واجهت العديد من الفرق التي تدمج Gemini API في خدمات التعرف على الصور حيرة مشتركة: فعند إرسال نفس الصورة واستخدام نفس الموجه (Prompt) عبر موقع gemini.google.com، ينجح النموذج في التعرف على التفاصيل بدقة وتقديم إجابات مهيكلة؛ ولكن عند الانتقال إلى استخدام gemini-3.5-flash API للقيام بنفس المهمة، تكون النتائج خشنة بشكل ملحوظ، بل وقد تغفل عن معلومات جوهرية. هذا التباين في الأداء بين "قوة الموقع" و"ضعف الـ API" لا يعني أن النموذج نفسه قد تم إضعافه، بل يعني أنك بدأت تلاحظ الفجوة الهندسية بين نسخة الويب والـ API.
تتمحور هذه المقالة حول استنتاج جوهري: نسخة الويب من Gemini هي عبارة عن "وكيل" (Agent) متكامل يقوم تلقائيًا بتحسين الموجهات، وإجراء الاستدلال متعدد الخطوات، واستدعاء الأدوات، والتحقق من النتائج؛ بينما استدعاء الـ API يمنحك "نموذجًا خامًا" (Raw Model) حيث تحصل على ما تطلبه بالضبط. بعد فهم هذه الفجوة، ستتمكن من خلال 6 نصائح لتحسين الـ API — تتجاوز مجرد "تعديل الموجهات" — من جعل نتائج التعرف على الصور لديك تضاهي أداء الموقع الرسمي بثبات.

لماذا أداء التعرف على الصور في Gemini API أقل من نسخة الويب: الفجوة بين الوكيل والنموذج الخام
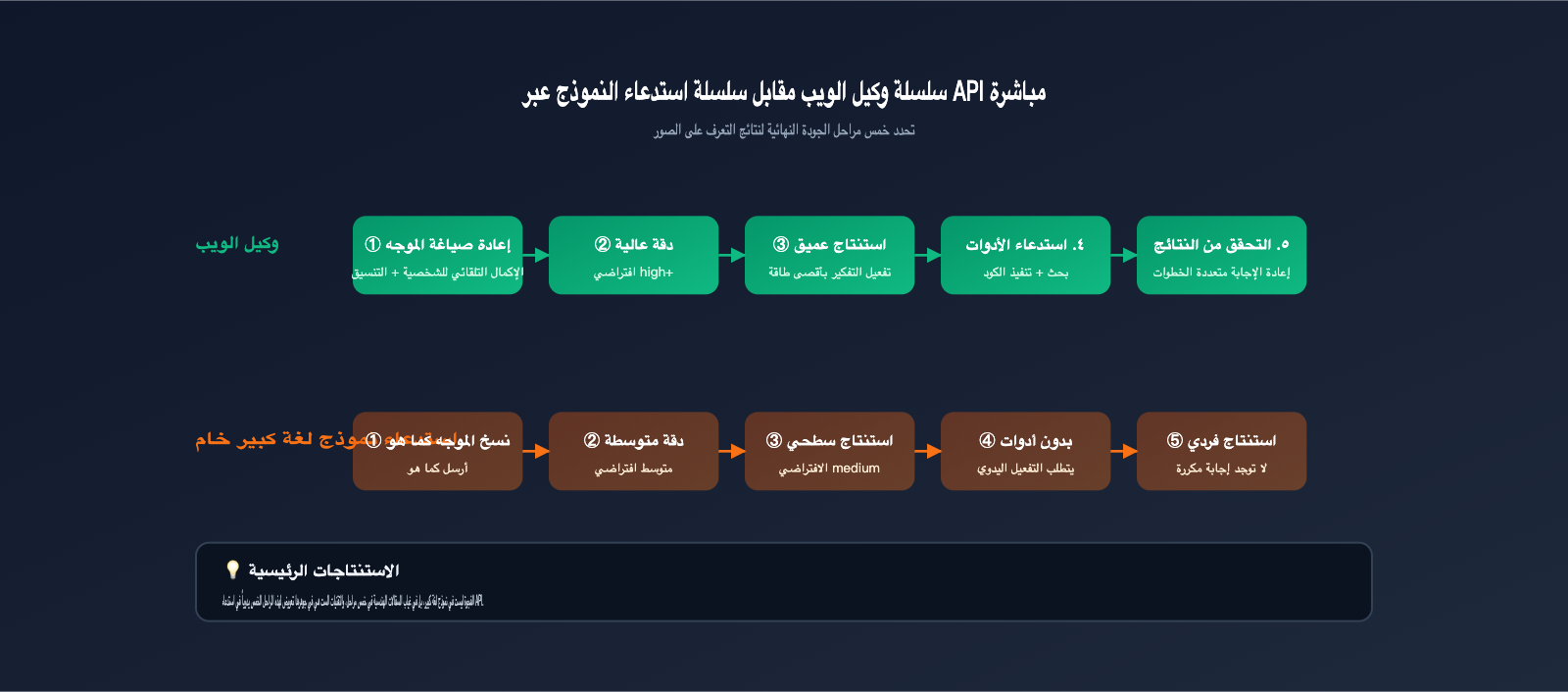
لتوضيح هذه الفجوة، يجب أولاً فهم مقدار العمل الذي يقوم به موقع gemini.google.com نيابة عنك منذ لحظة إرسالك للصورة وحتى حصولك على الإجابة النهائية. استنادًا إلى وثائق "الرؤية الوكيلة" (Agentic Vision) التي نشرتها جوجل وما لاحظناه في APIYI (apiyi.com) من فروقات في الاستجابة بين الموقع والـ API، فإن نسخة الويب هي في جوهرها "وكيل" (Agent) موجه للمنتج مبني حول النموذج الأساسي، وهي تقوم تلقائيًا بـ 5 مهام لم تطلبها أنت بشكل صريح:
- إعادة صياغة الموجه الخاص بك تلقائيًا، وتحويل "تعرف على هذه الصورة" إلى تعليمات كاملة تتضمن الدور، والمهمة، وتنسيق المخرجات.
- معالجة الصور داخليًا بدقة أعلى لضمان عدم ضغط التفاصيل إلى بكسلات غير واضحة.
- تفعيل ميزانية استدلال عالية الكثافة افتراضيًا (مشابه لـ thinking_level=high)، مما يمنح النموذج وقتًا "للتفكير".
- استدعاء أدوات مدمجة مثل تنفيذ الأكواد والبحث عبر الويب عند الحاجة لإجراء تحقق متقاطع، والتأكد من مصداقية التفاصيل.
- تنسيق النتائج وإجراء حكم "إعادة الإجابة"، حيث يتم سؤال النموذج مرة أخرى إذا كانت الإجابة غامضة.
أما عند استدعاء الـ API مباشرة، فلا تحدث أي من هذه المهام الخمس تلقائيًا. بعبارة أخرى، أنت تستدعي "نموذجًا" كامل القدرات، لكنك تفتقد إلى "السقالات الهندسية" (Engineering Scaffolding) المتكاملة. يوضح الجدول التالي الفروقات بين طريقتي الاستخدام في المسارات الرئيسية:
| وجه المقارنة | موقع gemini.google.com | gemini-3.5-flash API |
|---|---|---|
| معالجة الموجه | إعادة صياغة تلقائية، إكمال الدور والتنسيق | تنفيذ حرفي لما يدخله المستخدم |
| دقة الصورة | دقة عالية افتراضية | دقة متوسطة افتراضية، تتطلب ضبطًا يدويًا |
| ميزانية الاستدلال | كثافة عالية، بدون حد أقصى صريح | متوسطة افتراضيًا، يمكن ضبطها يدويًا عبر thinking_level |
| استدعاء الأدوات | وصول افتراضي للبحث وتنفيذ الأكواد | معطل افتراضيًا، يتطلب تفعيلًا صريحًا |
| التحقق من النتائج | تحقق متعدد الخطوات بواسطة الوكيل | استدلال لمرة واحدة، بدون تحقق |
| شفافية الفوترة | مغطاة بباقة اشتراك شهرية | فوترة منفصلة حسب الـ Token |
نوصي بتجربة تشغيل نفس الصورة والموجه عبر بوابة مجمعة مثل APIYI (apiyi.com) للمقارنة بين نتائج التعرف على الصور لكل من gemini-3.5-flash API، وClaude Opus، وGPT-5.5، حيث يمكنك بسرعة تحديد ما إذا كانت المهمة الحالية معطلة بسبب قدرة النموذج، أم بسبب المسار الهندسي.
نصيحة Gemini API الأولى: رفع قيمة المعامل media_resolution
بدءاً من سلسلة Gemini 3، تم تقديم المعامل media_resolution الذي يتحكم بشكل مباشر في عدد الـ Token التي يخصصها الـ API "لرؤية" الصورة. يتوفر هذا المعامل بأربع درجات: low، medium، high، و ultra high، وعادة ما تكون القيمة الافتراضية هي medium. بالنسبة للصور التي تحتوي على تفاصيل دقيقة مثل النصوص الصغيرة، الفواتير، المخططات الكهربائية، أو لقطات واجهات المستخدم (UI)، غالباً ما تكون القيمة medium غير كافية، حيث يقوم النموذج بضغط الصورة إلى خريطة ميزات خشنة، مما يؤدي إلى فقدان التفاصيل.
يوضح الجدول التالي الفروقات الفعلية بين الدرجات الأربع، لمساعدتك في الاختيار بناءً على نوع المهمة:
| مستوى الدقة | استهلاك الـ Token | سيناريوهات الاستخدام | المشاكل الشائعة |
|---|---|---|---|
| low | الأدنى | الصور المصغرة، التعرف على الشعارات | فقدان شبه كامل للنصوص الصغيرة |
| medium (افتراضي) | متوسط | الصور العادية، صور الأشخاص | تفاصيل غير واضحة |
| high | مرتفع | المستندات، الجداول، الفواتير | المعلومات مقروءة بشكل جيد |
| ultra high | الأعلى | المخططات المعقدة، واجهات UI المزدحمة | قريبة من دقة الموقع الرسمي |
بالنسبة لمهام التعرف على الصور، فإن رفع هذا المعامل من medium إلى high عادة ما يؤدي فوراً إلى تحسين دقة التعرف بمستوى ملحوظ. إذا كانت ميزانيتك تسمح، وكانت المهمة تتضمن نصوصاً صغيرة أو جداول مزدحمة، فإن اختيار ultra high يعد خياراً منطقياً.
# استدعاء gemini-3.5-flash عبر APIYI مع تحديد دقة الوسائط high صراحةً
from google import genai
from google.genai import types
client = genai.Client(
api_key="YOUR_APIYI_KEY",
http_options={"base_url": "https://api.apiyi.com"}
)
resp = client.models.generate_content(
model="gemini-3.5-flash",
contents=[image_part, "استخرج جميع النصوص المرئية في الصورة وأخرجها في شكل جدول"],
config=types.GenerateContentConfig(
media_resolution="MEDIA_RESOLUTION_HIGH"
)
)
print(resp.text)
عند الاستدعاء عبر APIYI (apiyi.com)، يتم تمرير المعاملات مباشرة إلى الطبقة الأساسية دون تغليف إضافي من البوابة، لذا يمكنك تمرير القيم بثقة وفقاً للوثائق الرسمية.
نصيحة Gemini API الثانية: تفعيل thinking_level=high صراحةً
قدم نموذج Gemini 3.5 Flash المعامل thinking_level للتحكم في عمق التفكير الداخلي للنموذج قبل إنتاج الإجابة. في مهام التعرف على الصور، غالباً ما يكون الفرق بين رؤية التفاصيل بوضوح أو ارتكاب خطأ هو "التفكير لفترة كافية" و"التفكير بعناية". يميل الـ API افتراضياً إلى تفضيل السرعة على الجودة، لذا يُنصح في مهام التعرف على الصور بضبط هذا المعامل يدوياً على high، للسماح للنموذج بالحصول على وقت كافٍ للاستدلال المكاني والعد، تماماً كما يفعل في نسخة الويب.
| مستوى التفكير | السيناريوهات الموصى بها | الفرق في التجربة |
|---|---|---|
| low | المحادثات البسيطة، تحديد الأنماط | سرعة عالية، تعرف خشن |
| medium | الأسئلة والأجوبة العادية | مستوى متوسط |
| high (موصى به للصور) | المستندات، الفواتير، العد، الاستدلال المكاني | تجربة قريبة من الموقع الرسمي |
تؤكد الوثائق الرسمية على نقطة غير بديهية: بعد استخدام thinking_level=high، يجب عليك كتابة الموجه (Prompt) بشكل أكثر مباشرة وإيجازاً، وتجنب أساليب "سلسلة الأفكار" القديمة مثل "يرجى التفكير خطوة بخطوة، يرجى مراعاة مختلف الحالات". هذه الأساليب كانت مخصصة لتعويض نقص قدرات النماذج القديمة، أما مع سلسلة Gemini 3، فقد تجعل النموذج "يفرط في التحليل".
🎯 نصيحة اختيار المعاملات: اجعل الجمع بين
media_resolution=HIGHوthinking_level=highهو الإعداد الافتراضي لمهام التعرف على الصور، وقم بتضمينه في قوالب الاستدعاء الخاصة بك على APIYI (apiyi.com). لاحقاً، يمكنك إجراء تعديلات دقيقة نحوultra highأوlowبناءً على تجربة العمل الفعلية، لتجنب تجربة المعاملات بشكل متكرر في كل طلب.
نصيحة Gemini API الثالثة للتعرف على الصور: ضع التعليمات في system_instruction بدلاً من user prompt
من الأخطاء الشائعة عند استخدام API هو حشر كل شيء داخل user prompt: إعدادات الشخصية، وصف المهمة، تنسيق المخرجات، وأسئلة المستخدم، كلها مكدسة في نص واحد. هذا الأسلوب يجبر النموذج على إعادة قراءة السياق بالكامل في كل مرة، بينما "الموجه النظامي" (System Prompt) في إصدار الويب يستفيد من التخزين المؤقت وإعادة الاستخدام.
الطريقة الصحيحة هي وضع "تعليماتك الثابتة" داخل system_instruction:
config = types.GenerateContentConfig(
media_resolution="MEDIA_RESOLUTION_HIGH",
thinking_level="high",
system_instruction=(
"أنت مساعد دقيق لتحليل الصور."
"عند الإجابة، اعتمد فقط على التفاصيل المرئية بوضوح في الصورة، ولا تستنتج أي شيء من فراغ."
"أخرج النتائج بتنسيق JSON مهيكل، مع حقول ثابتة هي entities/attributes/text."
)
)
هذا الأسلوب يوفر فائدتين: أولاً، يلتزم النموذج بقواعد موحدة في كل إجابة، مما يجعل النتائج أكثر استقراراً. ثانياً، عند تفعيل ميزة التخزين المؤقت للموجه النظامي (System Prompt Caching)، يمكن أن تنخفض تكاليف الإدخال بمقدار 10 أضعاف، وهو أمر ذو قيمة كبيرة لعمليات تحليل الصور التي تُنفذ على دفعات طويلة. في لوحة تحكم APIYI (apiyi.com)، يمكنك مراقبة معدل نجاح التخزين المؤقت لكل معرف نموذج (Model ID) على حدة، مما يسهل عليك متابعة نتائج التحسين.
نصيحة Gemini API الرابعة للتعرف على الصور: فعّل تنفيذ الكود لتمكين النموذج من "تكبير الصورة"
قدمت جوجل في إعلانها عن الرؤية الوكيلة (Agentic Vision) في Gemini 3 Flash بيانات واضحة: تفعيل أدوات تنفيذ الكود فوق النموذج الأساسي يؤدي إلى تحسين جودة مهام التعرف على الصور بنسبة تتراوح بين 5% إلى 10%. يعود السبب في ذلك إلى قدرة النموذج على توليد كود Python داخلياً، يقوم بقص الصورة، تكبيرها، تدويرها، أو قراءة وحدات البكسل، ثم إعادة تغذية النموذج بالصور الفرعية المعالجة لتحليلها. وهذا بالضبط ما يفعله إصدار الويب افتراضياً.
لا يتم تفعيل تنفيذ الكود في API تلقائياً، لذا يجب التصريح عنه بوضوح:
config = types.GenerateContentConfig(
media_resolution="MEDIA_RESOLUTION_HIGH",
thinking_level="high",
tools=[types.Tool(code_execution=types.ToolCodeExecution())]
)
resp = client.models.generate_content(
model="gemini-3.5-flash",
contents=[image_part, "أحصِ عدد الأزرار الحمراء في الصورة واذكر مواقعها"],
config=config
)
بالنسبة لمهام العد، الاستدلال المكاني، وتحليل واجهات المستخدم المزدحمة، وهي مهام أثبتت التجربة الرسمية أن "تنفيذ الكود" يضيف لها قيمة كبيرة، يُعد هذا الخيار هو الأكثر فعالية من حيث التكلفة والأداء. لقد لاحظنا في APIYI (apiyi.com) أن تفعيل تنفيذ الكود يؤدي إلى زيادة طفيفة في زمن الاستجابة (Latency)، لذا ننصح بتفعيله افتراضياً في العمليات غير المتزامنة (Asynchronous)، وتفعيله حسب الحاجة في العمليات المتزامنة.
نصيحة Gemini API الخامسة: استخدم File API للصور الكبيرة بدلاً من تضمين base64
بالنسبة للصور التي يتجاوز حجمها بضعة ميجابايتات، تلجأ العديد من الفرق إلى تضمين الصور مباشرة في جسم الطلب باستخدام ترميز base64. هذه الطريقة مناسبة للصور الصغيرة، ولكن عندما يتجاوز إجمالي حجم الطلب 20 ميجابايت، يتم تفعيل قيود Gemini، مما قد يؤدي إلى ضغط الصور تلقائياً بشكل غير مرئي، وهو ما يؤدي بدوره إلى انخفاض جودة التعرف.
لقد حددت الوثائق الرسمية حدوداً واضحة للتعامل مع الصور:
| حجم الصورة | طريقة النقل الموصى بها | السبب |
|---|---|---|
| أقل من 5 ميجابايت | تضمين base64 | طلب خفيف واستدعاء بسيط |
| 5~20 ميجابايت | رفع عبر File API | تجنب تضخم حجم الطلب |
| أكبر من 20 ميجابايت | File API إلزامي | ترميز base64 قد يفسد الطلب |
| إعادة استخدام متكرر | File API موصى به | رفع مرة واحدة واستخدام متعدد، توفير في الـ Token |
من المزايا الأخرى لـ File API هي إمكانية إعادة استخدام نفس الصورة في طلبات متعددة، مما يوفر تكاليف الرفع المتكرر. عند استخدام بوابة APIYI (apiyi.com)، فإن نقطة نهاية File API تستخدم نفس مجموعة الاعتمادات، مما يغنيك عن الحاجة لفتح حساب Google Cloud منفصل لرفع الصور.

نصيحة Gemini API السادسة: بناء سلسلة وكيل (Agent) للتحقق متعدد الخطوات
بعد تطبيق النصائح الخمس السابقة، ستجد أن استدعاءات API الخاصة بك أصبحت قريبة جداً من تجربة استخدام الموقع الرسمي. لكن هناك "سلاح سري" في النسخة الويب وهو: التحقق متعدد الخطوات. حيث يقوم النموذج بعد توليد الإجابة بإجراء استنتاج ثانٍ للتحقق من الحقائق الجوهرية، وإذا واجه إجابة غير مؤكدة، فإنه يقوم بـ "إعادة التوليد". هذه القدرة لا تتوفر كمفتاح جاهز في API، لذا عليك بناء سلسلة وكيل (Agent) بسيطة بنفسك.
أبسط سلسلة عمل مكونة من خطوتين هي:
- الاستدعاء الأول: اطلب من
gemini-3.5-flashتوليد نتائج تعريف مهيكلة (مخرجات JSON). - الاستدعاء الثاني: أعد إدخال النتائج الأولية مع الصورة الأصلية واسأل النموذج: "بناءً على هذه الصورة، هل كل استنتاج مما يلي صحيح؟"
إذا حدد الاستدعاء الثاني أي حقل "غير صحيح"، فقم بتفعيل استدعاء ثالث لـ "إعادة التوليد". يمكن ربط هذه السلسلة بالكامل باستخدام نفس base_url و مفتاح API على منصة APIYI (apiyi.com)، دون الحاجة إلى خدمات إضافية. بالنسبة للأعمال التي تتطلب دقة عالية (مثل قراءة العقود، المساعدة في تصنيف الصور الطبية، أو مراجعة الامتثال الأمني)، يعد التحقق متعدد الخطوات خطوة حاسمة لرفع الدقة من 90% إلى 98%.
| نوع المهمة | السلسلة المقترحة | معاملات الخطوة الواحدة |
|---|---|---|
| أسئلة وأجوبة عامة | خطوة واحدة | high + thinking_high |
| استخراج البيانات من الوثائق | خطوة واحدة + التحقق عبر JSON | ultra high + thinking_high |
| العد المعقد | خطوتان + تنفيذ الكود | high + thinking_high + tools |
| أعمال عالية الدقة | سلسلة من ثلاث خطوات (تعريف ← تحقق ← إعادة توليد) | ultra high + thinking_high + tools |
قالب معاملات العملي: دمج النصائح الست في استدعاء واحد قابل لإعادة الاستخدام
لتسهيل التطبيق المباشر، إليك "قالب افتراضي لمهام التعرف على الصور"، والذي يدمج النصائح الست السابقة، وهو مناسب كبداية لمعظم الأعمال:
from google import genai
from google.genai import types
client = genai.Client(
api_key="YOUR_APIYI_KEY",
http_options={"base_url": "https://api.apiyi.com"}
)
# التعليمات النظامية
SYSTEM = (
"أنت مساعد تحليل صور دقيق. استشهد فقط بما هو مرئي بوضوح في الصورة،"
"لا تستنتج من العدم. أخرج JSON صارم، بحقول entities/attributes/text."
)
config = types.GenerateContentConfig(
media_resolution="MEDIA_RESOLUTION_HIGH",
thinking_level="high",
system_instruction=SYSTEM,
tools=[types.Tool(code_execution=types.ToolCodeExecution())],
response_mime_type="application/json"
)
resp = client.models.generate_content(
model="gemini-3.5-flash",
contents=[image_part, "قم بتحليل هذه الصورة وفقاً لمتطلبات SYSTEM"],
config=config
)
print(resp.text)
عند النشر الفعلي، يُنصح بتلخيص القالب في طبقة استدعاء SDK موحدة على APIYI (apiyi.com)، حيث يقوم فريق العمل بإرسال الصورة والسؤال فقط، بينما يتم حقن المعاملات بواسطة البوابة (Gateway) لتجنب الوقوع في الأخطاء المتكررة لكل مشروع.

الأسئلة الشائعة (FAQ): توضيح الفروقات بين Gemini API ونسخة الويب في التعرف على الصور
س1: هل سيظل أداء API أقل من نسخة الويب بعد تفعيل هذه الإعدادات؟
في الغالبية العظمى من حالات الاستخدام، ستتمكن من مضاهاة أداء الموقع الرسمي. ومع ذلك، قد تظل هناك فجوة طفيفة في المهام عالية الصعوبة (مثل النصوص الصغيرة جداً، الصور منخفضة الإضاءة، أو الأنماط الفنية الخاصة)، لأن نسخة الويب تستخدم خط معالجة (Pipeline) داخلياً معززاً وغير متاح للعامة. لمثل هذه السيناريوهات، يمكنك إجراء مقارنة أفقية باستخدام نماذج بصرية من مزودين آخرين عبر APIYI (apiyi.com) للعثور على النموذج الأنسب لعملك.
س2: هل سيؤدي ضبط thinking_level=high إلى مضاعفة التكلفة؟
سيؤدي ذلك إلى زيادة في استهلاك رموز (Tokens) الاستنتاج الداخلي، لكنه يؤثر فقط على مرحلة المخرجات. علاوة على ذلك، في مهام التعرف على الصور، تشكل رموز الصور عادةً الجزء الأكبر من التكلفة الإجمالية. إن التحسن في الدقة الناتج عن ضبط مستوى التفكير (thinking) إلى "high" يفوق بكثير التكلفة الإضافية، خاصة في المهام التي تهدف إلى استبدال المراجعة البشرية.
س3: كيف يمكنني تغيير base_url؟ أنا أستخدم حزمة SDK الرسمية من Google.
تدعم حزمة google-genai SDK توجيه الطلبات إلى بوابة APIYI (apiyi.com) عبر http_options={"base_url": "https://api.apiyi.com"}. يمكنك استخدام مفتاح API الذي تم إنشاؤه من لوحة تحكم APIYI، ولا تحتاج إلى مشروع منفصل على Google Cloud.
س4: هل يمكن حل المشكلات عن طريق تحسين الموجه (Prompt) فقط؟
السقف الذي يمكن الوصول إليه عبر تعديل الموجه فقط محدود جداً، فهو لا يغطي القدرات "خارج النموذج" مثل الدقة، وعمق الاستنتاج، واستدعاء الأدوات. من بين النصائح الست في هذا المقال، واحدة فقط تتعلق بالموجه، بينما الخمس الأخرى تتعلق بآليات هندسية.
س5: ماذا أفعل إذا كانت نسخة الويب تتعرف على "العلامات المائية الصينية" في الصور، بينما يغفل عنها الـ API دائماً؟
غالباً ما تعتمد تفاصيل العلامات المائية على مزيج من الدقة العالية وقص الصور عبر تنفيذ الكود. قم بضبط media_resolution إلى ultra high وقم بتفعيل code execution (تنفيذ الكود)، ثم استخدم سلسلة تحقق من خطوتين، وعادةً ما ستتمكن من التعرف عليها بشكل مستقر.
الخلاصة: إضافة القدرات الهندسية لنسخة الويب إلى استدعاءات API الخاصة بك
بالعودة إلى السؤال الأصلي: لماذا تبدو نتائج التعرف على الصور في Gemini API أقل جودة من نسخة الويب؟ الإجابة ليست أن النموذج أصبح أضعف، بل لأن نسخة الويب تأتي محملة بهيكل هندسي متكامل. عندما تستدعي gemini-3.5-flash API مباشرة، فإن إعادة صياغة الموجه، ومستويات الدقة، وميزانية الاستنتاج، واستدعاء الأدوات، والتحقق من النتائج، كلها أمور تحتاج إلى إكمالها بشكل صريح. بعد فهم هذه النقطة، يتضح أن جوهر النصائح الست هو "نقل المهام التي تقوم بها نسخة الويب نيابة عنك إلى سلسلة استدعاء API الخاصة بك".
مسار العمل واضح: ابدأ برفع media_resolution و thinking_level إلى الحد الأقصى، ثم انقل التعليمات إلى system_instruction وقم بتفعيل التخزين المؤقت (Caching). بالنسبة لمهام التعرف المعقدة، قم بتفعيل code execution (تنفيذ الكود)، واستخدم File API للصور الكبيرة، وأخيراً استخدم سلسلة وكيل (Agent) من خطوتين أو ثلاث لضمان دقة عالية في المهام الحساسة. بعد تطبيق هذه المجموعة من الإجراءات، والعودة إلى لوحة تحكم APIYI (apiyi.com) لمقارنة معدلات النجاح وزمن الاستجابة، ستجد أن معظم الفرق التقنية يمكنها تقليص الفجوة بين "نسخة الويب و API" إلى مستوى يكاد لا يُرى بالعين المجردة.
📌 توقيع المؤلف: تم إعداد هذا المقال بواسطة الفريق التقني في APIYI (apiyi.com). للمزيد من أدلة العمل والضبط العملي لنماذج Gemini و Claude و GPT، يرجى متابعة مركز مساعدة APIYI.