ملاحظة من المؤلف: أطلقت OpenAI مؤخراً سلسلة mini الجديدة، حيث أصبح نموذج gpt-5.4-mini متاحاً الآن عبر الـ API، متفوقاً على GPT-5 mini في اختبار SWE-Bench Pro بنسبة 54.4% مقابل 45.7%. تستعرض هذه المقالة بالتفصيل قفزة قدراته، وخصم 90% على المدخلات المخزنة، والمفاضلة بينه وبين إصدارات 4o-mini و5-mini.
إذا كنت لا تزال تستخدم gpt-4o-mini أو gpt-5-mini، فربما لاحظت أن OpenAI أطلقت في 17 مارس 2026 ما وصفته بـ "أقوى نموذج mini لدينا حتى الآن" وهو gpt-5.4-mini. حقق هذا النموذج 54.4% في اختبار SWE-Bench Pro (مقارنة بـ 45.7% لـ GPT-5 mini)، و60.0% في Terminal-Bench 2.0، و72.1% في مهام استخدام الحاسوب (OSWorld-Verified)، كل ذلك مع سرعة استجابة أسرع بمرتين من الجيل السابق.
قد يبدو هذا مجرد تحديث بسيط، لكن القصد من تصميمه يتجاوز ذلك بكثير. فقد حددت OpenAI رسمياً نموذج gpt-5.4-mini كنموذج mini "مُحسّن خصيصاً للبرمجة، واستخدام الحاسوب، والوكلاء الفرعيين (Subagents)"، وهي المرة الأولى التي يتم فيها توفير قدرات الوكلاء (agentic) في فئة النماذج ذات السعر الاقتصادي. سنقوم في هذه المقالة بتفكيك ماهية GPT-5.4 mini، وما الذي يميزه عن 4o-mini و5-mini، وما يعنيه ذلك لعملك الفعلي.
القيمة الجوهرية: قراءة شاملة لخطة دمج GPT-5.4 mini من زوايا قفزة القدرات، وهيكل التسعير، وتحسين التخزين المؤقت، والمفاضلة مع سلسلة mini القديمة، مع تقديم معايير واضحة لاتخاذ قرار الترقية.

نقاط أساسية حول API نموذج GPT-5.4 mini
| النقطة | الشرح | القيمة |
|---|---|---|
| قفزة القدرات | SWE-Bench Pro 54.4% مقابل 45.7% لـ GPT-5 mini | تحسن بنسبة 19% في دقة مهام البرمجة |
| نافذة سياق 400K | 400,000 رمز للمدخلات + 128,000 للمخرجات | معالجة مستودعات الأكواد / المستندات الطويلة دفعة واحدة |
| خصم 90% على التخزين | تخزين المدخلات بسعر $0.075 فقط لكل مليون رمز | انخفاض حاد في التكلفة لسيناريوهات السياق المتكرر |
| استخدام الحاسوب | OSWorld-Verified 72.1% | دعم كامل لأتمتة سطح المكتب لأول مرة في سلسلة mini |
| إتاحة افتراضية | متاح مباشرة في المجموعات الافتراضية لـ APIYI | جاهز للاستخدام الفوري للمستخدمين الجدد دون طلب |
الاختلافات الجوهرية بين GPT-5.4 mini والجيل السابق
نموذج GPT-5.4 mini ليس مجرد "نسخة مخفضة السعر". فقد أجرت OpenAI ترقيات جوهرية في القدرات عبر ثلاثة أبعاد:
أولاً، إدخال تنظيم الوكلاء الفرعيين (Subagents) لأول مرة في فئة الـ mini. في الماضي، كان من المستحيل تقريباً على نماذج mini تنسيق مهام فرعية متعددة بشكل موثوق أو إدارة سلاسل استدعاء الأدوات؛ حيث كانت تفقد السياق أو تتجاهل التعليمات بعد 3-4 خطوات. من خلال آلية "رموز التفكير" (Reasoning Tokens) المعززة والتدريب على اتباع التعليمات، حقق GPT-5.4 mini موثوقية تصل إلى حوالي 90% من إصدار GPT-5.4 القياسي في سيناريوهات تعاون الوكلاء المتعددين، وبتكلفة تعادل 1/6 فقط.
ثانياً، دعم كامل لاستخدام الحاسوب (Computer Use). يُعد GPT-5.4 mini أول نموذج في سلسلة mini من OpenAI يصل بمعدل OSWorld-Verified إلى أكثر من 70%. وهذا يعني أنه يمكنك نشر وكلاء أتمتة سطح المكتب بالكامل بتكلفة mini، للقيام بمهام مثل النقر، وملء النماذج، والتعامل مع الملفات.
ثالثاً، زيادة سرعة الاستجابة بمقدار الضعف. مع الحفاظ على قفزة القدرات، أصبح GPT-5.4 mini أسرع بمرتين من GPT-5 mini. بالنسبة لسيناريوهات الإنتاجية العالية (خدمة العملاء، المعالجة المجمعة)، فهذا يعني توفيراً مباشراً في التكاليف.

دليل البدء السريع لـ API نموذج GPT-5.4 mini
مثال Python مبسط (لاستبدال نماذج mini القديمة)
إذا كنت تستخدم سابقاً gpt-4o-mini أو gpt-5-mini، فما عليك سوى تعديل معامل model للتبديل إلى gpt-5.4-mini، ولن تحتاج لتغيير أي شيء آخر في الكود:
import openai
client = openai.OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gpt-5.4-mini", # هذا السطر هو الوحيد الذي يتغير
messages=[
{"role": "user", "content": "استخدم Python لتنفيذ ذاكرة تخزين مؤقت متزامنة تدعم LRU"}
]
)
print(response.choices[0].message.content)
مثال cURL مبسط
curl https://vip.apiyi.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer YOUR_API_KEY" \
-d '{
"model": "gpt-5.4-mini",
"messages": [
{"role": "user", "content": "لخص النقاط الرئيسية في هذه الوثيقة الطويلة"}
]
}'
نمط استدعاء Computer Use (مدعوم لأول مرة في سلسلة mini)
# تفعيل أدوات Computer Use
response = client.chat.completions.create(
model="gpt-5.4-mini",
messages=[{
"role": "user",
"content": "ساعدني في فتح المتصفح، والبحث عن 'OpenAI API documentation'، والدخول إلى النتيجة الأولى"
}],
tools=[{
"type": "computer_use",
"config": {
"screen_width": 1920,
"screen_height": 1080
}
}]
)
# يقوم النموذج بإرجاع تعليمات تشغيل مهيكلة (مثل النقر/الكتابة/التمرير)
for action in response.choices[0].message.tool_calls:
print(f"الإجراء: {action.function.name}, المعاملات: {action.function.arguments}")
عرض كود الاستدعاء الكامل لبيئة الإنتاج (يتضمن تتبع إصابة الذاكرة المؤقتة وحساب التكاليف)
import openai
from typing import List, Dict
# أسعار GPT-5.4 mini (لكل 1 مليون رمز)
PRICE_INPUT = 0.75
PRICE_INPUT_CACHED = 0.075 # سعر إصابة الذاكرة المؤقتة (خصم 90%)
PRICE_OUTPUT = 4.50
def call_gpt54_mini(
messages: List[Dict],
api_key: str,
max_tokens: int = 4096
) -> Dict:
"""
استدعاء GPT-5.4 mini بمستوى إنتاجي، مع تتبع معدل إصابة الذاكرة المؤقتة
"""
client = openai.OpenAI(
api_key=api_key,
base_url="https://vip.apiyi.com/v1"
)
try:
response = client.chat.completions.create(
model="gpt-5.4-mini",
messages=messages,
max_tokens=max_tokens
)
usage = response.usage
input_tokens = usage.prompt_tokens
output_tokens = usage.completion_tokens
# الرموز التي أصابت الذاكرة المؤقتة (تعتمد على إصدار SDK)
cached_tokens = getattr(usage, 'prompt_tokens_details', {}).get('cached_tokens', 0)
regular_input = input_tokens - cached_tokens
# حساب التكلفة المجزأة
input_cost = (
regular_input / 1_000_000 * PRICE_INPUT +
cached_tokens / 1_000_000 * PRICE_INPUT_CACHED
)
output_cost = output_tokens / 1_000_000 * PRICE_OUTPUT
total_cost = input_cost + output_cost
cache_rate = cached_tokens / max(input_tokens, 1) * 100
print(f"📊 الإدخال: {input_tokens:,} | إصابة الذاكرة: {cached_tokens:,} ({cache_rate:.1f}%)")
print(f"📊 الإخراج: {output_tokens:,} رمز")
print(f"💰 التكلفة الحالية: ${total_cost:.4f}")
print(f"💰 التوفير عبر الذاكرة: ${(cached_tokens / 1_000_000 * (PRICE_INPUT - PRICE_INPUT_CACHED)):.4f}")
return {
"content": response.choices[0].message.content,
"tokens": {
"input": input_tokens,
"cached": cached_tokens,
"output": output_tokens
},
"cost_usd": total_cost,
"cache_hit_rate": cache_rate
}
except openai.RateLimitError:
return {"error": "تم تجاوز حد السرعة، يرجى المحاولة لاحقاً"}
except openai.APIError as e:
return {"error": f"خطأ في API: {str(e)}"}
# مثال على الاستخدام
result = call_gpt54_mini(
messages=[
{"role": "system", "content": "أنت مهندس Python خبير"},
{"role": "user", "content": "ساعدني في مراجعة مشاكل الأمان في هذا الكود المتزامن..."}
],
api_key="YOUR_API_KEY"
)
print(result["content"])
🎯 نصيحة للبدء السريع: أصبح نموذج GPT-5.4 mini متاحاً بالكامل في خدمة وكيل API الخاص بـ APIYI ضمن المجموعة الافتراضية (Default)، ولا يحتاج المستخدمون الجدد لتقديم طلب لاستخدامه. يُنصح بالاتصال عبر منصة APIYI (apiyi.com)، حيث تحصل على 10% إضافية عند شحن 100 دولار، وهو ما يعادل خصم 15% تقريباً عن الموقع الرسمي، مع دعم الاتصال المباشر والتوافق التام مع مكتبة OpenAI SDK.
تفاصيل أسعار API نموذج GPT-5.4 mini
هيكل الأسعار الرسمي
تم رفع تسعير GPT-5.4 mini مقارنة بسلسلة mini القديمة، ولكن يمكن تقليل التكلفة الفعلية بشكل كبير من خلال آلية الذاكرة المؤقتة:
| نوع المحاسبة | السعر (لكل 1 مليون رمز) | ملاحظات |
|---|---|---|
| الإدخال | $0.75 | السعر القياسي |
| إدخال الذاكرة المؤقتة | $0.075 | خصم 90%، توفير كبير في التكلفة |
| الإخراج | $4.50 | يتضمن رموز الاستنتاج (reasoning tokens) |
| إدخال Batch API | $0.75 | نفس السعر القياسي |
| نقطة بيانات المنطقة | +10% | لسيناريوهات الامتثال للبيانات |
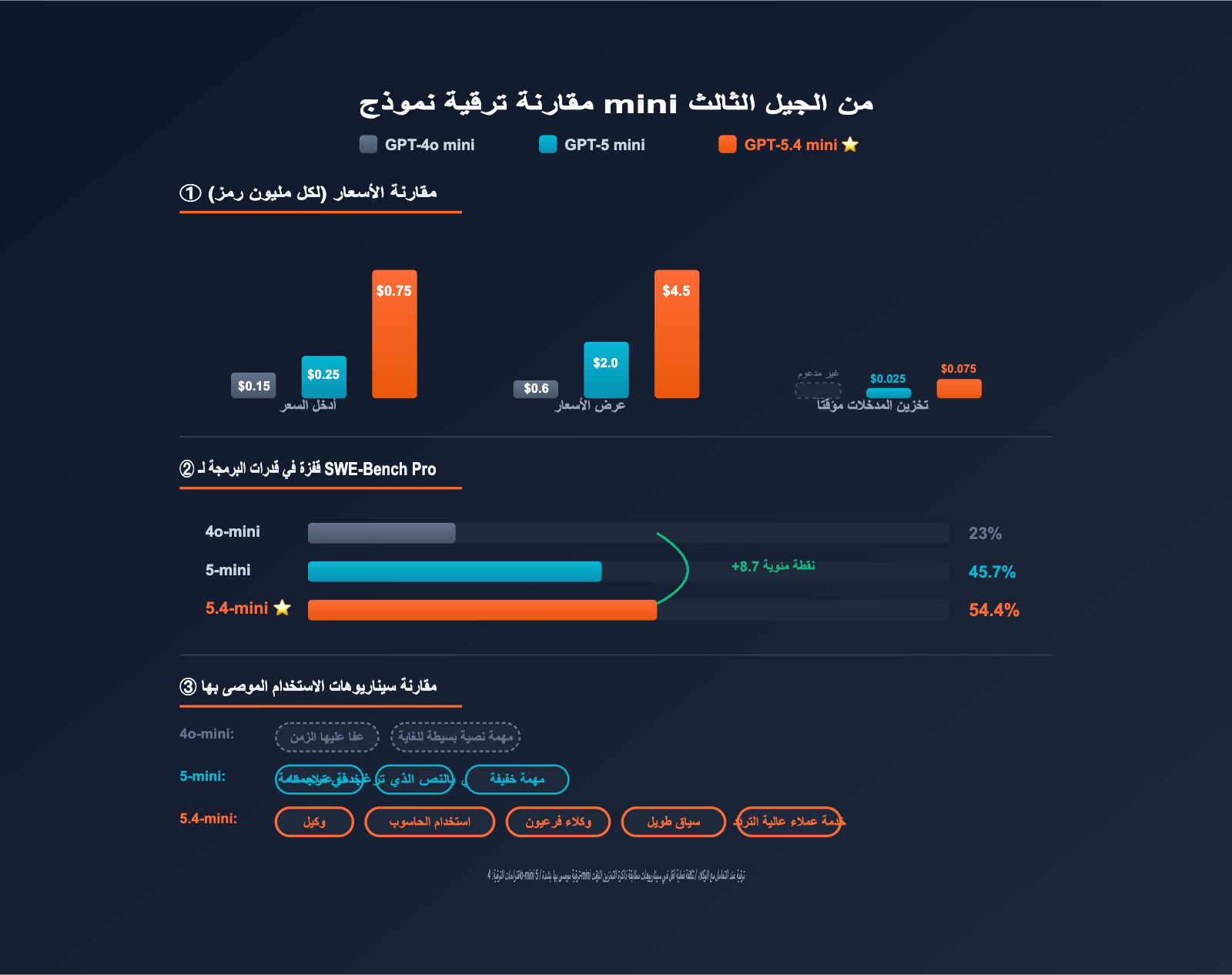
مقارنة أسعار سلسلة mini عبر الأجيال الثلاثة
| النموذج | سعر الإدخال | إدخال الذاكرة | سعر الإخراج | نافذة السياق | الحد الأقصى للإخراج |
|---|---|---|---|---|---|
| GPT-4o mini | $0.15 | غير مدعوم | $0.60 | 128K | 16K |
| GPT-5 mini | $0.25 | $0.025 | $2.00 | 400K | 128K |
| GPT-5.4 mini | $0.75 | $0.075 | $4.50 | 400K | 128K |
⚠️ ملاحظة هامة: السعر القياسي لـ GPT-5.4 mini هو 5 أضعاف سعر GPT-4o mini و3 أضعاف سعر GPT-5 mini. لكن انتبه لحقيقتين: 1) عند تفعيل الذاكرة المؤقتة يمكن أن تنخفض التكلفة إلى $0.0075/1M في بعض السيناريوهات عالية التكرار، 2) القفزة في القدرات تعني أن المهام غالباً لا تحتاج إلى جولات تصحيح متعددة، مما يقلل إجمالي عدد الاستدعاءات.
تقدير التكلفة في سيناريوهات إصابة الذاكرة المؤقتة
يعد خصم 90% على الذاكرة المؤقتة في GPT-5.4 mini الميزة الأكثر استهانة بها في هذا التحديث:
| السيناريو | رموز الإدخال | معدل إصابة الذاكرة | التكلفة الفعلية لكل استدعاء |
|---|---|---|---|
| خدمة عملاء عالية التكرار (إعادة استخدام موجه النظام) | 5K | 80% | $0.0046 |
| مساعد البرمجة (إعادة استخدام السياق) | 50K | 70% | $0.034 |
| أسئلة وأجوبة الوثائق الطويلة (إعادة استخدام الوثيقة) | 200K | 90% | $0.030 |
| تنسيق الوكيل الفرعي (تعليمات مشتركة) | 30K | 85% | $0.0162 |
💰 نصيحة لتحسين الذاكرة المؤقتة: تعمل آلية الذاكرة المؤقتة في GPT-5.4 mini بشكل أفضل في سيناريوهات موجه النظام الطويل + السياق المتكرر. بالنسبة لخدمة العملاء، ومساعد البرمجة، والوثائق الطويلة، قد تكون التكلفة الفعلية أقل من GPT-5 mini. يمكنك الاستفادة من عرض الشحن في APIYI (apiyi.com) لتقليل الفاتورة بشكل أكبر.
قفزة نوعية في قدرات GPT-5.4 mini API
مقارنة الأداء عبر الاختبارات المعيارية
| بُعد التقييم | GPT-4o mini | GPT-5 mini | GPT-5.4 mini | نسبة التحسن |
|---|---|---|---|---|
| SWE-Bench Pro (البرمجة) | ~23% | 45.7% | 54.4% | +8.7pp |
| Terminal-Bench 2.0 | ~30% | ~50% | 60.0% | +10pp |
| OSWorld-Verified (استخدام الحاسوب) | غير مدعوم | ~58% | 72.1% | +14pp |
| سرعة الاستجابة | مرجعي | مرجعي | ضعف السرعة | مضاعف |
تحليل ترقية القدرات
SWE-Bench Pro بنسبة 54.4%: هذه هي النتيجة الأكثر إثارة للاهتمام في GPT-5.4 mini. فقد وصلت النسبة إلى 54.4%، وهي تقترب من أداء النسخة القياسية GPT-5.4 (التي تبلغ 57.7%)، ولكن بتكلفة تعادل سدس سعر النسخة القياسية فقط. بالنسبة للمهام الواقعية مثل إصلاح مشكلات GitHub وإعادة هيكلة قواعد الأكواد، أصبح نموذج mini الآن خياراً يعتمد عليه.
Terminal-Bench بنسبة 60.0%: يعني هذا أن نموذج mini قادر على إنجاز أكثر من 60% من المهام المتعلقة بتنفيذ أوامر الطرفية (Terminal)، وتصحيح الأخطاء، وسير العمل المؤتمت بشكل مستقر. وبالاقتران مع تقنيات الوكلاء الفرعيين (Subagents)، يمكن بناء تطبيقات موثوقة لأتمتة CI/CD، وبوتات مراجعة الأكواد، وغيرها.
OSWorld بنسبة 72.1%: يمثل هذا اختراقاً تاريخياً لسلسلة mini في مهام "استخدام الحاسوب" (Computer Use). أصبح بإمكانك الآن نشر وكلاء أتمتة سطح المكتب بتكلفة mini، للتعامل مع النماذج، والنقر، وعمليات الملفات.
مقارنة بين GPT-5.4 mini والنماذج المماثلة
| النموذج | الإدخال / الإخراج | نافذة السياق | قدرات البرمجة | Computer Use | السيناريوهات الموصى بها |
|---|---|---|---|---|---|
| GPT-4o mini | $0.15 / $0.60 | 128K | ضعيفة | غير مدعوم | قديم، مهام بسيطة جداً |
| GPT-5 mini | $0.25 / $2.00 | 400K | متوسطة | مدعوم جزئياً | خدمة عملاء عامة، مهام خفيفة |
| GPT-5.4 mini | $0.75 / $4.50 | 400K | قوية | مدعوم بالكامل | الوكلاء / Computer Use / سياق طويل |
| GPT-5.4 قياسي | $5.00 / $30.00 | 1M | فائقة | فائقة | استنتاج معقد، قرارات حاسمة |
| Claude Haiku 4.5 | $0.80 / $4.00 | 200K | قوية | غير مدعوم | أسلوب كتابي قوي / تأليف |
نصائح لاتخاذ قرار الترقية
المقارنة بين 4o-mini و 5.4-mini: لا يزال GPT-4o mini يتمتع بميزة سعرية في مهام النصوص البسيطة. لكن قدراته أصبحت متأخرة بشكل ملحوظ، طالما أن تطبيقك يتضمن الاستنتاج، البرمجة، أو سياقاً طويلاً، فإن الترقية إلى 5.4-mini تستحق العناء. حتى مع حساب السعر الذي يبلغ 5 أضعاف، فإن الجودة المحسنة وعدد الاستدعاءات الفعلي غالباً ما يجعلها أكثر جدوى اقتصادية.
المقارنة بين 5-mini و 5.4-mini: لا يزال GPT-5 mini قادراً على أداء مهام خدمة العملاء العامة والترجمة. ولكن إذا كنت بحاجة إلى Computer Use، تنسيق الوكلاء الفرعيين (Subagents)، أو سير عمل وكيل معقد، فإن 5.4-mini هو الخيار الأمثل. في الوقت نفسه، ارتفعت خصومات التخزين المؤقت لتصل إلى 90% مع قيمة مطلقة أعلى، مما يجعلها أكثر توفيراً على المدى الطويل.
المقارنة بين 5.4-mini والنسخة القياسية: يتشابه GPT-5.4 mini مع النسخة القياسية في 80% من المهام الروتينية، بينما يبلغ سعره سدس السعر فقط. فقط عندما تتضمن المهمة استنتاجاً فائقاً (مثل الإثباتات الرياضية أو وكيل معقد يعمل لمدة 20 ساعة)، ستحتاج إلى الانتقال للنسخة القياسية.
📊 نصيحة مسار الترقية: يمكنك من خلال APIYI (apiyi.com) إجراء مقارنة سلسة بين GPT-4o mini / 5-mini / 5.4-mini / 5.4 قياسي باستخدام نفس مفتاح API، فقط عن طريق تعديل معامل
model. هذا النوع من الربط الموحد مناسب جداً للفرق التي تحتاج إلى ترحيل تدريجي أو إجراء اختبارات A/B.
سيناريوهات استخدام GPT-5.4 mini API
إن مزيج "القدرة العالية + تحسين التخزين المؤقت + Computer Use + الوكلاء الفرعيين" في GPT-5.4 mini يجعله مناسباً بشكل خاص للسيناريوهات التالية:
- خدمة العملاء ذات التدفق العالي: معدل نجاح عالٍ في التخزين المؤقت، سرعة استجابة فائقة، وعمق استنتاجي كافٍ للتعامل مع المشكلات المعقدة.
- توليد المحتوى على نطاق واسع: التلخيص الجماعي، الترجمة، وإعادة الصياغة، مع معالجة مستندات كاملة في سياق 400K دفعة واحدة.
- تعاون الوكلاء المتعددين (Subagents): لأول مرة في فئة النماذج المصغرة (mini)، يتم تحقيق تنسيق موثوق للمهام الفرعية.
- وكلاء أتمتة سطح المكتب: بفضل نسبة نجاح 72.1% في OSWorld، أصبح التعامل مع المتصفحات، النماذج، وعمليات الملفات أمراً ممكناً.
- الإكمال البرمجي الخفيف والمراجعة: أداء SWE-Bench Pro بنسبة 54.4% يقترب من النسخة القياسية، مما يجعله مناسباً للدمج في بيئات التطوير (IDE).
- المعالجة الجماعية للمستندات: بالتعاون مع Batch API والتخزين المؤقت، يوفر ميزة تكلفة هائلة عند معالجة آلاف المستندات.
- أدوات التعليم والتدريب: تعزيز رموز الاستنتاج (Inference Tokens) يوفر قدرات أكثر موثوقية في حل المسائل والإجابة على الأسئلة.
🎯 قرار السيناريو: إذا كان تطبيقك يتجاوز 10 آلاف استدعاء يومياً، ومعدل نجاح التخزين المؤقت أعلى من 50%، وتحتاج إلى قدرات استنتاجية أو أدوات — فإن GPT-5.4 mini هو النموذج المصغر الأكثر استحقاقاً للتحويل إليه في عام 2026. يمكنك الوصول إليه مباشرة عبر APIYI (apiyi.com)، ومجموعة Default متاحة دون الحاجة لأي طلبات إضافية.
دليل الوصول إلى GPT-5.4 mini عبر منصة APIYI
سياسة الإتاحة لمجموعة Default
تطبق منصة APIYI على نموذج GPT-5.4 mini سياسة إتاحة مماثلة لـ Grok 4.3، وتختلف عن سياسة GPT-5.5 Pro:
- ✅ مجموعة Default (الافتراضية): متاحة بالكامل، ويمكن للمستخدمين الجدد استخدامها فور التسجيل.
- ✅ مجموعة SVIP (المتقدمة): متاحة بالكامل، دون أي قيود.
- ✅ خصم التخزين المؤقت (Cache): سعر $0.075 لكل 1 مليون رمز متاح بالكامل.
لماذا GPT-5.4 mini متاح لجميع المجموعات بينما GPT-5.5 Pro متاح فقط لـ SVIP؟ يعود السبب الجوهري إلى تقييم مخاطر الاستدعاء الواحد:
- GPT-5.4 mini: تكلفة الاستدعاء الواحد عادة ما تكون بضع سنتات، لذا فإن إتاحته لجميع المجموعات لا تشكل مخاطرة.
- GPT-5.5 Pro: قد تصل تكلفة الاستدعاء الواحد إلى عدة دولارات، لذا يتطلب حماية عبر مجموعة SVIP لتجنب الاستخدام الخاطئ من قبل المبتدئين.
هذا التصميم القائم على إدارة المخاطر يضمن بقاء سلسلة mini ذات عتبة دخول منخفضة لجميع المطورين، بينما توفر النماذج عالية القيمة حماية إضافية عبر المجموعات.
مقارنة التكاليف: APIYI مقابل الموقع الرسمي
| البند | موقع OpenAI الرسمي | APIYI (apiyi.com) |
|---|---|---|
| السعر الأساسي | $0.75 / $4.50 لكل 1M | $0.75 / $4.50 لكل 1M (نفس السعر) |
| خصم التخزين المؤقت | $0.075 / 1M (90%) | $0.075 / 1M (متزامن تماماً) |
| عروض الشحن | لا يوجد | اشحن $100 واحصل على $10 إضافية (10%) |
| التكلفة الفعلية | 100% السعر القياسي | حوالي 90% من السعر القياسي (خصم 15%) |
| الوصول المحلي | يتطلب VPN | اتصال مباشر، لا يحتاج VPN |
| طرق الدفع | بطاقات ائتمان دولية | يدعم العملة الصينية، Alipay، WeChat |
| توافق SDK | OpenAI الأصلي | متوافق تماماً مع OpenAI SDK |
| قيود المجموعات | لا يوجد | Default + SVIP متاح بالكامل |
💰 تحسين التكاليف: عند الوصول إلى GPT-5.4 mini عبر APIYI (apiyi.com)، فإن شحن 100 دولار يمنحك 10% إضافية، وهو ما يعادل خصم 15% عن السعر الرسمي، مع مزامنة كاملة لخصومات التخزين المؤقت. بالنسبة للتطبيقات ذات حجم الاستدعاء الكبير ونسبة نجاح التخزين المؤقت العالية، يمكن أن تكون التكلفة الإجمالية أقل بنسبة تزيد عن 20% مقارنة بموقع OpenAI الرسمي.
الأسئلة الشائعة (FAQ)
س1: ما هو GPT-5.4 mini؟ وما الفرق الجوهري بينه وبين GPT-5 mini و GPT-4o mini؟
GPT-5.4 mini هو الجيل الجديد من نماذج mini الذي أطلقته OpenAI في 17 مارس 2026، ويُصنف كـ "أقوى نموذج mini لدينا حتى الآن". الفروقات الجوهرية: 1) يتفوق بشكل ملحوظ في اختبار SWE-Bench Pro بنسبة 54.4% مقارنة بـ 45.7% لـ GPT-5 mini و 23% لـ 4o-mini؛ 2) يدعم لأول مرة بشكل كامل خاصية Computer Use (بنتيجة 72.1% في OSWorld)؛ 3) قدرات تنظيم الوكلاء الفرعيين (Subagents) أصبحت متاحة بسعر mini؛ 4) سرعة الاستجابة أسرع بمرتين من 5 mini. ومع ذلك، ارتفع السعر إلى $0.75/$4.50، ويمكن تعويض جزء من هذه التكلفة عبر التخزين المؤقت.
س2: أنا أستخدم حالياً gpt-4o-mini / gpt-5-mini، هل يستحق الترقية إلى 5.4-mini؟
لمستخدمي 4o-mini: نوصي بشدة بالترقية؛ فالفجوة في القدرات أصبحت كبيرة جداً، وحتى مع حساب السعر بـ 5 أضعاف، فإن الجودة الإجمالية وتقليل الحاجة للتصحيح المتكرر تجعل الترقية أكثر جدوى.
لمستخدمي 5-mini: يعتمد ذلك على سيناريو الاستخدام:
- ✅ نوصي بالترقية: إذا كانت تطبيقاتك تتضمن Computer Use، أو وكلاء فرعيين (Subagents)، أو سلاسل أدوات معقدة، أو سياقاً طويلاً (>200K).
- ⏸️ يمكنك الاستمرار: في سيناريوهات خدمة العملاء البسيطة، الترجمة الخفيفة، أو توليد النصوص البسيطة حيث لا يزال 5-mini كافياً.
أفضل ممارسة: قم بإجراء اختبار AB باستخدام نفس مفتاح API على منصة APIYI (apiyi.com) لتقييم أيهما أكثر جدوى.
س3: كيف يتم تفعيل خصم التخزين المؤقت $0.075/1M لـ GPT-5.4 mini؟
آلية التخزين المؤقت في OpenAI تُفعل تلقائياً، ولا تتطلب معاملات إضافية. عندما تتطابق بادئة الموجه (Prompt) التي ترسلها (عادةً ما تكون system prompt + سياق مشترك) مع الطلبات في آخر 5-10 دقائق، سيتم تفعيل التخزين المؤقت تلقائياً، والاستمتاع بخصم 90% ($0.075/1M).
نصائح للتحسين:
- ضع system prompt في بداية مصفوفة الرسائل (messages).
- ضع السياق المشترك (مثل قاعدة المعرفة أو ملخصات المستندات) بعد system prompt.
- ضع استعلام المستخدم الفعلي في النهاية.
- حافظ على استدعاءات عالية التردد (تنتهي صلاحية التخزين بعد 5 دقائق من الخمول).
عند الاستدعاء عبر منصة APIYI (apiyi.com)، تكون خصومات التخزين المؤقت متزامنة تماماً مع الموقع الرسمي دون الحاجة لإعدادات إضافية.
س4: متى يجب استخدام GPT-5.4 mini ومتى يجب استخدام النسخة القياسية من GPT-5.4؟
يفضل استخدام mini في السيناريوهات التالية:
- حجم استدعاءات مرتفع (>10K مرة/يوم).
- نسبة نجاح التخزين المؤقت > 50%.
- المهام من نوع SWE-Bench / Terminal-Bench.
- أتمتة Computer Use.
- بيئات الإنتاج الحساسة للتكلفة.
يفضل استخدام النسخة القياسية في السيناريوهات التالية:
- الإثباتات الرياضية بمستوى FrontierMath.
- الوكلاء (Agents) المعقدون الذين يعملون لساعات طويلة.
- المهام عالية المخاطر مثل قراءة العقود القانونية أو التشخيص الطبي.
- القرارات الحاسمة التي تتجاوز قيمة الاستدعاء الواحد فيها $0.10.
قاعدة بسيطة: 80% من المهام تكفيها نسخة mini، ولا ننتقل للنسخة القياسية إلا في حالات الاستنتاج المعقد للغاية.
س5: كيف يمكن استدعاء GPT-5.4 mini عبر APIYI؟ وما هي التعديلات المطلوبة في الكود؟
منصة APIYI متوافقة تماماً مع OpenAI SDK، فقط اتبع ثلاث خطوات:
- قم بزيارة موقع APIYI (apiyi.com) لتسجيل حساب (لا حاجة لطلب تفعيل، مجموعة Default متاحة مباشرة).
- احصل على مفتاح API.
- عدل
base_urlفي الكود إلىhttps://vip.apiyi.com/v1واضبطmodelعلىgpt-5.4-mini.
client = openai.OpenAI(
api_key="YOUR_KEY",
base_url="https://vip.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gpt-5.4-mini",
messages=[...]
)
شحن 100 دولار يمنحك 10% إضافية، وهو ما يعادل خصم 15% عن السعر الرسمي، مع مزامنة كاملة لخصومات التخزين المؤقت.
س6: هل يدعم GPT-5.4 mini الضبط الدقيق (Fine-tuning)؟
لا يدعم ذلك. هذا أحد القيود الرئيسية الحالية لنموذج GPT-5.4 mini. إذا كان تطبيقك يتطلب الضبط الدقيق، يجب عليك اختيار:
- GPT-5 mini (يدعم الضبط الدقيق، قدرات أقل قليلاً).
- GPT-4o mini (يدعم الضبط الدقيق، قدرات أضعف).
- GPT-5.4 النسخة القياسية (يدعم الضبط الدقيق، بسعر 6 أضعاف).
البديل: استخدام Reasoning Token + Function Calling + آلية التخزين المؤقت في GPT-5.4 mini، والتي غالباً ما تحقق نتائج ممتازة دون الحاجة لضبط دقيق.
س7: كيف يتم استدعاء خاصية Computer Use في GPT-5.4 mini؟
يتم تفعيلها عبر معامل tools:
response = client.chat.completions.create(
model="gpt-5.4-mini",
messages=[{"role": "user", "content": "ساعدني في فتح المتصفح والبحث عن..."}],
tools=[{
"type": "computer_use",
"config": {"screen_width": 1920, "screen_height": 1080}
}]
)
سيعيد النموذج تعليمات تشغيل مهيكلة (click/type/scroll/screenshot)، وعليك تنفيذ هذه الإجراءات في جانب العميل وإرسال النتائج للنموذج لمواصلة الاستنتاج. النتيجة 72.1% في اختبار OSWorld-Verified تعني أن معظم مهام سطح المكتب يمكن إنجازها.
س8: ما هي القيود المعروفة لـ GPT-5.4 mini؟
تشمل القيود الرئيسية ما يلي:
- لا يدعم الضبط الدقيق (Fine-tuning): لا يمكن ضبطه باستخدام مجموعات بيانات مخصصة.
- لا يدعم توليد الصور: مخرجات نصية فقط، لا يمكنه توليد صور.
- السعر أعلى من نماذج mini القديمة: السعر القياسي هو 5 أضعاف سعر 4o-mini، ويحتاج إلى تحسين عبر التخزين المؤقت.
- احتساب Reasoning Token ضمن تكاليف المخرجات: قد تتجاوز تكلفة المخرجات في المهام المعقدة التوقعات.
- رسوم إضافية لتوطين البيانات (+10%): توجد تكاليف إضافية في سيناريوهات الامتثال.
بالنسبة للسيناريوهات الحساسة جداً للوقت (استجابة أقل من ثانية واحدة)، نوصي بالاختبار قبل اتخاذ قرار التبديل.
النقاط الجوهرية لـ GPT-5.4 mini API
- قفزة في القدرات: حقق 54.4% في اختبار SWE-Bench Pro، متفوقاً على GPT-5 mini الذي سجل 45.7% بفارق 8.7 نقطة مئوية كاملة.
- خصم التخزين المؤقت (Cache): خصم 90% على سعر التخزين المؤقت للمدخلات ليصل إلى $0.075 لكل مليون رمز، مما يقلل التكاليف بشكل كبير في سيناريوهات الاستخدام عالي التكرار.
- استخدام الحاسوب (Computer Use): سجل 72.1% في اختبار OSWorld، وهي المرة الأولى التي تدعم فيها سلسلة mini أتمتة سطح المكتب بشكل كامل.
- دعم الوكلاء الفرعيين (Subagents): لأول مرة يتم توفير ميزة التعاون بين الوكلاء المتعددين ضمن فئة أسعار mini.
- نافذة سياق 400 ألف رمز: معالجة كتاب تقني كامل أو قاعدة برمجية ضخمة دفعة واحدة.
- سرعة استجابة مضاعفة: سرعة أكبر بمرتين مع الحفاظ على قفزة نوعية في القدرات.
- إتاحة كاملة عبر Default: متاح مباشرة عبر مجموعة Default في APIYI، دون الحاجة لأي طلبات إضافية.
ملخص
النقاط الرئيسية لـ GPT-5.4 mini API:
- دوافع الترقية: قفزة شاملة في ثلاثة أبعاد رئيسية: SWE-Bench Pro و Terminal-Bench و OSWorld، مع دخول ميزتي "استخدام الحاسوب" والوكلاء الفرعيين إلى فئة أسعار mini لأول مرة.
- تحديد الأسعار: $0.75 / $4.50 لكل مليون رمز، مع خصم 90% على التخزين المؤقت للمدخلات ليصل إلى $0.075، مما يجعل التكلفة الفعلية في السيناريوهات عالية التكرار أقل من إصدار mini القديم.
- طريقة الوصول: استدعاء مباشر عبر مجموعة Default في منصة APIYI (apiyi.com)، مع عرض "اشحن 100 واحصل على 10 إضافية"، واتصال مباشر من داخل الصين دون الحاجة لبرامج كسر الحجب.
إن GPT-5.4 mini ليس مجرد "نسخة أغلى من GPT-5 mini"، بل هو خطوة محورية من OpenAI لنقل قدرات الوكلاء (Agentic) إلى فئة الأسعار الاقتصادية. بالنسبة للتطبيقات التي تستدعي النموذج أكثر من 10 آلاف مرة يومياً، وتتمتع بمعدل نجاح تخزين مؤقت يتجاوز 50%، وتحتاج إلى قدرات الوكلاء أو استخدام الحاسوب، فإن هذه الترقية تعتبر خياراً لا غنى عنه. أما بالنسبة للمهام النصية البسيطة، فلا يزال بإمكانك الاستمرار في استخدام GPT-4o mini أو GPT-5 mini.
نوصي بالوصول السريع إلى GPT-5.4 mini عبر منصة APIYI (apiyi.com)، حيث تتوفر المجموعة الافتراضية (Default) دون طلب، وتتم مزامنة خصومات التخزين المؤقت بالكامل، مع ميزة الشحن الإضافي بنسبة 10% واتصال مستقر ومباشر.
قراءة إضافية
إذا كنت مهتماً بـ API الخاص بنموذج GPT-5.4 mini، فنوصيك بمتابعة القراءة:
- 📘 دليل ربط API لنموذج GPT-5.5 Pro – تعرف على نموذج الاستدلال الرائد من OpenAI، وكيف يكمل نموذج mini في سيناريوهات الاستخدام.
- 📊 تحليل عميق لآلية التخزين المؤقت في OpenAI: أفضل الممارسات للحصول على خصم 90% – أتقن التقنيات الهندسية لتحسين التخزين المؤقت.
- 🚀 تطبيق عملي: بناء وكيل أتمتة لاستخدام الحاسوب (Computer Use) استناداً إلى GPT-5.4 mini – استكشف تطبيقات الأتمتة المكتبية على مستوى الإنتاج.
📚 المراجع
-
وثائق OpenAI الرسمية لنموذج GPT-5.4 mini: مواصفات النموذج، التسعير، وأمثلة الاستدعاء.
- الرابط:
developers.openai.com/api/docs/models/gpt-5.4-mini - ملاحظة: احصل على أحدث المعايير التقنية الرسمية والموثوقة.
- الرابط:
-
تقييم DataCamp لنموذج GPT-5.4 mini: تفاصيل معايير الأداء (Benchmark) والمقارنة بين الأجيال.
- الرابط:
datacamp.com/blog/gpt-5-4-mini-nano - ملاحظة: تقييم مستقل من طرف ثالث، مناسب للمقارنة الأفقية مع النماذج المماثلة.
- الرابط:
-
وثائق ربط APIYI لنموذج GPT-5.4 mini: حلول الاستدعاء المحلية، شرح المجموعات، وعروض الشحن.
- الرابط:
docs.apiyi.com - ملاحظة: دليل عملي للربط مخصص للمطورين داخل الصين.
- الرابط:
-
صفحة تسعير OpenAI: جدول الأسعار الكامل وشرح آلية التخزين المؤقت.
- الرابط:
developers.openai.com/api/docs/pricing - ملاحظة: أحدث معايير الفوترة لجميع النماذج.
- الرابط:
المؤلف: الفريق التقني لـ APIYI
النقاش التقني: نرحب بمناقشاتكم في قسم التعليقات حول تجربة الترقية لنموذج GPT-5.4 mini، ولمزيد من المعلومات حول ربط النماذج، يمكنكم زيارة مركز توثيق APIYI عبر الرابط docs.apiyi.com.