In April 2026, Claude Opus 4.7 set a new benchmark for coding models with a 87.6% score on SWE-bench Verified. Yet, just two weeks later, xAI challenged the long-held consensus that "coding models must be expensive" by releasing Grok 4.3 at one-tenth the cost. This article answers the two questions developers care about most: Can Grok 4.3 serve as a direct replacement for Claude Opus 4.7 in programming tasks? And if it can't be a perfect replacement, what unique advantages does Grok 4.3 offer that make it worth using?
Core Value: After reading this, you’ll know exactly whether to choose Grok 4.3, Claude Opus 4.7, or a hybrid approach for your specific coding scenarios, and how you can cut your total costs by over 60% using the APIYI API proxy service.

Grok 4.3 vs Claude Opus 4.7 Core Differences
To determine if a "direct replacement" is possible, let’s first align all the key parameters for both models in programming-related dimensions.
Grok 4.3 vs Claude Opus 4.7 Parameter Overview
| Dimension | Grok 4.3 | Claude Opus 4.7 | Winner |
|---|---|---|---|
| Release Date | 2026-04-30 | 2026-04-16 | Claude (14 days earlier) |
| Input Price | $1.25 / 1M | $5.00 / 1M | Grok 4.3 |
| Output Price | $2.50 / 1M | $25.00 / 1M | Grok 4.3 |
| Context Window | 1M tokens | 1M tokens | Draw |
| Max Output | Standard | 128K tokens | Claude |
| Output Speed | 207 tokens/sec | ~78 tokens/sec | Grok 4.3 |
| Reasoning Mode | Enabled by default | xhigh / Adaptive | Claude (More granular) |
| SWE-bench Verified | ~73% | 87.6% | Claude (+14.6pt) |
| SWE-bench Pro | Not disclosed | 64.3% | Claude |
| CursorBench | Not disclosed | 70% | Claude |
| Vending-Bench (Agent) | Top-tier | Medium | Grok 4.3 |
| Prompt Caching Discount | 75% | 90% | Claude |
| Batch API Discount | 50% | 50% | Draw |
| Video Input | ✅ Native | ❌ Not supported | Grok 4.3 |
| Docs (PDF/XLSX/PPTX) | ✅ Native | ❌ Requires post-processing | Grok 4.3 |
| Server-side Tools | ✅ Built-in web/code | ❌ Requires custom build | Grok 4.3 |
One-Sentence Positioning
Summarizing the table above: Claude Opus 4.7 remains the ceiling for "precision-sensitive coding tasks," while Grok 4.3 is the best choice for "cost-sensitive, long-chain, and multimodal" development scenarios. It isn't a direct replacement, but rather a "precision vs. cost-performance" split in workload distribution.
🎯 Quick Trial Suggestion: Both models are available on APIYI (apiyi.com) with the base_url set to
https://vip.apiyi.com/v1. Grok 4.3 pricing matches the official xAI rate ($1.25/$2.50), and Claude Opus 4.7 pricing is passed through directly from Anthropic ($5.00/$25.00). There are no markups, and you can call them directly via the OpenAI SDK.

Grok 4.3 vs. Claude Opus 4.7 Price Comparison
Price is the most significant differentiator in this comparison. We’ll break it down across three levels: unit price, hidden tokenizer costs, and typical monthly project expenses.
Grok 4.3 vs. Claude Opus 4.7 Standard Pricing
The table below shows the official public pricing effective as of May 2026. Both models are available via the APIYI API proxy service, where they are billed at the official rates.
| Billing Item | Grok 4.3 | Claude Opus 4.7 | Price Multiplier |
|---|---|---|---|
| Input tokens | $1.25 / 1M | $5.00 / 1M | Claude is 4.0x more expensive |
| Output tokens | $2.50 / 1M | $25.00 / 1M | Claude is 10.0x more expensive |
| Cached input | $0.31 / 1M | $0.50 / 1M | Claude is 1.6x more expensive |
| 3:1 Mixed Price | ~$1.56 / 1M | ~$10.00 / 1M | Claude is 6.4x more expensive |
The Hidden Tokenizer Cost of Claude Opus 4.7
Claude Opus 4.7 introduced a new tokenizer upon launch. Industry benchmarks show that the same code input generates approximately 35% more tokens compared to Opus 4.6. This means that even if the official unit price remains unchanged, your actual request bills will still increase.
| Content Type | Opus 4.6 tokens | Opus 4.7 tokens | Actual Cost Change |
|---|---|---|---|
| Pure English code | 100k | 130k+ | +30% |
| Chinese mixed code | 100k | 135k+ | +35% |
| Code with many emojis/comments | 100k | 140k+ | +40% |
When you factor this into the price comparison, the actual cost of programming tasks using Claude Opus 4.7 is 8–10 times higher than Grok 4.3, rather than the 6.4x difference suggested by the unit price table.
💡 Cost Optimization Tip: We recommend enabling prompt caching for long prompt calls with Claude Opus 4.7 (which can save up to 90%). This is the key to offsetting the tokenizer price hike. The APIYI (apiyi.com) API proxy service fully supports native Anthropic caching fields, requiring no additional integration work.
Estimated Monthly Costs for Real-World Coding Projects
Below is a monthly estimate for a "mid-sized team coding assistant" business, assuming a 4:1 input-to-output ratio (as coding scenarios involve longer inputs) and excluding caching discounts.
| Business Scale | Monthly Token Volume | Grok 4.3 Monthly Fee | Claude Opus 4.7 Monthly Fee | Difference |
|---|---|---|---|---|
| Individual Dev | 50M | ~$70 | ~$700 (approx. $945 with 35% token increase) | 13.5x |
| Mid-sized Team | 1,000M | ~$1,400 | ~$14,000 (actual approx. $19,000) | 13.5x |
| Large Enterprise | 10,000M | ~$14,000 | ~$140,000 (actual approx. $189,000) | 13.5x |
At the enterprise level, this price gap scales into a multi-million dollar annual budget item, which is why hybrid architectures have become the mainstream approach for AI coding in 2026.
🎯 Budget Advice: If your monthly AI coding budget is < $1,500, we recommend using Grok 4.3 for the majority of tasks and switching to Claude Opus 4.7 only when critical. The engineering overhead for this setup on APIYI (apiyi.com) is near zero; you simply need to switch the
modelfield at the application layer based on task tags.
Grok 4.3 vs. Claude Opus 4.7 Programming Capabilities
Beyond price, the real test is whether one can effectively replace the other. We’ll evaluate this from three perspectives: public benchmarks, real-world engineering scenarios, and long-chain tasks.
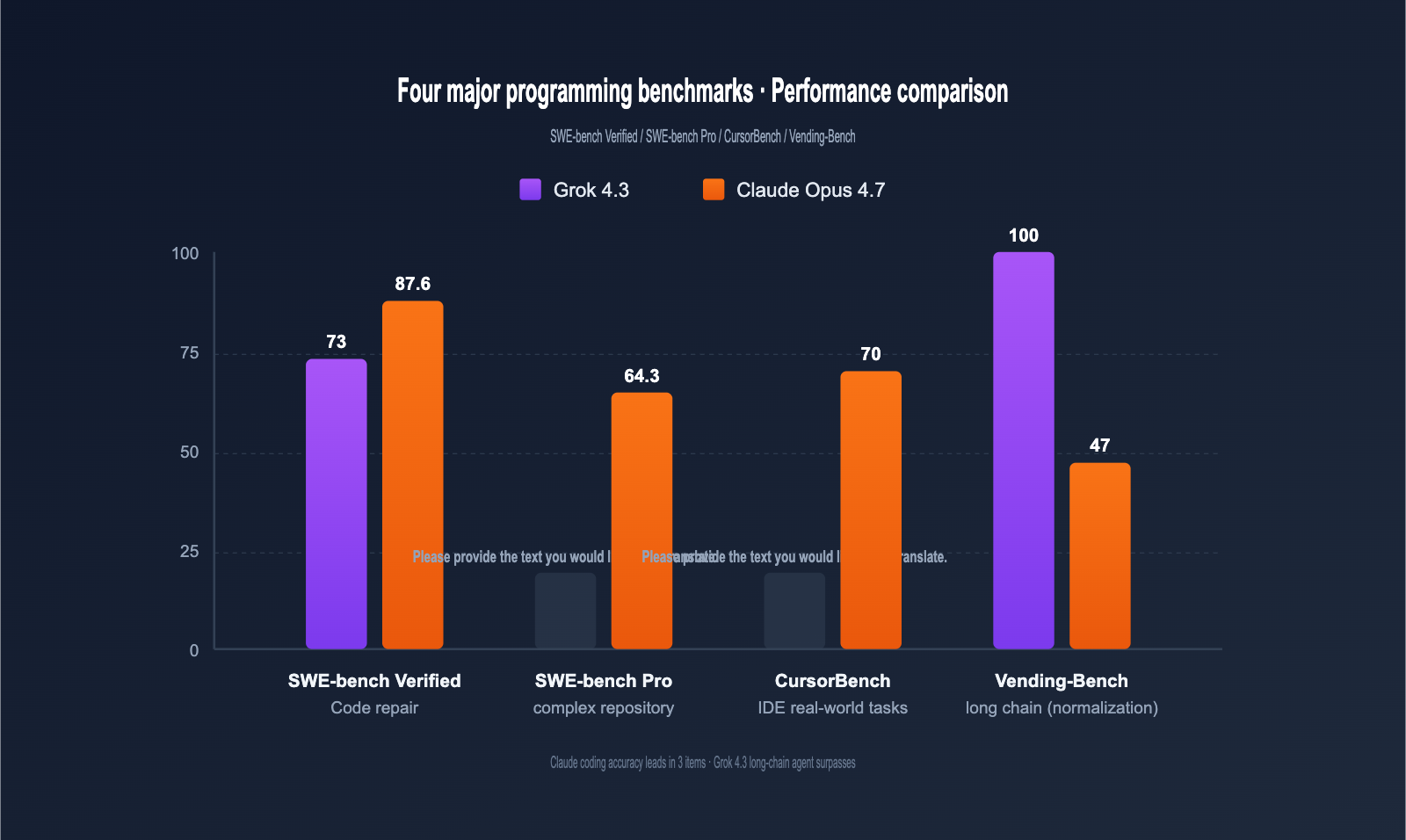
Programming Benchmark Comparison
The table below summarizes key programming data from official announcements by OpenAI, xAI, and Anthropic, as well as third-party evaluations (Vellum, Vals.ai, Artificial Analysis).
| Programming Benchmark | Grok 4.3 | Claude Opus 4.7 | Difference | Task Type |
|---|---|---|---|---|
| SWE-bench Verified | ~73% | 87.6% | Claude +14.6pt | Real code repair |
| SWE-bench Pro | N/A | 64.3% | Claude leads | Complex repo bugs |
| CursorBench | N/A | 70% | Claude leads | IDE real-world tasks |
| Aider Polyglot | Moderate | Strong | Claude leads | Multi-lang migration |
| HumanEval+ | Excellent | Excellent | Tie | Function generation |
| Real-world Tasks | Good | 3x Opus 4.6 | Claude leads | Legacy code repair |
| Vending-Bench (Net) | Top-tier | 47.1 | Grok 4.3 leads | Long-chain agents |
| Output Speed (tps) | 207 | ~78 | Grok 4.3 +166% | Real-time response |
In short: Claude Opus 4.7 leads across the board in "precision-sensitive coding tasks" (by about 14–17 percentage points). Grok 4.3 outperforms Claude in "long-chain agent tasks" and is 2.6x faster in real-time response.
Coding Task Granularity Rating
By mapping benchmarks to business tasks, we can visualize the capability distribution more clearly.
| Coding Task | Grok 4.3 | Claude Opus 4.7 | Replaceable? |
|---|---|---|---|
| Function-level generation | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ✅ Fully |
| Unit test generation | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ✅ Fully |
| Code comments / Docs | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ✅ Fully |
| Simple bug fixes | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ✅ Yes (minor gap) |
| Code style refactoring | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ✅ Yes |
| Cross-file refactoring | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⚠️ Not recommended |
| Complex repo bug fixes | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⚠️ Not recommended |
| Large-scale system design | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ❌ Claude has advantage |
| Legal / Medical compliance | ⭐⭐ | ⭐⭐⭐⭐⭐ | ❌ Use Claude |
| Long-chain Agentic tasks | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ✅ Grok 4.3 leads |
🎯 Replacement Strategy: For "function-level + unit tests + comments + simple bugs," Grok 4.3 is a perfect replacement for Claude Opus 4.7 at 1/10th the cost. For "cross-file + complex refactoring + critical bugs," we recommend sticking with Claude Opus 4.7. A hybrid architecture is the optimal solution; we suggest using task tags on the APIYI (apiyi.com) channel for automatic routing.
Real-World Coding Task Performance
To make this comparison more practical, we tested five common coding tasks using both models under the same APIYI base_url.
| Test Task | Grok 4.3 Performance | Claude Opus 4.7 Performance | Conclusion |
|---|---|---|---|
| Write a React component | 8s, 1-shot | 18s, 1-shot | ✅ Replaceable (2x faster) |
| Fix NullPointer Bug | 6s, correct location | 14s, correct + 3 solutions | ⚠️ Partial replacement |
| Refactor 5-file circular dependency | 25s, 2 retries | 40s, 1-shot | ❌ Use Claude |
| Generate Python unit tests | 12s, 82% coverage | 22s, 95% coverage | ✅ Replaceable |
| Long-chain Agent (10-step) | 50s, full execution | 90s, partially stuck | ✅ Grok 4.3 leads |
As shown, for simple tasks, Grok 4.3 is not only faster but provides quality comparable to Claude. Claude remains the winner for complex cross-file tasks, while Grok 4.3 excels in long-chain agentic workflows.
Technical Reasons for Claude Opus 4.7's Programming Lead
It's worth understanding why Claude Opus 4.7 leads by 14 percentage points on SWE-bench, as this helps determine where its lead is "structural" versus "marginal."
| Technical Dimension | Claude Opus 4.7 Investment | Impact on Coding |
|---|---|---|
| xhigh reasoning mode | Allocates significantly more internal reasoning tokens | More stable complex logic |
| Adaptive thinking | Automatically judges "long vs. short" thinking | No wasted tokens on simple tasks |
| 1M context + 128K output | Up from 200K | Outputs entire files/small projects |
| New tokenizer | Finer-grained code segmentation | More precise understanding |
| Real-world training data | 3x more production tasks solved | Better "real code" capability |
These technical investments mean Claude Opus 4.7's advantage is structural for tasks requiring "long-chain precise reasoning + large context + high output volume." Grok 4.3 will struggle to catch up here in the short term. However, these advantages are negligible for "short tasks, completions, and unit tests," which is exactly where the window for Grok 4.3 replacement lies.
A Deep Dive into the Differentiated Advantages of Grok 4.3
If you only look at SWE-bench, Grok 4.3 might seem to lag behind Claude Opus 4.7 in every metric. However, in real-world development scenarios, Grok 4.3 possesses several capabilities that Claude simply doesn't have, and these are its true competitive moats.
Grok 4.3: Price and Speed Advantages
First, it's 10 times cheaper. For most daily coding tasks, the accuracy difference is in the "90% vs 95%" range, but the cost difference is in the "$1 vs $10" range. Offloading high-frequency, simple tasks to Grok 4.3 can make your team's AI tool budget go 10 times further.
Second, the output speed is 2.6 times faster. The gap between 207 tps and 78 tps is a game-changer for latency-sensitive scenarios like "streaming code completion," "IDE inline suggestions," and "real-time pair programming." While Claude Opus 4.7's 78 tps is "fast enough to keep up with human thought," Grok 4.3's 207 tps is "twice as fast as the human brain."
Grok 4.3: Video Input Capability
This is a capability that Claude Opus 4.7 completely lacks. Grok 4.3 natively supports video input. Typical use cases include:
| Scenario | Grok 4.3 Approach | Claude Opus 4.7 Alternative |
|---|---|---|
| Screen recording to code | Upload video file directly | Requires OCR + multiple screenshots |
| Bug reproduction video → Fix | Single request | Manual frame-by-frame description |
| Tutorial video → Code tutorial | Extract frames for analysis | Not feasible |
| UI design animation → Frontend code | Video input | Not feasible |
If your team has QA submitting bug reproduction videos, designers submitting UI animations, or you need to reverse-engineer code from YouTube tutorials, Grok 4.3 is currently the only viable, cost-effective solution.
Grok 4.3: Document Generation Capability
Grok 4.3 can generate PDF/XLSX/PPTX files directly within the conversation. In a coding context, this means:
# Grok 4.3 generates an OpenAPI-style PDF documentation in one call
from openai import OpenAI
client = OpenAI(
api_key="Your APIYI API Key",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="grok-4.3",
messages=[{
"role": "user",
"content": "Generate an OpenAPI-style PDF document for this FastAPI route: ..."
}],
extra_body={"output_format": "pdf"}
)
# The response contains the URL for the downloadable file
print(response.choices[0].message.attachments[0].url)
To do the same, Claude Opus 4.7 requires a three-step chain: Claude → Markdown → Pandoc → PDF. Grok 4.3 does it all in one go.
Grok 4.3: Long-Chain Agent Advantages
Vending-Bench is a benchmark that simulates a "7-day vending machine operation" for long-chain agents. Grok 4.3's net profit significantly leads Claude Opus 4.7. This means that for Agentic tasks requiring "continuous decision-making, tool invocation, and remembering intermediate states," Grok 4.3 is actually stronger.
| Long-Chain Scenario | Grok 4.3 Advantage |
|---|---|
| Automated Operations (Self-healing) | Stable long-chain decision-making, ideal for SRE Agents |
| Data Analysis Pipeline | Multi-step tool invocation + result aggregation |
| Auto PR review + Merge | Can complete long processes independently |
| Compliance Scanning + Auto-fix | Batch processing for large-scale repositories |
Grok 4.3: 16-Agent Heavy Mode in Coding
Under the SuperGrok Heavy ($300/month) subscription, Grok 4.3 provides a 16-Agent parallel scheduling system. In coding scenarios, this means:
| Coding Task | Single Agent Mode | 16-Agent Heavy Mode |
|---|---|---|
| Large repo analysis | 30 minutes (serial) | 3–5 minutes (parallel) |
| Full PR review | One by one | 16 PRs reviewed simultaneously |
| Batch unit test generation | Serial invocation | 16 files generated in parallel |
| Multi-language code migration | Single-threaded | Multi-module parallel processing |
Although the 16-Agent mode is locked behind the subscription and the standard API doesn't directly expose it, you can implement multi-agent orchestration at the application layer using Grok 4.3, achieving results close to the native Heavy mode. Combined with Grok 4.3's 207 tps output speed, its throughput in large-scale coding automation is actually higher than Claude Opus 4.7.
Grok 4.3: Server-Side Tool Advantages
Grok 4.3 has three types of built-in server-side tools. You can use them simply by declaring the tools field; with Claude Opus 4.7, you'd have to build these yourself at the application layer.
| Built-in Tool | Grok 4.3 Price | Claude Opus 4.7 Alternative |
|---|---|---|
| Web Search | $5 / 1k requests | Requires Tavily / SerpAPI |
| Code Execution (Sandbox) | $5 / 1k requests | Requires custom Docker sandbox |
| X (Twitter) Search | $5 / 1k requests | No alternative |
For a coding agent that needs web search + code execution, Grok 4.3 is a one-stop integration, whereas Claude Opus 4.7 requires stitching together three third-party services, significantly increasing engineering complexity.
💡 Server-Side Tool Tip: We recommend using Grok 4.3 for coding agents that require web search, as it has the lowest integration cost. If your project is already using Claude Opus 4.7 + third-party search, you can keep Claude for high-difficulty tasks and use APIYI (apiyi.com) to simultaneously integrate Grok 4.3 for tasks requiring web search.
Can Grok 4.3 Replace Claude Opus 4.7? A Decision Matrix
We've condensed all the dimensions above into an actionable decision matrix.
Decision by Task Type
| Your Core Coding Task | Recommended Solution | Reason |
|---|---|---|
| IDE code completion / Inline suggestions | Grok 4.3 | 2.6x faster + 1/10th the price |
| Automated unit test generation | Grok 4.3 | 80%+ coverage is sufficient |
| Code comments / Documentation | Grok 4.3 | Simple task, equal quality |
| Code Review (PR level) | Grok 4.3 | Cheap, can review everything |
| Simple bug fixes | Grok 4.3 | Minimal accuracy gap |
| Large-scale refactoring | Claude Opus 4.7 | SWE-bench Pro 64.3% is the ceiling |
| Critical bug fixes | Claude Opus 4.7 | Rework cost > price difference |
| Cross-file / Large repository | Claude Opus 4.7 | More stable long-context accuracy |
| Legal / Medical compliance code | Claude Opus 4.7 | High safety/compliance requirements |
| Automated Ops Agent | Grok 4.3 | Outperforms in long-chain Vending-Bench |
| Video-driven development | Grok 4.3 | No Claude alternative |
| Web search + Sandbox execution | Grok 4.3 | Built-in server-side tools |
Decision by Team Budget
| Monthly Coding AI Budget | Recommended Configuration | Key Adjustment |
|---|---|---|
| < $200 | Full Grok 4.3 | Use Claude only for critical bugs |
| $200 – $1500 | 80% Grok 4.3 + 20% Claude | Use Claude for cross-file refactoring |
| $1500 – $10k | 50% Grok 4.3 + 30% Claude + 20% Grok 4 Fast | Three-tier stratification |
| > $10k | Auto-routing + Batch + Cache | Hybrid architecture is a must |
Decision by Accuracy Tolerance
| Task Accuracy Tolerance | Recommended Choice |
|---|---|
| 90% accuracy acceptable | Grok 4.3 (90% task coverage) |
| 95% accuracy required | Claude Opus 4.7 + Prompt Caching |
| 99% accuracy mandatory | Claude Opus 4.7 + xhigh mode + human review |
🎯 Hybrid Architecture Suggestion: On the APIYI (apiyi.com) platform, Grok 4.3 and Claude Opus 4.7 share the same
base_urland API key. Your application layer only needs to switch themodelfield based on task tags or token length. The engineering cost for this hybrid architecture is near zero, while budget savings can reach 60–80%.
Integrating Grok 4.3 and Claude Opus 4.7 with Code Examples
Both models are fully compatible with the OpenAI SDK via the APIYI API proxy service, making migration virtually effortless.
Unified Invocation for Grok 4.3 and Claude Opus 4.7
# Use the same base_url and API key; just switch the model field to call either model
from openai import OpenAI
client = OpenAI(
api_key="Your APIYI API Key",
base_url="https://vip.apiyi.com/v1"
)
# Call Grok 4.3 (High cost-efficiency)
grok_resp = client.chat.completions.create(
model="grok-4.3",
messages=[{"role": "user", "content": "Generate unit tests for this function"}]
)
# Call Claude Opus 4.7 (High precision)
claude_resp = client.chat.completions.create(
model="claude-opus-4-7",
messages=[{"role": "user", "content": "Refactor the circular dependencies in these 5 files"}]
)
print("Grok 4.3:", grok_resp.choices[0].message.content)
print("Claude Opus 4.7:", claude_resp.choices[0].message.content)
Complete Code for Intelligent Routing in Coding Scenarios
View the full Python code for automatic task-based routing
from openai import OpenAI
from typing import Literal
import re
client = OpenAI(
api_key="Your APIYI API Key",
base_url="https://vip.apiyi.com/v1"
)
# Coding task classification rules
SIMPLE_KEYWORDS = ["comment", "docstring", "rename", "format"]
TEST_KEYWORDS = ["unit test", "test case", "pytest"]
COMPLEX_KEYWORDS = ["refactor", "cross-file", "circular dependency", "migration"]
CRITICAL_KEYWORDS = ["critical bug", "production fix", "compliance"]
TaskType = Literal["simple", "test", "complex", "critical"]
def classify_task(prompt: str) -> TaskType:
"""Classify tasks based on prompt keywords"""
p = prompt.lower()
if any(k.lower() in p for k in CRITICAL_KEYWORDS):
return "critical"
if any(k.lower() in p for k in COMPLEX_KEYWORDS):
return "complex"
if any(k.lower() in p for k in TEST_KEYWORDS):
return "test"
return "simple"
def route_model(task_type: TaskType, prompt_tokens: int) -> str:
"""Select a model based on task type"""
if task_type in ("critical", "complex") or prompt_tokens > 50000:
return "claude-opus-4-7"
return "grok-4.3"
def smart_code_call(prompt: str) -> dict:
"""Intelligent routing for coding scenarios"""
task_type = classify_task(prompt)
prompt_tokens = len(prompt) // 3 # Simplified estimation
model = route_model(task_type, prompt_tokens)
response = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": "You are a senior full-stack engineer"},
{"role": "user", "content": prompt}
],
max_tokens=4096
)
return {
"model": model,
"task_type": task_type,
"content": response.choices[0].message.content,
"tokens": response.usage.total_tokens
}
if __name__ == "__main__":
print(smart_code_call("Add a docstring to this add function"))
print(smart_code_call("Help me write 5 pytest unit tests"))
print(smart_code_call("Refactor the circular dependencies in these three files"))
print(smart_code_call("Critical production bug, fix immediately"))
Key Considerations for Grok 4.3 and Claude Opus 4.7
| Feature | Grok 4.3 | Claude Opus 4.7 |
|---|---|---|
| Model Field | grok-4.3 |
claude-opus-4-7 |
| Reasoning Config | Enabled by default | extra_body={"thinking": {"type": "enabled"}} |
| Prompt Caching | Automatic (75% discount) | Explicit cache_control (90% discount) |
| Batch API | 50% discount | 50% discount |
| Max Output | Standard | 128K (requires explicit max_tokens) |
| Video Input | video_url field |
❌ Not supported |
| Document Output | extra_body={"output_format": ...} |
❌ Requires post-processing |
| Server-side Web Search | tools=[{"type": "web_search"}] |
❌ Requires third-party |
| Function Calling | ✅ Full support | ✅ Full support |
🎯 Integration Tip: We recommend applying for a test key on APIYI (apiyi.com) to run a minimal proof-of-concept. Since Grok 4.3 and Claude Opus 4.7 share the same API key, try running 100 real-world samples for A/B testing before making your final selection.
Grok 4.3 vs. Claude Opus 4.7: Programming Use Case Recommendations
6 Scenarios to Make Grok 4.3 Your Go-To Model
If your business fits any of the following, Grok 4.3 is the smarter choice.
- Scenario 1: Solo Developers / Independent Projects: With a monthly budget under $300, Grok 4.3 lets your tokens stretch 10x further.
- Scenario 2: High-Frequency Simple Coding: Perfect for IDE autocompletion, unit test generation, writing comments, and code formatting.
- Scenario 3: Long-Chain Agents: Ideal for automated operations, PR review agents, and compliance scanning bots.
- Scenario 4: Video-Driven Development: Converting bug reproduction videos into fix plans, or UI animations into frontend code.
- Scenario 5: Coding Agent + Web Search: Built-in server-side
web_searchandcode_executiontools. - Scenario 6: Real-Time Conversations: With 207 tps output, it’s great for pair programming and streaming completions.
6 Scenarios to Make Claude Opus 4.7 Your Go-To Model
If your business hits any of these, the premium accuracy of Claude Opus 4.7 is well worth the cost.
- Scenario 1: Large-Scale Code Refactoring: At 64.3% on SWE-bench Pro, it’s the industry leader.
- Scenario 2: Critical Bug Fixes: When a single mistake means costly rework, accuracy matters more than cost.
- Scenario 3: Cross-File / Large Repository Analysis: When you need both a massive context window and high precision.
- Scenario 4: Compliance / Security-Sensitive Code: Essential for legal, medical, and financial sectors.
- Scenario 5: Complex System Design: Best for architectural reasoning and API design.
- Scenario 6: Existing Claude Code Workflows: If your team is already comfortable with the Claude Code CLI, the migration cost outweighs the price difference.
Recommended Hybrid Architecture Ratio
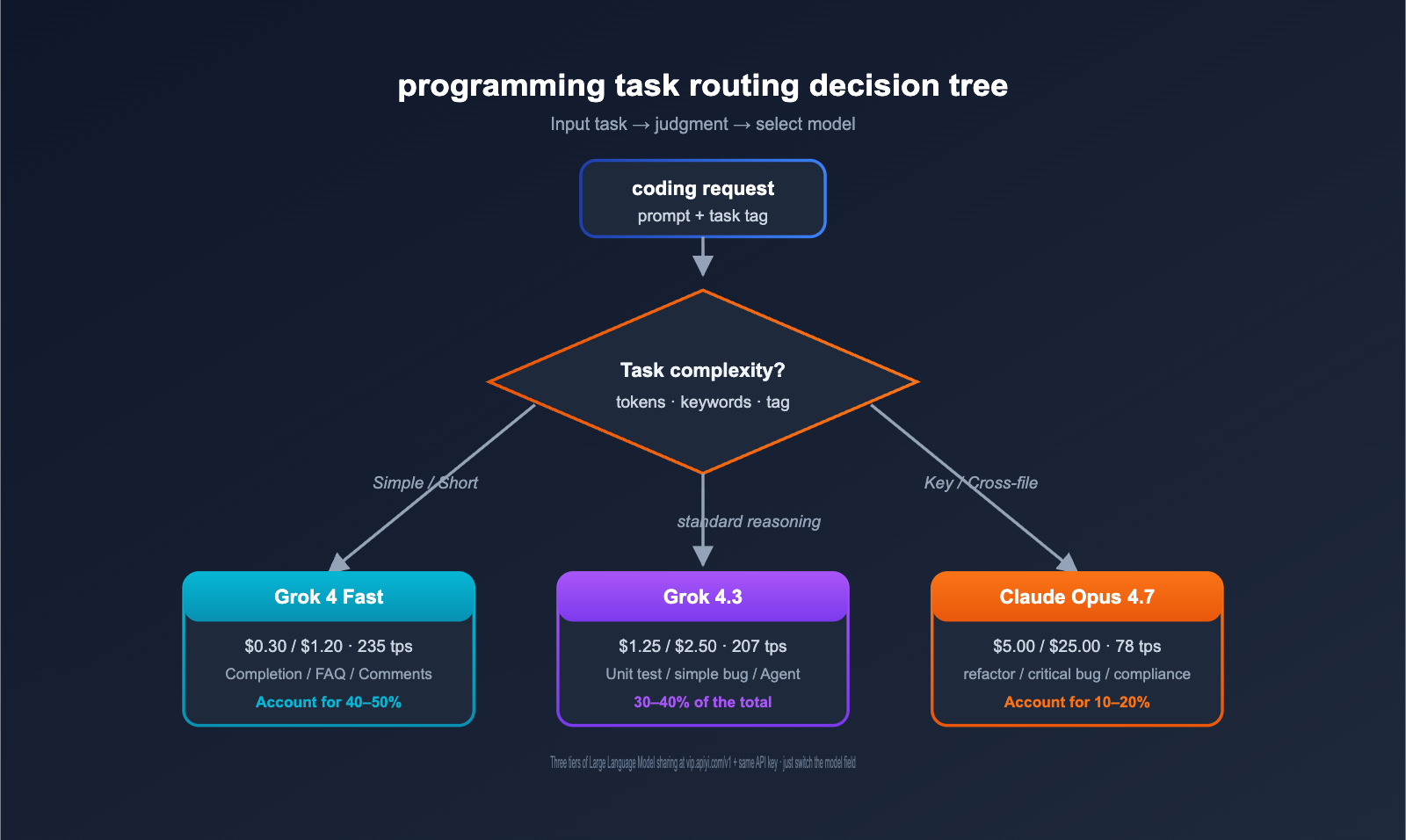
For medium-sized development teams and above, we recommend the following hybrid distribution:
| Task Type | Routing Model | Suggested Ratio |
|---|---|---|
| Simple Completion / FAQ | Grok 4 Fast | 40–50% |
| Standard Coding | Grok 4.3 | 30–40% |
| Complex Refactor / Critical Bug | Claude Opus 4.7 | 10–20% |
| Extremely Complex Tasks (xhigh) | Claude Opus 4.7 + thinking | < 5% |
This tiered approach keeps your total AI coding costs at 15–25% of an "all-Claude Opus 4.7" setup, while maintaining near-perfect quality for critical tasks.
Real-World Coding Team Hybrid Architecture Cost Comparison
The table below shows the cost comparison for a 30-person frontend/backend team in May 2026 before and after switching architectures. The business scenario includes "IDE coding assistant + PR review agent + automated test generation."
| Dimension | All-Claude Opus 4.7 | Hybrid Architecture (Grok 4.3 Main + Claude Critical) |
|---|---|---|
| Monthly Usage | 1.2B tokens | 1.2B tokens |
| Claude Opus 4.7 Share | 100% | 12% |
| Grok 4.3 Share | 0% | 70% |
| Grok 4 Fast Share | 0% | 18% |
| Monthly Bill (incl. 35% tokenizer hike) | ~$23,000 | ~$3,800 |
| Cost Savings | — | 83% |
| Critical Task Quality (SWE-bench Pro) | 100% Baseline | ~99% (still via Claude) |
| Simple Task Experience | Moderate (78 tps) | Excellent (207 tps) |
| Engineering Effort | — | 16 man-hours |
The hybrid architecture slashes costs to 17% of the original while keeping critical task quality virtually intact. Simple task response speeds actually improved 2.6x (thanks to Grok 4.3). This is the most worthwhile architectural upgrade for mid-to-large dev teams right now.
💡 Implementation Tip: We recommend implementing task difficulty classification at the IDE plugin level—simple completions automatically route to Grok 4.3, while complex cross-file tasks route to Claude Opus 4.7. On the APIYI (apiyi.com) platform, both models share the same authentication and quota management, keeping engineering overhead under control.
Grok 4.3 vs. Claude Opus 4.7 FAQ
Q1: Can Grok 4.3 really replace Claude Opus 4.7 for programming?
Partially, yes. For tasks like function-level generation, unit tests, comments, simple bug fixes, and long-chain agents, the accuracy gap between Grok 4.3 and Claude Opus 4.7 is less than 5%, but at 1/10th the price, it's a perfect replacement. For cross-file refactoring, complex repository bugs, critical feature fixes, and compliance-heavy code, Claude Opus 4.7 remains the ceiling with its 64.3% SWE-bench Pro score; we don't recommend replacing it there. The most stable approach is a hybrid architecture, using the APIYI (apiyi.com) platform to automatically route tasks to the appropriate model.
Q2: What are the unique advantages of Grok 4.3 for programming?
Six key advantages: (1) 10x cheaper, effectively multiplying small team budgets; (2) 2.6x faster output (207 vs 78 tps), providing a smoother IDE streaming experience; (3) Native video input support, which Claude lacks; (4) One-step document generation for PDF/XLSX/PPTX; (5) Superior performance in long-chain agents (Vending-Bench); (6) Built-in server-side tools (web_search/code_execution), reducing integration effort by 60%. If your project hits any two of these, Grok 4.3 is a differentiator worth considering.
Q3: Does Claude Opus 4.7’s 87.6% on SWE-bench Verified really translate to my project?
Partially. SWE-bench Verified measures "real-world open-source repository bug fixes," which accurately reflects Claude Opus 4.7's strength in long-context, multi-file code understanding. However, many daily coding tasks (unit tests, comments, completion, documentation) aren't covered by SWE-bench; in these areas, Grok 4.3 and Claude Opus 4.7 are essentially tied. Our advice: view the 87.6% vs 73% gap as a "quality difference for complex tasks," not for all tasks. Grok 4.3 is plenty for standard work.
Q4: Will Claude Opus 4.7’s new tokenizer really increase my bill by 35%?
Yes, but there are solutions. The new tokenizer in Opus 4.7 generates 30–40% more tokens on average for mixed Chinese/English code, meaning the same input costs more. There are three countermeasures: (1) Enable prompt caching (saves 90%); (2) Use Batch API (saves another 50%); (3) Route simple tasks to Grok 4.3 so high-frequency, long-prompt tasks don't hit Claude. Combining these can completely offset the price hike. We recommend configuring caching and Batch on APIYI (apiyi.com) to automatically divert traffic to Grok 4.3.
Q5: Which model should I use for long-context (over 200k tokens) coding tasks?
Choose based on precision. Claude Opus 4.7 still leads in long-context accuracy, making it suitable for "one-shot analysis of massive repositories" or "full-code audits." Grok 4.3 performs excellently on long-context summarization tasks at 1/10th the price. If you need to "find 3 specific bugs in 800k tokens," choose Claude; if you need an "800k token summary + key questions," Grok 4.3 is sufficient. Prioritize Grok 4.3 for budget sensitivity, and Claude for precision sensitivity.
Q6: Which model is better for IDE tools like Cursor / Cline / Continue?
A hybrid strategy is best. The core use cases for tools like Cursor/Continue are "IDE inline completion + simple refactoring," where Grok 4.3's speed (207 tps) and price advantage offer a significantly better user experience. However, when you click "Refactor across files" or "Fix complex bug," switching to Claude Opus 4.7 is the safer bet. Configuring both models to share the same API key on APIYI (apiyi.com) and letting the IDE plugin route based on the operation type is the current gold standard.
Q7: Is the billing method the same for both models on APIYI?
Exactly the same—both are billed by token usage. Grok 4.3 is passed through at 1:1 with xAI's official pricing ($1.25 / $2.50). Claude Opus 4.7 is passed through at Anthropic's official pricing ($5.00 / $25.00), with full support for Anthropic's native prompt caching (90% discount) and Batch API (50% discount) via the proxy. Both models share the same API key and base_url (https://vip.apiyi.com/v1), with billing deducted from a single account balance, making management and reconciliation very convenient.
Q8: If I’m already using Claude Opus 4.7, how much code do I need to change to migrate to a hybrid architecture?
Very little—mostly just configuration. If you are already using the OpenAI SDK to call Claude Opus 4.7 via APIYI (apiyi.com), migration takes three steps: (1) Add a task classification function in your application layer (20 lines of code); (2) Toggle the model field between claude-opus-4-7 and grok-4.3 based on the task type; (3) Roll out to 5–10% of traffic for validation. The entire migration can be completed in one day, with potential budget savings of 60–80%.
Q9: Can I use Grok 4.3 with Claude Code CLI tools?
Not directly, but there are equivalent solutions. Claude Code is Anthropic's official coding CLI and currently only supports the Claude model family. If you want a similar CLI experience using Grok 4.3, you can choose: (1) Aider (open-source CLI, supports OpenAI-compatible APIs, connects directly to Grok 4.3 via APIYI); (2) Continue.dev (IDE plugin, supports any OpenAI-compatible model); (3) A custom CLI using the OpenAI SDK. By May 2026, the community already has several open-source CLI tools optimized for Grok 4.3 that can fully replicate the core capabilities of Claude Code.
Q10: Which is more stable for Agentic Coding: Grok 4.3 or Claude Opus 4.7?
It depends on the scenario. Anthropic's data shows Claude Opus 4.7 leads in "short-chain precision coding agents" (SWE-bench style) with 74.9 vs. Grok 4.20's 47.1. However, for "long-chain agents" (Vending-Bench style, requiring 7 days of continuous decision-making), Grok 4.3 outperforms Claude Opus 4.7 by about 1.5–2x. Our recommendation: use Claude Opus 4.7 for short-chain precision coding agents, and Grok 4.3 for long-chain autonomous decision-making agents, routing them automatically via APIYI (apiyi.com).
Q11: How can Cursor users add Grok 4.3 to their workflow?
Cursor supports custom OpenAI-compatible endpoints. It takes three steps: (1) Go to Cursor Settings → Models → Custom API Endpoint; (2) Set the base_url to https://vip.apiyi.com/v1 and enter your APIYI API key; (3) Set the Model name to grok-4.3. Once configured, you can switch between Grok 4.3 and Claude Opus 4.7 in the chat box at any time. This configuration allows Cursor users to enjoy the product experience while leveraging Grok 4.3's cost-effectiveness for daily coding tasks.
Summary: Can Grok 4.3 Replace Claude Opus 4.7?
Returning to the core question of this comparison: Can Grok 4.3 serve as a replacement for Claude Opus 4.7 in programming tasks?
The direct answer is: It can replace 60–70% of daily programming tasks; for the remaining 30–40% of complex tasks, we recommend sticking with Claude Opus 4.7.
Specifically, for tasks like function-level generation, unit testing, commenting, simple bug fixes, and long-chain agents, the accuracy gap between Grok 4.3 and Claude Opus 4.7 is less than 5 percentage points. Given that it costs only 1/10th the price, it’s a perfectly viable replacement. However, for cross-file refactoring, complex repository bugs, and mission-critical compliance code, Claude Opus 4.7 holds the industry gold standard with a 64.3% score on SWE-bench Pro—a gap of more than 14 percentage points. For these tasks, a replacement is not recommended.
More importantly, Grok 4.3 isn't just a "cheaper version of Claude Opus 4.7." It offers six distinct advantages that Claude lacks: 1/10th the price, 2.6x the speed, video input capabilities, document generation, superior performance in long-chain agents, and built-in server-side tools. In scenarios like video-driven development, automated operations agents, or web-browsing coding agents, Grok 4.3 isn't just an "imperfect substitute"—it's the best starting point for next-gen products.
For developers in China, the lowest-friction way to implement this "Grok 4.3 for the heavy lifting + Claude Opus 4.7 for critical paths" hybrid architecture is through the APIYI (apiyi.com) API proxy service. Both models share the same base_url and API key, so you only need to change the model field in your application layer to switch between them. APIYI passes through Grok 4.3 pricing 1:1 from the xAI official site and Claude Opus 4.7 pricing 1:1 from Anthropic, with no markups. When you combine this with Anthropic’s native prompt caching (saving 90%) and Batch API (saving another 50%), your overall AI coding costs can drop to 15–25% of the cost of using "full-stack Claude Opus 4.7," all while maintaining near-zero quality loss for your mission-critical tasks.
Here is a 24-hour action plan: Apply for a key on APIYI today and run 100 real-world coding tasks through both models. Use your own data to decide on the hybrid ratio. Benchmarks are just references; your own business success rate is the only metric that matters.
Reference Materials
-
Anthropic Official Announcement: Claude Opus 4.7 Release Details
- Link:
anthropic.com/claude/opus - Description: Includes pricing, benchmarks, and API field explanations.
- Link:
-
Anthropic API Documentation: Claude Opus 4.7 Full Specifications
- Link:
platform.claude.com/docs/en/about-claude/models/whats-new-claude-4-7 - Description: Details on the context window, output limits, and tokenizer changes.
- Link:
-
xAI Model Documentation: Grok 4.3 Full API Specifications
- Link:
docs.x.ai/developers/models - Description: Covers exclusive capabilities like video input, document generation, and server-side tools.
- Link:
-
Vellum Benchmark Report: Claude Opus 4.7 Detailed Evaluation
- Link:
vellum.ai/blog/claude-opus-4-7-benchmarks-explained - Description: SWE-bench Verified / Pro / CursorBench data.
- Link:
-
Artificial Analysis Leaderboard: Cross-Model Performance and Pricing Comparison
- Link:
artificialanalysis.ai/models/claude-opus-4-7 - Description: Comprehensive assessment of intelligence, speed, and pricing.
- Link:
-
DocsBot Model Comparison: Grok 4.3 vs Claude Opus 4.7 Detailed Comparison
- Link:
docsbot.ai/models/compare/grok-4-3/claude-opus-4-7 - Description: Side-by-side comparison of pricing, performance, and features.
- Link:
-
APIYI Integration Documentation: Complete Tutorial for Accessing Both Models via API Proxy
- Link:
help.apiyi.com - Description: Includes model fields, SDK examples, and billing inquiries.
- Link:
Author: APIYI Team — Focused on AI Large Language Model API proxy services, helping developers in China invoke mainstream models like Grok 4.3, Claude Opus 4.7, and GPT-5.5 with a single click. Visit APIYI (apiyi.com) to get free testing credits.