Kürzlich hat das Open-Source-Projekt ARIS-Code auf GitHub still und leise die Marke von 8.400+ Sternen und 783 Forks geknackt. Es wurde vom Entwickler wanshuiyin auf Basis der Open-Source-Version von Claude Code weiterentwickelt. Der vollständige Name lautet „Auto-Research-In-Sleep“ – frei übersetzt: „Forschung während des Schlafens“. Das ist kein reines Marketing-Versprechen: Es ermöglicht Claude Code tatsächlich, während Sie schlafen, automatisch Experimente durchzuführen, Literatur zu recherchieren und Paper zu überarbeiten, sodass Sie am nächsten Morgen mit einem deutlichen Fortschritt in Ihrer Arbeit aufwachen.
Die Diskussionen, die ARIS-Code in akademischen Kreisen ausgelöst hat, sind besonders bemerkenswert: Die vom Autor veröffentlichten drei Fallstudien aus der Community zeigen, dass die von der KI erstellten Entwürfe in KI-Bewertungen ein Niveau von 7-8/10 erreichten und bereits bei Top-Konferenzen der Informatik, AAAI 2026 und IEEE TGRS, eingereicht wurden. Dies bedeutet, dass vollautomatische KI-Forschung nicht mehr nur auf Demo-Niveau existiert, sondern tatsächlich in der Lage ist, einreichungsfähige Manuskripte zu produzieren.
Dieser Artikel analysiert die Kernarchitektur von ARIS-Code, die 42 integrierten Skills sowie die spezifische Methode, wie man das System in einer inländischen Umgebung über einen API-Proxy-Dienst mit Claude-Modellen verbindet, um Ihnen bei der Entscheidung zu helfen, ob dieses Tool für Ihren Forschungsworkflow geeignet ist.
🎯 Besonderer Hinweis: Da ARIS-Code auf der Open-Source-Version von Claude Code basiert, kann der Executor nur Claude-Modelle (Sonnet/Opus/Haiku) anbinden. GPT- oder Gemini-Modelle werden als Haupt-Executor nicht unterstützt. Wir empfehlen die Anbindung der Claude-Modelle über die Plattform APIYI (apiyi.com). Diese Plattform ist mit dem nativen Anthropic-Protokoll kompatibel, bietet einen stabilen Zugriff aus dem Inland, eine nutzungsbasierte Abrechnung und erfordert keine ausländische Kreditkarte.
Was ist das Projekt ARIS-Code: Auto-Research-In-Sleep?
ARIS (Auto-Research-In-Sleep) ist ein autonomes Forschungsworkflow-System für ML/KI-Wissenschaftler. Das Projekt finden Sie auf GitHub unter: github.com/wanshuiyin/Auto-claude-code-research-in-sleep. Das Ziel des Designs ist klar definiert: Forschern zu ermöglichen, den gesamten Prozess von der „Literaturübersicht → Ideenfindung → Experimentdurchführung → Paper-Schreiben → Rebuttal-Reaktion“ mit minimalem menschlichem Eingriff zu bewältigen und sie so von repetitiver körperlicher Arbeit zu befreien.
Im Kern ist ARIS-Code eine Methodenbibliothek. Das gesamte System besteht aus reinen Markdown-Dateien (SKILL.md); es gibt keine Frameworks, die installiert werden müssen, keine Datenbanken, die gewartet werden müssen, und keine Docker-Container, die konfiguriert werden müssen. Jeder Skill ist eine Arbeitsanweisungs-Beschreibung, die von jedem beliebigen LLM-Agenten gelesen werden kann. Daher können Sie den Executor von Claude Code auf Codex CLI, OpenClaw, Cursor, Trae oder jedes andere Tool, das den Agenten-Modus unterstützt, umstellen, während der Workflow weiterhin effektiv bleibt.
Dieses „Zero-Dependency, Zero-Lock-in“-Design ist das größte Merkmal, das ARIS-Code von anderen KI-Forschungstools unterscheidet. Im Grunde genommen wird der Forschungsprozess in „explizites Prompt-Engineering“ übersetzt, anstatt ihn in ein Black-Box-Tool zu verpacken. Für Forscher ist dies von großer Bedeutung, da es bedeutet, dass der Workflow lesbar, modifizierbar und migrierbar ist, anstatt an ein bestimmtes kommerzielles Produkt gebunden zu sein.
Erwähnenswert ist, dass das ARIS-Code-Repository bereits 719 Commits angesammelt hat und sich das Projekt in einer schnellen Iterationsphase befindet. In den letzten drei Monaten wurden wertvolle Skills wie paper-talk (Generierung von Konferenzvorträgen), resubmit-pipeline (Workflow für die Wiedereinreichung nach Ablehnung) und kill-argument (Generierung von kontradiktorischen Gegenargumenten) hinzugefügt, was das gesamte Ökosystem sehr lebendig macht.
ARIS-Code Kernarchitektur: Executor-Reviewer Dual-Modell-Gegenspieler-Prüfung
Der entscheidende technische Mehrwert von ARIS-Code liegt in seiner Dual-Modell-Gegenspieler-Architektur. Dies ist der grundlegende Unterschied zu anderen wissenschaftlichen Assistenten auf dem Markt. Die Projektentwickler formulieren im README eine tiefgreifende Beobachtung: Die Selbstprüfung durch ein einzelnes Modell weist strukturelle Schwächen auf. Wenn dasselbe Modell sowohl Aufgaben ausführt als auch die Ergebnisse bewertet, reproduziert es systematisch seine eigenen blinden Flecken und gerät in die Falle eines lokalen Optimums.
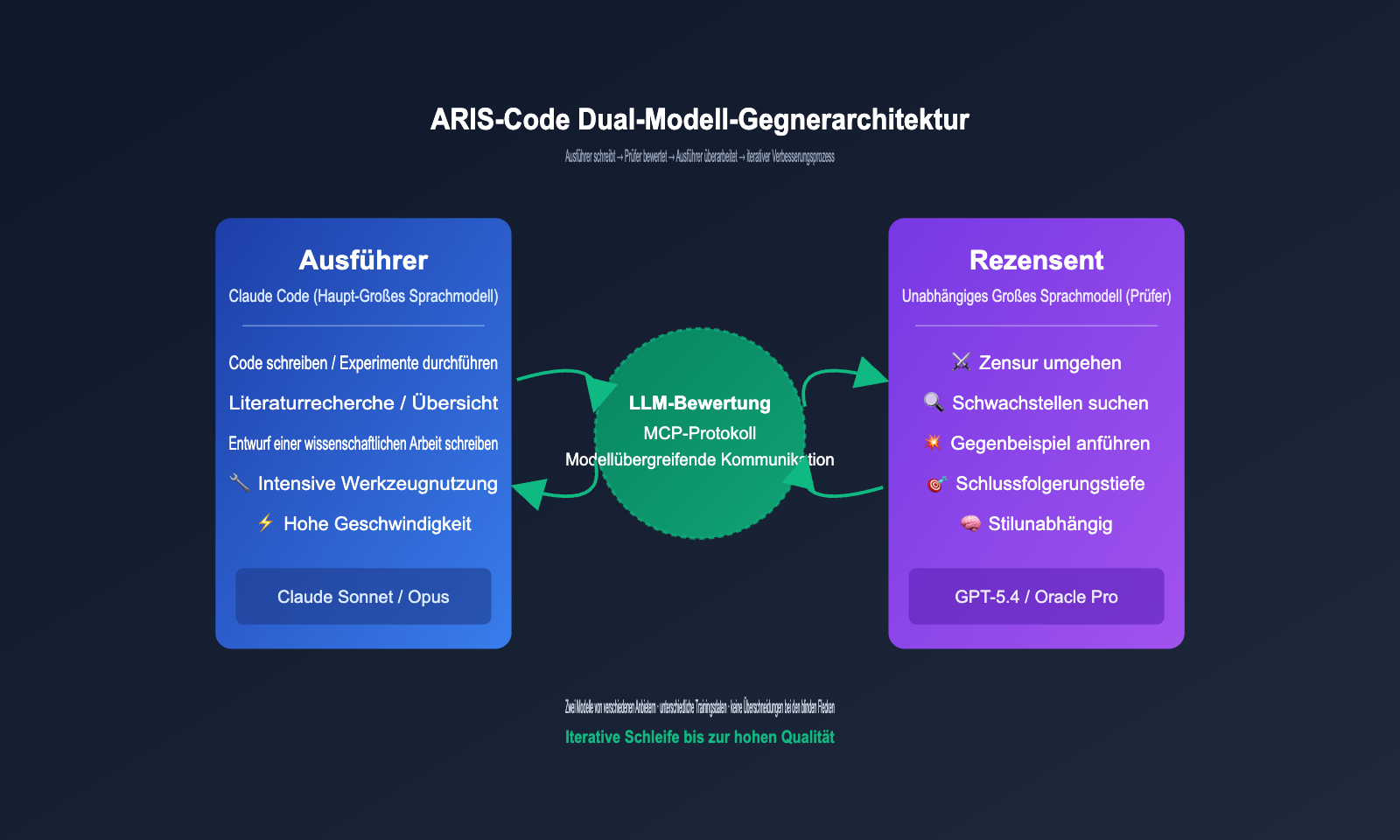
Die von ARIS-Code gewählte Lösung besteht darin, die Prüfungsbefugnis an ein völlig unabhängiges Modell zu übertragen. Die Rollenverteilung sieht wie folgt aus:
| Rolle | Modellauswahl | Zuständigkeitsbereich | Empfohlene Fähigkeiten |
|---|---|---|---|
| Executor (Ausführer) | Claude Sonnet / Opus | Hauptausführung: Code schreiben, Literaturrecherche, Experimente, Entwurf | Geschwindigkeit, großes Kontextfenster, stabile Werkzeugnutzung |
| Reviewer (Prüfer) | GPT-5.4 (Codex MCP) / Oracle Pro | Gegenspieler-Prüfung: Schwachstellen finden, Schlussfolgerungen hinterfragen | Tiefes logisches Denken, kritisch, unabhängiger Stil |
| Koordinationsmechanismus | LlmReview Toolchain | Modellübergreifende Kommunikation, Status-Persistenz | Transparente Übertragung via MCP-Protokoll |
Der gesamte Workflow lässt sich als einfacher Kreislauf zusammenfassen: Executor schreibt → Reviewer prüft → Executor korrigiert → erneute Prüfung und Korrektur, bis der Reviewer die Freigabe erteilt. Dieser Kreislauf ist deshalb so effektiv, weil beide Modelle von unterschiedlichen Anbietern stammen, mit verschiedenen Daten trainiert wurden und unterschiedliche Schlussfolgerungsstile aufweisen – ihre blinden Flecken überschneiden sich also nicht.
Um eine Verfälschung wissenschaftlicher Ergebnisse durch LLM-Halluzinationen zu verhindern, hat ARIS-Code zudem eine mehrschichtige Beweis-Audit-Kette entworfen: experiment-audit (Code-Integrität) → result-to-claim (Ergebnis-zu-Behauptung) → paper-claim-audit (Audit der wissenschaftlichen Behauptungen) → citation-audit (Überprüfung der Zitate). Jede Ebene verfügt über ein unabhängiges JSON-Urteil und einen SHA256-Hash zur Reproduzierbarkeitsprüfung – eine technische Strenge, die bei KI-Werkzeugen für die Forschung selten ist.
🔧 Konfigurationsempfehlung: Wenn Sie die Dual-Modell-Architektur von ARIS-Code vollständig nachbilden möchten, empfiehlt es sich im Inland, über APIYI (apiyi.com) gleichzeitig API-Schlüssel für Claude- und GPT-Modelle zu beziehen. Eine Plattform bietet Zugriff auf beide Schnittstellen, ohne dass separate Auslandskonten oder Kreditkartenbindungen erforderlich sind.
ARIS-Code: Integrierte Pipeline mit über 42 Skills für die gesamte Forschung
Besonders beeindruckend an ARIS-Code sind die über 42 integrierten Skills. Diese sind keine isolierten Werkzeuge, sondern bilden eine Pipeline, die den gesamten wissenschaftlichen Lebenszyklus abdeckt. Ich habe sie nach Workflow-Phasen kategorisiert:
| Workflow-Phase | Repräsentative Skills | Kernkompetenzen |
|---|---|---|
| Ideenfindung (Idea Discovery) | research-lit / novelty-check / idea-creator / idea-discovery | Literaturrecherche aus mehreren Quellen, modellübergreifende Neuheitsprüfung, Generierung von 8-12 Ideen |
| Experimentierphase (Experimentation) | experiment-bridge / experiment-queue / run-experiment | Code-Review → GPU-Deployment → Multi-Seed-Orchestrierung → automatische OOM-Behandlung |
| Automatische Prüfung (Auto Review) | auto-review-loop / research-review / experiment-audit | 4-stufige iterative Verbesserung, strukturierte Peer-Review, Code-Integritätsprüfung |
| Wissenschaftliches Schreiben (Paper Writing) | paper-writing / paper-claim-audit / proof-checker / citation-audit | Narrativ → LaTeX → PDF, Audit von Behauptungen, Beweisprüfung, Zitat-Verifizierung |
| Rebuttal-Management | rebuttal | Analyse von Reviewer-Kommentaren → Entwurf der Antwort → Stresstest |
| Meta-Fähigkeiten | research-wiki / meta-optimize / deepxiv | Persistente Wissensdatenbank, äußere Optimierung, alternative Literaturquellen |
Der praxistauglichste Skill ist experiment-bridge, der den Prozess von "Code-Review → GPU-Remote-Deployment → Experimentstart → Ergebnissammlung" zu einer durchgängigen Pipeline verbindet. Wenn der Reviewer vorschlägt, eine Ablation-Studie durchzuführen, schreibt der Executor automatisch das Skript, synchronisiert es per rsync auf den GPU-Knoten, startet das Training, überwacht die Protokolle und sammelt die Ergebnisse – ohne dass der Forscher manuell eingreifen muss.
Ein weiterer bemerkenswerter Skill ist citation-audit, der durch die Anbindung an echte Datenbanken wie DBLP und CrossRef das größte Problem beim Schreiben von Papern mit LLMs löst: Zitat-Halluzinationen. Jedes BibTeX-Element stammt aus einer echten Datenbank und ist nicht vom Modell erfunden. Dies ist eine Grundvoraussetzung für das wissenschaftliche Schreiben, da jede erfundene Quelle zur sofortigen Ablehnung führen kann.
Forscher schätzen zudem das research-wiki, eine sitzungsübergreifende, persistente Wissensdatenbank. Sie sammelt über verschiedene Projekte hinweg Notizen, Ideenentwürfe und Aufzeichnungen gescheiterter Experimente und bildet so ein stetig wachsendes, persönliches wissenschaftliches Gedächtnis. Wenn Sie nach drei Monaten zu einem pausierten Projekt zurückkehren, müssen Sie nicht alle relevanten Papiere erneut lesen – der KI-Assistent hat den Kontext für Sie bewahrt.
💡 Nutzungshinweis: Der Aufruf eines jeden Skills verbraucht eine erhebliche Menge an Claude-API-Tokens, insbesondere bei Aufgaben wie dem Schreiben von Papern. Wir empfehlen die Anbindung der Claude-Modelle über apiyi.com, da die Plattform eine nutzungsbasierte Abrechnung sowie eine vollständige Überwachung des Token-Verbrauchs bietet, was die Kostenschätzung für ein einzelnes Paper erheblich erleichtert.
Vollständige Konfigurationsanleitung für die Anbindung von ARIS-Code an APIYI
Da der Executor von ARIS-Code auf der Open-Source-Version von Claude Code basiert, akzeptiert er ausschließlich das native Anthropic-API-Protokoll. Das bedeutet, dass GPT- oder Gemini-Modelle nicht direkt als Executor verwendet werden können. Dies ist eine harte Einschränkung und für viele Entwickler bei der ersten Bereitstellung der größte Stolperstein.
Die Konfiguration zur Anbindung von Claude-Modellen über APIYI ist sehr einfach und lässt sich in 5 Schritten zusammenfassen:
# Schritt 1: Projekt-Repository klonen
git clone https://github.com/wanshuiyin/Auto-claude-code-research-in-sleep
cd Auto-claude-code-research-in-sleep
# Schritt 2: Skills im lokalen Claude Code Konfigurationsverzeichnis installieren
mkdir -p ~/.claude/skills/
cp -r skills/* ~/.claude/skills/
# Schritt 3: APIYI-Proxy-Adresse konfigurieren (Kernschritt)
export ANTHROPIC_BASE_URL="https://vip.apiyi.com"
export ANTHROPIC_AUTH_TOKEN="Dein APIYI-Schlüssel"
# Schritt 4: Claude Code starten
claude
# Schritt 5: Beliebigen Skill in Claude Code aufrufen
# Beispiel: /research-pipeline "factorized gap in discrete diffusion LMs"
Der entscheidende Punkt ist hier Schritt 3, bei dem die Umgebungsvariable ANTHROPIC_BASE_URL gesetzt wird. Sie weist Claude Code an, nicht den offiziellen Anthropic-Endpunkt abzufragen, sondern das API-Proxy-Dienst-Gateway zu nutzen. Die Schnittstelle dieses Gateways ist vollständig mit dem nativen Anthropic-Protokoll kompatibel. Die in ARIS-Code integrierten Skills erfordern keinerlei Code-Änderungen; alle Funktionen, einschließlich Tool-Aufrufe, Streaming-Ausgabe und Gedankengänge (Thinking), werden transparent übertragen.
Falls Sie zusätzlich die Reviewer-Seite (Codex MCP) bereitstellen möchten, lautet der Ablauf:
# Codex MCP für die Reviewer-Seite installieren
npm install -g @openai/codex
codex setup # Hier kann ebenfalls die Proxy-Adresse für GPT-Modelle eingetragen werden
claude mcp add codex -s user -- codex mcp-server
Für Forscher, die die Ergebnisse auf dem Niveau der ARIS-Code-Forschungsarbeit vollständig reproduzieren möchten, bietet das Projekt zudem eine Oracle-MCP-Anbindung an GPT-5.4 Pro als fortgeschrittenen Reviewer. Dieser Ansatz ist in der intensiven Phase der Erstellung wissenschaftlicher Arbeiten äußerst nützlich, da die Tiefe der Kritik und die Fähigkeit zur Konstruktion von Gegenbeispielen bei der Pro-Version deutlich über der Basisversion liegen.
🚀 Einheitliche Anbindung: Die Plattform APIYI (apiyi.com) unterstützt gleichzeitig die Claude-Serie (Sonnet 4.5/Opus 4), die GPT-Serie (GPT-5/o4), die Gemini-Serie (Gemini 3 Pro) und weitere gängige Modelle. Ein einziger Schlüssel reicht aus, um sowohl den Executor als auch den Reviewer von ARIS-Code zu betreiben, was für das Kostenmanagement und die Zusammenführung der Aufrufprotokolle in Forschungsteams sehr vorteilhaft ist.
ARIS-Code Effort Levels und GPU-Konfigurationsstrategien
ARIS-Code bietet 4 Effort Levels zur Balance zwischen Kosten und Qualität – ein sehr durchdachtes technisches Design. Die Anforderungen an die Tiefe variieren je nach Forschungsphase stark: In der frühen Explorationsphase ist es nicht nötig, Token zu verschwenden, während in der heißen Phase vor einer Einreichung die Qualität maximiert werden muss.
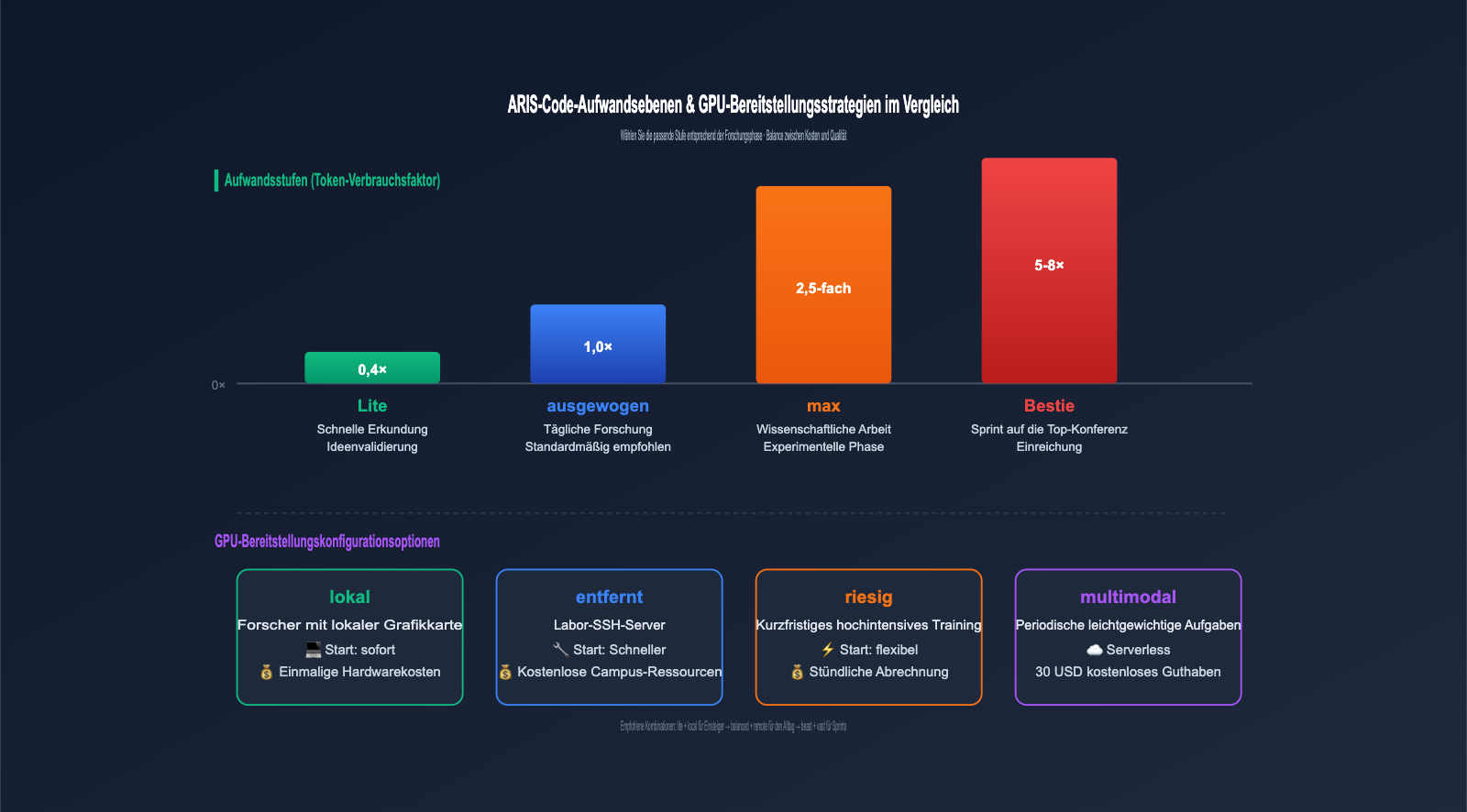
| Effort Level | Token-Faktor | Anwendungsszenario | Geschätzte Kosten pro Aufruf |
|---|---|---|---|
| lite | 0,4× | Schnelle Exploration, Ideenvalidierung | Sehr niedrig |
| balanced | 1,0× | Standard-Forschungsablauf | Standard |
| max | 2,5× | Experimentelle Phase für wissenschaftliche Arbeiten | Mittel bis hoch |
| beast | 5-8× | Konferenz-Einreichung, Submission Mode | Hoch |
Für die GPU-Seite bietet ARIS-Code ebenfalls 4 Konfigurationsoptionen, die sowohl lokale Setups als auch Cloud-Lösungen abdecken:
| GPU-Konfiguration | Anwendungsszenario | Kostenstruktur |
|---|---|---|
| local | Forscher mit lokaler Grafikkarte | Einmalige Hardwarekosten |
| remote | SSH-Server im Labor | Kostenlose Campus-Ressourcen |
| vast | Kurzfristiges, intensives Training | Stündliche Abrechnung, flexibel |
| modal | Periodische, leichte Aufgaben | Serverless, 30 USD Gratisguthaben |
💰 Empfehlung zur Kostenkontrolle: Wenn Sie gerade erst mit ARIS-Code beginnen, empfiehlt es sich, den Prozess zunächst mit lite + local zu testen und die Modellaufrufe über apiyi.com zu leiten, um den Token-Verbrauch einfach nachverfolgen zu können. Sobald der Prozess stabil läuft, können Sie auf den Modus „max“ oder „beast“ für ernsthafte Forschungsarbeiten umsteigen. So vermeiden Sie hohe Token-Kosten durch Konfigurationsfehler in der Anfangsphase.
ARIS-Code Praxis-Workflow: Vom ersten Satz zum Paper
Das Beeindruckendste an ARIS-Code ist die End-to-End-Pipeline /research-pipeline. Dieser Skill verknüpft alle oben genannten Phasen zu einem einzigen Befehl. Sie müssen lediglich eine Forschungsrichtung beschreiben, und das System erstellt innerhalb von 8 bis 24 Stunden einen ersten Entwurf.
Ein typischer Aufruf sieht so aus:
# Szenario 1: Ganz neues Thema, Start bei Null
/research-pipeline "factorized gap in discrete diffusion LMs"
# Szenario 2: Verbesserung eines bestehenden Papers
/research-pipeline "improve method X" \
--ref-paper https://arxiv.org/abs/2406.04329 \
--base-repo https://github.com/org/project
# Szenario 3: Nur Rebuttal
/rebuttal "paper/ + reviews" --venue ICML --char-limit 5000
Während der Ausführung durchläuft ARIS-Code systematisch folgende Schritte: Literaturrecherche → Ideengenerierung → Prüfung auf Neuartigkeit → Versuchsplanung → GPU-Zuweisung → Ergebnissammlung → Paper-Entwurf → Zitationsprüfung → Formatierung. Bei unklaren Entscheidungspunkten pausiert das System und wartet auf einen manuellen Checkpoint. In der Standardkonfiguration ermöglicht --AUTO_PROCEED false ein manuelles Eingreifen nach jedem Feedback der Reviewer.
ARIS-Code bietet zudem einen äußerst nützlichen style-ref-Parameter. Sie können ein Referenz-Paper für den Stil angeben (z. B. ein historisch exzellentes Paper der gleichen Konferenz), und das System imitiert dessen Struktur und Erzählrhythmus, ohne dabei konkrete Absätze zu kopieren. Für Forscher, die auf eine hohe "Annahmequote" abzielen, ist dies ein entscheidender Vorteil, da die impliziten Anforderungen von Top-Konferenzen an den Schreibstil oft schwerer zu treffen sind als der Inhalt selbst.
Ein weiteres bemerkenswertes technisches Detail ist die Integration von Overleaf-Synchronisation, W&B-Überwachung der Trainingskurven sowie Push-Benachrichtigungen via Lark/Feishu. Wenn Experimente auf der GPU einen kritischen Wendepunkt erreichen, erhalten Sie sofort eine Nachricht auf Ihr Smartphone – so betreiben Sie Forschung, während Sie schlafen.
📊 Leistungsdaten: Die vom Autor veröffentlichten 3 Community-Paper-Fallstudien zeigen, dass die von ARIS-Code erstellten Paper in KI-Bewertungen 7-8/10 Punkte erreichten (CS-Konferenzen, AAAI 2026, IEEE TGRS). Der Autor weist jedoch ausdrücklich darauf hin, dass menschliche Reviewer Perspektiven einbringen, die KI-Bewertungssysteme nicht erfassen können, weshalb eine menschliche Kontrolle unverzichtbar bleibt.
ARIS-Code FAQ
Q1: Warum kann ARIS-Code nicht GPT-5 als Executor verwenden?
Da ARIS-Code ein Fork der Open-Source-Version von Claude Code ist, ist die Executor-Ebene fest an das native Anthropic-API-Protokoll gebunden. Dies betrifft das Format der Tool-Aufrufe, das Streaming-Format und die Chain-of-Thought-Struktur, die tief mit Claude-Modellen verzahnt sind. Wenn Sie den Executor wechseln möchten, müssten Sie auf OpenClaw oder eine Codex-CLI-Distribution umsteigen, was jedoch nicht mehr dem originalen ARIS-Code entspricht. Wir empfehlen die direkte Anbindung der Claude-Modelle über apiyi.com – das ist die unkomplizierteste Lösung.
Q2: Wie viele Token werden für ein vollständiges Paper benötigt?
Im "Beast"-Modus verbraucht ein Durchlauf von /research-pipeline etwa 5 bis 15 Millionen Input- und Output-Token, was bei Claude Sonnet Kosten im Bereich von einigen zehn bis hundert Euro entspricht. Im "Balanced"-Modus lässt sich dies auf 2 bis 5 Millionen Token reduzieren. Die genauen Kosten hängen von der Komplexität der Experimente und der Anzahl der Iterationen ab.
Q3: Kann man ARIS-Code auch ohne lokale GPU nutzen?
Absolut. ARIS-Code unterstützt die Cloud-GPU-Modi "vast" und "modal". Modal bietet zudem ein kostenloses Guthaben von 30 USD, was für einige leichtgewichtige Experimente völlig ausreicht. Wenn Sie nur theoretische Paper schreiben (/proof-writer + /formula-derivation), benötigen Sie gar keine GPU.
Q4: Muss im Zwei-Modell-Architektur-Ansatz zwingend GPT-5.4 als Reviewer verwendet werden?
Nein, das ist nicht zwingend. Das Projekt unterstützt den Austausch durch GLM, MiniMax, Kimi oder jedes andere Modell, das mit dem OpenAI-Protokoll kompatibel ist. Wir empfehlen die Nutzung von Aggregator-Plattformen wie apiyi.com, um Zugriff auf verschiedene Reviewer-Modelle zu erhalten und A/B-Tests durchzuführen, um das für Ihr Fachgebiet am besten geeignete kritische LLM zu finden. Einige Forscher berichten, dass Gemini 3 Pro bei mathematischen Beweisen als Reviewer überraschend gut abschneidet, während GPT-5.4 bei technischen Optimierungen weiterhin die erste Wahl bleibt.
Q5: Ist ARIS-Code für Bachelor-Studierende oder Anfänger geeignet?
Es ist eher für Postgraduierte und Forscher mit Erfahrung geeignet. Der Grund: Die Qualität der Ergebnisse hängt stark vom Urteilsvermögen des Forschers ab. Wenn ein Reviewer beispielsweise ein Gegenbeispiel anführt, müssen Sie beurteilen können, ob es sich um eine kritische Schwachstelle oder ein irrelevantes Detail handelt. Unerfahrene Nutzer könnten sich von der KI in die Irre führen lassen.
Q6: Was tun, wenn die Netzwerkverbindung in China instabil ist?
Direktverbindungen zur offiziellen Anthropic-API führen in China häufig zu Verbindungsabbrüchen oder Timeouts, was lange /research-pipeline-Aufgaben unterbrechen kann. Eine bewährte Lösung ist die Umstellung der ANTHROPIC_BASE_URL auf ein API-Proxy-Dienst, das in einem inländischen Rechenzentrum gehostet wird. So kann ARIS-Code auch im "Schlafmodus" 8 Stunden lang ohne Unterbrechung durch Netzwerkjitter laufen – besonders kritisch für kontinuierliche Experimente im "Beast"-Modus.
Zusammenfassung
Das Aufkommen von ARIS-Code bestätigt einen wichtigen Trend: Forschungswerkzeuge im Zeitalter der Großen Sprachmodelle entwickeln sich von der „punktuellen Unterstützung“ hin zur „vollständigen Workflow-Automatisierung“. Die Executor-Reviewer-Dual-Modellarchitektur, die 42 Workflow-Skills und das von Abhängigkeiten befreite Markdown-Design bilden zusammen einen äußerst ausgereiften methodischen Rahmen.
Für Forscher im Inland ist die größte Hürde bei der Implementierung von ARIS-Code nicht die Lernkurve der Technologie, sondern der stabile Modellaufruf von Claude. Wir empfehlen den Zugriff auf die Claude-Modellreihe über die Plattform apiyi.com. Gleichzeitig können Sie dort die passenden GPT-Modelle für den Reviewer-Prozess beziehen. So deckt eine einzige Plattform den gesamten Modellbedarf des ARIS-Code-Workflows ab, was die Kostenabrechnung und die Zusammenführung von Aufrufprotokollen erheblich vereinfacht. Zudem sorgt die Stabilität der inländischen IDC-Knoten dafür, dass das Kernszenario „Experimente über Nacht laufen lassen“ nicht durch Netzwerkprobleme unterbrochen wird.
Wenn Sie gerade eine Einreichung für eine Top-Konferenz vorbereiten oder eine Forschungsrichtung verfolgen, die Sie validieren möchten, aber keine Zeit für manuelle Iterationen haben, ist ARIS-Code einen Versuch am Wochenende wert – wenn Sie am nächsten Morgen tatsächlich einen ersten Entwurf vorfinden, hat sich die Zeitinvestition mehr als gelohnt.
📌 Autor: APIYI Team — Wir beschäftigen uns intensiv mit KI-Großmodell-API-Diensten und dem Entwickler-Ökosystem. Weitere Fallstudien zur Einbindung von Claude/GPT/Gemini finden Sie im Dokumentationszentrum unter apiyi.com.