Anmerkung des Autors: Detaillierte Analyse der nativen, multimodalen Thinker-Talker MoE-Architektur des Qwen3.5-Omni-Modells von Alibaba, inklusive 256K-Kontextfenster, Audio-Video-Kodierung und der Audio-Visual Vibe Coding-Emergenz.
Das Team von Alibaba Qwen hat am 30. März 2026 offiziell Qwen3.5-Omni veröffentlicht. Dies ist ein natives, multimodales, einheitliches Modell, das Text, Bild, Audio und Video in einem einzigen Rechenpfad verarbeitet. Als Teil der intensiven Veröffentlichungsoffensive von Alibaba im März und April erreichte Qwen3.5-Omni in 215 Benchmarks den SOTA-Status und markiert damit einen bedeutenden Durchbruch für chinesische KI-Anbieter im Bereich der voll-modalen Großsprachmodelle.
Kernwert: Erfahren Sie in 3 Minuten alles über das Thinker-Talker-Architekturdesign von Qwen3.5-Omni, die Auswahlstrategien für die drei Modellvarianten sowie die Audio-Visual Vibe Coding-Emergenz.
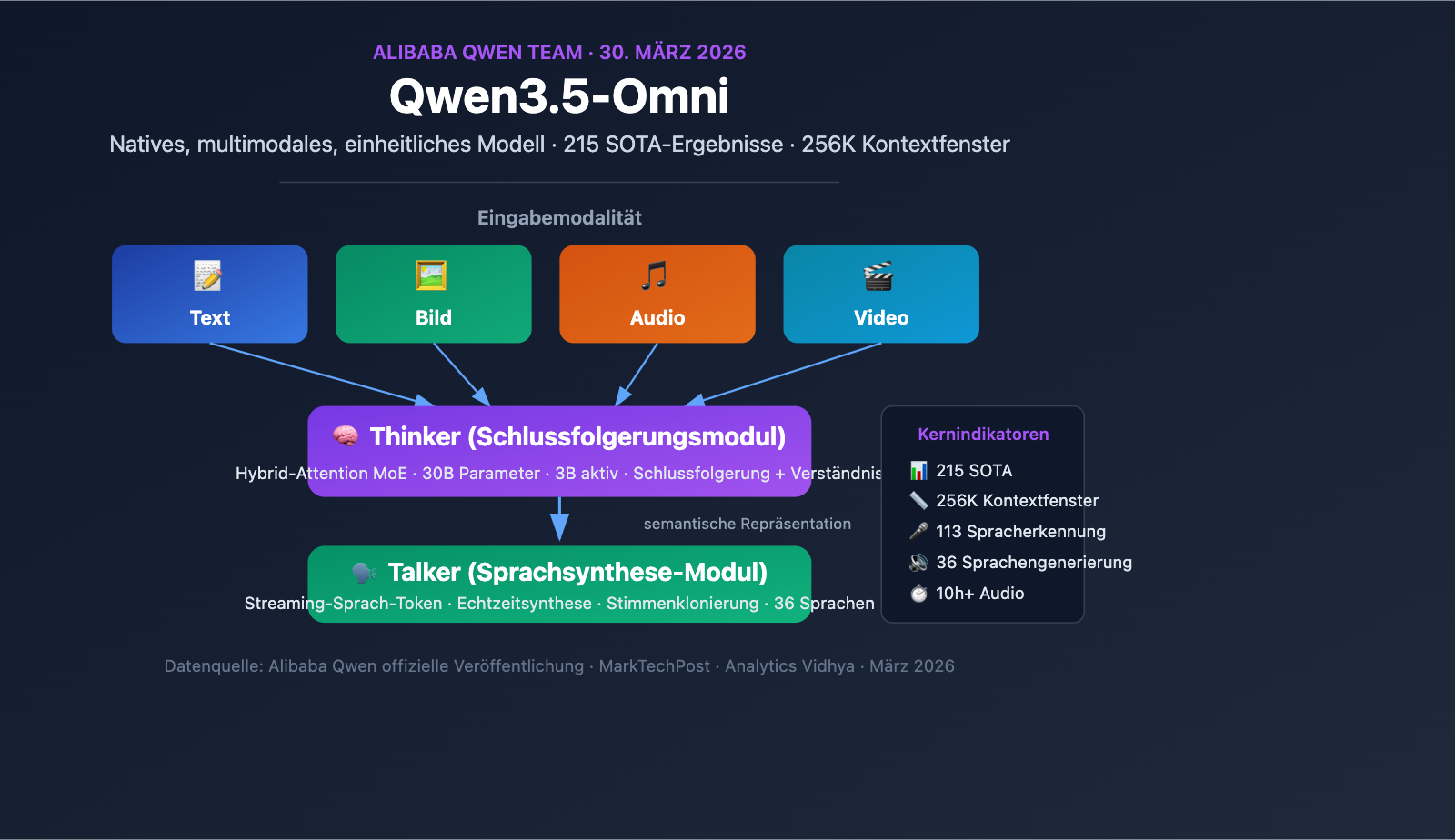
Qwen3.5-Omni Multimodales Modell – Kerninformationen
Kurzübersicht der Qwen3.5-Omni Parameter
| Parameter | Details |
|---|---|
| Veröffentlichungsdatum | 30. März 2026 |
| Herausgeber | Alibaba Qwen-Team |
| Architektur | Thinker-Talker + Hybrid-Attention MoE |
| Modellvarianten | Plus (30B-A3B MoE), Flash (leichtgewichtiges MoE), Light (dichtes Modell/offene Gewichte) |
| Kontextfenster | 256K Token |
| Audiokapazität | 10+ Stunden kontinuierliches Audio |
| Videokapazität | 400+ Sekunden 720p-Video (1 FPS Sampling) |
| Spracherkennung | 113 Sprachen und Dialekte (Vorgänger nur 19) |
| Sprachgenerierung | 36 Sprachen (Vorgänger nur 10) |
| Trainingsdaten | Über 100 Millionen Stunden Audio- und Videodaten |
| Benchmark-Ergebnisse | SOTA in 215 Audio-/Video-Verständnis-Benchmarks |
Modellpositionierung von Qwen3.5-Omni
Die Kernbedeutung von Qwen3.5-Omni liegt in seiner nativen Multimodalität – es handelt sich nicht um eine zusammengesetzte Lösung, bei der ein Textmodell mit Audio- und Videomodulen verbunden wird, sondern um ein einheitliches Modell, das von Grund auf mit über 100 Millionen Stunden Audio- und Videodaten vortrainiert wurde. Alle Modalitäten werden im selben Rechenpfad verarbeitet, was bedeutet, dass das Modell semantische Informationen in Audio und Video tatsächlich verstehen kann, anstatt sie lediglich in Text zu transkribieren.
Gleichzeitig ist Qwen3.5-Omni eines der Modelle aus Alibabas intensiver Veröffentlichungsserie im März und April 2026. Nur wenige Tage später, am 2. April, veröffentlichte Alibaba das Modell Qwen3.6-Plus (unterstützt 1 Million Token Kontext, Fokus auf agentische Programmierung), was das starke Engagement von Alibaba im Bereich der Großsprachmodelle unterstreicht.
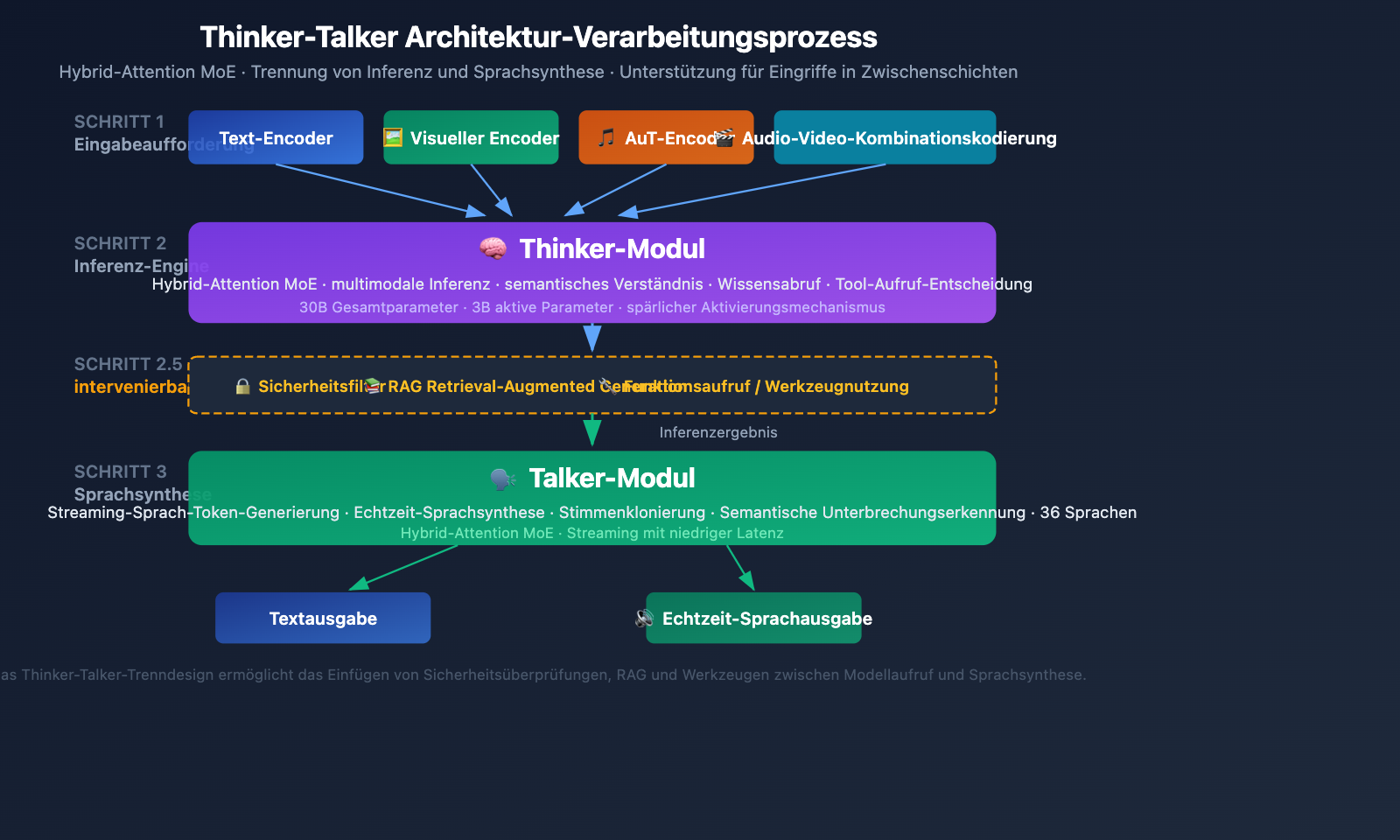
Detaillierte Analyse der Qwen3.5-Omni Thinker-Talker-Architektur
Das Thinker-Talker-Dual-Modul-Design
Qwen3.5-Omni nutzt eine einzigartige Thinker-Talker-Dual-Modul-Architektur. Dieses Design wurde erstmals mit Qwen2.5-Omni eingeführt und in der Version 3.5 grundlegend aktualisiert – beide Module verwenden nun die Hybrid-Attention-MoE-Architektur (Mixture-of-Experts mit hybrider Aufmerksamkeit).
Thinker-Modul (Denker):
- Verarbeitet alle Eingabemodalitäten: Text, Bild, Audio, Video
- Führt Schlussfolgerungs- und Verständnisaufgaben aus
- Erzeugt interne Repräsentationen für das logische Denken
- Verwendet einen nativen Audio-Transformer (AuT)-Encoder für die Audioverarbeitung
- Gibt strukturierte semantische Repräsentationen aus
Talker-Modul (Sprecher):
- Empfängt die Schlussfolgerungs-Repräsentationen des Thinkers
- Wandelt semantische Repräsentationen in Streaming-Audio-Token um
- Unterstützt Echtzeit-Sprachsynthese
- Ermöglicht eine natürliche Sprachausgabe (einschließlich Intonation, Emotion und Pausen)
Technischer Mehrwert der Thinker-Talker-Architektur
Der entscheidende Vorteil dieses getrennten Designs ist die Interventionsmöglichkeit in der Mitte – externe Systeme (RAG-Abruf-Pipelines, Sicherheitsfilter, Funktionsaufrufe) können zwischen der Ausgabe des Thinkers und der Synthese durch den Talker eingreifen. Das bedeutet:
- Unternehmen können vor der Sprachausgabe Sicherheitsüberprüfungen durchführen
- Entwickler können auf Basis der Schlussfolgerungsergebnisse Werkzeugaufrufe auslösen
- RAG-Systeme können Wissensabrufe vor der Antwort ergänzen
MoE-Mechanismus zur spärlichen Aktivierung
Der Kern des Hybrid-Attention-MoE-Designs ist die spärliche Aktivierung – das Modell aktiviert bei der Verarbeitung jedes Tokens nur einen Teil der Parameter (von insgesamt 30 Mrd. Parametern sind nur 3 Mrd. aktiv). Dieser Mechanismus ermöglicht es dem Modell, eine hohe Kapazität beizubehalten und gleichzeitig die Rechenkosten für einen einzelnen Modellaufruf in einem akzeptablen Rahmen zu halten, was für Echtzeitanwendungen (wie Sprachdialoge) entscheidend ist.
🎯 Entwicklungstipp: Die getrennte Thinker-Talker-Architektur von Qwen3.5-Omni eignet sich hervorragend für den Aufbau mehrstufiger KI-Workflows. Wenn Sie multimodale Fähigkeiten in Ihre eigene Anwendung integrieren möchten, können Sie über die APIYI-Plattform (apiyi.com) schnell die Leistungsunterschiede zwischen Qwen3.5-Omni und anderen gängigen multimodalen Modellen testen.
Vergleich der drei Qwen3.5-Omni Modellvarianten
Leitfaden zur Auswahl: Plus / Flash / Light
Qwen3.5-Omni bietet drei Modellvarianten für unterschiedliche Szenarien:
| Variante | Architekturtyp | Parameterumfang | Verfügbarkeit | Einsatzszenario |
|---|---|---|---|---|
| Plus | MoE (30B-A3B) | 30 Mrd. gesamt / 3 Mrd. aktiv | API (DashScope) | Höchste Qualität, komplexe multimodale Aufgaben |
| Flash | Leichtes MoE | Weniger Parameter | API (DashScope) | Szenarien mit geringer Latenz, Echtzeitdialoge |
| Light | Dichtes Modell | Kleinere Skalierung | Offene Gewichte (HuggingFace) | Lokale Bereitstellung, Edge-Geräte |
Auswahlempfehlung:
- Beste Ergebnisse erzielen → Wählen Sie die Plus-Variante, die in 215 Benchmarks die höchste Punktzahl erreicht hat
- Geringe Latenz anstreben → Wählen Sie die Flash-Variante, ideal für Echtzeit-Sprachdialoge und Streaming-Interaktionen
- Lokale Bereitstellung erforderlich → Wählen Sie die Light-Variante, deren offene Gewichte auf lokalen GPUs ausgeführt werden können
API-Anbindung von Qwen3.5-Omni
Die API von Qwen3.5-Omni folgt dem Standardformat /v1/chat/completions, wobei der Ausgabetyp über den Parameter modalities festgelegt wird:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # Einheitliche Anbindung über APIYI
)
response = client.chat.completions.create(
model="qwen3.5-omni-plus",
modalities=["text", "audio"],
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "Bitte analysiere den Inhalt dieses Videos"},
{"type": "video_url", "video_url": {"url": "https://example.com/video.mp4"}}
]
}
]
)
Vollständiges Beispiel für multimodale Eingabe anzeigen
import openai
import base64
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
# Multimodale Eingabe: Bild + Audio + Text
response = client.chat.completions.create(
model="qwen3.5-omni-plus",
modalities=["text", "audio"],
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "Bitte erstelle einen Analysebericht basierend auf dem Bild und der Sprachbeschreibung"},
{
"type": "image_url",
"image_url": {"url": "data:image/png;base64,..."}
},
{
"type": "input_audio",
"input_audio": {
"data": base64.b64encode(audio_bytes).decode(),
"format": "wav"
}
}
]
}
],
max_tokens=2000
)
# Textantwort abrufen
print(response.choices[0].message.content)
# Wenn eine Audioausgabe angefordert wurde, Audiodaten abrufen
if hasattr(response.choices[0].message, 'audio'):
audio_data = response.choices[0].message.audio
print(f"Audioformat: {audio_data.format}")
💡 Hinweis zur Anbindung: Die API von Qwen3.5-Omni ist mit dem OpenAI-SDK-Format kompatibel. Wenn Sie bereits Code auf Basis des OpenAI-SDKs haben, müssen Sie lediglich die Parameter
base_urlundmodelanpassen, um schnell zu wechseln. Über die APIYI-Plattform (apiyi.com) können Sie die multimodale Leistung von Qwen3.5-Omni und Modellen wie GPT-4o direkt vergleichen.
Qwen3.5-Omni Benchmark-Leistungsanalyse
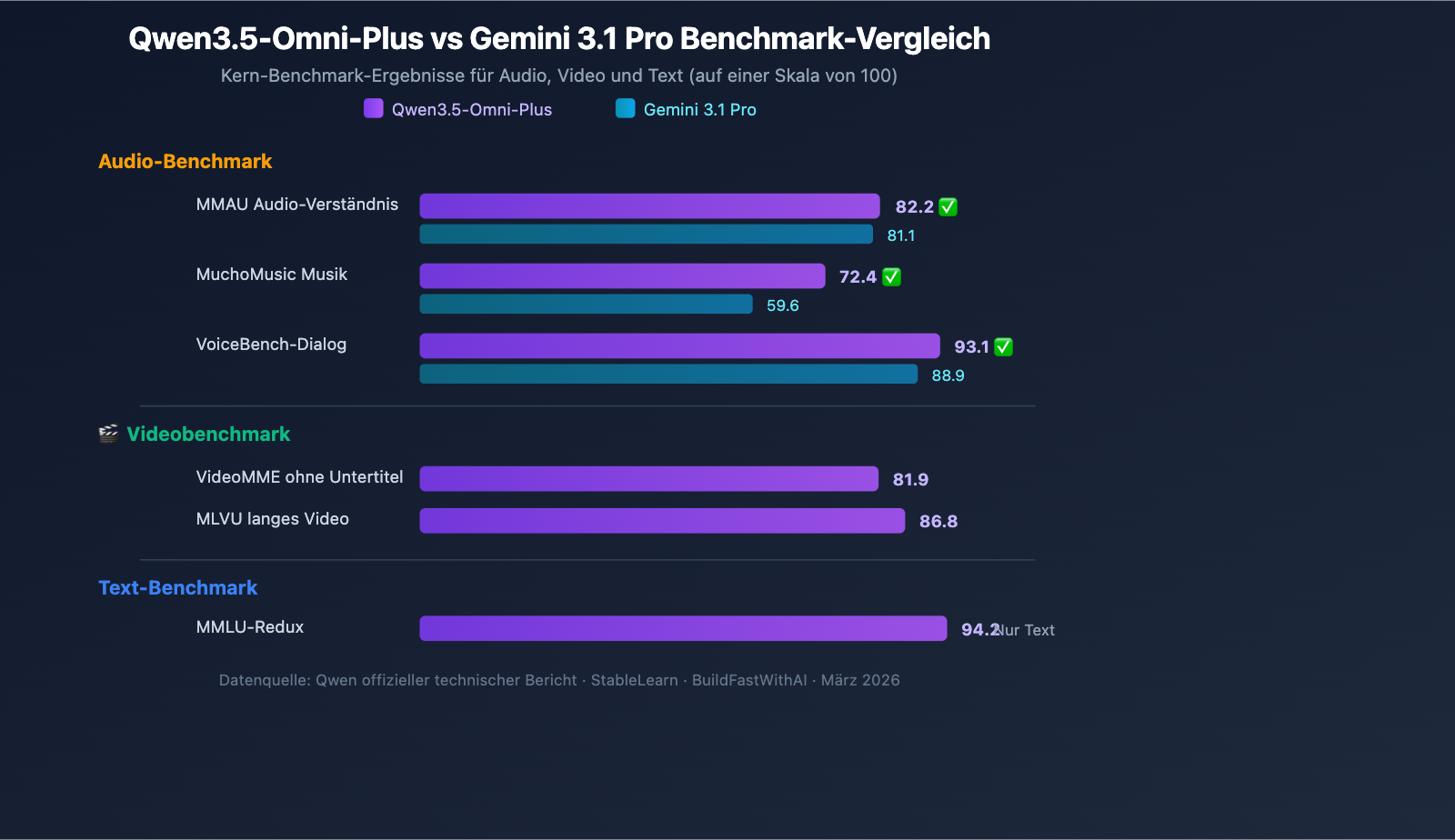
Audio-Verständnisfähigkeiten
Qwen3.5-Omni-Plus übertrifft Google Gemini 3.1 Pro in audiobezogenen Benchmarks durchweg:
| Benchmark | Qwen3.5-Omni-Plus | Gemini 3.1 Pro | Gewinner |
|---|---|---|---|
| MMAU Audio-Verständnis | 82,2 | 81,1 | Qwen |
| MuchoMusic Musikverständnis | 72,4 | 59,6 | Qwen (+21%) |
| VoiceBench Dialog | 93,1 | 88,9 | Qwen |
Beim Musikverständnis (MuchoMusic) ist der Vorsprung von Qwen3.5-Omni mit 21 % besonders deutlich.
Bild- und Videofähigkeiten
| Benchmark | Qwen3.5-Omni-Plus | Beschreibung |
|---|---|---|
| MMMU-Pro | 73,9 | Höchste Punktzahl für multimodales Verständnis |
| RealWorldQA | 84,1 | Visuelle Fragenbeantwortung in der realen Welt |
| VideoMME (ohne Untertitel) | 81,9 | Multimodales Videoverständnis |
| MLVU | 86,8 | Verständnis langer Videos |
| MVBench | 79,0 | Mehrdimensionaler Videobenchmark |
| LVBench | 71,2 | Benchmark für lange Videos |
Beibehaltung der Textschlussfolgerung
Qwen3.5-Omni behält seine volle multimodale Leistungsfähigkeit bei, ohne dass die Textschlussfolgerungsleistung nennenswert abnimmt:
| Benchmark | Qwen3.5-Omni-Plus | Qwen3.5-Plus (Nur Text) | Differenz |
|---|---|---|---|
| MMLU-Redux | 94,2 | 94,3 | -0,1 |
| C-Eval | 92,0 | 92,3 | -0,3 |
| IFEval | 89,7 | 89,7 | 0 |
Das bedeutet, dass Sie bei der Wahl von Qwen3.5-Omni keine Abstriche bei der Qualität der Textschlussfolgerung machen müssen – Sie können ein Modell für Text- und multimodale Szenarien gleichzeitig verwenden.
🎯 Empfehlung zur Modellauswahl: Qwen3.5-Omni bietet klare Vorteile beim Audio- und Musikverständnis. Wenn Ihre Anwendung Sprachinteraktion oder Audioanalyse umfasst, sollten Sie dieses Modell bevorzugen. Über APIYI (apiyi.com) können Sie schnell die Leistungsunterschiede zwischen Qwen3.5-Omni und GPT-4o in Ihren spezifischen Szenarien vergleichen.
Die 3 differenzierenden Fähigkeiten von Qwen3.5-Omni
Fähigkeit 1: Audio-Visual Vibe Coding
Qwen3.5-Omni zeigt eine von der Qwen-Entwicklergruppe als „Audio-Visual Vibe Coding“ bezeichnete emergente Fähigkeit – das Modell kann durch das Ansehen von Videos + das Anhören von Sprachbefehlen ausführbaren Code schreiben, ohne speziell dafür trainiert worden zu sein.
In praktischen Tests konnte das Modell:
- Handgezeichnete Skizzen (per Kamera aufgenommen) in ausführbare React-Webseiten umwandeln.
- Funktionscode basierend auf Videodemonstrationen und mündlichen Beschreibungen schreiben.
- Visuelle Designabsichten verstehen und die entsprechende Frontend-Implementierung generieren.
Diese Fähigkeit ist für die schnelle Prototypenentwicklung und Low-Code-Szenarien von erheblichem Wert.
Fähigkeit 2: Erkennung semantischer Unterbrechungen
Herkömmliche Sprachinteraktionssysteme können nicht zwischen den reaktiven Rückmeldungen der Benutzer wie „Mhm“ oder „Ja“ und einer tatsächlichen Unterbrechungsabsicht unterscheiden. Qwen3.5-Omni führt eine native Turn-Taking Intent Recognition (Erkennung der Absicht zur Gesprächsübernahme) ein, die unterscheiden kann zwischen:
- Reaktivem Feedback (Backchanneling): Wie „Mhm“, „Ja“ usw., ohne semantische Unterbrechungsabsicht.
- Semantischer Unterbrechung (Semantic Interruption): Situationen, in denen der Benutzer die klare Absicht hat, das Gespräch zu übernehmen.
Dies macht das Sprachdialogerlebnis mit Qwen3.5-Omni deutlich natürlicher und menschenähnlicher.
Fähigkeit 3: Stimmenklonierung
Benutzer können eine Sprachaufnahme hochladen; Qwen3.5-Omni lernt und klont diese Stimmmerkmale und verwendet die geklonte Stimme in allen nachfolgenden Sprachausgaben. Die geklonte Stimme behält ihre Natürlichkeit und Stabilität auch in mehrsprachigen Szenarien bei.
Die Positionierung von Qwen3.5-Omni in Alibabas KI-Offensive
Alibabas KI-Modell-Veröffentlichungsplan für März/April 2026
| Veröffentlichungsdatum | Modell | Positionierung | Hauptmerkmale |
|---|---|---|---|
| 30. März | Qwen3.5-Omni | Natives multimodales Modell | Einheitliche Verarbeitung von Text/Bild/Audio/Video |
| 2. April | Qwen3.6-Plus | Enterprise-Agenten-Modell | 1 Mio. Token Kontextfenster, agentenbasiertes Programmieren |
| Laufend | Qwen3-TTS | Sprachsynthese | Open-Source-TTS-Serie, unterstützt Stimmenklonierung |
Dieser dichte Veröffentlichungsrhythmus zeigt, dass Alibaba den Ausbau seiner Kapazitäten bei Großsprachmodellen auf breiter Front vorantreibt. Qwen3.5-Omni deckt die multimodale Wahrnehmung und das Verständnis ab, während Qwen3.6-Plus auf die Generierung von Unternehmenscode und Agentenfähigkeiten spezialisiert ist – beide ergänzen sich ideal.
Bemerkenswert ist, dass die Plus- und Flash-Varianten von Qwen3.5-Omni als Closed-Source-API veröffentlicht wurden, was mit Alibabas bisheriger Open-Source-Strategie bricht. Medien wie WinBuzzer analysieren dies als Reaktion auf den kommerziellen Druck und den Fokus auf Profitabilität – ein Bloomberg-Bericht titelte treffend: „Alibaba bringt drittes Closed-Source-KI-Modell auf den Markt, Fokus auf Gewinn“.
💰 Kostentipp: Wenn Sie planen, Qwen3.5-Omni in Ihr Produkt zu integrieren, empfiehlt es sich, zunächst ein Proof-of-Concept über das kostenlose Guthaben der Plattform APIYI (apiyi.com) durchzuführen, um die Modellleistung zu validieren, bevor Sie in die produktive Bereitstellung gehen. Die Plattform unterstützt die gesamte Modellpalette von Qwen, GPT, Claude bis hin zu Gemini und ermöglicht so eine flexible Auswahl für verschiedene Szenarien.
Häufig gestellte Fragen (FAQ)
Q1: Ist Qwen3.5-Omni Open-Source oder Closed-Source?
Qwen3.5-Omni gibt es in drei Varianten: Plus und Flash sind derzeit nur über die Alibaba Cloud DashScope API verfügbar (Closed-Source), während die Gewichte der Light-Variante auf HuggingFace zum Download bereitstehen (Open-Source). Das Vorgängermodell Qwen3-Omni war unter der Apache 2.0-Lizenz vollständig Open-Source, doch bei der 3.5-Version sind die Plus/Flash-Varianten auf ein reines API-Modell umgestiegen. Wenn Sie eine lokale Bereitstellung benötigen, ist die Light-Variante die richtige Wahl.
Q2: Wie schneidet Qwen3.5-Omni im Vergleich zu GPT-4o ab?
Beim Verständnis von Audio und Musik liegt Qwen3.5-Omni-Plus deutlich vor GPT-4o. Bei der Videoverarbeitung haben beide Modelle ihre jeweiligen Stärken. In der Textlogik liegt Qwen3.5-Omni nahezu gleichauf mit dem reinen Textmodell Qwen3.5-Plus. Wir empfehlen, über die Plattform APIYI (apiyi.com) Vergleichstests in Ihrem spezifischen Anwendungsfall durchzuführen, da die Leistung je nach Szenario stark variieren kann.
Q3: Wie kann ich schnell mit der Qwen3.5-Omni API starten?
Die API von Qwen3.5-Omni ist mit dem Standard-OpenAI-SDK kompatibel, was die Einbindung sehr einfach macht. Installieren Sie einfach das openai-SDK, konfigurieren Sie den entsprechenden API-Schlüssel und die base_url, und schon können Sie den Modellaufruf starten. Über APIYI (apiyi.com) erhalten Sie kostenloses Testguthaben, um die multimodalen Aufrufe mit den Codebeispielen in diesem Artikel schnell zu validieren.
Zusammenfassung
Die wichtigsten Punkte zum multimodalen Modell Qwen3.5-Omni:
- Natives All-Modal-Design: Verarbeitet Text, Bild, Audio und Video in einer einzigen Pipeline, statt auf zusammengesetzte Lösungen zu setzen.
- Thinker-Talker-Architektur: Trennung von Schlussfolgerung und Sprachsynthese, unterstützt Eingriffe auf Zwischenebene sowie Werkzeugaufrufe.
- 3 Varianten zur Auswahl: Plus (leistungsstärkste), Flash (geringe Latenz), Light (offene Gewichte für lokale Bereitstellung).
- 215 SOTA-Benchmarks: Führend bei Audio- und Musikverständnis, deutlich vor Gemini 3.1 Pro.
- Emergente Fähigkeiten: „Audio-Visual Vibe Coding“ ermöglicht es dem Modell, Code basierend auf Video- und Audioeingaben zu schreiben.
Qwen3.5-Omni markiert einen bedeutenden Fortschritt in der multimodalen KI – ein Modell, das Text, Bild, Audio und Video abdeckt, ohne bei der Textschlussfolgerung Kompromisse einzugehen. Für Entwickler, die multimodale Funktionen benötigen, ist dies eine ernstzunehmende Option.
Wir empfehlen, Qwen3.5-Omni und andere führende multimodale Modelle schnell über APIYI (apiyi.com) zu testen. Die Plattform bietet kostenlose Kontingente und eine einheitliche API-Schnittstelle, was den Vergleich und die Auswahl erheblich erleichtert.
📚 Referenzen
-
MarkTechPost-Bericht: Detaillierte Vorstellung von Qwen3.5-Omni
- Link:
marktechpost.com/2026/03/30/alibaba-qwen-team-releases-qwen3-5-omni-a-native-multimodal-model-for-text-audio-video-and-realtime-interaction - Hinweis: Ausführliche technische Analyse und Erläuterung der Architektur.
- Link:
-
Qwen3-Omni GitHub-Repository: Quellcode und Modellgewichte
- Link:
github.com/QwenLM/Qwen3-Omni - Hinweis: Vollständiger Code und Dokumentation des Vorgängermodells Qwen3-Omni.
- Link:
-
Analytics Vidhya Deep Dive: Analyse des technischen Berichts zu Qwen3.5-Omni
- Link:
analyticsvidhya.com/blog/2026/03/qwen3-5-omni-ai-model - Hinweis: Umfassende Analyse von Funktionen wie Stimmenklonierung und Vibe Coding.
- Link:
-
eWeek-Bericht: Qwen3.5-Omni als Alibabas fortschrittlichstes multimodales Modell
- Link:
eweek.com/news/qwen3-5-omni-alibaba-multimodal-ai-launch - Hinweis: Branchenperspektive und Wettbewerbsvergleich.
- Link:
-
HuggingFace Modellseite: Qwen3-Omni-30B-A3B-Instruct
- Link:
huggingface.co/Qwen/Qwen3-Omni-30B-A3B-Instruct - Hinweis: Download der Modellgewichte und technische Spezifikationen.
- Link:
Autor: APIYI Technik-Team
Technischer Austausch: Diskutieren Sie gerne in den Kommentaren über praktische Anwendungen multimodaler KI. Weitere KI-Entwicklungsressourcen finden Sie im APIYI-Dokumentationszentrum unter docs.apiyi.com.