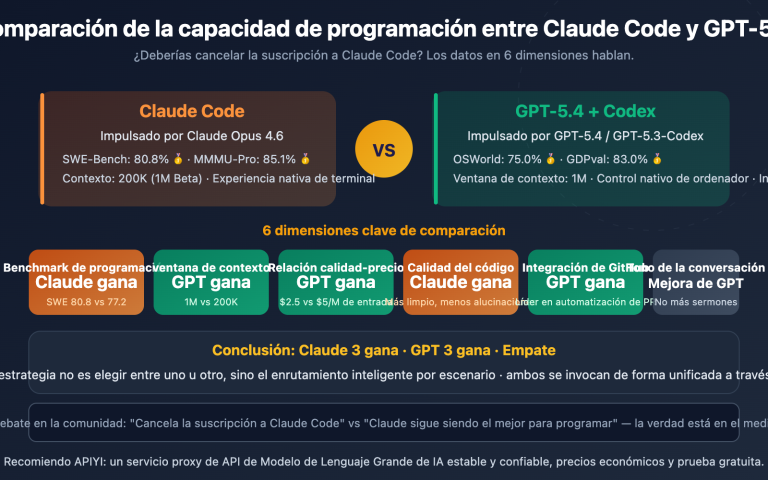
Nota del autor: Análisis profundo de los 5 avances principales del modelo unificado de generación y edición de imágenes Qwen-Image-2.0, incluyendo su arquitectura ligera de 7B, resolución nativa 2K, indicaciones largas de 1000 tokens y otros aspectos técnicos destacados, junto con una guía de acceso a la API y uso práctico.
El equipo de Tongyi de Alibaba lanzó el 10 de febrero de 2026 Qwen-Image-2.0, una actualización importante que unifica la generación y la edición de imágenes en un solo modelo. Lo más impresionante es que ha logrado reducir drásticamente el número de parámetros de los 20B de la generación anterior a solo 7B, consiguiendo al mismo tiempo una mejora integral en el rendimiento. APIYI, como socio autorizado de Alibaba Cloud, está trabajando actualmente en su integración y se espera que esté disponible pronto, ofreciendo además ventajas competitivas en el precio.
Valor principal: A través de este análisis profundo, conocerás los 5 avances clave de Qwen-Image-2.0, sus diferencias reales con la competencia y cómo empezar a usarlo rápidamente a través de la API.
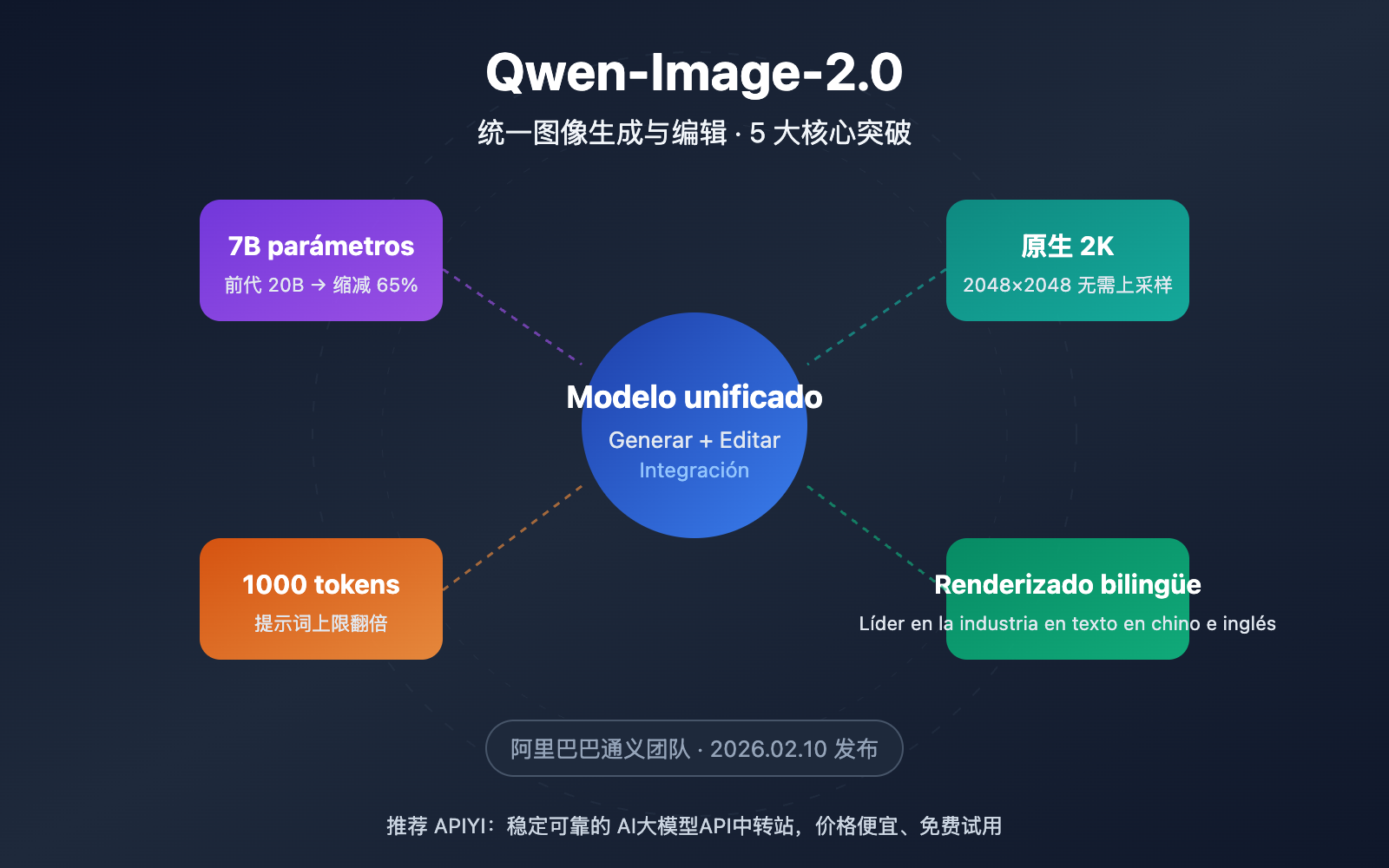
Resumen de puntos clave de Qwen-Image-2.0
| Punto clave | Descripción | Valor |
|---|---|---|
| Generación + Edición Unificada | Texto a imagen y edición de imágenes integrados en un solo modelo 7B | No es necesario cargar dos modelos por separado, reduciendo drásticamente los costes de despliegue |
| Reducción de parámetros del 65% | De los 20B de la generación anterior a 7B (decodificador de difusión) | Velocidad de inferencia más rápida y requisitos de memoria de vídeo significativamente menores |
| Resolución nativa 2K | Soporta salida nativa de hasta 2048×2048 | Sin necesidad de escalado (upsampling), con mayor claridad en los detalles |
| Indicación de 1000 tokens | El límite de la indicación se duplica (antes ~500 tokens) | Permite descripciones de escenas más complejas y un control más preciso |
| Renderizado de texto bilingüe | Generación de texto en chino e inglés líder en la industria | Resultados excepcionales en carteles, infografías y escenas que contienen texto |
Análisis de la tecnología principal de Qwen-Image-2.0
Qwen-Image-2.0 adopta un nuevo diseño de arquitectura de doble componente: el modelo de lenguaje visual Qwen3-VL de 8B parámetros actúa como codificador de condiciones, y el MMDiT (Multi-modal Diffusion Transformer) de 7B parámetros funciona como decodificador de difusión. Este diseño permite al modelo comprender profundamente la información semántica tanto del texto como de la imagen, para luego generar imágenes de alta calidad a través del proceso de difusión.
La mayor diferencia con su predecesor, Qwen-Image-2512, radica en su estrategia de entrenamiento unificada: la generación de texto a imagen (T2I) y la edición de imágenes (I2I/TI2I) se fusionan en una única propagación hacia adelante (forward pass). Esto significa que un solo modelo puede realizar tareas que antes requerían dos modelos independientes, Qwen-Image (generación) y Qwen-Image-Edit (edición), reduciendo significativamente la complejidad y el coste de despliegue.
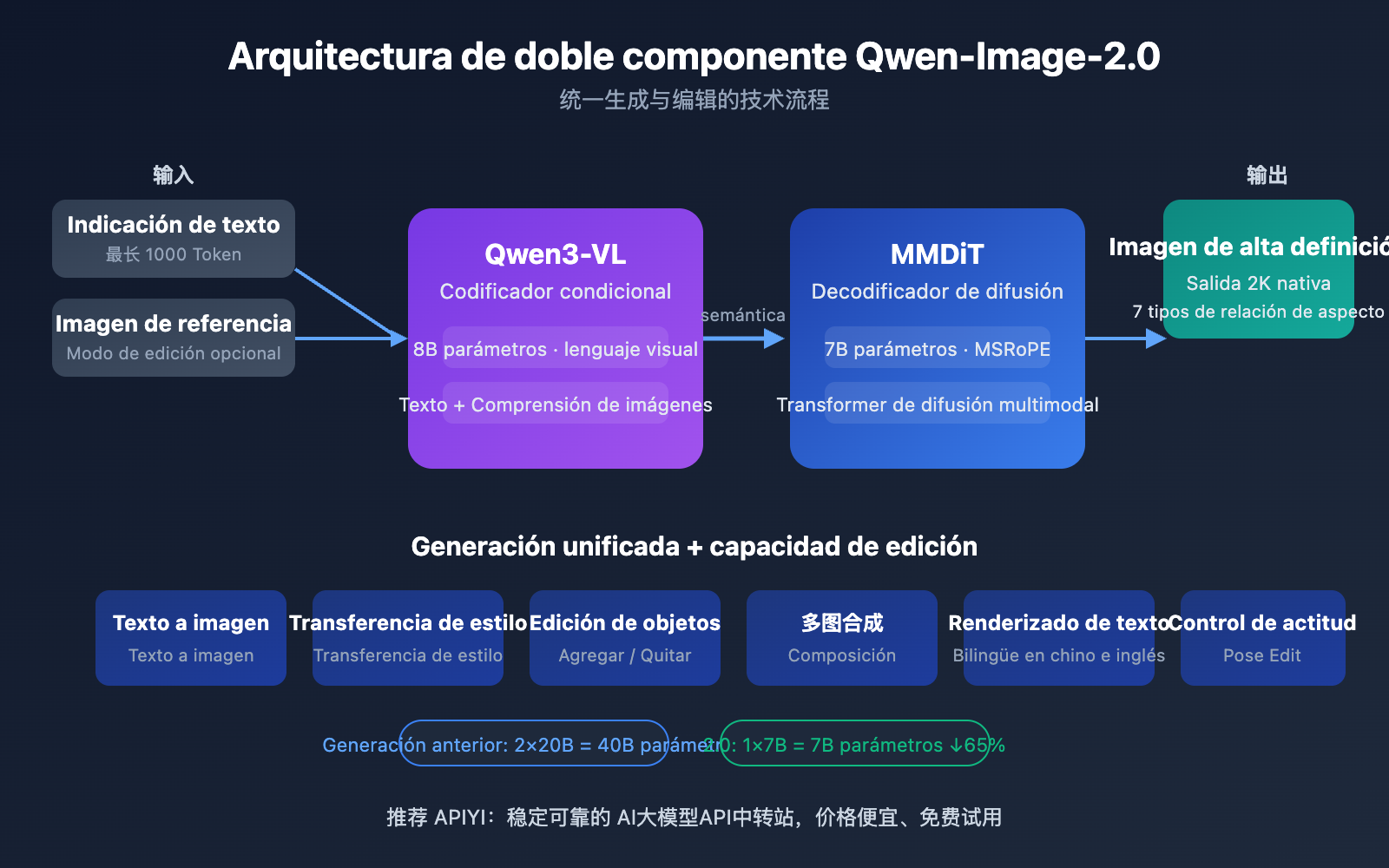
Detalles de los cinco avances principales de Qwen-Image-2.0
Avance 1: Arquitectura unificada de generación y edición
Esta es la innovación más emblemática de Qwen-Image-2.0. Mientras que la generación anterior requería mantener por separado un modelo de texto a imagen y un modelo de edición de imágenes, la versión 2.0 fusiona ambos en uno solo:
| Capacidad | Solución anterior | Qwen-Image-2.0 |
|---|---|---|
| Texto a imagen | Qwen-Image-2512 (20B) | Modelo unificado (7B) |
| Edición de imagen | Qwen-Image-Edit-2511 (20B) | Modelo unificado (7B) |
| Transferencia de estilo | Manejada por el modelo de edición por separado | Soportada directamente por el modelo unificado |
| Composición multi-imagen | Manejada por el modelo de edición por separado | Soportada directamente por el modelo unificado |
| VRAM total del modelo | Requiere cargar 2 modelos de 20B | Solo requiere 1 modelo de 7B |
En el uso práctico, puedes usar una indicación de texto para generar una imagen y luego realizar directamente transferencia de estilo, añadir o eliminar objetos, o ajustar la pose sobre esa misma imagen; todo el proceso sin necesidad de cambiar de modelo.
Avance 2: Superación del rendimiento con solo 7B de parámetros
Se ha reducido de 20B a 7B (decodificador de difusión), lo que supone una reducción del 65% en la cantidad de parámetros, pero la calidad de la imagen ha mejorado en lugar de disminuir. La clave detrás de esto es la capacidad de comprensión semántica profunda del codificador Qwen3-VL: este Modelo de Lenguaje Grande visual de 8B asume más trabajo en la fase de "comprensión de necesidades", permitiendo que el decodificador de difusión se concentre de manera más eficiente en la "generación de la imagen".
Para los desarrolladores, esto significa:
- Mejora en la velocidad de inferencia: Llamadas a la API de aproximadamente 5-8 segundos por imagen.
- Reducción de los requisitos de VRAM: Se estima que puede ejecutarse con 24GB de VRAM (la generación anterior requería más de 48GB).
- Reducción de costes de despliegue: Es viable ejecutarlo en GPUs de consumo de una sola tarjeta.
Avance 3: Resolución nativa 2K
Qwen-Image-2.0 admite de forma nativa la salida en resolución de 2048×2048, sin necesidad de pasos adicionales de escalado por superresolución (upsampling). Soporta 7 relaciones de aspecto estándar:
| Relación de aspecto | Resolución | Escenarios recomendados |
|---|---|---|
| 16:9 | 1664×928 | Portadas de video, imágenes para blogs (predeterminado) |
| 1:1 | 1328×1328 | Avatares de redes sociales, imágenes principales de productos |
| 9:16 | 928×1664 | Fondos de pantalla para móviles, portadas de videos cortos |
| 4:3 | 1472×1104 | Presentación horizontal tradicional |
| 3:4 | 1104×1472 | Presentación vertical tradicional |
| 3:2 | 1584×1056 | Imagen horizontal estilo fotografía |
| 2:3 | 1056×1584 | Imagen vertical estilo fotografía |
Avance 4: Indicación larga de 1000 Tokens
El límite de la indicación ha aumentado de unos 500 tokens en la generación anterior a 1000 tokens. Este espacio duplicado te permite describir escenas mucho más complejas. En pruebas reales, esto es especialmente valioso para:
- Infografías profesionales: Control preciso de la disposición, el contenido del texto y la combinación de colores.
- Escenarios con múltiples sujetos: Descripción simultánea de las relaciones espaciales e interacciones entre varios objetos.
- Fusión de estilos: Descripción detallada del estilo artístico deseado y los requisitos de textura.
Avance 5: Liderazgo en renderizado de texto bilingüe
La capacidad de Qwen-Image-2.0 para generar texto dentro de las imágenes es líder en la industria, especialmente en el renderizado de chino, soportando varios estilos de fuente como Kaishu, Shoujin y Xiaozhuan. Esto le otorga una ventaja clara en:
- Diseño de pósteres de marketing e imágenes promocionales.
- Gráficos técnicos con anotaciones en chino.
- Contenido visual para redes sociales.
- Generación de materiales visuales de marca.
🎯 Sugerencia práctica: Qwen-Image-2.0 se encuentra actualmente en fase de prueba beta por invitación para su API. APIYI (apiyi.com) está trabajando activamente en su integración y ofrecerá precios con un 20% de descuento respecto al sitio oficial, permitiendo llamadas unificadas en formato compatible con OpenAI. Estén atentos.
Guía rápida de Qwen-Image-2.0
Ejemplo minimalista
Aquí tienes la forma básica de llamar a la API de Qwen-Image-2.0 para generar una imagen (basado en el formato de la API DashScope):
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="qwen-image-2.0",
messages=[{
"role": "user",
"content": "Un Shiba Inu con gafas de sol surfeando en la playa, día soleado, estilo fotografía de alta definición"
}]
)
print(response.choices[0].message.content)
Ver ejemplo de llamada a la API nativa de DashScope
from dashscope import MultiModalConversation
import os
response = MultiModalConversation.call(
api_key=os.getenv("DASHSCOPE_API_KEY"),
model="qwen-image-max",
messages=[{
"role": "user",
"content": [{
"text": "Escritorio de oficina moderno y minimalista, con un portátil y plantas, luz natural suave"
}]
}],
size="1328*1328",
prompt_extend=True,
watermark=False
)
image_url = response.output.choices[0].message.content[0]["image"]
print(f"URL de la imagen: {image_url}")
# Nota: La URL es válida por 24 horas, descárgala y guárdala a tiempo.
Sugerencia: APIYI (apiyi.com) está integrando Qwen-Image-2.0. En ese momento, admitirá llamadas en formato compatible con OpenAI, permitiendo probar y comparar con una sola API Key varios modelos de generación de imágenes como GPT Image 1.5, Gemini 3 Pro Image, FLUX.2, entre otros.
Qwen-Image-2.0 frente a la competencia

| Comparativa | Qwen-Image-2.0 | GPT Image 1.5 | Gemini 3 Pro Image | FLUX.2 Max |
|---|---|---|---|---|
| Desarrollador | Alibaba | OpenAI | Black Forest Labs | |
| Generación y edición unificada | ✅ | ✅ | ✅ | ❌ |
| Resolución máxima | 2K | 2K+ | 2K | 2K |
| Renderizado de texto en chino | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐ |
| Velocidad de inferencia | 5-8 seg | 10-15 seg | 5-10 seg | 10-20 seg |
| Ecosistema de código abierto | Generación anterior abierta | Código cerrado | Código cerrado | Parcialmente abierto |
| Referencia de precios API | 20% menos que el oficial (APIYI) | $0.04-0.08/imagen | Facturación por token | $0.04/imagen |
Ventajas competitivas de Qwen-Image-2.0:
- El más fuerte en contextos chinos: Capacidad de renderizado de texto bilingüe líder en la industria, con resultados en pósteres e infografías en chino significativamente superiores a la competencia.
- Arquitectura más ligera: Con 7B de parámetros logra una calidad similar a GPT Image 1.5, con menores costos de inferencia.
- Potencial de código abierto: Toda la serie anterior es de código abierto bajo Apache-2.0, se espera que la versión 2.0 también lo sea.
- Ecosistema rico: Más de 2,380 likes en HuggingFace, más de 484 adaptadores LoRA y una comunidad muy activa.
Nota comparativa: Los datos anteriores provienen de documentación técnica pública y del ranking AI Arena. Se recomienda realizar pruebas reales a través de la plataforma APIYI (apiyi.com) para comparar el rendimiento de cada modelo en su escenario específico.
Escenarios de aplicación recomendados para Qwen-Image-2.0
Este modelo es ideal para los siguientes casos:
- Imágenes de productos para e-commerce: Un modelo único para generar imágenes de productos y reemplazar fondos, simplificando drásticamente el flujo de trabajo. Perfecto para equipos de diseño y operaciones de comercio electrónico.
- Diseño de materiales de marketing: Pósteres, imágenes para redes sociales y recursos publicitarios. Su potente renderización de texto en chino es su principal ventaja competitiva. Ideal para equipos de marketing.
- Diseño creativo: Soporta múltiples estilos artísticos como realista, anime, acuarela y dibujo a mano. Permite un control preciso de la dirección creativa mediante indicaciones largas de hasta 1000 tokens. Ideal para diseñadores y creadores de contenido.
- Generación de diagramas técnicos: Páginas de PPT, infografías, diagramas de flujo y otros contenidos profesionales con una maquetación precisa a nivel de píxel. Ideal para equipos de documentación técnica.
🎯 Sugerencia: Si tu negocio implica la generación de una gran cantidad de contenido visual con texto en chino, Qwen-Image-2.0 es actualmente la opción más destacada. Te recomendamos realizar pruebas comparativas a través de la plataforma APIYI (apiyi.com) para encontrar la solución que mejor se adapte a tus necesidades.
Evolución de versiones y precios de Qwen-Image-2.0
Línea de tiempo de la evolución
Desde el lanzamiento de su primera versión en agosto de 2025, la serie Qwen-Image ha mantenido un ritmo de iteración muy frecuente:
| Versión | Fecha | Mejoras principales |
|---|---|---|
| Qwen-Image v1 | 08/2025 | Lanzamiento inicial 20B MMDiT, código abierto Apache-2.0 |
| Qwen-Image-Edit | 08/2025 | Se añade un modelo de edición especializado |
| Qwen-Image-2512 | 12/2025 | Mejora en texturas realistas y renderización de texto |
| Qwen-Image-2.0 | 02/2026 | Arquitectura unificada, ligereza de 7B, resolución nativa 2K |
Referencia de precios
| Canal | Modelo | Precio de referencia |
|---|---|---|
| Alibaba Cloud DashScope | qwen-image-max | ¥0.50 / imagen |
| Alibaba Cloud DashScope | qwen-image-plus | ¥0.20 / imagen |
| Replicate | Qwen Image | $0.030 / imagen |
| Fal.ai | Qwen Image Edit | $0.021 / imagen |
| APIYI (Próximamente) | Qwen-Image-2.0 | Menos del 80% del precio oficial |
💡 El precio de la versión oficial de Qwen-Image-2.0 aún no se ha anunciado. En APIYI (apiyi.com) estamos trabajando activamente en su integración y ofreceremos un precio con un descuento superior al 20% respecto al oficial. Regístrate para obtener una cuota de prueba gratuita; ¡mantente atento!
Preguntas frecuentes
Q1: ¿Cuál es la diferencia entre Qwen-Image-2.0 y Qwen-Image-2512?
La mayor diferencia es que la versión 2.0 unifica la generación y la edición en un solo modelo de 7B parámetros, mientras que su predecesor, el 2512, era un modelo de 20B exclusivo para generación de imagen a partir de texto (text-to-image) y requería cargar Qwen-Image-Edit por separado para editar. La versión 2.0 también admite resolución nativa de 2K e indicaciones largas de hasta 1000 tokens, con mejoras significativas en la calidad de imagen y el renderizado de texto.
Q2: ¿Se puede usar Qwen-Image-2.0 a través de una API actualmente?
Actualmente se encuentra en fase de prueba beta por invitación; puedes probarlo gratis online en chat.qwen.ai. APIYI (apiyi.com) está en proceso de integración y, una vez lanzado, ofrecerá precios con un 20% de descuento respecto al sitio oficial. Además, será compatible con el formato de OpenAI, permitiendo comparar múltiples modelos de generación de imágenes con una sola clave (API Key).
Q3: ¿Es recomendable Qwen-Image-2.0 para despliegue local?
Los pesos de Qwen-Image-2.0 aún no son de código abierto. Sin embargo, dado que toda la serie anterior se lanzó bajo la licencia Apache-2.0, la comunidad espera que esta versión también lo sea. Un tamaño de 7B parámetros sugiere que podrá ejecutarse en GPUs de consumo (con 24GB de VRAM). Mientras esperas al lanzamiento del código abierto, te recomendamos validar los resultados rápidamente mediante la API de APIYI (apiyi.com).
Resumen
Puntos clave de Qwen-Image-2.0:
- Arquitectura unificada como mayor atractivo: Un solo modelo de 7B realiza tanto la generación como la edición, mientras que la generación anterior requería dos modelos de 20B.
- Ligero sin sacrificar calidad: Reducción del 65% en parámetros, pero con una mejora integral en la calidad de imagen y en el abanico de funciones.
- Irremplazable para contextos en chino: Renderizado de texto bilingüe y soporte para múltiples fuentes, lo que lo convierte en la opción preferida para generar contenido visual con texto en chino.
- Acceso vía API próximamente: Actualmente en fase de pruebas, con la versión oficial a la vuelta de la esquina.
Qwen-Image-2.0 representa un avance importante en los modelos de generación de imágenes de desarrollo chino. Para los equipos que necesitan contenido visual de alta calidad con texto en chino, este es, sin duda, uno de los modelos más interesantes a seguir.
Te recomendamos seguir las novedades de APIYI (apiyi.com) para obtener acceso temprano y precios preferenciales (un 20% más baratos que el oficial). La plataforma ofrece saldo gratuito y una interfaz unificada para múltiples modelos, facilitando una comparativa y validación rápida.
📚 Referencias
-
Blog oficial de Qwen: Anuncio del lanzamiento de Qwen-Image-2.0
- Enlace:
qwen.ai/blog?id=qwen-image-2.0 - Descripción: Interpretación técnica oficial y presentación de funciones
- Enlace:
-
Repositorio de GitHub: Página principal del proyecto Qwen-Image
- Enlace:
github.com/QwenLM/Qwen-Image - Descripción: Código fuente abierto, documentación técnica y guía de uso
- Enlace:
-
Clasificación de AI Arena: Ranking de generación de texto a imagen y edición de imágenes
- Enlace:
arena.ai/leaderboard/text-to-image - Descripción: Clasificación de evaluación independiente de terceros, con datos actualizados en tiempo real
- Enlace:
-
Documentación de la API de Alibaba Cloud: API de generación de imágenes DashScope
- Enlace:
help.aliyun.com/zh/model-studio/qwen-image-api - Descripción: Documentación oficial de acceso a la API y explicación de parámetros
- Enlace:
Autor: Equipo técnico
Intercambio técnico: Te invitamos a debatir en la sección de comentarios. Para más información, puedes visitar la comunidad técnica de APIYI apiyi.com