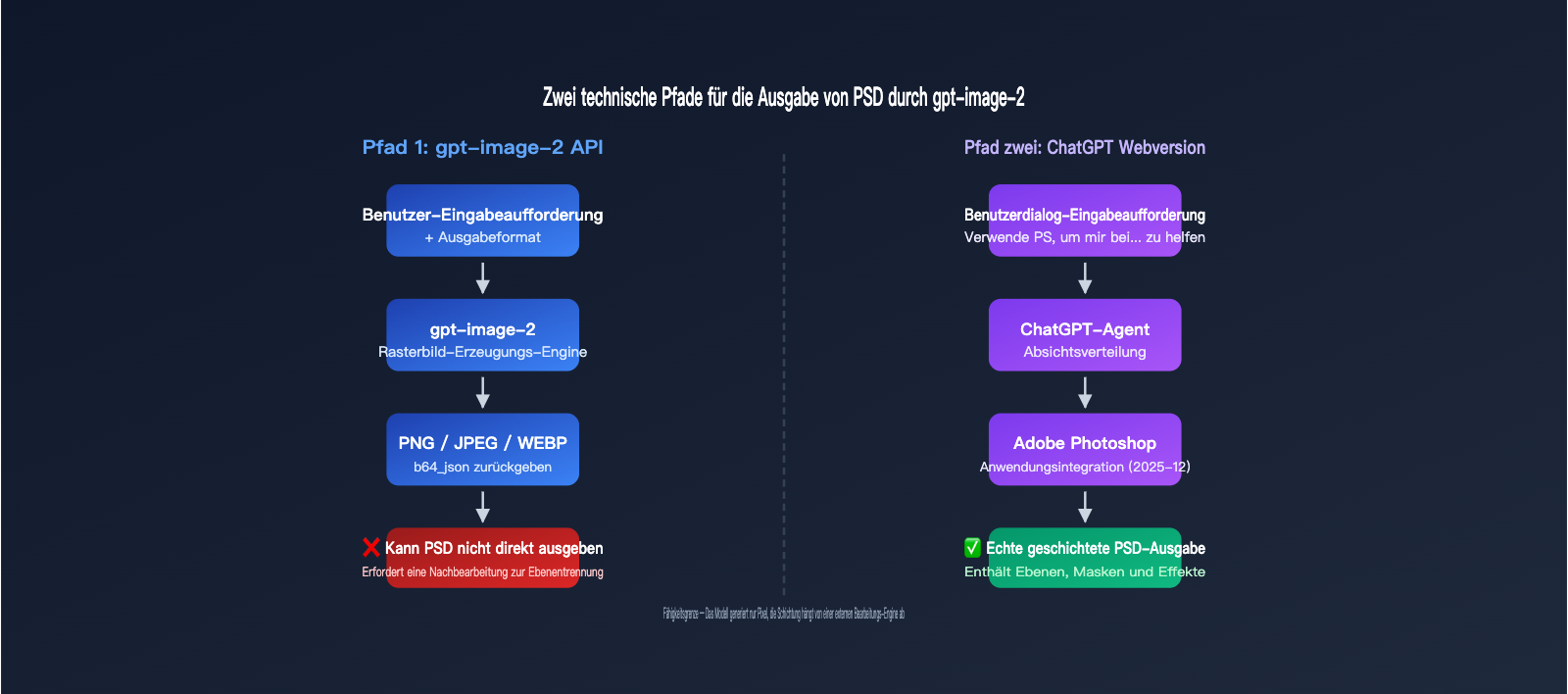
Viele Designer und Entwickler stellen bei der Arbeit mit gpt-image-2 dieselbe Frage: Kann man direkt PSD-Dateien mit Ebenen generieren? Die Antwort ist zweigeteilt: Die ChatGPT-Webversion kann dank der Adobe Photoshop-Integration eine Ebenenbearbeitung ermöglichen, während die gpt-image-2-API selbst nur die Standardformate PNG, JPEG oder WEBP ausgeben kann.
Dieser Artikel klärt die tatsächlichen Grenzen der PSD-Ausgabe von gpt-image-2 und stellt drei praktikable Workflows vor, damit Sie je nach Szenario den passenden Weg wählen können. Egal, ob Sie als Einzelkünstler oder in einem Entwicklerteam arbeiten, hier finden Sie die passende Lösung.

Grundlegendes Verständnis der PSD-Ausgabe von gpt-image-2
Bevor Sie beginnen, müssen Sie eine wichtige Tatsache verstehen: gpt-image-2 ist ein Modell zur Bilderzeugung, keine Bildbearbeitungssoftware. Es besitzt von sich aus nicht die Fähigkeit, "Dateien mit Ebenen" zu erstellen; jede PSD-Ausgabe erfordert die Zusammenarbeit mit externen Tools.
Wesentliche Unterschiede bei den Ausgabeformaten
Die offiziellen Definitionen von OpenAI für die gpt-image-Serie sind eindeutig: Das Modell unterstützt nur drei Arten von gerasterten Bildformaten:
| Ausgabeformat | Dateiendung | Ebenen | Transparenz | Typisches Szenario |
|---|---|---|---|---|
| PNG | .png |
❌ Nein | ✅ Unterstützt | Standardformat, ideal für Assets mit transparentem Hintergrund |
| JPEG | .jpg |
❌ Nein | ❌ Nicht unterstützt | Kleine Dateigröße, ideal für Fotos |
| WEBP | .webp |
❌ Nein | ✅ Unterstützt | Modernes Webformat, gute Balance zwischen Größe/Qualität |
| PSD | .psd |
✅ Ja | ✅ Unterstützt | API unterstützt dies nicht, erfordert Nachbearbeitung |
🎯 Fazit: Die gpt-image-2-API akzeptiert über den Parameter
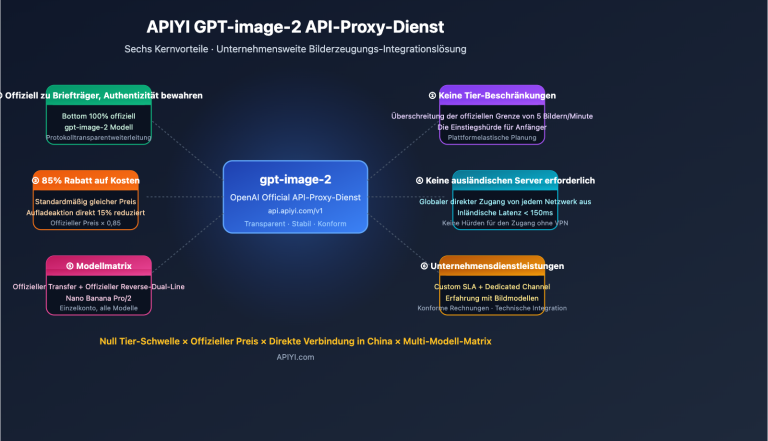
output_formatnur die Wertepng,jpegundwebp. Es gibt keine Parameter, mit denen direkt eine PSD-Datei ausgegeben werden kann. Wenn Sie gpt-image-2 stabil in Unternehmensprojekten nutzen möchten, können Sie den API-Proxy-Dienst von APIYI (apiyi.com) verwenden. Diese Plattform ist mit den offiziellen OpenAI-Schnittstellenspezifikationen kompatibel und unterstützt alle Parameter für die drei genannten Formate.
Warum die API keine PSD-Dateien ausgeben kann
PSD ist das proprietäre Ebenenformat von Adobe Photoshop, das Ebenen, Masken, Mischmodi, Einstellungsebenen und andere komplexe Strukturen enthält. Um eine echte PSD-Datei zu generieren, benötigt man keine Bilderzeugungs-KI, sondern eine Bildbearbeitungs-Engine. Deshalb gilt:
- gpt-image-2-API: Erzeugt ein flaches Rasterbild; das Konzept von "Ebenen" ist dem Modell fremd.
- ChatGPT-Webversion: Nutzt die Integration der Adobe Photoshop-App; die Ebenen werden tatsächlich von Photoshop erstellt.
Dies sind zwei völlig unterschiedliche Systeme, auf die wir im Folgenden näher eingehen.
3 Ansätze für den Export von PSD-Dateien mit gpt-image-2
Für die Anforderung „Ich brauche unbedingt eine PSD-Datei“ gibt es derzeit drei gangbare Wege, die sich für unterschiedliche Szenarien eignen. Die folgende Tabelle vergleicht die Kernmerkmale:
| Ansatz | Implementierung | Echte PSD-Ebenen | Automatisierungsgrad | Zielgruppe |
|---|---|---|---|---|
| Ansatz A: ChatGPT + Photoshop-Integration | Aufruf des Adobe-Plugins im Web | ✅ Ja | Halbautomatisch | Grafikdesigner, Gelegenheitsnutzer |
| Ansatz B: API-Generierung + manuelle PS-Konvertierung | API-Aufruf für PNG, dann manuelle PS-Importierung | ⚠️ Pseudo-Ebenen (eine Ebene) | Vollmanuell | Entwickler mit Batch-Bedarf |
| Ansatz C: API-Generierung + Drittanbieter-Tools | Bildgenerierung via API, dann Skript/KI-Tool zur Ebenentrennung | ✅ Ja (algorithmenbasiert) | Vollautomatisch | Engineering-Szenarien, Pipelines |
🎯 Empfehlung: Wenn Sie nur gelegentlich ein geschichtetes Bild benötigen, ist Ansatz A am einfachsten. Wenn Sie Bildgenerierungsfunktionen in Ihr Produkt integrieren müssen, ist der Aufruf der gpt-image-2 API über APIYI (apiyi.com) in Kombination mit Ansatz B oder C die kontrollierbarere Wahl.
Ansatz A: ChatGPT-Weboberfläche + Photoshop-Integration zur PSD-Ausgabe
Dies ist eine Funktion, die OpenAI offiziell im Dezember 2025 eingeführt hat. Adobe und OpenAI haben gemeinsam Adobe Photoshop, Adobe Express und Adobe Acrobat in ChatGPT integriert, sodass 800 Millionen Nutzer professionelle Bildbearbeitungsfunktionen direkt im Chat nutzen können.
Schritte zur Aktivierung von Photoshop für ChatGPT
Der Schlüssel zum gesamten Prozess ist die Rolle von ChatGPT als „umfassender Agent“, der die natürlichsprachlichen Absichten der Nutzer an gpt-image-2 zur Bildgenerierung weiterleitet und anschließend die Adobe Photoshop-Anwendung für die Ebenenbearbeitung anweist.
Nutzer-Eingabe → ChatGPT analysiert Absicht
├─ Aufruf von gpt-image-2 zur Generierung des Rohbildes
└─ Aufruf der Photoshop-Anwendung zur Ebenenverarbeitung
↓
Ausgabe der herunterladbaren PSD-Datei
Detaillierter Ablauf:
- Melden Sie sich bei der ChatGPT-Weboberfläche (chatgpt.com) an und stellen Sie sicher, dass Ihr Konto auf eine Version mit Bildfunktionen aktualisiert wurde.
- Klicken Sie im Eingabefeld auf "+" → "Mehr" → wählen Sie die App "Adobe Photoshop" aus.
- Geben Sie eine Eingabeaufforderung ein, z. B.:
Verwende Adobe Photoshop, um eine Illustration einer nächtlichen Stadt zu erstellen und unterteile Vordergrundfiguren, Gebäude im Mittelgrund und den Himmel im Hintergrund in verschiedene Ebenen. - ChatGPT ruft automatisch gpt-image-2 auf, um das Basisbild zu generieren.
- Direkt danach wird die Photoshop-Anwendung für die Ebenentrennung, Anpassungen und Mischvorgänge aufgerufen.
- Nach Abschluss können Sie über den Download-Button im Chat die PSD-Datei mit Ebenen herunterladen.
Funktionsumfang von Photoshop für ChatGPT
Die offizielle Adobe-Hilfedokumentation listet die Kernoperationen auf, die von der integrierten Version unterstützt werden:
| Operationstyp | Unterstützt | Hinweis |
|---|---|---|
| Anpassung lokaler Bereiche | ✅ | Helligkeit/Kontrast für bestimmte Bildteile |
| Kreative Effekte | ✅ | Integrierte Filter wie Glitch, Glow |
| Hintergrundunschärfe/-ersatz | ✅ | Nutzung von Adobe Firefly |
| Ebenentrennung | ✅ | Trennung von Subjekt, Vorder- und Hintergrund |
| Masken und Auswahlen | ⚠️ Teilweise | Komplexe Auswahlen besser in der Desktop-Version |
| Smartobjekte | ❌ | Erstellung bearbeitbarer Smartobjekte nicht möglich |
| Erweiterte Mischmodi | ❌ | Nur grundlegende Mischmodi unterstützt |
🎯 Hinweis zum Funktionsumfang: Photoshop in ChatGPT eignet sich für leichte Bearbeitungen; der volle Funktionsumfang bleibt der Photoshop-Desktop-Version vorbehalten. Wenn Sie häufig oder in großen Mengen PSD-Dateien generieren müssen, ist ein Workflow über APIYI (apiyi.com) zur direkten Anbindung der gpt-image-2 API (Ausgabe als PNG) und anschließende Übergabe an die Desktop-Version von Photoshop effizienter.
Einschränkungen von Ansatz A
Obwohl die Integration von ChatGPT und Photoshop ein flüssiges Erlebnis bietet, gibt es einige harte Einschränkungen:
- Keine API-Anbindung: Dies ist eine Funktion, die auf die Weboberfläche beschränkt ist. Es gibt keine öffentliche API-Schnittstelle, um diesen Workflow in eigenen Programmen zu replizieren.
- Langsame Generierungsgeschwindigkeit: Ein einzelner Generierungs- und Ebenentrennungsprozess dauert in der Regel 60–120 Sekunden.
- Geringe Kontrollierbarkeit: Die Anzahl, Benennung und Reihenfolge der Ebenen werden von ChatGPT selbst bestimmt und lassen sich nicht durch eine Eingabeaufforderung erzwingen.
- Kontingentbeschränkungen: Kostenlose Nutzer haben begrenzte tägliche Aufrufe, und auch Plus-Nutzer unterliegen Obergrenzen.
Diese Einschränkungen machen Ansatz A für „Inspirationssuche“ und „einmalige Kreationen“ geeignet, jedoch nicht für stabile Produktionsumgebungen.

Option B: gpt-image-2 API + manuelle PSD-Konvertierung in Photoshop
Wenn Ihre Anforderung darin besteht, „Bilder programmatisch in Massen zu generieren und sie nach einer manuellen Auswahl in PSD-Dateien umzuwandeln“, ist Option B die direkteste Lösung. Dieser Ansatz entkoppelt die Bilderzeugung durch KI vollständig von der manuellen Ebenenbearbeitung.
Minimales Beispiel für den gpt-image-2 API-Aufruf
Hier ist der minimale, ausführbare Code zur Generierung von Bildern über die API unter Verwendung der OpenAI-kompatiblen Schnittstelle:
import requests
import base64
response = requests.post(
"https://api.apiyi.com/v1/images/generations",
headers={"Authorization": "Bearer YOUR_API_KEY"},
json={
"model": "gpt-image-2",
"prompt": "Cyberpunk-Stadt bei Nacht, Neonlichter, verregnete Straßen",
"size": "1024x1024",
"quality": "high",
"output_format": "png"
}
)
data = response.json()["data"][0]
image_bytes = base64.b64decode(data["b64_json"])
with open("output.png", "wb") as f:
f.write(image_bytes)
📦 Vollständiges Python-Beispiel (inkl. Fehlerbehandlung und Parameterbeschreibung)
import os
import base64
import requests
from typing import Optional
def generate_image(
prompt: str,
output_path: str,
size: str = "1024x1024",
quality: str = "high",
output_format: str = "png",
background: Optional[str] = None
) -> dict:
"""
Aufruf von gpt-image-2 zur Bilderzeugung
Args:
prompt: Bildbeschreibung
output_path: Pfad zur Ausgabedatei
size: 1024x1024 / 1024x1536 / 1536x1024
quality: low / medium / high
output_format: png / jpeg / webp
background: transparent / opaque (nur für png/webp)
"""
api_key = os.getenv("APIYI_API_KEY")
if not api_key:
raise ValueError("Bitte setzen Sie die Umgebungsvariable APIYI_API_KEY")
payload = {
"model": "gpt-image-2",
"prompt": prompt,
"size": size,
"quality": quality,
"output_format": output_format,
}
if background:
payload["background"] = background
response = requests.post(
"https://api.apiyi.com/v1/images/generations",
headers={
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
},
json=payload,
timeout=180
)
response.raise_for_status()
result = response.json()
image_data = result["data"][0]["b64_json"]
with open(output_path, "wb") as f:
f.write(base64.b64decode(image_data))
return {
"path": output_path,
"usage": result.get("usage", {}),
"size": size
}
if __name__ == "__main__":
info = generate_image(
prompt="Eine futuristische Stadtillustration, vorbereitet für ein Produktwerbeplakat",
output_path="hero.png",
size="1536x1024",
quality="high",
background="transparent"
)
print(f"Erfolgreich generiert: {info}")
🎯 Hinweis zur Anbindung: Wenn Sie gpt-image-2 über APIYI (apiyi.com) aufrufen, müssen Sie lediglich die offizielle OpenAI-URL
api.openai.comdurchapi.apiyi.comersetzen. Alle anderen Parameter sind vollständig kompatibel, und Sie könnenoutput_formatfür png, jpeg oder webp festlegen.
PNG in Photoshop importieren und als PSD speichern
Nachdem Sie das von der API zurückgegebene PNG erhalten haben, ist dies der Standardprozess für die Konvertierung in eine PSD-Datei in Photoshop:
- Öffnen Sie die PNG-Datei in der Photoshop-Desktopversion (
Datei → Öffnen). - Das Bild besteht zunächst aus einer einzelnen Ebene, die normalerweise als „Hintergrund“ angezeigt wird.
- Doppelklicken Sie auf die Ebene, um sie zu entsperren und in eine bearbeitbare Ebene umzuwandeln.
- Trennen Sie das Motiv nach Bedarf:
- Verwenden Sie das Objektauswahlwerkzeug, um das Motiv automatisch zu erkennen.
- Verwenden Sie die Generative Erweiterung, um den Hintergrund neu zu gestalten.
- Verwenden Sie Alpha-Kanäle, um transparente Bereiche zu extrahieren.
- Speichern als PSD:
Datei → Speichern unter → Photoshop (.PSD).
Echte Ebenenkapazitäten von Option B
Beachten Sie, dass ein direktes PNG standardmäßig nur eine Ebene enthält. Um eine echte PSD-Datei mit mehreren Ebenen zu erhalten, müssen Sie zusätzliche Arbeit bei der Ebenentrennung leisten. Gängige Methoden sind:
| Methode zur Ebenentrennung | Bedienkomplexität | Qualität der Ebenen |
|---|---|---|
| Manuelle Auswahl + Ebene duplizieren | Hoch | Sehr hoch |
| KI-Freistellungstools (Remove.bg) | Niedrig | Mittel |
| Photoshop Objektauswahl + Generative Füllung | Mittel | Hoch |
| Photoshop Neural Filters (Tiefenschätzung) | Niedrig | Mittel (Pseudo-3D-Ebenen) |
Prompt-Engineering-Tipps für gpt-image-2 bei PSD-Ausgabe
Um die Effizienz der Ebenentrennung bei Option B zu maximieren, sollten Sie bereits in der Prompt-Phase die spätere Trennbarkeit berücksichtigen. Hier ist eine bewährte Prompt-Vorlage:
[Thema]: Ein Produktwerbeplakat, das Hauptmotiv ist ein futuristischer Sportschuh
[Anforderungen an die Komposition]:
- Motiv zentriert, nimmt 60 % der Bildfläche ein
- Hintergrund in einer einfarbigen oder einfachen Verlaufsfarbe, um das spätere Freistellen zu erleichtern
- Deutlicher Farbkontrast und Tiefenunschärfe zwischen Motiv und Hintergrund
- Keine Elemente im Hintergrund einfügen, die dem Motiv ähneln
[Ausgabeparameter]:
- Auflösung: 1536x1024
- Hintergrund: transparent (falls unterstützt)
- Stil: Kommerzielle Fotografie-Qualität
Diese Art der Prompt-Gestaltung macht die generierten PNGs „freundlicher“ für die spätere Ebenentrennung, wodurch die Erkennungsrate von Freistellungstools deutlich steigt.
| Prompt-Schlüsselwörter | Einfluss auf die Ebenentrennung |
|---|---|
pure background / solid color background |
Sauberere Freistellungskanten |
clear subject separation |
Klare Trennung zwischen Motiv und Hintergrund |
centered composition |
Erleichtert die automatische Erkennung der Motivposition |
studio lighting |
Reduziert Schattenwurf, verringert Fehlinterpretationen |
no overlapping elements |
Vermeidet gegenseitige Überlappungen der Ebenen |
🎯 Effizienzsteigerung: Bei der Anbindung von gpt-image-2 über APIYI (apiyi.com) können Sie systemweite Prompt-Vorlagen nutzen, um diese Einschränkungen voreinzustellen und sicherzustellen, dass alle vom Team generierten Bilder für den nachgelagerten PSD-Workflow optimiert sind.
Option C: API + Drittanbieter-Tools zur automatisierten PSD-Ausgabe
Für produktive Szenarien (z. B. automatische Generierung von E-Commerce-Materialien oder Werbeproduktionslinien) ist die manuelle Bedienung von Photoshop nicht praktikabel. Hier ist der Einsatz von automatisierten Tools zur Ebenentrennung erforderlich.
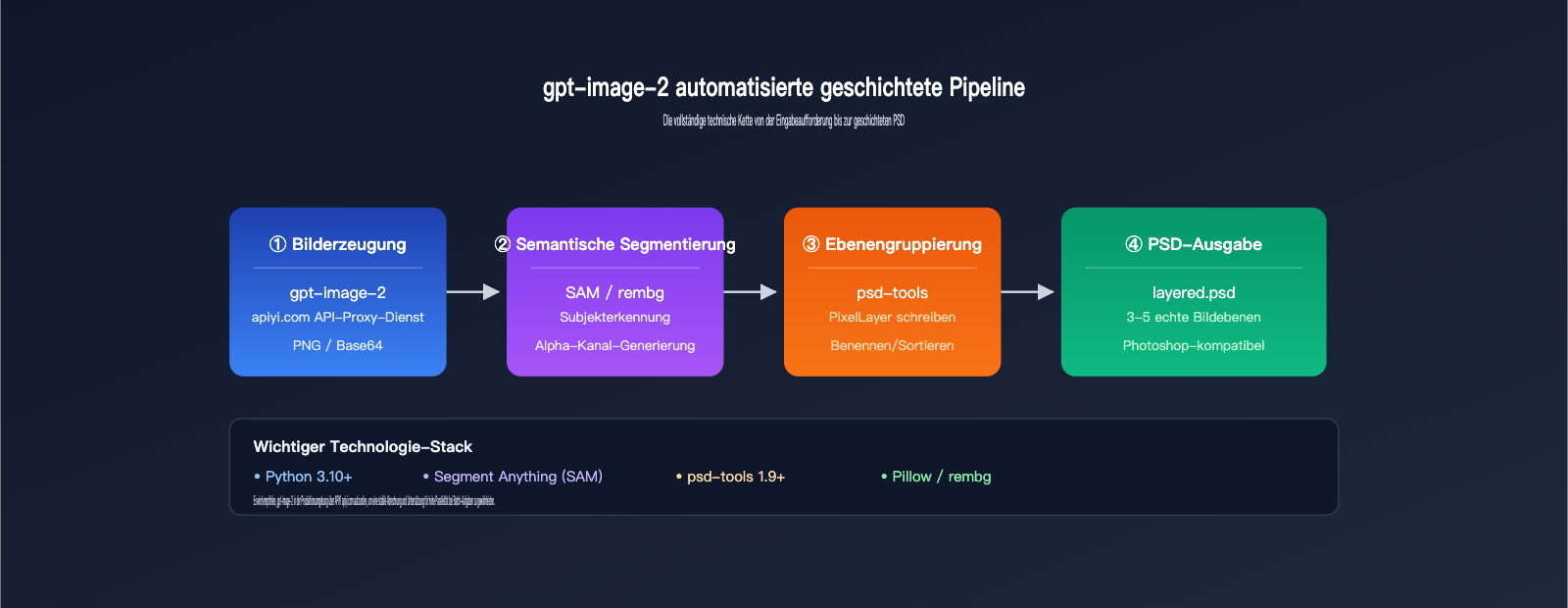
Architektur des automatisierten Workflows
[Benutzer-Prompt]
↓
[gpt-image-2 API generiert Originalbild]
↓
[Semantisches Segmentierungsmodell erkennt Bereiche] (z. B. SAM, Florence)
↓
[Alpha-Kanal-Generierung für jede Ebene]
↓
[psd-tools / photoshop-python-api schreibt PSD]
↓
[Ausgabe der PSD-Datei mit mehreren Ebenen]
Die gesamte Pipeline kann vollständig per Code implementiert werden, ohne dass der Photoshop-Client geöffnet werden muss.
Wichtige Tool-Kombinationen
| Tool | Funktion | Empfehlung |
|---|---|---|
| psd-tools (Python) | Lesen und Schreiben von PSD-Strukturen | ⭐⭐⭐⭐⭐ |
| Pillow | Grundlegende Bildverarbeitung | ⭐⭐⭐⭐⭐ |
| SAM (Segment Anything) | Semantische Segmentierung von Meta | ⭐⭐⭐⭐⭐ |
| rembg | Ein-Klick-Freistellung, Hintergrundentfernung | ⭐⭐⭐⭐ |
| MiDaS | Tiefenschätzung, Trennung von Vorder- und Hintergrund | ⭐⭐⭐⭐ |
| Photopea API | Online-PSD-Bearbeitung | ⭐⭐⭐ |
Beispielcode für automatisierte Ebenentrennung
from psd_tools import PSDImage
from psd_tools.api.layers import PixelLayer
from PIL import Image
from rembg import remove
original = Image.open("gpt_image_2_output.png")
foreground = remove(original)
background = Image.new("RGBA", original.size, (255, 255, 255, 0))
psd = PSDImage.new(mode="RGBA", size=original.size)
psd.append(PixelLayer.frompil(background, psd, "Background"))
psd.append(PixelLayer.frompil(foreground, psd, "Foreground"))
psd.save("layered_output.psd")
🎯 Engineering-Empfehlung: In Produktionsumgebungen empfiehlt es sich, den Prozess „gpt-image-2 aufrufen → freistellen → in PSD schreiben“ als Microservice zu kapseln. Der Aufruf der gpt-image-2 API über APIYI (apiyi.com) unterstützt hohe Parallelität und stabile Abrechnung, was sich ideal als Upstream-Kapazität für Bild-Pipelines eignet.
Hinweise zu Option C
- Ebenenqualität hängt vom Segmentierungsmodell ab: SAM ist präziser als rembg, verursacht aber höhere Inferenzkosten.
- PSD-Kompatibilität: Die von
psd-toolsgenerierten PSDs funktionieren in gängigen Photoshop-Versionen gut, bei sehr alten Versionen können jedoch Metadaten verloren gehen. - Rechenkosten bei Massenverarbeitung: Die Ausführung des Segmentierungsmodells für jedes Bild erhöht die GPU-Kosten erheblich.
- Hybride Lösungen sind realistischer: Ein Kompromiss ist die API-Generierung + einfache Hintergrundtrennung + manuelle Feinbearbeitung bei Bedarf.
Fortgeschritten: Praxisbeispiel für die Ebenentrennung nach Rollen
Wenn Sie mehrere semantische Objekte wie Personen, Produkte, Texte usw. auf separate Ebenen legen müssen, können Sie SAM (Segment Anything Model) für eine präzisere Segmentierung kombinieren:
📦 SAM + psd-tools vollständiges Beispiel für die Ebenentrennung nach semantischen Objekten
import torch
import numpy as np
from PIL import Image
from segment_anything import SamPredictor, sam_model_registry
from psd_tools import PSDImage
from psd_tools.api.layers import PixelLayer
def gpt_image_to_layered_psd(image_path: str, output_psd: str, points: list):
"""
Konvertiert das von gpt-image-2 ausgegebene PNG in eine PSD mit Ebenen für semantische Objekte
Args:
image_path: Pfad zum von gpt-image-2 generierten PNG
output_psd: Pfad zur PSD-Ausgabedatei
points: Liste der Mittelpunkte der zu segmentierenden Objekte [(x, y, label), ...]
"""
image = Image.open(image_path).convert("RGBA")
image_np = np.array(image)
sam = sam_model_registry["vit_h"](checkpoint="sam_vit_h.pth")
sam.to("cuda" if torch.cuda.is_available() else "cpu")
predictor = SamPredictor(sam)
predictor.set_image(image_np[:, :, :3])
psd = PSDImage.new(mode="RGBA", size=image.size)
for idx, (x, y, label) in enumerate(points):
masks, scores, _ = predictor.predict(
point_coords=np.array([[x, y]]),
point_labels=np.array([1]),
multimask_output=False
)
mask = masks[0]
layer_array = image_np.copy()
layer_array[~mask] = [0, 0, 0, 0]
layer_image = Image.fromarray(layer_array, "RGBA")
psd.append(PixelLayer.frompil(layer_image, psd, label))
background_array = image_np.copy()
background_image = Image.fromarray(background_array, "RGBA")
background_layer = PixelLayer.frompil(background_image, psd, "Background")
psd.insert(0, background_layer)
psd.save(output_psd)
print(f"✅ PSD mit mehreren Ebenen wurde generiert: {output_psd}")
if __name__ == "__main__":
gpt_image_to_layered_psd(
image_path="gpt_image_2_poster.png",
output_psd="layered_poster.psd",
points=[
(512, 400, "Subject"),
(200, 600, "ProductLeft"),
(800, 600, "ProductRight"),
]
)
Durch diesen Prozess kann ein mit gpt-image-2 generiertes Plakat in 3-5 echte PSD-Ebenen zerlegt werden, wobei jede Ebene in Photoshop unabhängig bearbeitet werden kann.
Fehlerbehandlung und Fehlerdiagnose
In technischen Szenarien können sowohl der gpt-image-2-Aufruf als auch die nachgelagerte Segmentierung fehlschlagen. Die folgende Tabelle fasst häufige Probleme und Lösungsansätze zusammen:
| Fehlerbild | Grundursache | Lösung |
|---|---|---|
API gibt invalid output_format zurück |
Nicht unterstützter Wert wie psd übergeben |
Nur png/jpeg/webp verwenden |
Feld b64_json ist leer |
Blockierung durch Inhaltsfilter | Prompt optimieren, sensible Beschreibungen vermeiden |
| Gezackte Kanten nach Freistellung | Segmentierungsmodell zu ungenau | SAM + Kanten-Feathering (Nachbearbeitung) verwenden |
| PSD lässt sich in Photoshop nicht öffnen | Unvollständige Metadaten durch psd-tools | psd-tools auf Version 1.9+ aktualisieren |
| Ebenen nach Trennung verschoben | RGBA-Kanäle nicht ausgerichtet | Leinwandgröße vor dem Schreiben vereinheitlichen |
| Aufrufgeschwindigkeit langsam | Ratenbegrenzung bei hoher Parallelität | Lastverteilung über APIYI (apiyi.com) nutzen |
🎯 Stabilitätshinweis: Für Produktionsumgebungen wird empfohlen, Wiederholungs- und Fallback-Logik in die API-Aufrufschicht zu integrieren. Anfragen, die über APIYI (apiyi.com) geleitet werden, erkennen automatisch die Ratenbegrenzungen von OpenAI und unterstützen intelligentes Umschalten, um die Ausfallrate bei Batch-Aufgaben zu senken.
Häufig gestellte Fragen zur PSD-Ausgabe von gpt-image-2
Hier finden Sie Antworten auf die am häufigsten gestellten Fragen aus der Praxis.
F1: Kann die gpt-image-2 API wirklich keine PSD-Dateien direkt ausgeben?
Das ist korrekt, sie kann es nicht. Die offizielle OpenAI-Dokumentation beschränkt die zulässigen Werte für den Parameter output_format explizit auf png, jpeg und webp. Jeder Dienst, der behauptet, "direkt PSD über die API auszugeben", führt im Hintergrund auf eigenen Servern einen Prozess zur Ebenentrennung (wie in Szenario C beschrieben) durch und verpackt das Ergebnis in eine PSD-Datei – dies ist keine native Fähigkeit des gpt-image-2-Modells selbst.
🎯 Klarstellung: Wenn Sie eine stabile Anbindung an das offizielle gpt-image-2 wünschen, können Sie einen API-Proxy-Dienst wie APIYI (apiyi.com) nutzen, der mit den offiziellen OpenAI-Schnittstellen kompatibel ist. Dies stellt sicher, dass sich die Parameter wie bei OpenAI verhalten und nicht durch eine Zwischenschicht "manipuliert" werden.
F2: Sind die PSD-Dateien aus der ChatGPT-Weboberfläche wirklich in Ebenen unterteilt?
Ja, das sind sie. Da im Hintergrund eine echte Adobe Photoshop-Instanz die Bearbeitung vornimmt, enthalten die generierten PSD-Dateien echte Ebenen, Masken und Effekte. Sie haben jedoch keine präzise Kontrolle über die Anzahl und Benennung der Ebenen. In den meisten Fällen erhalten Sie 3 bis 5 Ebenen (Hintergrund, Hauptmotiv, Vordergrund, Einstellungsebenen usw.).
F3: Gibt es Unterschiede in der Ausgabe zwischen gpt-image-2 und gpt-image-2-all?
Es gibt geringfügige Unterschiede. gpt-image-2-all nutzt den Reverse-Kanal, der dem der ChatGPT-Weboberfläche entspricht; das zurückgegebene b64_json-Feld enthält das Präfix data:image/png;base64,. Im Gegensatz dazu spricht gpt-image-2 direkt die OpenAI Images API an und gibt einen reinen Base64-String ohne Präfix zurück. Beide unterstützen keine PSD-Ausgabe, aber der zugrunde liegende Code zur String-Verarbeitung muss unterschiedlich behandelt werden.
F4: Wenn ich nur ein PNG mit transparentem Hintergrund benötige, brauche ich dann überhaupt PSD?
Für viele Anwendungsfälle ist das tatsächlich nicht nötig. Die gpt-image-2 API unterstützt den Parameter background: "transparent", um direkt PNGs mit transparentem Hintergrund zu erstellen. Dies ist ideal für:
- Freistellen von E-Commerce-Produkten
- Logos, Icons und Sticker-Materialien
- UI-Elemente
Nur wenn Sie nach der Erstellung auch Nicht-Hauptbereiche in Ebenen anpassen müssen, ist ein PSD-Workflow erforderlich.
F5: Wie lassen sich die Kosten für die massenhafte PSD-Generierung kontrollieren?
Die Kosten setzen sich aus drei Teilen zusammen:
| Kostenfaktor | gpt-image-2 API-Anteil | Nachbearbeitungs-Anteil |
|---|---|---|
| Kosten pro Bild | ca. $0,03 – $0,20 | GPU-Rechenleistung für Freistellung ~$0,001 |
| Zeitaufwand | 60-120 Sekunden | 5-30 Sekunden |
| Stabilität | Abhängig von OpenAI-Limits | Eigene Rechenleistung steuerbar |
🎯 Kostensenkungsstrategie: Bei großen Mengen empfiehlt es sich, nur für hochwertige Kandidaten eine Ebenentrennung durchzuführen. Nutzen Sie zunächst gpt-image-2 mit niedriger Qualität (
quality=low), um schnell Vorschaubilder zu generieren. Über die einheitliche Abrechnung von APIYI (apiyi.com) können Sie den Verbrauch prüfen und erst nach Bestätigung mit hoher Qualität (high) die finale Generierung und Ebenentrennung durchführen.
F6: Kann ich mit gpt-image-2 vorhandene PSD-Dateien direkt bearbeiten?
Nein. Das Image-Edit-Interface von gpt-image-2 akzeptiert nur PNG/JPEG/WEBP als Eingabe und kann die interne Ebenenstruktur einer PSD-Datei nicht lesen. Wenn Sie "eine bestimmte Ebene einer PSD-Datei mit KI neu zeichnen" möchten, ist das Standardvorgehen:
- Exportieren Sie die Ebene in Photoshop als PNG (mit Alpha-Kanal).
- Nutzen Sie das Edit-Interface von gpt-image-2 in Kombination mit einer Maske für die Neubearbeitung.
- Fügen Sie das Ergebnis als neue Ebene wieder in die ursprüngliche PSD-Datei ein.
Praxisbeispiele für die PSD-Ausgabe mit gpt-image-2
Verschiedene Branchen haben unterschiedliche Anforderungen an die PSD-Ausgabe. Hier sind drei typische Workflows.
Beispiel 1: Massenproduktion von E-Commerce-Produktplakaten
Ein grenzüberschreitendes E-Commerce-Team muss täglich über 300 Produktplakate erstellen. Die Anforderung: Eine Ebene für das Produkt, eine für den Hintergrund und eine für den Text, damit das Marketing die Texte schnell austauschen kann.
Workflow-Design:
- Nach dem Hochladen des Produkts gibt das Marketing die Verkaufsargumente als Schlagworte ein.
- Aufruf der gpt-image-2 API zur Generierung des Hauptbildes (
output_format=png,background=transparent). - Einsatz von
rembgzur präzisen Nachbearbeitung der Freistellungskanten. - Erstellung einer 3-Ebenen-Struktur mittels
psd-tools:- Ebene 1: Produkt (transparenter Hintergrund)
- Ebene 2: KI-generierter Szenenhintergrund
- Ebene 3: Platzhalter-Textebene
- Designer müssen nur noch die Textebene in der PSD anpassen.
Effizienzgewinn: Die Erstellungszeit pro Plakat sinkt von 30 Minuten auf 2 Minuten; der Designer übernimmt nur noch die Endkontrolle.
🎯 Szenario-Wahl: Für solche repetitiven Aufgaben bietet die Kombination aus der gpt-image-2-Schnittstelle von APIYI (apiyi.com) und einem unternehmensweiten Abrechnungsmodell planbare Kosten und skalierbare Kapazitäten.
Beispiel 2: Schnelles Prototyping von Spiele-UI-Assets
Das Grafikteam benötigt in der Prototyping-Phase eine große Anzahl an "Platzhalter"-UI-Assets – Buttons, Icons, Banner usw. – im PSD-Format für die spätere Feinbearbeitung.
Workflow-Design:
gpt-image-2 generiert visuelle Basis
↓
SAM segmentiert automatisch die Hauptform
↓
Export mehrerer PNGs (Rahmen, Icon, Glanz etc.)
↓
psd-tools kombiniert diese zu einer PSD mit Ebenen
↓
Grafiker verfeinern die finale Version in Photoshop
| Asset-Typ | gpt-image-2 Ausgabe | Nachbearbeitung | Anzahl Ebenen |
|---|---|---|---|
| Button | Transparentes PNG | Status-Slicing (Standard/Hover/Klick) | 3 |
| Icon | Transparentes PNG | Trennung von Glanz/Schatten | 2-4 |
| Banner | RGB PNG | Trennung von Motiv/Hintergrund/Lichteffekt | 3-5 |
| Karte | RGB PNG | Trennung von Rahmen/Basis/Badge | 3-4 |
Beispiel 3: Mehrsprachige Marketinginhalte
Das Werbeteam muss ein Hauptmotiv an 10 verschiedene Sprachen anpassen. Die Kernanforderung ist, dass die Textebene unabhängig und die Bildebene fix ist.
Wichtige Schritte:
- Generierung des Hauptmotivs ohne Text mit gpt-image-2 (im Prompt explizit
no text,no lettersangeben). - Erstellung eines Platzhalters für die Textebene mittels
psd-tools. - Zur Anpassung an 10 Sprachen muss später nur noch die Textebene geändert werden.
Der Vorteil dieses Workflows: Das Hauptmotiv wird nur einmal generiert, die Textebene bleibt vollständig kontrollierbar, was Rechtschreibfehler bei der KI-Generierung von Fremdsprachen vermeidet.
🎯 Hinweis zu Sprachen: gpt-image-2 ist bei englischen Texten relativ zuverlässig, bei Chinesisch, Japanisch oder Koreanisch treten jedoch häufig Fehler auf. Es wird empfohlen, beim Aufruf von gpt-image-2 über APIYI (apiyi.com) Text im Prompt explizit auszuschließen und die Verwaltung stattdessen über die PSD-Textebene zu steuern.
Beispiel 4: Unterstützung für Comics und Storyboards
Illustratoren nutzen gpt-image-2 häufig, um Skizzen für Storyboards zu generieren und diese dann in Photoshop zu verfeinern. Dieser hybride Prozess ("KI für Inspiration + manuelle Verfeinerung") erfordert eine strukturierte Ebenenverwaltung.
Typisches Ebenen-Schema:
- Skizzenebene: gpt-image-2 Ausgabe als Referenz-Basis.
- Lineart-Ebene: Zeichnen der Linien basierend auf der Skizze.
- Grundfarbenebene: Flächenfüllung.
- Schattenebene: Ausarbeitung der dunklen Bereiche.
- Glanzlichtebene: Akzente setzen.
- Effektebene: Dekorative Elemente.
Vorgehensweise:
1. gpt-image-2 generiert 1024x1536 Hochformat-Komposition.
2. In Photoshop als Ebene 0 festlegen (gesperrt, nicht bearbeitbar).
3. 5-6 neue leere Ebenen darüber für die Zeichnung erstellen.
4. Nach Abschluss als PSD archivieren.
Dieser Prozess verwandelt KI-Skizzen in Assets, an denen weitergearbeitet werden kann, anstatt sie als einmalige Bilder zu betrachten.
Vergleich von gpt-image-2 mit anderen Bildformaten
Um die Rolle von PSD in Ihrem Workflow besser zu verstehen, haben wir hier einen direkten Vergleich mit anderen gängigen Ausgabeformaten zusammengestellt.
| Format | Dateigröße | Bearbeitungsfreundlichkeit | Software-Kompatibilität | Eignung für gpt-image-2 Nachbearbeitung |
|---|---|---|---|---|
| PNG | Mittel | Niedrig (flach) | ✅ Exzellent | ⭐⭐⭐⭐⭐ Standardwahl |
| JPEG | Klein | Sehr niedrig | ✅ Exzellent | ⭐⭐⭐ Nur als Vorschau |
| WEBP | Klein | Niedrig | ⚠️ Web-fokussiert | ⭐⭐⭐ Für Web-Szenarien |
| PSD | Groß | ✅ Sehr hoch | ⚠️ Adobe-Ökosystem | ⭐⭐⭐⭐ Erfordert Nachbearbeitung |
| TIFF | Sehr groß | Mittel | ✅ Druck-fokussiert | ⭐⭐ Druck-Szenarien |
| SVG | Klein | ✅ Sehr hoch (vektorbasiert) | ✅ Web/Druck | ❌ Nicht von gpt-image-2 unterstützt |
Wie diese Tabelle zeigt, liegt der Kernwert von PSD in der „Bearbeitungsfreundlichkeit“, die von anderen Formaten kaum erreicht wird. Wenn Sie keine nachträgliche Bearbeitung benötigen, ist PNG in der Regel die bessere Wahl.
Zusammenfassung: Best Practices für die PSD-Ausgabe mit gpt-image-2
Zurück zur Ausgangsfrage: Wie kann gpt-image-2 PSD-Dateien ausgeben? Nach einer umfassenden Analyse lassen sich die wichtigsten Erkenntnisse in drei Punkten zusammenfassen:
- Der API-Pfad unterstützt keine direkte PSD-Ausgabe: Die gpt-image-2 API unterstützt lediglich die drei Rasterformate PNG, JPEG und WEBP. Dies ist die technische Grenze des Modells selbst.
- Die ChatGPT-Webversion kann über Photoshop echte, mehrschichtige PSD-Dateien ausgeben: Die Adobe Photoshop-App übernimmt hierbei die Ebenenverarbeitung, was ideal für die Anforderungen einzelner Designer ist.
- Für technische Szenarien ist eine Kombination aus „API-Generierung + Nachbearbeitung“ erforderlich: Durch den Einsatz von Tools wie SAM oder rembg zur automatischen Ebenentrennung und
psd-toolszum Schreiben der Datei lässt sich eine automatisierte Stapelverarbeitung realisieren.
| Benutzerrolle | Empfohlene Lösung | Tool-Kombination |
|---|---|---|
| Einzeldesigner | Lösung A | ChatGPT + Photoshop-Integration |
| Kleine Teams | Lösung B | gpt-image-2 API + manuelle Ebenentrennung in Photoshop |
| Unternehmensentwickler | Lösung C | gpt-image-2 API + automatisierte Ebenen-Pipeline |
🎯 Abschließende Empfehlung: Nutzen Sie zunächst die ChatGPT-Webversion mit der Photoshop-Integration, um den Prozess der Ebenentrennung zu verstehen, bevor Sie sich für den Aufbau einer API-Pipeline entscheiden. Wenn Sie eine technische Integration planen, können Sie gpt-image-2 über APIYI (apiyi.com) zentral anbinden. Die Plattform bietet OpenAI-kompatible Schnittstellen mit hoher Stabilität für Unternehmen und transparenter Abrechnung.
Wir hoffen, dass dieser vollständige Leitfaden zur PSD-Ausgabe mit gpt-image-2 Ihnen hilft, Umwege zu vermeiden. Die eigentliche Herausforderung bei der Ausgabe von PSD-Dateien durch gpt-image-2 liegt nicht in der API, sondern in der Wahl des richtigen Workflows. Wenn Sie Ihre Anforderungen, Ihr Budget und den Automatisierungsgrad berücksichtigen und sich für Lösung A, B oder C entscheiden, sollten Sie den gesamten Prozess in der Regel innerhalb einer Woche implementieren können.
Autor: APIYI Technical Team | apiyi.com — Plattform für unternehmensweite KI-Großes Sprachmodell-API-Proxy-Dienste