Der größte Kostenfaktor bei LLM-Anwendungen sind nicht die ausgegebenen Tokens, sondern die wiederholt übertragenen System-Prompts und langen Dokumente. OpenAI und Anthropic haben darauf reagiert – mit Prompt Caching. Doch die Abrechnungsphilosophien beider Unternehmen unterscheiden sich grundlegend: OpenAI setzt auf „Zero-Config und moderate Rabatte“, während Claude den Weg der „expliziten Deklaration und maximalen Rabatte“ geht.
Dieser Artikel basiert auf den neuesten offiziellen Dokumentationen und Praxistests von Entwicklern vom Mai 2026. Wir vergleichen die Cache-Abrechnungsregeln von OpenAI und Claude anhand von sechs Dimensionen: Mindestlänge der Eingabeaufforderung, Strukturvorgaben, Aufschläge beim Schreiben, Rabatte beim Lesen, TTL-Steuerung und Cache-Granularität. Zudem berechnen wir anhand eines realen Szenarios mit 100.000 Tokens, wie viel Sie mit den jeweiligen Lösungen tatsächlich sparen können.
Kernnutzen: Nach der Lektüre dieses Artikels wissen Sie sofort, welche Cache-Lösung für Ihr Unternehmen geeignet ist, wie viel Sie sparen können und welche technischen Anpassungen erforderlich sind.
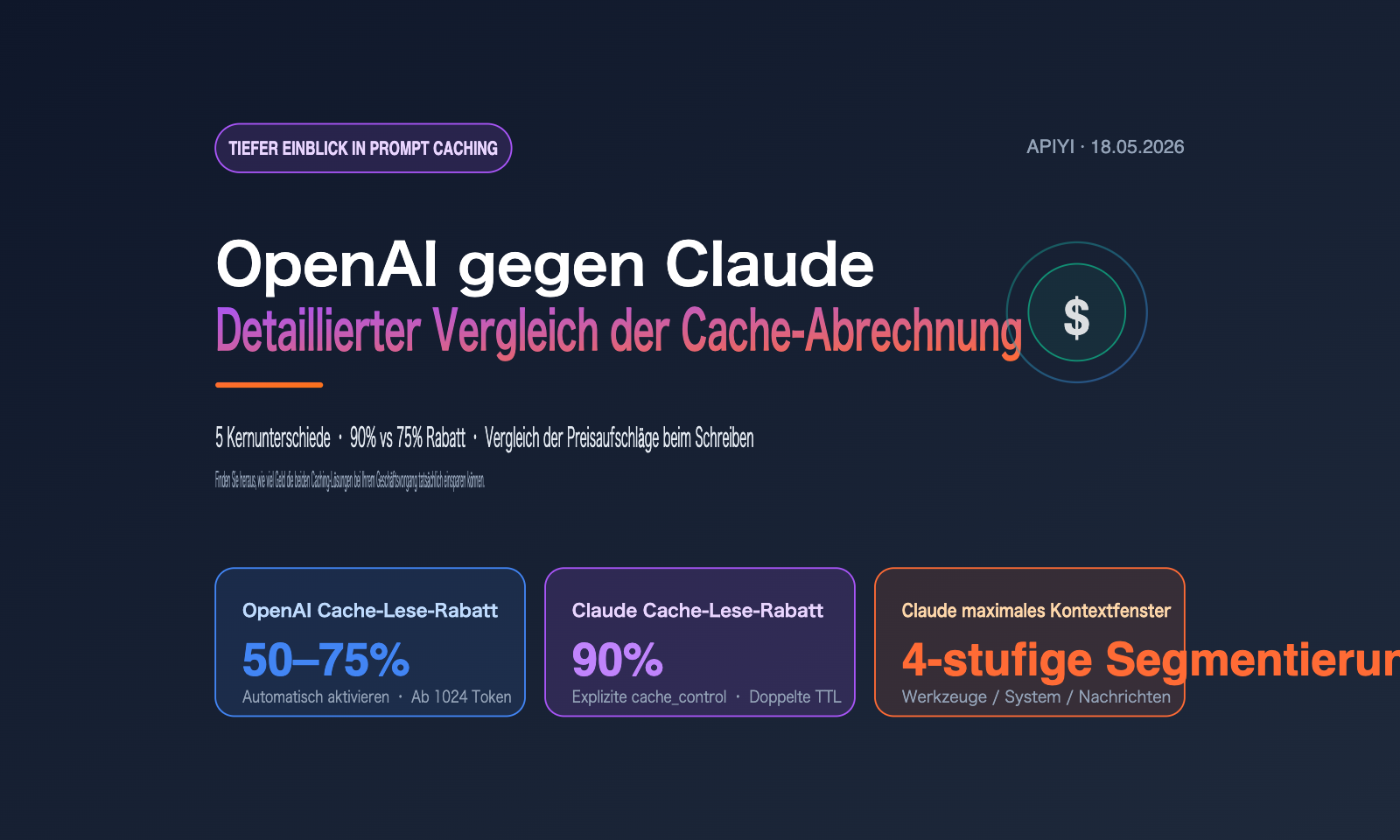
5 Kernunterschiede bei der Cache-Abrechnung von OpenAI und Claude im Überblick
Auf den ersten Blick scheinen beide Cache-Lösungen lediglich „Rabatte beim Lesen aus dem Cache“ zu bieten. Doch die Designphilosophie hinter jeder Regel bestimmt den tatsächlichen wirtschaftlichen Nutzen in verschiedenen Geschäftsszenarien. Die folgende Tabelle fasst die 5 Hauptunterschiede basierend auf den offiziellen Preisdokumenten zusammen.
| Differenzierungsmerkmal | OpenAI-Cache | Claude-Cache |
|---|---|---|
| Aktivierung | Vollautomatisch, keine Konfiguration | Expliziter cache_control-Parameter |
| Mindestlänge Eingabe | 1024 Tokens (einheitlich) | 1024 / 4096 Tokens (modellabhängig) |
| Zusatzkosten Schreiben | 0 (kein Aufschlag) | 1,25× (5 Min.) oder 2× (1 Std.) Basispreis |
| Leserabatt | 50 % – 75 % Rabatt | 90 % Rabatt (einheitlich) |
| Cache-Granularität | Einzelne Präfix-Übereinstimmung | Bis zu 4 Breakpoint-Ebenen |
| TTL-Steuerung | Automatisch zwischen 5–10 Min. | Zwei Stufen: 5 Min. und 1 Std. wählbar |
Wenn man diese Tabelle versteht, lässt sich das Fazit kurz zusammenfassen: OpenAI ermöglicht einen „kostenlosen“ Einstieg, Claude erfordert eine „investitionsorientierte“ Implementierung. OpenAI eignet sich für schnelle Projekte mit begrenztem Budget und Ressourcen, während Claude ideal für groß angelegte, kontrollierbare und langfristige Produktionslasten ist.
🎯 Empfehlung für den schnellen Vergleich: Wenn Sie die Cache-Abrechnungseffekte von OpenAI und Claude im selben Projekt testen möchten, empfiehlt sich die Anbindung über den API-Proxy-Dienst APIYI (apiyi.com). Die Plattform bietet ein OpenAI-kompatibles Protokoll für beide Anbieter. So können Sie mit nur einem Code-Satz und durch einfaches Umschalten des
model-Feldes diecached_tokensundcache_read_input_tokensbeider Anbieter direkt vergleichen.
Details zu den Abrechnungsregeln für OpenAI-API-Caching
Das Caching-Design von OpenAI ist extrem simpel. Die Kernregel lautet: Sobald Ihr Eingabeaufforderungs-Präfix mindestens 1024 Token umfasst und identisch mit der vorherigen Anfrage ist, gewährt das System automatisch einen Rabatt – ganz ohne Code- oder Header-Anpassungen.
Anforderungen an Länge und Struktur der Eingabeaufforderung für OpenAI-Caching
Die Bedingungen für einen Cache-Treffer bei OpenAI lassen sich in zwei harte Einschränkungen unterteilen: Die Eingabeaufforderung muss mindestens 1024 Token lang sein, und der Cache gleicht nur den Präfix-Teil der Anfrage ab. Dynamische Inhalte müssen daher zwingend am Ende der Eingabeaufforderung stehen. Die Regeln im Detail:
- Mindestlänge: Die Gesamtlänge der Eingabeaufforderung muss ≥ 1024 Token betragen. Ist sie kürzer, erfolgt kein Caching (es gibt jedoch keine Fehlermeldung).
- Präfix-Abgleich: Das System vergleicht die Eingabeaufforderung Token für Token ab dem Anfang. Sobald sich ein Element in der Mitte ändert, wird der gesamte nachfolgende Teil zum Standardtarif abgerechnet.
- 128-Token-Schritte: Cache-Treffer erfolgen in 128-Token-Schritten. Nach Überschreiten der 1024-Token-Grenze führen jeweils 128 weitere identische Token zu weiteren Treffern.
- Identität: Dies umfasst Systemnachrichten, Tool-Definitionen, historische Nachrichten und Bilder. Jede noch so kleine Abweichung macht den Cache ungültig.
- Automatische Verwaltung: Es sind keine Cache-IDs oder manuelle Invalidierungen erforderlich. Der Cache wird nach 5–10 Minuten Inaktivität automatisch gelöscht, in Zeiten geringer Auslastung kann dies auf bis zu 1 Stunde verlängert werden.
Das bedeutet: Wenn auf Ihren System-Prompt dynamische Präfixe wie Zeitstempel oder Benutzer-IDs folgen, wird der gesamte Cache ungültig. Das Verschieben dynamischer Inhalte an das Ende und statischer Inhalte an den Anfang ist entscheidend für die Wirksamkeit des OpenAI-Cachings.
Echte Rabattbereiche bei OpenAI
Die Leserabatte von OpenAI sind nicht einheitlich, sondern modellabhängig. Einige neue Modelle wie GPT-5.5 bieten einen aggressiveren Rabatt von 75 %. Die folgende Tabelle zeigt die Cache-Preise für gängige OpenAI-Modelle im Mai 2026.
| Modell | Standard-Input ($/M) | Cache-Lesen ($/M) | Rabattsatz |
|---|---|---|---|
| GPT-5.5 | 5,00 | 1,25 | 75% |
| GPT-5.5 mini | 0,25 | 0,0625 | 75% |
| GPT-4o | 2,50 | 1,25 | 50% |
| GPT-4o mini | 0,15 | 0,075 | 50% |
| o1-preview | 15,00 | 7,50 | 50% |
OpenAI gibt die Anzahl der tatsächlich im Cache gefundenen Token im Feld usage.prompt_tokens_details.cached_tokens der Antwort zurück. Sie können dieses Feld direkt zur Berechnung der Einsparungen verwenden. Vollautomatisch + moderater Rabatt ist das Kernkonzept der OpenAI-Abrechnung.
Details zu den Abrechnungsregeln für Claude-API-Caching
Die Philosophie hinter dem Caching von Claude ähnelt eher einem "expliziten Versprechen": Sie müssen dem Modell explizit mitteilen: "Diesen Teil möchte ich zwischenspeichern". Dafür gewährt das Modell einen extremen Rabatt von 90 %, allerdings ist das Schreiben mit einem Aufschlag verbunden.
Mindestanforderungen an Token für das Claude-Caching (modellabhängig)
Während OpenAI eine pauschale Grenze von 1024 Token vorgibt, unterscheidet Claude nach Modellklassen. Hier sind die Mindestschwellen für die aktuellen Claude-Modelle:
| Modell | Mindest-Cache-Token | Standard-Input ($/M) | 5-Min-Schreiben ($/M) | Cache-Lesen ($/M) |
|---|---|---|---|---|
| Claude Opus 4.7 / 4.6 / 4.5 | 4096 | 5,00 | 6,25 | 0,50 |
| Claude Sonnet 4.6 / 4.5 | 1024 | 3,00 | 3,75 | 0,30 |
| Claude Opus 4.1 | 1024 | 15,00 | 18,75 | 1,50 |
| Claude Haiku 4.5 | 4096 | 1,00 | 1,25 | 0,10 |
Das bedeutet: Wenn Sie die neueste Opus- oder Haiku-Generation verwenden, wird ein 3000 Token langer System-Prompt überhaupt nicht zwischengespeichert. Sie müssen aktiv Inhalte (wie vollständige Tool-Definitionen oder Beispiel-Dialoge) hinzufügen, um die 4096-Token-Marke zu erreichen. Bei der Sonnet-Serie ist dies nicht erforderlich; hier reichen 1024 Token aus.
TTL-Stufen und Amortisationsregeln bei Claude
Ein weiteres wichtiges Merkmal von Claude ist die Wahlmöglichkeit zwischen zwei TTL-Stufen (Time-to-Live): standardmäßig 5 Minuten oder optional 1 Stunde, mit deutlichen Preisunterschieden.
- 5 Minuten TTL: 25 % Aufschlag beim Schreiben. Rentiert sich bereits ab dem ersten Lesezugriff – ideal für Chatbots und häufige Abfragen.
- 1 Stunde TTL: 100 % Aufschlag beim Schreiben (doppelter Preis). Rentiert sich erst ab ≥ 2 Lesezugriffen – ideal für Batch-Verarbeitung, Agenten-Workflows oder regelmäßige Berichte.
- Gemischte TTL: Längere TTL-Stufen müssen vor kürzeren platziert werden, um verschiedene Cache-Strategien gleichzeitig zu nutzen.
Wichtig: Die 5-Minuten-TTL verlängert sich nach jedem erfolgreichen Lesezugriff automatisch. Ein "aktiver" Cache kann also unbegrenzt bestehen bleiben, solange die Anfragen innerhalb des 5-Minuten-Fensters liegen – Sie zahlen die Schreibgebühr nur einmal.
Hierarchien und Breakpoint-Steuerung bei Claude
Der größte Vorteil von Claude sind die bis zu 4 Cache-Breakpoints, mit denen Sie Ihre Eingabeaufforderung in mehrere unabhängig verwaltbare Ebenen unterteilen können. Die Hierarchie folgt strikt der Reihenfolge Tools → System → Messages. Die Tool-Ebene enthält Definitionen und Funktions-Schemas, die System-Ebene System-Prompts und Rollenzuweisungen, und die Messages-Ebene den Dialogverlauf sowie Kontextdokumente.
Besonders kritisch: Ein Fehler in einer oberen Ebene macht alle darunterliegenden Ebenen ungültig. Ändern Sie eine Zeile in der Tool-Definition, werden die Caches für System und Messages ebenfalls gelöscht. Umgekehrt bleibt der Cache der oberen Ebenen gültig, wenn Sie nur die letzte Benutzernachricht ändern. Architektonisch sollten Sie Inhalte mit der geringsten Änderungsrate so weit oben wie möglich platzieren.
Beachten Sie zudem, dass jeder Breakpoint ein Rückblick-Fenster von etwa 20 Blöcken hat: Das System sucht ab dem Breakpoint 20 Blöcke zurück nach identischen Inhalten. Nach mehr als 20 Dialogrunden empfiehlt es sich, einen weiteren Breakpoint einzufügen, damit der historische Cache nicht "unsichtbar" wird.
💡 Architektur-Empfehlung: Für komplexe Anwendungen, die mehrere Modelle gleichzeitig einbinden, empfehlen wir praktische Tests über die Plattform APIYI (apiyi.com). Sie unterstützt einheitliche Schnittstellen für OpenAI und Claude, sodass Sie ohne Code-Änderungen direkt vergleichen können, welche Cache-Strategie für Ihre Arbeitslast kosteneffizienter ist.
Kostenanalyse der Cache-Abrechnung bei OpenAI und Claude
Theoretische Analysen sind das eine, doch die tatsächlichen finanziellen Auswirkungen zeigen sich erst in konkreten Anwendungsszenarien. Wir haben ein typisches Geschäftsszenario modelliert:
- Statischer System-Prompt: 100.000 Token (technische Dokumentation + Few-Shot-Beispiele)
- Pro Benutzeranfrage: 100 Token Eingabe (tatsächliche Frage) + 1.000 Token Ausgabe
- Aufrufhäufigkeit: 1.000 Anfragen pro Tag, gleichmäßig über die Arbeitszeit verteilt
- Vergleichsmodelle: GPT-5.5 vs. Claude Sonnet 4.6 (beide als „Arbeitspferde“ ihrer jeweiligen Anbieter)

Vergleichstabelle der täglichen Kosten für die Cache-Abrechnung
Die folgende Tabelle schlüsselt die Kosten für das oben genannte Szenario auf. Bitte beachten Sie, dass alle Zahlen die Kosten für die Eingabe-Token darstellen und die Ausgabe-Token ausschließen (da die Preise für die Ausgabe bei beiden Anbietern ähnlich sind).
| Posten | GPT-5.5 ohne Cache | OpenAI mit Cache | Sonnet 4.6 ohne Cache | Claude 5min Cache |
|---|---|---|---|---|
| Erstmalige Schreibkosten | — | $0,50 | — | $0,375 |
| Folgeabrufe (999 Mal) | $499,50 | $124,875 | $299,70 | $29,97 |
| Tägliche Eingabekosten | $500,00 | $125,38 | $300,00 | $30,35 |
| Einsparungsquote | 0% | 75% | 0% | 90% |
| Monatliche Kosten (30 Tage) | $15.000 | $3.761 | $9.000 | $910 |
Das Fazit ist eindeutig: Bei gleicher Last betragen die monatlichen Kosten für Claude Sonnet 4.6 mit aktiviertem Cache nur etwa 24 % der monatlichen Kosten von GPT-5.5 mit aktiviertem Cache. Wenn Ihr Geschäftsmodell typischerweise aus „langem System-Prompt + kurzen Fragen“ besteht, wächst der Kostenvorteil von Claude linear mit dem Skalierungsumfang.
Es gibt jedoch zwei implizite Voraussetzungen, die man beachten sollte:
- Der Cache muss tatsächlich treffen: Wenn sich der System-Prompt häufig ändert, schrumpfen die Einsparungen bei beiden Anbietern erheblich.
- Unterschiede in der Modellleistung werden nicht berücksichtigt: Die Ausgabequalität von GPT-5.5 und Sonnet 4.6 kann je nach Aufgabe variieren; eine ganzheitliche Bewertung basierend auf geschäftlichen Kennzahlen ist erforderlich.
💰 Tipp zur Kostenoptimierung: Für budgetsensitive Projekte empfiehlt sich die Nutzung der API über die Plattform APIYI (apiyi.com). Diese bietet flexible Abrechnungsmodelle und attraktivere Preise, was besonders für kleine Teams und Einzelentwickler ideal ist, um den echten ROI von Caching-Strategien schnell zu validieren, ohne zwei separate Abrechnungssysteme verwalten zu müssen.
Empfehlungen für Caching-Szenarien bei OpenAI und Claude
Der Preis ist nur eine Variable. Ob sich der technische Aufwand für das Caching lohnt, ob eine stabile Trefferquote gewährleistet werden kann und ob die Lösung mit einer Multi-Modell-Architektur kompatibel ist – all das muss bedacht werden. Im Folgenden finden Sie klare Empfehlungen für verschiedene Geschäftsszenarien.
Typische Szenarien für das OpenAI-Caching
Der größte Vorteil des OpenAI-Cachings liegt in der „nahtlosen Integration“. Es eignet sich besonders für Teams, die keine speziellen Ressourcen für die Optimierung der Eingabeaufforderung (Prompt Engineering) haben oder sich in einer frühen Phase befinden, in der die Geschäftslogik noch nicht stabil ist.
- Einfache Chatbots und FAQ-Systeme, bei denen die System-Eingabeaufforderung kurz ist, aber das Aufrufvolumen hoch.
- Phase der schnellen Prototypen-Validierung: Hier steht die Reduzierung von Entwicklungsaufwand im Vordergrund, um erst die Ergebnisse zu sehen, bevor über Optimierungen gesprochen wird.
- Projekte, die bereits intensiv das OpenAI-Ökosystem nutzen (Function Calling, Structured Outputs etc.) und keine neuen SDKs einführen möchten.
- Umgebungen mit Team-übergreifender Zusammenarbeit, in denen nicht garantiert werden kann, dass alle Entwickler den Parameter
cache_controlkorrekt verwenden.
Typische Szenarien für das Claude-Caching
Die Vorteile des Claude-Cachings kommen bei langen Eingabeaufforderungen, häufigen Lesezugriffen und kontrollierbaren Produktionslasten voll zur Geltung.
- Lange System-Eingabeaufforderungen + RAG mit umfangreichen Dokumenten: Wenn beispielsweise ein komplettes Produkthandbuch in die System-Eingabeaufforderung geladen wird, ist der Rabatt von 90 % äußerst attraktiv.
- Agenten mit mehrstufigen Tool-Aufrufen: Tool-Definitionen und System-Eingabeaufforderungen können unabhängig voneinander zwischengespeichert werden, was ideal für lange Inferenzketten ist.
- Batch- / Offline-Aufgaben: Ein TTL von 1 Stunde kombiniert mit wenigen Lesezugriffen pro Minute nutzt den 2-fachen Aufschlag für Schreibvorgänge optimal aus.
- Mehrschichtige Eingabeaufforderungen: Vorlagen, Wissensdatenbanken und Benutzerkontext können in vier verschiedene Breakpoints unterteilt werden, um die Gültigkeit präzise zu steuern.
Vergleichstabelle: Caching-Kosten und Auswahlkriterien
Die folgende Tabelle vergleicht die wichtigsten Entscheidungskriterien beider Anbieter, damit Sie diese direkt mit Ihrem Projekt abgleichen können.
| Entscheidungskriterium | OpenAI-Caching | Claude-Caching | Empfehlung |
|---|---|---|---|
| Technischer Aufwand | Nahezu null | Erfordert cache_control-Anpassung |
OpenAI |
| Einsparpotenzial | 50 %–75 % | 90 % | Claude |
| Eignung für lange Prompts | Mittel | Exzellent | Claude |
| Eignung für kurze Prompts | Ab 1024 Token | Opus/Haiku ab 4096 Token | OpenAI |
| Agenten / Tool-Nutzung | Tool-Definition belegt Prompt | Tools separat cachebar | Claude |
| Geringe Prompt-Standards | Fehlerunanfällig | Fehleranfällig | OpenAI |
| TTL-Steuerung | Nicht unterstützt | 5 Min. / 1 Std. wählbar | Claude |

Praxis-Guide: Cache-Abrechnung für OpenAI und Claude
Nach der Theorie folgt nun die Praxis: Hier sind die kompakten Code-Beispiele, die Sie direkt in Ihre Projekte übernehmen können.
Code-Beispiel für OpenAI-Cache-Abrechnung
OpenAI benötigt keine speziellen Cache-Parameter. Der Schlüssel liegt darin, statische Inhalte an den Anfang und dynamische Inhalte an das Ende zu stellen. Die Trefferquote lässt sich über usage.prompt_tokens_details.cached_tokens überprüfen.
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
LONG_SYSTEM = "(Ihr 100k-Token-langer System-Prompt, muss am Anfang stehen und immer identisch sein)"
response = client.chat.completions.create(
model="gpt-5.5",
messages=[
{"role": "system", "content": LONG_SYSTEM},
{"role": "user", "content": "Wie ist das Wetter heute?"} # Dynamischer Inhalt am Ende
],
)
# Überprüfung des Cache-Treffers
print(response.usage.prompt_tokens_details.cached_tokens)
Code-Beispiel für Claude-Cache-Abrechnung
Claude erfordert eine explizite cache_control-Angabe, die in den Inhaltsblöcken von system oder messages markiert werden muss. Hier ist die typische Verwendung mit "System + 1 Breakpoint".
import anthropic
client = anthropic.Anthropic(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com"
)
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1024,
system=[
{
"type": "text",
"text": "(4096+ Token langer System-Prompt, muss ganz vorne stehen)",
"cache_control": {"type": "ephemeral"} # Standard 5 Min, änderbar auf ttl="1h"
}
],
messages=[{"role": "user", "content": "Wie ist das Wetter heute?"}],
)
# Überprüfung des Cache-Treffers
print(response.usage.cache_read_input_tokens,
response.usage.cache_creation_input_tokens)
Vollständiger Code mit 4 Breakpoints für mehrstufiges Caching
import anthropic
client = anthropic.Anthropic(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com"
)
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1024,
tools=[
{
"name": "search_db",
"description": "...",
"input_schema": {...},
"cache_control": {"type": "ephemeral", "ttl": "1h"} # Längste TTL nach oben
}
],
system=[
{
"type": "text",
"text": "Zusammenfassung der Wissensdatenbank (bleibt langfristig gleich)",
"cache_control": {"type": "ephemeral", "ttl": "1h"}
},
{
"type": "text",
"text": "Tägliche dynamische Anweisungen (wird täglich aktualisiert)",
"cache_control": {"type": "ephemeral"} # Standard 5 Minuten
}
],
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": "Wichtige Daten aus dem Finanzbericht der letzten Woche..."},
{
"type": "text",
"text": "Bitte fasse das für mich zusammen",
"cache_control": {"type": "ephemeral"}
}
]
}
]
)
Der Hauptunterschied: OpenAI agiert völlig transparent ohne explizites Caching, während Claude den Entwickler zwingt, aktiv über Cache-Grenzen nachzudenken. Über eine einheitliche API-Schnittstelle können Sie durch einfaches Umschalten des model-Feldes nahtlos zwischen beiden Anbietern wechseln.
Entscheidungshilfe: OpenAI vs. Claude Cache-Abrechnung
Kurz gefasst: Je komplexer die Anwendung, je länger die Prompts und je häufiger die Aufrufe, desto mehr zahlt sich der 90%-Rabatt von Claude aus. Bei einfachen Anwendungen mit kurzen Prompts und schnellen Release-Zyklen ist die Konfigurationsfreiheit von OpenAI die bessere Wahl.
Empfohlene Vorgehensweise:
- Schritt 1: Echte Last messen. Analysieren Sie die durchschnittliche Token-Anzahl Ihrer System-Prompts und das tägliche Aufrufvolumen. Diese Werte bestimmen Ihr Einsparpotenzial.
- Schritt 2: Hauptmodell wählen. Wenn die Leistungsfähigkeit für Ihre Anforderungen ausreicht, bevorzugen Sie das Modell mit den attraktiveren Cache-Rabatten.
- Schritt 3: Prompt-Engineering. Platzieren Sie "wiederkehrende Inhalte" am Anfang und "variable Inhalte" am Ende oder hinter einem eigenen Breakpoint.
🚀 Schnellstart-Empfehlung: Nutzen Sie die Plattform APIYI (apiyi.com), um Prototypen schnell aufzusetzen. Sie können OpenAI und Claude über eine einheitliche Schnittstelle ansprechen, ohne mehrere SDKs integrieren zu müssen. Durch einfaches Ändern des
model-Feldes wechseln Sie zwischen den Modellen, und die Cache-Abrechnungsdaten werden über das OpenAI-kompatible Protokoll zurückgegeben, was den direkten Vergleich erleichtert.
Häufige Fragen zur Cache-Abrechnung bei OpenAI und Claude
F1: Warum „funktioniert“ das Caching bei OpenAI bei mir nicht?
Dafür gibt es meist drei Gründe: Erstens ist die Gesamtlänge der Eingabeaufforderung kürzer als 1024 Token; zweitens wurden dynamische Inhalte (wie Zeitstempel oder Benutzer-IDs) an den Anfang der Eingabeaufforderung gestellt, wodurch das Präfix bei jedem Aufruf unterschiedlich ist; drittens lag zwischen zwei aufeinanderfolgenden Anfragen ein Zeitraum von mehr als 5–10 Minuten, wodurch der Cache automatisch geleert wurde. Wir empfehlen, dieselbe Eingabeaufforderung zweimal hintereinander zu senden und zu beobachten, ob cached_tokens einen Wert ungleich Null liefert, um Umgebungsprobleme schnell auszuschließen.
F2: Kann die 4096-Token-Mindestschwelle bei Claude umgangen werden?
Nein. Bei Opus 4.7/4.6/4.5 und Haiku 4.5 müssen zwingend 4096 Token erreicht werden, damit sie in den Cache aufgenommen werden. Wenn Ihre System-Eingabeaufforderung tatsächlich nur etwas über 2000 Token umfasst, gibt es zwei Wege: Entweder Sie wechseln zu Sonnet 4.6 (Cache ab 1024 Token) oder Sie ergänzen Ihre System-Eingabeaufforderung um Tool-Definitionen, Beispiel-Dialoge oder Stilrichtlinien, um die 4096-Token-Schwelle zu erreichen.
F3: Lohnt sich der Aufschlag von 25 % für das Schreiben in den Cache?
In den allermeisten Fällen ja. Das 5-Minuten-Caching bei Claude kostet nur 25 % mehr als die Standard-Eingabe, während das Lesen 90 % günstiger ist. Das bedeutet: Sobald derselbe Inhalt nur ein einziges Mal gelesen wird, hat sich der Aufschlag für das Schreiben bereits amortisiert. Bei einem 1-Stunden-Cache sind zwei Lesevorgänge für den Break-even erforderlich. Wenn Sie unsicher sind, ob die Trefferquote ausreicht, erstellen Sie in Ihrer Produktionsumgebung eine Statistik der cache_read_input_tokens über 24 Stunden – die Daten zeigen Ihnen die tatsächlichen Einsparungen.
F4: Können OpenAI und Claude gleichzeitig Caching nutzen?
Ja, und das ist sogar empfehlenswert. Die Caching-Mechanismen beider Anbieter beeinflussen sich nicht gegenseitig. Sie können in einem Projekt für verschiedene Geschäftsmodule unterschiedliche Modelle wählen: Zum Beispiel OpenAI für die Absichtserkennung (kurze Eingabeaufforderung, hohe Frequenz) und Claude für die Zusammenfassung langer Dokumente (lange Eingabeaufforderung, tiefe Schlussfolgerungen). Durch eine einheitliche Zugriffsschicht, die ein System für Eingabeaufforderungs-Vorlagen nutzt, vermeiden Sie die doppelte Pflege zweier Caching-Strategien.
F5: Wie können Entwickler in China die Caching-Effekte von OpenAI und Claude schnell testen?
Der direkteste Weg ist die Nutzung einer einheitlichen Zugriffsplattform, die von China aus erreichbar ist. Wir empfehlen APIYI (apiyi.com). Diese Plattform bietet für OpenAI und Claude jeweils OpenAI-kompatible Protokollschnittstellen und leitet die Caching-Abrechnungsfelder beider Anbieter (cached_tokens und cache_read_input_tokens) direkt durch. Sie können beide Modelle in einem einzigen Skript ausführen und die tatsächlichen Einsparungen direkt vergleichen, ohne separate Konten bei beiden Anbietern beantragen und pflegen zu müssen.
Fazit: Wie wählt man die richtige Cache-Abrechnung für OpenAI und Claude?
Zurück zum Kernkonflikt: Geld sparen vs. Aufwand sparen – das ist der grundlegende Unterschied bei der Cache-Abrechnung von OpenAI und Claude. OpenAI deckt mit einer Konfiguration ohne Aufwand und moderaten Rabatten 80 % der gängigen Szenarien ab. Claude gewinnt mit expliziten Deklarationen und extremen Rabatten bei großen, langen Eingabeaufforderungen und hochfrequenten Produktionslasten.
Entscheidungsprinzip in drei Sätzen:
- Eingabeaufforderung < 4096 Token und einfaches Geschäftsszenario → Wählen Sie das OpenAI-Caching und profitieren Sie direkt von 50–75 % Rabatt.
- Eingabeaufforderung > 4096 Token und mehrfaches Lesen pro Minute → Wählen Sie das 5-Minuten-Caching von Claude und profitieren Sie direkt von 90 % Rabatt.
- Agenten / Batch / stundenübergreifende Aufrufe → Wählen Sie das 1-Stunden-Caching von Claude; bereits nach 2 Lesevorgängen amortisiert sich die Investition.
Unser technischer Rat: Optimieren Sie zuerst die Struktur Ihrer Eingabeaufforderung, bevor Sie über Cache-Rabatte verhandeln. Platzieren Sie statische Inhalte am Anfang und dynamische am Ende. Führen Sie dann parallele Lasttests für beide Lösungen durch und treffen Sie Ihre endgültige Wahl auf Basis der tatsächlichen Abrechnungsdaten.
Wir empfehlen, die Effekte schnell über APIYI (apiyi.com) zu validieren, um die für Ihr Unternehmen am besten geeignete Caching-Lösung zu erhalten, ohne sich an einen einzigen Anbieter zu binden.
Autor: APIYI Technik-Team – Spezialisiert auf die praktische Anwendung von APIs für große Sprachmodelle. Wenn Sie mehr über Kosten- und Leistungsdaten der Modellreihen OpenAI, Claude und Gemini in realen Geschäftsszenarien erfahren möchten, besuchen Sie APIYI (apiyi.com) für aktuelle Bewertungsberichte und kostenlose Testguthaben.