Nota del autor: Comparación en profundidad de los 3 modelos de IA más potentes para resolver problemas matemáticos en 2026, incluyendo datos de pruebas de referencia autorizadas como AIME y MATH, para ayudarte a encontrar el modelo de razonamiento matemático más adecuado.
Elegir qué modelo de IA usar para resolver problemas matemáticos es una de las decisiones más importantes para desarrolladores y estudiantes. Este artículo compara tres de los últimos modelos de razonamiento matemático lanzados en 2026: Gemini 3.1 Pro Preview, Claude Sonnet 4.6 y GPT-5.4, ofreciendo recomendaciones claras basadas en puntuaciones de pruebas de referencia, capacidad de razonamiento, precio de la API y escenarios de uso.
Valor principal: Después de leer este artículo, sabrás exactamente qué modelo de IA elegir para diferentes escenarios de resolución de problemas matemáticos y cómo invocarlos con el coste óptimo.
Comparación Rápida de Modelos de IA para Resolución de Problemas Matemáticos
Antes de entrar en el análisis detallado, echa un vistazo a esta tabla comparativa de datos clave para entender rápidamente las diferencias principales entre los tres modelos de IA para resolución de problemas matemáticos.
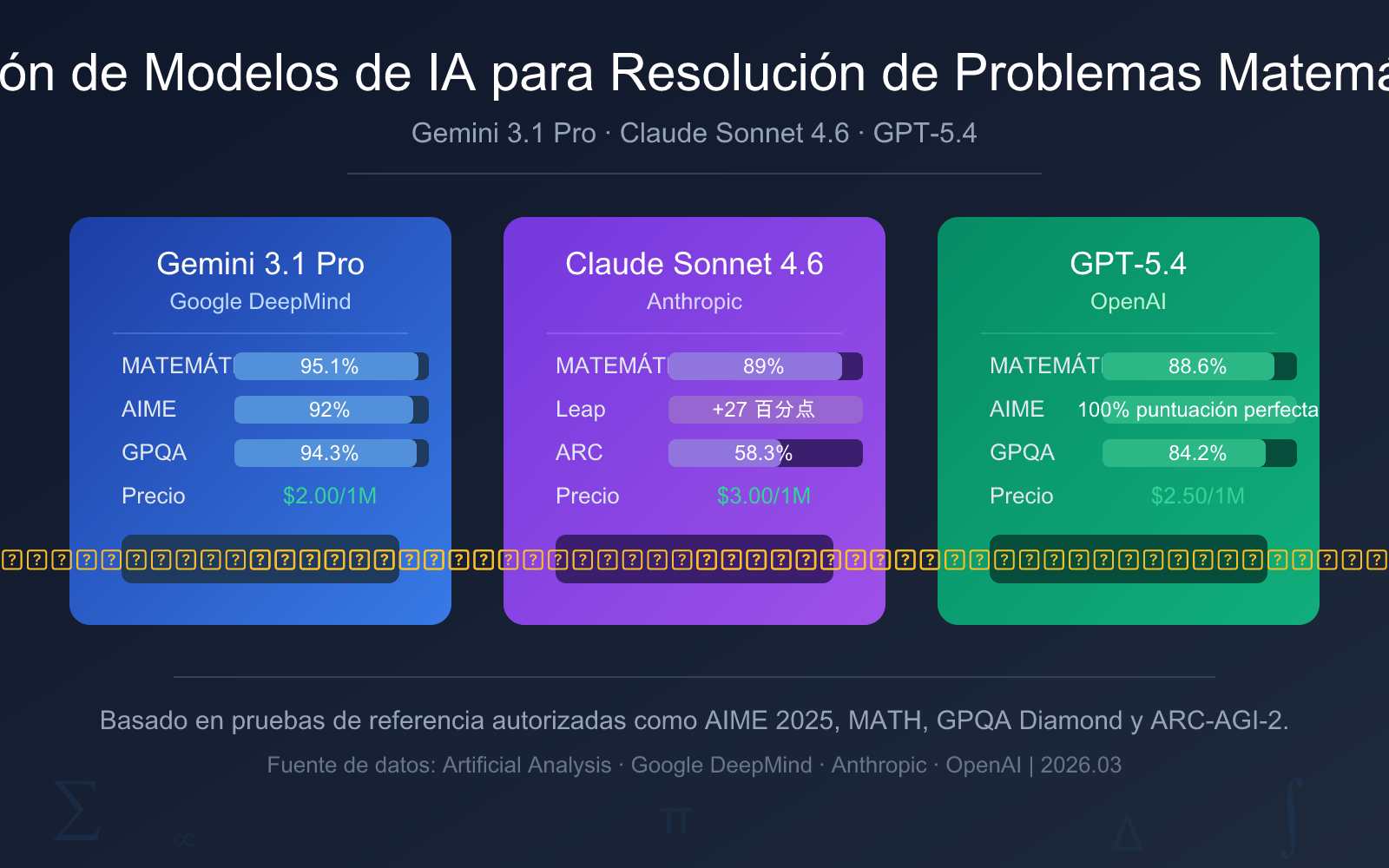
| Dimensión de Comparación | Gemini 3.1 Pro Preview | Claude Sonnet 4.6 | GPT-5.4 |
|---|---|---|---|
| Fecha de Lanzamiento | 19 de febrero de 2026 | Principios de 2026 | 6 de marzo de 2026 |
| AIME 2025 | 92% (sin herramientas) | — | 100% (puntuación perfecta) |
| Benchmark MATH | 95.1% | 89% | 88.6% |
| GPQA Diamond | 94.3% | 74.1% | 84.2% |
| ARC-AGI-2 | 77.1% | 58.3% | 73.3% |
| Precio de Entrada | $2.00 / 1M tokens | $3.00 / 1M tokens | $2.50 / 1M tokens |
| Precio de Salida | $12.00 / 1M tokens | $15.00 / 1M tokens | $15.00 / 1M tokens |
| Recomendación General | ⭐ Primera opción recomendada | ⭐ Primera opción para aprendizaje | ⭐ Primera opción para competiciones |
Orden de Recomendación de Modelos de IA para Matemáticas
Desde la perspectiva de la relación calidad-precio, sugerimos el siguiente orden:
- Primera opción: Gemini 3.1 Pro Preview: Lidera con un 95.1% en el benchmark MATH, precio más bajo y la capacidad matemática general más fuerte.
- Segunda opción: Claude Sonnet 4.6: Capacidad matemática aumentada en 27 puntos porcentuales, proceso de resolución claro y comprensible, ideal para escenarios de aprendizaje.
- Nivel competición: GPT-5.4: Puntuación perfecta del 100% en AIME 2025, adecuado para competiciones matemáticas de alta dificultad e investigación profesional.
🎯 Recomendación Técnica: Los tres modelos se pueden invocar de manera unificada a través de la plataforma APIYI apiyi.com. Se recomienda probar cada uno con problemas matemáticos reales para seleccionar el modelo que mejor se adapte a tus necesidades.
Análisis Detallado de la Capacidad de Resolución Matemática de Gemini 3.1 Pro Preview
Gemini 3.1 Pro Preview es el último modelo insignia lanzado por Google DeepMind el 19 de febrero de 2026. Esta es la primera vez que Google utiliza un incremento de versión «.1» (las actualizaciones intermedias anteriores siempre usaban «.5»), lo que marca una actualización dirigida centrada en la capacidad de razonamiento inteligente.
Puntuaciones de Gemini 3.1 Pro en Benchmarks Matemáticos
| Benchmark | Puntuación | Explicación |
|---|---|---|
| MATH | 95.1% | Prueba matemática integral que cubre múltiples áreas como álgebra, geometría, cálculo, etc. |
| AIME 2025 (sin herramientas) | 92% | American Invitational Mathematics Examination, nivel de dificultad de competición de secundaria. |
| AIME 2025 (ejecución de código) | 100% | La versión anterior Gemini 3 Pro obtuvo puntuación perfecta al habilitar la ejecución de código. |
| GPQA Diamond | 94.3% | Preguntas y respuestas científicas a nivel de posgrado, líder entre todos los modelos de su clase. |
| ARC-AGI-2 | 77.1% | Capacidad de razonamiento abstracto, duplicada respecto a la generación anterior 3 Pro. |
| MathArena Apex | Liderazgo significativo | Más de 20 veces mejor que la generación anterior. |
De los 18 benchmarks principales publicados oficialmente por Google, Gemini 3.1 Pro obtuvo el primer lugar en 12 de ellos. En razonamiento matemático, su desempeño del 95.1% en el benchmark MATH es particularmente destacado, lo que significa que posee una capacidad de resolución de problemas extremadamente fuerte en todas las subáreas matemáticas como álgebra, geometría, probabilidad y cálculo.
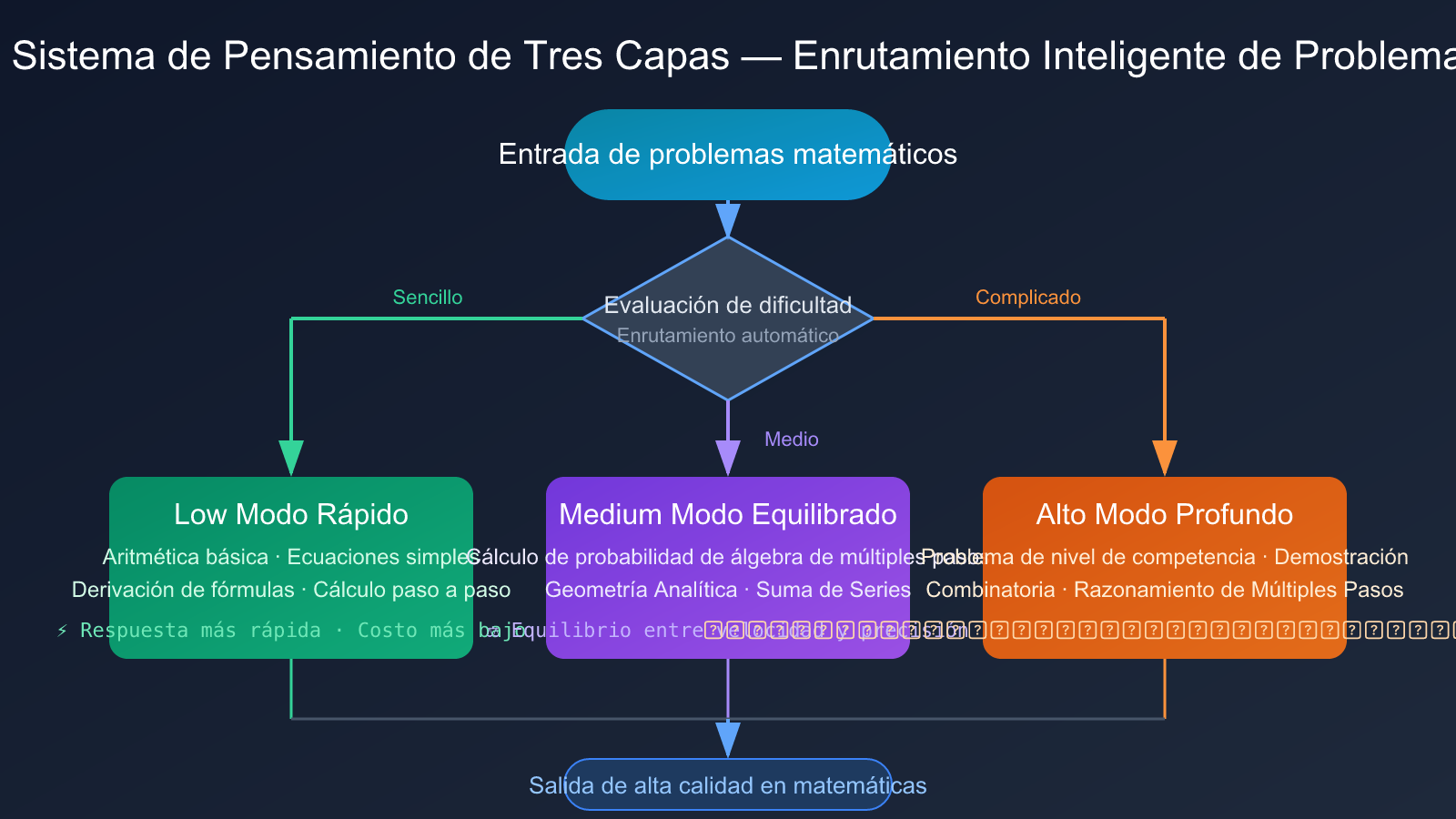
Sistema de Pensamiento de Tres Niveles de Gemini 3.1 Pro
Gemini 3.1 Pro introduce una innovación arquitectónica clave: el sistema de pensamiento de tres niveles:
- Low (Modo Rápido): Procesa cálculos matemáticos simples y derivaciones de fórmulas, con la velocidad de respuesta más rápida.
- Medium (Modo Equilibrado): Nueva capa intermedia, procesa problemas matemáticos de dificultad media, equilibrando velocidad y precisión.
- High (Modo Profundo): Procesa problemas complejos de razonamiento de múltiples pasos, como problemas matemáticos de nivel de competición.
Este sistema de tres niveles permite a los desarrolladores enrutar de manera flexible según la dificultad del problema matemático, sin tener que elegir entre «rápido pero aproximado» y «lento pero preciso». Esta ventaja arquitectónica es especialmente evidente para escenarios que procesan por lotes problemas matemáticos de diferentes dificultades (como el sistema de generación de preguntas adaptativas de una plataforma educativa).
Experiencia Práctica de Resolución Matemática con Gemini 3.1 Pro
En la resolución práctica de problemas matemáticos, el desempeño de Gemini 3.1 Pro Preview se puede resumir como «completo y estable»:
- Área de Álgebra: Operaciones con polinomios, resolución de sistemas de ecuaciones, demostración de desigualdades, etc., con casi cero errores, gracias a la alta cobertura del 95.1% en MATH.
- Área de Geometría: Cadenas de razonamiento completas en geometría analítica y geometría sólida, destacando especialmente en problemas de cálculo relacionados con coordenadas.
- Probabilidad y Estadística: Lógica de razonamiento clara en problemas de probabilidad condicional, permutaciones y combinaciones, capaz de manejar correctamente cálculos complejos por pasos.
- Cálculo: Resolución precisa de integrales definidas e indefinidas, capaz de reconocer técnicas de integración comunes y aplicarlas correctamente.
El logro de Gemini 3.1 Pro de obtener el primer lugar en 12 de los 18 benchmarks principales no es casual. Su puntuación en el Artificial Analysis Intelligence Index es de 57 puntos, empatando con GPT-5.4 (xhigh) en el primer lugar, muy por encima de la mediana de 28 puntos, lo que refleja una ventaja integral en razonamiento inteligente.
Claude Sonnet 4.6: Capacidad de Resolución de Problemas Matemáticos Explicada
Claude Sonnet 4.6 es el último modelo de gama media lanzado por Anthropic, que ha logrado un salto cualitativo en su capacidad de razonamiento matemático: pasó del 62% de su predecesor, Sonnet 4.5, al 89%, un aumento de 27 puntos porcentuales.
Puntuaciones de Evaluación de Claude Sonnet 4.6 en Matemáticas
| Evaluación de Referencia | Sonnet 4.6 | Sonnet 4.5 (Predecesor) | Magnitud de la Mejora |
|---|---|---|---|
| Matemáticas Integrales | 89% | 62% | +27 puntos porcentuales |
| ARC-AGI-2 | 58.3% | 13.6% | Mejora de 4.3 veces |
| GPQA Diamond | 74.1% | — | Razonamiento científico a nivel de posgrado |
| Capacidad de Programación | 79.6% | — | Cercano al 80.8% de Opus 4.6 |
| Análisis Financiero | 63.3% | — | El mejor de su categoría |
El salto en capacidad matemática del 62% al 89% es uno de los cambios más llamativos de Sonnet 4.6. Esto significa que ha evolucionado de ser un "modelo que ocasionalmente comete errores en problemas matemáticos" a convertirse en un "modelo capaz de manejar cálculos complejos de manera confiable".
Mecanismo de Pensamiento Adaptativo de Claude Sonnet 4.6
Otro punto destacado de Claude Sonnet 4.6 es su mecanismo de Profundidad de Pensamiento Adaptativo (Adaptive Thinking):
- Problemas simples: Respuesta rápida, sin desperdiciar recursos de razonamiento. Por ejemplo, aritmética básica, resolución de ecuaciones simples.
- Problemas de dificultad media: Extensión moderada de la cadena de pensamiento. Por ejemplo, operaciones algebraicas de múltiples pasos, cálculo de probabilidades.
- Problemas complejos: Activa automáticamente cadenas de razonamiento profundas. Por ejemplo, matemáticas combinatorias, problemas de demostración, problemas de nivel de competencia.
La ventaja de este mecanismo adaptativo en el uso práctico es que no necesitas ajustar manualmente la profundidad del razonamiento; el modelo juzga automáticamente la dificultad del problema matemático y asigna los recursos computacionales correspondientes, logrando un equilibrio óptimo entre latencia y costo.
Ventaja Única de Claude Sonnet 4.6: Claridad en el Proceso de Resolución
En escenarios de resolución de problemas matemáticos, Claude Sonnet 4.6 tiene una ventaja única ampliamente reconocida: la claridad del proceso de resolución. Múltiples evaluaciones señalan que los modelos Claude tienen el mejor desempeño en la explicación de conceptos matemáticos. Además, el Learning Mode (Modo de Aprendizaje) lanzado por Anthropic está diseñado específicamente para guiar el proceso de razonamiento del estudiante, en lugar de dar la respuesta directamente.
Esto hace que Claude Sonnet 4.6 sea especialmente adecuado para:
- Escenarios de educación y tutoría en matemáticas.
- Estudiantes que necesitan comprender los pasos de resolución.
- Investigadores que desean verificar el razonamiento de una solución.
💡 Consejo de Aprendizaje: Si tu necesidad principal es "comprender el proceso de resolución de problemas matemáticos" y no solo obtener la respuesta, Claude Sonnet 4.6 es la mejor opción. Puedes obtener créditos de prueba gratuitos a través de APIYI (apiyi.com) para experimentar el nivel de detalle de su proceso de resolución.
GPT-5.4: Capacidad de Resolución de Problemas Matemáticos Explicada
GPT-5.4 es el último modelo insignia lanzado por OpenAI el 6 de marzo de 2026. Es el primer modelo de razonamiento de OpenAI que integra capacidades profesionales de vanguardia, capacidad de programación (proveniente de GPT-5.3-Codex), operación nativa de computadora y una ventana de contexto de 1.05M en un mismo modelo predeterminado.
Puntuaciones de Evaluación de GPT-5.4 en Matemáticas
| Evaluación de Referencia | Puntuación | Explicación |
|---|---|---|
| AIME 2025 | 100% (puntuación perfecta) | Nivel de competencia matemática de secundaria, rendimiento perfecto |
| GSM8K | 99% | Problemas de matemáticas de primaria, rendimiento casi perfecto |
| MATH | 88.6% | Evaluación integral de razonamiento matemático |
| GPQA Diamond | 84.2% (estándar) / 92.8% (alto razonamiento) | Razonamiento científico a nivel de posgrado |
| ARC-AGI-2 | 73.3% (estándar) / 83.3% (Pro) | Capacidad de razonamiento abstracto |
| FrontierMath (predecesor 5.2) | 40.3% | Nuevo récord en matemáticas de vanguardia a nivel experto |
GPT-5.4 logró la sorprendente puntuación perfecta del 100% en AIME 2025, lo que significa que puede resolver perfectamente todos los problemas de alta dificultad del American Invitational Mathematics Examination. Para usuarios que necesitan resolver problemas matemáticos de nivel de competencia, este rendimiento es muy convincente.
Vale la pena señalar que la puntuación de GPT-5.4 en la evaluación MATH es del 88.6%, lo que muestra una brecha considerable en comparación con el 95.1% de Gemini 3.1 Pro. Esto indica que, aunque GPT-5.4 tiene un rendimiento perfecto en problemas de competencia de alto nivel, no es el más fuerte en pruebas integrales que cubren un amplio espectro de áreas matemáticas.
Opciones de Configuración de Razonamiento de GPT-5.4
GPT-5.4 ofrece múltiples configuraciones de razonamiento para adaptarse a diferentes problemas matemáticos:
- GPT-5.4 Estándar: Adecuado para cálculos matemáticos cotidianos y problemas de dificultad media.
- GPT-5.4 Thinking: Activa el razonamiento avanzado, adecuado para razonamientos complejos de múltiples pasos y demostraciones.
- GPT-5.4 Pro: Configuración de máximo rendimiento, ARC-AGI-2 puede alcanzar el 83.3%, adecuado para escenarios de máxima dificultad.
Sin embargo, es importante tener en cuenta que el precio de GPT-5.4 Pro es de $30.00/1M de entrada + $180.00/1M de salida, un costo muy superior al de la versión estándar. Para la mayoría de los escenarios de resolución de problemas matemáticos, la versión estándar es suficiente.
Experiencia Práctica de GPT-5.4 en Resolución de Problemas Matemáticos
El rendimiento de GPT-5.4 en problemas matemáticos de nivel de competencia es especialmente impresionante:
- Matemáticas de Competencia: Responde casi perfectamente problemas integrales de teoría de números, combinatoria y geometría de nivel AMC/AIME; la puntuación perfecta del 100% en AIME es bien merecida.
- Problemas de Demostración: Capaz de construir cadenas completas de demostración matemática, lógicamente rigurosas y con transiciones naturales entre pasos.
- Matemáticas Aplicadas: La puntuación del 99% en GSM8K indica que también es muy confiable en problemas aplicados (como cálculos de ingeniería, modelado económico).
- Razonamiento de Múltiples Pasos: Gracias a la ventana de contexto ultra larga de 1.05M, puede mantener cadenas de razonamiento completas mientras procesa problemas matemáticos extremadamente complejos de múltiples pasos.
Una ventaja única de GPT-5.4 es que su predecesor, GPT-5.2, estableció un nuevo récord del 40.3% en FrontierMath (matemáticas de vanguardia a nivel experto). Esto significa que la serie GPT también posee cierta capacidad de exploración en problemas matemáticos verdaderamente de vanguardia y no resueltos, algo que otros modelos actualmente difícilmente pueden igualar.
Interpretación de las Pruebas de Referencia para Modelos de IA de Resolución de Matemáticas
Antes de comparar los modelos de IA para resolver problemas matemáticos, es fundamental comprender el significado y el enfoque de cada prueba de referencia. Esto permite evaluar con mayor precisión las capacidades de cada modelo:
| Prueba de Referencia | Nombre Completo | Contenido de la Prueba | Nivel de Dificultad |
|---|---|---|---|
| AIME 2025 | American Invitational Mathematics Examination | Problemas reales de la competencia estadounidense, cubre teoría de números, combinatoria, geometría, etc. | Nivel de competencia de secundaria (Top 5% de estudiantes) |
| MATH | Mathematics Aptitude Test of Heuristics | Prueba integral que cubre 7 áreas principales como álgebra, geometría, cálculo, etc. | Nivel de secundaria a pregrado |
| GSM8K | Grade School Math 8K | 8000 problemas de matemáticas aplicadas de primaria a secundaria básica | Nivel básico |
| GPQA Diamond | Graduate-Level Google-Proof QA | Preguntas de razonamiento científico a nivel de posgrado, redactadas por expertos en el campo | Nivel de posgrado/doctorado |
| ARC-AGI-2 | Abstraction and Reasoning Corpus | Reconocimiento de patrones lógicos completamente nuevos, evalúa la capacidad de razonamiento abstracto | Nivel de inteligencia general |
| FrontierMath | Frontier Mathematics | Problemas matemáticos de vanguardia a nivel experto, involucran áreas no resueltas o nuevas | Nivel de experto/investigador |
Comprensión clave: AIME se enfoca más en técnicas matemáticas de nivel competitivo y pensamiento creativo, mientras que MATH se centra en la capacidad de cobertura integral en áreas amplias. Un modelo que obtiene puntuación perfecta en AIME pero no la más alta en MATH (como GPT-5.4) indica que es extremadamente fuerte en problemas ingeniosos de nivel competitivo, pero su cobertura en ciertas áreas fundamentales podría ser ligeramente inferior a la de un modelo con una puntuación MATH más alta.
Esta es la razón por la que recomendamos a Gemini 3.1 Pro Preview como la opción integral preferida: un 95.1% en MATH significa que tiene un desempeño más equilibrado en todas las subáreas de las matemáticas.
Es importante señalar que la prueba de referencia AIME 2025 actualmente tiende a saturarse: varios modelos de primera línea (combinados con ejecución de código) pueden alcanzar más del 95% o incluso la puntuación perfecta. Por lo tanto, las pruebas que realmente pueden diferenciar la verdadera capacidad matemática de un modelo son aquellas de mayor dificultad, como MathArena Apex y FrontierMath. En MathArena Apex, Gemini 3.1 Pro logró una mejora de más de 20 veces con respecto a su generación anterior, mostrando una base de razonamiento matemático intrínseco extremadamente sólida.
Otra dimensión que vale la pena considerar es ARC-AGI-2 (capacidad de razonamiento abstracto). Esta prueba evalúa la capacidad del modelo para reconocer patrones lógicos completamente nuevos, patrones que el modelo nunca ha visto durante su entrenamiento. Gemini 3.1 Pro Preview lidera con un 77.1%, lo que indica que no solo puede resolver tipos de problemas conocidos, sino que también posee una mayor capacidad de razonamiento de generalización, desempeñándose mejor frente a nuevos tipos de problemas matemáticos.
Práctica de Invocación de API para Modelos de IA de Resolución de Matemáticas
A continuación, se muestra un ejemplo de código mínimo para invocar un modelo de IA de resolución de matemáticas a través de API. Con solo 10 líneas de código puedes ejecutarlo:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1" # Interfaz unificada de APIYI
)
response = client.chat.completions.create(
model="gemini-3.1-pro-preview", # Se puede cambiar a claude-sonnet-4.6 o gpt-5.4
messages=[{"role": "user", "content": "Resolver: Dada la progresión aritmética {an} con primer término a1=2 y diferencia común d=3, encontrar la suma S20 de los primeros 20 términos"}]
)
print(response.choices[0].message.content)
Ver el código completo para invocar la resolución matemática (incluye comparación de múltiples modelos)
import openai
from typing import Optional
def solve_math(
problem: str,
model: str = "gemini-3.1-pro-preview",
system_prompt: Optional[str] = None
) -> str:
"""
Invoca un modelo de IA para resolver un problema matemático.
Args:
problem: Descripción del problema matemático.
model: Nombre del modelo, compatible con gemini-3.1-pro-preview / claude-sonnet-4.6 / gpt-5.4.
system_prompt: Indicación del sistema, puede especificar el estilo de resolución.
Returns:
Respuesta de resolución del modelo.
"""
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1" # Interfaz unificada de APIYI
)
messages = []
if system_prompt:
messages.append({"role": "system", "content": system_prompt})
else:
messages.append({
"role": "system",
"content": "Eres un experto en resolución de problemas matemáticos. Resuelve los problemas matemáticos con pasos claros, explicando la base del razonamiento en cada paso."
})
messages.append({"role": "user", "content": problem})
try:
response = client.chat.completions.create(
model=model,
messages=messages,
max_tokens=2000
)
return response.choices[0].message.content
except Exception as e:
return f"Error: {str(e)}"
# Ejemplo de uso: Comparar la respuesta de tres modelos al mismo problema.
problem = "En el triángulo ABC, se conocen a=5, b=7, C=60°. Encontrar el área del triángulo y la longitud del tercer lado c."
models = ["gemini-3.1-pro-preview", "claude-sonnet-4.6", "gpt-5.4"]
for m in models:
print(f"\n{'='*50}")
print(f"Modelo: {m}")
print(f"{'='*50}")
result = solve_math(problem, model=m)
print(result)
Recomendación: Obtén créditos de prueba gratuitos a través de APIYI apiyi.com. Con una sola clave API puedes invocar los tres modelos de resolución matemática mencionados y comparar rápidamente su desempeño en tus problemas reales.
Comparación de precios y relación costo-beneficio de modelos de IA para resolver problemas matemáticos
Al elegir un modelo de IA para resolver problemas matemáticos, el precio es un factor que no se puede ignorar. A continuación, se presenta una comparación detallada de precios de tres modelos:
| Dimensión de precio | Gemini 3.1 Pro Preview | Claude Sonnet 4.6 | GPT-5.4 |
|---|---|---|---|
| Precio de entrada | $2.00/1M tokens | $3.00/1M tokens | $2.50/1M tokens |
| Precio de salida | $12.00/1M tokens | $15.00/1M tokens | $15.00/1M tokens |
| Precio mixto (3:1) | $4.50/1M tokens | $6.00/1M tokens | $5.63/1M tokens |
| Recargo por contexto largo | >200K se duplica | Ninguno | >272K se duplica |
| Ventana de contexto | 1M tokens | Ventana estándar | 1.05M tokens |
| Salida máxima | 65,536 tokens | Salida estándar | 128,000 tokens |
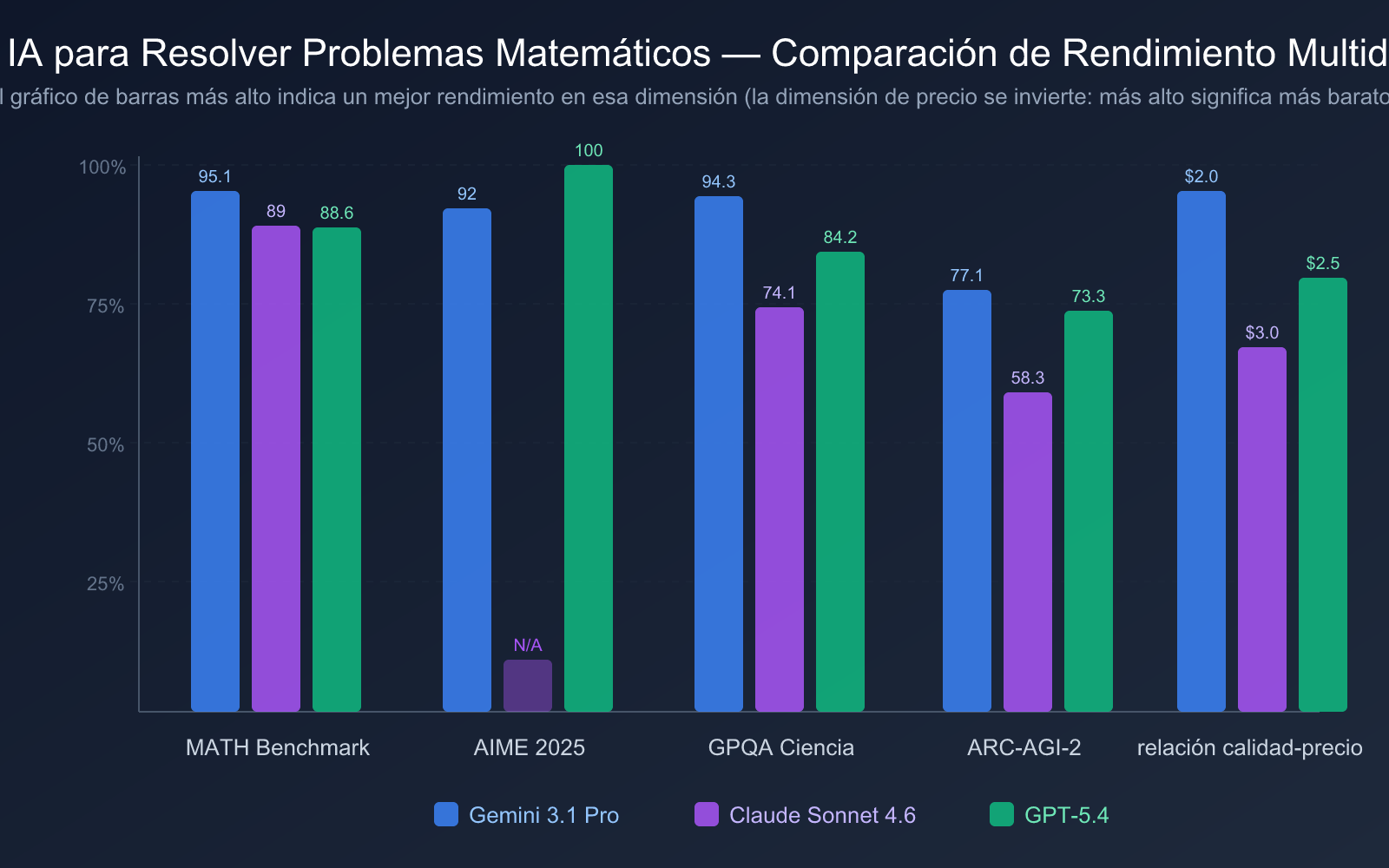
Desde la perspectiva de la relación costo-beneficio:
- Gemini 3.1 Pro Preview tiene la mejor relación costo-beneficio: precio de entrada de solo $2.00/1M tokens, y un puntaje líder del 95.1% en la referencia MATH. Según el análisis de Artificial Analysis, su costo operativo es aproximadamente 1/7.5 del de Claude Opus 4.6, pero iguala o supera las referencias de matemáticas y programación.
- Claude Sonnet 4.6 tiene un precio moderado: la tarificación de $3.00/$15.00 es igual a la de la generación anterior Sonnet 4.5, pero la capacidad matemática mejoró 27 puntos porcentuales, mejorando significativamente la relación costo-beneficio.
- GPT-5.4 Standard tiene un precio razonable: la tarificación de $2.50/$15.00 está dentro de un rango razonable, pero si se usa GPT-5.4 Pro ($30/$180), el costo aumentará significativamente.
💰 Recomendación de costos: Para necesidades diarias de resolución de problemas matemáticos, se recomienda usar Gemini 3.1 Pro Preview para obtener la mejor relación costo-beneficio. Si se necesita optimizar aún más los costos, se puede considerar usar una plataforma de agregación de API para obtener planes de recarga más flexibles.
Estimación práctica del costo de resolución de problemas matemáticos
Para ayudarte a comprender de manera más intuitiva la diferencia de costos, aquí tienes una estimación de costos para un escenario típico de resolución de problemas matemáticos:
Supuesto del escenario: Resolver 100 problemas matemáticos de dificultad media por día, cada problema consume en promedio 500 tokens de entrada + 1500 tokens de salida.
| Modelo | Costo diario entrada | Costo diario salida | Costo diario total | Costo mensual (30 días) |
|---|---|---|---|---|
| Gemini 3.1 Pro | $0.10 | $1.80 | $1.90 | $57.00 |
| GPT-5.4 | $0.13 | $2.25 | $2.38 | $71.25 |
| Claude Sonnet 4.6 | $0.15 | $2.25 | $2.40 | $72.00 |
| GPT-5.4 Pro | $1.50 | $27.00 | $28.50 | $855.00 |
| DeepSeek R2 | $0.03 | $0.33 | $0.36 | $10.80 |
De la estimación de costos se puede ver claramente:
- El costo mensual de Gemini 3.1 Pro Preview es de aproximadamente $57, siendo el más económico entre los tres modelos principales.
- Los costos de Claude Sonnet 4.6 y GPT-5.4 Standard son similares, alrededor de $71-72/mes.
- El costo de GPT-5.4 Pro es de hasta $855/mes, adecuado solo para escenarios con presupuesto generoso que requieran una precisión extrema.
- DeepSeek R2 ofrece una solución altamente competitiva con un costo ultra bajo de $10.80/mes.
Comparación del Índice de Inteligencia Integral para Modelos de IA de Resolución Matemática
Además de las pruebas de referencia individuales, el índice de inteligencia integral puede reflejar de manera más completa el potencial de razonamiento matemático de los modelos. El Artificial Analysis Intelligence Index es actualmente uno de los sistemas de evaluación integral más autorizados, calculando la puntuación integral del modelo basándose en cuatro dimensiones: razonamiento, conocimiento, matemáticas y programación.
| Modelo | Índice de Inteligencia Integral | AIME 2025 | MATH | GPQA Diamond | ARC-AGI-2 | Evaluación Integral |
|---|---|---|---|---|---|---|
| GPT-5.4 (xhigh) | 57 | 100% | 88.6% | 84.2% | 73.3% | Campeón en problemas de competición, índice integral empatado en primer lugar |
| Gemini 3.1 Pro Preview | 57 | 92% | 95.1% | 94.3% | 77.1% | Índice integral empatado en primer lugar, cobertura matemática más completa |
| Claude Opus 4.6 | 53 | — | — | 91.3% | — | Capacidad de razonamiento científico y explicación de primer nivel |
| Claude Sonnet 4.6 (max) | 52 | — | 89% | 74.1% | 58.3% | Excelente relación calidad-precio, proceso de resolución más claro |
Desde la perspectiva del índice de inteligencia integral, GPT-5.4 (xhigh) y Gemini 3.1 Pro Preview están empatados en primer lugar con 57 puntos, pero cada uno tiene un enfoque diferente:
- GPT-5.4: Rendimiento perfecto (100%) en problemas de competición como AIME, pero puntuación ligeramente inferior en la referencia integral MATH (88.6%).
- Gemini 3.1 Pro: Rendimiento más equilibrado en la referencia integral MATH (95.1%) y en el razonamiento científico GPQA Diamond (94.3%).
Esto significa que si tus necesidades matemáticas se inclinan hacia competiciones y problemas extremadamente difíciles, GPT-5.4 es superior; si necesitas un rendimiento estable que cubra un amplio espectro de áreas matemáticas, Gemini 3.1 Pro Preview es la opción más segura.
Recomendaciones por Escenario para Modelos de IA de Resolución Matemática
Diferentes escenarios de aplicación matemática tienen diferentes requisitos para los modelos. A continuación, se presentan recomendaciones basadas en escenarios de uso real:
Escenarios matemáticos para elegir Gemini 3.1 Pro Preview
- Plataforma integral de tutoría matemática: Cubre todas las áreas (álgebra, geometría, cálculo, etc.), con la mayor capacidad integral (MATH 95.1%).
- Procesamiento de grandes volúmenes de problemas matemáticos: Precio más bajo, su sistema de pensamiento de tres niveles se adapta automáticamente a la dificultad del problema, reduciendo costes.
- Escenarios que combinan cálculo científico: Capacidad de razonamiento científico del 94.3% en GPQA Diamond, ideal para problemas que cruzan física, química y matemáticas.
- Problemas matemáticos con visualización: La capacidad multimodal de Gemini ofrece ventajas al procesar problemas matemáticos que incluyen diagramas y figuras geométricas.
Escenarios matemáticos para elegir Claude Sonnet 4.6
- Educación y tutoría matemática: Proceso de resolución más claro, su "Learning Mode" guía específicamente el razonamiento del estudiante, no da la respuesta directamente sino que guía el pensamiento.
- Aprendizaje de pasos de resolución: Escenarios donde se necesita entender "por qué hacerlo así". La capacidad explicativa de Claude es reconocida como la mejor. El 70% de los usuarios prefieren Sonnet 4.6 sobre la versión anterior 4.5, lo que indica una mejora cualitativa en la experiencia de usuario.
- Asistencia en investigación matemática: Ideal para investigadores que necesitan procesos de derivación detallados para verificar ideas. Su profundidad de pensamiento adaptativa coincide automáticamente con la complejidad del problema.
- Cálculos de oficina y finanzas: Mejor de su clase en análisis financiero (63.3%), productividad en oficina GDPval-AA con 1633 Elo, superando incluso al más costoso Opus 4.6.
- Combinación de programación + matemáticas: Capacidad de programación del 79.6%, cercana a Opus 4.6, ideal para desarrolladores que necesitan escribir programas de cálculo matemático.
Escenarios matemáticos para elegir GPT-5.4
- Competiciones matemáticas de alta dificultad: Puntuación perfecta en AIME (100%), modelo preferido para problemas matemáticos de nivel competitivo.
- Razonamiento matemático en documentos largos: Ventana de contexto de 1.05M tokens, ideal para manejar problemas complejos que requieren mucha información de fondo matemático.
- Investigación matemática profesional: La versión anterior GPT-5.2 estableció un nuevo récord del 40.3% en FrontierMath, con gran capacidad en matemáticas avanzadas de nivel experto.
- Banca de inversión y finanzas cuantitativas: Alta puntuación del 87.3% en tareas de modelado bancario, adecuado para escenarios de matemáticas financieras de alto nivel.
Estrategia de uso mixto: La mejor combinación de modelos para resolver matemáticas
En entornos de producción reales, muchos equipos adoptan estrategias de uso mixto para obtener los mejores resultados:
Estrategia 1: Enrutamiento por nivel de dificultad
- Problemas básicos (aritmética, ecuaciones simples) → Modo "Low" de Gemini 3.1 Pro, coste más bajo.
- Problemas de dificultad media (razonamiento de múltiples pasos, problemas aplicados) → Modo adaptativo de Claude Sonnet 4.6, proceso de resolución claro.
- Problemas de alta dificultad (competición, demostraciones) → Modo "Thinking" de GPT-5.4, mayor precisión.
Estrategia 2: Validación cruzada
- Primero resolver rápidamente con Gemini 3.1 Pro (bajo coste, alta velocidad).
- Validar resultados clave con GPT-5.4 (alta precisión).
- Reformular para el usuario con Claude Sonnet 4.6 cuando se necesite explicación (expresión clara).
🚀 Recomendación de implementación: Las estrategias de uso mixto anteriores se pueden implementar fácilmente a través de la plataforma APIYI (apiyi.com). Con una sola clave API puedes invocar todos los modelos, solo necesitas cambiar el parámetro
modelen el código.
Recomendaciones de decisión para modelos de IA de resolución de problemas matemáticos
Basándonos en el análisis anterior, aquí tienes las recomendaciones para diferentes grupos de usuarios:
| Tipo de Usuario | Modelo Recomendado | Razón Principal |
|---|---|---|
| Estudiantes / Autodidactas | Claude Sonnet 4.6 | Proceso de resolución claro, modo "Learning" que guía el pensamiento |
| Desarrolladores de Plataformas Educativas | Gemini 3.1 Pro Preview | Capacidades más completas, precio más bajo, tres niveles de razonamiento adaptados a la dificultad |
| Concursantes / Entrenadores | GPT-5.4 | Puntuación perfecta en AIME, capacidad de resolución de problemas de nivel competitivo más fuerte |
| Investigadores | Gemini 3.1 Pro Preview | 94.3% en GPQA Diamond, liderazgo en capacidades interdisciplinarias ciencia + matemáticas |
| Procesamiento por Lotes Empresarial | Gemini 3.1 Pro Preview | Mejor relación costo-beneficio, precio de entrada de $2.00 por 1M tokens |
| Equipos de Cuantificación Financiera | GPT-5.4 | 87.3% en modelado de banca de inversión, más fuerte en escenarios de matemáticas financieras |
💡 Consejo de selección: La elección del modelo de IA para resolver problemas matemáticos depende principalmente de tu escenario de aplicación específico. Si no estás seguro de cuál es el más adecuado, te sugerimos probar los tres modelos con el mismo problema matemático a través de la plataforma APIYI apiyi.com, y tomar la decisión final basándote en la calidad de la solución y la velocidad de respuesta. La plataforma soporta una interfaz unificada para llamadas, facilitando la comparación rápida y el cambio.
Otros modelos de IA para resolución de problemas matemáticos que vale la pena considerar
Además de los tres modelos principales mencionados anteriormente, hay otros modelos de IA para problemas matemáticos que son dignos de mención en escenarios específicos:
| Nombre del Modelo | AIME 2025 | Ventaja Principal | Precio API (Entrada/Salida) | Escenario Adecuado |
|---|---|---|---|---|
| DeepSeek R2 | Supera a Gemini 3.1 Pro | Relación costo-beneficio extrema | $0.55/$2.19 por 1M | Procesamiento por lotes de matemáticas sensible al presupuesto |
| Claude Opus 4.6 | — | 91.3% en GPQA, explicaciones más profundas | $15/$75 por 1M | Investigación de alto nivel y razonamiento profundo |
| Qwen3-235B | 89.2% | El más fuerte de código abierto | Costo de despliegue propio | Escenarios que requieren despliegue privado |
| DeepSeek R1 | Aprox. 87.5% | Referencia de código abierto, 671B MoE | Costo de despliegue propio | Investigación comunitaria y desarrollo secundario de código abierto |
| MiMo-V2-Flash | 94.1% | Costo de inferencia solo 2.5% del de Claude | Muy bajo | Inferencia a gran escala y bajo costo |
Uno que merece especial atención es DeepSeek R2, que superó a Gemini 3.1 Pro Preview en AIME, con un precio aproximadamente 1/4 del de este último. Si tu escenario de resolución de problemas matemáticos es extremadamente sensible al presupuesto, DeepSeek R2 es una opción muy competitiva.
Por otro lado, MiMo-V2-Flash alcanzó un alto puntaje del 94.1% en AIME 2025, pero su costo de inferencia es solo el 2.5% del de Claude, lo que lo hace ideal para plataformas EdTech que necesitan procesar grandes volúmenes de problemas matemáticos.
Técnicas para optimizar indicaciones en modelos de IA de resolución matemática
Independientemente del modelo que elijas, una buena indicación puede mejorar significativamente la calidad de la solución. Aquí hay técnicas de indicación validadas:
- Especificar el tipo de problema: En la indicación, anota "Este es un problema de matemáticas combinatorias" o "Este es un problema de geometría analítica" para ayudar al modelo a aplicar la estrategia correcta.
- Solicitar solución paso a paso: Agrega "Por favor, deriva paso a paso, indicando el teorema o fórmula usado en cada paso" para mejorar la legibilidad del proceso.
- Especificar el formato de salida: Por ejemplo, "Usa formato LaTeX para las fórmulas matemáticas" o "Enmarca la respuesta final en un cuadro".
- Proporcionar restricciones de contexto: Como "Supón que x es un entero positivo" o "Resuelve dentro del conjunto de los números reales", para evitar que el modelo genere discusiones de casos innecesarias.
- Validación cruzada con múltiples modelos: Para resultados clave, usa diferentes modelos para verificar la consistencia de la respuesta y aumentar la confianza.
Preguntas frecuentes
P1: ¿Son confiables los resultados de las pruebas comparativas de los modelos de IA para resolver problemas matemáticos?
Las pruebas comparativas proporcionan una base estandarizada para comparaciones horizontales, pero la efectividad real también se ve afectada por factores como el tipo de problema y la calidad de la indicación. AIME y MATH son actualmente los puntos de referencia más autorizados para el razonamiento matemático, ampliamente reconocidos por la academia y la industria. Se recomienda que, además de consultar los datos de referencia, pruebes con tus propios problemas reales para verificar el rendimiento.
P2: Soy estudiante, ¿qué modelo de IA para resolver problemas matemáticos debería elegir?
Se recomienda elegir primero Claude Sonnet 4.6. Su proceso de resolución es el más claro, con una explicación explícita del razonamiento en cada paso, lo que lo hace ideal para aprender y comprender el pensamiento matemático. La función "Learning Mode" de Anthropic puede guiarte para que pienses por ti mismo, en lugar de dar la respuesta directamente. Si te encuentras con problemas de competencia particularmente difíciles, puedes cambiar a GPT-5.4 para buscar ayuda.
P3: ¿Cómo puedo empezar a probar rápidamente estos modelos de IA para resolver problemas matemáticos?
Se recomienda utilizar una plataforma de agregación de API que admita una interfaz unificada para múltiples modelos:
- Visita APIYI (apiyi.com) y regístrate para obtener una cuenta.
- Obtén tu clave API y el crédito gratuito de prueba.
- Utiliza el ejemplo de código Python proporcionado en este artículo, modificando el parámetro
modelpara cambiar entre los diferentes modelos. - Prueba los tres modelos con el mismo problema matemático y compara la calidad de la solución y la velocidad de respuesta.
P4: ¿Estos modelos de IA para resolver problemas matemáticos admiten la salida de fórmulas en LaTeX?
Los tres modelos admiten la salida de fórmulas matemáticas en formato LaTeX. Simplemente agrega "Por favor, genera todas las fórmulas matemáticas en formato LaTeX" a la indicación. Gemini 3.1 Pro y GPT-5.4 tienen un formato LaTeX más estandarizado, mientras que Claude Sonnet 4.6 ofrece explicaciones textuales más detalladas entre las fórmulas. Para escenarios donde necesites copiar fórmulas directamente a un artículo, se recomienda usar Gemini o GPT.
P5: ¿Pueden los modelos de IA para resolver problemas matemáticos procesar problemas que están en una imagen?
Gemini 3.1 Pro Preview y GPT-5.4 admiten entrada multimodal, lo que significa que puedes subir directamente una imagen que contenga un problema matemático para obtener la solución. Gemini se destaca especialmente en el procesamiento de imágenes que contienen figuras geométricas y fórmulas escritas a mano. Claude Sonnet 4.6 también admite entrada de imágenes, pero su reconocimiento de figuras geométricas complejas es ligeramente inferior al de Gemini. Si tus problemas matemáticos suelen estar en forma de imagen (por ejemplo, al buscar una solución fotografiando un problema), Gemini 3.1 Pro Preview es la mejor opción.
Conclusión
Puntos clave para elegir un modelo de IA para resolver problemas matemáticos:
- Capacidad integral: Gemini 3.1 Pro Preview: Liderazgo integral con un 95.1% en MATH, precio óptimo de $2.00/1M tokens, y un sistema de pensamiento de tres niveles que se adapta flexiblemente a diferentes dificultades.
- Aprendizaje y comprensión: Claude Sonnet 4.6: Un salto de 27 puntos porcentuales en habilidad matemática hasta el 89%, pasos de solución claros, y una profundidad de pensamiento adaptativa que equilibra costo y calidad.
- Problemas de competencia: GPT-5.4: Puntuación perfecta del 100% en AIME 2025, contexto ultra-largo de 1.05M, y una capacidad de razonamiento de alta dificultad sin igual.
Ningún modelo es la solución óptima en todos los escenarios matemáticos. El panorama competitivo de los modelos de IA para resolver problemas matemáticos en 2026 se puede resumir así:
- Cobertura integral: Gemini 3.1 Pro Preview ocupa la primera posición general con un 95.1% en MATH y el precio más bajo.
- Educación y aprendizaje: Claude Sonnet 4.6, con su salto matemático de 27 puntos porcentuales y su capacidad de explicación inigualable, es la mejor opción para escenarios educativos.
- Competencias extremas: GPT-5.4, con su absoluta destreza evidenciada por la puntuación perfecta en AIME, es insuperable en el campo de las competencias matemáticas de alta dificultad.
- Prioridad presupuestaria: DeepSeek R2 ofrece una capacidad de razonamiento matemático comparable a un precio inferior a 1/4 del de Gemini.
La estrategia más inteligente es elegir el modelo adecuado según tus necesidades reales, o incluso utilizar varios modelos de forma mixta para problemas de diferente dificultad, aprovechando al máximo las ventajas únicas de cada uno.
Se recomienda probar y comparar rápidamente estos modelos a través de APIYI (apiyi.com). La plataforma ofrece crédito gratuito y una interfaz API unificada; con una sola integración puedes invocar de manera flexible todos los modelos principales de razonamiento matemático, facilitando la implementación de una estrategia de uso mixto de múltiples modelos.
📚 Referencias
-
Hoja de especificaciones del modelo Google DeepMind Gemini 3.1 Pro: Datos de referencia oficiales y detalles técnicos
- Enlace:
deepmind.google/models/model-cards/gemini-3-1-pro/ - Descripción: Contiene los resultados completos de las pruebas de referencia y explicaciones de la arquitectura.
- Enlace:
-
Notas de lanzamiento de Anthropic Claude Sonnet 4.6: Detalles sobre la mejora de las capacidades de razonamiento matemático
- Enlace:
docs.anthropic.com - Descripción: Incluye datos comparativos de Sonnet 4.6 con su predecesor y una explicación del mecanismo de pensamiento adaptativo.
- Enlace:
-
Anuncio de lanzamiento de OpenAI GPT-5.4: Funciones del modelo más reciente y datos de referencia
- Enlace:
openai.com/index/introducing-gpt-5-4/ - Descripción: Contiene los resultados completos de las pruebas de referencia de GPT-5.4 y una explicación de su configuración de razonamiento.
- Enlace:
-
Evaluación de modelos de Artificial Analysis: Plataforma de comparación de referencia independiente de terceros
- Enlace:
artificialanalysis.ai/evaluations/aime-2025 - Descripción: Proporciona clasificaciones y análisis independientes para pruebas de referencia como AIME 2025.
- Enlace:
-
Clasificación de referencia AIME 2025: Comparación autoritativa de capacidades de razonamiento matemático
- Enlace:
vals.ai/benchmarks/aime - Descripción: Datos de clasificación de referencia de IA de razonamiento matemático actualizados continuamente.
- Enlace:
Autor: Equipo técnico de APIYI
Intercambio técnico: Comparte tu experiencia usando IA para resolver problemas matemáticos en los comentarios. Para más tutoriales sobre invocación de modelos, visita el centro de documentación de APIYI en docs.apiyi.com.