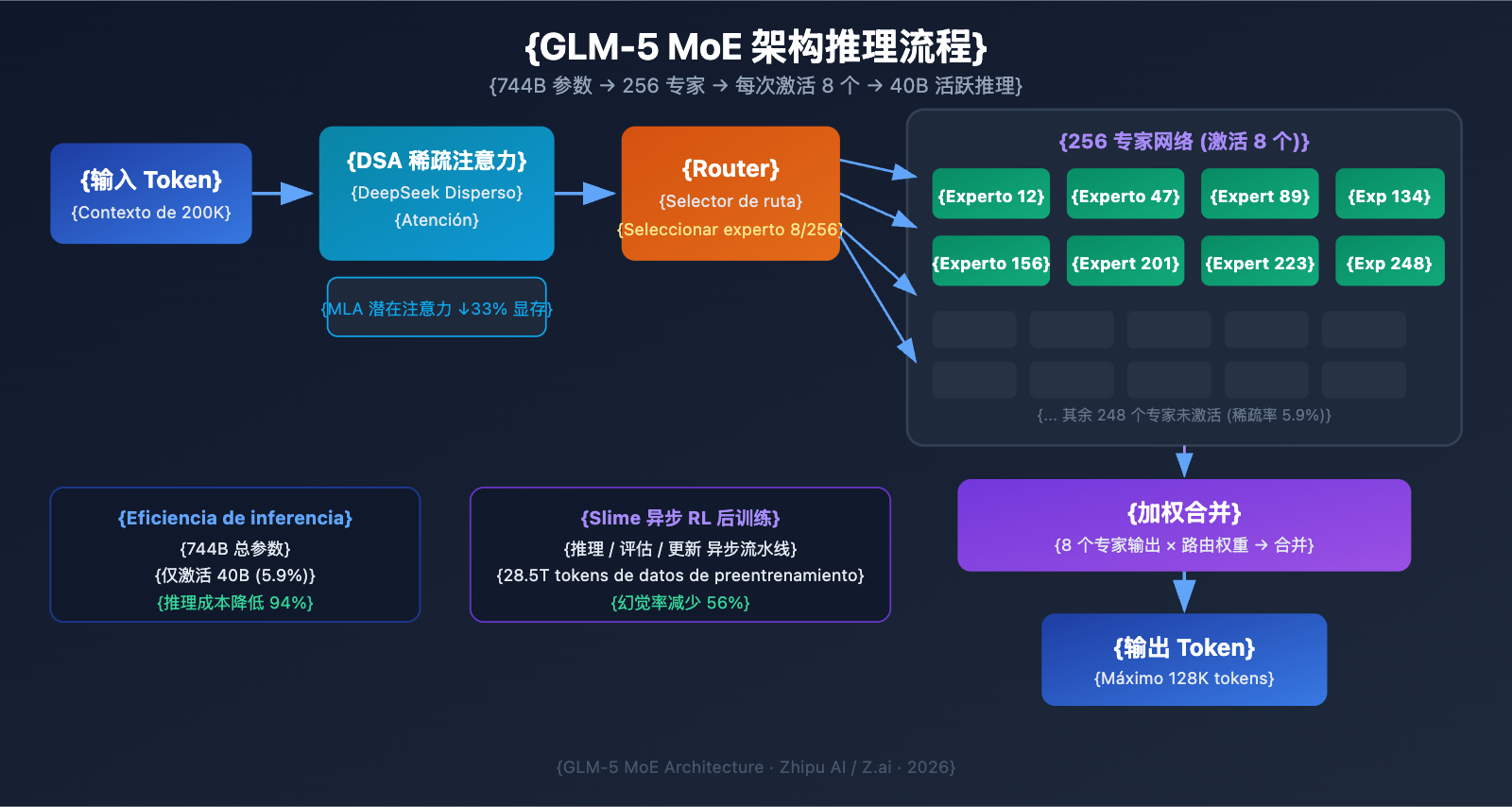
智谱AI在 2026 年 2 月 11 日正式发布了 GLM-5,这是目前参数规模最大的开源大语言模型之一。GLM-5 采用 744B MoE 混合专家架构,每次推理激活 40B 参数,在推理、编码和 Agent 任务上达到了开源模型的最佳水平。
核心价值: 读完本文,你将掌握 GLM-5 的技术架构原理、API 调用方法、Thinking 推理模式配置,以及如何在实际项目中发挥这个 744B 开源旗舰模型的最大价值。

GLM-5 核心参数一览
在深入技术细节之前,先看一下 GLM-5 的关键参数:
| 参数 | 数值 | 说明 |
|---|---|---|
| 总参数量 | 744B (7440 亿) | 当前最大开源模型之一 |
| 活跃参数 | 40B (400 亿) | 每次推理实际使用 |
| 架构类型 | MoE 混合专家 | 256 专家,每 token 激活 8 个 |
| 上下文窗口 | 200,000 tokens | 支持超长文档处理 |
| 最大输出 | 128,000 tokens | 满足长文本生成需求 |
| 预训练数据 | 28.5T tokens | 较上代增加 24% |
| 许可证 | Apache-2.0 | 完全开源,支持商业使用 |
| 训练硬件 | 华为昇腾芯片 | 全国产算力,不依赖海外硬件 |
GLM-5 的一个显著特点是它完全基于华为昇腾芯片和 MindSpore 框架训练,实现了对国产算力栈的完整验证。这对于国内开发者来说,意味着技术栈的自主可控又多了一个强有力的选择。
GLM 系列版本演进
GLM-5 是智谱AI GLM 系列的第五代产品,每一代都有显著的能力跃升:
| 版本 | 发布时间 | 参数规模 | 核心突破 |
|---|---|---|---|
| GLM-4 | 2024-01 | 未公开 | 多模态基础能力 |
| GLM-4.5 | 2025-03 | 355B (32B 活跃) | MoE 架构首次引入 |
| GLM-4.5-X | 2025-06 | 同上 | 强化推理,旗舰定位 |
| GLM-4.7 | 2025-10 | 未公开 | Thinking 推理模式 |
| GLM-4.7-FlashX | 2025-12 | 未公开 | 超低成本快速推理 |
| GLM-5 | 2026-02 | 744B (40B 活跃) | Agent 能力突破,幻觉率降 56% |
从 GLM-4.5 的 355B 到 GLM-5 的 744B,总参数量翻了一倍多;活跃参数从 32B 提升到 40B,增幅 25%;预训练数据从 23T 增加到 28.5T tokens。这些数字背后是智谱AI在算力、数据和算法三个维度上的全面投入。
🚀 快速体验: GLM-5 已上线 APIYI apiyi.com,价格与官网一致,充值加赠活动下来大约可以享受 8 折优惠,适合想要快速体验这款 744B 旗舰模型的开发者。
Análisis técnico de la arquitectura MoE de GLM-5
Por qué GLM-5 elige la arquitectura MoE
MoE (Mixture of Experts o Mezcla de Expertos) es actualmente la ruta tecnológica predominante para escalar los Modelos de Lenguaje Grande. A diferencia de la arquitectura Dense (donde todos los parámetros participan en cada inferencia), la arquitectura MoE solo activa una pequeña fracción de las redes de expertos para procesar cada token. Esto permite mantener la enorme capacidad de conocimiento del modelo mientras se reducen drásticamente los costes de inferencia.
El diseño de la arquitectura MoE de GLM-5 cuenta con las siguientes características clave:
| Característica de la arquitectura | Implementación en GLM-5 | Valor técnico |
|---|---|---|
| Total de expertos | 256 | Capacidad de conocimiento inmensa |
| Activación por token | 8 expertos | Alta eficiencia de inferencia |
| Tasa de dispersión | 5,9% | Solo utiliza una pequeña parte de los parámetros |
| Mecanismo de atención | DSA + MLA | Reduce los costes de despliegue |
| Optimización de memoria | MLA reduce un 33% | Menor ocupación de memoria de vídeo (VRAM) |
En pocas palabras, aunque GLM-5 tiene 744B de parámetros, solo activa 40B (aprox. 5,9%) en cada inferencia. Esto significa que su coste de inferencia es mucho menor que el de un modelo Dense de tamaño equivalente, permitiéndole al mismo tiempo aprovechar el vasto conocimiento contenido en sus 744B de parámetros.
DeepSeek Sparse Attention (DSA) en GLM-5
GLM-5 integra el mecanismo DeepSeek Sparse Attention, una tecnología que mantiene la capacidad de manejar contextos largos mientras reduce significativamente los costes de despliegue. Junto con Multi-head Latent Attention (MLA), GLM-5 puede funcionar de manera eficiente incluso con una ventana de contexto ultra larga de 200K tokens.
Específicamente:
- DSA (DeepSeek Sparse Attention): Reduce la complejidad de los cálculos de atención mediante patrones de atención dispersos. Mientras que el mecanismo de atención total tradicional requiere una computación inmensa para procesar 200K tokens, el DSA reduce el gasto computacional centrándose selectivamente en posiciones clave de los tokens, manteniendo la integridad de la información.
- MLA (Multi-head Latent Attention): Comprime la caché KV de los cabezales de atención en un espacio latente, reduciendo la ocupación de memoria en aproximadamente un 33%. En escenarios de contexto largo, la caché KV suele ser el principal consumidor de VRAM; el MLA alivia eficazmente este cuello de botella.
La combinación de estas dos tecnologías significa que: incluso un modelo de escala 744B, tras una cuantización FP8, puede ejecutarse en 8 GPUs, reduciendo drásticamente la barrera de entrada para su despliegue.
Post-entrenamiento de GLM-5: Sistema RL asíncrono Slime
GLM-5 utiliza una nueva infraestructura de aprendizaje por refuerzo (RL) asíncrono llamada "slime" para su post-entrenamiento. El entrenamiento RL tradicional presenta cuellos de botella en la eficiencia: existen largos tiempos de espera entre los pasos de generación, evaluación y actualización. Slime asincroniza estos pasos, permitiendo iteraciones de post-entrenamiento más granulares y aumentando considerablemente el rendimiento del entrenamiento.
En el flujo de entrenamiento RL convencional, el modelo debe completar un lote de inferencias, esperar los resultados de la evaluación y luego actualizar los parámetros; los tres pasos se ejecutan en serie. Slime desacopla estos tres pasos en tuberías (pipelines) asíncronas independientes, permitiendo que la inferencia, la evaluación y la actualización se realicen en paralelo, mejorando así significativamente la eficiencia del entrenamiento.
Esta mejora tecnológica se refleja directamente en la tasa de alucinaciones de GLM-5, que se ha reducido en un 56% en comparación con la generación anterior. Unas iteraciones de post-entrenamiento más completas permiten que el modelo mejore notablemente su precisión fáctica.
Comparativa entre GLM-5 y la arquitectura Dense
Para entender mejor las ventajas de la arquitectura MoE, podemos comparar GLM-5 con un hipotético modelo Dense de la misma escala:
| Dimensión de comparación | GLM-5 (744B MoE) | Hipotético 744B Dense | Diferencia real |
|---|---|---|---|
| Parámetros por inferencia | 40B (5,9%) | 744B (100%) | MoE reduce un 94% |
| VRAM necesaria para inferencia | 8x GPU (FP8) | Aprox. 96x GPU | MoE es significativamente menor |
| Velocidad de inferencia | Rápida | Extremadamente lenta | MoE es más apto para despliegue real |
| Capacidad de conocimiento | Conocimiento total de 744B | Conocimiento total de 744B | Equivalente |
| Especialización | Diferentes expertos para diferentes tareas | Procesamiento uniforme | MoE es más refinado |
| Coste de entrenamiento | Alto pero controlable | Extremadamente alto | MoE ofrece mejor relación calidad-precio |
La ventaja principal de la arquitectura MoE es que ofrece la capacidad de conocimiento de 744B parámetros con la alta eficiencia de un coste de inferencia de solo 40B parámetros. Por esta razón, GLM-5 puede ofrecer un rendimiento de vanguardia a un precio muy inferior al de los modelos de código cerrado de nivel similar.
Guía rápida de la API de GLM-5
Detalles de los parámetros de solicitud de la API de GLM-5
Antes de escribir código, echemos un vistazo a la configuración de los parámetros de la API de GLM-5:
| Parámetro | Tipo | Requerido | Valor por defecto | Descripción |
|---|---|---|---|---|
model |
string | ✅ | – | Fijo en "glm-5" |
messages |
array | ✅ | – | Mensajes en formato chat estándar |
max_tokens |
int | ❌ | 4096 | Número máximo de tokens de salida (límite de 128K) |
temperature |
float | ❌ | 1.0 | Temperatura de muestreo, cuanto más baja, más determinista |
top_p |
float | ❌ | 1.0 | Parámetro de muestreo de núcleo |
stream |
bool | ❌ | false | Si se usa salida en streaming |
thinking |
object | ❌ | disabled | {"type": "enabled"} activa el razonamiento |
tools |
array | ❌ | – | Definición de herramientas para Function Calling |
tool_choice |
string | ❌ | auto | Estrategia de selección de herramientas |
Ejemplo de llamada minimalista a GLM-5
GLM-5 es compatible con el formato de la interfaz del SDK de OpenAI, por lo que solo necesitas cambiar los parámetros base_url y model para conectarte rápidamente:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Interfaz unificada de APIYI
)
response = client.chat.completions.create(
model="glm-5",
messages=[
{"role": "system", "content": "Eres un experto sénior en tecnología de IA"},
{"role": "user", "content": "Explica el funcionamiento y las ventajas de la arquitectura de Mezcla de Expertos (MoE)"}
],
temperature=0.7,
max_tokens=4096
)
print(response.choices[0].message.content)
Este código es la forma más básica de llamar a GLM-5. El ID del modelo es glm-5, y la interfaz es totalmente compatible con el formato chat.completions de OpenAI. Migrar proyectos existentes es tan sencillo como cambiar dos parámetros.
Modo de razonamiento (Thinking) de GLM-5
GLM-5 admite el modo de razonamiento Thinking, similar a la capacidad de pensamiento extendido de DeepSeek R1 y Claude. Al activarlo, el modelo realiza un razonamiento interno en cadena antes de responder, lo que mejora significativamente el rendimiento en problemas matemáticos, lógicos y de programación complejos:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Interfaz unificada de APIYI
)
response = client.chat.completions.create(
model="glm-5",
messages=[
{"role": "user", "content": "Demuestra que: para todo entero positivo n, n^3 - n es divisible por 6"}
],
extra_body={
"thinking": {"type": "enabled"}
},
temperature=1.0 # Se recomienda usar 1.0 para el modo Thinking
)
print(response.choices[0].message.content)
Sugerencias de uso para el modo Thinking de GLM-5:
| Escenario | ¿Activar Thinking? | Sugerencia de temperature | Descripción |
|---|---|---|---|
| Pruebas matemáticas/Problemas de competición | ✅ Sí | 1.0 | Requiere razonamiento profundo |
| Depuración de código/Diseño de arquitectura | ✅ Sí | 1.0 | Requiere análisis sistemático |
| Razonamiento lógico/Análisis | ✅ Sí | 1.0 | Requiere pensamiento en cadena |
| Conversación diaria/Escritura | ❌ No | 0.5-0.7 | No requiere razonamiento complejo |
| Extracción de información/Resumen | ❌ No | 0.3-0.5 | Busca una salida estable |
| Generación de contenido creativo | ❌ No | 0.8-1.0 | Requiere diversidad |
Salida en streaming de GLM-5
Para escenarios que requieren interacción en tiempo real, GLM-5 admite la salida en streaming, permitiendo que los usuarios vean los resultados gradualmente a medida que el modelo los genera:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
stream = client.chat.completions.create(
model="glm-5",
messages=[
{"role": "user", "content": "Implementa un cliente HTTP con caché usando Python"}
],
stream=True,
temperature=0.6
)
for chunk in stream:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
Function Calling y construcción de Agents con GLM-5
GLM-5 ofrece soporte nativo para Function Calling, que es la capacidad central para construir sistemas de Agents. GLM-5 obtuvo una puntuación del 50.4% en HLE w/ Tools, superando a Claude Opus (43.4%), lo que demuestra su excelente desempeño en la llamada a herramientas y la orquestación de tareas:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
tools = [
{
"type": "function",
"function": {
"name": "search_documents",
"description": "Busca documentos relevantes en la base de conocimientos",
"parameters": {
"type": "object",
"properties": {
"query": {"type": "string", "description": "Palabras clave de búsqueda"},
"top_k": {"type": "integer", "description": "Cantidad de resultados devueltos", "default": 5}
},
"required": ["query"]
}
}
},
{
"type": "function",
"function": {
"name": "execute_code",
"description": "Ejecuta código Python en un entorno sandbox",
"parameters": {
"type": "object",
"properties": {
"code": {"type": "string", "description": "Código Python a ejecutar"},
"timeout": {"type": "integer", "description": "Tiempo de espera (segundos)", "default": 30}
},
"required": ["code"]
}
}
}
]
response = client.chat.completions.create(
model="glm-5",
messages=[
{"role": "system", "content": "Eres un asistente de IA capaz de buscar documentos y ejecutar código"},
{"role": "user", "content": "Búscame los parámetros técnicos de GLM-5 y luego dibuja un gráfico comparativo de rendimiento con código"}
],
tools=tools,
tool_choice="auto"
)
# Procesar la llamada a la herramienta
message = response.choices[0].message
if message.tool_calls:
for tool_call in message.tool_calls:
print(f"Llamando a la herramienta: {tool_call.function.name}")
print(f"Parámetros: {tool_call.function.arguments}")
Ver ejemplo de llamada con cURL
curl https://api.apiyi.com/v1/chat/completions \
-H "Authorization: Bearer $API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "glm-5",
"messages": [
{"role": "system", "content": "Eres un ingeniero de software sénior"},
{"role": "user", "content": "Diseña la arquitectura de un sistema de programación de tareas distribuidas"}
],
"max_tokens": 8192,
"temperature": 0.7,
"stream": true
}'
🎯 Consejo técnico: GLM-5 es compatible con el formato del SDK de OpenAI; los proyectos existentes solo necesitan modificar los parámetros
base_urlymodelpara migrar. Al llamar a través de la plataforma APIYI (apiyi.com), puedes disfrutar de una gestión de interfaz unificada y bonificaciones por recarga.
Pruebas de rendimiento Benchmark de GLM-5
Datos clave de los Benchmarks de GLM-5
GLM-5 ha demostrado el nivel más alto entre los modelos de código abierto en varios benchmarks principales:
| Benchmark | GLM-5 | Claude Opus 4.5 | GPT-5 | Contenido de la prueba |
|---|---|---|---|---|
| MMLU | 85.0% | 88.7% | 90.2% | 57 materias de conocimiento |
| MMLU Pro | 70.4% | – | – | Multidisciplinar mejorado |
| GPQA | 68.2% | 71.4% | 73.1% | Ciencia de nivel de posgrado |
| HumanEval | 90.0% | 93.2% | 92.5% | Programación en Python |
| MATH | 88.0% | 90.1% | 91.3% | Razonamiento matemático |
| GSM8k | 97.0% | 98.2% | 98.5% | Problemas matemáticos aplicados |
| AIME 2026 I | 92.7% | 93.3% | – | Competición matemática |
| SWE-bench | 77.8% | 80.9% | 80.0% | Ingeniería de software real |
| HLE w/ Tools | 50.4% | 43.4% | – | Razonamiento con herramientas |
| IFEval | 88.0% | – | – | Seguimiento de instrucciones |
| Terminal-Bench | 56.2% | 57.9% | – | Operaciones de terminal |
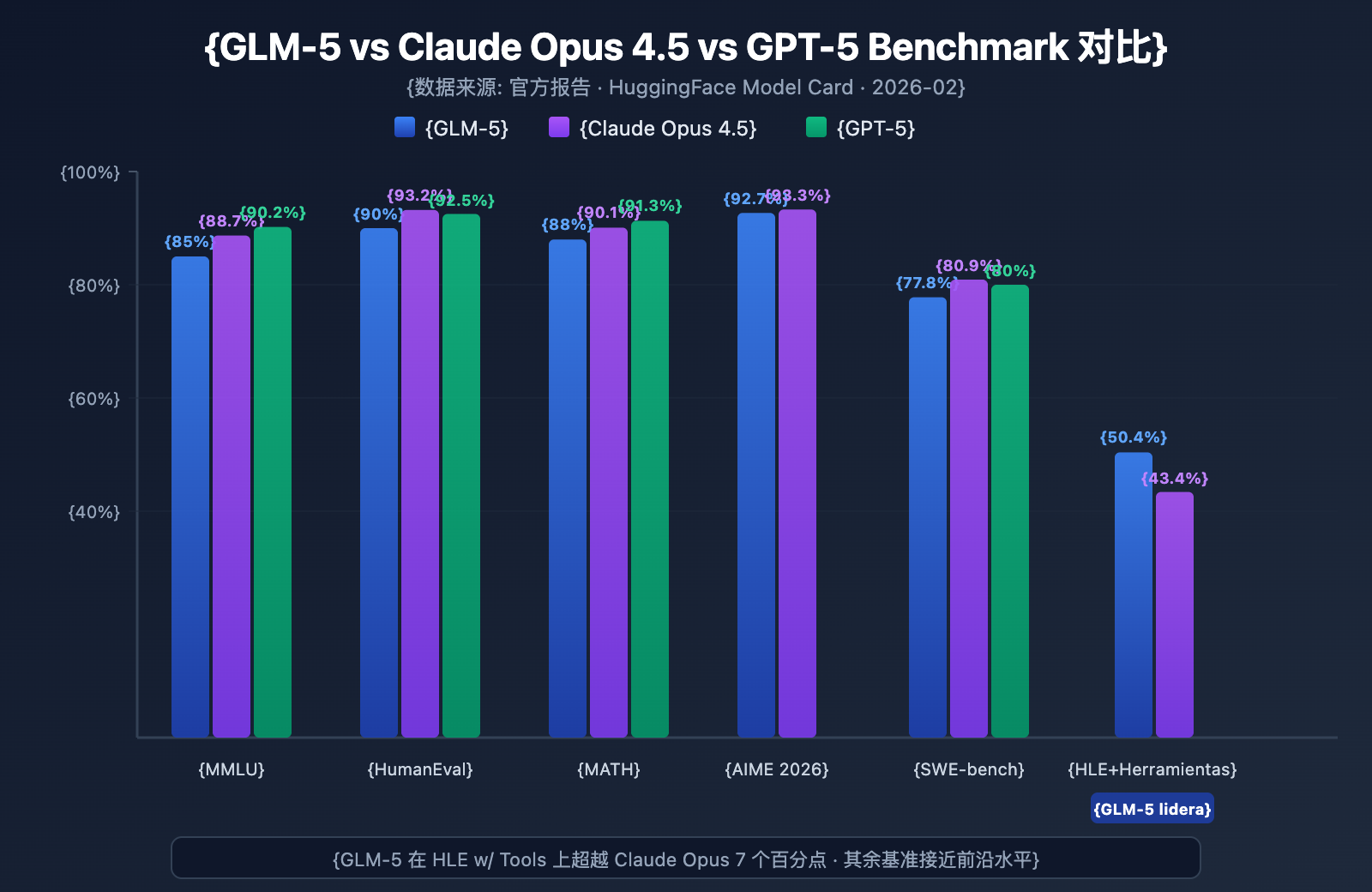
Análisis de rendimiento de GLM-5: 4 ventajas clave
A partir de los datos de los benchmarks, podemos destacar varios puntos de interés:
1. Capacidad de Agent de GLM-5: HLE w/ Tools supera a los modelos cerrados
GLM-5 obtuvo una puntuación del 50.4% en Humanity's Last Exam (con uso de herramientas), superando el 43.4% de Claude Opus y quedando solo por detrás del 51.8% de Kimi K2.5. Esto indica que GLM-5 ya posee el nivel de los modelos de vanguardia en escenarios de Agents, donde se requiere planificación, llamada a herramientas y resolución iterativa de tareas complejas.
Este resultado es coherente con la filosofía de diseño de GLM-5: ha sido optimizado específicamente para flujos de trabajo de Agents, desde su arquitectura hasta el post-entrenamiento. Para los desarrolladores que buscan construir sistemas de AI Agents, GLM-5 ofrece una opción de código abierto con una excelente relación calidad-precio.
2. Capacidad de programación de GLM-5: Entra en el primer nivel
Con un 90% en HumanEval y un 77.8% en SWE-bench Verified, GLM-5 está muy cerca del nivel de Claude Opus (80.9%) y GPT-5 (80.0%) en generación de código y tareas de ingeniería de software reales. Para un modelo de código abierto, alcanzar un 77.8% en SWE-bench es un hito importante: significa que GLM-5 es capaz de entender issues reales de GitHub, localizar problemas en el código y enviar correcciones efectivas.
3. Razonamiento matemático de GLM-5: Cerca del límite máximo
En AIME 2026 I, GLM-5 alcanzó un 92.7%, quedando solo 0.6 puntos porcentuales por detrás de Claude Opus. El 97% en GSM8k también demuestra que GLM-5 es sumamente confiable en problemas matemáticos de dificultad media. Su puntuación del 88% en MATH también lo sitúa en el primer nivel.
4. Control de alucinaciones de GLM-5: Reducción drástica
Según datos oficiales, GLM-5 ha reducido la tasa de alucinaciones en un 56% en comparación con la generación anterior. Esto se debe a las iteraciones de post-entrenamiento más exhaustivas permitidas por el sistema RL asíncrono Slime. En escenarios que requieren alta precisión, como extracción de información, resumen de documentos y preguntas y respuestas en bases de conocimientos, una menor tasa de alucinaciones se traduce directamente en una calidad de salida más confiable.
Posicionamiento de GLM-5 frente a modelos de código abierto similares
En el panorama actual de los Modelos de Lenguaje Grande de código abierto, el posicionamiento de GLM-5 es bastante claro:
| Modelo | Escala de parámetros | Arquitectura | Ventaja principal | Licencia |
|---|---|---|---|---|
| GLM-5 | 744B (40B activos) | MoE | Agent + Baja alucinación | Apache-2.0 |
| DeepSeek V3 | 671B (37B activos) | MoE | Calidad-precio + Razonamiento | MIT |
| Llama 4 Maverick | 400B (17B activos) | MoE | Multimodal + Ecosistema | Llama License |
| Qwen 3 | 235B | Dense | Multilingüe + Herramientas | Apache-2.0 |
Las ventajas diferenciadoras de GLM-5 se manifiestan principalmente en tres aspectos: optimización específica para flujos de trabajo de Agents (liderazgo en HLE w/ Tools), una tasa de alucinaciones extremadamente baja (reducción del 56%) y la seguridad en la cadena de suministro que ofrece su entrenamiento con potencia de cómputo de origen nacional. Para las empresas que necesitan desplegar modelos de vanguardia de código abierto, GLM-5 es una opción que merece especial atención.
Análisis de precios y costes de GLM-5
Precios oficiales de GLM-5
| Tipo de facturación | Precio oficial Z.ai | Precio OpenRouter | Descripción |
|---|---|---|---|
| Tokens de entrada | $1.00/M | $0.80/M | Por millón de tokens de entrada |
| Tokens de salida | $3.20/M | $2.56/M | Por millón de tokens de salida |
| Entrada en caché | $0.20/M | $0.16/M | Precio de entrada cuando hay acierto en caché |
| Almacenamiento de caché | Temporalmente gratuito | – | Tarifa de almacenamiento de datos en caché |
Comparativa de precios: GLM-5 vs. Competencia
La estrategia de precios de GLM-5 es muy competitiva, especialmente si se compara con los modelos de vanguardia de código cerrado:
| Modelo | Entrada ($/M) | Salida ($/M) | Coste relativo a GLM-5 | Posicionamiento del modelo |
|---|---|---|---|---|
| GLM-5 | $1.00 | $3.20 | Base | Flagship de código abierto |
| Claude Opus 4.6 | $5.00 | $25.00 | ~ 5-8x | Flagship de código cerrado |
| GPT-5 | $1.25 | $10.00 | ~ 1.3-3x | Flagship de código cerrado |
| DeepSeek V3 | $0.27 | $1.10 | ~ 0.3x | Calidad-precio (Código abierto) |
| GLM-4.7 | $0.60 | $2.20 | ~ 0.6-0.7x | Flagship de generación anterior |
| GLM-4.7-FlashX | $0.07 | $0.40 | ~ 0.07-0.13x | Coste ultra bajo |
Viendo los precios, GLM-5 se posiciona entre GPT-5 y DeepSeek V3: es mucho más barato que la mayoría de los modelos punteros de código cerrado, pero ligeramente más caro que los modelos de código abierto ligeros. Teniendo en cuenta su escala de 744B de parámetros y que ofrece el mejor rendimiento en el ecosistema de código abierto, este precio es bastante razonable.
Línea completa de productos GLM y precios
Si el GLM-5 no se ajusta exactamente a lo que buscas, Zhipu ofrece una línea completa de productos para elegir:
| Modelo | Entrada ($/M) | Salida ($/M) | Escenario de uso |
|---|---|---|---|
| GLM-5 | $1.00 | $3.20 | Razonamiento complejo, Agentes, documentos largos |
| GLM-5-Code | $1.20 | $5.00 | Especializado en desarrollo de código |
| GLM-4.7 | $0.60 | $2.20 | Tareas generales de complejidad media |
| GLM-4.7-FlashX | $0.07 | $0.40 | Llamadas de alta frecuencia y bajo coste |
| GLM-4.5-Air | $0.20 | $1.10 | Equilibrio y ligereza |
| GLM-4.7/4.5-Flash | Gratis | Gratis | Experiencia inicial y tareas sencillas |
💰 Optimización de costes: GLM-5 ya está disponible en APIYI (apiyi.com), con precios idénticos a los oficiales de Z.ai. Gracias a las promociones de recarga de la plataforma, el coste real de uso puede reducirse hasta un 20% respecto al precio oficial, lo que es ideal para equipos y desarrolladores con necesidades de llamadas constantes.
Escenarios de uso y sugerencias de selección para GLM-5
¿Para qué escenarios es adecuado GLM-5?
Basándonos en las características técnicas y el rendimiento en benchmarks de GLM-5, estas son las recomendaciones específicas:
Escenarios altamente recomendados:
- Flujos de trabajo de Agentes: GLM-5 ha sido diseñado específicamente para tareas de Agentes de ciclo largo. Con un 50.4% en HLE w/ Tools, supera a Claude Opus, siendo ideal para construir sistemas de Agentes con planificación autónoma y llamada a herramientas.
- Tareas de ingeniería de código: Con un 90% en HumanEval y 77.8% en SWE-bench, es capaz de generar código, corregir bugs, realizar revisiones de código y diseño de arquitectura.
- Razonamiento matemático y científico: Con un 92.7% en AIME y 88% en MATH, es perfecto para demostraciones matemáticas, derivación de fórmulas y cálculo científico.
- Análisis de documentos extensos: Su ventana de contexto de 200K permite procesar repositorios de código completos, manuales técnicos, contratos legales y otros textos larguísimos.
- Preguntas y respuestas con baja alucinación: La tasa de alucinación se ha reducido en un 56%, lo que lo hace apto para bases de conocimiento (RAG) y resúmenes de documentos donde se requiere alta precisión.
Escenarios donde podrías considerar otras opciones:
- Tareas multimodales: El núcleo de GLM-5 solo admite texto. Si necesitas comprensión de imágenes, elige modelos visuales como GLM-4.6V.
- Latencia extremadamente baja: La velocidad de inferencia de un modelo MoE de 744B no es tan rápida como la de los modelos pequeños. Para escenarios de alta frecuencia y baja latencia, se recomienda GLM-4.7-FlashX.
- Procesamiento por lotes de ultra bajo coste: Si vas a procesar volúmenes masivos de texto donde la calidad no es crítica, DeepSeek V3 o GLM-4.7-FlashX ofrecen costes menores.
Comparativa de selección: GLM-5 vs. GLM-4.7
| Dimensión de comparación | GLM-5 | GLM-4.7 | Sugerencia de selección |
|---|---|---|---|
| Escala de parámetros | 744B (40B activos) | No revelado | GLM-5 es mayor |
| Capacidad de razonamiento | AIME 92.7% | ~85% | Razonamiento complejo: GLM-5 |
| Capacidad de Agente | HLE w/ Tools 50.4% | ~38% | Tareas de Agentes: GLM-5 |
| Capacidad de codificación | HumanEval 90% | ~85% | Desarrollo de código: GLM-5 |
| Control de alucinaciones | Reducción del 56% | Base | Alta precisión: GLM-5 |
| Precio de entrada | $1.00/M | $0.60/M | Sensible al coste: GLM-4.7 |
| Precio de salida | $3.20/M | $2.20/M | Sensible al coste: GLM-4.7 |
| Longitud de contexto | 200K | 128K+ | Documentos largos: GLM-5 |

💡 Consejo de elección: Si tu proyecto requiere una capacidad de razonamiento de primer nivel, flujos de trabajo de Agentes o el procesamiento de contextos larguísimos, GLM-5 es la mejor opción. Si tienes un presupuesto limitado y la complejidad de las tareas es moderada, GLM-4.7 sigue siendo una excelente solución por su relación calidad-precio. Ambos modelos se pueden invocar a través de la plataforma APIYI (apiyi.com), lo que facilita cambiar de uno a otro para realizar pruebas en cualquier momento.
Preguntas frecuentes sobre la API de GLM-5
Q1: ¿Cuál es la diferencia entre GLM-5 y GLM-5-Code?
GLM-5 es el modelo insignia de propósito general (Entrada $1.00/M, Salida $3.20/M), ideal para todo tipo de tareas de texto. GLM-5-Code es una versión optimizada específicamente para programación (Entrada $1.20/M, Salida $5.00/M), con mejoras adicionales en generación de código, depuración y tareas de ingeniería. Si tu escenario principal es el desarrollo de software, vale la pena probar GLM-5-Code. Ambos modelos se pueden invocar a través de una interfaz unificada compatible con OpenAI.
Q2: ¿El modo Thinking de GLM-5 afecta la velocidad de salida?
Sí. En el modo Thinking, GLM-5 genera primero una cadena de razonamiento interna antes de entregar la respuesta final, por lo que la latencia del primer token (TTFT) aumenta. Para preguntas sencillas, se recomienda desactivar el modo Thinking para obtener una respuesta más rápida. Para problemas complejos de matemáticas, programación y lógica, se recomienda activarlo; aunque es más lento, la precisión mejora significativamente.
Q3: ¿Qué cambios debo hacer en mi código para migrar de GPT-4 o Claude a GLM-5?
La migración es muy sencilla, solo necesitas modificar dos parámetros:
- Cambia la
base_urla la dirección de la interfaz de APIYI:https://api.apiyi.com/v1 - Cambia el parámetro
modela"glm-5"
GLM-5 es totalmente compatible con el formato de la interfaz chat.completions del SDK de OpenAI, incluyendo los roles system/user/assistant, salida en streaming, Function Calling, entre otros. A través de una plataforma de API unificada, también puedes alternar entre modelos de diferentes proveedores bajo una misma API Key, lo cual es muy conveniente para realizar pruebas A/B.
Q4: ¿GLM-5 admite entrada de imágenes?
No. GLM-5 es un modelo de texto puro y no admite entrada de imágenes, audio o video. Si necesitas capacidades de comprensión visual, puedes utilizar las variantes de modelos de visión de Zhipu, como GLM-4.6V o GLM-4.5V.
Q5: ¿Cómo se utiliza la función de caché de contexto de GLM-5?
GLM-5 admite el almacenamiento en caché de contexto (Context Caching). El precio de la entrada almacenada en caché es de solo $0.20/M, que es 1/5 del precio de la entrada normal. En conversaciones largas o escenarios donde se necesita procesar repetidamente el mismo prefijo, la función de caché puede reducir significativamente los costos. Por el momento, el almacenamiento de la caché es gratuito. En conversaciones de varias rondas, el sistema identificará y almacenará automáticamente los prefijos de contexto repetidos.
Q6: ¿Cuál es la longitud máxima de salida de GLM-5?
GLM-5 admite una longitud máxima de salida de 128,000 tokens. Para la mayoría de los escenarios, el valor predeterminado de 4096 tokens es suficiente. Si necesitas generar textos largos (como documentación técnica completa o grandes bloques de código), puedes ajustarlo mediante el parámetro max_tokens. Ten en cuenta que cuanto más larga sea la salida, mayor será el consumo de tokens y el tiempo de espera.
Mejores prácticas para el uso de la API de GLM-5
Al utilizar GLM-5 en la práctica, las siguientes experiencias pueden ayudarte a obtener mejores resultados:
Optimización de la indicación (System Prompt) de GLM-5
GLM-5 responde con alta calidad a las indicaciones de sistema (system prompt). Diseñar una indicación adecuada puede mejorar notablemente la calidad de la salida:
# Recomendado: Definición clara del rol + requisitos de formato de salida
messages = [
{
"role": "system",
"content": """Eres un arquitecto experto en sistemas distribuidos.
Por favor, sigue estas reglas:
1. La respuesta debe estar estructurada, utiliza formato Markdown.
2. Proporciona soluciones técnicas específicas en lugar de generalidades.
3. Si incluyes código, proporciona un ejemplo ejecutable.
4. Indica los riesgos potenciales y las precauciones en los lugares apropiados."""
},
{
"role": "user",
"content": "Diseña un sistema de cola de mensajes que soporte millones de conexiones concurrentes"
}
]
Guía de ajuste de temperature para GLM-5
Diferentes tareas tienen distinta sensibilidad a la temperatura (temperature). Aquí tienes algunas sugerencias basadas en pruebas reales:
- temperature 0.1-0.3: Generación de código, extracción de datos, conversión de formatos y otras tareas que requieren una salida precisa.
- temperature 0.5-0.7: Documentación técnica, preguntas y respuestas, resúmenes y otras tareas que requieren estabilidad pero con cierta flexibilidad expresiva.
- temperature 0.8-1.0: Escritura creativa, lluvia de ideas y otras tareas que requieren diversidad.
- temperature 1.0 (Modo Thinking): Razonamiento matemático, programación compleja y otras tareas de razonamiento profundo.
Consejos para el manejo de contextos largos en GLM-5
GLM-5 admite una ventana de contexto de 200K tokens, pero en la práctica debes considerar lo siguiente:
- Priorizar información importante: Coloca el contexto más crítico al principio de la indicación (prompt), no al final.
- Procesamiento por fragmentos: Para documentos que superen los 100K tokens, se recomienda procesarlos por partes y luego combinarlos para obtener una salida más estable.
- Aprovechar la caché: En conversaciones de varias rondas, el contenido del prefijo idéntico se almacenará automáticamente en caché, con un precio de entrada de solo $0.20/M.
- Controlar la longitud de salida: Al ingresar contextos largos, configura adecuadamente
max_tokenspara evitar salidas excesivamente extensas que aumenten costos innecesarios.
Referencia de despliegue local de GLM-5
Si necesitas desplegar GLM-5 en tu propia infraestructura, estos son los principales métodos de despliegue:
| Método de despliegue | Hardware recomendado | Precisión | Características |
|---|---|---|---|
| vLLM | 8x A100/H100 | FP8 | Framework de inferencia principal, soporta decodificación especulativa |
| SGLang | 8x H100/B200 | FP8 | Inferencia de alto rendimiento, optimizado para GPUs Blackwell |
| xLLM | Huawei Ascend NPU | BF16/FP8 | Adaptación para potencia de cómputo nacional |
| KTransformers | GPU de consumo | Cuantización | Inferencia acelerada por GPU |
| Ollama | Hardware de consumo | Cuantización | La experiencia local más sencilla |
GLM-5 ofrece formatos de peso en precisión completa BF16 y cuantización FP8, que pueden descargarse desde HuggingFace (huggingface.co/zai-org/GLM-5) o ModelScope. La versión cuantizada en FP8 reduce significativamente los requisitos de VRAM manteniendo la mayor parte del rendimiento.
Configuraciones clave necesarias para desplegar GLM-5:
- Paralelismo de tensores: 8 vías (tensor-parallel-size 8)
- Utilización de VRAM: Se recomienda establecerlo en 0.85
- Parser de llamada a herramientas: glm47
- Parser de inferencia: glm45
- Decodificación especulativa: Soporta los métodos MTP y EAGLE
Para la mayoría de los desarrolladores, realizar llamadas vía API es la forma más eficiente, ya que ahorra costes de despliegue y mantenimiento, permitiendo centrarse únicamente en el desarrollo de la aplicación. Para escenarios que requieran un despliegue privado, se puede consultar la documentación oficial:
github.com/zai-org/GLM-5
Resumen de llamadas a la API de GLM-5
Consulta rápida de capacidades principales de GLM-5
| Dimensión de capacidad | Rendimiento de GLM-5 | Escenarios de aplicación |
|---|---|---|
| Razonamiento | AIME 92.7%, MATH 88% | Demostraciones matemáticas, razonamiento científico, análisis lógico |
| Codificación | HumanEval 90%, SWE-bench 77.8% | Generación de código, corrección de bugs, diseño de arquitectura |
| Agent | HLE w/ Tools 50.4% | Llamada a herramientas, planificación de tareas, ejecución autónoma |
| Conocimiento | MMLU 85%, GPQA 68.2% | Preguntas y respuestas académicas, consultoría técnica, extracción de conocimiento |
| Instrucciones | IFEval 88% | Salida formateada, generación estructurada, cumplimiento de reglas |
| Precisión | Reducción de alucinaciones en 56% | Resumen de documentos, verificación de hechos, extracción de información |
Valor del ecosistema de código abierto de GLM-5
GLM-5 utiliza la licencia Apache-2.0, lo que significa:
- Libertad comercial: Las empresas pueden usarlo, modificarlo y distribuirlo gratuitamente sin pagar cuotas de licencia.
- Ajuste fino (Fine-tuning) personalizado: Es posible realizar un ajuste fino de dominio basado en GLM-5 para construir modelos específicos para una industria.
- Despliegue privado: Los datos sensibles no salen de la red interna, cumpliendo con requisitos de cumplimiento en sectores como finanzas, salud o gobierno.
- Ecosistema de la comunidad: Ya existen más de 11 variantes cuantizadas y más de 7 versiones ajustadas en HuggingFace, y el ecosistema sigue expandiéndose.
Como el último modelo insignia de Zhipu AI, GLM-5 ha establecido un nuevo estándar en el campo de los Modelos de Lenguaje Grande de código abierto:
- Arquitectura MoE de 744B: Sistema de 256 expertos, activa 40B de parámetros en cada inferencia, logrando un equilibrio excelente entre capacidad del modelo y eficiencia de inferencia.
- El Agent de código abierto más potente: Con un 50.4% en HLE w/ Tools, supera a Claude Opus, diseñado específicamente para flujos de trabajo de Agent de ciclo largo.
- Entrenado con potencia de cómputo nacional: Entrenado sobre 100,000 chips Huawei Ascend, validando la capacidad de las pilas de cómputo nacionales para el entrenamiento de modelos de vanguardia.
- Alta relación costo-rendimiento: Entrada a $1/M y salida a $3.2/M, muy por debajo de los modelos cerrados de nivel similar; la comunidad de código abierto puede desplegarlo y ajustarlo libremente.
- Contexto ultra largo de 200K: Soporta el procesamiento de bases de código completas y documentos técnicos extensos de una sola vez, con una salida máxima de 128K tokens.
- 56% menos alucinaciones: El post-entrenamiento con RL asíncrono Slime ha mejorado drásticamente la precisión de los hechos.
Se recomienda experimentar rápidamente todas las capacidades de GLM-5 a través de APIYI (apiyi.com). Los precios de la plataforma son idénticos a los oficiales, y las promociones de recarga permiten disfrutar de un descuento aproximado del 20%.
Este artículo fue escrito por el equipo técnico de APIYI Team. Para más tutoriales sobre el uso de modelos de IA, por favor sigue el centro de ayuda de APIYI en apiyi.com.