facturación por caché
| Tipo de caché | Multiplicador de coste | Tiempo de vida (TTL) | Escenario de uso |
|---|---|---|---|
| Token de entrada normal | 1× Precio base | No se cachea | Procesamiento nuevo cada vez |
| Escritura en caché (primera vez) | 1.25× | 5 minutos TTL | Creación de la caché |
| Escritura en caché (larga duración) | 2× | 1 hora TTL | Escenarios de llamadas frecuentes |
| Lectura de caché (acierto/hit) | 0.1× (ahorro del 90%) | Durante la validez | Solicitudes repetidas |
Ejemplo de cálculo de ahorro real:
Escenario: System Prompt de OpenClaw de 8,000 tokens
50 llamadas al día, con 48 aciertos en caché
Sin usar caché: 50 × 8,000 = 400,000 tokens
Coste = 400,000 × $3/1M = $1.20/día = $36/mes
Con caché: 2 escrituras: 2 × 8,000 × 1.25 = 20,000 tokens = $0.06
48 aciertos: 48 × 8,000 × 0.1 = 38,400 tokens = $0.12
Coste diario ≈ $0.18 → Mensual ≈ $5.40
Ahorro: $36 - $5.40 = $30.60/mes (solo en el System Prompt)
Porcentaje de ahorro: 85%
Cómo habilitar la facturación por caché en OpenClaw
Para activar la facturación por caché existe un requisito indispensable: debes utilizar la interfaz de formato nativo de Anthropic (/v1/messages), en lugar del modo compatible con OpenAI (/v1/chat/completions).
Configuración correcta (ejemplo con Python SDK):
import anthropic
# Es obligatorio usar el SDK nativo de Anthropic, no el de OpenAI
client = anthropic.Anthropic(
api_key="tu-clave-api",
base_url="https://api.apiyi.com/v1" # APIYI soporta el formato nativo de Anthropic
)
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=4096,
system=[
{
"type": "text",
"text": "Eres un asistente de IA profesional... [System Prompt de 8000 tokens]",
"cache_control": {"type": "ephemeral"} # ← CLAVE: marcar este contenido para caché
}
],
messages=[
{"role": "user", "content": "Ayúdame a organizar mis correos de hoy"}
]
)
Restricciones técnicas de la caché:
- Se pueden establecer un máximo de 4 puntos de interrupción de caché (marcas
cache_control). - Serie Sonnet: el contenido mínimo cacheable debe ser ≥ 1,024 tokens.
- Opus / Haiku 4.5: el contenido mínimo cacheable debe ser ≥ 4,096 tokens.
- Modelos compatibles: Claude Opus 4, Sonnet 4.6, Sonnet 4.5, Sonnet 4, Sonnet 3.7, Haiku 4.5, Haiku 3.5, Haiku 3, etc.
🎯 Nota importante: APIYI (apiyi.com) ofrece soporte completo para llamadas en formato nativo de Anthropic, incluyendo el parámetro
cache_control. Al usar el formato nativo con los modelos de Claude en APIYI, puedes disfrutar simultáneamente de la facturación por caché (hasta 90% de ahorro) + el 20% de descuento de APIYI, logrando un efecto de ahorro acumulado espectacular.
III. Conocimiento clave: Por qué el modo compatible con OpenAI no ahorra tokens
Este es el error más común en el que suelen caer los usuarios de OpenClaw.
Diferencias fundamentales entre los formatos de interfaz
Muchas herramientas de IA de terceros y servicios proxy ofrecen un modo compatible con OpenAI para facilitar la vida al usuario, permitiendo usar el formato de interfaz /v1/chat/completions de OpenAI para llamar a modelos que no son de OpenAI, como Claude.
A primera vista, esto permite "usar un solo código para todos los modelos", pero tiene un fallo fatal:
El formato de interfaz /v1/chat/completions no tiene un lugar para el parámetro cache_control, ya que esta es una función nativa exclusiva de Anthropic.
Cuando llamas a Claude a través del formato compatible con OpenAI:
- Tu solicitud se convierte al formato de OpenAI.
- El servicio proxy/pasarela la convierte de nuevo al formato nativo de Anthropic.
- Pero la información de
cache_controlya se ha perdido en el primer paso. - El servidor de Claude recibe una solicitud sin marcas de caché y factura cada vez por el total de tokens.
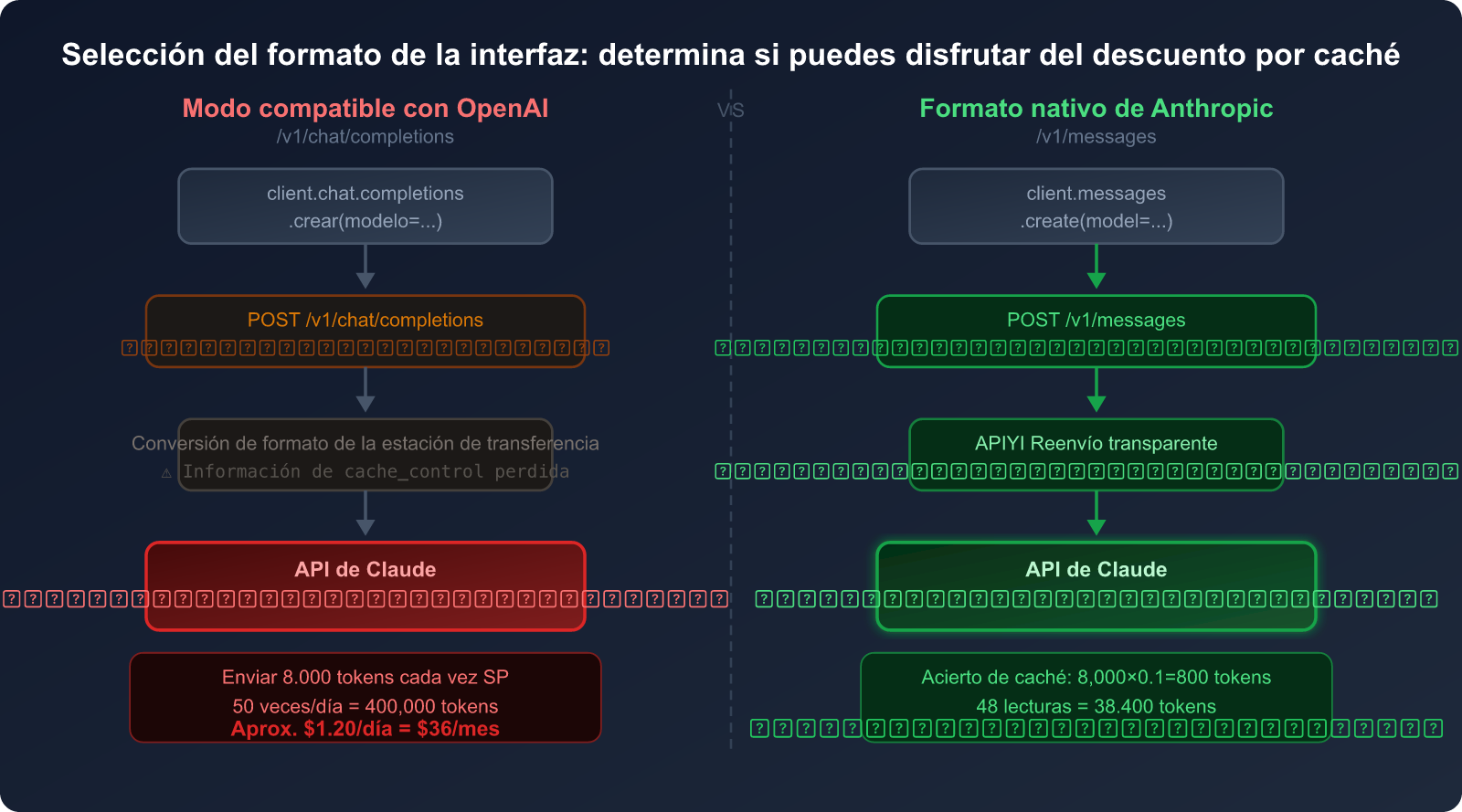
Comparativa: Modo compatible con OpenAI vs. Formato nativo de Anthropic
| Dimensión de comparación | Modo compatible con OpenAI | Formato nativo de Anthropic |
|---|---|---|
| Ruta de la interfaz | /v1/chat/completions |
/v1/messages |
| Soporte de caché de Claude | ❌ No compatible | ✅ Soporte completo |
Parámetro cache_control |
❌ No existe este campo | ✅ Soporta 4 puntos de interrupción |
| Facturación del System Prompt | 💸 Total (1× precio) | 💰 Lectura de caché (0.1× precio) |
| Complejidad del código | Baja (código genérico) | Media (requiere SDK de Anthropic) |
| Efecto de ahorro (uso frecuente) | 0% | Hasta 90% |
Problemas adicionales de los despliegues de API no originales
Además del formato de la interfaz, hay otra situación que suele causar confusión: un modelo con el "mismo nombre" desplegado por un proveedor de nube no equivale al original.
Tomemos como ejemplo el GLM-5 (de Zhipu AI):
- API original de z.ai: Soporta la función de facturación por caché desarrollada por Zhipu.
- GLM-5 desplegado en Alibaba Cloud / Tencent Cloud, etc.: Utiliza la pasarela de API del proveedor de nube y no cuenta con la función de facturación por caché original.
Esto no es un problema de GLM-5, sino un mal común de los despliegues no originales: cuando los proveedores de nube alojan modelos, generalmente solo exponen una API de chat estándar y no transmiten las características privadas del fabricante original (como la facturación por caché).
Analogía: Es como comprar un producto a través de un revendedor; no siempre puedes disfrutar de los servicios postventa especializados oficiales del fabricante.
Impacto real:
Escenario: 50 llamadas diarias, System Prompt de 6,000 tokens
API original (con soporte de caché):
Escritura: 2 veces × 6,000 × 1.25 = 15,000 tokens
Lectura: 48 veces × 6,000 × 0.1 = 28,800 tokens
Consumo equivalente ≈ 43,800 tokens/día
API no original (sin caché):
Total: 50 veces × 6,000 = 300,000 tokens/día
Diferencia: El consumo sin caché es 6.85 veces mayor que con caché.
IV. Comparativa de APIs originales: Cómo elegir el mejor plan de acceso para OpenClaw
Comparativa de cuatro planes de acceso
| Plan de acceso | Precio (relativo al original) | Soporte de caché | Soporte multimodelo | Escenario ideal |
|---|---|---|---|---|
| API oficial de Anthropic | 100% (precio original) | ✅ Completo | ❌ Solo Claude | Presupuesto amplio, usuarios exclusivos de Claude |
| APIYI (formato nativo de Anthropic) | 80% (20% de descuento) | ✅ Completo | ✅ Multimodelo | Recomendado: Ahorro + cambio flexible |
| Proxy genérico (compatible con OpenAI) | 85-95% variable | ❌ No soportado | ✅ Multimodelo | Cuando no se usa el caché de Claude |
| Despliegue no original de proveedores de nube | 90-110% variable | ❌ No soportado | ❌ Un solo modelo | Escenarios con requisitos de cumplimiento corporativo |
La lógica de ahorro doble de APIYI
La ventaja de APIYI en los modelos Claude reside en que: soporta simultáneamente el formato nativo de Anthropic y ofrece un 20% de descuento.
La combinación de estos dos puntos significa:
Usuario estándar (precio original + compatible con OpenAI, sin caché):
Consumo mensual de tokens de System Prompt: 12,000,000 tokens
Coste = 12,000,000 × $3/1M = $36
Usuario de APIYI (20% de descuento + formato nativo + caché):
Tokens facturados reales ≈ 1,440,000 tokens (tras caché)
Coste = 1,440,000 × $3×0.8/1M = $3.46
Ahorro total = ($36 - $3.46) / $36 ≈ 90%
🎯 Sugerencia de selección: Si usas OpenClaw y tu modelo principal es Claude, te recomendamos encarecidamente acceder a través de APIYI apiyi.com usando el formato nativo de Anthropic. El precio base con 20% de descuento sumado al 90% de ahorro por caché puede reducir tu factura entre un 85% y un 90%. Además, APIYI soporta otros modelos como GLM-5 o GPT, lo que te permite alternar y comparar resultados fácilmente.
V. Guía completa de ahorro en OpenClaw: 5 pasos ejecutables de inmediato
Paso 1: Cambiar a la interfaz de formato nativo de Anthropic
Este es el paso más importante, ya que determina directamente si puedes disfrutar de la facturación por caché.
Método de configuración en OpenClaw:
En la configuración de modelos de OpenClaw (config.json), busca el campo models.providers y añade a APIYI como proveedor siguiendo este formato. La clave es establecer el campo api como "anthropic-messages", lo que permite usar el formato nativo de Anthropic y el soporte de caché:
{
"models": {
"providers": {
"apiyi": {
"baseUrl": "https://api.apiyi.com",
"apiKey": "sk-tu-token-aquí",
"api": "anthropic-messages",
"headers": {
"anthropic-version": "2023-06-01",
"anthropic-beta": ""
},
"models": [
{
"id": "claude-sonnet-4-6",
"name": "claude-sonnet-4-6",
"reasoning": false,
"input": ["text"],
"contextWindow": 200000,
"maxTokens": 16384
},
{
"id": "claude-sonnet-4-6-thinking",
"name": "claude-sonnet-4-6-thinking",
"reasoning": false,
"input": ["text"],
"contextWindow": 200000,
"maxTokens": 16384
}
]
}
}
}
}
Puntos clave de la configuración:
"api": "anthropic-messages"← Lo más crítico, especifica el uso del formato nativo/v1/messagesen lugar del formato compatible/v1/chat/completions."baseUrl": "https://api.apiyi.com"← URL base de APIYI (no es necesario añadir/v1, OpenClaw lo hará automáticamente)."anthropic-version": "2023-06-01"← Cabecera de versión de la API de Anthropic; sin ella, la solicitud fallará.contextWindow: 200000← Claude Sonnet 4.6 soporta una ventana de contexto de 200K.
Verificar si el caché está funcionando:
Revisa las cabeceras de respuesta de la API o los registros para encontrar los campos cache_read_input_tokens y cache_creation_input_tokens. Si tienen valores, el caché está activo:
# Verificar la respuesta del caché
response = client.messages.create(...)
# Comprobar el campo usage
print(response.usage)
# Ejemplo de salida:
# Usage(
# input_tokens=150, # Tokens nuevos en esta llamada
# cache_creation_input_tokens=8000, # Primera escritura en caché (facturado a 1.25x)
# cache_read_input_tokens=0, # Acierto de caché posterior (facturado a 0.1x)
# output_tokens=300
# )
🎯 Modo de acceso: Tras registrarte y obtener tu clave API en APIYI apiyi.com, simplemente configura el
base_urlcomohttps://api.apiyi.com/v1para usar el formato nativo de Anthropic. No necesitas cambiar nada más en tu código y la facturación por caché de Claude se activará de inmediato.
Paso 2: Colocar los puntos de interrupción de caché de forma razonable
La ubicación de los puntos de interrupción de caché (cache_control) es vital. Debes cachear el contenido que sea "grande y estático":
# Mejores prácticas: cachear indicación del sistema + definiciones de herramientas
response = client.messages.create(
model="claude-sonnet-4-6",
system=[
{
"type": "text",
"text": SYSTEM_PROMPT, # Indicación principal del sistema de 5,000-10,000 tokens
"cache_control": {"type": "ephemeral"} # Punto de interrupción 1
},
{
"type": "text",
"text": TOOL_DEFINITIONS, # Lista de herramientas (normalmente también grande)
"cache_control": {"type": "ephemeral"} # Punto de interrupción 2
}
],
messages=conversation_history, # Historial de conversación (no se cachea, cambia cada vez)
...
)
Claves de la estrategia de caché:
- ✅ Ideal para caché: Indicaciones del sistema, definiciones de herramientas, documentos estáticos extensos, contenido de documentos recuperados por RAG.
- ❌ No apto para caché: Mensajes actuales del usuario, contenido generado dinámicamente, datos que cambian en cada interacción.
- ⚠️ Atención al orden: El caché funciona por coincidencia de prefijo; el contenido estático debe ir al principio de la secuencia de mensajes.
Paso 3: Activar QMD para reducir la longitud del contexto
QMD (Quick Memory Database) es la función de búsqueda semántica local de OpenClaw. Así es como funciona:
Método tradicional:
Envía [todo el historial] cada vez → Consume gran cantidad de tokens
Método QMD:
Crea base de datos vectorial local → Busca los fragmentos históricos más relevantes
Envía solo [los 3-5 registros más relevantes] cada vez → Ahorra entre 60-97% de tokens
Efecto real de ahorro de QMD: Según la documentación oficial de OpenClaw, QMD puede lograr un ahorro de tokens del 60-97%, dependiendo del volumen del historial y del tipo de tarea.
Cómo activarlo (Interfaz de ajustes de OpenClaw):
- Settings → Memory → Enable QMD
- Configura la ruta de almacenamiento de QMD (local, los datos no se suben a la nube)
- Establece el umbral de relevancia (se recomienda más de 0.7 para evitar ruido histórico)
Paso 4: Elegir el modelo adecuado según el tipo de tarea
No todas las tareas requieren el modelo más potente. La asignación correcta de modelos es clave para el control de costes:
Estrategia de niveles de tareas:
Tareas simples (recordatorios, conversión de formato, búsquedas simples)
→ Usa Claude Haiku 4.5 (el más rápido y económico)
→ Aproximadamente 1/5 del precio de Sonnet
Tareas intermedias (gestión de correos, organización de archivos, revisión de código)
→ Usa Claude Sonnet 4.6 (el más equilibrado)
→ Tasa de éxito del 86.9% (Nº 1 en PinchBench)
Tareas complejas (análisis de arquitectura, investigación de varios pasos, razonamiento complejo)
→ Usa Claude Opus 4.6 (el razonamiento más potente)
→ Activa el modo de razonamiento solo cuando sea realmente necesario
Paso 5: Limpieza periódica del contexto
El historial de conversación es una de las mayores fuentes de consumo de tokens (40-50%). Se recomienda:
- Establecer un número máximo de turnos de contexto: Resumir y limpiar el historial automáticamente tras 15-20 turnos.
- Limpieza manual tras finalizar una tarea: Reiniciar el contexto antes de empezar una tarea nueva.
- Activar la función de compresión de sesión de OpenClaw: Usa la IA para comprimir historiales largos en resúmenes concisos.
Estimación del efecto combinado de las cinco optimizaciones
Para un usuario medio de OpenClaw (con un gasto mensual sin optimizar de unos $300-600), este es el ahorro esperado tras aplicar los cinco pasos:
| Paso de optimización | Fuente de consumo abordada | Proporción de ahorro esperada | Dificultad de ejecución |
|---|---|---|---|
| 1. Cambiar a formato nativo Anthropic | Facturación repetida de System Prompt | Ahorro 85-90% (en SP) | ⭐ Baja (cambiar base_url) |
| 2. Configurar puntos de caché | Definiciones de herramientas + Docs estáticos | Ahorro 80-90% (en herramientas) | ⭐⭐ Baja-Media |
| 3. Activar QMD | Tokens del historial de conversación | Ahorro 60-97% (en historial) | ⭐⭐ Baja-Media |
| 4. Clasificación de modelos por tarea | Coste total de tokens | Ahorro 30-70% (diferencia de precio) | ⭐⭐⭐ Media |
| 5. Limpieza periódica del contexto | Efecto bola de nieve del historial | Ahorro 20-40% (beneficio a largo plazo) | ⭐ Baja |
🎯 Prioridad de ejecución sugerida: El Paso 1 (cambiar al formato nativo) y el Paso 3 (activar QMD) son los que ofrecen mayor beneficio con menor esfuerzo. Se recomienda priorizar estos dos pasos, lo que suele reducir la factura entre un 60% y un 80% de inmediato. Al acceder a Claude mediante APIYI apiyi.com, el Paso 1 solo requiere modificar una línea en
base_urly se completa en menos de 5 minutos.
VI. Configuración práctica: Ejemplo completo de OpenClaw + APIYI + Caché de Claude
A continuación, se muestra un ejemplo de configuración de OpenClaw completo y optimizado, listo para que la mayoría de los usuarios lo reutilicen directamente:
import anthropic
# Usando el formato nativo de Anthropic a través de APIYI
client = anthropic.Anthropic(
api_key="sk-your-apiyi-key", # Clave de APIYI (regístrate en apiyi.com para obtenerla)
base_url="https://api.apiyi.com/v1"
)
# Definir la indicación del sistema (contenido extenso, ideal para caché)
SYSTEM_PROMPT = """
Eres un asistente inteligente de IA profesional que se ejecuta en la plataforma OpenClaw.
Tus responsabilidades incluyen: gestionar agendas, procesar correos electrónicos, organizar archivos, asistir en el desarrollo de código...
[Normalmente contiene entre 5,000 y 10,000 tokens de instrucciones detalladas]
"""
# Definir la lista de herramientas (también contenido fijo extenso, ideal para caché)
TOOL_DEFINITIONS = """
Herramientas disponibles: calendar_api, email_api, file_system, code_runner...
[Descripción detallada de herramientas, normalmente entre 2,000 y 5,000 tokens]
"""
def call_openclaw_with_cache(conversation_history: list, user_message: str):
"""Invocación de la API de OpenClaw optimizada, con caché habilitado"""
response = client.messages.create(
model="claude-sonnet-4-6", # Número 1 en el ranking de PinchBench
max_tokens=4096,
# Indicación del sistema: marcar puntos de interrupción de caché
system=[
{
"type": "text",
"text": SYSTEM_PROMPT,
"cache_control": {"type": "ephemeral"} # Punto de interrupción de caché 1
},
{
"type": "text",
"text": TOOL_DEFINITIONS,
"cache_control": {"type": "ephemeral"} # Punto de interrupción de caché 2
}
],
# Historial de conversación + mensaje nuevo
messages=[
*conversation_history, # Mensajes históricos (no se cachean, cambian cada vez)
{"role": "user", "content": user_message}
]
)
# Imprimir el uso de tokens (para monitorear el efecto de la optimización)
usage = response.usage
print(f"Tokens de entrada: {usage.input_tokens}")
print(f"Escritura en caché: {usage.cache_creation_input_tokens}")
print(f"Lectura de caché: {usage.cache_read_input_tokens}")
print(f"Tokens de salida: {usage.output_tokens}")
return response.content[0].text
🎯 Inicio rápido: Sustituye la
api_keydel código anterior por la clave que obtuviste al registrarte en APIYI (apiyi.com). Sin necesidad de otros cambios, podrás usar de inmediato la combinación del formato nativo de Anthropic + facturación por caché + el 20% de descuento de APIYI.
Preguntas frecuentes (FAQ)
P: ¿Realmente APIYI admite el formato nativo de Anthropic (/v1/messages)?
Sí, APIYI (apiyi.com) admite simultáneamente dos formatos de interfaz:
- Formato nativo de Anthropic:
/v1/messages(admite facturación por caché). - Formato compatible con OpenAI:
/v1/chat/completions(conveniente para código genérico).
Para los modelos Claude, se recomienda encarecidamente utilizar el formato nativo de Anthropic, ya que solo así podrás disfrutar de la facturación por caché. Simplemente usa el SDK de Python de anthropic y apunta el base_url a APIYI.
🎯 Visita APIYI (apiyi.com) para registrar una cuenta; en la consola podrás ver ejemplos de código de acceso para ambos formatos.
P: ¿Es suficiente un TTL de caché de 5 minutos? ¿Cómo sé si necesito un TTL de 1 hora?
Esto depende de tu frecuencia de invocación:
- Si tus llamadas a OpenClaw tienen un intervalo < 5 minutos (como cuando procesas un flujo de tareas continuo), el TTL predeterminado de 5 minutos es suficiente.
- Si el intervalo de llamada está entre 5 minutos y 1 hora (por ejemplo, haces una pausa tras procesar un lote de tareas), considera el TTL de 1 hora (el coste es el doble del precio de escritura, pero la tasa de acierto de caché es mayor).
- Si el intervalo de llamada es > 1 hora, el caché tiene poco sentido y es mejor reescribirlo cada vez.
P: Al usar modelos chinos como GLM-5, ¿qué consejos hay para ahorrar dinero?
La función de caché de GLM-5 requiere el uso de la API nativa a través del sitio oficial de Zhipu AI (z.ai); los despliegues de terceros como Alibaba Cloud no pueden usarla.
APIYI también es compatible con modelos chinos como GLM-5, con precios por debajo del 80% del original, lo que te facilita comparar el rendimiento de cada modelo con una interfaz unificada durante la fase de pruebas. Una vez que determines qué modelo se adapta mejor a tu escenario, podrás decidir si seguir con APIYI o conectar directamente con el fabricante original.
P: Ya estoy usando otro servicio proxy de API, ¿qué tan difícil es migrar a una plataforma que admita el formato nativo?
El coste de migración es muy bajo. Lo único que necesitas modificar son dos parámetros en tu código:
# Antes de la migración (formato compatible con OpenAI)
from openai import OpenAI
client = OpenAI(api_key="sk-xxx", base_url="dirección_del_proxy_antiguo")
response = client.chat.completions.create(model="claude-sonnet-4-6", ...)
# Después de la migración (formato nativo de Anthropic, admite caché)
import anthropic
client = anthropic.Anthropic(
api_key="sk-nueva-clave-APIYI", # ← Cambia por la clave de APIYI
base_url="https://api.apiyi.com/v1" # ← Cambia por la dirección de APIYI
)
response = client.messages.create(model="claude-sonnet-4-6", ...)
# Luego, añade cache_control en el parámetro system para habilitar el caché
El trabajo principal consiste en cambiar chat.completions.create por messages.create. El formato del mensaje tiene diferencias sutiles (la estructura role/content es consistente, pero system pasa de ser una cadena a una lista de objetos). Normalmente, la migración se completa en menos de medio día.
P: ¿Cómo verifico si mi instancia de OpenClaw ha habilitado el caché correctamente?
El método más directo: al realizar dos llamadas consecutivas, observa el objeto usage en la respuesta de la API:
- Primera llamada:
cache_creation_input_tokenstiene un valor (escritura en caché). - Segunda llamada:
cache_read_input_tokenstiene un valor (acierto de caché).
Si el valor de cache_read_input_tokens en la segunda llamada es igual al número de tokens de tu System Prompt, significa que el caché está funcionando perfectamente.
P: ¿Es obligatorio desactivar el modo de razonamiento/pensamiento (Extended Thinking)?
No es obligatorio desactivarlo por completo, pero debe usarse según sea necesario. Estrategia recomendada:
- Tareas sencillas (clasificación de correos, agenda): desactivar el modo de razonamiento.
- Tareas intermedias (revisión de código, resumen de información): desactivado por defecto, activarlo si hay dificultades.
- Tareas complejas (decisiones de arquitectura, investigación de varios pasos): activarlo, pero estableciendo un límite razonable de
budget_tokens.
En la API de Claude, puedes limitar el consumo máximo de tokens del modo de razonamiento mediante thinking: {"type": "enabled", "budget_tokens": 5000}.
Resumen: La lógica central de ahorro de OpenClaw
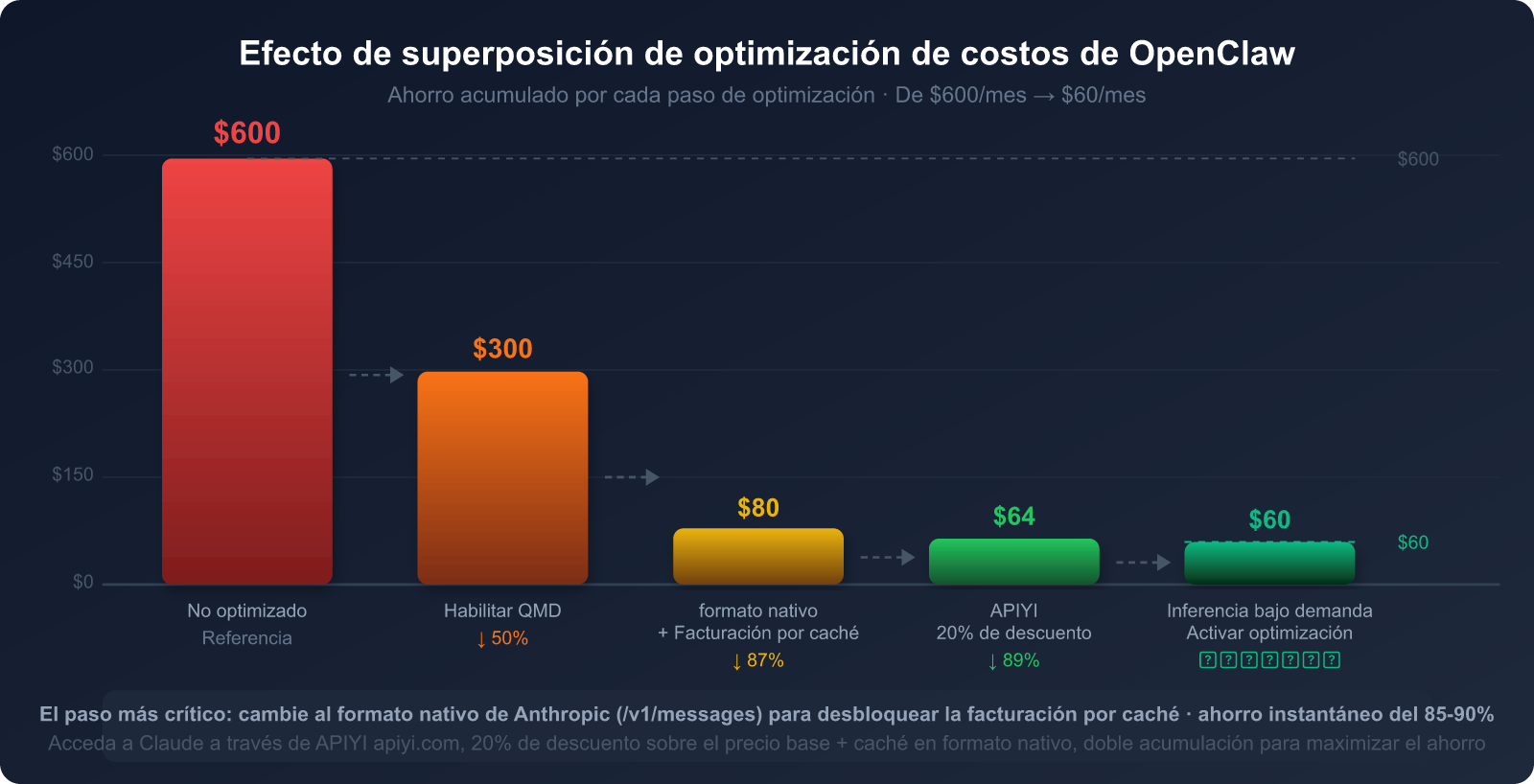
Resumamos todos los métodos de ahorro en un solo gráfico:
Repasemos los puntos clave de este artículo:
Las tres causas principales de alto consumo:
- Reenvío del historial de conversación en cada turno (representa el 40-50% del consumo).
- Reenvío del System Prompt en cada turno (representa el 25-30%).
- Uso descontrolado del modo de inferencia (representa el 20-25%).
Los métodos de ahorro más eficientes:
- 🥇 Facturación por caché de Claude: Ahorra hasta un 90% (es obligatorio usar el formato nativo de Anthropic).
- 🥈 Búsqueda semántica local QMD: Ahorra entre un 60% y 97% de los tokens de contexto histórico.
- 🥉 Clasificación de modelos por tarea: Usa Haiku para tareas ligeras y Sonnet/Opus para tareas complejas.
- Canal de API elige APIYI: Precio base con 20% de descuento + soporte de formato nativo.
Un conocimiento fundamental:
El formato compatible con OpenAI (
/v1/chat/completions) no puede transmitircache_control.
Incluso si llamas a Claude a través de un servicio proxy, no disfrutarás de los descuentos por caché.
Para ahorrar, debes usar el formato nativo de Anthropic (/v1/messages).
🎯 Actúa ahora: Visita APIYI en apiyi.com para registrarte y obtener una clave API que soporte el formato nativo de Anthropic.
Cambia labase_urlahttps://api.apiyi.com/v1. Completarás el cambio en menos de 3 minutos y verás una reducción significativa en tu factura de tokens desde el primer día. Con modelos de Claude al 20% de descuento y una interfaz unificada para múltiples modelos, es la mejor opción para que los usuarios de OpenClaw reduzcan costes y mejoren la eficiencia.
Todos los datos de precios de API en este artículo se basan en información pública de marzo de 2026; el precio real está sujeto a los anuncios oficiales de cada plataforma.
Autor: Equipo de APIYI | Para más trucos de uso de OpenClaw, visita el centro de ayuda de APIYI en apiyi.com