Erhalten Sie beim Aufrufen der Modelle Gemini 3.0 Pro Preview oder gemini-3-flash-preview den Fehler thinking_budget and thinking_level are not supported together? Dies ist ein Kompatibilitätsproblem, das durch Parameter-Upgrades der Google Gemini API zwischen verschiedenen Modellversionen verursacht wird. In diesem Artikel analysieren wir die Ursache dieses Fehlers aus der Perspektive der API-Design-Evolution und zeigen Ihnen die korrekten Konfigurationsmethoden.
Zentraler Nutzen: Nach der Lektüre dieses Artikels werden Sie die korrekte Konfiguration der Denkmodus-Parameter für Gemini 2.5- und 3.0-Modelle beherrschen, häufige API-Aufruffehler vermeiden und die Inferenzleistung sowie die Kostenkontrolle optimieren.

Kernelemente der Evolution der Gemini API Denkmodus-Parameter
| Modellversion | Empfohlener Parameter | Datentyp | Konfigurationsbeispiel | Anwendungsfall |
|---|---|---|---|---|
| Gemini 2.5 Flash/Flash-Lite | thinking_budget |
Integer oder -1 | thinking_budget: 0 (deaktiviert)thinking_budget: -1 (dynamisch) |
Präzise Kontrolle des Denk-Token-Budgets |
| Gemini 3.0 Pro/Flash | thinking_level |
Enum-Wert | thinking_level: "minimal"/"low"/"medium"/"high" |
Vereinfachte Konfiguration nach Szenario |
| Kompatibilitätshinweis | ⚠️ Nicht gleichzeitig verwenden | – | Das Senden beider Parameter führt zu einem 400-Fehler | Wählen Sie einen Parameter basierend auf der Modellversion |
Kernunterschiede der Gemini Denkmodus-Parameter
Der Hauptgrund für die Einführung des Parameters thinking_level in Gemini 3.0 durch Google ist die Vereinfachung der Konfigurationserfahrung für Entwickler. Während thinking_budget in Gemini 2.5 verlangt, dass Entwickler die Anzahl der Denk-Token präzise schätzen, abstrahiert thinking_level in Gemini 3.0 diese Komplexität in vier semantische Stufen, was die Einstiegshürde für die Konfiguration senkt.
Diese Designänderung spiegelt die Abwägung von Google bei der API-Entwicklung wider: Ein gewisses Maß an Feinsteuerung wird zugunsten einer besseren Benutzerfreundlichkeit und Konsistenz über verschiedene Modelle hinweg geopfert. Für die meisten Anwendungsszenarien ist die Abstraktion durch thinking_level völlig ausreichend. Nur wenn eine extreme Kostenoptimierung oder eine spezifische Kontrolle des Token-Budgets erforderlich ist, sollte man auf thinking_budget zurückgreifen.
💡 Technischer Rat: Für die praktische Entwicklung empfehlen wir, Schnittstellentests über die Plattform APIYI (apiyi.com) durchzuführen. Diese Plattform bietet eine vereinheitlichte API-Schnittstelle und unterstützt Modelle wie Gemini 2.5 Flash, Gemini 3.0 Pro und Gemini 3.0 Flash. Dies hilft Ihnen, die tatsächlichen Auswirkungen und Kostenunterschiede verschiedener Denkmodus-Konfigurationen schnell zu validieren.
Grundursache des Fehlers: Strategie zur Aufwärtskompatibilität beim Parameterdesign
Analyse der API-Fehlermeldung
{
"status_code": 400,
"error": {
"message": "Unable to submit request because thinking_budget and thinking_level are not supported together.",
"type": "upstream_error",
"code": 400
}
}
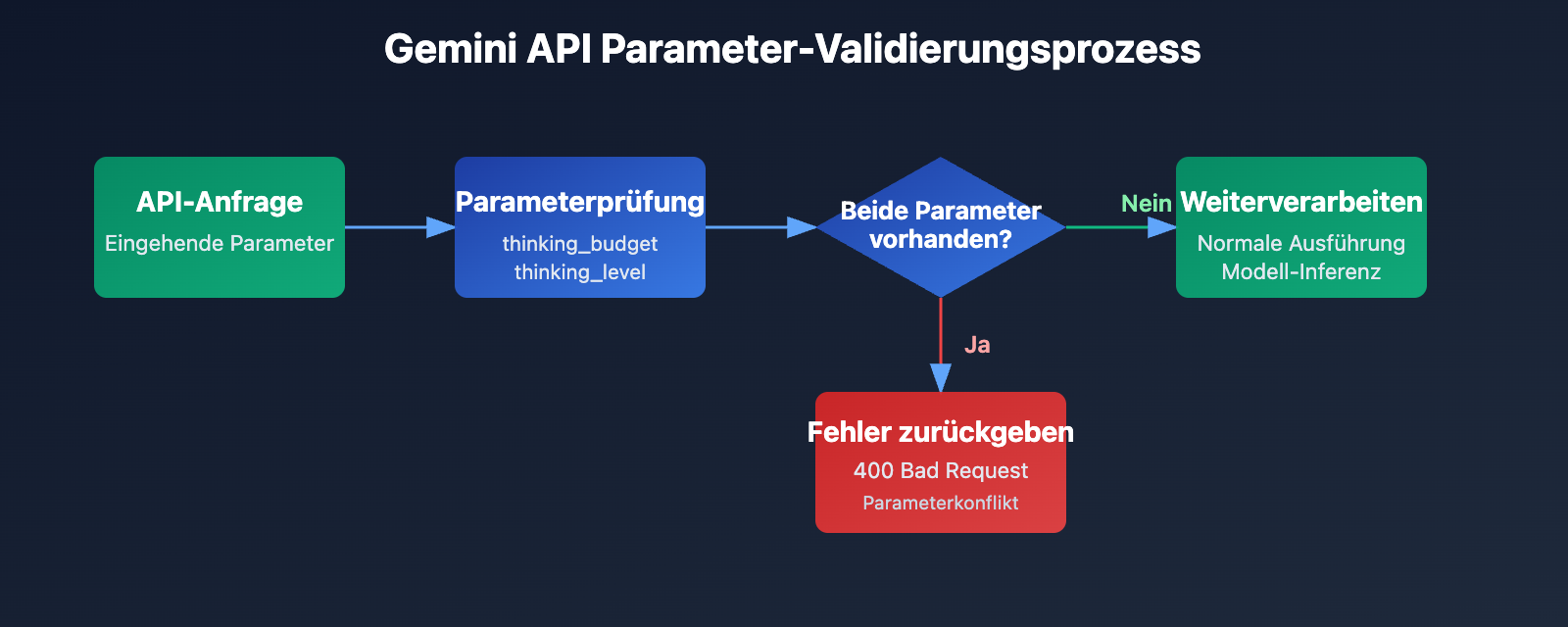
Der Kern dieser Fehlermeldung ist, dass thinking_budget und thinking_level nicht gleichzeitig existieren dürfen. Als Google neue Parameter in Gemini 3.0 einführte, wurden die alten Parameter nicht sofort entfernt, sondern eine Exklusivitätsstrategie angewandt:
- Gemini 2.5 Modelle: Akzeptieren nur
thinking_budget, ignorierenthinking_level. - Gemini 3.0 Modelle: Bevorzugen
thinking_level, akzeptieren aber auchthinking_budgetzur Abwärtskompatibilität. Es dürfen jedoch niemals beide gleichzeitig übergeben werden. - Fehlerauslöser: Die API-Anfrage enthält sowohl den Parameter
thinking_budgetals auchthinking_level.
Warum tritt dieser Fehler auf?
Entwickler stoßen normalerweise in den folgenden drei Szenarien auf diesen Fehler:
| Szenario | Ursache | Typisches Code-Merkmal |
|---|---|---|
| Szenario 1: Automatische Befüllung durch das SDK | Einige KI-Frameworks (wie LiteLLM, AG2) füllen Parameter basierend auf dem Modellnamen automatisch aus, was zur gleichzeitigen Übergabe beider Parameter führt. | Verwendung eines gekapselten SDKs, ohne den tatsächlichen Request-Body zu prüfen. |
| Szenario 2: Hardcodierte Konfiguration | thinking_budget wurde fest im Code programmiert. Beim Wechsel auf ein Gemini 3.0 Modell wurde der Parametername nicht aktualisiert. |
Zuweisung beider Parameter in Konfigurationsdateien oder im Code. |
| Szenario 3: Fehleinschätzung von Modell-Aliasen | Verwendung von Aliasen wie gemini-flash-preview, die tatsächlich auf Gemini 3.0 verweisen, aber mit Gemini 2.5 Parametern konfiguriert wurden. |
Modellname enthält preview oder latest, aber die Parameterkonfiguration wurde nicht synchronisiert. |
🎯 Auswahl-Tipp: Wenn Sie die Version des Gemini-Modells wechseln, empfehle ich, die Parameterkompatibilität zuerst über die Plattform APIYI (apiyi.com) zu testen. Diese Plattform unterstützt den schnellen Wechsel zwischen den Serien Gemini 2.5 und 3.0, was es einfach macht, die Antwortqualität und Latenzunterschiede verschiedener Denkmodus-Konfigurationen zu vergleichen und Parameterkonflikte in der Produktion zu vermeiden.
3 Lösungen: Den richtigen Parameter passend zur Modellversion wählen
Lösung 1: Konfiguration für Gemini 2.5 (Verwendung von thinking_budget)
Geeignete Modelle: gemini-2.5-flash, gemini-2.5-pro usw.
Parameter-Details:
thinking_budget: 0– Deaktiviert den Denkmodus vollständig (geringste Latenz und Kosten).thinking_budget: -1– Dynamischer Denkmodus, das Modell passt sich der Komplexität der Anfrage an.thinking_budget: <positive Ganzzahl>– Legt die Obergrenze der Thinking-Token präzise fest.
Minimalistisches Beispiel
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gemini-2.5-flash-preview-04-17",
messages=[{"role": "user", "content": "Erkläre das Prinzip der Quantenverschränkung"}],
extra_body={
"thinking_budget": -1 # Dynamischer Denkmodus
}
)
print(response.choices[0].message.content)
Vollständigen Code anzeigen (inkl. Extraktion der Denkprozesse)
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gemini-2.5-flash-preview-04-17",
messages=[{"role": "user", "content": "Erkläre das Prinzip der Quantenverschränkung"}],
extra_body={
"thinking_budget": -1, # Dynamischer Denkmodus
"include_thoughts": True # Rückgabe der Denk-Zusammenfassung aktivieren
}
)
# Denkprozesse extrahieren (falls aktiviert)
for part in response.choices[0].message.content:
if hasattr(part, 'thought') and part.thought:
print(f"Denkprozess: {part.text}")
# Finale Antwort extrahieren
final_answer = response.choices[0].message.content
print(f"Finale Antwort: {final_answer}")
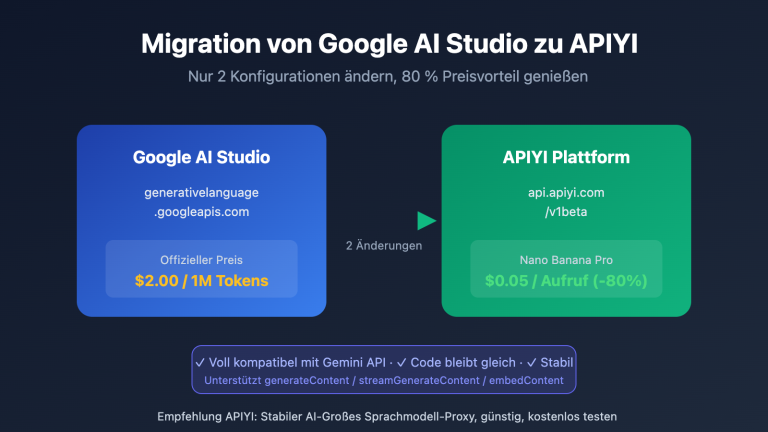
Hinweis: Gemini 2.5 Modelle werden am 3. März 2026 eingestellt. Es wird empfohlen, frühzeitig auf die Gemini 3.0 Serie zu migrieren. Über die Plattform APIYI (apiyi.com) können Sie Qualitätsunterschiede vor und nach der Migration schnell vergleichen.
Lösung 2: Konfiguration für Gemini 3.0 (Verwendung von thinking_level)
Geeignete Modelle: gemini-3.0-flash-preview, gemini-3.0-pro-preview
Parameter-Details:
thinking_level: "minimal"– Minimales Denken, nahezu Null-Budget, erfordert die Übergabe von Denk-Signaturen (Thought Signatures).thinking_level: "low"– Geringe Denkintensität, geeignet für einfache Anweisungsfolge und Chat-Szenarien.thinking_level: "medium"– Mittlere Denkintensität, geeignet für allgemeine Reasoning-Aufgaben (nur von Gemini 3.0 Flash unterstützt).thinking_level: "high"– Hohe Denkintensität, maximiert die Reasoning-Tiefe, geeignet für komplexe Probleme (Standardwert).
Minimalistisches Beispiel
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gemini-3.0-flash-preview",
messages=[{"role": "user", "content": "Analysiere die Zeitkomplexität dieses Codes"}],
extra_body={
"thinking_level": "medium" # Mittlere Denkintensität
}
)
print(response.choices[0].message.content)
Vollständigen Code anzeigen (inkl. Übergabe von Denk-Signaturen)
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
# Erste Dialogrunde
response_1 = client.chat.completions.create(
model="gemini-3.0-flash-preview",
messages=[{"role": "user", "content": "Entwirf einen LRU-Cache-Algorithmus"}],
extra_body={
"thinking_level": "high",
"include_thoughts": True
}
)
# Denk-Signaturen extrahieren (Gemini 3.0 gibt diese automatisch zurück)
thought_signatures = []
for part in response_1.choices[0].message.content:
if hasattr(part, 'thought_signature'):
thought_signatures.append(part.thought_signature)
# Zweite Dialogrunde, Übergabe der Signaturen zur Aufrechterhaltung der Reasoning-Kette
response_2 = client.chat.completions.create(
model="gemini-3.0-flash-preview",
messages=[
{"role": "user", "content": "Entwirf einen LRU-Cache-Algorithmus"},
{"role": "assistant", "content": response_1.choices[0].message.content, "thought_signatures": thought_signatures},
{"role": "user", "content": "Optimiere die Speicherkomplexität dieses Algorithmus"}
],
extra_body={
"thinking_level": "high"
}
)
print(response_2.choices[0].message.content)
💰 Kostenoptimierung: Für budgetsensible Projekte empfiehlt es sich, die Gemini 3.0 Flash API über die Plattform APIYI (apiyi.com) aufzurufen. Diese bietet flexible Abrechnungsmodelle und günstigere Preise, ideal für kleine bis mittlere Teams und Einzelentwickler. In Kombination mit
thinking_level: "low"lassen sich die Kosten weiter senken.
Lösung 3: Strategie zur Parameteranpassung bei dynamischem Modellwechsel
Anwendungsfall: Wenn Ihr Code gleichzeitig Gemini 2.5 und 3.0 Modelle unterstützen muss.
Intelligente Funktion zur Parameteranpassung
def get_thinking_config(model_name: str, complexity: str = "medium") -> dict:
"""
Wählt automatisch den richtigen Denkmodus-Parameter basierend auf der Modellversion.
Args:
model_name: Name des Gemini-Modells
complexity: Denk-Komplexität ("minimal", "low", "medium", "high", "dynamic")
Returns:
Ein Dictionary mit Parametern für extra_body
"""
# Gemini 3.0 Modell-Liste
gemini_3_models = [
"gemini-3.0-flash-preview",
"gemini-3.0-pro-preview",
"gemini-3-flash",
"gemini-3-pro"
]
# Gemini 2.5 Modell-Liste
gemini_2_5_models = [
"gemini-2.5-flash-preview-04-17",
"gemini-2.5-flash-lite",
"gemini-2-flash",
"gemini-2-flash-lite"
]
# Modellversion bestimmen
if any(m in model_name for m in gemini_3_models):
# Gemini 3.0 verwendet thinking_level
level_map = {
"minimal": "minimal",
"low": "low",
"medium": "medium",
"high": "high",
"dynamic": "high" # Standardmäßig hoch
}
return {"thinking_level": level_map.get(complexity, "medium")}
elif any(m in model_name for m in gemini_2_5_models):
# Gemini 2.5 verwendet thinking_budget
budget_map = {
"minimal": 0,
"low": 512,
"medium": 2048,
"high": 8192,
"dynamic": -1
}
return {"thinking_budget": budget_map.get(complexity, -1)}
else:
# Unbekanntes Modell, standardmäßig Gemini 3.0 Parameter verwenden
return {"thinking_level": "medium"}
# Anwendungsbeispiel
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
model = "gemini-3.0-flash-preview" # Dynamisch umschaltbar
thinking_config = get_thinking_config(model, complexity="high")
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": "Ihre Frage"}],
extra_body=thinking_config
)

| Denk-Komplexität | Gemini 2.5 (thinking_budget) | Gemini 3.0 (thinking_level) | Empfohlenes Szenario |
|---|---|---|---|
| Minimal | 0 |
"minimal" |
Einfache Anweisungen, hoher Durchsatz |
| Niedrig | 512 |
"low" |
Chatbots, leichtgewichtiges QA |
| Mittel | 2048 |
"medium" |
Allgemeines Reasoning, Codegenerierung |
| Hoch | 8192 |
"high" |
Komplexe Probleme, Tiefenanalyse |
| Dynamisch | -1 |
"high" (Standard) |
Automatische Komplexitätsanpassung |
🚀 Schnellstart: Wir empfehlen die Plattform APIYI (apiyi.com) für den schnellen Aufbau von Prototypen. Sie bietet sofort einsatzbereite Gemini API-Schnittstellen ohne komplexe Konfiguration. In nur 5 Minuten ist die Integration abgeschlossen und Sie können per Mausklick zwischen verschiedenen Denkmodus-Parametern wechseln, um die Ergebnisse zu vergleichen.
Detaillierte Erläuterung des Gemini 3.0 Thought Signatures Mechanismus
Was sind Thought Signatures?
Die in Gemini 3.0 eingeführten Thought Signatures (Gedankensignaturen) sind verschlüsselte Repräsentationen der internen Schlussfolgerungsprozesse (Reasoning) des Modells. Wenn Sie include_thoughts: true aktivieren, gibt das Modell eine verschlüsselte Signatur des Denkprozesses in der Antwort zurück. Diese Signaturen können Sie in nachfolgenden Dialogen übergeben, damit das Modell die Kontinuität der Reasoning-Kette beibehält.
Kernmerkmale:
- Verschlüsselte Darstellung: Der Inhalt der Signatur ist nicht lesbar und kann nur vom Modell selbst analysiert werden.
- Erhalt der Reasoning-Kette: Durch die Übergabe von Signaturen in Multi-Turn-Dialogen kann das Modell auf Basis seiner vorherigen Überlegungen weiter schlussfolgern.
- Automatische Rückgabe: Gemini 3.0 gibt Thought Signatures standardmäßig zurück, auch wenn diese nicht explizit angefordert wurden.
Praktische Anwendungsszenarien für Thought Signatures
| Szenario | Signatur-Übergabe erforderlich? | Erläuterung |
|---|---|---|
| Single-Turn Q&A | ❌ Nicht erforderlich | Isolierte Frage, keine Beibehaltung der Reasoning-Kette nötig. |
| Multi-Turn Dialog (einfach) | ❌ Nicht erforderlich | Der Kontext ist ausreichend, keine Abhängigkeit von komplexem Reasoning. |
| Multi-Turn Dialog (komplexes Reasoning) | ✅ Erforderlich | Zum Beispiel: Code-Refactoring, mathematische Beweise, mehrstufige Analysen. |
| Minimaler Denkmodus (minimal) | ✅ Zwingend notwendig | thinking_level: "minimal" erfordert die Übergabe der Signatur, andernfalls wird ein 400-Fehler ausgegeben. |
Beispielcode für die Übergabe von Thought Signatures
import openai
client = openai.OpenAI(
api_key="IHR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
# Runde 1: Das Modell einen Algorithmus entwerfen lassen
response_1 = client.chat.completions.create(
model="gemini-3.0-pro-preview",
messages=[{"role": "user", "content": "Entwirf einen verteilten Rate-Limiting-Algorithmus"}],
extra_body={
"thinking_level": "high",
"include_thoughts": True
}
)
# Thought Signatures extrahieren
signatures = []
for part in response_1.choices[0].message.content:
if hasattr(part, 'thought_signature'):
signatures.append(part.thought_signature)
# Runde 2: Optimierung basierend auf dem vorherigen Reasoning
response_2 = client.chat.completions.create(
model="gemini-3.0-pro-preview",
messages=[
{"role": "user", "content": "Entwirf einen verteilten Rate-Limiting-Algorithmus"},
{
"role": "assistant",
"content": response_1.choices[0].message.content,
"thought_signatures": signatures # Thought Signatures übergeben
},
{"role": "user", "content": "Wie geht man mit Inkonsistenzen bei verteilten Uhren um?"}
],
extra_body={"thinking_level": "high"}
)
💡 Best Practice: In Szenarien, die komplexes Multi-Turn-Reasoning erfordern (wie Systemdesign, Algorithmus-Optimierung oder Code-Reviews), empfiehlt es sich, die Auswirkungen der Signatur-Übergabe über die Plattform APIYI (apiyi.com) zu testen. Die Plattform unterstützt den vollständigen Gemini 3.0 Thought Signature Mechanismus, was die Verifizierung der Reasoning-Qualität unter verschiedenen Konfigurationen erleichtert.
Häufig gestellte Fragen (FAQ)
Q1: Warum gibt Gemini 2.5 Flash trotz thinking_budget=0 weiterhin Denkinhalte zurück?
Dies ist ein bekannter Bug. In der Version Gemini 2.5 Flash Preview 04-17 wurde thinking_budget=0 nicht korrekt umgesetzt. Dies wurde in den offiziellen Google-Foren bestätigt.
Temporäre Lösungen:
- Verwenden Sie
thinking_budget=1(einen Minimalwert) statt 0. - Aktualisieren Sie auf Gemini 3.0 Flash und nutzen Sie
thinking_level="minimal". - Filtern Sie die Denkinhalte in der Nachbearbeitung (falls die API ein
thought-Feld zurückgegeben hat).
Wir empfehlen den schnellen Wechsel auf das Gemini 3.0 Flash Modell über APIYI (apiyi.com). Die Plattform unterstützt die neuesten Versionen, wodurch solche Bugs vermieden werden können.
Q2: Wie lässt sich feststellen, ob aktuell ein Gemini 2.5 oder 3.0 Modell verwendet wird?
Methode 1: Modellnamen prüfen
- Gemini 2.x: Namen enthalten
2.5-flash,2-flash-lite. - Gemini 3.x: Namen enthalten
3.0-flash,3-pro,gemini-3-flash.
Methode 2: Testanfrage senden
# Nur thinking_level übergeben und Antwort beobachten
response = client.chat.completions.create(
model="ihr-modell-name",
messages=[{"role": "user", "content": "test"}],
extra_body={"thinking_level": "low"}
)
# Wenn ein 400-Fehler mit dem Hinweis erscheint, dass thinking_level nicht unterstützt wird, handelt es sich um Gemini 2.5.
Methode 3: API-Response-Header prüfen
Einige API-Implementierungen geben das Feld X-Model-Version im Response-Header zurück, worüber sich die Modellversion direkt identifizieren lässt.
Q3: Wie viele Token verbrauchen die verschiedenen thinking_level Stufen in Gemini 3.0 konkret?
Google hat das genaue Token-Budget für die verschiedenen thinking_level nicht öffentlich bekannt gegeben, bietet jedoch folgende Orientierungshilfe:
| thinking_level | Relative Kosten | Relative Latenz | Reasoning-Tiefe |
|---|---|---|---|
| minimal | Am niedrigsten | Am niedrigsten | Kaum Reasoning |
| low | Niedrig | Niedrig | Oberflächliches Reasoning |
| medium | Mittel | Mittel | Moderates Reasoning |
| high | Hoch | Hoch | Tiefgehendes Reasoning |
Empfehlung für die Praxis:
- Vergleichen Sie den tatsächlichen Token-Verbrauch der verschiedenen Stufen über die Plattform APIYI (apiyi.com).
- Verwenden Sie dieselbe Eingabeaufforderung mit low/medium/high und beobachten Sie die Abrechnungsunterschiede.
- Wählen Sie die passende Stufe basierend auf Ihrem konkreten Anwendungsfall (Antwortqualität vs. Kosten).
Q4: Kann in Gemini 3.0 die Verwendung von thinking_budget erzwungen werden?
Ja, aber es wird nicht empfohlen.
Gemini 3.0 akzeptiert den Parameter thinking_budget zwar aus Gründen der Abwärtskompatibilität, die offizielle Dokumentation weist jedoch explizit darauf hin:
"Obwohl
thinking_budgetzur Abwärtskompatibilität akzeptiert wird, kann die Verwendung mit Gemini 3 Pro zu suboptimaler Leistung führen."
Gründe:
- Der interne Reasoning-Mechanismus von Gemini 3.0 ist speziell für
thinking_leveloptimiert. - Das Erzwingen von
thinking_budgetkönnte die Reasoning-Strategien der neuen Version umgehen. - Dies kann zu einer schlechteren Antwortqualität oder erhöhter Latenz führen.
Der richtige Ansatz:
- Migrieren Sie auf den Parameter
thinking_level. - Nutzen Sie eine Anpassungsfunktion für Parameter (wie in "Lösung 3" beschrieben), um dynamisch den korrekten Parameter auszuwählen.
Zusammenfassung
Die wichtigsten Punkte zu den Fehlermeldungen bei thinking_budget und thinking_level in der Gemini API:
- Parameter-Exklusivität: Gemini 2.5 verwendet
thinking_budget, während Gemini 3.0thinking_levelnutzt. Diese Parameter dürfen nicht gleichzeitig übermittelt werden. - Modellerkennung: Die Version wird anhand des Modellnamens identifiziert. Für die 2.5-Serie wird
thinking_budgetverwendet, für die 3.0-Seriethinking_level. - Dynamische Anpassung: Nutzen Sie eine Anpassungsfunktion, die basierend auf dem Modellnamen automatisch den richtigen Parameter auswählt, um Hardcoding zu vermeiden.
- Denk-Signaturen (Thinking Signatures): Gemini 3.0 führt einen Mechanismus für Denk-Signaturen ein. Bei komplexen Szenarien mit mehreren Interaktionsrunden muss die Signatur übermittelt werden, um die Schlussfolgerungskette (Reasoning Chain) aufrechtzuerhalten.
- Migrationsempfehlung: Gemini 2.5 wird am 3. März 2026 eingestellt. Es wird empfohlen, frühzeitig auf die 3.0-Serie zu migrieren.
Wir empfehlen APIYI (apiyi.com), um die tatsächlichen Auswirkungen der verschiedenen Konfigurationen des Denkmodus schnell zu validieren. Die Plattform unterstützt die gesamte Gemini-Modellreihe, bietet eine einheitliche Schnittstelle sowie flexible Abrechnungsmodelle und eignet sich ideal für schnelle Vergleichstests sowie den produktiven Einsatz.
Autor: APIYI-Technikteam | Bei technischen Fragen besuchen Sie bitte APIYI (apiyi.com), um weitere Lösungen für die Integration von Großes Sprachmodellen zu erhalten.